一种基于用户隐式反馈的微博信息过滤方法
2016-11-02石曦彤汪嘉琪刘邦望
石曦彤,汪嘉琪,刘邦望,李 叶
(东北林业大学信息与计算机工程学院,哈尔滨 150040)
一种基于用户隐式反馈的微博信息过滤方法
石曦彤,汪嘉琪∗,刘邦望∗,李 叶∗
(东北林业大学信息与计算机工程学院,哈尔滨150040)
微博平台的兴起革新了人们的互动方式,给人们获取信息带来了极大便利。然而,在信息超载的环境下,人们需要花费大量的时间从许多冗余的微博信息中寻找自己感兴趣的信息,剔除无用信息。针对该问题,本文设计了一种新的方法对用户的微博信息进行过滤。该方法在传统方法基础上增加用户反馈环节;同时,考虑用户兴趣随时间变化的特点,在进行信息过滤时考虑时间对兴趣度的影响。该方法为微博信息个性化过滤提供了一种新思路。
微博;信息过滤;隐式反馈;时间权重
0 引 言
新浪微博是一个由新浪网筹策推出的提供微型博客类服务的社交网站。通过微博,用户可以将看到的、听到的、想到的事情写成一句话,或发送一张图片,通过电脑或者手机随时随地提送给朋友,一起分享、讨论;还可以关注朋友,即时看到朋友们的发布信息。微博平台的兴起创意变革了人们的互动方式,为人们获取信息带来了极大便利。然而,在信息超载[1-2]的环境下,人们需要从大量的资源内容中寻找自己感兴趣的信息,剔除那些无用的信息。无用信息不仅会造成网络资源浪费,影响人们的正常有序交流,甚至还可能会被用来散播虚假消息、商业广告或恶意链接,从而造成重大的经济和社会危害。
为了提高用户体验,有针对性地为用户提供个性化的关注信息,设计一种新的能够反映用户兴趣变化的信息过滤方法即已突显其高度必要及重要作用。因此,本文引入用户反馈机制,并选用用户最新的评价信息来自动更新推荐模型,该模型能够根据用户的实时需求和关注动态来为用户做出推荐,为用户提供“私人定制”式的贴心服务,用户体验也随即得到现实高度提升。
1 微博信息过滤方法
本文设计研发的基于用户隐式反馈的微博信息过滤方法如图1所示。就整体来说,方法主要包括收集用户数据、提取微博信息特征、建立用户兴趣模型、信息过滤和推荐、用户反馈和更新用户兴趣集6个部分。在具体实现过程中,该方法利用新浪公开的API获取用户的基本数据和用户行为日志作为数据集合进行实验;利用TF-IDF方法对经由中文分词技术得到的词进行统计以获取微博信息特征;采用隐式方式确定用户的兴趣后,再利用基于向量空间模型的表示法来建立用户兴趣模型;然后,又采用向量的夹角余弦值来计算用户兴趣特征与微博内容特征之间的相似度,将其作为向用户推荐微博的推荐度,同时则选取推荐度较大的一定数量微博作为推荐集而对外形成推荐;最后,即根据用户的反馈将微博信息分为有用信息和无用信息2类,而且将其中的有用信息添加到用户兴趣集,开始新一轮的特征提取工作,以更新用户的兴趣模型。下面将逐一论述各个部分的重点实现过程。
1.1建立用户兴趣集
微博信息的提取主要有2种方式。一种是利用图遍历的思想通过网络爬虫提取,另一种是通过微博开放平台的微博API提取。利用网络爬虫提取的微博信息,一般为文本文件的形式,里面包含了很多标签内容,占用存储空间大,格式复杂且规范性较差,需要对其进行文本规范化处理[3]。而通过微博开放平台的微博API提取的微博信息需要的存储空间相对较小,格式相对规范和简便,易于操作。所以本文采用微博API提取微博信息。提取的数据经过处理、且去除垃圾信息后用于本方法。提取的部分数据如图2所示。
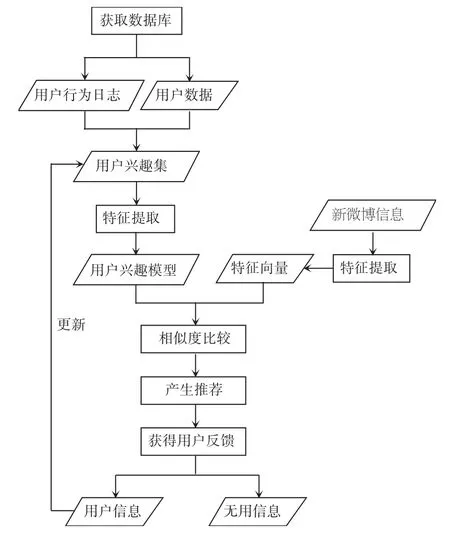
图1 基于用户反馈的微博信息过滤方法Fig.1 Method for filtering microblog information based on user’s implicit feedback
在此,针对提取信息的说明解释即如表1所示。
提取与用户相关的微博信息之后,将一定时间段内(如近30天)用户阅读过或做出转发、点赞、评论等行为的微博信息作为用户u的兴趣集合,记作Ru。这个用户兴趣集合将是下一步进行微博信息特征提取的基础。
1.2提取微博信息特征
1.2.1进行中文分词
利用中文分词把没有分割标志的汉字串(没有词的边界)转换到符合语言实际的词串,也就是在书面汉语中建立词的边界。例如,对图2所示的信息提取样例中的text字段内容进行分词,则可将“就是在一起没有心理负担”转化为“就是/在一起/没有/心理/负担”。现代中文分词系统包括:中国科学院计算所汉语词法分析系统ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System),量智能分词研究版和Taku Kudo博士创立的基于CRFs(Conditional Random Fields)D的CRF++等分词系统[4-7]。本文中推荐采用的是ICTCLAS,其特色表现即是综合性能优,分词精度较高及分析速度较快,而这些优点均可与微博信息的分词要求相互匹配、且能达到良好适应。
1.2.2提取文本内容的特征向量
在计算词语权值的方法中使用较多的是Saltond在1989年提出的TF-IDF算法,这是一种可得较好效果的技术方法。故本文采用基于TF-IDF的话题相关性度量方法来处理微博信息。TF-IDF是一种统计方法,用以评估一个字词对于一个文件集或一个语料库中内含的一份文件的重要程度,TF-IDF的思想是对关于可见预定文档中最有意义的字词应该是在文件中出现的频率高,但同时在语料库中其他的文档中出现频率低的字词。研究中,将针对在训练文本集中的每个字词计算其TF-IDF值。

图2 数据提取样例Fig.2 A sample of data extraction
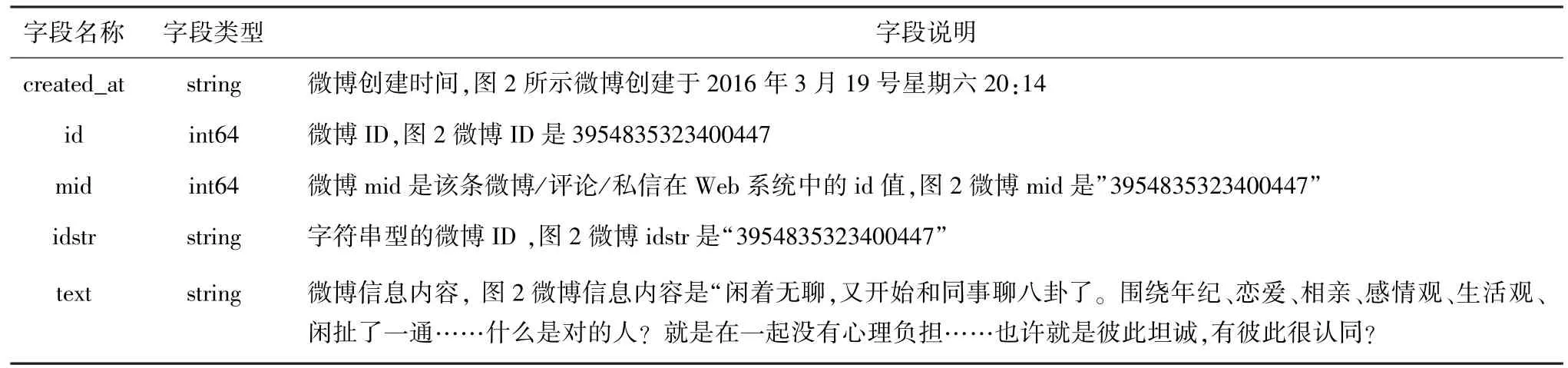
表1 微博信息字段的含义Tab.1 Meaning of Microblog information field
给定一个含有s条微博信息的集合S,给定一条微博信息k,给定一个词v,分析可知该词的TF-IDF值则能用以下公式进行计算:

其中,d是指微博信息集合S中包含v词的微博数目,hv是指词v在微博信息k中出现的次数,nk是指微博信息k的总词数。通过公式(1)计算得出微博信息中每个字词的TFIDF值后,将这些字词按TF-IDF值降序排列,并选取排在最前面的m个字词作为该微博信息的特征词,微博信息k被表示成特征词的向量{(x1,v1)(x2,v2)…(xm,vm)},向量中的元素xi是第i项关键词,vi表示第i项特征词xi的TF-IDF值。
1.3建立用户兴趣模型
用户兴趣模型用于描述、存储和管理用户的兴趣需求。目前常见的用户兴趣模型表示法有:主题表示法、关键词列表表示法和基于向量空间模型的表示法等。本文对于用户的兴趣,采用隐式方式确定,并用基于向量空间模型的表示法建立用户模型。对在用户u感兴趣的微博信息集合Ru中的所有微博信息进行中文分词,分词后得到的字词pi的权重wi可以通过公式(4)计算得到。

其中,ek表示所有含字词ki的微博信息中字词ki的TFIDF值的累加和,Ck={t1,t2,t3,t4}表示用户对微博信息k的操作集合。一般地,可以根据用户行为所反映的兴趣度不同,将t1、t2、t3和t4设定为不同的值,以体现用户对微博信息的兴趣差异。在本文方法中,所关注的用户行为主要包括:浏览、点赞、评论和转发4种,令t1=0.1表示用户微博浏览了该微博信息,t2=0.2表示用户对该微博信息给予了点赞,t3=0.3表示用户对该微博信息发表了评论,t4=0.4表示用户已经转发了该微博信息。由公式(4)可以得到表示用户对该字词感兴趣的程度的权值,然后将这些字词按权值wi降序排列,取前n个字词,作为用户u的特征词,再将用户兴趣模型表示成一个n维的特征向量{(p1,w1)(p2,w2)…(pn,wn)},其中的每一维分量均由特征词pi及其权重wi共同组成。
1.4信息过滤和推荐
为了能生成最适合用户的微博信息推荐列表,需要对微博信息内容与用户兴趣的相似度进行衡量。本文采用余弦相似度[8-10]计算用户兴趣特征与微博信息内容的特征词向量之间的相似度。
研究得到的用户兴趣模型的特征向量为U={p1,p2,…,pn},其中pi为特征词,总共n个。微博信息k的特征词向量为Xk={x1,x2,…,xm},其中xi为特征词,总共m个。合并2个向量,便将得到特征词的集合D= Xk∪U={r1,r2,…,rt},合并之后则有t个特征词。由于2个向量的特征词可能会有部分出现重复,故合并后集合中特征词的数量t是在区间[max(m,n),m+n]上的。根据特征词的集合D,进一步可以得到2个向量Dk={v1,v2,…,vr}和DU={w1,w2,…,wr},其中v代表Dk中对应的特征词在微博k的特征词集中的权重,若无对应特征词则赋值为0;w代表D中对应的特征词在用户兴趣集中的权重,同样,若这个词不存在,则赋值为0。此时,根据余弦相似度的思想,研究还可将这2个向量类比成空间中的2条线段,通过计算其夹角的大小来判断向量的相似程度。公式如下:
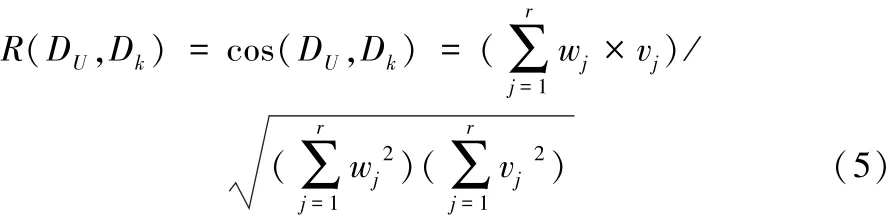
最终求得的余弦相似度R越接近于1,就表示向量之间更相似。此时相似度R便可作为向用户发出推荐的推荐依据。将R(DU,Dk)的值按从大到小排列,取其中推荐度最大的30条微博信息作为用户的推荐集,其它的信息即可视作无用信息予以过滤处理。
1.5用户反馈和更新用户兴趣集
综上可知,一次用户信息过滤已经完成,为使得下一次用户信息过滤更加贴合用户兴趣,就需要利用本次用户反馈的信息更新用户兴趣集合。本文利用用户的行为分析隐式获取用户反馈,同时更新用户兴趣集合Ru。为了考虑数据的时效性,每次用户登录时,对于微博集合Ru中的每个微博均需重新赋予一个时间权重。文献[11]中提出时间权重ρk应该满足如下条件:
1)ρk在k≥1上为单调增加的正函数;
2)ρk增长趋势应该比较平缓;
研究中仅仅考虑与用户当前正在浏览的时间最近的30天之内的微博,对于微博集合Ru中的微博以用户当前正在浏览的时间点A往前数30天的时间点B为基础(以分钟为单位),若用户在这30天内浏览或转发、点赞、评论微博k的时间点C与时间点B之间的间隔为K分钟,那么微博信息k
2 结束语
本文提出了一种基于用户隐式反馈的微博信息过滤方法,以帮助用户快速地发现其感兴趣的微博内容。考虑到用户的兴趣可能会随着时间的推移而发生改变,本文在传统的基于内容过滤的方法上提出了改进,直接有效地对用户访问过的微博信息赋予时间权重,以更准确地获得用户的喜好模型,推荐符合其当前兴趣的微博内容,为该领域的研究提供了一种新思路。
[1]李书宁.互联网信息环境中信息超载问题研究[J].情报科学,2005,23(10):1587-1590.
[2]罗玲.信息时代的信息超载影响及对策[J].现代情报,2011,31(6):36-38.
[3]邱洋.微博数据提取及话题检测方法研究[D].大连:大连理工大学,2013.
[4]奉国和,郑伟.国内中文自动分词技术研究综述[J].图书情报工作,2011,55(2):41-45.
[5]张华平,刘群.ICTCLAS汉语分词系统[EB/OL].[2016-01-27].http://ictclas.nlpir.org/.
[6]海量信息技术有限公司.海量信息[EB/OL].[2016-01-28]. http://www.hylanda.com/.
[7]韩雪冬.基于CRFs的中文分词算法研究与实现[D].北京:北京邮电大学,2010.
[8]胡迪,陈运,杨义先,等.基于支持向量机与余弦夹角法的中文网页过滤的研究与设计[J].成都信息工程学院学报,2011,26(5):527-532.
[9]郭庆琳,李艳梅,唐琦.基于VSM的文本相似度计算的研究[J].计算机应用研究,2008,25(11):3256-3258.
[10]王嫣然,陈梅,王翰虎,等.一种基于内容过滤的科技文献推荐算法[J].计算机技术与发展,2011,21(2):66-69.
[11]殷春武.基于时间权重的回归预测模型[J].统计与决策,2011(7):161-162.
A method for filtering microblog information based on user’s implicit feedback
SHI Xitong,WANG Jiaqi∗,LIU Bangwang∗,LI Ye∗
(School of Information&Computer Engineering,Northeast Forestry University,Harbin 150040,China)
The development of Microblog innovates the communication ways and makes information access more convenient.However,under the circumstance of information overload,it is time-consuming for people to find interesting information from a large amount of redundant information.To tackle the problem,this paper provides a new method for filtering microblog information.This method adds a step of user’s feedback based on the traditional methods.Considering user’s interest changes with time,this method measures the effect of time on the interesting degree the information.The method provides a new way for filtering weblog information.
microblog;information filtering;implicit feedback;weight of time
TP391
A
2095-2163(2016)03-0038-04
2016-04-18
石曦彤(1995-),女,本科生,主要研究方向:智能信息处理;汪嘉琪(1995-),女,本科生,主要研究方向:智能信息处理;刘邦望(1995-),女,本科生,主要研究方向:智能信息处理;李 叶(1992-),女,本科生,主要研究方向:智能信息处理。
∗代表作者贡献相同,排名不分先后。
