融合评论标签的个性化推荐算法*
2016-10-28王梦恬魏晶晶廖祥文林锦贤陈国龙
王梦恬,魏晶晶,廖祥文,林锦贤,陈国龙
福州大学 数学与计算机科学学院,福州 350108
融合评论标签的个性化推荐算法*
王梦恬,魏晶晶,廖祥文+,林锦贤,陈国龙
福州大学 数学与计算机科学学院,福州 350108
传统的推荐算法大都从评论中挖掘用户兴趣或产品特征,然而由于评论形式自由,规则性差,导致从评论中获取有效信息较困难,推荐结果不理想。在电子商务等领域,评论标签作为一种新的评论方式已经被广泛使用。与评论相比,评论标签具有规则性强,信息密度大等特点,因此提出了一种融合评论标签的推荐算法。该算法从评论标签中挖掘用户对产品特征的观点,并利用其构建用户兴趣模型和产品特征模型,然后向用户推荐在他们感兴趣的特征上有较高评价的产品。与传统推荐算法进行对比,实验结果表明,融合评论标签的算法能有效地提高用户的覆盖率,并提升推荐算法的准确性。
评论标签;产品特征;推荐算法
1 引言
互联网的普及在信息时代满足了用户对信息的需求,然而信息超载现象却使得用户难以快速方便地寻找到自己喜欢的产品,信息的使用率反而降低。在竞争日趋激烈的电子商务等领域,优质的推荐系统不仅能提升用户体验,还能为企业带来不可估量的经济效益。因此,越来越多的电子商务网站选择推荐系统为用户提供个性化服务。
要进行高效的推荐,就必须尽可能完整和准确地挖掘用户信息以及产品信息。当前的推荐算法大都从评论中挖掘用户的观点以构建用户模型和产品模型[1],但评论主观性强,规则性差,挖掘有效信息较困难,因此推荐效果不理想。而评论标签却具有较强的规则性,更容易获取到有效的信息。例如,图1是来自京东商城的用户关于某手机的反馈,用户的评论即心得大多是对产品整体的评论,或无意义的评论,难以体现用户的具体兴趣;而评论标签相对而言呈现出较强的规则性,大部分直接表明用户对产品特征的观点。
目前,越来越多网站提供了标签评论功能,如京东商城、国美在线、苏宁易购等,用户既可以自定义评论标签,也可以直接使用热门的评论标签。针对评论存在的不足,本文认为评论标签具有一定的研究价值,因此提出了融合评论标签的推荐算法,拟通过解决以下两个问题,提升推荐算法的准确性和有效性:
(1)评论中难以挖掘出有效信息。如果要从评论中获取用户关于产品特征的观点,则每句评论必须同时含有产品特征和观点倾向的相关词汇,但评论随意性很高,大多数都不满足这一要求,因此从中获得有效信息较困难。这将使得构建出的用户模型准确性较低,从而导致推荐结果不理想。
(2)部分用户无法获得个性化推荐。由于大量用户对某类产品的评论记录有限,用户的评价习惯若使得所有评论都无法抽取出有效信息,算法将无法为这类用户构建出兴趣模型,从而无法进行有效的个性化推荐。本文通过融合评论标签来弥补评论导致的有效信息过少等问题,有助于用户兴趣模型和产品特征模型的构建,从而提升用户的覆盖率和推荐算法的性能。

Fig.1 UsersƳ comments on mobile phone from Jingdong图1 京东商城用户关于手机的评论
2 相关工作
针对网站的不同特点,国内外学者对推荐算法进行了广泛的研究。传统的推荐算法主要有两种:基于内容的推荐算法和协同过滤推荐算法。基于内容的推荐通过匹配用户模型和产品模型,为用户推荐匹配度较高的产品。常用的协同过滤推荐算法则是通过寻找用户或产品的最近邻居,利用最近邻居的信息进行预测评分从而产生推荐。传统的协同过滤算法[2]在研究初期取得了较大的成效,之后不少的工作都是以该算法为基础展开的[3-4]。随着电子商务网站信息的丰富,数据呈现出复杂性和多样性等特点,非结构化信息使得更多因素需要被考虑,如地理信息、标签信息等。显然,单纯使用用户评分的算法在新的数据环境下已经无法满足推荐要求。因此,针对数据的不同特点,国内外学者提出了相适应的解决方案。
Huang等人提出了基于图模型的推荐算法[5],结果表明,在图模型中结合产品内容和用户购买记录可以达到较准确的预测结果。Koren等人提出了矩阵分解模型[6],该模型通过隐含特征联系用户与产品,实验结果表明该模型的效果明显好于传统的协同过滤算法。为了适应不同的数据环境,Bao等人提出的TopicMF[7]模型也取得了较好的推荐效果。Wang等人[8]认为推荐系统和搜索引擎有相似的目标,前者预测用户兴趣,后者表明购买意向,该文旨在探究如何将两者结合进行推荐。Musat等人[9]将用户的评论文本作为主要依据,通过判断评论文本所属的主题确定用户的兴趣,并在该层面上进行用户相似度的计算,从而有效降低数据稀疏性的影响。鲁凯等人[10]利用上下文信息缓解数据稀疏性的负面影响,并利用产品之间的层次关联关系挖掘用户的潜在喜好,然后在特定时间段对用户进行建模。孙建凯等人[11]提出了面向排序的协同过滤算法,该算法在计算用户的相似性时,不仅考虑了用户对产品的偏好程度,还结合了偏好的流行程度,实验结果表明,与传统的协同过滤方法相比,该算法的推荐有效性更高。Wang等人认为用户在不同时间段有不同的需求,因此融合了时间因素预测用户的购买行为[12]。
随着标签系统如豆瓣、Delicious等社交网络的兴起,Zhou等人提出了基于标签的推荐框架[13-14],该算法通过标签间的联系聚类出相应主题,根据用户对主题的兴趣程度计算用户间的相似性并进行推荐,有效地克服了标签语义带来的问题。Parra-Santander等人[15]利用标签表示用户信息,并利用改进的BM25算法计算用户之间的相似性并进行推荐,实验结果表明该算法好于传统的协同过滤算法。Liang等人[16]建立了用户、产品和标签之间的多元关系以定义标签的语义,然后确定每个用户喜欢的标签和每个产品的相关标签来生成推荐,从而减小标签噪声带来的影响。Liang等人[17]在算法中分别计算了用户使用标签的相似性、用户评价产品的相似性以及用户-标签-产品相似性,从而获得更准确的邻居用户以快速定位用户感兴趣的产品。闫俊等人[18]将社会化标签分别映射到情感、流派和上下文信息3个语义空间,并在不同的空间计算用户和产品的相似度,最后融合这3个空间的相似度为用户进行推荐。
虽然研究者对标签已经做了较深入的研究,但此类标签与评论标签不同,它通常只具有标注意义,不表达用户观点,如“篮球”、“健康”等标签,若将此类推荐框架直接用于评论标签,将忽视很多重要信息,无法取得较好的推荐效果。因此,本文认为评论标签中含有大量的有效信息,且评论标签还未被充分利用,具有一定的研究价值。
3 融合评论标签的推荐算法
3.1问题描述
本文的推荐任务是向用户推荐在他们感兴趣的特征上有较高评价的产品。为了方便研究,本文的个性化推荐问题可形式化描述为:给定用户集合U= {u1,u2,…,um},产品集合P={p1,p2,…,pn},评论集合C= {c1,c2,…,cp},评论标签集合T={t1,t2,…,tq},产品特征集合F={f1,f2,…,fl},以及用户对产品的评分集合Aij(i∈m,j∈l);通过挖掘评论集合C和评论标签集合T中的信息,构造(特征,观点,情感)元组,并通过公式分别将该元组信息转换为矩阵Xij(i∈m,j∈l),即用户兴趣模型,以及矩阵Yij(i∈m,j∈l),即产品特征模型,最后计算用户Ui对产品Pj的预测评分Rij,降序排列Rij即可生成推荐列表。
3.2构建用户兴趣模型和产品特征模型
3.2.1构造(特征,观点,情感)元组
根据用户对产品的评价规律,本文假设不同用户所关注的产品特征不同,且用户倾向于评论自己所关注的特征;同时,用户评价特征所表达出的情感极性,也反映了产品该特征的品质优劣情况。因此,本文以产品特征为对象进行数据处理,构造出(特征,观点,情感)元组。为方便表示,设产品的特征词集合为F,评价特征的观点词集合为O,观点词O的情感极性为S,至此,该元组可表示为(F,O,S)。
构造(F,O,S)元组主要由以下3个步骤组成:
(1)用ictclas对标签集合T和评论集合C进行分词及词性标注,分析标注词性并抽取特征词F和观点词O,构造(F,O)元组。如图1中可构造出(电池,耐用)、(系统,流畅)等元组。
(2)判断观点词O的情感极性S,构造(F,O,S)元组。若O为正向情感词,则S=1,若O为负向情感词,则S=-1,否则S=0。如观点词“耐用”为正向情感词,则S=1,因此可得元组(电池,耐用,1)。
(3)考虑极性是否需要反转。若观点词O前存在着否定词,则S=-S。如“质量不好”的观点词“好”之前存在着否定词“不”,则该情感极性需反转,因此最终可得(质量,好,-1)元组。通过充分挖掘(F,O,S)元组,即可构建出用户兴趣模型和产品特征模型。
3.2.2构建用户兴趣模型
由于用户的评价具有倾向性,本文提出如下假设:若用户在评论和标签中提到某特征的次数越多,则用户对该特征的关注程度越大。因此,本文的用户兴趣模型描述的是用户对某类产品某个特征的关注程度,其值用Xij(i∈m,j∈l)表示:计算公式如下所示:

其中,tij和tagij分别表示用户ui在评论和标签中提到特征fj的次数。式(1)将用户提及特征的次数tij和tagij缩放至用户对产品的评分范围,即Xij∈[0,5]。
3.2.3构建产品特征模型
产品特征模型描述的是产品某个特征的品质,用Yij(i∈m,j∈l)表示,该值越高说明产品该特征的品质越好,反之则越差。本文假设产品特征的品质优劣由特征流行性和情感评价共同决定。流行性越大且情感评价越正面,则该特征的品质越好。其中,流行性由该特征在评论和标签中被提到的次数表示,情感评价则由该特征的平均情感极性表示,Yij(i∈m,j∈l)的计算公式如下:

其中,在产品pi的评论和标签中,特征fj被提到的次数分别为k和d,平均情感极性分别为Sij和Gij。式(2)同式(1)一样,将产品的特征品质情况缩放至用户对产品的评分范围,即Yij∈[0,5]。
3.3融合产品特征的矩阵分解
矩阵分解的基本思想是,将用户产品的评分矩阵A进行拆分,从而将用户和产品分别映射到相同维度的隐因子向量空间P和Q上,那么就可以通过优化目标函数来学习特征矩阵P和Q,并通过计算用户和产品的隐因子向量内积获得用户对产品的预测评分。
以上的矩阵分解是建立在这样一个假设上,即用户和产品的特性可以由相同的隐因子特征集来描述。基于同样的假设,本文引申出融合产品特征的矩阵分解,即用户、产品特征和产品之间也能用隐因子向量描述。因此,通过提炼用户兴趣模型和产品特征模型中的信息,就能刻画出用户对产品特征的兴趣程度以及产品关于其特征的品质优劣情况。而计算方法同样能够类比于传统的矩阵分解算法,即通过优化目标函数将用户兴趣矩阵Xij和产品特征矩阵Yij分解到用户的隐因子向量U1、产品特征的隐因子向量V和产品的隐因子向量U2上[1]。最后,结合用户产品评分信息A、用户兴趣模型X和产品特征模型Y,可以得到融合产品特征的目标函数,该目标函数如下式所示:
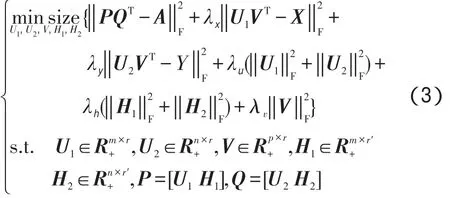
在获得隐因子向量U1、U2、V、H1、H2后,通过计算相应的向量内积即可获得A、X和Y的预测值,即。
3.4评分预测
在进行评分预测时,本文假设用户的购买行为只是基于k个用户最关注的特征。因此,在用户模型中,取用户ui关注度最大的k个产品特征进行评分预测,其中q∈Qi={qi1,qi2,…,qik},α∈[0,1]。其评分预测公式如下:
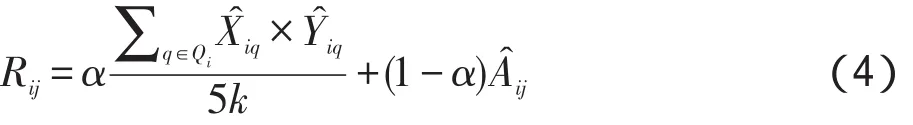
对于用户ui,降序排列Rij,取前N个值较大的产品pj,即可生产推荐列表。
融合评论标签的推荐算法的主要流程如下所示:
输入:用户评论集合C,用户标签集合T,用户数目m,产品数目n,用户对产品的评分Aij(i∈m,j∈l),显性特征数目r,隐性特征个数r',用户最关注特征数目k,系数α。
输出:用户ui对产品pj的预测评分Rij。
(1)用ictclas对集合C和集合T进行分词处理和词性标注,构建(F,O,S)元组;
(2)根据式(1)计算用户兴趣模型,即矩阵Xij;
(3)根据式(2)计算产品特征模型,即矩阵Yij;
(4)根据式(3)优化损失函数,获得参数U1、U2、V、H1、H2;
(5)根据如下公式预测矩阵:
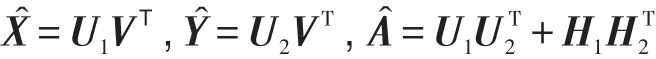
(6)根据式(4)计算用户ui对产品pj的预测评分Rij;
(7)输出用户ui对产品pj的预测评分Rij;
(8)对用户ui,降序排列Rij生成推荐列表。
4 实验结果及分析
4.1数据集
本文方法是针对电子商务网站中某一产品类别提出的,因此本文实验将该产品类别设定为手机。实验数据来自于京东商城(http://www.jd.com)中的真实数据。在2014年10月至11月,本文共抽取了京东商城上在售的2 638个手机产品的相关信息,其中产品评论共计1 081 543条,评论标签共计2 419 771个;同时抽取了评论手机产品的用户17 144个,并抽取了这些用户对各类商品的评论共计95 141条,评论标签共计165 636个。
为了确保本文实验数据的可行性,对上述数据集进行了过滤,即选择了对手机的评论数在5条以上的用户以及这些用户所评论的产品进行实验,过滤后的具体数据信息如表1所示。实验随机选取每个用户80%的记录作为训练集,其余20%的记录则作为测试集。

Table 1 Experimental data表1 实验数据统计表
4.2情感词典
本实验使用HowNet情感词典来计算评论标签中观点词的情感极性。
HowNet情感词典是《知网》发布的中英文词集,共包含中英文情感分析词语集12个,本文选用其中的中文正面评价词语集和中文负面评价词语集作为情感词典,中文正面评价词语共3 730个,中文负面评价词语共3 116个。由于网络用语的流行性和产品类别的独有性,本实验在原词典中添加了若干个常用的评价词语。如在中文正面评价词语集中添加了“给力”、“满意”、“不错”、“耐用”等词语,在中文负面评价词语集中添加了“差”、“失望”、“坑”、“粗糙”等词语。
本文使用词语匹配的方式来确定观点词的情感极性,即如果观点词出现在中文正面评价词语集中,则该观点词的情感极性为正向;如果观点词出现在中文负面评价词语集中,则该观点词的情感极性为负向;否则,该观点词的情感极性为中性。
4.3评价指标
本文根据训练集中的数据为每个用户建立模型,并利用构建出的模型得到预测评分,最后依据该评分为每个用户生成相应的推荐列表。若推荐列表中的产品是该用户测试集中的产品,则说明该产品是用户喜欢的,同时表明算法对该产品的预测准确。
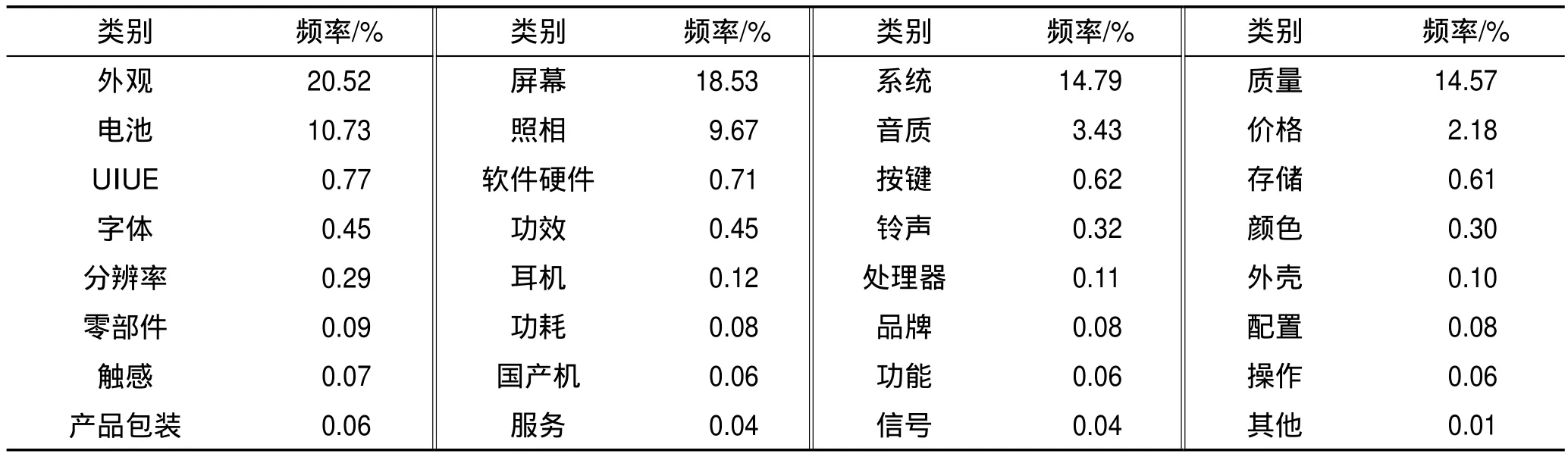
Table 2 Frequency of feature表2 特征类别频率统计
实验共选取了3个评价指标:用户覆盖率(user coverage)、召回率(recall)和推荐有效性(NDCG@n)。其中,用户覆盖率考察算法能够进行个性化推荐的用户比例,该值越大,则用户覆盖率越大,算法性能越好。召回率指的是推荐列表中用户喜欢的产品个数占测试集中用户喜欢总个数的比值。召回率越大,则说明推荐算法的准确性越高。NDCG@n是度量推荐算法有效性的评价指标,若用户喜欢的产品在推荐列表中的位置越靠前,则推荐算法的有效性越好。评价指标的公式如下所示:
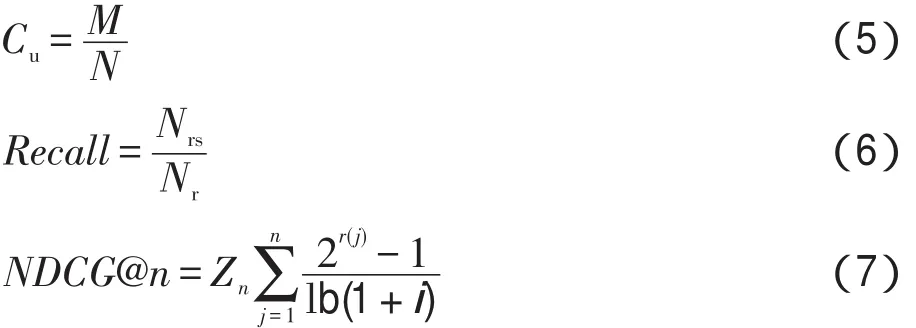
其中,M为算法能构建出兴趣信息的用户数;N为用户总数;Nrs为推荐列表中用户喜欢的产品个数;Nr为数据集中用户喜欢的产品总数;n为推荐列表长度;r(j)表示推荐列表中第j个位置的产品级别,若用户购买过该产品,则r(j)=1,否则,r(j)=0。
4.4实验设置
在电子商务等各类网站,评论标签及评论都面临着口语化程度高及零散化严重等问题。例如,“耳机”这一特征类别,可以由特征词“耳机”、“耳塞”和“耳麦”等意思相近的一系列词语表示,对于该“一义多词”现象,目前尚未有完整的语料集或词典进行归纳整理。综合考虑多方面因素,本文实验采用文献[19]中的方法解决该问题。即3个标注人员对手机类别的特征词进行标注,若某个特征词被至少两个标注人员归为同一个类别,则认为该归类合理,其中标注的一致率约为92.73%。同时,本文还统计了该数据集中各个特征类别的出现频率,结果如表2所示。
从表2的结果可知,各特征类别分布不均,且用户关注的特征相对比较集中,“外观”、“屏幕”等8个特征类别的出现频率和就达到了94.42%。因此,本文选取频率大于等于0.1%的特征类别进行实验。
针对表2中选取出的特征类别,构造出了相应的(F,O,S)元组。(F,O,S)元组的构造至关重要,它通过直接影响用户模型和产品模型的构建,从而间接影响推荐结果。本文分别统计了从评论和评论标签中构造出的(F,O,S)元组的相关信息,结果如表3所示。由表3的统计结果可知:
(1)对于相同数量的用户或产品,标签数约是评论数的2倍,说明用户倾向于使用标签。
(2)对于相同数量的评论和标签,标签生成的(F, O,S)元组数多于评论,说明从标签中更容易获取有效信息。
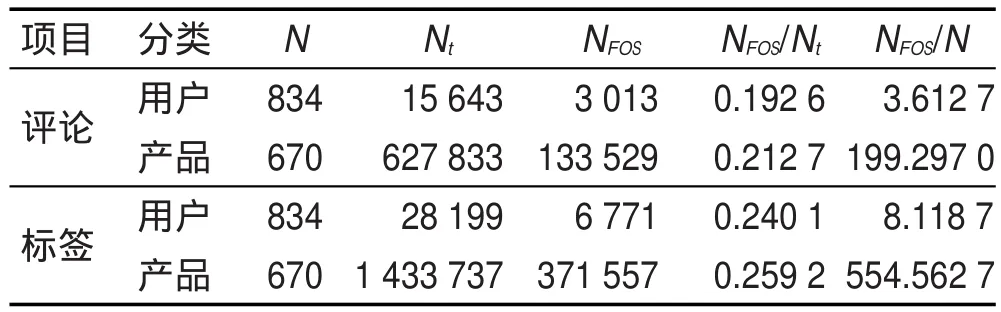
Table 3 Information of(F,S,O)tuples表3 (F,O,S)元组信息表
(3)单位用户或产品在标签中获得的(F,O,S)元组数约是评论的2.5倍,说明标签所含的信息量多于评论。其中,N表示用户或产品总数;Nt表示评论数或标签数;NFOS表示构造出的(F,O,S)元组数。
4.5实验结果及分析
为了验证本文方法FTR(fusing tag recommendation)的有效性,本实验将与如下两个方法进行对比:
(1)文献[1]中的方法只使用评论进行用户兴趣模型和产品特征模型的构建,并利用构建出的用户模型和产品模型完成相应的推荐,本文将其视为基线方法(explicit factor models,EFM)。
(2)构建用户兴趣模型时融合了评论标签中的信息,但产品特征模型的构建只使用了评论中的信息,同时利用构建出的用户模型和产品模型完成相应的推荐(tag explicit factor models,TEFM)。
上述方法皆关联α、用户关注的特征个数k和推荐列表长度n这3个参数,因此本文将基于上述参数探讨所提方法的有效性。
实验1用户覆盖率的实验结果比较。
用算法分别构造出用户兴趣模型后,实验1统计了能够成功构造出兴趣模型并获得个性化推荐的用户比例,实验结果如表4所示。

Table 4 User coverage表4 用户覆盖率
由表4可知:基准方法的用户覆盖率为59.71%,即大约40%的用户无法获得个性化推荐,只能得到相同的推荐结果;而TEFM和FTR将用户覆盖率提升至91.97%,说明融合评论标签挖掘出了更多用户的兴趣信息,可以为更多的用户建立兴趣模型,从而使得大部分用户都能得到个性化推荐。用户覆盖率的大幅度提升可以表明评论标签中含有更多的有效信息,能够为大多数用户构建出更准确更完整的用户兴趣模型。
实验2探究α的取值对实验结果的影响。
实验2探究算法中最优的α值,设k=15,n=10,实验结果分别如图2和图3所示。
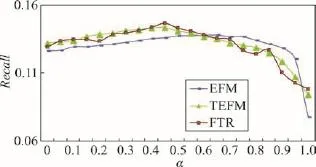
Fig.2 Recall at varyingα图2 α取值不同时的召回率
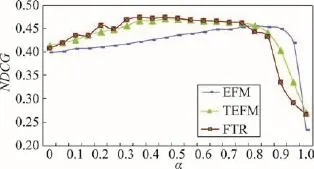
Fig.3 NDCG at varyingα图3 α取值不同时的NDCG
由图2和图3可知:FTR和EFM的参数值分别为0.45和0.80时推荐效果最好,并且FTR最大的Recall和NDCG均高于EFM,说明本文方法好于基准方法。
当α处在某范围内时,FTR的效果明显好于EFM,但却和TEFM的曲线基本重叠,说明融合评论标签构建用户模型对算法有较明显作用,但融合标签构建产品模型则意义不大。这是因为,产品的评论记录较多,可以获取到较完整的产品特征信息,融合标签难以获取额外的有效的产品特征信息,融合标签构建产品模型无法起到明显的作用。而用户模型的构建则与此相反,由于用户评论记录有限,评论标签能在一定程度上弥补评论信息过少等带来的问题,从而构建出更完整的用户模型,并获得理想的推荐效果。但当α过大时,召回率和NDCG迅速下降,说明推荐效果不仅和评论及标签中的信息有关,同时还受用户评分信息的影响。
实验3在不同的用户关注特征个数k下的实验结果。
根据实验2的结果,设实验3和实验4中FTR、TEFM的α值为0.45,EFM的α值为0.80,并设推荐列表长度n=20,实验结果分别如图4和图5所示。
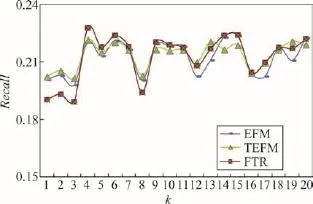
Fig.4 Recall at varying k图4 k取值不同时的召回率
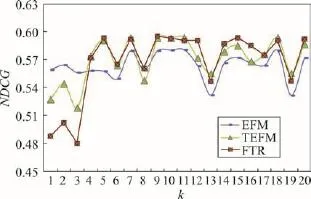
Fig.5 NDCG at varying k图5 k取值不同时的NDCG
由图4和图5可知:3种方法的召回率都在k=4时最大,说明在该数据集中只需少量的特征就可以获得较理想的推荐效果。另外,EFM和TEFM的NDCG在k=11时最大,而FTR的NDCG则在k=9时最大,说明FTR用更少的特征就能获得最好的推荐有效性。从总体上看,实验结果在k>3之后便迅速提升,且FTR的推荐效果基本好于TEFM和EFM,说明融合评论标签的推荐算法能在一定程度上提升推荐的准确率和有效性。
实验4在不同的推荐列表长度n下的实验结果。
根据实验3的结果,设在Recall的实验中3种方法的k都等于4,在NDCG的实验中,TEFM和EFM中的k=11,FTR中的k=9,实验结果分别如图6和图7所示。
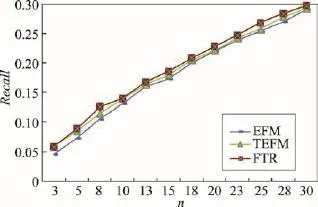
Fig.6 Recall at varying n图6 n取值不同时的召回率
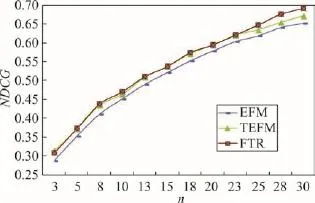
Fig.7 NDCG at varying n图7 n取值不同时的NDCG
由图6和图7可知:随着推荐长度的增加,Recall和NDCG逐渐增大,推荐准确率和有效性越来越好,且FTR的推荐结果略好于EFM,说明评论标签在推荐算法效果的提升上有一定的作用。
根据以上实验结果可知,推荐效果随着推荐列表长度n的增大而越来越好,且算法的准确率和有效性分别在用户关注的特征个数k=4和k=9时最好。以上结果同时表明:融合评论标签的推荐算法,大幅度提升了用户覆盖率,使得更多的用户能获得个性化推荐。同时,在召回率和推荐有效性上,本文方法FTR取得了最理想的推荐结果。说明评论标签能够构建出更完整更准确的用户兴趣模型,而融合评论标签的推荐算法不仅能有效提升用户的覆盖率,还能提升算法的准确性和有效性。
5 总结与展望
本文针对评论规则性差,获取有效信息较困难等问题,提出了融合评论标签的推荐算法,并结合实验结果进行相关分析。结果表明,同评论相比,评论标签密度大,所含信息丰富,在获取用户对产品特征的观点上具有较大优势,有助于构建更完整更准确的用户兴趣模型,并提升用户的覆盖率,同时提高算法的准确率和有效性。下一步工作中,将探索其他因素对推荐算法的影响,并探究更高效更稳定的推荐算法。
[1]Zhang Yongfeng,Lai Guokun,Zhang Min,et al.Explicit factor models for explainable recommendation based on phrase-level sentiment analysis[C]//Proceedings of the 37th International ACM SIGIR Conference on Research&Development in Information Retrieval,Gold Coast,Australia, Jul 6-11,2014.New York:ACM,2014:83-92.
[2]Su Xiaoyuan,Khoshgoftaar T M.A survey of collaborative filtering techniques[J].Advances in Artificial Intelligence, 2009,4:1-19.
[3]Parra-Santander D,Brusilovsky P.Improving collaborative filtering in social tagging systems for the recommendation of scientific articles[C]//Proceedings of the 2010 IEEE/ WIC/ACM International Conference on Web Intelligence and IntelligentAgent Technology,Toronto,Canada,Aug 31-Sep 3,2010.Piscataway,USA:IEEE,2010:136-142.
[4]Wang Chong,Blei D M.Collaborative topic modeling for recommending scientific articles[C]//Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,San Diego,USA,Aug 21-24, 2011.New York:ACM,2011:448-456.
[5]Huang Z,Chung W,Chen H.A graph model for Ecommerce recommender systems[J].Journal of the American Society for Information Science and Technology,2004,55(3):259-274.
[6]Koren Y,Bell R,Volinsky C.Matrix factorization techniques for recommender systems[J].Computer,2009,42(8):30-37.
[7]Bao Yang,Fang Hui,Zhang Jie.TopicMF:simultaneously exploiting ratings and reviews for recommendation[C]//Proceedings of the 28th AAAI Conference on Artificial Intelligence,Québec,Canada,Jul 27-31,2014.Menlo Park, USA:AAAI,2014:2-8.
[8]Wang Jian,Zhang Yi,Chen Tao.Unified recommendation and search in E-commerce[C]//LNCS 7675:Proceedings of the 8th Asia Information Retrieval Societies Conference, Tianjin,China,Dec 17-19,2012.Berlin,Heidelberg:Springer, 2012:296-305.
[9]Musat C,Liang Y,Falting B.Recommendation using textual opinions[C]//Proceedings of the 23rd International Joint Conference on Artificial Intelligence,Beijing,Aug 3-9,2013. Menlo Park,USA:AAAI,2013:2684-2690.
[10]Lu Kai,Zhang Guanyuan,Wan Bin.CICF:a context information based collaborative filtering algorithm[J].Journal of Chinese Information Processing,2014,28(2):122-128.
[11]Sun Jiankai,Wang Shuaiqiang,Ma Jun.Weighted-Tau Rank: a ranking-oriented algorithm for collaborative filtering[J]. Journal of Chinese Information Processing,2014,28(1):33-39.
[12]Wang Jian,Zhang Yi.Opportunity model for E-commerce recommendation:right product;right time[C]//Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval,Dublin, Ireland,Jul 28-Aug 1,2013.NewYork:ACM,2013:303-312.
[13]Kim H N,Ji A T,Ha I,et al.Collaborative filtering based on collaborative tagging for enhancing the quality of recommendation[J].Electronic Commerce Research and Applications,2010,9(1):73-83.
[14]Zhou T C,Ma Hao,Lyu M R,et al.UserRec:a user recommendation framework in social tagging systems[C]//Proceedings of the 24th AAAI Conference on Artificial Intelligence,Atlanta,USA,Jul 11-15,2010.Menlo Park,USA: AAAI,2010:1486-1491.
[15]Parra-Santander D,Brusilovsky P.Improving collaborative filtering in social tagging systems for the recommendation of scientific articles[C]//Proceedings of the 2010 IEEE/ WIC/ACM International Conference on Web Intelligence and IntelligentAgent Technology,Toronto,Canada,Aug 31-Sep 3,2010.Piscataway,USA:IEEE,2010:136-142.
[16]Liang Huizhi,Xu Yue,Li Yuefeng,et al.Connecting users and items with weighted tags for personalized item recommendations[C]//Proceedings of the 21st ACM Conference on Hypertext and Hypermedia,Toronto,Canada,Jun 13-16,2010.New York:ACM,2010:51-60.
[17]Liang Huizhi,Xu Yue,Li Yuefeng,et al.Tag based collaborative filtering for recommender systems[C]//LNCS 5589: Proceedings of the 4th International Conference on Rough Sets and Knowledge Technology,Gold Coast,Australia,Jul 14-16,2009.Berlin,Heidelberg:Springer,2009:666-673.
[18]Yan Jun,Liu Wenfei,Lin Hongfei.Music recommendation study based on tags multi-space[J].Journal of Chinese Information Processing,2014,28(4):117-122.
[19]Lu Yue,Castellanos M,Dayal U,et al.Automatic construction of a context-aware sentiment lexicon:an optimization approach[C]//Proceedings of the 20th International Conference on World Wide Web,Hyderabad,India,Mar 28-Apr 1, 2011.New York:ACM,2011:347-356.
附中文参考文献:
[10]鲁凯,张冠元,王斌.CICF:一种基于上下文信息的协同过滤推荐算法[J].中文信息学报,2014,28(2):122-128.
[11]孙建凯,王帅强,马军.Weighted-Tau Rank:一种采用加权Kendall Tau的面向排序的协同过滤算法[J].中文信息学报,2014,28(1):33-39.
[18]闫俊,刘文飞,林鸿飞.基于标签混合语义空间的音乐推荐方法研究[J].中文信息学报,2014,28(4):117-122.

WANG Mengtian was born in 1990.She is an M.S.candidate at University of Fuzhou.Her research interests include data mining and opinion analysis,etc.
王梦恬(1990—),女,福州大学硕士研究生,主要研究领域为数据挖掘,观点分析等。

WEI Jingjing was born in 1984.She is a Ph.D.candidate at University of Fuzhou.Her research interest is opinion mining.
魏晶晶(1984—),女,福州大学博士研究生,主要研究领域为观点挖掘。

LIAO Xiangwen was born in 1980.He received the Ph.D.degree from University of Chinese Academy of Sciences in 2009.Now he is an associate professor and M.S.supervisor at Fuzhou University,and the senior member of CCF. His research interest is Web text opinion mining.
廖祥文(1980—),男,2009年于中国科学院获得博士学位,现为福州大学副教授、硕士生导师,CCF高级会员,主要研究领域为网络文本观点挖掘。

LIN Jinxian was born in 1957.He received the Ph.D.degree from Xi’an Jiaotong University in 2004.Now he is a professor and M.S.supervisor at Fuzhou University.His research interest is high performance computing.
林锦贤(1957—),男,2004年于西安交通大学获得博士学位,现为福州大学教授、硕士生导师,主要研究领域为高性能计算。

CHEN Guolong was born in 1965.He received the Ph.D.degree from Xi’an Jiaotong University in 2002.Now he is a professor and Ph.D.supervisor at Fuzhou University.His research interest is network information security.
陈国龙(1965—),男,2002年于西安交通大学获得博士学位,现为福州大学教授、博士生导师,主要研究领域为网络信息安全。
Personalized RecommendationAlgorithm Fusing Comment Tag*
WANG Mengtian,WEI Jingjing,LIAO Xiangwen+,LIN Jinxian,CHEN Guolong
College of Mathematics and Computer Science,Fuzhou University,Fuzhou 350108,China
E-mail:liaoxw@fzu.edu.cn
The user interests and product features are extracted from comments in traditional recommendation algorithms.However,the expected recommendation performance is not achieved as it is difficult to obtain valid information,caused by the free-form and poor regularity of comments.In the current field of electronic commerce,the comment tag as a new way of comments has been widely used.Compared with comments,the comment tag has the advantages of strong regularity and information density.Thus this paper proposes a recommendation algorithm fusing comment tag which extracts the users’opinions for the product features and then makes use of them to construct user interests model and product features model.Therefore,the proposed algorithm can recommend the products with wellreviews on specific features which users are interested in.Compared with traditional algorithms,the experimental results show that the proposed algorithm can effectively improve the user coverage and the recommendation accuracy.
comment tag;product feature;recommendation algorithm
2015-08,Accepted 2015-10.
10.3778/j.issn.1673-9418.1509076
A
TP391
*The National Natural Science Foundation of China under Grant No.61300105(国家自然科学基金);the Doctoral Scientific Program of the Ministry of Education of China under Grant No.2012351410010(教育部博士点基金联合资助项目);the Science and Technology Major Program of Fujian Province under Grant No.2013H6012(福建省科技重大专项);the Science and Technology Plan Program of Fuzhou under Grant Nos.2012-G-113,2013-PT-45(福州市科技计划项目).
CNKI网络优先出版:2015-10-28,http://www.cnki.net/kcms/detail/11.5602.TP.20151028.1045.002.html
WANG Mengtian,WEI Jingjing,LIAO Xiangwen,et al.Personalized recommendation algorithm fusing comment tag.Journal of Frontiers of Computer Science and Technology,2016,10(10):1429-1438.
