基于局部邻域嵌入的无监督特征选择
2016-10-26脱倩娟
脱倩娟, 赵 红
(闽南师范大学 福建省粒计算重点实验室 福建 漳州 363000)
基于局部邻域嵌入的无监督特征选择
脱倩娟,赵红
(闽南师范大学 福建省粒计算重点实验室福建 漳州 363000)
机器学习中,特征选择可以有效降低数据维度.考虑到流形学习能够保持原始数据的几何结构,l2,1范数能够防止过拟合,提升模型的泛化能力,将二者结合起来可以提高特征选择的效果和效率.结合局部邻域嵌入(LNE)算法和l2,1范数,提出一种新的无监督特征选择方法.其主要思想是:首先利用数据样本和邻域间的距离以及重构系数构造相似矩阵;其次构建低维空间并结合l2,1范数进行稀疏回归;最后计算每个特征的重要性并选出最优特征子集.实验通过与几种典型的特征选择算法做对比,验证了所提算法的有效性.
机器学习; 局部邻域嵌入; 流形学习; 无监督特征选择
0 引言
在当今社会中,随着科技信息的发展,计算机视觉、数据挖掘、机器学习、信息检索等研究领域出现的数据大都呈现出高维状态.高维数据中通常含有冗余维度,直接对高维数据进行研究不但会消耗大量时间,而且还会对研究任务造成不良影响.因此,对数据进行降维显得尤为重要,将高维数据转化成低维数据并且尽量保留原有数据的拓扑结构是降维的目标和方向.
特征选择是一种非常有效的降维方法,根据原始数据有无标签信息,可以分为有监督的特征选择[1-2]和无监督的特征选择[3-4].有监督的特征选择利用标签信息可以准确快速地选出对分类有利的特征,但对数据进行标记需要投入大量的人力、物力,这就意味着大多数数据可能没有标签,在实际应用中处理无标签数据经常使用无监督的特征选择算法.传统的无监督特征选择算法[5]对特征进行单独评价没有考虑到数据的整体分布情况,有可能选不出全局最优特征子集.为了避免该问题,一些无监督特征选择算法[6-7]从全局考虑每个特征的重要性,选出的特征子集能够较好地保持原始数据的几何结构.如文献[3]提出的多类簇特征选择方法(MCFS),它通过解决稀疏特征问题得到低维嵌入空间,进而解决特征选择问题;文献[6]利用局部线性嵌入算法获得局部邻域之间的重构关系,结合l1范数选出最优特征子集;文献[7]提出一种无监督判别特征选择方法(UDFS),它对每个样本定义一个局部判别得分,利用l2,1范数[8]得到最优特征子集.
上述文献[3]和[6]中所提的方法都使用了流形学习[9-11]的思想.使用流形学习进行特征选择不但能够找到高维空间中的低维流形达到降维的目的,而且可以提高数据处理的效率.常见的流形学习方法可以分为非线性流形学习和线性流形学习.非线性流形学习算法包括等距映射(ISOMAP)[9]、局部线性嵌入(LLE)[10-12]、拉普拉斯特征映射(LE)[13]等.线性流形学习算法包括主成分分析(PCA)[14]、线性区别分析(LDA)[15].有的线性流形学习算法则是对非线性流形学习算法的线性拓展,如局部保持投影(LPP)[16]是拉普拉斯特征映射(LE)的线性逼近,邻域保持嵌入(NPE)[17]是局部线性嵌入(LLE)的线性逼近.
在流形学习中,构造数据之间的相似关系起着至关重要的作用,它的构建结果可能直接影响到最终的嵌入结果.文献[18]提到两种常见的构造相似矩阵的方式:一种是利用成对数据之间的距离,如LE选用热核函数确定数据点之间的权重大小,对噪声和离群点比较敏感;另一种是利用数据的重构系数,如LLE计算局部线性重构系数来保持原始数据的流形结构,对数据样本大小和邻域个数比较敏感.单独使用其中一种方式构造相似矩阵时,数据样本关系有可能被固定地表示成一种形式.比如热核函数中的参数一旦确定,样本间的相似关系就会被确定唯一,这不符合现实世界的数据分布规律.文献[18]将两种方法结合起来,不但弥补了各自的缺陷而且更具有一般性,得到的低维嵌入空间使得数据类簇更明显.在得到的低维空间中加入l2,1范数不但可以防止过拟合,提升模型的泛化能力,而且可以达到去噪的效果.
本文在文献[18]的思想基础上结合l2,1范数提出了基于局部邻域嵌入的无监督特征选择方法(UFLNE).首先,计算数据和其邻域间的欧氏距离以及重构系数,并结合二者构造相似矩阵,避免了单独使用可能带来的影响;其次,利用得到的相似矩阵构建低维嵌入空间,很好地保持了原始数据集的流形结构;再次,使用l2,1范数进行稀疏回归,准确计算每个特征的重要性;最后,根据特征的重要性进行降序排列,选出指定个数的特征.
1 算法的基本原理
算法主要分为两部分:第一部分利用局部邻域嵌入算法(LNE)构建低维嵌入空间;第二部分利用l2,1范数进行稀疏回归得到每个嵌入低维空间的特征重要性.
1.1LNE构建低维嵌入空间
局部邻域嵌入算法假设每个数据点都存在一个很小的邻域,它们近似于低维任意子空间的同一流形.假设数据矩阵为X=[x1, x2, … , xn]∈Rm×n,它的低维嵌入空间为Y=[y1, y2, …, yn]∈Rc×n(c≤m).
局部邻域嵌入算法(LNE)的步骤如下.
1) 寻找k近邻点.
对于每一个数据点xi,计算xi和其他数据点之间的欧氏距离.然后选出xi的k个近邻点,记为:

其中:将对应的距离记为如下形式:
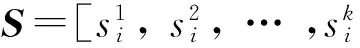
2) 利用重构系数结合成对距离构造相似矩阵.具体形式为:
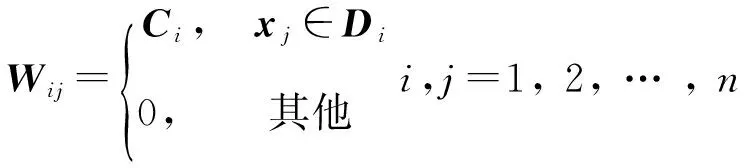
(1)
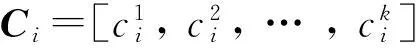
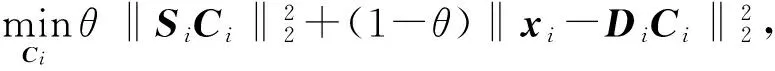
(2)
其中:Si=diag(S),θ∈[0,1]是平衡参数.使用Lagrangian乘数法后,对Ci求偏导,并令其为0,得到:
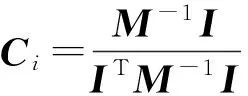
(3)
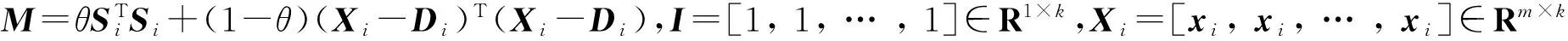
3) 求低维嵌入空间.
为使W在低维空间中保持不变,低维嵌入空间Y可由下列目标函数得到:

(4)
其中:Q=(1-W)T(1-W).将式(4)转化为下列广义特征值问题:
QY=λY,
(5)
得到Q的特征值与特征向量,由于最小特征值经常趋于零,所以低维嵌入空间Y=[y1, y2, …, yn]∈Rc×n由第2小特征值到第c+1小特征值所对应的特征向量构成.
1.2基于l2,1范数的特征选择
在低维嵌入空间基础上,通过最小化式(6)的目标函数:
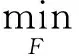
(6)
那么每个嵌入原始空间的特征重要性由式(7)得到:
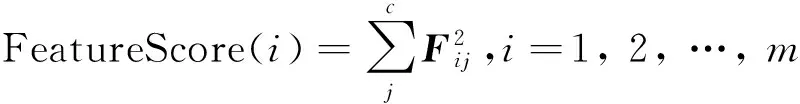
(7)
根据式(7)将所有的特征进行降序排列,选出最重要的(FeatureScore越大越重要)d个特征.
具体的算法表述如下.
算法:基于局部邻域嵌入的无监督特征选择(UFLNE).
输入:数据集X=[x1,x2, … ,xn]∈Rm×n(n是样本个数,m是特征个数),低维嵌入空间的维数c,选择的特征数目d,近邻个数k,平衡参数θ.
输出:指定个数的特征.
步骤1:找出每个数据样本的k近邻,并利用式(1)和式(3)构造相似矩阵;
步骤2:求解式(5),得到Q的特征值特征向量,用Q的第2小特征值到第c+1小特征值所对应的特征向量构成低维嵌入空间Y=[y1,y2, … ,yn]∈Rc×n;
步骤3:求出式(6)中的稀疏矩阵F∈Rm×c;
步骤4:根据式(7)计算每个特征的重要性得分;
步骤5:选出d个FeatureScore最大的特征.
根据上述的算法步骤,每步时间复杂度分别为:步骤1中寻找k近邻需要O(n2k),求成对距离需要O(n2m);步骤2中求解Q的特征值特征向量需要O(n2m);步骤3中求解稀疏矩阵需要O(m2n);步骤4中计算每个特征的重要性得分需要O(cm);步骤5中根据FeatureScore选择特征需要O(mlogm).所以算法的整体时间复杂度为O(n2k+n2m+m2n+cm+mlogm).
2 仿真实验
实验选用K-means算法进行聚类,进行10次实验记录平均值.将得到的结果和多类簇特征选择(MCFS)、无监督判别特征选择(UDFS)、基于拉普拉斯打分的特征选择(LaplacianScore)[15]、基于最大方差的特征选择(MaxVaiance)4种典型的特征选择算法以及选择所有特征(AllFeature)时的结果进行比较.利用人工标记的数据标签与聚类后的数据标签之间的归一化互信息(取值范围在0和1之间)和聚类精度去衡量不同算法在选择不同特征时的效果,值的大小可以体现算法的好坏.
2.1实验数据集
本文使用以下4个现实世界中的数据集[19]:图像数据集COIL20,字母识别数据集ISOLET,生物数据集Lymphoma,Lung_discrete.具体情况如表1.
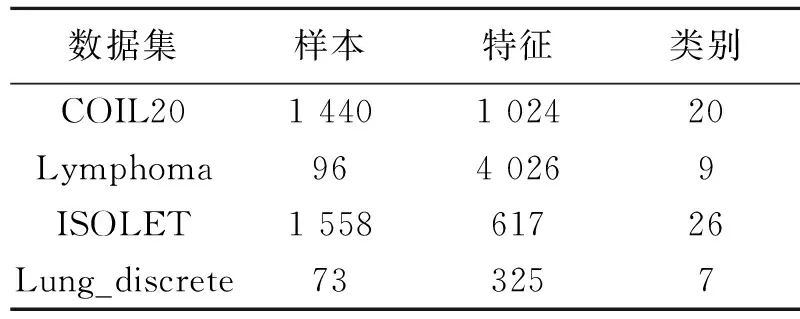
表1 实验数据集的具体情况Tab.1 The whole situation of experimental data sets
2.2实验的参数设置
本文算法及对比算法的聚类数目q设置为各数据标签包含的类别数,即分别为20,9,26,7.MCFS和提出的算法UFLNE需要设置邻域k,这里统一指定k=5.利用网络搜索策略来调节UFLNE中的稀疏参数α和UDFS中的稀疏参数γ,设置参数均为{10-3, 10-2, 10-1, 1, 101, 102, 103},记录每种算法在不同参数时的最好结果.UFLNE中还需要设置一个控制平衡的参数θ,令θ=0.25.最后将所有特征选择算法中的特征选择数目均设置为:{10, 20,…,100, 120, 140, … , 200}.
2.3实验结果分析
表2和表3分别列出不同特征选择算法在选择120特征时的聚类精度和归一化互信息.从表2和表3中的数据对比信息可以看出本文所提算法在两种评价指标下的结果大部分优于对比算法.
此外,为了比较不同的特征选择数目对算法性能的影响,用图1和图2显示各个算法在选择不同特征数时的实验结果.图1和图2中的横坐标均表示选择的特征个数,纵坐标分别表示聚类精度和归一化互信息.从图中可以看出随着选择的特征数目的增加,聚类精度和归一化互信息的值也会发生相应的变化.在数据集COIL20和Lung_discrete上当特征个数小于50时所提算法的效果尤为突出,这说明本文算法在某些数据集上只要选择很少的特征就能达到不错的效果.在数据集Lymphoma和ISOLET上当选择的特征数目增加到一定程度时所提算法的聚类精度和归一化互信息的值会逐渐优于对比算法.从总体性能上,可以发现利用本文算法进行特征选择会比一般的特征选择算法效果好.

表2 不同特征选择算法的聚类精度Tab.2 Clustering accuracy of different feature selection algorithms
注:每种算法的最好结果用粗体标注,第二好结果用下划线标注.
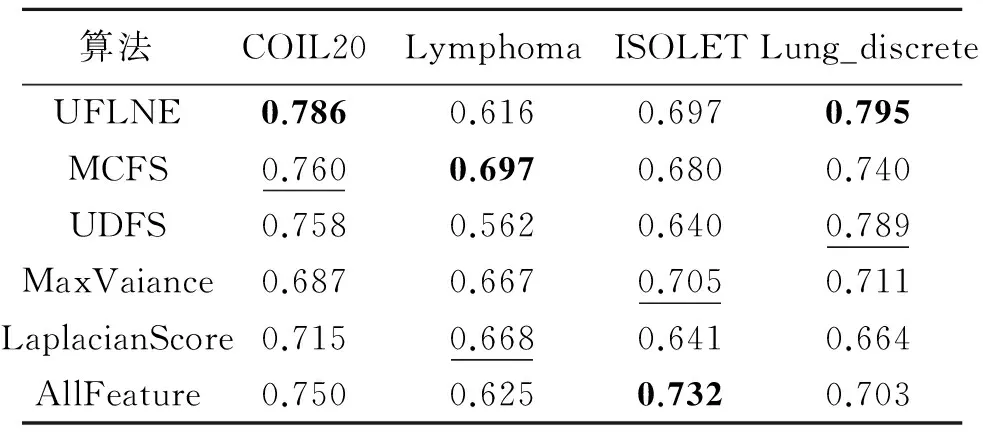
表3 不同特征选择算法归一化互信息Tab.3 Normalized mutual information of different feature selection algorithms
注:每种算法的最好结果用粗体标注,第二好结果用下划线标注.

图1 不同特征数时各个算法的聚类精度Fig.1 Clustering accuracy of different feature selection algorithms in different number of the selected features
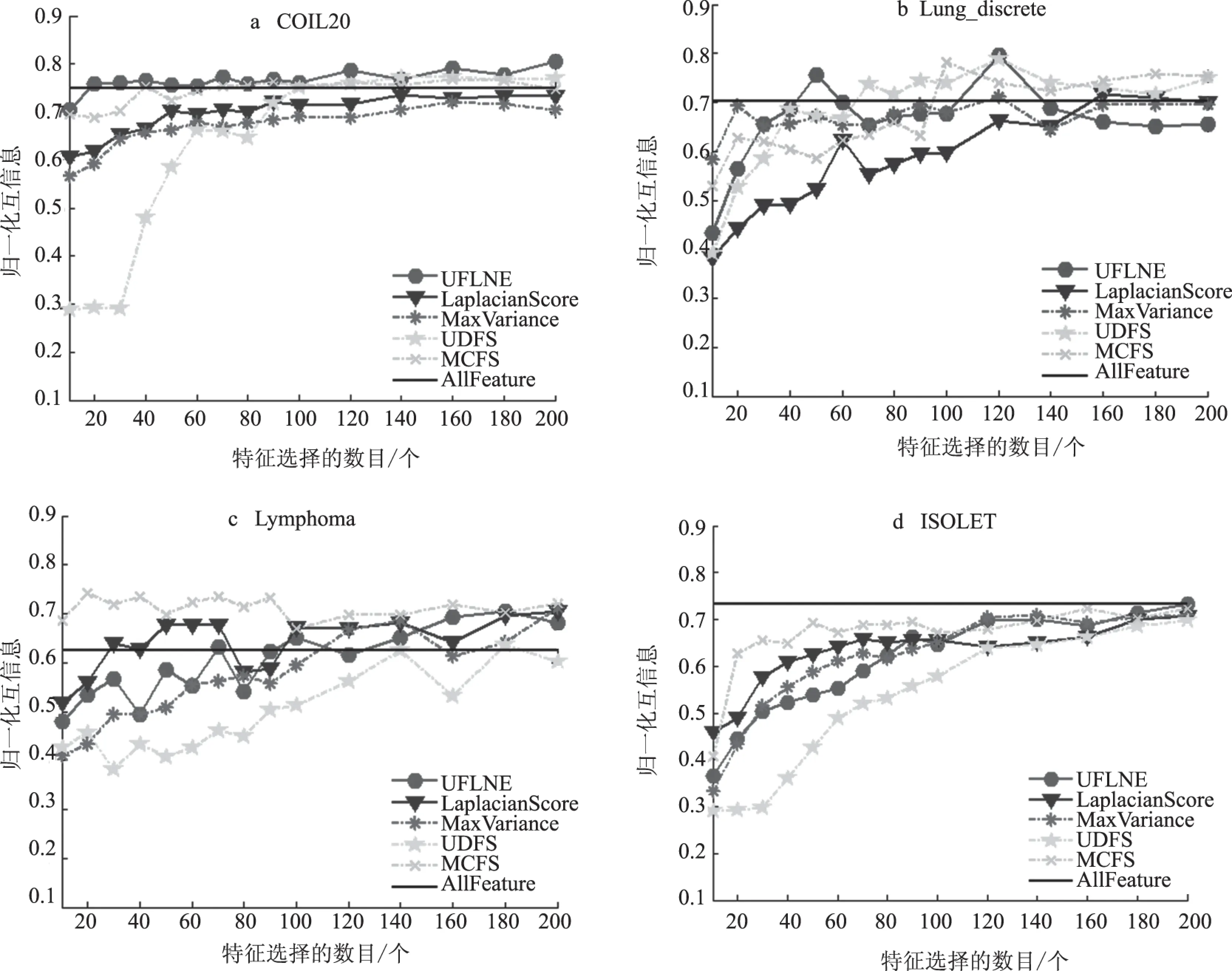
图2 不同特征数时各个算法的归一化互信息Fig.2 Normalized mutual information of different feature selection algorithms in different number of the selected features
本文算法是一种基于流行学习的特征选择算法,结合局部邻域嵌入和l2,1范数,准确地评价了每个数据样本的重要性,得到的全局最优解能够避免了一些贪心算法可能带来的缺陷.但是,本文算法将利用LNE构建低维空间和利用l2,1范数进行稀疏回归分为两个独立的部分,不能将构建低维空间的误差和特征选择的误差综合考虑.探索它们之间的相互联系,将其统一在同一框架中将是进一步学习研究的方向.
[1]DUDA R O, HART P E, STORK D G. Pattern classification[M]. New York: John Willey & Sons, 2004.
[2]COVER T M, THOMAS J A. Elements of information theory[M]. 2nd edition. New York: John Willey & Sons, 2003.
[3]CAI D, ZHANG C, HE X. Unsupervised feature selection for multi-cluster data[C]// Proceedings of the 16th ACM SIGKDD international conference on knowledge discovery and data mining. Washington, 2010: 333-342.
[4]HE X, CAI D, NIYOGI P.Laplacian score for feature selection[C]// Advances in neural information processing systems. Columbia, 2005: 507-514.
[5]PENG H, LONG F, DING C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy[J]. Pattern analysis and machine intelligence, IEEE transactions on, 2005, 27(8): 1226-1238.
[6]谭台哲, 叶青, 尚鹏. 基于局部重构的无监督特征选择方法[J]. 计算机应用研究,2014, 31(9): 2828-2831.
[7]YANG Y,SHEN H T, MA Z, et al.l2,1norm regularized discriminative feature selection for unsupervised learning[C]// IJCAI Proceedings: international joint conference on artificial intelligence. Bacelona, 2011.
[8]LI Z, YANG Y, LIU J, et al. Unsupervised feature selection using nonnegative spectral analysis[C]// National conference on artificial intelligence. Toronto, 2012: 1026-1032.
[9]TENENBAUM J B, DE SILVA V, LANGFORD J C. A global geometric framework for nonlinear dimensionality reduction[J]. Science, 2000, 290(5500): 2319-2323.
[10]ROWEIS S T, SAUL L K. Nonlinear dimensionality reduction by locally linear embedding[J].Science, 2000, 290(5500): 2323-2326.
[11]SAUL L K, ROWEIS S T. Think globally, fit locally: unsupervised learning of low dimensional manifolds[J]. The journal of machine learning research, 2003, 4(6): 119-155.
[12]马丽, 董唯光, 梁金平, 等. 基于随机投影的正交判别流形学习算法[J]. 郑州大学学报(理学版), 2016, 48(1): 102-109.
[13]BELKIN M, NIYOGI P. Laplacian eigenmaps and spectral techniques for embedding and clustering[C]//Advances in neural information processing systems. Denver, 2001, 585-591.
[14]SCHÖLKOPF B, SMOLA A, MÜLLER K R. Kernel principal component analysis[C]// International conference on artificial neural networks. Berlin, 1997: 583-588.
[15]BELHUMEUR P N, HESPANHA J P, KRIEGMAN D J. Eigenfaces vs. fisherfaces: Recognition using class specific linear projection[J]. Pattern analysis and machine intelligence, IEEE transactions on, 1997, 19(7): 711-720.
[16]HE X F, NIYOGI P. Locality preserving projections[J]. Neural information processing systems, 2005, 45(1): 186-197.
[17]HE X, CAI D, YAN S, et al. Neighborhood preserving embedding[C]// Tenth IEEE international conference on computer vision (ICCV'05). Beijing, 2005: 1208-1213.
[18]ZHEN L, PENG X, PENG D. Local neighborhood embedding for unsupervised nonlinear dimension reduction[J]. Journal of software, 2013, 8(2): 410-417.
[19]LI J D, CHENG K W, LIU H. Feature selection datasets[EB/OL].[2016-09-14].http://featureselection.asu.edu/datasets.php.
(责任编辑:王浩毅)
Unsupervised Feature Selection Based on Local Neighborhood Embedding
TUO Qianjuan,ZHAO Hong
(LaboratoryofGranularComputing,MinnanNormalUniversity,Zhangzhou363000,China)
In machine learning, feature selection can effectively reduce the data dimension. Manifold learning andl2,1norm can improve the effectiveness and efficiency of feature selection. Manifold learning can maintain the geometric structure of the original data.l2,1norm can prevent the over fitting, and it can enhance the generalization ability of the model. A new unsupervised feature selection method based on local neighborhood embedding (LNE) algorithm andl2,1norm were proposed. The main ideas were as following. Firstly, it constructed similar matrix by the distances and reconstruction coefficients between each data and its neighborhood. Secondly, it built a low dimensional space and usedl2,1norm sparse regression. Finally, it calculated the importance of each feature and chose the optimal feature subset. Experimental results showed the effectiveness of the proposed algorithm by comparing it with several typical feature selection algorithms.
machine learning; local neighborhood embedding; manifold learning; unsupervised feature selection
2016-06-04
国家自然科学基金资助项目(61379049,61472406);福建省自然科学基金资助项目(2015J01269);漳州市自然科学基金资助项目(ZZ2016J35).
脱倩娟(1991—),女,甘肃庆阳人,硕士研究生,主要从事机器学习、数据挖掘研究,E-mail:qianjuan_Tuo@163.com;通讯作者:赵红(1979—),女,黑龙江哈尔滨人,副教授,主要从事粒计算、代价敏感学习、分层分类学习研究,E-mail:HongZhaocn@163.com.
TP181
A
1671-6841(2016)03-0057-06
10.13705/j.issn.1671-6841.2016087
引用本文:脱倩娟,赵红.基于局部邻域嵌入的无监督特征选择[J].郑州大学学报(理学版),2016,48(3):57-62.
