微博意见领袖话语传播特征的组间差异研究*——基于词汇计量和活跃度的分析
2016-10-19王宇波
王宇波,谭 昭
(武汉大学 文学院,湖北 武汉 430072)
微博意见领袖话语传播特征的组间差异研究*
——基于词汇计量和活跃度的分析
王宇波,谭昭
(武汉大学 文学院,湖北 武汉 430072)
通过量化微博传播的相关指标,筛选出具有代表性的30位新浪微博意见领袖,抓取约50余万字的原创微博语料建立语料库,分析了不同职业、学历、年龄、性别的微博意见领袖在词汇密度、词汇变化性、词类离散度、微博活跃度方面的组间差异,发现意见领袖的身份特征与其话语传播特征之间存在密切关联,相关统计数据和研究结论可为新媒体语言监测、网络监管和舆情监测提供信息参考。
新媒体;影响力;词汇密度;离散度;活跃度
“意见领袖”(Opinion Leader)的概念最早由美国传播学学者Lazarsfeld在其著作“The People’s Choice”中提出[1]。近年来,随着互联网的发展,尤其是社交网络的迅猛发展,新媒体意见领袖在信息传播中的作用更加重要。据中国互联网络信息中心(CNNIC)2015年7月22日发布的《第36次中国互联网络发展状况统计报告》显示,“2015年上半年,微博客用户中,使用新浪微博的用户占69.4%,一至五级城市的使用率都在65%以上。”[2]相关研究表明,微博作为网络舆论的最主要阵地之一,其意见领袖在突发事件的信息传播[3]、话语权的实现[4]、网络舆论及口碑效应的影响力[5-6]等方面具有重要作用,研究微博等社交网络中意见领袖的话语传播特征对新媒体语言监测也具有重要意义。
微博意见领袖通过原创、转发或评论来表达对社会事件的观点,以个人号召力影响信息传播,具有独特的话语传播特征。本文依据自制的2015年新浪微博意见领袖排行榜,建立一个小型语料库,并根据行业、学历、年龄、性别四种身份特征将其分组,使用Corpus Word Parser、CCRL、SPSS软件对语料进行分词、词性标注和统计分析,通过词汇密度、词汇变化性、词类离散度等词汇计量特征以及微博活跃度等传播指数,对比不同身份特征的新媒体意见领袖话语传播特征,分析其组间差异,为网络监管、舆情监测及引导提供信息参考。
一、意见领袖语料库建设
微博平台上具有舆论影响力的人群包括社会名人、机构、网络红人和其他大V等,但是有影响力的用户并不全是微博意见领袖。目前,暂无较权威的微博意见领袖排行榜,从多家机构已发布的中国微博意见领袖排行榜看,存在行业覆盖面窄、参照时间短等弊端,不利于进行社会语言学分析。本文为考察不同身份特征意见领袖的话语传播特征,筛选出30位不同社会属性的意见领袖,制定了覆盖面较全的2015年微博意见领袖排行榜和语料库。具体步骤如下:
第一步,以环球网论坛在2015年2-3月间4次公布的“新浪微博意见领袖百强排行榜” 为依据,收集了榜单中所有账户在2015年1月1日-4月30日期间的全部微博,包括发博时间、转发量、评论数、回帖数、点赞数等相关信息。
第二步,确定两个一级量化指标和七个二级量化指标。由于微博意见领袖具有主题依赖性的特点[7],即在某一主题内特别活跃并且在该主题内具有极大影响力的用户。因此,本文将“用户影响力”和“用户活跃度”作为衡量微博意见领袖的两个一级指标。“用户影响力”包括“被转发数、被评论数、被提及数”3个二级指标,“用户活跃度”包括“原创数”、“自回帖数”、“回他人贴数”、“活跃天数”4个二级指标。
第三步,量化相关指标。影响力的计算公式:Influence影响力=V被转发*W1+V被评论*W2+V被提及*W3,活跃度的计算公式:Activity活跃度=V原创数*W4+V自回帖数*W5+V回他人贴数*W6+V天数*W7。本文采用美国学者T.L.saaty提出的AHP层次分析法确定W1-7各指标的权重,并结合刘志明、刘鲁制定的权重数据及计算方法进行量化[7]。
第四步,根据计算结果,筛选出前50名微博意见领袖,然后参考近两年行业微博情况报告、微博名人排行榜、新浪微博名人堂等资料,分析得到微博意见领袖的14个行业分布,权衡行业、年龄、学历、性别的人数比例后,制定出囊括了30人的“新浪微博意见领袖排行榜”(排名不分前后),见表1。
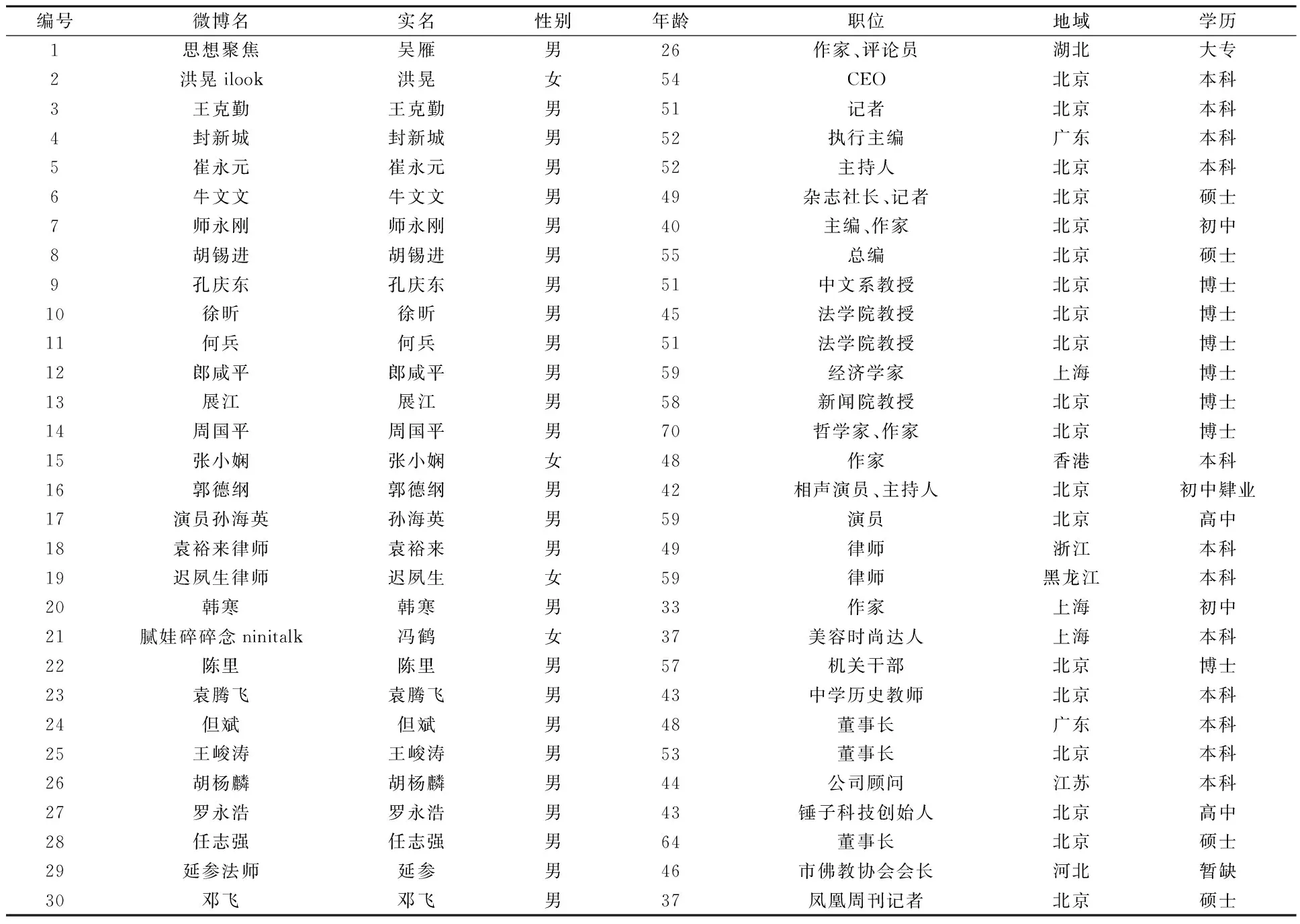
表1 新浪微博意见领袖排行榜
第五步,将30位微博意见领袖在2015年1-4月期间的原创微博建立小型语料库,共7091条,总计496 917字。根据行业、学历、年龄、性别四个类别对语料进行分类,使用教育部语言文字应用研究所研制的“Corpus Word Parser”软件对语料进行分词、词类统计,用EXCEL计算词汇密度、词汇变化性、词类标准偏差、微博活跃度,对词汇丰富性和微博传播指数进行全面综合的分析和组间计量对比,分析不同身份特征新媒体意见领袖的话语传播特征。
二、词汇密度组间差异
Arnaud[8],Linnarud[9],Laufer & Nation[10]309,Read[11]等国外学者先后提出多种测量“词汇丰富性”(lexical richness)的数理统计方法,考察语言使用者在自由言语产出中使用词汇的丰富程度。王立非、孙晓坤[12],崔艳嫣、王同顺[13],张艳、陈纪梁[14]等国内研究者也都基本上采用国外提出的词型标记比和词频概貌的测量手段。Read[11]认为词汇丰富性包含词汇密度、词汇变化性、词汇复杂性(表达精确性)、错误数量四种测量维度,这一观点得到较为广泛的认可。四类测量方法中,词汇复杂性和错误数量多用来测量语言习得的效果,因此,本文将采用词汇密度、词汇变化性的测量方法,考察微博意见领袖的词汇丰富性。
(一)词汇密度及其测量方法
Holmes认为,语篇的作者本身拥有一定量的词汇存储,而且偏爱使用一些词汇,作者的词汇量反映在词汇的出现频率中,词汇频率分布的测试可以应用到不同类别作者的比较分析之中[15]。词汇密度作为一个语言特征,是衡量单位篇章信息含量的尺度,在一定程度上反映了语言材料传播的信息量和感知难度,而且测量结果稳定,不会受到语篇长度的影响,经常被用来区别语体风格[14,16-17]。Halliday认为,词汇密度反映的是句中实词所占的比例。词汇密度越大,所载的信息量也越大。反之, 信息量就越少[18]。陈会军认为,词汇密度过低会影响信息的表达质量和篇章体裁的准确体现,词汇密度过高会增加人们对篇章的感知难度[16]57。
词汇密度( lexical density)计算公式最早由Ure提出,“词汇密度=篇章中的实词词项数量÷篇章单词总量*100%”,计算结果为篇章中每百字中所包含的实词词项数量[19],这一测量方法也是目前运用最多的传统计算方法。Halliday提出了新的计算方法,“词汇密度=词项数量÷篇章小句总量*100%”,他认为计算单位小句内实词所占的百分比,比Ure计算篇章的词汇密度更能准确地体现单位篇章的信息含量。
(二)意见领袖词汇密度
1.不同行业的组间比较。为有效地进行组间差异比较,首先将30位意见领袖所在的14种职业合并为“党政、经济、文化、公知、文艺、宗教、自由职业”7个领域,然后统计出各领域意见领袖在各词类的词种数、频次、句子总数等方面的数据,进而测量不同类别意见领袖微博文本的词汇密度。本文同时采用Ure和Halliday的测量方法分别计算各行业的词汇密度,统计数据如表2:

表2 各职业意见领袖词汇密度统计 %
Ure、宋婧婧、李小凤等采用Ure的测量方法,考察过不同语体的词汇密度差异,口语语体词汇密度普遍低于书面语体。Ure研究数据显示,英语口语篇章的词汇密度在40%以下,书面语篇篇章的词汇密度在40%以上。宋婧婧认为现代汉语口语、书面语料的词汇密度分别为61%、75%[20]。蔡玮认为报刊新闻词汇密度约为84.9%[21]。李小凤的研究显示,电声语体为75.3%、书面语体为77.6%、文艺语体为75.3%、政论语体为75.4%、科学语体为79.8%、公文语体为83.1%。本文依据Ure的测量方法,词汇密度明显低于已有研究数据,其中党政、文化、公知、文艺低于30%,宗教甚至低于10%。根据高低排序为:自由职业>文艺>文化>党政>公知>经济>宗教。按照Halliday的计算方法也得到类似的序列:自由职业>党政>公知>文艺>文化>宗教>经济。两种测量结果中,自由职业的词汇密度都最高,宗教和经济的词汇密度最低。
七个类别的词汇密度可以分为两个类别:一类是词汇密度相对较高的党政、公知、文艺、文化、自由职业,这些意见领袖的微博信息量较大,微博内容涉及法制、民生、社会等话题;另一类是词汇密度相对较低的宗教、经济,这两类意见领袖的微博信息量较小,内容主要以生活为主,句子短句、散句居多。
2.不同学历的组间比较。根据意见领袖的学历分布,分为本科以下、本科、硕士、博士四组,分组计量各学历层次的词汇密度,见表3。

表3 各学历层次意见领袖词汇密度统计 %
两种测量结果都显示,本科学历意见领袖的词汇密度最低,博士以及本科以下学历的词汇密度居中,硕士学历的词汇密度最高。说明词汇密度的大小与学历层次高低之间不存在线性相关。
3.不同年龄段的组间比较。本文筛选的30位微博意见领袖,其年龄主要集中在40-60岁间,30岁左右的人数较少。因此,本文将意见领袖按年龄分为两大类:五十岁以下的中青年与五十岁以上的中老年。词汇密度(U)计算结果显示,中青年组为17.82%,中老年组为17.43%;词汇密度(H)计算结果显示,中青年组为2.9613,中老年组为2.5343。中青年组意见领袖词汇密度整体上略高于中老年组,但是差距比较小。
4.不同性别的组间比较。性别语言研究一直是社会语言学的研究热点,同时也是心理学、社会学、人类学等多个学科领域所关注的研究课题。近年来,学界逐渐把性别语言差异研究的重点转向了交际中的话语模式等方面。Wardhaugh认为,男女两性在话语模式上存在着不同程度的差异,具有不同的风格,主要表现在话题的选择、话语量大小与话轮的控制及交际策略方面[22]。其中,话语量的研究主要是比较两性说话的时长或文本长度,不同于词汇密度所反映的信息量。目前,还未见从词汇密度比较两性话语信息大小的相关研究。从词汇密度分析两性的信息量差异,可以丰富性别语言关于话语模式的研究。
词汇密度(U)计算结果显示,男性意见领袖为14.48%,女性为24.94%;词汇密度(H)计算结果显示,男性为2.2171,女性为3.7124。两种测量方式都说明,女性意见领袖比男性意见领袖的词汇密度要高,女性的信息量更大。Coates[23]、Romaine[24]、许力生[25]、Tannen[26]、王宇波[27]164等都认为男性话语量高于女性。可见,词汇密度反映的信息量与话语量是表现话语特征的两个不同维度。男性话语量相对较大,但是信息量相对较小,女性则相反。
三、词汇变化性比较
(一)词汇变化性及测量方法
词汇变化性,即词汇多样性(lexical diversity),是反映作者词汇丰富性的一个非常重要的指标,通常用来测量篇章词汇的使用范围或种类,数据可以反映语言使用者用词是否丰富多样、是否较少重复等,数值越高表明用词范围越广。
传统计算词汇变化性方法是通过类符(Type)和形符(Tokens)的比值来测量(TTR),即语篇中所有不同的单词在连续呈现的单词总数中所占的百分比[10]309。不过,这种传统的TTR算法虽然简单,但计算结果会受到文本长度的影响。当文本长度增加时,TTR比值会随之降低,不能很好地测量不同文本长度下的词汇复杂性[28],其信度一直以来备受质疑。Dugast提出了更为复杂的Uber index测量方法[29],计算公式为:
UberindexU=(logTokens)2/
(logTokens-logTypes)
Tweedie &Baayen认为这一公式为词汇变化性提供了相对精确的测量方法[30],且“不受文本长短的影响”[31]。Jarvis[32]、McCarthy[33]认为Uber index的信度较好,因此,本文采用该方法测量意见领袖的词汇变化性。
(二)意见领袖词汇变化性
词汇变化性可以用来评估意见领袖的词汇知识及其语言输出中的词汇变化特点,不同职业意见领袖词汇多样性的测量结果见表4。

表4 各职业意见领袖词汇变化性统计
测量结果显示,自由职业意见领袖的词汇变化性最大,词汇知识最丰富。宗教词汇变化性最小,词汇知识相对匮乏。这一倾向和词汇密度的测量结果具有相似性,自由职业在所有类别中的词汇变化性和词汇密度最大,宗教类最小。
不同学历层次意见领袖的词汇变化性中,硕士学历最高,为34.86,其次是本科以下和博士,分别为33.84和32.90,本科学历最低,为29.42。这一倾向与词汇密度也相似,说明微博意见领袖的学历变化与词汇密度、词汇变化性的高低不呈线性相关。
不同年龄段、不同性别意见领袖之间的词汇变化性差距较小。中青年组略高于中老年组,分别为30.08和30.05;男性词汇多样性略高于女性,分别为29.71和29.27。年龄组的词汇多样性高低与其词汇密度高低具有同一倾向,中青年组都高于老年组,说明中青年意见领袖微博内容更为广泛,微博文本的词种数更多。不同性别意见领袖的词汇多样性高低与其词汇密度高低不一致。在词汇变化性上,女性低于男性,但是在词汇密度上,女性却高于男性。说明男性的词汇知识更丰富,微博涉及的主题更多,内容更为广泛,词种更丰富。
(三)词类离散度比较
词汇变化性作为测量语篇词汇丰富程度的一个维度,依据的是词种数和词总数两个变量,只能反映词汇的整体情况,无法测量不同词类使用状况。由于不同类型的微博在词类和词频上存在差异,因此各词类的使用状况能够反映作者的文本风格特征。为了进一步考察意见领袖的词类变化性,本文以各词类出现的频次在词总数中所占百分比为依据,计算各词类数据之间的标准偏差。标准偏差代表了一组数据的离散程度,可以用来衡量作者的词类多样性。标准偏差越大,数值偏离平均值就越多,离散度就越高,名词、动词的比例相对较高,其他词类比例较低;反之,如果标准差相对较小,离散程度就较低,各词类分布相对均衡,连词、叹词、拟声词等词类使用比例增大。
对意见领袖的词类离散度测量后发现:1.不同行业的标准偏差由大到小排序为:自由职业(0.1089)、公知(0.1078)、政党(0.1054)、经济(0.0983)、文化(0.0970)、文艺(0.0924)、宗教(0.0886)。这一序列与词汇变化性、词汇密度的序列相似,自由职业仍然居首。自由职业类的名词和动词的比例高达33.94%和27.33%。离散度最小的宗教类,名词和动词的比例降低到27%和24%。2.不同学历层次意见领袖的词类离散度与学历具有密切联系,学历越高,词类离散度越高。标准偏差由大到小排序为:博士学历(0.1071)、硕士学历(0.1016)、本科学历(0.1000)、本科以下(0.0912)。3.不同年龄段的测量显示,中老年意见领袖的词类离散度为0.1032,略高于中青年组的0.0971。4.不同性别组的测量显示,男性意见领袖的词类离散度为0.1017,高于女性的0.896。可见,不同职业、性别的意见领袖,他们的词类离散度高低和词汇变化性大小具有相同倾向,而不同学历、年龄的意见领袖则没有。
词类离散度的高低受到低频词类使用比例的影响,实词中的名词、动词、形容词,虚词中的助词都是出现频次较高的词类,而虚词中的介词、连词、叹词、拟声词,实词中的量词都是出现频次较低的词类。当前者比例降低,后者比例增高时,离散度就会降低。考察发现,在职业中的宗教类、学历层次中的本科以下、年龄段中的中青年组,以及性别分类中的女性组中,意见领袖的名词、动词等高频词类出现的比例较低,而叹词、连词等低频词类较高。例如女性意见领袖的叹词和副词比例明显高于男性,叹词分别为0.16%, 0.14%,副词9.37%,6.28%。马琰[34]、王宇波[27]研究也发现女性叹词的使用频率明显高于男性,王德春等认为女性比男性更多地使用副词,以及起强调作用的词语[35]。
四、词汇丰富度与活跃度关系
微博的活跃度和传播度反映了账号的传播能力和传播效果,可以通过微博传播指数BCI(Micro-blog Communication Index)进行测量①。本文对意见领袖活跃度的分析采用BCI指数进行评估,利用其中的推送活跃度指数W1进行计算,公式为W1=30%×ln(X1+1)+70%×ln(X2+1),其中X1为发博数,X2为原创微博数。通过活跃度的测量,进而分析活跃度与词汇丰富性的关联。
每组意见领袖的活跃度是组内每位意见领袖W1指数之和的平均数。不同职业意见领袖的微博活跃度由高到低排序为:宗教(7.05)、经济(6.89)、公知(6.55)、文化(6.54)、党政(5.49)、文艺(4.40)、自由职业(3.19);不同学历层次意见领袖的微博活跃度由高到低排序为:本科(5.63)、博士(5.36)、硕士(4.89)、本科以下(4.56);年龄组中,中老年意见领袖为5.42,中青年为5.23;性别组中,女性意见领袖为133.93,男性为117.99。
将意见领袖的微博活跃度与词汇密度、词汇变化性、词类离散度的测量结果比较后发现,微博活跃度越高的职业,其词汇密度、词汇变化性和词类离散度越低;从学历差异看,活跃度与词汇密度正相关,与词汇变化性负相关;从年龄差异看,中老年组的微博活跃度、词类离散度比中青年组高,但是词汇密度和词汇变化性却低于中青年组;从性别差异看,女性的活跃度和词汇密度比男性略高,但是词汇多样性和词汇离散度却低于男性。
五、结 语
本文依据微博的传播特点,量化相关指标,筛选出了具有代表性的微博意见领袖,分别测量了不同行业、学历、年龄、性别的微博意见领袖在词汇密度、词汇变化性、词类离散度、微博活跃度等话语传播特征。研究发现,不同类型意见领袖的话语传播特征存在明显的组间差异。虽然本文得到了一些有益的结论,但是对微博意见领袖话语特征的分析还不够全面,如何采用更有效的方法识别微博意见领袖,对新媒体意见领袖进行长期跟踪和观察,促进新媒体语言规范化发展,监控及引导微博意见领袖的言论等方面,仍有待下一步的深入研究。
注释:
①BCI指数依据《中国移动互联网发展报告(2015)》的计算方法,BCI包括活跃度W1和传播度W2两个二级指标,其中W1又包括发博数X1和原创微博数X2两个三级指标。
[1]Lazarsfeld, P. F., Berelson, B., & Gaudet, H. The People’s Choice[M]. New York: Columbia University Press,1948.
[2]国家互联网络信息中心.第36次中国互联网络发展状况统计报告[EB/OL].(2015-07-22)[2016-03-15].http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/201507/P020150723549500667087.pdf
[3]姜珊珊,李欲晓,徐敬宏.非常规突发事件网络舆情中的意见领袖分析[J].情报理论与实践,2010,33(12):101-104.
[4]Lee, N.Y. & Kim, Y. The spiral of silence and journalists’ outspokenness on Twitter[J]. Asian Journal of Communication. 2014,24(3):262-278.
[5]Peng, Y., Li, J., Xia, H., Qi, S., & LI, J. The effects of food safety issues released by we media on consumers’ awareness and purchasing behavior: A case study in China[J]. Food Policy, 2015,51:44-52.
[6]元志润.在网络口碑沟通中的意见领袖(Opinion Leader)研究:以韩国超级博客(Power Blog)为例[D].上海:复旦大学,2011.
[7]刘志明,刘鲁.微博网络舆情中的意见领袖识别及分析[J].系统工程,2011(6):8-16.
[8]Arnaud,P.J.L.. The lexical richness of L2 written productions and the validity of vocabulary tests[M]∥In Culhane T, Klein B C & Stevenson D K (eds.). Practice and Problems in Language Testing: Papers from the International Symposium on Language Testing. Colchester: University of Essex,1984. 14-28.
[9]Linnarud,M. Lexis in Composition. A Performance Analysis of Swedish Learners’ Written English ( Lund Studies in English 74)[M]. Lund: CWK Gleerup,1986.
[10]Laufer,B.&Nation,P. Vocabulary size and use: Lexical richness in L2 written production[J]. Applied Linguistics,1995,16(3): 307-322.
[11]Read,J. Assessing Vocabulary[M]. Cambridge: Cambridge University Press,2000.
[12]王立非,孙晓坤.汉语写作能力对英语写作质量的影响[J].外语与外语教学,2005(4):24-29.
[13]崔艳嫣,王同顺.接受性词汇量、产出性词汇量与词汇深度知识的发展路径及其相关性研究[J].现代外语,2006(4):392-400.
[14]张艳,陈纪梁.言语产出中词汇丰富性的定量测量方法[J].外语测试与教学,2012(3):34-40.
[15]Holmes, D. I. “The Analysis of Literary Style: A Review,” Journal of the Royal Statistical Society, Series A, 1985,148:328-341.
[16]陈会军.词汇密度与难易度感知:科学论文及其摘要的对比研究[J].外语与外语教学,2003(4):56-57.
[17]李小凤.从词汇密度看电视语体的阶列[J].现代传播,2010(12):164-165.
[18]Halliday, M. Spoken and Written Language[M].Oxford: Oxford University Press, 1985.
[19]Ure, J. Lexical density and register differentiation[M]∥In G. Perren and J.L.M. Trim (eds), Applications of Linguistics.London: Cambridge University Press,1971:443-452.
[20]宋婧婧.现代汉语口语词研究:兼论对外汉语口语词教学[D].北京:中国传媒大学,2011.
[21]蔡玮.新闻类语篇研究的语体学意义[D].上海:复旦大学,2004.
[22]Wardhaugh, Ronald. An introduction to sociolinguistics, 6th Edition Blackwell Publishing, 2010.
[23]Coats, J. Women, Men and Language: A Social Linguistic Account of Sex Differences. London: Longman, 1986.
[24]Romanine, S. Language in Society: An Introduction to Social linguistics[M]. London: Oxford University Press, 1994.
[25]许力生.话语风格上的性别差异研究[J].外国语,1997(1):43-48.
[26]Tannen, D. You just don’t understand: Women and men in conversation[M]. New York: William Morrow,2007.
[27]王宇波.基于网络媒体监测语料库(汉语)的性别语言差异实证研究[D].武汉:华中师范大学,2011.
[28]陆芸.词汇丰富性测量方法及计算机程序开发:回顾与展望[J].南京工业大学学报:社会科学版,2012(2):104-108.
[29]Dugast,D. Sur quoi se fonde la notion d’etendue theoretique du vocabulaire?[J]. Le Francais Moderne, 1978,46:25-32.
[30]Tweedie,F. & R.Baayen. How variable may a constant be? Measures of lexical richness in perspective[J]. Computers & the Humanities, 1998,32(5):323-352.
[31]Vermeer, A. Coming to grips with lexical richness in spontaneous speech data. Language Testing, 2000,17(1):65-83.
[32]Jarvis S. Short texts, best-fitting curves and new measures of lexical diversity[J]. Language Testing, 2002,19(1): 57-84.
[33]McCarthy, P. M. An Assessment of the Range and Usefulness of Lexical Diversity Measures and the Potential of the Measure of Textual, Lexical Diversity (MTLD)[D]. Memphis Tennessee: University of Memphis Ph.D Dissertation, 2005:158.
[34]马琰.汉语恭维语中的性别语言实证研究[J].商洛学院学报,2009(5):57-62.
[35]王德春,孙汝建,姚远.社会心理语言学[M].上海:上海外语教育出版社,1995:214.
(责任编辑文格)
Inter-group Differences in the Features of Discourse Transmission of Micro-blog Opinion Leaders:Based on the Analysis of Words Computation and Activeness
WANG Yu-bo, TAN Zhao
(School of Chinese Language and Literature, Wuhan University, Wuhan 430072, Hubei, China)
The paper screens out 30 representative opinion leaders of Sina micro-blog through quantifying relevant indexes of micro-blog transmission, then builds a corpus by grasping original microblogs with more than 500,000 characters in order to analyze inter-group differences in aspects of lexical density, lexical variation, dispersion of parts of speech and activeness of micro-blogging between different occupations, education, ages as well as genders. The study finds out that identity characteristics of opinion leaders are closely associated with the features of their discourse transmission, and both relevant statistical data and research conclusions provides new media language monitoring, Internet censorship and opinion supervision with reference information.
new media; influence; lexical density; dispersion; activeness
2016-06-10
王宇波(1983-),男,湖北省汉川县人,武汉大学文学院讲师,博士,主要从事社会语言学研究;
谭昭(1994-),女,湖北省汉川县人,武汉大学文学院硕士生,主要从事社会语言学研究。
国家社科基金青年项目“基于大规模标注语料库的自媒体语言计量研究”(12CYY030);教育部人文社科青年项目“基于大规模标注博客语料库的性别话语差异实证研究”(12YJC740106);国家语委重点科研项目“新媒体意见领袖话语传播机制研究”(ZDI135-11);武汉大学自主科研(人文社科)项目; 中央高校基本科研业务费专项资金资助
G206.3;H13
A
10.3963/j.issn.1671-6477.2016.05.0008
