基于日班计划的车流推算研究
2016-10-18龙昭
龙 昭
(北京全路通信信号研究设计院集团有限公司,北京 100070)
基于日班计划的车流推算研究
龙 昭
(北京全路通信信号研究设计院集团有限公司,北京 100070)
车流推算是技术站进行作业安排的关键手段,研究了基于CIPS系统日班计划模块的车流推算及推流算法,给出具体的推流过程,并且实现了相关功能,应用于现场,获得了良好的效果。
日班计划;车流推算;技术站
1 问题与现状
技术站的车流推算是调度员安排全站调车作业、接发车作业和机车出入段作业的主要手段。通过车流推算,调度员掌握全站的车流情况,合理安排车流接续,进而指导全站的技术作业,因此,车流推算在调度工作中处于非常关键的位置[1]。
1.1车流推算的特点
车流推算的本质含义为如何通过推算,将本站现有和将要到来的车流快速有序的安排到出发列车中,正点发出,他是联系到达列车和出发列车的一条纽带。在车流推算过程中,必须考虑很多因素,如列车时刻表、编组计划、重点车流、无调车流、车站解编能力、场上车流分布情况、预计到达车流情况等,这些都对车流推算产生很大的影响。
由于未到站车流对车流推算的影响很大,这就决定一次推算时间不可能很长,如车站基本上只能看到未来3 h的到达列车及其确报,那么,推算时间过长也没有现实意义。这也使得调度人员需要根据车流情况反复推流,不断调整作业计划,以达到畅通的目标。
由于本务机出段必须有提前通知的计划,即列车没有编组完成就要通知,所以推流结果必须保证其严肃性,保证其对全站的指导意义,不可能在执行过程中随意更改。
1.2目前车流推算的现状
基于车流推算涉及因素的复杂度,编制一个完全自动化的推流系统是比较困难的。现在还无法编制一个系统,完全自动安排技术站的调车作业、出发列车作业、出发列车的编组内容、本务机的出入段等作业,而不需要人工参与,但仍然有很多同仁进行了这方面的研究和探讨,提出很多有益的想法。
文献[2]将车流推算看作商品交易行为,提出车流资源在编入出发列车时的虚拟价格概念及其确定方法,用来控制车流资源在车站的停留时间,最后用遗传算法进行求解。文献[3]建立了技术站阶段计划的车流推算模型,从寻找最优的列车解体、编组顺序出发,结合求解运输问题的表上作业方法,设计了求解该模型的混合遗传算法。文献[4]运用组合数学原理构造方案树,提出最大可能剩余量概念,导出计算公式,并以此作为方案值控制树的生长进而利用回溯算法搜索有利方案。
以上这些研究成果都是从数学上来解决推流问题,通过建模算法来得到优化结果。
CIPS系统在全路编组站调度指挥系统中具有领先地位,其系统地管理全站的现车和各种技术作业。在CIPS系统中有班计划管理子系统,它的主要功能是通过服务端的推流实时提供接发列车后的场内车流以及各个整点的车流,为调度员进行推流组织提供车流数据参考。但由于其数据完全为静态,并不能提供建议结果,再加上一些其他的功能缺陷,制约了班计划子系统的运用,也没有达到其作为调度常用工具的目的[5]。因此,完善推流系统,为调度员提供真正的决策支持就成为一项迫切的工作,这也是本文的研究内容。
由于推流工作既处于车站工作的核心位置,又与各项工作息息相关,因此基于一个车流系统来推流,才能真正发挥推流的优势,让调度员通过推流加调整的手段达到推流的目的。
2 车流推算过程
为调度员设计的推流过程如图1所示。
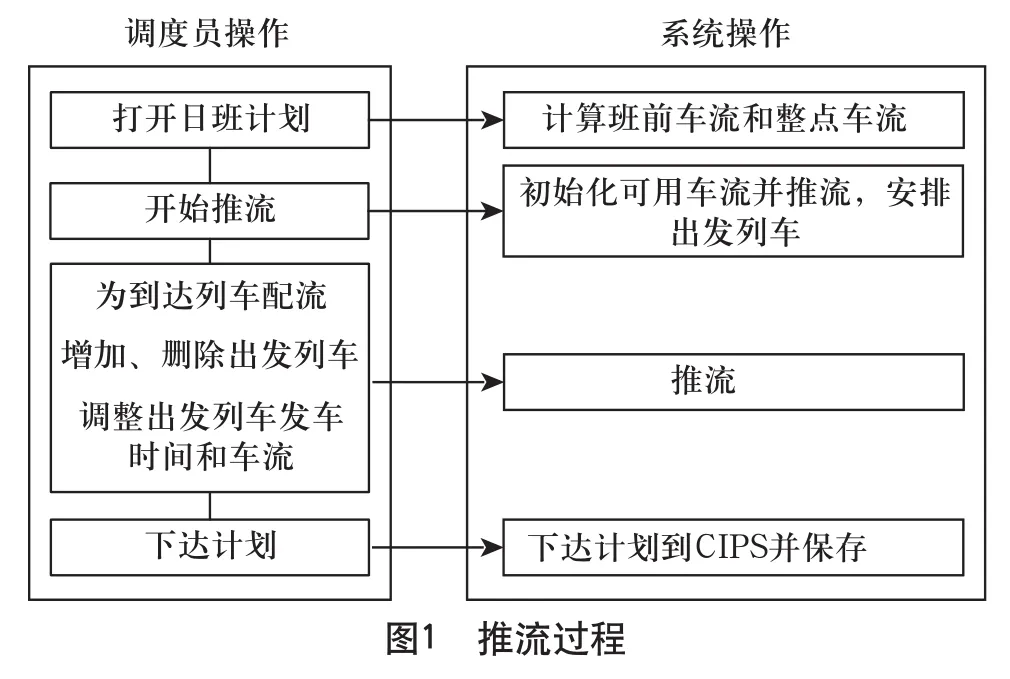
1)计算班前车流和整点车流
打开日班计划客户端时,根据当前场上的实时车流和06:00(18:00)到目前为止的到发列车情况计算06:00(18:00)时的车流,并从这个班前车流往后推,每个整点的车流显示在客户端上。
2)初始化可用车流
需要开始推流时,重新根据实时车流和到发列车情况计算每个车流的可用时间和使用权重,作为推流的原始数据。重新获取原始车流而不是使用班前车流来推,也是为了进一步修正车流数据,保证数据的准确性。
3)推流
有了可用车流就可以推算出发列车,为出发列车安排车流。在实际操作中,如果改变了将要到达列车的车流,或者增加、删除、修改了出发列车,则会重新推流,改变出发列车的车流。当然对于用户已经修改了车流的出发列车(默认为用户已经确认此车流),则不再为其重新安排车流。
4)下达计划
调度员调整完计划后,可以将计划下达到上层的CIPS系统,作为场调、机调的作业依据。系统也会将所做计划保存起来,用于以后查询当时做的计划,与实际数据进行比较,评比计划的兑现率。
3 原始车流和到发列车的确定
3.1原始车流切面的确定
在车流推算中,原始车流切面的确定是至关重要的,只有保证其准确,推流结果才有可用性。
既有CIPS系统的做法是在服务端推流,即每次交接班时在服务端推定06:00(18:00)的结存车流,往后对于每列车都推定接发这列车后的可用车流,整点车流是根据整点前后的列车数据得到的。这样做的好处是将所有的推流模块放在服务端,从数据结构上看比较优化。但也会出现一些问题,首先可能出现的问题就是到开不对接,因为在CIPS系统中,现车和列车属于不同的线程管理,双方通过其他机制来保证数据一致性,那么如果以某一特定时刻的现车和列车数据作为推流基础,就可能出现漏流和多流的情况。比如列车已经调度核准,由于数据不一致,可能现车还没入线,这就可能产生漏流;如列车已经发车报点,但现车还没来得及消失,这就可能形成多流的情况。在既有系统中有相应的措施在不断调整原始数据,弥补漏流和多流引起的误差。这样做还有一个缺陷就是会引起累积误差,如这个班有车流算错了,由于是滚动推算原始车流切面,则其错误会带到下一班中,引起误差无法消除。而且这种做法无法管理非运用车,因为只能得到班初的非运用车,对于往后的运转非、非转用操作无法科学的表达,所以整个班的非运用车数是固定不变的,这样推流肯定会出现误差。
考虑到这些缺陷,本项目重新系统地考虑了原始车流切面的确定准则,编制了新的规则。系统不再将原始切面的获取放在服务端,而是放在客户端。每次打开客户端时,系统通过读取数据库方式来保证数据的准确性,这是因为虽然在程序层面现车和列车的数据可能出现不一致,但在数据库层面上是一致的。打开客户端时,读取当前场内车流、当前所有已经入线的列车,然后根据接发车历史往前推定原始车流。回溯时,对于已经调度核准但还没有入线的列车,则不减去其车流,对于已经发车报点但还没有入线的列车,则不加上其车流,这样每个车的流都不会多算和少算。
每次打开客户端时,都重新推定其原始车流,肯定不会出现累积误差的问题。由于数据库系统保证了保存数据的一致性,那么不同机器在同一时间打开客户端、相同机器在不同时间打开客户端,也不会出现前存数据不一致的问题。
此前说的是打开客户端界面时推定前存车流,那么对于调度人员触发推流操作时,系统并不是用班前车流来推定当前车流,而是又会以读取数据库的方式重新获取一个当前车流、将要到达的车流、非运用车数据,这个车流才作为安排出发列车的原始资源。这样做的原因也是为了多一重保障,而且为了获取每个车流的可用时刻,必须有这样一个流程。
3.2 到发列车范围的确定
推流过程中,对于已经入线的到达列车以当前车流为准,对于还未到站的列车以阶段计划为准。这是因为行调通过邻台的接续等操作对于到达列车的掌握很准确,而列车时刻表和班计划并不能做到这一点。所以车站能够掌握未来3 h的到达列车情况,通过TMIS的原始确报进来以后,系统通过模糊匹配为到达列车匹配确报,得到车流,这个车流加上标准作业时间后,就可以作为可用车流,参与车流推算。对于阶段计划末车时刻以后的到达列车,以班计划为准。
在实际推流过程中,可能存在到达列车没有匹配上原始确报,但这种情况属于很少数,需要调度员人工挑报,为列车安上车流。对于实在没有确报但确实已经知道其车流的列车,可以修改其车流,让其车流参与推算。
推流的目的就是安排出发列车并为其安排编组,出发列车的来源以列车时刻表为准。这是因为编组站的技术作业比较复杂,行调无法实时掌握编组出发情况,因此出发列车的阶段计划并不准确。而班计划是对一天的工作安排,同样存在这个问题,为了提高正点率,以列车时刻表为挑选范围是比较合适的。每次推流时,挑选选定时间段的出发列车,根据其编组计划判断其是否够流,如果够流,则为其安排相应的流。
4 车流推算原理
本系统建立了基于车流权重的推流模型,用特定的算法进行求解。算法最终用C#语言实现,每次推流时间在1 s以内。
假设当前在场车流为S0={S(1),S(2)……S(n)},场上共有n支车流,Si={li,ti,λi,di}表示第i支车流的状态,其中li表示车流所在股道,ti表示车流的列车状态,λi表示车流可以用于出发列车的权重,di表示此车流的方向,每支车流都有唯一的方向号。
对于不在到达场的列车,由于其可用时间已经与到达列车的状态无关,所以ti为空,只有仍然在到达场的列车,其状态不同,则可用时间就不同,如对于在相同到达场的车流,已经列检和已经调度核准其预计可用时间肯定不一样。
对于同在场内的车流,其可用的权重也不同,如编组场的车流肯定比到达场的车流有更高的可用概率,所以设置了权重参数,推流时,权重越高的车流能够越优先用于出发列车。对于非运用车,其权重为0。对于在出发场的车流,如果已经转确报,即已经用于出发列车,则其权重为0。
假设在途车流为S1={S(1),S(2)……S(m)},在途共有m支车流,Sj={tj,λj,dj}表示第j支车流的状态,其中tj表示车流的列车状态,主要是到达时间,λj表示车流可以用于出发列车的权重,对于所有在途车流,其可用权重相同,dj表示此车流的方向。
定义车流集合为:S={S0,S1}
假设推流时间段内基本图中无调列车集合为T0={t(1),t(2)……t(p)},共有p列无调列车,Ti={di,ci,li}表示第i列车,di为规范化后的发车时间,ci表示此列车编组计划,li表示列车发车系统。
由于基本图中的发车日期都是固定的,需要将发车时间规范化到推流时间范围内。无调列车的编组为空,完全根据接续车次来为其安排编组,而有调列车的编组可以有多个方向,所以ci是个编组方向的集合,编组方向之间有先后顺序。每个列车有其原始的发车系统,即从哪个系统发车,推流时可以判断某支车流用于此列车时是否需要交换,但对于环发的情况需要特殊考虑,即可以改变列车的发车系统,这一点在下面的内容中将详细阐述。
假设推流时间段内基本图中有调列车集合为T1={t(1),t(2)……t(q)},共有q列有调车列车,tj={dj,cj,lj}表示j列车,其含义与无调列车一致。
定义目标列车集合为:T={T0,T1}
模型可以定义为得到一个优化的方案,将资源S分配到T中,最终确定每列车的编组内容,定义编组方案为O={o(1),o(2)……o(p+q)},共有p+q列车,ok表示第k列车的编组内容,包括此列车每支车流的来源,是车流来源S的子集,且任意两个编组方案不相交。由于可能存在欠流,所以ok可能为空。
可以看出,建立的模型并不复杂,没有必要用非常复杂的算法,系统设计了独特的数学算法。
Step1:确定车流来源S和初始出发列车集合T,初始化空白的编组方案O′,S中所有车流的权重重新初始化。
Step2:遍历T中所有已经经过用户编辑车流的出发列车,将相应列车的编组方案写入O′中,由于编组方案包含了车流来源,从S中将O′已经用掉的所有车流的权重设置为0。
Step3:为无调列车分配车流。对于T0中的所有列车,从S中查找车次为其接续车次,且接续时间能满足发车条件的车流,如果能找到,则将此车流分配给此无调列车,权重置0。由于无调列车往往是源到源的,所以可以直接将整列车的所有车流统一分配。
Step4:为有调列车分配车流。对于T1中的所有列车,车流分配流程如图2所示。
满足时间条件是指车流从当前线或者未到状态到能够发出所必需使用的标准时间,对于折角车流还必须加上一个交换时间。
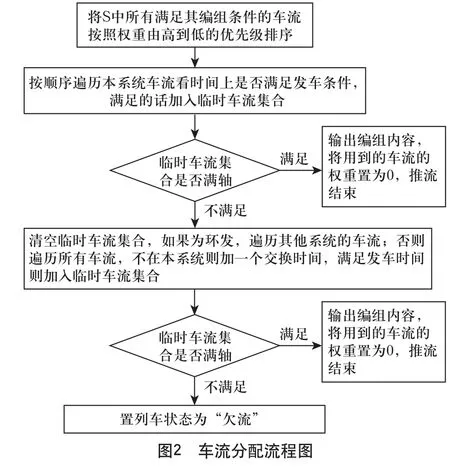
Step5:形成优化的编组方案O。
5 系统中特殊考虑之处
5.1非运用车的特殊考虑
推流时,非运用车不能作为出发车流发出,必须扣除。系统设计打开客户端后,前存非运用车即为当前的非运用车,由于在推流前可能有新的扣修,也可能被修峻,所以推流时不能以这个数据为准。系统设计为推流开始时重新获取非运用车数据,保证推流时车流的准确性。
5.2分系统推流
调度员在推流时,既需要全盘考虑车流,也需要分系统考虑,看本系统是否够流和其车流分布情况。基于日班计划的车流推算系统在推流时详细记录了每个流的线路和方向,因此完全支持分系统推流。
5.3环发的特殊考虑
所谓环发,是指车流不通过常规的车流径路发出,而是经过其相反方向从本站始发,然后绕行特定的车流径路到达目的地。环发是影响车流推算准确与否的关键因素,对于有环发情况的车站,如果不考虑其特殊性,那么推流结果同样不具实用性。
下面以武汉北编组站为例进行分析,武汉北下行出发场可以通过株洲发、麻城发两条正线将下行车流发往邻站滠口,但同时上行出发场也可以通过横店发这条正线将下行车流发往横店,然后到达滠口,形成环发的情况。
此时,上行系统通过横店发车时,其车流实际上是存在于上行系统的下行车流,而车次是下行的车次,即所有经过株洲发、麻城发的列车车次都有可能通过横店发。时刻表中,横店发车只有一条发车记录,完全是用于加开列车用,实际上基本图是没有列车经由横店发车的,即这条记录都是虚拟的。如果完全按照分系统推流,则所有存在于上行系统的下行流都将成为转角流,必须转角后从下行发出,这显然是不对的,这些流实际上是通过横店发出去的。
所以安排株洲、麻城发的基本图列车时,首先看下行系统是否够流,如果不够流,就考虑以相同车次从上行系统发车,此时正线是横店发,两者都不够条件时,才考虑折角。当然也存在这种情况,下行系统的流非常充足,可以开行列车,那么就可能引起上行系统的横店方向老是没有安排列车发出,所以系统必须考虑上下行系统中下行流的具体情况,合理穿插安排横店方向发出列车。
系统将这种情况作为配置写在程序中,较好的解决了这个问题。
5.4到达确报的模糊匹配
由于行车车次和确报车次的不一致性,存在到达列车的阶段计划车次和原始确报车次上下行对不上,或者字母上有差异的情况,这种现象在武汉北尤其突出。如果不能解决此问题,则大部分的到达列车无法自动配报,必须由调度人员人工配报,增加其工作难度,影响系统使用。
因此,系统设计了一个模糊匹配模块,对于上下行不一致的车次,用户维护一个数据表,然后就能够自动匹配。而对于字幕上有差异的车次,系统也做了改善,让其能够自动匹配上。通过修改,大大提高了到达列车的确报自动匹配率。
5.5调整出发列车发车时间的处理
推流操作后,系统根据基本图自动安排出发列车,但根据实际情况,调度员会调整列车,系统对人工调整采取的策略如下:
删除列车:删除此列车,重新推流,将多出来的车流重新分配到新加开的其他出发列车中。
增加列车:增加一列车,重新推流,为此列车安排车流。
拖动列车:往后拖动列车线改变发车点,当拖动时刻接近基本图中下一个同编挂要求的运行线(图定时间±15 min),且该运行线为空时,自动将车次改动到对应该运行线;反之改回去。如若运行线不为空,则仍用拖动前运行线的车次。拖动完成后,重新推流。
修改列车车流:修改某出发列车的车流后,重新推流,但首先必须从原始流中将此列车的流减去,然后再将流分配到其他未人工配流的列车。
6 结论
基于日班计划的车流推算系统在武汉北首次实施,经过“调度员使用→提出问题→修改并重新试用”的阶段。在此期间,调度员提出很多实用性的建议,进一步完善和扩展了推流系统,得到了很好的效果,解决了调度员盲目安排出发列车的问题。
[1]杨浩.铁路运输组织学[M].3版.北京:中国铁道出版社,2011.
[2]徐杰,杜文,刘春煌.铁路技术站车流推算模型和算法[J].中国铁道科学,2005,(4):120-123.
[3]王正彬,杜文,吴柏青,等.基于解编顺序的阶段计划车流推算模型及算法[J].西南交通大学学报,2008,(1):91-95.
[4]王慈光.编组站动态配流模型与算法研究[J].铁道学报,2004,(1):1-6.
[5]丁昆.铁路编组站CIPS系统的研究[J].中国铁路,2009,(11):27-31.
Traffi c fl ow estimation is a key method for carrying out operation in technical stations. The paper studies traffi c fl ow estimation based on the traffi c daily plan module of the CIPS system from the algorithm and processes of traffic flow estimation. It is proved that the functions can be realized through on-site application of the method with well effect.
daily plan; traffi c fl ow estimation; technical station
10.3969/j.issn.1673-4440.2016.03.003
2015-08-18)
