基于ARM9体系架构的编译优化研究
2016-10-17葛吴超周亦敏
葛吴超,周亦敏
(上海理工大学 光电信息与计算机工程学院,上海 200093)
基于ARM9体系架构的编译优化研究
葛吴超,周亦敏
(上海理工大学 光电信息与计算机工程学院,上海 200093)
在嵌入式系统软件开发过程中, GCC编译循环程序时的窥孔优化比较欠缺,编译代码在性能上较ARM商业编译器低。文中提出针对于ARM9处理器的循环计数值组合、循环处理数据合并和循环最优展开等3种窥孔优化方法优化汇编代码。选取矩阵乘法,图像合并和内存设置等经典程序运行在ARM9平台上,分别验证3种窥孔优化方法。实验数据表明,与GCC编译代码相比,经文中提出的方法优化后的代码在寄存器使用数量上,平均节省了50%,性能提升近2倍。
窥孔优化;循环计数值组合;循环处理数据合并;循环最优展开
嵌入式系统中,包含一些决定系统性能的关键程序。通过程序优化可大幅提升系统的性能,降低系统的整体功耗。优化可将一个不可行的系统变得可行,亦可将一个无竞争力的系统变得极具竞争力。对于程序的优化,使用传统的编译器优化可得到性能较好的目标代码。但要获得最佳性能,就要通过手写汇编来优化对软件性能起到决定作用的关键程序。手工编写汇编代码,可直接控制高级语言编程时不能有效使用的3个优化手段:条件执行、指令调整和寄存器分配[1]。本文基于ARM9指令架构的特点,应用上述优化手段,对决定系统性能的关键程序的汇编代码做二次优化。
1 ARM处理器结构
ARM采用RISC(Reduced Instruction Set Computer)指令结构,使用简单高效的指令,并通过简单指令组合来完成不常用的复杂功能。因此在ARM上实现特殊功能时,效率可能较低,但可利用流水线技术和超标量技术加以改进和弥补。ARM架构对存储器操作有限制,使得控制简单化[2-3]。
2 ARM9架构相关优化
ARM处理器指令具备条件执行的特征,利于取代比较指令优化分支结构和循环结构。ARM寄存器数量众多,结合多寄存器装载或存储的LDM和STM指令,易于实现循环展开优化。
近年来,嵌入式微处理器的代码优化得到广泛研究。Simunic等人[4]将代码优化分成算法优化、数据优化和指令流优化3类。kis Kaspersky[5]使用VC++6.0、BorlandC++5.0和WatcomC10.0的3种流行编译器分析优化内容,对比代码质量。Rainer Leupers[6]分析了大量嵌入式微处理器相关的优化方法、优化算法和优化工具。研究了寄存器分配、指令调度、代码选择、条件执行、函数内联等各种优化手段的优缺点。David A Ortiz和Nayda G等人[7]研究了编译器优化,指令级优化和源代码级优化对嵌入式系统的性能影响。刘露、李小进等人[8]通过研究处理器功耗与代码优化的关系,验证代码优化能影响cache命中率从而改善硬件功耗。王荣胜等[9]研究了基于ARM编译器的优化策略,并通过软硬件的综合测试来验证包括循环优化,指令归并优化,延迟分支等各项优化策略的效果。江毛进、陆鑫达等人[10]讨论了循环优化的目标和循环优化的各种程序变换方法。本文提出多层嵌套循环计数值组合、循环处理数据合并和循环最优展开等优化方法。
2.1循环计数值组合
多层嵌套循环需要多个循环计数器。对于ARM架构,一个计数器可满足循环计数低于32位的循环体。实际应用中,循环计数一般<32位,则可将多个循环计数值组合放在一个寄存器中,最内层的循环计数值放在寄存器的最高位,依次类推。组合方式可依据总的循环次数和循环嵌套层数来决定。以矩阵乘法程序为例,程序流程图如图1所示。
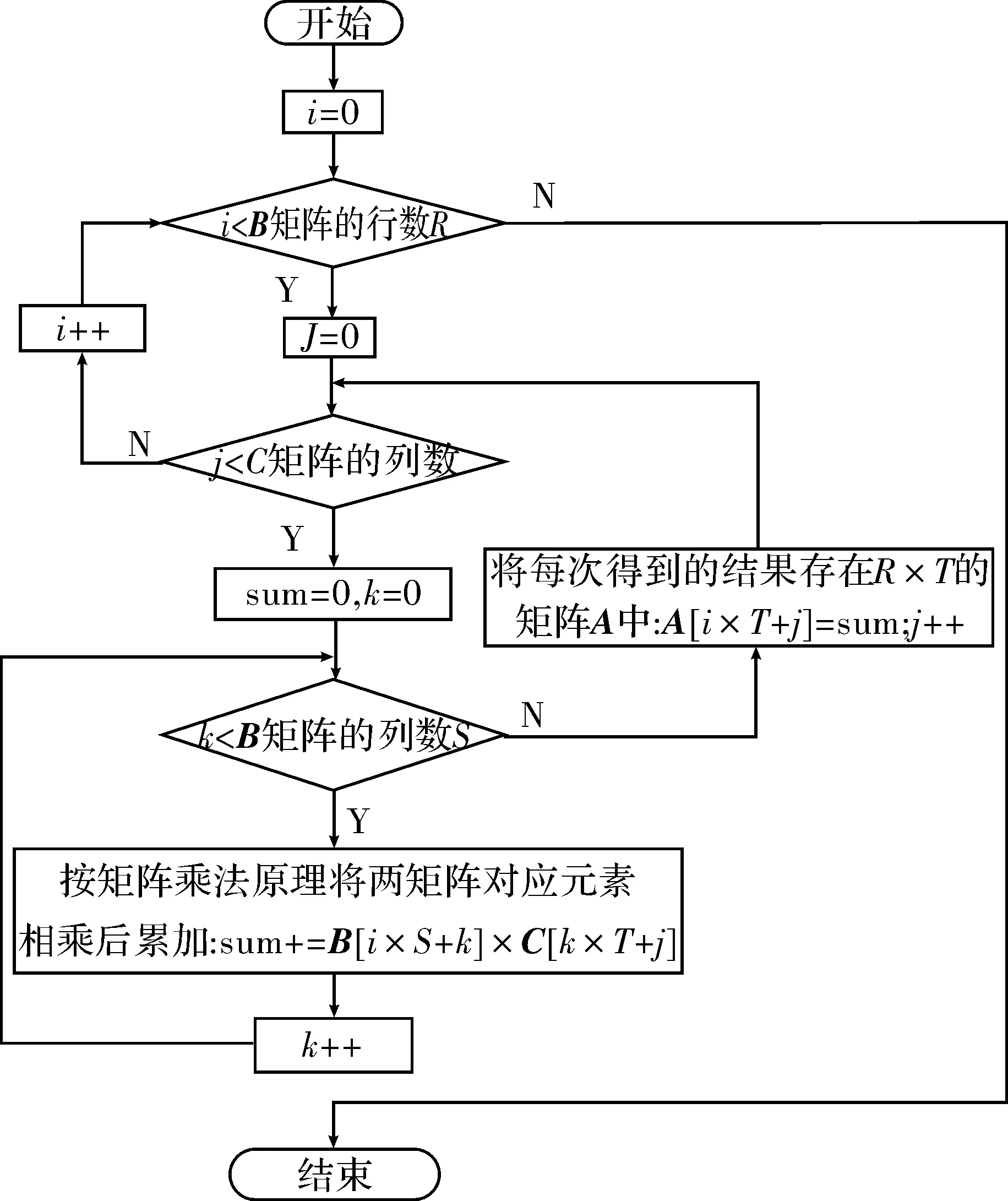
图1 矩阵乘法程序主流程
以上代码经ARM-Linux-gcc3.4.5编译后的代码的主要部分如下
.L6:ldrr3, [fp, #-28] //取i
bhi.L5
.L9: ldrr3, [fp, #-32]//取j
bhi.L8
.L12: ldrr3, [fp, #-36]//取k
bhi.L13
上述程序中3层循环的3个计数变量全都存储在内存中,这样严重影响了程序的性能。但若将3个变量全部存储在寄存器中这样又增加了寄存器使用数量。因此,对程序进行循环计数值合并到寄存器的优化。取1个寄存器r3,最低8位放最外层循环计数变量,第2个8位放中间层循环计数值,第3个8位放最内层循环计数值。同时利用条件执行来取代比较指令。优化后的程序如下
.LPI:add r3, r3, #39<<8;移位使用变量
.LPJ:add r3, r3, #39<<16;循环计数值合并
.LPK:ldr r5, [r1], #4
Ldr r6, [r2], #4*40
subsr3, r3, #(1<<16) ; 移位使用变量
mlar4,r5,r6,r4
bpl.LPK
…
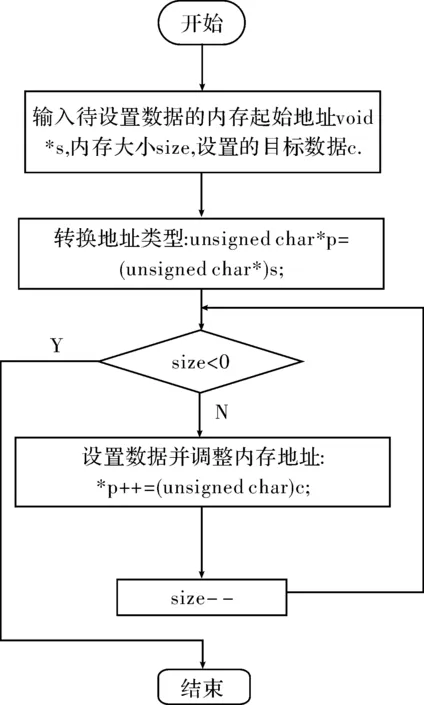
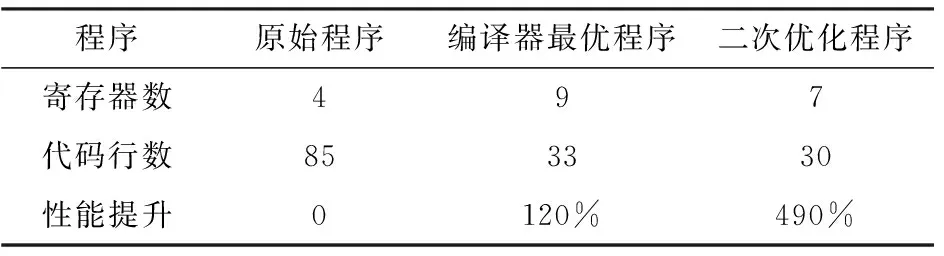
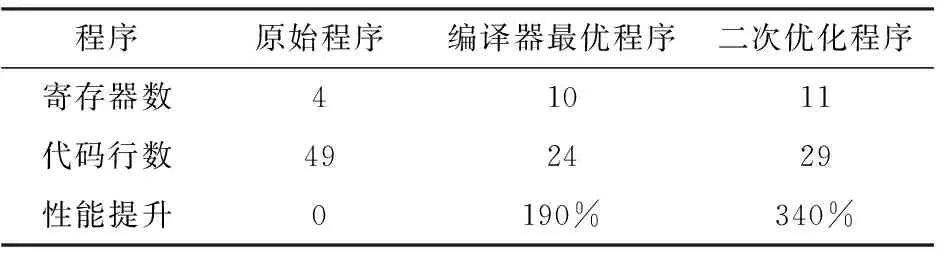
subplr1,r1,#4*40;j bpl.LPJ bpl.LPI 上述程序首先对r3的16~23位进行减1运算,直到结果为负便完成最内层循环计数。接着用加 来清除位16-31。然后对r3的位8~15减28来完成中间层循环计数。最外层循环也采用相同的处理方法。由此既节省了寄存器资源,又发挥了ARM加减指令处理宽范围常数的能力,ARM桶形寄存器的移位处理能力和ARM指令条件执行的优势。 理论上,当循环程序循环次数不超过32位,则不论循环嵌套多少层,均可将循环的计数值移位组合到一个寄存器中。单个寄存器组合一般情形:设循环嵌套层数为n,循环由外向内每层循环次数分别为 (i=1,2,3,…,n)。则有 (1) 设每个Xi(i=1,2,3,…,n)的二进制位数分别为Bi(i=1,2,3,…,n)。则有 (2) 再结合循环结束条件控制循环跳转与计数值重装即可完成循环控制。 2.2循环处理数据合并 ARM在处理<32位长度的变量(字节数据,双字节数据等)时,可将多个数据存放在单个32位寄存器中,即可减少代码尺寸,又能改善性能。以图像合并程序为例,程序流程如图2所示。 图2 图像合并程序主流程图 以上程序经ARM-Linux-gcc3.4.5编译后的代码的主要部分如下 ldrr2, [fp, #-16] ldrr3, [fp, #-32] ldrbr1, [fp, #-33] ldrr2, [fp, #-20] ldrr3, [fp, #-32] ldrbr3, [r3, #0] ldrbr3, [fp, #-33] ldrr2, [fp, #-24] ldrr3, [fp, #-32] ldrbr3, [r3, #0] mulr3, r1, r3 … 上述程序中,处理1 Byte的数据全部采用32位寄存器。且每个字节的处理均有多次内存操作。不仅浪费寄存器资源,同时频繁访问内存影响程序性能。因此可将4 Byte数据一次合并到一个寄存器中,通过移位的方式来进行单字节的处理。经二次优化后的主要代码如下 .merge_loop: ldrr4,[r1],#4;一次取4 Byte ldrr5,[r2],#4 addr6,r6,r7,LSL#8;移位处理单个字节 andr8,r14,r6,LSR#8; andr6,r14,r4,LSR#8; andr7,r14,r5,LSR#8; addr6,r6,r7,LSL#8 andr6,r14,r6,LSR#8 bgt.merge_loop ARM处理器中采用SIMD向量扩展作为计算加速部件,利用128或256位的SIMD寄存器对多个字符型、整型、浮点型数据同时进行相同操作,实现一种细粒度的数据级并行[11]。将4 Byte存放在一个寄存器中,使一次循环能处理多个数据。充分利用寄存器资源以及ARM桶形寄存器对移位所提供的硬件支持,使程序运行在性能最优化状态。 2.3循环最优展开 通过多次执行循环内部语句来展开循环,可减小循环开销。但当循环计数值不是展开次数的倍数或循环计数值比展开次数小时,需要对循环展开做一些特殊处理。实际情况中,循环展开次数与剩余循环的处理,循环体变量个数以及处理器能提供寄存器数量均有关[12]。当上述情况不存在时,循环展开多少次对性能提升最优也需要有一定理论依据。本文基于ARM指令的周期数及其所处理的数据格式特点为依据,以最佳次数展开循环,使得关键程序性能提升最大化。以内存设置程序为例,程序流程图如图3所示。 图3 内存设置程序主流程图 该代码经过ARM-Linux-gcc3.4.5编译后的代码的主要部分如下 .L16: ldrr3, [fp, #-24] cmpr3, #0;n>0 beq.L17 … str r2, [r0, #0]; *p++ =(unsigned char) c; … b.L16 .L17:;end 为提高效率,需使用STR或STM指令一次写入多个字节。因此,首先需对齐数组指针s边界。但只有当循环次数n足够大时,对齐才有意义。因此,设足够大的循环次数为N1,在n≥N1时,对齐数组指针s边界。且N1必须≥3,否则数据不足4 Byte,也就无所谓字边界对齐问题。 对齐处理后,一次循环使用4条批量存储指令,每条指令写8个字,这样每次可操作128 Byte存储单元。但只有在n≥N2≥128的前提下才值得这样做,此处N2为上限值。最后,还剩下n≤N2个字节要设置。但STR指令一次存储4 Byte,当n<4时,再使用STRB指令单字节操作剩余的字节单元。上述过程优化后的代码如下 .ALIGNED:;内存对齐 .LOOP128:;循环展开 STMIA R0!,{R1,R3-R8,R12} STMIA R0!,{R1,R3-R8,R12} STMIA R0!,{R1,R3-R8,R12} STMIA R0!,{R1,R3-R8,R12} … LDMFD sp!,{R4-R8} .MEMSET_4BT: SUBSR2,R2,#4 .LOOP4: STRGER1,[R0],#4 BGE.LOOP4 ADDR2,R2,#4 .MEMSET_1BT: SUBSR2,R2,#1 .LOOP1:STRGEB R1,[R0],#1 SUBGES R2,R2,#1 BGE.LOOP1 上述算法中以128Byte,4Byte和1Byte的形式进行,则按块分解循环次数n可表示为n=128n128+4n4+n1,0≤n4<32,0≤n1<4。则有以下3种情形,如表1所示。 (1) 0≤n (2)N1≤n (3)N2≤n时,与(2)中类似,总周期数为5(n4+z4+n1+z1)+32,列表如表1所示。 表1 n值与周期数的关系表 比较上表可知:当n4≥1时,第2行值小于第一行,除非n4=1或n4=0。设置N1为5,从第1行和第2行来选择最佳的周期。只要当n128≥1时,第2行的值就小于第2行的值。因此取N2为128。综上所述,在循环展开的过程中,可根据处理器指令周期特点以及程序处理数据的特征,列出与展开相关的指令周期多项式。根据多项式系数特征确定最优展开次数。 3.1实验环境 本文通过硬件实验验证优化方法的有效性。实验环境如下:硬件平台:精致2440开发板;处理器: S3C2440;内核:ARM920T;操作系统内核版本:Linux 2.6.22.6;编译工具:ARM-Linux-gcc-3.4.5。 3.2实验过程 取3组经典程序,矩阵乘法程序,图像合并程序和内存设置程序。将其编译成两种汇编程序,即原始程序和编译器最优程序。将原始程序进行二次优化得到二次优化程序。将其分别运行在目标平台上。统计1 000次实验数据,利用Matlab7.0获得性能直方图,通过对比分析验证优化手段的有效性。 3.3实验结果分析 3个程序运行平均时间如图4所示,寄存器使用数量、代码行数以及性能对比如表2~表4所示。 图4 程序运行平均时间图 程序原始程序编译器最优程序二次优化程序寄存器数497代码行数853330性能提升0120%490% 表3 图像合并程序性能指标统计表 表4 内存设置程序性能指标统计表 上述实验数据表明,3个经典程序经二次优化后,性能均优于原始程序和编译器最优程序。矩阵乘法程序和图像合并程序的代码也得到了精简,利于节省内存空间;寄存器使用方面,矩阵乘法程序利用循环计数值合并优化,利于节省寄存器资源;而图像合并程序和内存设置程序以牺牲寄存器资源换取程序性能的大幅提升。 本文提到的3种优化方法中,循环计数值的组合应用灵活,各种架构均可参考应用。但对于循环计数值超过32位时,如何应用多个寄存器进行组合并改善性能还有待研究。而循环的最优展开次数需根据处理器架构和程序的特点来确定,且需要列出指令周期多项式,过程较为繁琐,实际应用中可根据性能要求取舍。循环处理数据合并适用于图像和字符处理,内存对齐虽增加一定开销,但数据量较大时实用性较强。 [1]Andrew N Sloss,Dominic Symes,Chris Wright.ARM system developer’s guide designing and optimizing system software[M].沈建华,译.北京:北京航空航天大学出版社,2005. [2]三恒星科技.ARM9原理与应用设计[M].北京:电子工业出版社,2008. [3]Advanced RISC Machines Co.,Ltd. ARM920T system-on-chip platform OS processor[M].UK:Advanced RISC Machines Co.,Ltd,2001. [4]Simunic T,Benini L,G de Micheli. Energy-efficient design of battery-powered embedded systems[J].IEEE Transactions on Very Large Scale Integration Systems,2001,9(1):15-28. [5]Kris Kaspersky.Code optimization effective memory usage[M].谭金明,译.北京:电子工业出版社,2004. [6]Leupers R.Code optimization techniques for embedded processors[M].America:Kluwer Academic Publishers,2000. [7]David A Ortiz,Nayda G.Santiago impact of source code optimizations on power consumption of embedded systems[C].Mantreal: Joint 6th International IEEE Northeast Workshop on Circuits and Systems and TAISA Conference,2008. [8]刘露,李小进,张宏,等.基于访存特性的嵌入式移动设备软件低功耗优化方法[J].计算机应用研究,2014,31(11):3392-3396. [9]王荣胜.基于ARM的编译器选优技术研究与实现[D].长沙:国防科学技术大学,2007. [10]江毛进,陆鑫达,陈杰.编译中的循环优化[J].上海交通大学学报,1996,30(6):20-27. [11]侯永生,赵荣彩,黄磊,等.面向SIMD扩展部件的循环优化研究[J].计算机科学,2014,41(5):27-32. [12]周海亮,高军,张民选.一种基于流处理器的多重循环优化技术[C].北京:全国高性能计算学术会议,2006. Compiler Optimizations Based on ARM9 Architecture GE Wuchao, ZHOU Yimin (School of Optical-Electrical and Computer Engineering, University of Shanghai for Science and Technology,Shanghai 200093, China) Software developing in Embedded systems lacks the process of peephole optimization when using the GCC compiler, thus a poorer performance of the compiled code than that by the ARM compiler. This paper proposes a combination of cycle counter, consolidating data of cyclic process and cycle expansion optimally to optimize assembly code on the ARM9 processor, which are verified by running matrix multiplication, image merging and memory settings programs, respectively, on the ARM9 platform. Experimental data show that above mentioned methods reduce the number of register counts by 50% on average while nearly doubling the performance compared with the GCC compiled code. peephole optimization; combination of cycle counter; consolidating data of cyclic process; cycle expansion optimally 2015- 12- 10 葛吴超(1989-),男,硕士研究生。研究方向:嵌入式系统。周亦敏(1962-),男,副教授。研究方向:嵌入式系统。 10.16180/j.cnki.issn1007-7820.2016.09.029 TP316.2 A 1007-7820(2016)09-106-05

3 实验


4 结束语
