基于编辑距离和相似度改进的汉字字符串匹配
2016-10-17邵清,叶琨
邵 清,叶 琨
(上海理工大学 光电信息与计算机工程学院,上海 200093)
基于编辑距离和相似度改进的汉字字符串匹配
邵清,叶琨
(上海理工大学 光电信息与计算机工程学院,上海 200093)
为解决中文字符串匹配精度较低的问题,提出了一种基于编辑距离和相似度改进的汉字字符串近似匹配算法,针对汉字字符串特点,使用汉字拼音和五笔编码计算;通过改进动态规划算法,能够有效提高编辑距离的计算准确度以及执行效率;再引入考虑交换问题的归一化算法,以语义编辑距离与长句长度的比值作为归一化结果,以此来提高近似匹配算法的准确度。实验结果表明,改进后算法计算的相似度质量要优于改进前的算法结果,且对提高算法效率和查全率、查准率和时间性能等指标均有明显改善,证明该算法的可行性和有效性。
编辑距离;相似度;归一化;中文字符串;近似匹配
随着信息技术的广泛应用,作为基础性研究的字符串匹配面对越来越多的挑战[1]。从20世纪70年代开始,字符串匹配问题的研究[2]就得到许多学者的关注,并且研究成果已广泛应用于生物、医学、犯罪取证等领域。目前,计算字符串相似度的算法有多种,其中编辑距离算法作为常用的字符串相似度求解算法,具有应用广泛、查找有效和时间复杂度较低等优势。文献[3]将整条记录看作一个字符串,计算两个字符串的编辑距离,从而判断两条记录的相似匹配程度,但是由于字符串长短不一,可能存在冗余属性对;文献[4]提出了基于汉语拼音改进的编辑距离算法,把汉语拼音按照音调、声母和韵母3方面分类,分别计算编辑距离,但在计算时使用的传统动态规划算法没有考虑形近字会造成相似度较大的情况,所以,该算法并不具有较高的执行效率。文献[5~6]将字符串分解成中文字符和英文字符两部分,计算各自的编辑距离,提高了处理效率。不足之处在于,中文的编辑需要依赖输入法,是由多个字母按键组合而成,因此,假定任意两个中文字符串的差别为同一个值并不代表中文字符串间的实际距离,在求解编辑距离时,没有考虑可能存在的交换问题,可能导致错误结论。
针对以上文献的不足之处,本文提出的算法,主要针对编辑距离改进和汉字字符串相似度匹配进行,首先在预处理阶段对数据进行标准化处理,消除数据中的冗余属性对;其次改进动态规划算法,能够有效提高编辑距离的计算准确度以及执行效率;接着考虑可能存在的交换问题,对编辑距离进行归一化处理。该算法综合考虑了汉字字符串的特点,适用于汉字字符串,既能提高字符串近似匹配的精度,还能提高算法的执行效率。
基于字符串近似匹配算法的研究已较为成熟,但已有的解决方案中,字符串的近似匹配主要针对英文字符串,这些方法在汉字字符串匹配上难以取得同样好的效果[7]。因此需要对经典算法进行改进,设计出能有效识别汉字字符串的算法。本文将从以下几个角度展开研究:
(1)数据标准化。这个阶段是模糊匹配过程中一个关键阶段。由于模糊匹配的前提之一是数据源中的数据具有完全相同的模式[8]。但实际上,对于不同的数据源,由于开发人员的习惯、建立数据源的初衷等差异,使得这个前提基于不存在,因此需要在预处理阶段对数据进行标准化处理[9];(2)中文字符串识别。实体识别是找到那些指向相同实体的数据对象[10]。当把实体识别应用到具体数据时,最关键的操作是实体数据对象的匹配。实体数据对象匹配是指判断两个数据对象是否指向同一真实世界的实体,如当两家商店合并以后,需要合并所有百货资料,可是有些百货可能分别存在于原来的两个数据源中,且它们还可能有不同的数据表现形式[11]。传统的字符串精确匹配算法无法跟上信息和技术的迅速发展,国外学者开始对近似匹配算法展开研究,已取得了较大进展。随着近年来网络的迅速普及以及中文检索等要求的提高[12],我国逐步展开对中文字符串近似匹配的研究。已有的识别算法中,主要考虑英文字符串的相似性比较[13],但是因为中文字符串的特点与英文比较有较大差异,适用于英文字符串的算法可能不适用于中文,因此寻找中文字符串合适的近似匹配算法的需求迫在眉睫。本文将致力于探究中文字符串适用的近似匹配算法;(3)编辑距离改进。计算字符串相似度的现有算法中,以基于编辑距离的计算方法为主。虽然编辑距离算法在数据清理、拼写错误检测方面具有一定的优势[14],在删除错误方面也具有较高的精度,但仍存在一些问题。本文将针对编辑距离进行改进,以提高算法准确度;(4)相似度改进。本文主要从相似度的改进这个方面来提高算法效率。因为相似度算法的效率往往会直接影响到整个模糊匹配的算法结果和效率,故相似度的计算是关键。
1 基于编辑距离和相似度改进的匹配算法
1.1数据预处理
该处理主要包含4个步骤:(1)使对象具有唯一性,本文算法需要将对象的唯一标识插入属性结点表,并通过这一标识来检索对象;(2)将属性名统一,本文算法需要通过相应属性上的属性结点表来定位实体对象;(3)消除冗余的属性对。冗余的属性对对实体的描述价值可以由其中之一替代,为了提高效率,需要消除冗余的属性对;(4)使所有对象结点处于同一层上。
经过以上几步预处理,数据中的对象具备了标识唯一性和属性统一性,消除了冗余属性对,且属性都处于同一层。
1.2中文字符串识别
根据汉字音、形的特点,本文算法将利用汉字可分解的特征,采用拼音编码和五笔字型编码,将汉字通过算法得到对应的编码,汉字字符编码示例如表1所示。
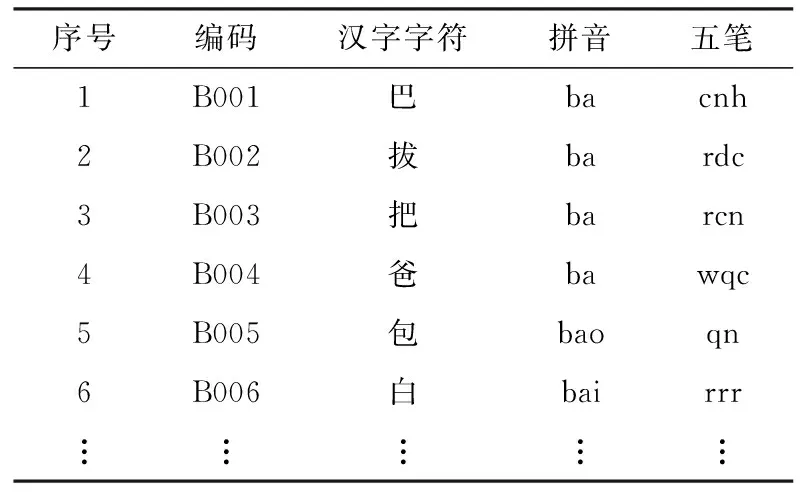
表1 汉字字符编码示例表
如表1所示,通过比较汉字的编码就可以获得单个汉字字符间的相似度,记为[15],然后结合单个汉字字符相似度的和以及编辑距离的值得出两个字符串的相似度。
1.3编辑距离计算
编辑距离[16]是指从源字符串S到目标字符串T的最小编辑操作次数,目的是计算S与T的相似度。主要的编辑操作包括对字符串的字符进行插入、替换等。即把字符串x与字符串y之间的互相转换所需的最少操作次数记为编辑距离ed(x,y)。
例如:将“今天是个好天气”转换成“今天天气好”,至少需4次编辑操作:删除字符“是”;删除字符“个”;删除字符“好”;在字符“气”后插入字符“好”。所以,“今天是个好天气”转换成“今天天气好”的编辑距离为4,此过程如图1所示。由图1可知,编辑距离ed(x,y)=4。
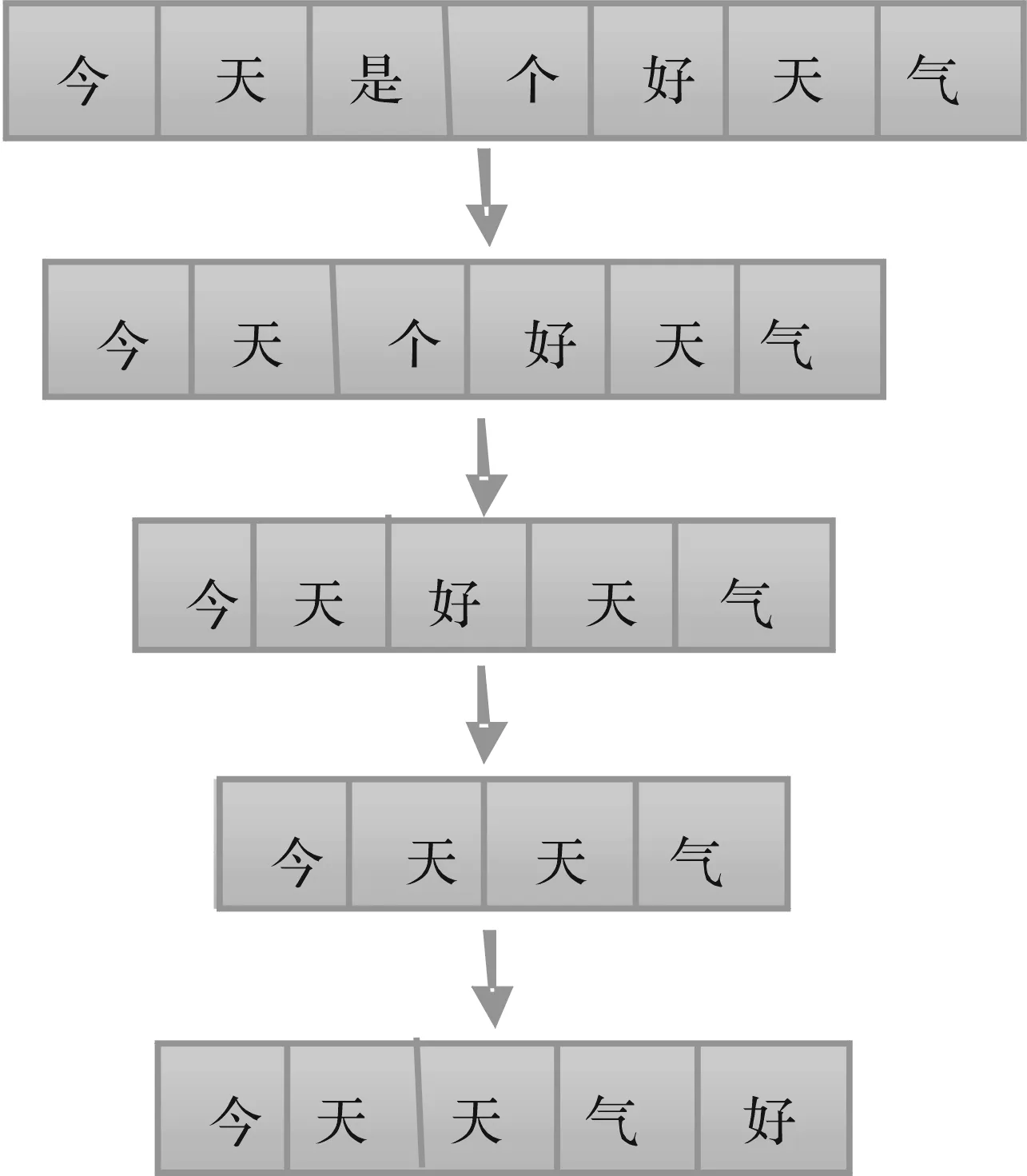
图1 编辑距离求解过程
求两个字符串之间编辑距离最为普遍的方法是动态规划算法[17]。算法中包含删除、插入、替换3种操作。该算法从字符串的左边第一位字符开始,依次进行比较,然后记录已经比较过的编辑距离的数值,最后得到下一个字符位置时的编辑距离。多数情况下,该算法可以有效计算字符串间的相似度。但是执行效率不高,如在使用上式计算中文的某些表达方式时, 可能得出错误的结果。例如两个字符串:“老师你好”和“你好老师”,利用上式计算得出,这两个字符串的编辑距离为4,相似度为0。而实际上,这两个字符串表达的意思相同。所以,在这种情况下,传统的动态规划算法将不再适用,需要进一步改进。
本文提出的改进算法通过考虑在删除、插入、替换等操作中的操作代价,对传统的动态规划算法进行优化,改进后的动态规划算法,主要步骤如下:
(1)构造|x|+1行,|y|+1列的矩阵D[|x|+1,|y|+1],其中,字符串x和y的长度分别用|x|和|y|来表示;
(2)矩阵元素D[i,j]就表示ed(x1i,y1j),即为上文提到的编辑距离。同理可知,矩阵右下角元素D[|x|+1,|y|+1]的含义就是ed(x,y);
(3)矩阵D的值通过如下公式计算,其中所需要的最少操作次数
Di,0=Di-1,0+1
D0,j=D0,j-1+1
如果xi=yi,
Di,j=Di=1,j-1
(1)
如果xi≠yi,则
Di,j=min(Di-1,j-1+cost(x,y),Di-1,j+1,Di,j-1+1)+1
(2)
其中,cost(x,y)表示操作代价,且当xi≠yi时,cost(x,y)=0。
实验表明,虽然改进算法在提高结果准确度的同时,也增加了时间复杂度,但是在能提高效率的前提下,增加时间复杂度的代价也是可以被接受的。
1.4相似度计算
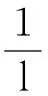
(3)
通常情况下,编辑距离与相似度成反比。所以,不能简单地用编辑距离来反映相似度。例如,凭感觉,两个长度为2、编辑距离为1的字符串的相似度,要低于长度为9、编辑距离为2的相似度,实则不然。因此,为了得出准确的相似度,对编辑距离进行归一化[20]处理是必要的。常用的归一化方法如下
(4)
两个中文字符串P=“上海理工大学光电学院”和Q=“光电信息”以词语作为编辑单元计算编辑距离,有k=8,m=10,n=4。
按照式(6)的归一化,有
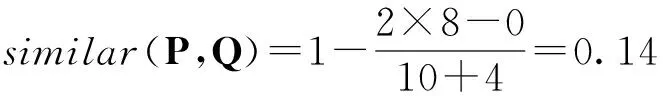
计算得到结果是负数,与常理不符。这是因为该算法时空复杂度较高,而且忽略了交换问题带来的影响,本文以语义编辑距离与长句长度的比值作为归一化结果,更加简单实用,得到计算字符串P与Q相似度的公式如下
(5)
式 (7) 中,在插入和删除代价均≤1的情况下,有0≤k≤l,所以0≤similar(P,Q)≤1。由此可得出,similar(P,Q)的值越大,表示P与Q越相似。
1.5匹配算法的实现
以下是匹配算法的主要流程:
(1)输入两个字符串P、Q;
(2)判断P、Q是否等值,若相等跳转到步骤(4),否则跳转到步骤(3);
(3)得到n=length(P)和m=length(Q),首先判断n与m的值,若n=0,则ed(P,Q)=m;若m=0则ed(P,Q)=n;若n=m,则跳转到步骤(4);否则跳转到步骤(5);
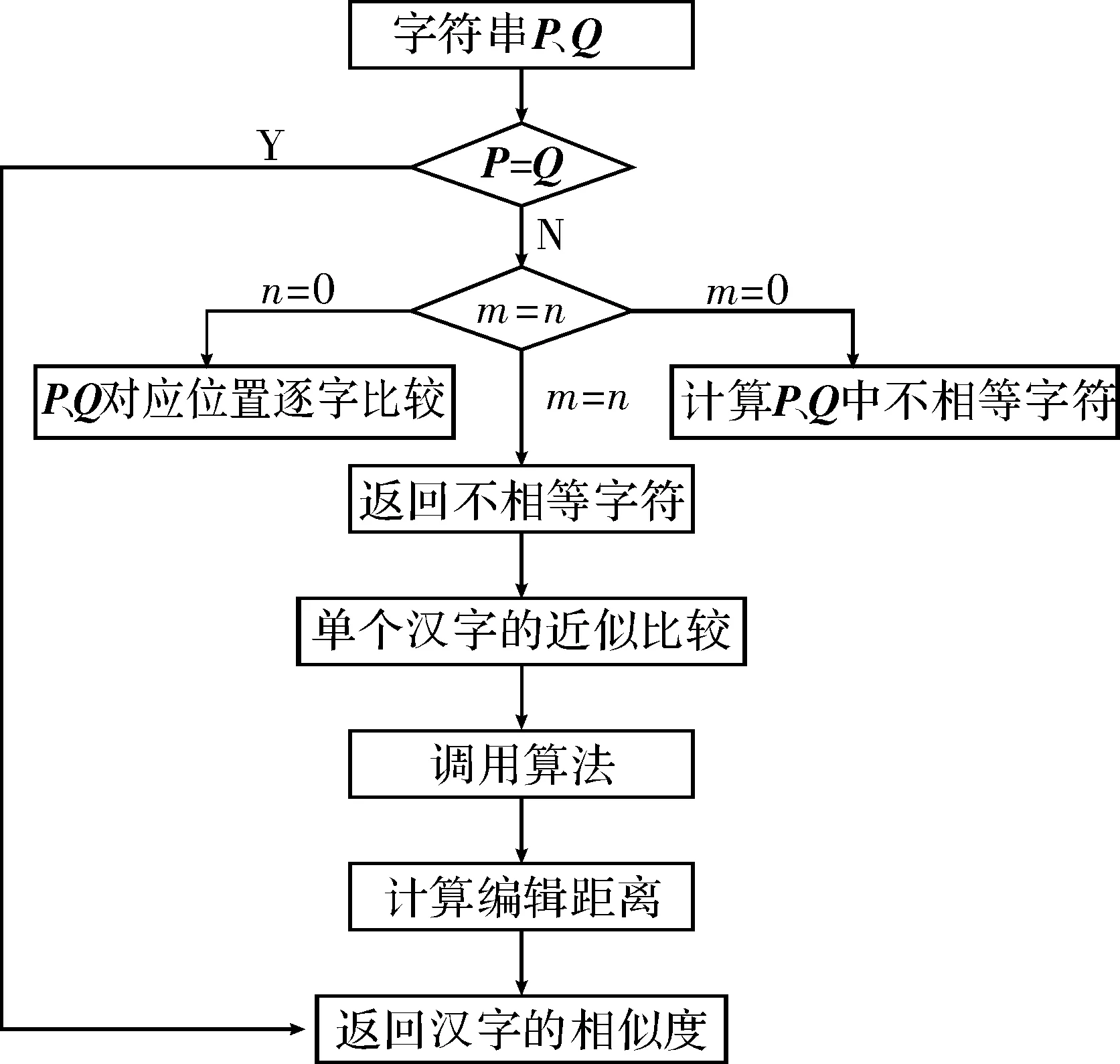
图2 匹配算法流程图
(4)令i=1,并从位置i开始逐字扫描,步长以1递增,直至最后一个字符;得出λ(i);
(5)使用改进的动态规划算法计算编辑距离根据行列对应值找出所有不匹配的字符;
(6) 计算两个字符串的相似度。
匹配算法流程如图2所示。
2 实验结果与分析
在安装有Delphi2007的Windows7测试环境下,实现基于编辑距离和相似度改进的汉字字符串匹配,并把实验结果与传统的动态规划算法和传统的相似度计算方法进行比较,选取不同的几对中文词语进行实验,一共8组词语,词长范围为2~3,包含形近字和音近字。实验结果如表2所示。
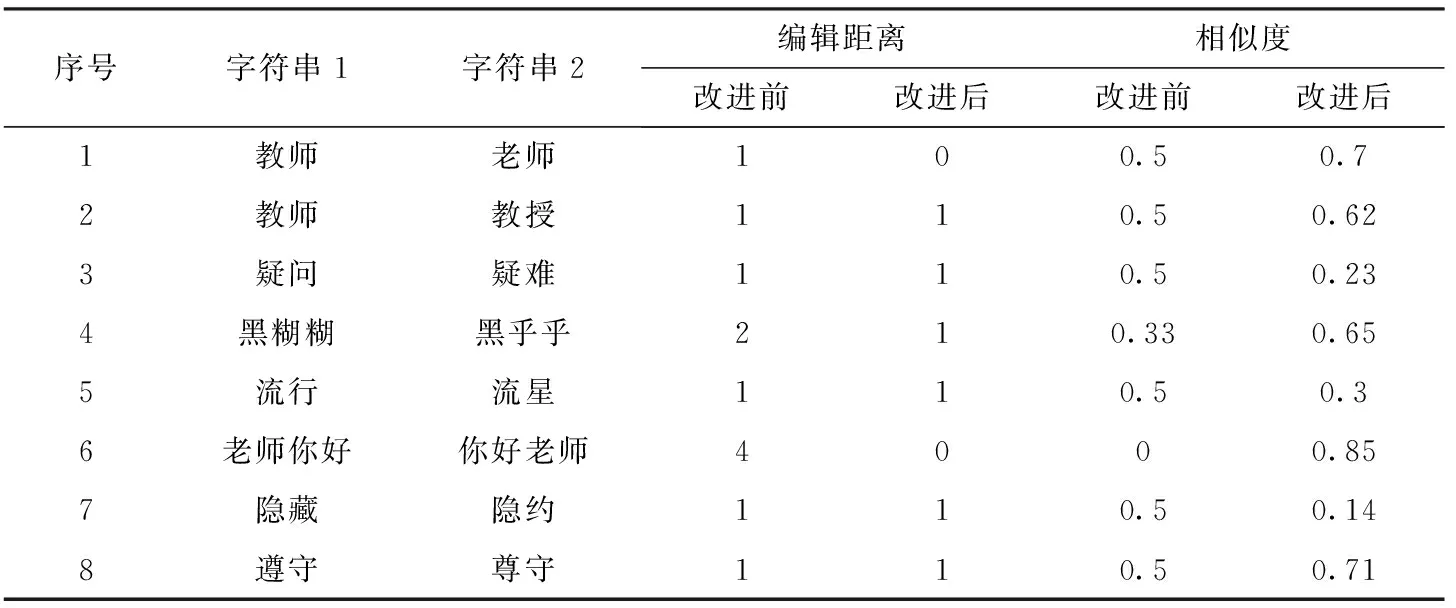
表2 编辑距离和相似度比较表
上述实验字符串中,既包含了同音、近音词的情况,也有形近字和同义词的情况。从相似度的计算结果看,改进后算法计算的相似度质量要优于旧算法的结果,也证明了该改进算法的可行性和有效性。
实验结果也表明,改进后的算法,在算法效率、查全率、查准率和时间性能等指标上均有明显改善。
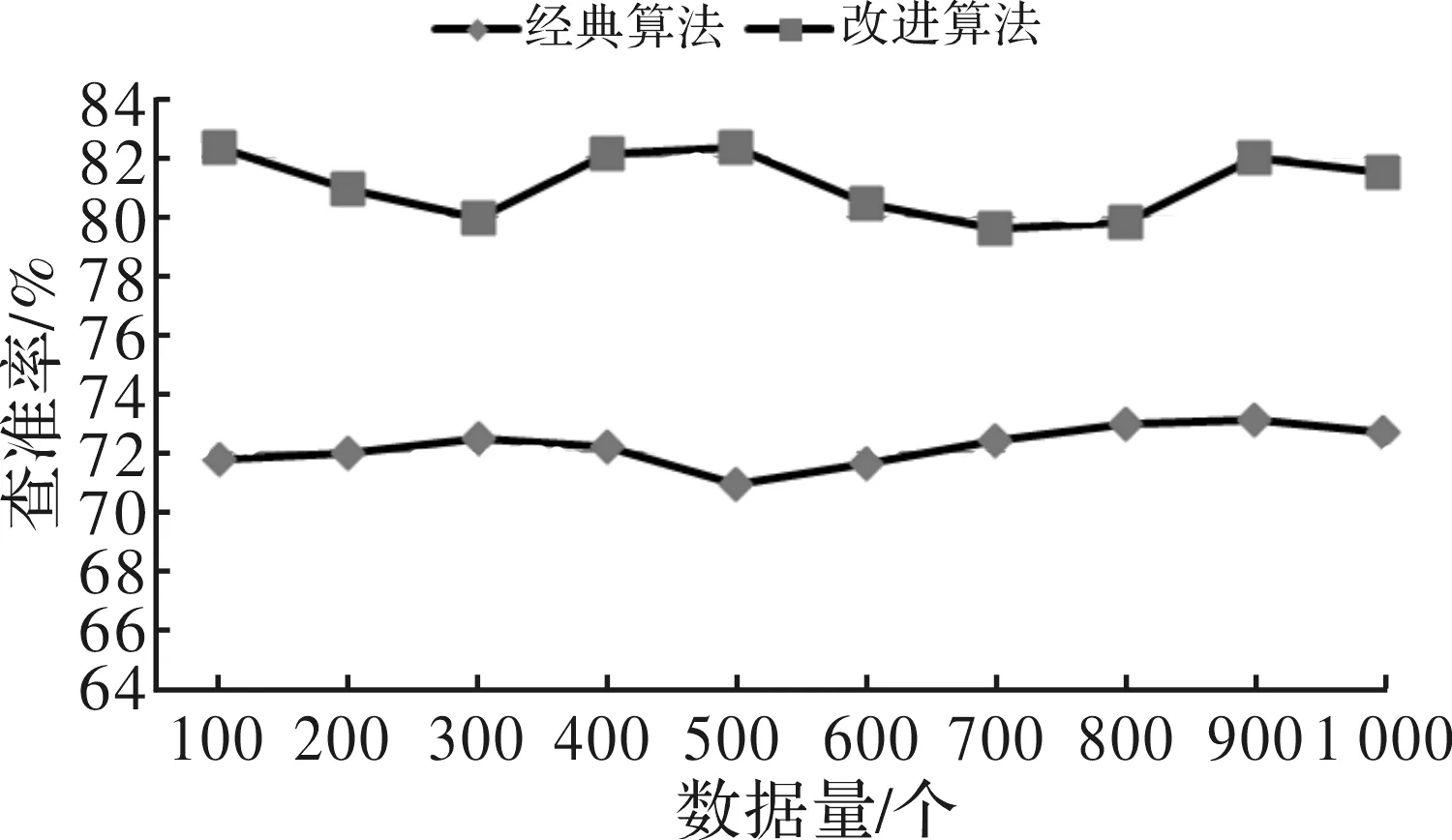
图3 各数据规模下的查准率
查准率=查出的相似的数据个数/算法检索到的数据格式。
由图3的实验结果可看出,改进后的算法在数据规模一致的前提下,查准率则由72.7%提升到81.5%。
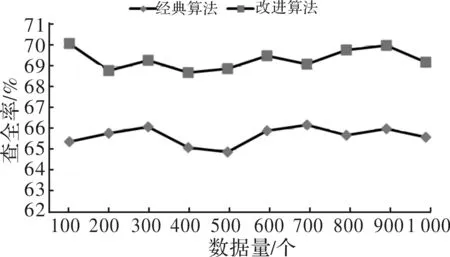
图4 各数据规模下的查全率
查全率=查到的相似的数据个数/系统中实际相似的数据个数。
由图4的实验结果可以看出,改进后的算法在数据规模一致的前提下,查全率由65.6%提升到69.2%。
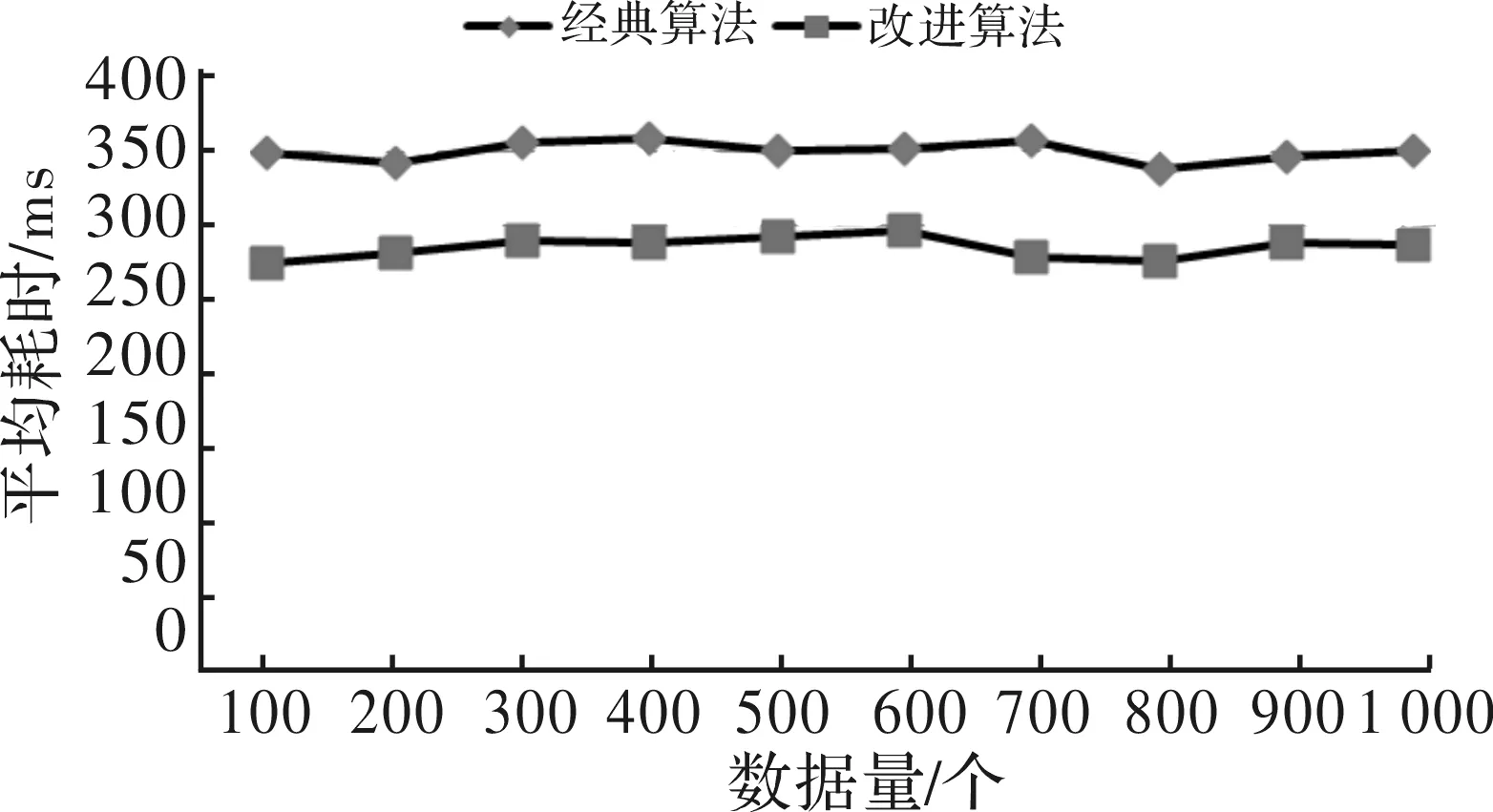
图5 各数据规模下的平均耗时
由图5的实验结果可看出,改进后的算法在数据规模一致的前提下,平均耗时由351ms降低到290ms。
从实验获得的结果来看,可以得出结论:改进后的算法在数据规模一致的前提下,查全率、查准率和时间性能均有提高,证明了改进算法的可行性和有效性。
3 结束语
本文针对传统近似匹配算法中,编辑距离计算时仅考虑英文字符串,并在计算相似度时未考虑交换的归一化等问题,提出了一种基于改进编辑距离和相似度的汉字字符串的近似匹配算法,通过改进的编辑距离算法提高识别准确度,使近似匹配算法更有实际应用的意义;同时在实验中给出相似度比较的实验结果,用3个评价指标验证算法的准确度。实验结果表明,与传统算法相比,改进后的算法在查准率、查全率和平均耗时方面都具有明显优势,提高了推荐算法的性能。
字符串近似匹配在语言识别、文件检索、模式识别等许多领域应用广泛,但由于语言中大量同义词、多义词的存在,导致了在词形上存在对应关系的不同实体不等于语义上也存在对应关系,因此,仅根据字符串模糊匹配的方法所获得的匹配结果是不够理想的,还应综合考虑这些实体的其他相关属性,这也将是下一步的研究方向。
[1]刘显敏,李建中.实体识别问题的相关研究[J].智能计算机与应用,2013,3(2):1-5,10.
[2]强宝华.异构数据库语义集成技术研究[D]. 重庆:重庆大学, 2005.
[3]LiangJin,ChenLi,MehrotraS.Efficientrecordlinkageinlargedatasets[C].Korea:Proceedingofthe8thInternationalConferenceonDatabaseSystemforAdvancedApplication,2003.
[4]俞荣华,田增平,周傲英.一种检测多语言文本相似重复记录的综合方法[J].计算机科学, 2002,29(1):118-121.
[5]曹犟,邬晓钧,夏云庆,等. 基于拼音索引的中文模糊匹配算法[J]. 清华大学学报:自然科学版,2009,49(S1):1328-1332.
[6]杜艾永,李立顺,朱愿,等.基于汉字机内编码的中文相似重复记录消除研究[J].电脑知识与技术,2009,5(29):8314-8316.
[7]李钝,曹元大,万月亮.信息安全中的变形关键词的识别[J].计算机工程,2007,33(21): 155-156,159.
[8]VernicaR,CareyMJ,LiC.Efficientparallelset-similarityjoinsusingmapreduce[J].ProceedingofSIGMOD,2010,3(1):218-229.
[9]Mongeae,Elkancp.Thefieldmatchingproblem:Algorithmandapplications[EB/OL]. (2008-06-16)[2015-01-11]http://www.cecs.csulb.edu/~monge/Papers/kdd96.ps.
[10]ElmagarmidAK,IpeirotisPG,VerykiosVS.Duplicaterecorddetection:asurvey[J].IEEETransactionsonKnowledgeandDataEngineering, 2007, 19(1): 1-16.
[11]周建芳,徐海银,卢正鼎.信息集成中的实体识别解决方案[J].小型微型计算机系统,2009, 30(9):1774-1780.
[12]车万翔,刘挺,秦兵,等.基于改进编辑距离的中文相似句子检索[J]. 高技术通讯,2004(7):15-19.
[13]范立新.改进的中文近似字符串匹配算法[J].计算机工程与应用,2006,2(1):22-24.
[14]赵作鹏,尹志民,王潜平,等.一种改进的编辑距离算法及其在数据处理中的应用[J].计算机应用, 2009,23(12):96-98.
[15]王静婷.基于汉字聚类特征的中文字符串相似度计算研究[J].现代图书情报技术,2011(2):48-53.
[16]LevenshteinVI.Binarycodescapableofcorrectingdeletions,insertionsandreversals[J].ProblemsofInformationTransmission, 1965,1(1): 8-17.
[17]于志恒.基于笔形相似的文本校对算法及其接口原型系统的研究[D]. 沈阳:东北师范大学,2007.
[18]刁兴春,谭明超,曹建军.一种融合多种编辑距离的字符串相似度计算方法[J].计算机应用研究,2010,27(12):4523-4525.
[19]ChristenP,ChurchesT,HeglandM.Febrl-Aparallelopensourcedatalinkagesystem[M].Berlin:SpringerHeidelberg, 2004.
[20]张仰森.中文校对系统中纠错知识库的构造及纠错建议的产生算法[J].中文信息学报, 2001,12(1):41-44,40.
Chinese Character String Matching Algorithm Based on Improved Edit Distance and Similarity
SHAO Qing, YE Kun
(School of Optical-Electrical and Computer Engineering, University of Shanghai for Science and Technology, Shanghai 200093, China)
A Chinese character string approximate matching algorithm based on the improved edit distance and similarity is proposed for better accuracy in Chinese string matching. Firstly the pinyin code is used by considering character of Chinese string, then dynamic programming algorithm is improved to effectively improve the accuracy of calculation; next, a normalization algorithm considering switching problems is introduced. With semantic edit and long distance the ratio of the length of the sentence as the result of the normalization, the accuracy and executive efficiency of approximate matching algorithm is improved. Experimental results show that the quality of the results by the improved algorithm is better than those by traditional algorithms with significant improvement in efficiency, recall, precision, time cost and other indicators.
edit distance; similarity; normalization; Chinese character string; approximate matching
2016- 12- 26
国家自然科学基金资助项目(61170277);上海市教委科研创新基金资助项目(02120557)
邵清(1970-),女,博士,副教授。研究方向:网络智能等。叶琨(1993-),女,硕士研究生。研究方向:网络智能。
10.16180/j.cnki.issn1007-7820.2016.09.003
TP391.41
A
1007-7820(2016)09-007-05
