基于Graphlab的网络图关键节点发现算法研究
2016-10-14高壮良吕雁飞张鸿
高壮良,吕雁飞,张鸿
基于Graphlab的网络图关键节点发现算法研究
高壮良1,吕雁飞2,张鸿2
(1. 北京航空航天大学计算机学院,北京 100191;2. 国家计算机网络应急技术处理协调中心,北京 100029)
针对桥接中心度的计算特点设计了一种分布式的网络图关键节点发现算法(DABC),并基于Graphlab进行了实现。算法具有良好的扩展性,由于能够利用集群的内存资源,算法能处理的图规模与集群的大小成正比,并且该算法利用并行处理大幅度提升了计算速度。实验表明,与传统的基于单机实现的关键节点发现算法相比,算法可以获得高达4倍的性能提升。
关键节点;桥接中心度;分布式算法;Graphlab
1 引言
网络图中的关键节点在图的组织和信息传播中起着枢纽作用,对图中关键节点进行标识和发现是图中的一个重要研究方向,有着丰富的应用场景和重要的应用价值。例如,社交网络成员中的关键节点通常具有更大的影响力或者更强的信息传播能力,找到社交网络中的关键节点可以分析甚至影响社交网络中的消息传播。在计算机网络拓扑中对关键节点进行保护可以提升整个网络的顽健性,反之对关键节点进行攻击会起到事半功倍的效果。此外,在反恐斗争中,关键节点研究也对重要恐怖分子的发现等[1]有着辅助作用。
识别网络图中关键节点的一类重要方法是计算图中节点的中心度,包括距离中心度、谱中心度和桥接中心度等。其中,桥接中心度是研究关键节点中常用的一种中心度度量,它可以用来衡量节点在网络图连通和信息传播中的重要程度。具有较高桥接中心度的节点代表着该点对图中的其他顶点的控制能力越大。近年来,桥接中心度在网络拓扑结构重要节点度量、关系网络研究等领域得到了广泛的应用。本文选用桥接中心度算法作为研究对象,下文如无特别说明,提到的中心度均为桥接中心度。
针对不同场景中的桥接中心度计算,相关工作已经给出了多种计算方法[2~9]。但是传统的计算桥接中心度的方法主要为集中式算法,即假设图存储在一台物理机上,并基于单机实现图的存储和计算。由于中心度计算算法的时间空间复杂度较高,集中式算法能够处理的图规模受到单机内存大小的限制,而且单机有限的处理能力也很大程度上影响了算法的执行效率。随着图规模的不断增加,算法的处理效率下降明显,严重影响了算法的应用范围,急需研究集群环境下的分布式算法。
分布式处理技术是目前的热点研究方向,以MapReduce[10]为代表的分布式计算框架目前已变得非常流行,其在处理大规模数据方面有着相当多的应用。与此同时,一些分布式图计算框架也不断被提出,如Pregel[11]、Graphlab[12,13]、PowerGraph[14],GraphX[15]等。这些分布式计算框架为开发者提供了很多的API来设计和实现自己的算法。本文针对关键节点发现的分布式算法进行了研究。
本文设计了计算桥接中心度的分布式算法(DABC, distributed algorithm for betweenness centrality)。在DABC算法中为图顶点分布存储在多台物理机器上,DABC算法设计了算法所需的数据结构,节点间数据通信机制,结果收集机制等。算法基于分布式图计算框架Graphlab进行了实现。由于可以使用分布式环境中多台服务器的内存资源,所以算法能够处理的图规模获得了较大提升,并且可以随集群规模扩展。同时由于使用了并行处理技术,算法的计算效率也比集中式算法明显增强。实验表明,在8台服务器组建的集群中,分布式算法可以处理5倍于集中式算法所能处理的图规模。由于支持并行处理,即使同在单机环境中,算法的处理速度也获得了提升,最好情况下提升幅度达到4倍以上。
2 相关工作
有向图中的桥接中心度是由Anthonisse等[2]在1971年首先提出。1977年,Freeman[3]将这一概念引入具有不连通节点的网络中。现在使用最广泛的是Freeman提出的定义,即基于最短路径的桥接中心度算法。在这种定义中首先计算所有节点对之间的最短路径,在所有最短路径中次数较多的节点拥有较高的桥接中心度。Carpenter等[4]在分析恐怖分子网络时指出桥接中心度是需要解决的重要的问题。Brands[5]通过对桥接中心度算法的深入研究,在2001年提出了高效的桥接中心度算法。在Brands提出的算法基础上,又产生了针对不同条件、不同类型图结构的变形算法[6],包括proximal betweenness算法、bounded-distance betweenness算法、distance-scaled betweenness 算法、group betweenness算法等。2012年,Lee[7]第一次提出了针对无向图的桥接中心度快速更新算法。同年,杨建祥[8]提出了社交网络桥接中心度快速更新算法。Tan[9]等提出了一种新的适用于CREW PRAM 的并行桥接中心度算法,应用于大规模网络分析。这些算法的出现为分析图结构数据提供了方便,但是由于这些算法都未采用分布式处理技术,所以算法能够处理的图规模受到了较大限制,也影响了算法的应用场景。
近年来,利用分布式计算框架处理图数据已经越来越流行。分布式计算框架也在不断发展。Pregel[11]借鉴了Leslie Valiant于20世纪80年代提出的BSP计算模型,采用“计算—通信—同步”的模式完成机器学习的数据同步和算法迭代,计算由主机(master)负责分配任务和收集结果。同时采用了基于检查点(checkpoint)的系统容错方法。Giraph[16]是应用较为广泛的Pregel克隆版本,在Pregel基础上,增加了主节点计算、面向边的输入和核外计算等功能。Graphlab[12, 13]是最近比较流行的图处理框架,它是一个分布式异步内存共享系统,节点程序可以直接访问该节点、相邻边和相邻节点的信息,并通过阻止相邻的程序同时运行来保证结果的正确性。在Pregel和GraphLab的基础上,PowerGraph[14]特别针对社交网络图数据的幂律分布特性,借鉴了GraphLab的内存共享技术和Pregel的协同收集技术,提出了Gather-Apply-Scatter计算模型,分解高度数的节点并提供更大的并行性。
3 分布式关键节点发现算法
3.1 桥接中心度概念与计算方法
桥接中心度可以简单描述为网络图中的顶点在连接其他任意节点的最短路径中所占的比重。假设网络图表示为,其中,节点用来表示图中的顶点集合,表示节点之间的边集合。在本文中只考虑无权图,即认为每条边的权值均为1。对节点表示点和点之间的最短路径的长度,若,。
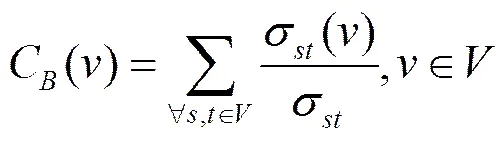
以图1中的有向图为例,图中包含5个顶点及5条边,顶点处在到,到,到的最短路径上,且到及到的最短路径只有一条,到的最短路径有2条,并且顶点在2条最短路径上都有出现,所以顶点的桥接中心度根据定义可计算得到。
图1 节点中心度示意
由节点中心度的定义可知,节点中心度计算可由计算图中两两节点的最短路径得到。目前计算中心度的最好算法是由Brandes[5]在2001年提出的,本文中称为FABC算法(faster algorithm for betweenness centrality)。FABC的计算过程可以简单描述如下。
定义点对之间的依赖为

(3)
而单点依赖满足
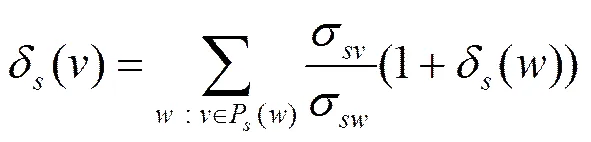
在本文的实验环境中,对一个包含3 000个顶点的无向图,算法的计算时间约为500 s,而且随着顶点数的不断增加,计算时间也随之增加。当顶点数达到万级别的时候,算法的时间消耗已变的不可接受。针对这个问题,本文提出了分布式的节点中心度计算方法。
3.2 DABC算法概述
在分布式系统中,一个完整的图通常被切分为数个部分,由不同的机器进行存储和处理。实际应用的图数据多数呈幂律分布[17],所以现在使用最广泛的切分方式是按点切分[18]。Powergraph已经证明相比于边切分,点切分能带来存储、通信和计算上的优势。在点切分方式中,一个点被复制成几份分别存储在几台机器上,而边不做复制。本文把其中的一个顶点称作master,而它的复制点统一称为mirror。master知道它的所有mirror信息,但是mirror只知道它隶属于master的信息。如图2所示,一个数据图被切分到2个机器上,顶点与顶点被切分,其中顶点、为master,它们的mirror分别为1、1。
本文设计了分布式计算桥接中心度的算法。算法执行过程中,所有机器并行计算得到最终结果。以图2中的切分方式为例,图3介绍了算法的执行过程。
假设当前顶点为执行顶点,顶点接收到的消息,将其到的最短路径个数更新为1,最短距离更新为1(每条边权重默认1)。如图3(a)所示。然后将消息发给它的邻居和1,1根据消息更新自己的及,1将自己的数据发送给,顶点根据消息更新自己的及,同时顶点也将自己的数据同步到1。直到顶点收到来自1和的消息,更新自己的为2及为3,如图3(b)所示。
最后根据式(1)可求得这一次消息传递中的各个顶点的桥接中心度。
3.3 基于Graphlab的DABC算法实现
下面将本节中用到的符号及其含义列出,如表1所示。

表1 符号及含义
本文使用了Graphlab框架来实现算法。Graphlab[12, 13]是基于BSP模型的图并行框架,以高性能著称。其不仅支持基于消息的编程模型,而且支持共享内存风格的“收集—更新—扩散”(记做GAS)模型,除此之外Graphlab还支持异步计算,对自然图的并行处理具有较高的性能。因此本文以Graphlab为基础框架来实现。
Graphlab主要分为3个计算过程。首先是收集阶段,工作顶点的边从邻接顶点和自身收集数据。然后是更新阶段,从节点将收集的数据发送给主节点进行汇总,主节点将汇总后的数据同步更新到从节点。最后是扩散阶段,工作顶点更新完成后,更新边上的数据,并通知对其有依赖的邻接顶点更新状态。
DABC算法主要分为2个步骤。步骤1:首先计算任意2个节点之间的最短路径及其数量,如图4所示。

/* 表示接收本地消息的顶点集合*/1) for 所有的do2) 将本地消息求和保存在部分结果,中3) if then 将,发送到 master4) 同步以保证所有机器均完成通信5) for 所有的do6) 遍历do7) if(<0) then8) 9) if()10) 11) if u有mirror顶点 then 将,发送到所有mirror顶点12),if u收到, ,then 更新本地信息13) 同步以保证所有机器均完成通信14) for 所有的do15) 遍历do16) if then17) 发送, 至18) 同步以保证所有机器均完成本轮迭代
在步骤1的一次迭代中,主要包括3个超级步。
第1个超级步。1) 本地计算:工作节点从接收到的来自本地邻居的消息(消息包含经过该邻居到节点的当前最短路径及数量)中;2) 通信:如果是mirror,则将、发送给它的master;如果是master,则接收其所有mirror的消息。3) 同步屏障:确保所有mirror发送完消息并且master接收到发给它的消息。
第2个超级步。1) 本地计算每个master节点从消息中遍历,如果存在<0,那么令,如果,那么令。2) 如果master发生更新,则将更新后的、发送给其所有的mirror;mirror接收新的、,覆盖自己的、。3) 同步屏障,确保所有通信正常结束。
第3个超级步。对于发生更新的master和mirror,将满足条件的、发给各自的本地邻居,最后,使用同步屏障,确保所有操作结束。
步骤1完成之后,任意2个顶点之间的最短路径及其数量已经求得,然后利用公式便可求得每个顶点的桥接中心度,这是算法的步骤2,如图5所示。

/*表示接收本地消息的顶点集合*/1) for所有的do2) 将本地消息求和保存在部分结果中3) if then 将发送到master4)同步以保证所有机器均完成通信5) for 所有的do6) 遍历do7) 8) 9) if u有mirror顶点 then 将发送到所有mirror顶点10),if u收到,then 更新本地信息11) 同步以保证所有机器均完成通信12) for 所有的do 13) 遍历do14) if then15) 发送至16) 同步以保证所有机器均完成本轮迭代
步骤2的一次迭代过程也包含3个超级步。
第1个超级步。1) 本地计算:工作节点接收到来自本地邻居的消息(消息包含经过该邻居到节点的点对依赖)。2) 通信:如果是mirror,则将发送给它的master;如果是master,则接收其所有mirror的消息。3) 同步屏障:确保所有mirror发送完消息并且master接收到发给它的消息。
第2个超级步。1) 本地计算:每个master节点从消息中遍历,然后根据式(3)及式(4)计算节点的桥接中心度。2) 通信:如果master发生更新,则将更新后的发送给其所有的mirror;mirror接收新的,覆盖自己的。3) 同步屏障:确保所有通信正常结束。
第3个超级步。对于发生更新的master和mirror,将满足条件的发给各自的本地邻居,最后,使用同步屏障,确保所有操作结束。
4 性能测试与分析
本节对分布式桥接中心度算法进行了测试和分析。测试的性能指标包括运行时间、内存消耗以及通信消耗。
4.1 实验环境
本实验共使用了8台物理服务器,服务器在内部局域网中通过吉比特交换机互连。服务器的硬件配置如下:CPU Intel Xeon E5-2650 2.0 GHz 8 Core,内存8 GB,硬盘500 GB。
实验使用的软件环境如下:操作系统64位Debian7,Graphlab2.2,OpenMPI1.6,编译环境为GCC 4.8,编程语言为C++。
实验采用了真实数据集与模拟数据集2类数据进行评估。真实数据集来自SNAP[19],该数据集描述了维基百科中的查询请求关系。模拟数据集则以固定幂律生成了随机网络图数据。实验采用的数据集信息如表2所示。

表2 实验数据集
数据集1中图的顶点数从1 000~4 000,本文使用数据集1的边数1这组数据来测试本文提出的算法和原有算法在运行时间上的差别。同时本文也使用数据集1测试在固定顶点数量,变化边数量的情况下,算法的运行时间。
数据集2包含真实数据集SNAP和另一组模拟数据。数据集2比数据集1具有更大的数据规模,用来测试在多台机器上算法的运行指标。
实验比较了集中式的中心度计算算法和本文提出的分布式中心度计算方法DABC的性能,并测试了在多台服务器组成的集群环境下,DABC算法的运行时间、内存消耗、通信量等指标。集中式的中心度算法采用了经典的FABC算法,在前文中已经有所介绍。
4.2 实验结果分析
图6给出了FABC算法与DABC算法的对比结果。测试使用了数据集1中的第1组数据。该实验在1台机器上进行,主要比较了算法在运行时间上的差别。如图6所示,本文提出的DABC算法比原有算法在时间上有了很大的提升,当顶点规模较小的时候,新算法的运行时间仅为原有算法的25%以下,当顶点数达到3 000时,算法的加速比有所下降,但加速效果同样明显。进一步计算可知,在本实验中,新算法的平均加速达到70%以上。
图7对比了在相同顶点数,边数不同的情况下DABC算法的运行时间。实验同样使用了数据集1中的数据。在数据集1中,本文固定图中顶点数,生成了不同边数的2组图。本实验中将边数较少的一组图称为稀疏图,边数较多的称为稠密图。
如图7所示,在相同顶点数的情况下,稠密图的耗时高于稀疏图。这是由于算法在运行过程中会搜索所有的边,所以边数的增加必然会导致运行时间的增长。
在集群环境中,数据图会被切分到每台机器上存储。机器间通过通信协作完成统一的计算任务。切分方式在某种程度上决定了数据的分布方式和机器间的协作方式,所以一个好的切分方法将会使算法的性能得到很大提升。
在本实验中,对比了3种切分方式,分别为random切分方式、oblivious切分方式、grid切分方式。其中,random切分方式将边随机的分配到每台机器上,切分速度较快,但是这种方式没有充分利用图的连通特征。而oblivious切分方式采取贪心算法策略进行数据图的切分,该切分方式解决的问题为在采用尽可能少的切分点的情况下达到负载均衡,该切分方式由于以贪心算法为基础,所以容易造成局部最优。grid切分方式基于散列分配边,该方法切分速度快、切分均衡、并且切分点较少。
本实验使用了数据集2中的数据。如图8所示,本文分别在2台机器和4台机器上进行了测试。在2台机器的情况下,3种切分方式的算法执行效率差不多,但是,随着机器数的增多,显然在grid切分方式下算法具有更好的效率。这是由于grid切分方式切分均衡、切分点少,使机器间通信减少,并且每台机器的计算负载也比较均衡。而另外2种切分方式,切分的点较多导致过多顶点被复制,使机器间通信频繁,而且切分不均衡也会导致集群的机器负载不匀,降低整体运行效率。
图9给出了算法在数据集2上的运行时间、内存消耗、通信量的统计情况。图9(a)给出了算法在运行过程中的运行时间与机器数量的关系。随着机器数的增加,DABC算法的运行时间不断降低,但是可以看到,加速率随着机器数的增加其有所下降。主要原因是由于机器数增加后,各机器间需要协作的工作也相应增加,导致整体通信量有所增加。另外,机器数量增加后,各机器间的工作负载也可能会不均衡,导致等待时间增多。图9(b)给出了参与计算的所有机器的内存消耗总量和与机器数量的关系。随着机器数的增加,算法消耗的内存整体上升,但是平均每台机器的消耗量有所下降。总量上升的主要原因是由于节点切分生成了多个mirror,并且为mirror生成了一些附加数据结构,占用了大量内存空间。图9(c)给出了算法在运行过程中每台机器平均通信量与机器数量的关系。可以看出曲线呈现下降趋势,这是因为随着机器增多,分配到每台机器中的顶点数目会相应减少,任意2台机器之间的通信量也会随着分区中顶点数目的减少而降低,所以平均通信量会减少。但集群的整体通信量有所增长,这是因为随着机器数的增加,图分区数量也相应增多,所以需要通信的节点数量也增加,导致通信总量的增加。
5 结束语
本文基于传统的集中式桥接中心度计算方法设计和实现了分布式桥接中心度计算算法DABC。算法包含最短路径计算和点中心度计算2个主要的分布式过程。实验结果表明该算法比原有算法在性能上有了大幅度的提升,同时由于采用了分布式架构,该算法具备了良好的扩展性,可以支持更大规模的图数据处理。
在未来工作中,将进一步优化和完善该算法。1)设计更好的切分方法以进一步降低算法的运行时间。2)采用优化的通信方法,以降低机器间的通信开销。
[1] BADER D A, KINTALI S, MADDURI K, et al. Approximating betweenness centrality[C]//Workshop on Algorithms and Models for the Web-Graph. San Diego, CA, c2007: 124-137.
[2] ANTHONISSE J. The rush in a directed graph[M]. Amsterdam: Stichting Mathematisch Contrum, 1971. 1-10.
[3] FREEMAN L. A set of measure of centrality based on betweenness[J]. Sociomtry, 1977, 40 (1): 35-41.
[4] CARPENTER T, KARAKOSTAS G, SHALLCROSS D. Practical issues and algorithms for analyzing terrorist networks[C]// International Workshop on Mobile Commerce. San Antonio, c2012.
[5] BRANDS U. A faster algorithm for betweenness centrality[J]. Journal of Mathematical Sociology, 2001, 25 (2):163-177.
[6] BRANDS U. On variants of shortest-path betweenness centrality and their generic computation[J]. Social Networks, 2008, 30(2):136-145.
[7] LEE M, LEE J, PARK J Y, et al. QUBE: a quick algorithm for updating betweenness centrality[C]//WWW. Lyon, France, c2012: 351-360.
[8] YANG J X, WANG C K, BAI Y Y. A fast algorithm for updating betweenness centrality in social networks[J]. Journal of Computer Research and Development, 2012, 49(l): 243-249.
[9] TAN G, TU D, SUN N. A parallel algorithm for computing betweenness centrality[C]//Washington ICPP. c2009: 340-347.
[10] JEREY D, SANJAY G. MapReduce: simplied data processing on large clusters[C]//6th USENIX Symp on Operating Syst Design and Impl. c2004: 137-150.
[11] GRZEGORZ M, MATTHEW H. Austern pregel: a system for large-scale graph processing[C]//The ACM SIGMOD Conference (SIGMOD). Indianapolis, Indiana, c2010: 135-146.
[12] LOW Y, GONZALEZ J, KYROLA A, et al. GraphLab: a new parallel framework for machine learning[C]//Uncertainty in Artificial Intelligence. c2010: 340-349.
[13] LOW Y, BICKSON D, GONZALEZ J, et al. Distributed GraphLab: a framework for machine learning and data mining in the cloud[J]. Proceedings of the VLDB Endowment, 2012, 5(8): 716-727.
[14] GONZALEZ J E, LOW Y, GU H, et al. PowerGraph: distributed graphparallel computation on natural graphs[C]//USENIX Conf Operating Systems Design and Implementation. c2012: 17-30.
[15] XIN R S, GONZALEZ J E, FRANKLIN M J, et al. GraphX: a resilient distributed graph system on Spark[C]//First International Workshop on Graph Data Management Experiences and Systems (GRADES 2013). c2013: 2-16.
[16] https://giraph.apache.org[EB/OL].2011.
[17] UGANDER J, KARRER B, BACKSTROM L, et al. The anatomy of the facebook social graph[J]. arXiv preprint arXiv:1111.4503. 2011.
[18] http://graphlab.org/projects/source.html[EB/OL]. 2014.
[19] JURE L, ANDREJ K. SNAP Datasets: large network dataset collection [EB/OL]. http://snap.stanford.edu/data/ 2014.
Key nodes discovery in network graph based on Graphlab
GAO Zhuang-liang1, LYU Yan-fei2, ZHANG Hong2
(1. School of Computer Science and Engineering, Beihang University, Beijing 100191, China; 2. National Computer Network Emergency Response Technical Team/Coordination Center of China, Beijing 100029, China)
A distributed key nodes discovery algorithm was proposed(DABC) which was implemented on Graphlab. Due to the good scalability, the scale of graph supported by the algorithm was enlarged significantly. The parallel processing also enhances the speed of calculation. Experiment results show that proposed algorithm can achieve up to 4 times performance improvement compared with the traditional centralized key node discovery algorithm.
key node, betweenness centrality, distributed algorithm, Graphlab
TP316.4
A
10.11959/j.issn.1000-436x.2016066
2015-04-03;
2015-11-11
吕雁飞,lyf@cert.org.cn
国家重点基础研究发展计划(“973”计划)基金资助项目(No.2011CB302605)
The National Basic Research Program of China (973 Program) (No.2011CB302605 )
高壮良(1990-),男,山东菏泽人,北京航空航天大学硕士生,主要研究方向为分布式图计算。
吕雁飞(1984-),男,辽宁朝阳人,博士,国家计算机网络应急技术处理协调中心工程师,主要研究方向为大数据技术。
张鸿(1976-),男,陕西西安人,博士,国家计算机网络应急技术处理协调中心高级工程师,主要研究方向为云计算、大数据、网络安全。
