基于场景运动程度的深度视频时域一致性增强
2016-10-13富显祖王晓东娄达平章联军
富显祖,王晓东,娄达平,秦 闯,章联军
基于场景运动程度的深度视频时域一致性增强
富显祖,王晓东,娄达平,秦 闯,章联军
( 宁波大学信息科学与工程学院,浙江宁波315211 )
深度视频静止区域普遍存在深度值时域不一致,导致编码效率下降且影响绘制质量。针对该问题,提出一种基于场景运动程度的深度视频一致性增强算法。首先,应用基于块的直方图差值(Block Histogram Difference, BH)对深度视频每帧之间做相对运动程度量化度量,根据BH值自适应选取运动程度相对最弱的视频段作为深度值修正源,通过运动检测对相应彩色视频做运动区域分割,接着,利用彩色视频准确的时域一致信息,对深度视频中静止区域的错误变化深度值进行时域一致性校正,最后应用计算复杂度低的时域加权滤波函数对校正后的深度视频进一步优化,得到时域一致性优化的深度视频。本文算法相比于原估计获得的深度视频节省编码码率17.48%~31.75%,深度图所绘制的虚拟视点主观质量提高。
深度视频;时域一致性;运动剧烈程度;深度值修正
0 引 言
当前的三维视频应用广泛,如3DTV、多视点视频、自由视点视频,给观看者带来沉浸感和真实感。基于深度的绘制技术(Depth-image-based Rendering,DIBR)是其中的核心技术之一[1-2],获取高分辨率和准确的深度图就显得尤为重要。目前高分辨率的深度图主要通过深度估计获取,深度估计软件DERS对于深度图的估计是每帧独立进行的,导致深度图在时域上存在严重不一致问题,不仅降低深度视频编码时的帧间预测效率,同时绘制的虚拟视点在时间方向上出现闪烁现象,虚拟视点质量不佳。就此,在第86届MEPG(Moving Picture Experts Group)会议后,发布的深度估计参考软件DERS5.1在构建最小化能量函数时引入增强深度图时域一致性的权重因子[3-4],一定程度抑制静止区域深度值不一致问题,但仍难保证时域上较高一致性。针对该问题,目前已有许多方法被提出,主要分两种:动态的深度估计[4-7]、深度视频滤波处理[8-10]。增强方法通常利用彩色图的时域一致性作为指导,根据彩色图相邻帧估计的运动矢量,融合前一帧深度值到当前对应的深度值中[11-12],忽略了轴方向的运动矢量从而降低了绘制的准确度,文献[13-14]提出3D运动估计来解决该问题。接着,一些时域滤波方法被提出用来融合帧间的深度值,基于权重均值、权重中值滤波、多边滤波或能量函数等[15-16]。Zuo等人[17]提出综合静止可靠性和深度值可靠信分析的加权时域滤波算法,但静止可靠性权重很难做到鲁棒,同时获得的一致性在时域上并不持久。以上方法一方面过高依赖准确的运动估计,实际难以满足;另一方面时域一致性效果仅维持在相邻几帧之间,持久性差。Sheng等人[18]针对以上情况,先实行深度分层处理,运动区域应用空域补偿,静止区域构建静态模型进行优化和自更新,较好的获得持久且准确的时域一致性增强结果。本文提出利用运动程度分析,用相对可靠的深度值修正时域不一致的深度值,进一步应用结合时空域相关性的加权滤波来优化深度空域连续性和时域一致性。
1 深度估计中的时域一致性问题
深度估计分为三步骤:视差计算、基于grap-cut算法的最小能量函数使得误差最小、视差深度转换。第一步中,视差搜索范围内计算候选像素的视差,对应的能量函数包括三项:
2 深度视频时域一致性增强
本文所提基于运动程度分析的深度视频时域一致性增强的预处理算法框图如图1所示。对深度视频进行运动程度分析,自适应选取运动程度相对弱、深度值相对可靠的帧段;对相应彩色视频先后进行粗检测、细检测后得到运动区域掩膜视频,在和辅助下,用作为修正源,对进行深度值时域一致性修正获得修正后的深度视频,最后,结合时空域相关性和运动区域判断的加权时域滤波再对其优化,获得最终的深度视频,其中表示帧,、为帧内像素坐标。

图1 深度视频时域一致性增强算法框图
2.1 深度视频场景运动程度度量
本文对深度视频按时间顺序依次计算帧间的基于块的直方图差值(Block Histogram Difference, BH)来量化度量深度视频在时间方向上的场景运动相对强弱程度,其计算是基于两帧之间直方图绝对误差和(Sum of Absolute Difference,SAD):
2.2 选择深度值修正源帧段
本文考虑原深度估计中的时域一致性增强带来的影响,为尽可能避免选取该方法导致的错误深度值所分布的帧段作为修正源,优先考虑时间方向上在帧段之前的帧段作为修正源帧段,据此,设计如下步骤确定深度值修正源的帧段和待修正的目标帧:
1) 计算总帧数为的深度视频的BH值获得-1个BH值;按时间顺序,从第一帧开始计算连续长度为的BH值的均值,依次后推,计算获得个帧段的BH均值,在这些均值中求取最大值与最小值来确定帧段与的长度以及位置。公式如下:
当满足条件时重复步骤2),直到不满足约束条件或达到预设的最大长度值时停止,即确定最终的和,根据和可确定帧段和的首帧与尾帧帧号,分别用、与、表示。
3) 合理选择运动相对弱的帧段作为修正源
经过BH均值统计,将主要出现如图2的三种情况,对应情况处理:情况1,则直接选取帧段作为对帧段及其余部分的深度修正源。情况2,,而帧段邻近第一帧,则只能选取时间末端帧作为深度修正源。情况3,,但帧段首帧离视频第一帧距离大于或等于,考虑选取修正源应以时间方向靠前的帧段优先原则,则在帧段前的帧段内再应用式(5)得到,确定帧段,当满足时,该帧段选为深度值修正源,否则按情况2处理。当场景存在运动而其程度无明显波动,即不用确定帧段,选取时间最前的帧段作为修正源。
2.3 运动区域分割
权衡计算复杂度和对多模态复杂场景的运动检测需求,针对YUV空间,本文采用文献[20]中的方法对彩色视频进行运动区域分割得到掩膜视频,主要包含粗检测和细检测两个步骤。
1) 运动区域粗检测
采用运行期均值法(Running Average,RA)对每一帧运动区域粗检测。首先对的前帧取均值作为背景帧,为当前时刻视频帧。为增强背景帧的鲁棒性,引入学习因子,则:
当检测区域满足式(10)则属于运动区域。为减少噪声,b选取较大值。本文b=35,,。获得粗检测的运动区掩膜视频。

图2 视频帧间相对运动剧烈程度的主要情况示意图
2) 运动区域细检测
应用改进的高斯混合模型(Gaussian Mixture Model,GMM)进一步检测,在检测前,对进行形态学膨胀获得,设置较大的膨胀结构元素,大小取15×15,符合不增大计算量又满足效果的需求,能将粗检测后存在的空洞填充且使运动区域更完整。改进的GMM其初始化阶段采用期望值有效统计的在线期望最大的更新方式,有效估计背景模型参数且加快收敛,一般取3~5个高斯分布进行建立背景模型,为适应复杂场景,本文取5个;其他预设参数及公式和步骤详见文献[20]。经细检测后应用高斯滤波滤除噪声,内部膨胀填补细小空洞,获得最终的运动区域掩膜视频。
2.4 深度值时域一致性修正
在修正前进行修正源帧的选取和修正目标帧的待修正区域掩码的确定,目标帧即为视频中不属于帧段的帧。等间隔选取帧段中的4帧作为候选修正源帧,应用分别计算这4帧与目标帧静止区域的公共区域面积,选取该面积最大的帧作为当前目标帧的修正源帧,能最大程度修正存在的不一致深度值,相应的公共区域掩膜即目标帧的深度待修正区域掩膜。修正步骤如下:
1) 为实现可靠的匹配和修正,按16×16为单位进行修正。首先对修正目标帧遍历统计所有块,当块内的1/4以上的像素点属于待修正区域,则标记为待修正块;
2) 计算修正源帧与目标帧在对应待修正块的深度值差绝对值的均值,做如下判断:当,则表明深度值相近,不需要修正;当,则表明深度值发生一定程度的错误变化,直接应用修正源帧的深度值进行修正;当,则表明该块深度值变化幅度过大,为避免错误修正,利用彩色图辅助,对两帧彩色图中的块做亮度分量的匹配,计算对应块的亮度值差绝对值的均值,做判断:当,则直接做深度值修正,反之,不修正。遍历的所有待修正块,进行如上步骤,完成对目标帧的时域一致深度值修正,遍历所有目标帧获得修正后的。以上门限阈值的设定,根据已有的深度视频发生深度值错误变化区域的统计和实验结果对比,本文阈值、、分别设置为3、10、4。
2.5 加权时域滤波
虽应用原深度值进行修正,仍会导致修正块周边深度值不连续。同时区域分割准确度有限,时域跨度较大的修正会使得一些相邻帧少数区域的深度值一致性变弱,需对深度视频进一步优化。为保证运动区域深度动态变化,仅在静止区域进行,优化加权计算式:
条件中判断前后帧对应像素点是否属于静止区域且做空域相关性判断,满足两个条件时设置加权标识为1,反之,为0,同前取值依据,该判断门限取30。该制约条件的作用是避免两种像素参与加权:深度值原本存在错误变化,或因运动分割不准确,原属于运动区域边缘部分而划分到静止区域中的。考虑以和的形式参与加权,、是通过下式判断结果来确定:
满足判断条件反映当前像素点深度值在时域上可靠性较高,则设置较大权重,反之设置较小权重。考虑以和的形式参与加权。以上时域滤波的加权优化,计算复杂低,利用时空域相关性一定程度改善的静止区域深度值不连续问题,其中加权深度值分量引入优化后的,增强一致性的时域方向的连续性;引入表征空域相关性的加权分量,使得加权模型更加可靠。
3 实验结果分析
为验证本文提出的基于运动程度的深度视频一致性增强方法的有效性,将本文算法与文献[4]和Lee算法[16]、Zuo算法[17]进行对比,其中本算法与Lee算法、Zuo算法的结果是在文献[4]获得的原始深度图上优化得到的。从深度视频的编码效率和绘制的虚拟视点质量两方面进行评估,再做深度视频时域一致性测试。实验测试序列为Newspaper、Lovebird2、BookArrival和Akko,各有5个视点,详见表1。
3.1 深度视频编码效率及虚拟视点的客观质量对比
编码实验采用参考软件JM8.6和HM15.0编码平台进行仿真,编码结构分别采用IBBP与IBBB;设置不同量化步长QP:22、27、32;其他配置参数均为默认。表2列出解码后绘制虚拟视点的峰值信噪比(PSNR)均值对比结果;表3、4列出深度编码效率对比结果。实验结果表明,在不同编码平台下,本文算法性能平稳,相比于文献[4]节省码率17.48%~31.75%。Lee和Zuo算法适用于静止区域大运动程度弱的视频序列,对运动程度较强的序列节省码率效果下降明显,而Lee算法采用空域上四邻参考且时域上多帧参考,一定程度改善主客观质量,且时域一致性增强效果比Zuo算法好,但其计算成本较高。而本文算法针对不同序列节省码率不仅相比Lee算法有所提高,且适应性强,性能更加稳定,计算复杂度相对较低。相比于Zuo算法,一致性增强时间范围更长,修正幅度大,且运动区域判断更加准确,相比主观质量较好。
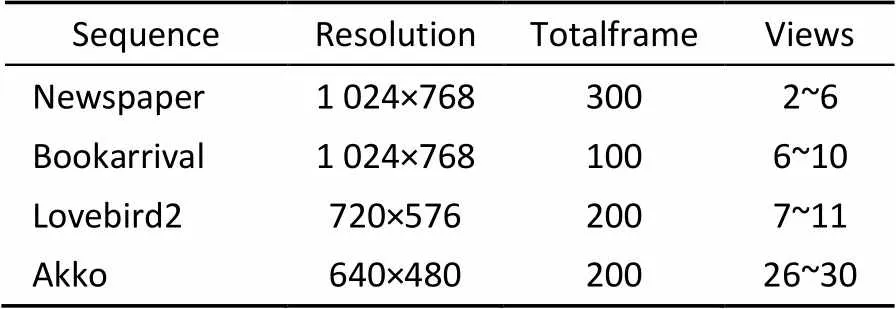
表1 测试序列参数

表2 虚拟视点的PSNR均值对比
3.2 深度视频时域一致性检测
本文采用Zuo算法中的一致性检测方法[17],对深度视频指定的静止区域统计其每个像素深度值在时间方向上方差的均值,即时域均方差。不同是本文统计的时间跨度大,包含运动物体经过前后帧段的静止区域,如原深度视频Newspaper的运动物体未经过的第1~30帧静止区域统计的方差均值为1.083 05,经过后的112~300帧统计结果为1.178 85,但因前后该区域深度值变化较大,整体统计方差均值为47.291 11,第31~111帧中,运动物体经过,静止区域深度值发生明显错误变化。测试序列中统计的静止区域用方框标记在图3中。统计结果如表5。从结果可知本文算法的时域均方差最小,相比Lee算法、Zuo算法获得了更好的深度视频持久的时域一致性增强效果。
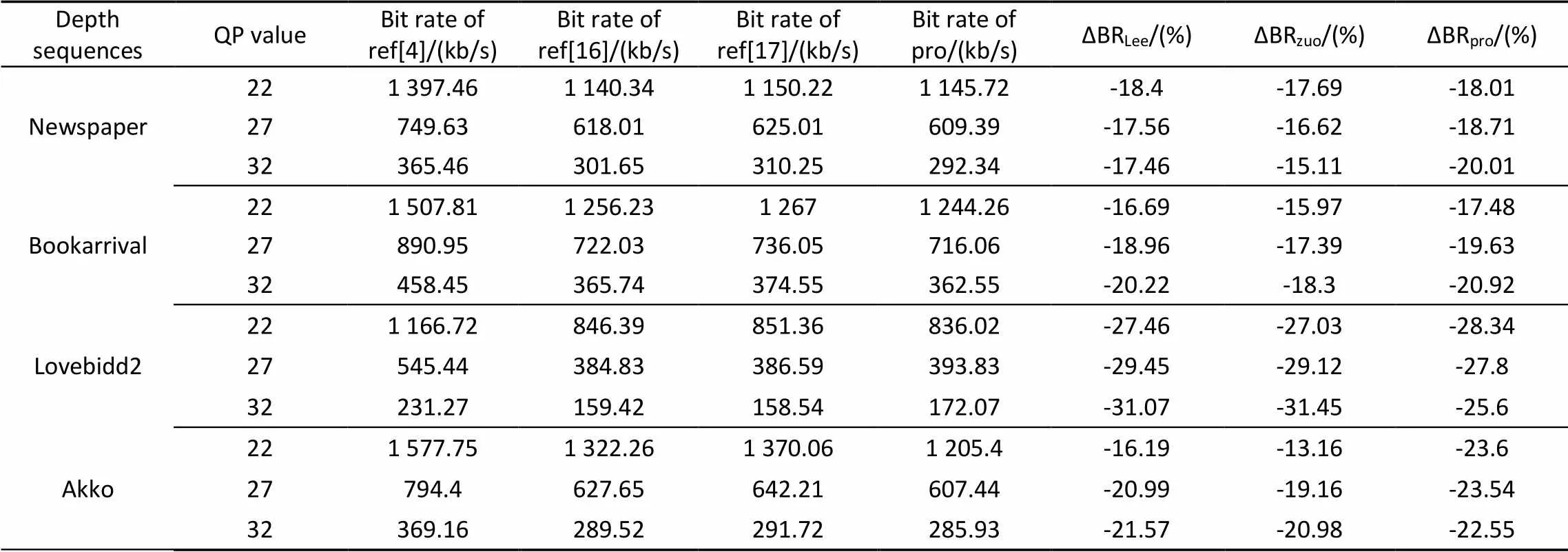
表3 JM8.6平台下编码效率比较
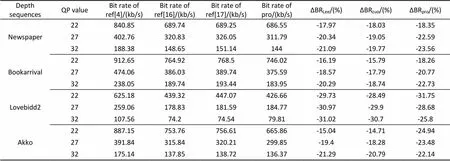
表4 HM15.0平台下编码效率比较

图3 测试视频的静止区域选择
3.3 主观效果评价
图4给出序列Newspaper的三个不同时刻的彩色图、文献[4]获得对应的原始深度图和本文算法处理后的深度图。对比一:第1帧与第73帧人物背后静止区域的深度值变化,对比说明本文算法时域一致性增强效果持久。对比二:第73帧至第74帧中运动物体经过的静止背景区域深度值变化情况,对比表明本文算法时域一致增强效果稳定良好。评价深度图的优劣在于其绘制的虚拟视点的质量,图5给出绘制虚拟视点局部放大细节的主观对比,其中如V9F34表示视点9的第34帧。从运动物体边缘的细节看出本文算法处理后的深度图所绘制出的虚拟视点相比原始深度图与Zuo算法发生纹理失真更少,主观质量更好。
表5 时域一致性检测
Table 5 Temporal consistency test

Depth sequencesViewsFrames Ref[4]Ref[16]Ref[17]Proposed Newspaper41~30,112~30047.291 11 17.870 2131.097 50 14.361 21 628.428 00 12.769 3216.275 06 9.626 25 Bookarrival71~10016.153 10 4.891 027.690 15 4.549 37 91.373 06 0.203 080.459 01 0.140 54 Lovebird280~2007.044 33 3.309 123.490 60 3.655 86 100.013 50 0.011 020.013 05 0.011 53 Akko270~45,165~2009.818 03 2.808 203.524 17 2.202 78 2910.279 47 6.903 827.540 60 6.798 77

图4 深度视频时域一致性增强效果主观评价

图5 虚拟视点局部放大对比
结束语
针对深度估计中时域一致性增强方法的不足和多数方法获得的效果在时间上持续短,时域不一致改善幅度较低,深度修正不准确等问题,提出基于运动程度强弱的深度视频时域一致性优化算法,用相对可靠的深度值进行时间范围更长的一致性修正,应用运动分割和彩色信息辅助修正,再结合时空域相关性的加权模型进一步增强深度空域连续性和时域一致性。实验结果表明,本文算法有效增强深度视频时域一致性,一致性效果持久,节省编码比特率17.48%~31.75%的同时改善虚拟视点的绘制质量。
[1] Fehn C. Depth-image-based rendering (DIBR),Compression and Transmission for a New Approach on 3D-TV [J]. Proceedings of SPIE - The International Society for Optical Engineering(S0277-786X),2004,5291:93-104.
[2] Mori Y,Fukushima N,Yendo T,. View Generation with 3D Warping Using Depth Information for FTV [J]. Signal Processing Image Communication(S0923-5965),2009,24(S1/2):65-72.
[3] Tanimoto M,Fujii T,Suzuki K. Reference Software of Depth Estimation and View Synthesis for FTV/3DV [R]. ISO/IEC JTC1 /SC29/WG11,M15836,2008:5-34.
[4] LEE S B,LEE C,HO Y S. Experimental Results on Improved Temporal Consistency Enhancement [R]. ISO/IEC JTC1/SC29/WG11,M16063,2009:12-42.
[5] Larsen E S,Mordohai P,Pollefeys M,. Temporally Consistent Reconstruction from Multiple Video Streams Using Enhanced Belief Propagation [C]// IEEE International Conference on Computer Vision,Rio de Janeiro,Brazil,Oct 14-20,2007:1-8.
[6] ZUO Xinxin,ZHENG Jiangbing. A Refined Weighted Mode Filtering Approach for Depth Video Enhancement [C]// International Conference on Virtual Reality and Visualization (ICVRV),Xi¢an,China,Sept 14-15,2013:138-144.
[7] Stankiewicz O,DomańSki M,Wegner K. Estimation of Temporally-consistent Depth Maps from Video with Reduced Noise [C]// 3DTV-Conference: The True Vision - Capture, Transmission and Display of 3D Video (3DTV-CON),Lisbon,Portugal,July 8-10,2015:1-4.
[8] LI Li,ZHANG Caiming. Spatio-Temporal Consistency in Depth Video Enhancement [J]. Journal of Advanced Mechanical Design Systems & Manufacturing(S1881-3054),2013,7(5):808-817.
[9] JUNG Seungwon. Enhancement of Image and Depth Map Using Adaptive Joint Trilateral Filter [J]. IEEE Transactions on Circuits & Systems for Video Technology(S1051-8215),2013,23(2):258-269.
[10] PENG Zhongju,CHEN Fen,JIANG Gangyi,. Depth Video Spatial and Temporal Correlation Enhancement Algorithm Based on Just Noticeable Rendering Distortion Model [J]. Journal of Visual Communication & Image Representation(S1047-3203),2015,33(C):309-322.
[11] Christian R,Carsten S,Dodgson N A,. Coherent Spatiotemporal Filtering,Upsampling and Rendering of RGBZ Videos [J]. Computer Graphics Forum(S0167-7055),2012,31(2):247-256.
[12] MIN Dongbo,LU Jiangbo,Minh N Do. Depth Video Enhancement Based onWeighted Mode Filtering [J]. IEEE Transactions on Image Processing(S1057-7149),2012,21(3):1176-1190.
[13] Vogel C,Schindler K,Roth S. 3D cene Flow Estimation with a Rigid Motion Prior [C]// IEEE International Conference on Computer Vision,Barcelona,Spain,Nov 6-13,2011:1291-1298.
[14] Vogel C,Schindler K,Roth S. Piecewise Rigid Scene Flow [C]// IEEE International Conference on Computer Vision,Sydney,Australia,Dec 1-8,2013:1377-1384.
[15] ZHU Jiejie,WANG Liang,GAO Jizhou,. Spatial-temporal Fusion for High Accuracy Depth Maps Using Dynamic MRFs [J]. IEEE Transactions on Pattern Analysis & Machine Intelligence(S0162-8828),2010,32(5):899-909.
[16] LEE Sangbeom,HO Yosung. Temporally Consistent Depth Video Filter Using Temporal Outlier Reduction [J]. Signal Image & Video Processing(S1863-1703),2014,9(6):1401-1408.
[17] ZUO Yifan,AN Ping,MA Ran,. Temporal Consistency Enhancement on Depth Sequences [J]. Journal of Optoelectronics Laser(S1005-0086),2014,25(1):172-177.
[18] LU Sheng,King Ngi Ngan,Lim Chern Loon,. Online Temporally Consistent Indoor Depth Video Enhancement via Static Structure [J]. IEEE Transactions on Image Processing(S1057-7149),2015,24(7):2197-2211.
[19] FU Deliang,ZHAO Yin,YU Lu. Temporal Consistency Enhancement on Depth Sequences [C]// Picture Coding Symposium (PCS),Nagoya,Japan,Dec 8-10,2010:342-345.
[20] LIU Min,LIU Weizhong,ZHANG Daoli. An Efficient Approach of Moving Objects Detection in Complex Background [J]. Proceedings of SPIE - The International Society for Optical Engineering(S0277-786X),2009,7495:74952V-2-74952V-5.
Temporal Consistency Enhancement on Depth Sequences Based on the Motion Intensity of Scene
FU Xianzu,WANG Xiaodong,LOU Daping,QIN Chuang,ZHANG Lianjun
( School of Information Science and Engineering, Ningbo University, Ningbo315211, Zhejiang Province, China)
The flaw in most depth videos is the temporal inconsistency of the depth value of static region, which decreases encoding performance and the quality of rendering. To solve the problem, this paper proposes a method to enhance the temporal consistency of depth video based on the motion intensity of scene. Firstly, we applied block histogram difference (BH) to measure the relative motion intensity of each depth frame, and selected a segment of video as the source for refinement adaptively according to BH value. Secondly, we detected motion region and made a segmentation for each frame of corresponding color video,then refined the depth value which had changed variously in static regions using the accurate temporal consistency information of color video. Finally, we applied the weighted mode temporal filtering on refined depth video to generate well optimized depth video further. Experiment results show that proposed algorithm can save encoding bite rate ranging from 17.48% to 31.75%, while it improves the subjective quality of rendered virtual views.
depth video; temporal consistency; motion intensity; depth refinement
1003-501X(2016)12-0175-08
TN911.73; TP391
A
10.3969/j.issn.1003-501X.2016.12.027
2016-01-15;
2016-04-22
国家科技支撑计划(2012BAH67F01);国家自然科学基金重点项目(U1301257)
富显祖(1991-),男(汉族),福建宁德人。硕士研究生,主要研究工作是多媒体信号处理。E-mail: andyfu57@gmail.com。
王晓东(1970-),男(汉族),浙江绍兴人。硕士,副教授,主要研究工作是网络通信、多媒体信号处理。
