基于紧密二值描述子的RGB-D人脸描述方法
2016-10-13刘小金王华凌
刘小金,尹 东,王华凌
基于紧密二值描述子的RGB-D人脸描述方法
刘小金1,2,尹 东1,2,王华凌3
( 1. 中国科学技术大学信息科学技术学院,合肥 230027; 2. 中国科学院电磁空间信息重点实验室,合肥 230027; 3. 安徽中烟工业有限责任公司合肥卷烟厂,合肥230601 )
提出了一种紧密二值描述子用于解决RGB-D人脸识别过程中的特征表达问题。首先,不同于手工设计的特征,该方法使用无监督学习从训练数据自动获取紧密的二值特征;其次,该方法使用像素与周围像素的差异信息作为输入,利用了空间上下文信息;最后,考虑到Depth图像平滑性特点,对分块的Depth和RGB图提取不同半径范围的像素差异信息。实验结果表明,该方法具有较强的人脸描述能力,且对光照和面部遮挡具有一定的鲁棒性,并在两个公开的RGB-D数据库上获得了较好的识别率。
人脸识别;无监督学习;紧密二值特征;RGB-D
0 引 言
近年来,随着低成本的Kinect[1]的产生,RGB-D[2](RGB-Depth)数据的获取变得十分的简单,RGB-D数据提供了2-D人脸识别相应的彩色图像,也提供了3-D人脸识别的深度图像,使得研究基于RGB-D数据的人脸识别成为一个活跃的话题。如何找到一些有效的特征来描述RGB-D人脸数据是其中的关键。
对于RGB数据的人脸识别,基于局部二值模式(Local Binary Pattern, LBP)[3]的人脸描述方法获得广泛的关注。LBP算子是一种有效的纹理描述算子,由于它的旋转不变性和灰度不变特征,已经广泛地应用于人脸识别。但是,原始的LBP算子明显的局限性在于它只在一个3×3的区域邻域内计算的特征不能获得较大尺度的结构特征,而这些大尺度特征有可能是一些重要的关键特征。对于Depth人脸图像,由于Depth图像的平滑性特征,LBP不能有效的提取深度信息。因此Huang[4]在LBP算子的基础上,利用深度信息相比灰度信息平滑特征,使用固定的比特编码Depth信息,提出了3DLBP算子,并获得较好的描述能力。在此之后,一系列基于3DLBP算法的RGB-D人脸识别方法被提出。文献[5]中使用局部熵放大深度信息,对RGB图像提取显著图,最后使用Hog算子对两种图像提取特征,作为最后的特征表示。文献[6]中使用3DLBP和HAOG(Histogram of Averaged Oriented Gradients)分别提取深度和灰度特征,并进行相似度层融合,作为最终的特征表达。文献[7]中使用多尺度,多种分块模式的3DLBP特征提取深度信息,使用LBP提取RGB人脸信息,将两种特征直接串联作为最终的人脸表示。
然而上述的特征都是手工设计的二值特征[8]。手工设计的二值特征通常有如下的缺点。1) 由于计算复杂度的增加,通常无法对较大邻域范围的样本进行特征量化和编码,然而更大邻域内的样本可以提供更多的信息量。2) 通常使用固定的编码策略进行编码,虽然其方法简单但是可区分性不足,因为无法有效的利用全局信息和图像的上下文信息。3) 通常情况下获得的直方图的分布不均匀。因此本文结合基于学习型的人脸识别[9]理论,从特征学习的角度出发,通过无监督学习的方法对较大空间的邻域学习一种二值模型,使其既可以较好的表达Depth图像,也可以较好的表达RGB图像。
1 学习紧密二值码(CBC)
为了克服上面手工设计的特征的缺点,本文结合基于学习型[9]的人脸识别方法,设计了一种无监督特征学习方法,学习了一种紧密的二值码。由于基于学习的方法可以更好地探索到数据变化的特点,使得本文设计的二值码既适用于Depth图像又适用于RGB图像。
学习紧密二值码[10](Compact Binary Code,CBC)的目的在于学习多个哈希函数将原始的像素映射和量化为二值矢量,同时使得该二值描述子具有可区分。具体来说,假设原始的训练样本为,映射函数为。对于每个样本,将其映射为二值向量,。其中:
式(2)是NP-hard问题,为了解决该问题,将符号函数放松为带符号的函数,除了2中的符号函数保留,其它两项中的符号函数去掉,则可知可以修改为式(3),详细推导见文献[11]。
2 RGB-D人脸表示
鉴于原始的LBP和3DLBP算子均是对邻域范围内的像素差异(PD,pixel difference)进行编码。本文也并非对原始像素进行二值码学习,而是对邻域像素差异信息学习紧密二值码。由于计算量的增大,LBP和3DLBP都固定邻域半径大小为1。然而,考虑到大的邻域范围内获取的信息量更加丰富这一特征,本文选用较大的邻域半径提取PD。同时针对Depth图像相较RGB图像更加平滑的特点,本文对RGB和Depth图像分别采用不同的邻域半径提取PD。假设邻域半径的大小设为,则提取的PD的维度为(2+1)(2+1)-1。
本文的RGB-D人脸表示的算法步骤:
其中K-means聚类中心选择为500,则提取的特征的长度为32 000(8×8×500)。和分别设置为0.001和0.000 1。由于最后的特征维度较大,而人脸中提取的特征存在大量的冗余, 高维的特征使得描述子匹配的速度下降,产生过拟合的风险。因此,本文对该特征使用WPCA(Whitened PCA)降维。最后将两直方图串联在一起,作为RGB-D人脸表达。传统的方法通常使用基于欧式距离相似度量准则对图像进行匹配。本文同时测试了PCCS(Pearson Correlation Coefficient),Chi-squared,,CS(Cosine Similarity)等相似度量参数。但是在本文实验中,同其它的测试的准则相比,CS和PCCS的测试结果最好且相近。由于PCCS计算速度相对较慢,本文使用CS度量准则。公式为

图1 PD窗口半径大小对本文算法的影响
3 实验及结果分析
为了验证本文算法的有效性,本文选取了IIIT-D RGB-D和EURECOM这两个使用普遍的RGB-D人脸数据集验证进行了如下三组实验。IIIT-D RGB-D(IIIT-D) 人脸数据集由Kinect采集得到,包含106个人的人脸图像,Depth和RGB图像各4 605幅。EURECOM数据集包含52个人的936幅图像。数据集包含9种不同的面部变化: 正脸,微笑,张嘴,光照变化,眼睛的遮挡,嘴巴的遮挡,半边脸的遮挡,左侧图,右侧图。EURECOM数据集包含Session1(s1)和Session2(s2)时间段。
实验1 首先研究PD中窗口大小的选取对识别率的影响。参照文献[7]中的设置,对IIIT-D使用数据集提供的5组随机选取的训练和测试集。对EURECOM数据集,对于每个Session,选择其中的正脸为训练集,剩余为测试集。实验中,图像的尺度均归一化到128×128,使用5折交叉验证,获得相应的CMC(Cumulative Match Characteristic)曲线。由于IIIT-D RGB-D图像分块大小为16×16,EURECOM分块的大小为32×32,因此选取邻域半径2到6,实验结果如图1。由图1可知,对于IIIT-D数据集,随着窗口的增大,识别率在一定范围内先提高后下降。这是由于当PD区域的大小接近该分块大小值时,每个分块提取的PD的数目减少,使得识别率有所下降。对于EURECOM数据集,该数据集中图像大于IIIT-D中的图像尺度,因此识别率较好时,选用的窗口较大。对于IIIT-D数据集,Depth图像固定窗口半径为3,RGB图像窗口半径为4。对于EURECOM数据集,窗口半径都为6。
然后对于本文描述子分别使用RGB信息,Depth信息和RGB-D信息做输入,对3DLBP算子仅仅使用Depth信息作为输入。其中3DLBP直接对整张图像提取特征,实验结果如图2。可以看出结合RGB和Depth信息的识别率最高,对于IIIT-D RGB-D数据集,使用RGB信息的次之,使用Depth信息的识别效果最差。但是对于EURECOM数据集的Session 2,使用Depth信息的识别率次之。该实验结果说明相较于仅使用RGB信息和Depth信息,RGB-D信息确实能提高识别效果,而单独使用Depth信息的识别率不高,且相对不稳定。但是单独使用Depth信息,本文方法的识别率好于3DLBP算子。说明本文算法在一定程度上可以较好的表达Depth信息。但是由于Kinect获得的Depth图像的质量较差,使得单独使用Depth信息的识别率不高。
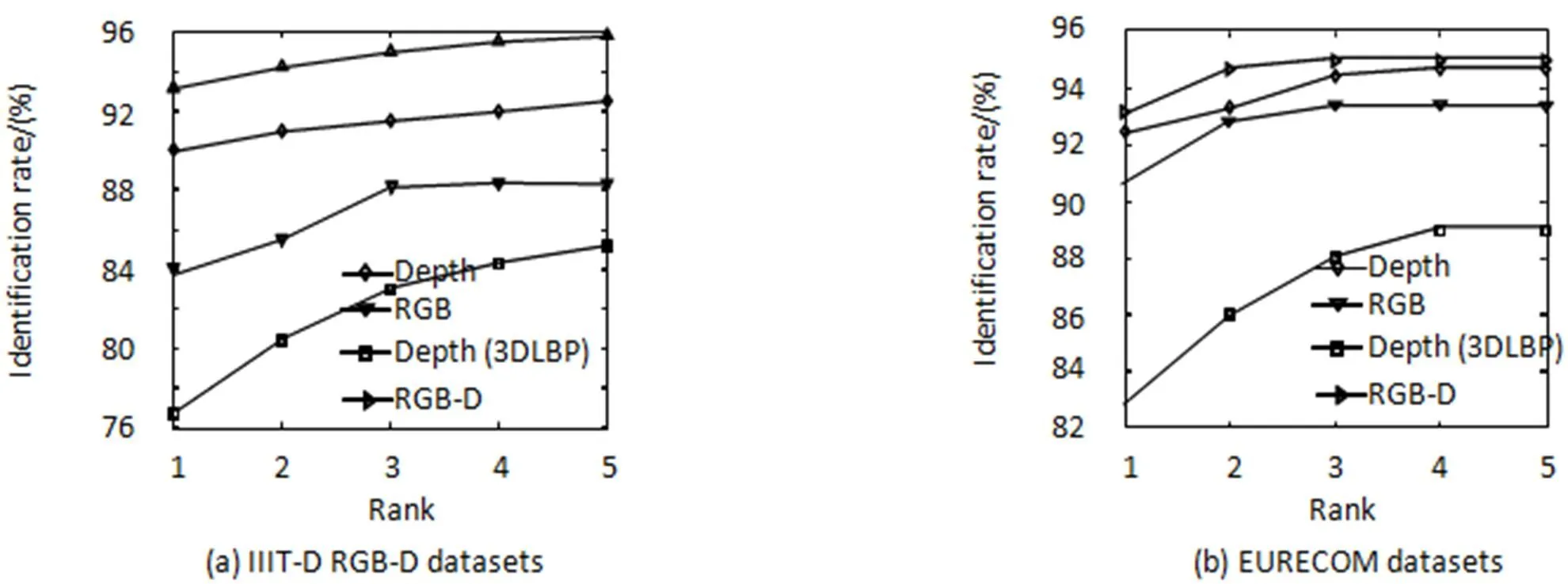
图2 本文算法和3DLBP在3种输入(RGB, Depth, RGB-D)情况下的CMC曲线
实验2 对比分析本文算法的有效性。将本文设计的描述子和FPLBP[12](Four Patch Local), PHOG[13](Pyramid Histogram of Oriented Gradients), SR[14](Sparse Representation)这三种只利用RGB信息的方法进行对比研究,同时与文献[5],文献[6]和文献[7]这三种利用RGB图像和Depth图像的3D方法对比。其中SR中稀疏度设置为5,这几种方法均在两组数据集上进行实验,2D的方法仅仅使用RGB图像作为输入,3D的方法使用RGB-D图像作为输入,本文算法的参数设置同实验1,对于IIIT-D RGB数据集,训练和测试集的选取不变。对于EURECOM数据集,从每类样本中随机选取的2张作为训练集,剩余作为测试集。最后对比几种算法的平均计算时间,所有实验的平台均为Matlab2013a,电脑的硬件配置为3.30 GHz CPU和8.00 GB RAM。实验结果分别为表1和图3所示。

图3 本文算法和多种现有2D和3D算法在两组RGB-D数据集上的CMC曲线
由表1可知,本文算法的平均计算时间高于文献[6]和文献[7],低于文献[5]。本文算法虽然不是最低,但是其识别的准确度相对较好,并且和文献[6-7]这两种识别率较高的算法相比,计算时间在同一量级上。综合而言,本文算法较好。

表1 几种RGB-D人脸表示算法的计算时间
由图3可以看出本文算法在各个Rank上的识别效果均好于上述基于2D和3D的人脸识别算法。该结果也进一步说明Depth信息和RGB信息能够改善识别的精确度。同时本文算法的特征长度小于FPLBP,PHOG和文献[5]、[7]中的特征长度。FPLBP的特征长度为560,PHOG的特征长度为680,文献[5]中特征长度为81×5=405,文献[7]中使用3DLBP和LBP,则特征长度为5个LBP算子的长度,即为256×5=1 280。而本文中特征维度为100×2=200。在特征维度上本文算法小于选取的几种2D和3D的算法,但是在识别率上有所提高。说明本文设计的特征描述子具有较强的表示能力和可鉴别性。
实验3 分析本文的算法在各种面部变化情况下的识别率。由于EURECOM数据集包含9种不同的面部变化,参照文献[2]选用的实验数据集,本实验也使用其中7种(除去左侧图,右侧图)面部变化的RGB-D图像,将时段s1和s2合并,使用本文算法进行实验,获得每种面部变化的Rank-1识别率和总的Rank-1识别率。同文献[5-7]中针对RGB-D数据的人脸识别算法对比。实验结果如表2所示。

表2 在EURECOM人脸数据库上的Rank-1识别率(%)
由表2中可以看出,本文算法对于正脸,微笑和光照变化这几种面部变化较小的情况能够达到较好的识别效果,但是对于嘴巴的遮挡和半边脸的遮挡两种面部遮挡严重的情况识别率较低。分析产生该问题的原因,主要是由于遮挡情况较严重时,特别是半边脸的遮挡,造成大量的信息损失。针对这两种遮挡情况,本文算法优于其他的方法。对于文献[5],其采用的方法是对多尺度的Depth图像和RGB图像分别提取熵图像和显著图,然后对两种图像提取Hog特征,串联作为最后的特征。对于遮挡情况较大时,使用多尺度的图像并没有增加太多的信息量,因此该方法对遮挡严重情况的识别率也不高。对于文献[6],其分别采用3DLBP和HAOG提取Depth和RGB图像的特征并串联,由于该方法对原始图像提取特征,也容易受到遮挡部分的干扰。对于文献[7],由于其中采用了多种分块策略,使用3DLBP和LBP分别提取多种分块区域Depth图像和RGB图像的信息,因此其对较小的面部变化具有较好的识别效果,但是对大面积的遮挡仍然会缺失一些关键信息。实验结果分析本文算法对光照和遮挡不严重的情况具有一定的鲁棒性。
4 结 论
结合LBP和3DLBP这两种手工设计的二值特征的优点和局限性,本文提出了一种基于无监督学习的紧密二值特征用来表征RGB-D人脸图像,该算法首先对分块的Depth图像和RGB图像提取不同窗口大小的像素差异信息,然后对像素差异信息使用无监督滤波的学习方法提取紧密的二值码,最后将这些二值特征使用K-mean聚类获得相应的码本,提取对应的直方图,并使用WPCA获得紧密的特征表示用于分类。该算法公开数据集上均取得较高的识别率。实验分析表明,本文的紧密二值特征具有较好的RGB-D人脸的特征表示能力,且对光照和遮挡有一定的鲁棒性。此外,由于使用无监督的学习的方法,在学习紧密二值码的过程中,未用到训练样本的标签信息,因此可以灵活的调整训练样本的数目来获得区分性强的二值特征。本文下一步的工作是进行速度方面的优化。
[1] ZENG Wenjun,ZHANG Zhengyou. Microsoft kinect sensor and its effect [J]. IEEE MultiMedia(S1070-986X),2012,19(2):4-10.
[2] Min R,Kose N,Dugelay J L. KinectFaceDB:A kinect database for face recognition [J]. IEEE Transactions on Systems,Man,and Cybernetics:Systems(S2168-2216),2014,44(11):1534-1548.
[3] Ahonen T,Hadid A,Pietikainen M. Face description with local binary patterns:Application to face recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence(S0162-8828),2006,28(12):2037-2041.
[4] HUANG Yonggang,WANG Yunhong,TAN Tieniu. Combining Statistics of Geometrical and Correlative Features for 3D Face Recognition [C]// Proceedings of the British Machine Vision Conference 2006,Edinburgh,UK,September 4-7,2006:879-888.
[5] Goswami G,Bharadwaj S,Vatsa M,. On RGB-D face recognition using Kinect [C]// IEEE Sixth International Conference on Biometrics:Theory,Applications and Systems,BTAS 2013,Arlington,VA,USA,September 29 - October 2,2013:1-6.
[6] Cardia Neto J B,Marana A N. 3DLBP and HAOG fusion for face recognition utilizing Kinect as a 3D scanner [C]// Proceedings of the 30th Annual ACM Symposium on Applied Computing,Salamanca,Spain,April 13-17,2015:66-73.
[7] Neto J B C,Marana A N. Face Recognition Using 3DLBP Method Applied to Depth Maps Obtained from Kinect Sensors [C]// X Workshop Computer Vision WVC(2014),Uberlândia,Minas Gerais,Brazil,October 06-08,2014:168-172.
[8] JIN Lu,GAO Shenghua,LI Zechao,. Hand-Crafted Features or Machine Learnt Features? Together They Improve RGB-D Object Recognition [C]// 2014 IEEE International Symposium on Multimedia,Taichung,Taiwan,December 10-12,2014:311-319.
[9] CAO Zhimin,YIN Qi,TANG Xiao¢ou,. Face recognition with learning-based descriptor [C]// IEEE Conference on Computer Vision and Pattern Recognition(CVPR2010),San Francisco,California,USA ,June13-18,2010:2707-2714.
[10] LIONG V E,LU Jiwen,WANG Gang,. Deep hashing for compact binary codes learning [C]// IEEE Conference on Computer Vision and Pattern Recognition(CVPR2015),Boston,MA,USA,June 7-12,2015:2475-2483.
[11] LU Jiwen,LIONG Venice Erin,ZHOU Xiuzhuang,. Learning compact binary face descriptor for face recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence(S0162-8828),2015,37(10):2041-2056.
[12] Wolf L,Hassner T,Taigman Y. Descriptor based methods in the wild [C]// 10th European Conference on Computer Vision:Workshop Faces in 'Real-life' images:Detection,Alignment,and Recognition,Marseille,France,October 17,2008:68-81.
[13] YANG Bai,GUO Lihua,JIN Lianwen,. A novel feature extraction method using pyramid histogram of orientation gradients for smile recognition [C]//Proceedings of the International Conference on Image Processing,ICIP 2009,Cairo,Egypt,November 7-10,2009:3305-3308.
[14] John Wright,YANG Allen Y,Ganesh Arvind,. Robust face recognition via sparse representation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence(S0162-8828),2009,31(2):210-227.
RGB-D Face Description by Compact Binary Feature
LIU Xiaojin1,2,YIN Dong1,2,WANG Hualing3
( 1. School of Information Science and Technology, USTC, Hefei 230027, China;2. Key Laboratory of Electromagnetic Space Information of CAS, Hefei 230027, China; 3. Hefei Cigarette Factory of China Tobacco Anhui Industrial Co, LTD, Hefei 230601, China)
A compact binary feature for RGB-D face description and recognition is proposed. First, different from traditional hand-craft feature, we learned the compact binary feature from the training set using unsupervised learning method. Then, in order to make full use of the contextual information, we use the pixel difference vectors as the input. Finally, considering the smoothness of the depth image, we extract different size of pixel difference vectors from every block of RGB and depth image. This work demonstrates that the proposed method is highly discriminable and is robust to facial occlusion and illumination. And recognition rates are comparatively high on two publicly available RGB-D Kinect database.
face recognition; unsupervised learning; compact binary feature; RGB-D
1003-501X(2016)12-0162-06
TP391.4
A
10.3969/j.issn.1003-501X.2016.12.025
2016-01-25;
2016-06-14
安徽省科技厅项目“海量人脸图像快速检索云服务平台及应用示范”。
刘小金(1991-),女(汉族),湖北武汉人。硕士研究生,主要研究方向为计算机视觉、机器学习。E-mail: lxj91@mail.ustc.edu.cn。
尹东(1965-),男(汉族),江西莲花人。硕士,副教授,主要研究方向为智能信息处理、图像处理。E-mail: yindong@ustc.edu.cn。
