时空LBP矩和Dempster-Shafer证据融合的双模态情感识别
2016-10-13王晓华侯登永任福继王家勇
王晓华,侯登永,胡 敏,任福继,2,王家勇
时空LBP矩和Dempster-Shafer证据融合的双模态情感识别
王晓华1,侯登永1,胡 敏1,任福继1,2,王家勇1
( 1. 合肥工业大学计算机与信息学院情感计算与先进智能机器安徽省重点实验室,合肥230009;2. 德岛大学先端技术科学教育部,日本德岛 77085020 )
针对视频情感识别中存在运算复杂度高的缺点,提出一种基于时空局部二值模式矩(Temporal-Spatial Local Binary Pattern Moment,TSLBPM)的双模态情感识别方法。首先对视频进行预处理获得表情和姿态序列;然后对表情和姿态序列分别提取TSLBPM特征,计算测试序列与已标记的情感训练集特征间的最小欧氏距离,并将其作为独立证据来构造基本概率分配(Basic Probability Assignment,BPA);最后使用Dempster-Shafer证据理论联合规则得到情感识别结果。在双模态表情和姿态情感数据库上的实验结果表明,本文提出的时空局部二值模式矩可以快速提取视频图像的时空特征,能有效识别情感状态。与其他方法的对比实验也验证了本文融合方法的优越性。
视频感情识别;双模态情感识别;时空局部二值模式矩;Dempster-Shafer证据理论
0 引 言
近年来,随着计算机视觉及人工智能技术的发展,人类迫切希望计算机能够更人性化,可以自动感知和响应自然的人类行为,像人与人之间的交流那样自然。非语言交流在人类交往中起着重要的作用,拥有读懂非语言情感的能力对于理解、分析和预测他人的行为和意图具有至关重要的地位。要实现自然的人机交互,就要求计算机具有和人类相似的情感感知和识别能力。人类的情感状态是复杂而且多变的,我们观察到的情感状态自然也是通过多种方式,如面部表情、身体姿态、音频信号等,这些通过不同方式获得的情感信息也是互补的。
关于情感识别方面的研究大多基于单模态,比如人脸表情识别[1]、姿态情感识别和语音情感识别等[2-5]。Pardas M[6]等人提取面部动画参数作为表情特征,利用隐马尔可夫模型(HMM)识别图像序列中的表情。Camurri等人[7]做了关于舞蹈动作对情感识别作用的研究,结果表明部分舞蹈动作有助于情感识别。既然人类的情感状态是通过多种方式表达的,那么仅通过单模态进行情感识别就会存在一定的局限性,介于此,双模态或者多种模态的情感识别成为目前研究的主流方向。文献[4]针对目前实时自动情感识别中表情和姿态特征提取问题,提出结合局部运动和外观特征的新型框架模型,该框架模型采用MHI-HOG和图像的梯度直方图特征,通过时间归一化或词袋捕捉运动和外观的信息。Yan等人[8]研究了基于视频的表情和姿态双模态情感识别,提出了一种基于双边稀疏偏最小二乘的情感识别方法,计算复杂度低,实验取得了不错的效果。Gunes和Piccard对姿态和表情的双模态情感识别研究进行了大量探索和研究[9-12],首先提出一个识别框架,然后建立了基于表情和姿态的双模态情感数据库,应用基于视频的HMM和最大投票顶点帧的方法进行情感识别研究。尽管实验取得了不错的效果,但是实时特征提取处理相当复杂,涉及到光流、边缘、跟踪等处理,在实际应用中无法满足实时性的要求。
综上,本文在前人研究的基础上,提出一种基于时空LBP矩特征的表情和姿态双模态情感识别方法。将视频中的面部表情和上身姿态看成由每帧图像沿时间轴堆叠而成的三维时空体。与其他方法相比,在特征提取上,本文方法从视频帧序列中直接提取时空特征,不需要对视频帧时间对齐,可避免视频帧序列持续时间不同所造成的后果,同时特征维数小,对光照表现一定的鲁棒性等特性。在分类识别上,D-S证据理论融合两种模态的数据信息,可以克服单一模态的局限性,得到更为可靠、准确的结果。
1 TSLBPM特征提取方法
对于视频序列中的某一帧图像,其局部像素的梯度位置和方向常被用来表征图像的纹理特征分布。借鉴传统的LBP[13]算法思想,本文将其从描述单幅图像不同像素点的空间关系扩展到时间序列中,并融合灰度共生矩阵提出一种基于时空的局部二值模式矩,它是通过度量相邻帧序列及其对应像素点间的大小关系来获取纹理特征值,具有计算复杂度低、对光照变化不敏感等优点,适用于静态背景环境中的情感识别。
1.1 时空局部二值模式(TSLBP)
对于视频中时刻图像I中像素位置,考虑以其为中心的邻域窗口及其前后两帧的像素窗口,可以得到像素值向量[14]:

由3个0/1比特组成,其十进制编码值计算如式(4)所示:

图1 ATSLBP(1,8)的计算流程
1.2 时空局部二值模式矩(TSLBPM)
时空LBP的特征值是将二进制序列乘以相应的权重因子转化成十进制后得到的,这使得相似的二进制序列经十进制编码后数值相差很大,导致相似的二进制特征无法落入直方图相邻的区域。同时,计算得到的十进制编码数相对比较大,在进行直方图统计时,直方图分布过于稀疏,特征分布不集中。在时空LBP算子的基础上,考虑相邻帧图像对应位置的像素值变化,借鉴灰度共生矩阵[15]在研究灰度图像纹理空间相关特性的思想,本文进一步提出时空局部二值模式矩。将式(2)得到的像素二值向量写成一个3´8矩阵:
在式(5)中,其中每一行表示每一帧的二进制序列,每一列表示相邻帧对应位置的二进制序列。
灰度共生矩阵的纹理特征量描述符角二阶矩(Angular Second Moment,ASM)能量,是对图像纹理的灰度变化稳定程度的度量,反映了图像灰度分布均匀程度和纹理粗细度。借鉴这一思想,我们对求取ASM能量。纵向统计字符跳变次数,即、、、的跳变次数,得到的灰度共生矩阵:
在灰度共生矩阵中,跳变次数大小反应了相邻两帧图像纹理变化的程度。如果其值集中在对角线分布,说明相邻两帧之间纹理未发生变化或发生较大变化,也即相邻两帧之间未产生动作变化或动作幅度较大,此时ASM有较大值;如果其值分布较均匀,说明相邻帧之间纹理发生部分变化,也即相邻帧之间产生小幅动作变化,此时ASM有较小值。ASM值的大小衡量当前纹理变化是否稳定,能够有效描述帧间的运动信息,由此可以有效表征图像的纹理特征。
2 基于TSLBPM和Dempster-Shafer理论的双模态情感识别
2.1 Dempster-Shafer证据理论
证据理论[16-17]是由Dempster提出的一种不精确推理理论,并由Shafter对其进行完善,因此又被称为D-S(Dempster-Shafer)证据理论。它可以将具有模糊性、不确定性的信息按照合成法则融合成一个新的信任函数,并由此得到最终的决策结果,具有处理不确定信息的能力,可获得较高的准确性和识别性能。
在D-S理论中,设是一个元素互斥的识别框架集合,其中包含的所有取值。定义一个函数满足下面条件:
2.2 基本概率分配函数的构造
在情感识别中,将情感的类别表示成识别框架中的焦点元素,设有类情感,即。在本文中,证据来自于表情和姿态两种模态(=1,2)。首先提取所有测试样本和训练样本的TSLBPM特征,然后计算某一测试样本与所有训练样本的欧氏距离,记为每一类情感的最小欧式距离,表示表情或姿态,是情感的类别。在进行合成规则前,先将所有的进行归一化,即:
2.3 决策融合及判决规则
2.4 基于TSLBPM和D-S理论的双模态情感识别方法
本文从视频的原始图像中提取出表情序列和姿态序列。对于视频图像中姿态动作的变化,由于时空LBP矩保留了时空LBP良好的抗噪声能力,可以不用对其进行目标追踪、分割等一系列常规视频图像处理的环节,就可以达到较好的实验效果。在预处理部分,主要对视频帧序列进行图像标准化处理。另外,由于一个几秒的视频往往包含几十帧的图像信息,数据庞大,这就给特征提取带来困扰,影响后续的模式识别。本文采用均值聚类的方法分别对表情序列和姿态序列进行聚类,用=5幅图像序列信息来代替整个图像序列信息,从而极大地减少了计算量。
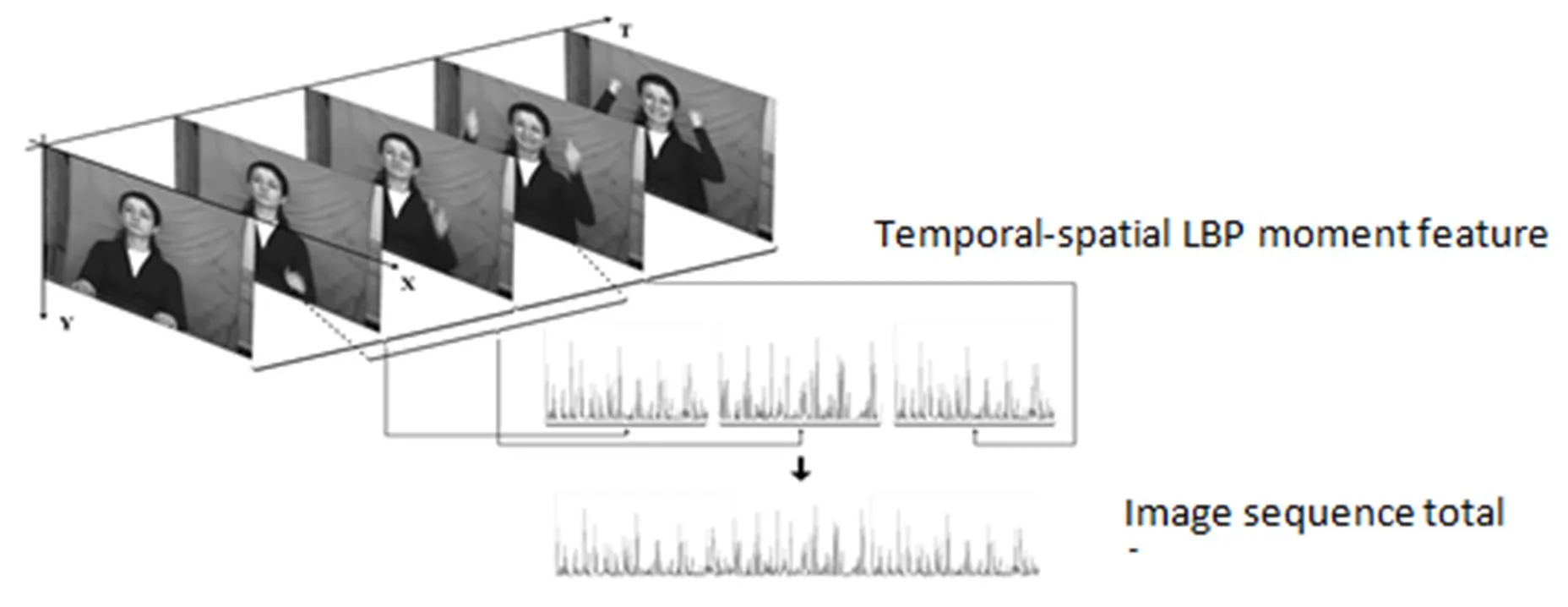
图2 上身姿态三维时空体特征图谱
3 实验结果与分析
3.1 实验数据库
为了验证本文方法的有效性,本文使用双模态表情和姿态情感数据库(Bimodal Face and Body Gesture Database,FABO)(分辨率为1 024×768,15 f/s)进行实验。在FABO数据库中,由于每个人的样本数和情感类别数均不一样,为了保证实验数据的一致性,本文选取FABO数据库中样本数相对较多且情感类别数相对均匀的12个人做了相关实验。所选样本共包括高兴、害怕、生气、厌烦和不确定5类情感,其中姿态和表情各取238个样本,一半作为训练一半作为测试。本文实验是在Windows XP系统下(双核CPU 2.53 GHz 内存2 G),使用VC6.0+OpenCV1.0实现的。实验中将人脸表情图片帧和上身姿态图片帧分别统一大小为96×96和128×96。本文实验最后的识别率均为实验结果的平均值。表情图片和姿态图片统一大小后的部分图像如图4所示。

图4 表情和姿态图片样本
3.2 单模态情感识别实验
在D-S证据融合前,首先对表情和姿态两个单模态进行单独的情感识别。先分别对表情序列和姿态序列提取TSLBPM特征,然后使用分类器进行分类识别。
本实验中需要定义的参数是表情和姿态图像的分块大小。图5给出了平均识别率与分块大小的对应关系。从识别率考虑,取表情图像分块为6×6,姿态图像分块为4×4。图6给出了在此分块方法下,表情和姿态两种单模态的混淆矩阵。表1显示了在FABO数据库上分别采用支持向量机(SVM)、最小距离分类器和最近邻分类器(NNC)时表情和姿态两种单模态的平均识别率。表2给出了本文算法与其它文献算法识别率的比较结果。
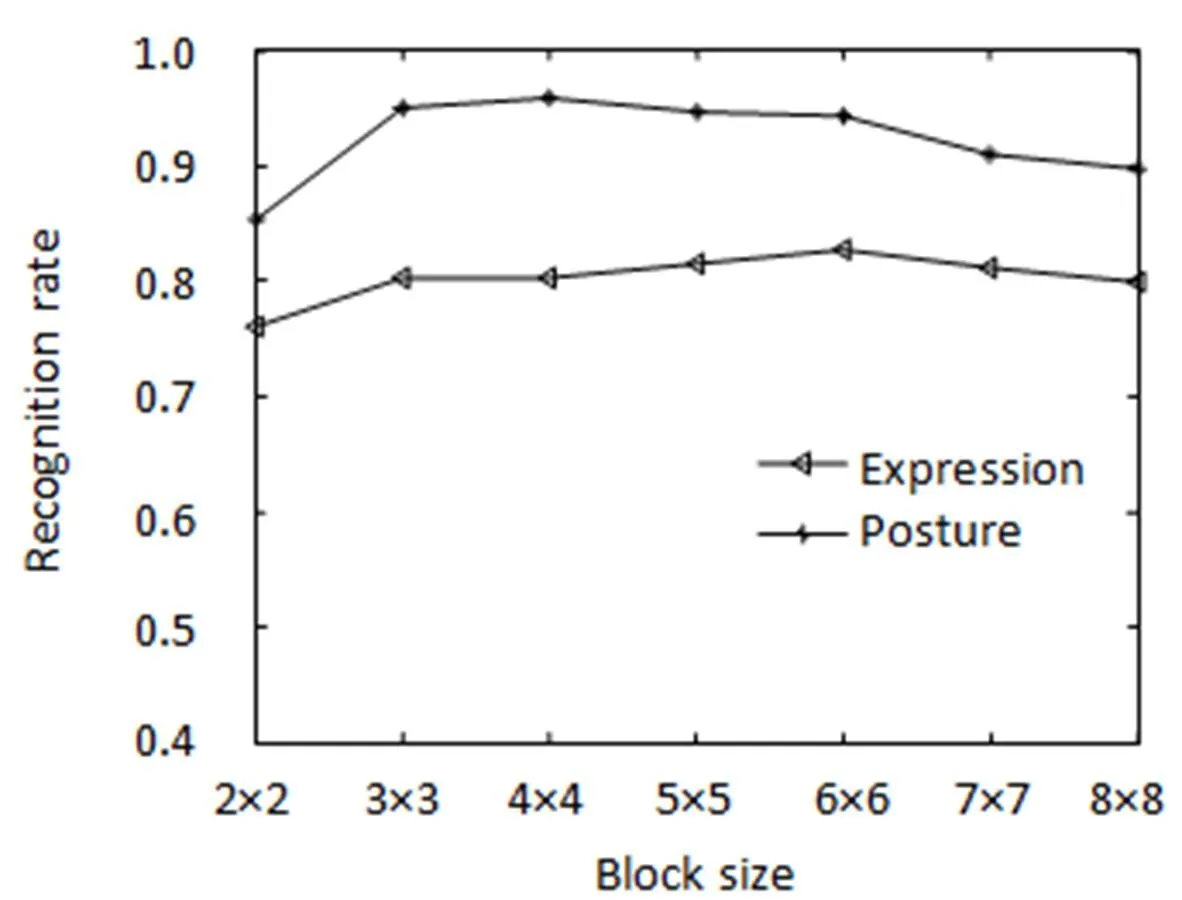
图5 分块大小与平均识别率关系图
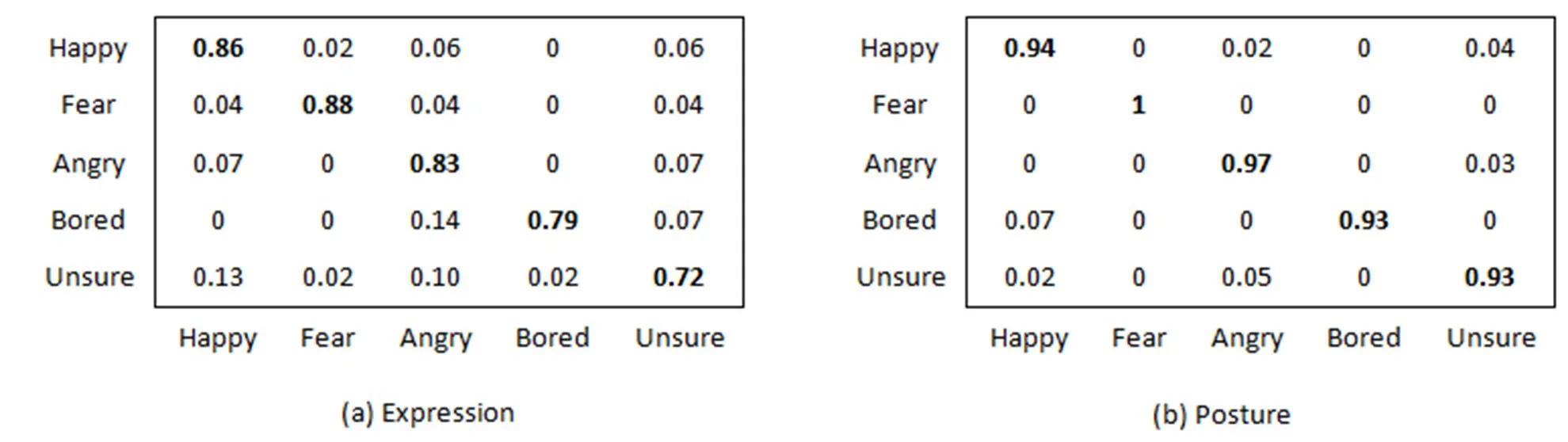
图6 表情和姿态单模态识别混淆矩阵
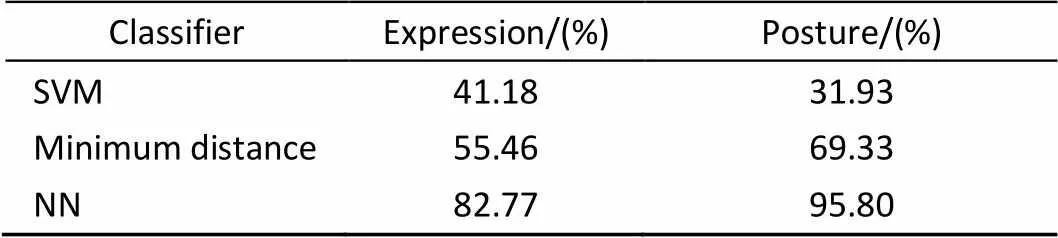
表1 基于表情和姿态的单模态情感识别的平均识别率
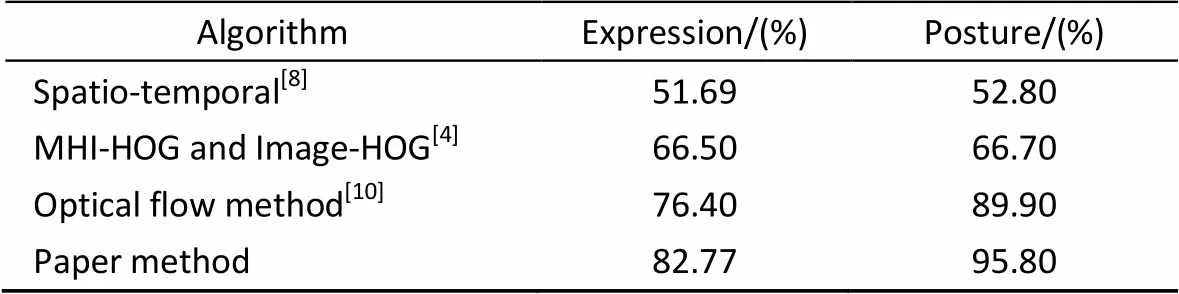
表2 基于单模态的不同特征提取方法的平均识别率比较
从表1的实验结果来看,使用NNC分类器的实验结果要好于SVM和最小距离分类器,并且姿态单模态的识别率高于表情单模态的识别率。究其原因,是因为姿态动作的变化幅度大,纹理变化比较明显,提取的特征更加有效,而表情的纹理变化比较微小,相比于姿态动作较难识别。表2表明,与其他论文中的方法相比,本文提出的时空LBP矩特征在单模态情感识别上的识别性能显著优于其他方法,是一种有效的特征提取方法。
3.3 双模态情感识别实验
由表3结果看出,将表情和姿态两种单模态利用D-S证据理论进行融合获得的识别率为96.64%,取得比两种单模态都要高的识别率,说明了融合表情和姿态进行情感识别的有效性。同时,与其他论文融合方法相比,本文融合方法具有更好的优越性。两种模态相融合与单模态情感识别相比,准确率和稳定性明显提高。原因在于:D-S证据理论以欧氏距离构造BPA,根据组合规则,融合来自表情和姿态两种模态的识别信息,能够实现较弱分类(单模态)决策对较强分类(双模态)决策的有效支持,从而可以进一步提高识别准确率和可靠性。
表4为D-S证据理论融合数据的实验结果,这里选取两类出现误识别的情感数据作为应用举例。分析表4的数据可以得出:1) 表情和姿态两种单模态融合后的信任度值大于单模态的信任度值,增加了正确目标的可信度,大幅度降低对目标识别的不确定性。2) 对于两种单模态均无法正确识别的情感样本,利用D-S融合后仍能将其准确识别出来,说明了基于D-S证据理论的多模态融合方法增强了系统的识别能力,提高了系统的可靠性和准确性。

表3 不同融合方法的平均识别率对比
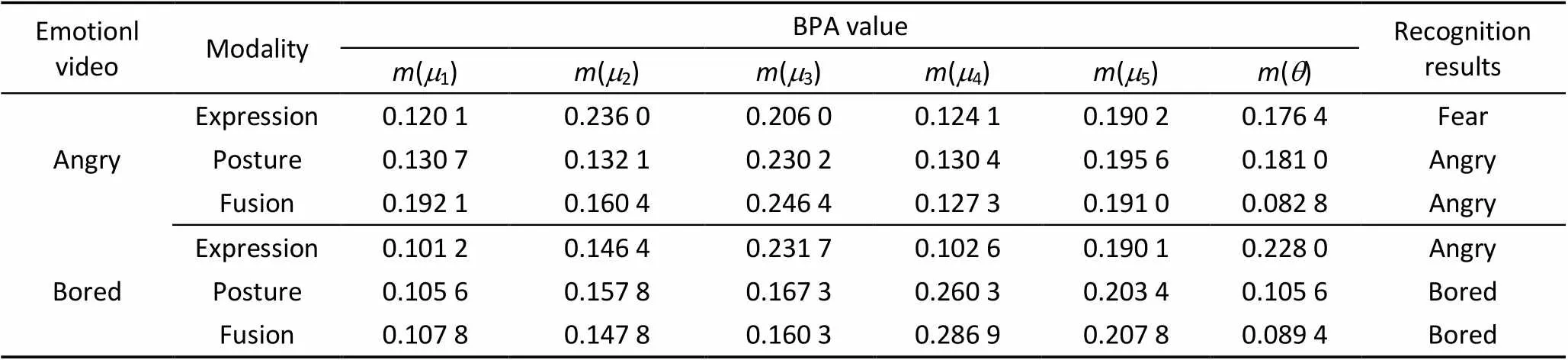
表4 D-S方法的数据融合结果
4 结 论
本文提出的时空局部二值模式矩可以快速提取视频图像的时空特征,能有效识别认知情感状态。此方法从一个全新的角度对情感识别问题进行探索,将刻画图像局部特征的有效算子发展为三维形式并应用于视频数据,它无需降维,无需进行时间对齐,能够从时空体积直接提取有效低维特征。在分类识别上,用NN分类器分别基于表情和姿态两种单模态进行情感识别,并以NN的输出作为独立证据分别构造基本概率分配值;然后利用D-S证据理论合成法则对各证据信息进行合成;最后依据判别规则获得最终的情感识别结果。从其实验数据来看,可以得出如下结论:
1) 在基于视频纹理特征提取中,TSLBPM考虑帧间的纹理变化,融入时间信息,相比较原始LBP特征更能有效提取动态的纹理特征变化,可以很好的提取局部特征。
2) TSLBPM特征保留了原始LBP特征对光照变化鲁棒的优点,特征维数小,且计算简单有效,满足实时系统的要求。
3) 利用D-S证据理论对来自不同模态的TSLBPM特征进行融合,并使用曲线拟合来构造BPA函数,能够有效弱化信息的不完整性及错误数据对识别的不良影响,使得系统最终获得较高的识别率。
[1] ZHANG Wei,ZHANG Youmei,MA Lin,. Multimodal learning for facial expression recognition [J]. Pattern Recognition(S0031-3203),2015,48(10):3191-3202.
[2] Valstar Michel,JIANG Bihan,Mehu Marc,. The first facial expression recognition and analysis challenge [C]// 2011 IEEE International Conference on Automatic Face & Gesture Recognition and Workshops,Santa Barbara,CA,Mar 21-25,2011,31:921-926.
[3] Ou Jun,BAI Xiaobo,PEI Yun,. Automatic Facial Expression Recognition Using Gabor Filter and Expression Analysis [C]// ICCMS '10. Second International Conference on Computer Modeling and Simulation,Sanya,Hainan,Jan 22-24,2010,2:215-218.
[4] CHEN Shizhi,TIAN Yingli,LIU Qingshan,. Recognizing expressions from face and body gesture by temporal normalized motion and appearance features [J]. Image & Vision Computing(S0262-8856),2013,31(2):175-185.
[5] Ayadi M E,Kamel M S,Karray F. Survey on speech emotion recognition:Features,classification schemes,and databases [J]. Pattern Recognition(S0031-3203),2011,44(3):572-587.
[6] Pardas M,Bonafonte A. Facial animation parameters extraction and expression recognition using Hidden Markov Models [J]. Signal Processing Image Communication(S0923-5965),2002,17(9):675-688.
[7] Camurri A,Lagerlöf I,Volpe G. Recognizing emotion from dance movement:comparison of spectator recognition and automated techniques [J]. International Journal of Human-Computer Studies(S1071-5819),2003,59(1/2):213-225.
[8] YAN Jingjie,ZHENG Wenming,XIN Minghai,. Bimodal emotion recognition based on body gesture and facial expression [J]. Journal of Image & Graphics(S1793-6756),2013,18(9):1101-1106.
[9] Gunes H,Piccardi M. A bimodal Face and Body Gesture Database for Automatic Analysis of Human Nonverbal Affective Behavior [C]// International Conference on Pattern Recognition,Hong Kong,China,Aug 20-24,2006,1:1148-1153.
[10] Gunes H,Piccardi M. Bi-modal emotion recognition from expressive face and body gestures [J]. Journal of Network & Computer Applications(S1084-8045),2007,30(4):1334–1345.
[11] Gunes H,Piccardi M. Fusing face and body gesture for machine recognition of emotions [C]// IEEE International Workshop on Robot and Human Interactive Communication,Roman,Aug 13-15,2005:306-311.
[12] Hatice G,Massimo P. Automatic temporal segment detection and affect recognition from face and body display [J]. IEEE Transactions on Systems Man & Cybernetics Part B Cybernetics A Publication of the IEEE Systems Man & Cybernetics Society(S2168-2216),2009,39(1):64-84.
[13] 胡敏,许艳侠,王晓华,等. 自适应加权完全局部二值模式的表情识别 [J]. 中国图象图形学报,2013,18(10):1279-1284.
HU Min,XU Yanxia,WANG Xiaohua,Facial expression recognition based on AWCLBP [J]. Journal of Image and Graphics,2013,18(10):1279-1284.
[14] ZHAO Guoying,Pietikainen Matti. Dynamic Texture Recognition Using Local Binary Patterns with an Application to Facial Expressions [J]. IEEE Transactions on Pattern Analysis & Machine Intelligence(S1939-3539),2007,29(6):915-928.
[15] 桑庆兵,李朝锋,吴小俊. 基于灰度共生矩阵的无参考模糊图像质量评价方法 [J]. 模式识别与人工智能,2013,25(05):492-497.
SANG Qinbing,LI Zhaofeng,WU XiaojunNo-Reference Blurred Image Quality Assessment Based on Gray Level Co-occurrence Matrix [J]. Pattern Recognition and Artificial Intelligence,2013,25(05):492-497.
[16] 李先锋,朱伟兴,孔令东,等. 基于SVM和D-S证据理论的多特征融合杂草识别方法 [J]. 农业机械学报,2012,42(11):164-168.
LI Xianfeng,ZHU Weixing,KONG Lindong,Method of Multi-feature Fusion Based on SVM and D- S Evidence Theory in Weed Recognition [J]. Transactions of the Chinese Society for Agricultural Machinery,2012,42(11):164-168.
[17] 王晓华,金超,任福继,等. Dempster-Shafer证据融合金字塔韦伯局部特征的表情识别[J]. 中国图象图形学报,2014,19(9):1297-1305.
WANG Xiaohua,JIN Chao,REN Fuji,Research on facial expression recognition based on pyramid Weber local descriptor and the Dempster-Shafer theory of evidence [J].Journal of Image and Graphics,2014,19(9):1297-1305.
Dual-modality Emotion Recognition Model Based on Temporal-spatial LBP Moment and Dempster-Shafer Evidence Fusion
WANG Xiaohua1,HOU Dengyong2,HU Min1,REN Fuji1,2,WANG Jiayong1
( 1. School of Computer and Information of Hefei University of Technology, Anhui Province Key Laboratory of Affective Computingand Advanced Intelligent Machine, Hefei 230009, China;2. University of Tokushima, Graduate School of Advanced Technology &Science, Tokushima 7708502, Japan )
To overcome the deficiency of high complexity performance in video emotion recognition, we propose a novel Local Binary Pattern Moment method based on Temporal-Spatial for feature extraction of dual-modality emotion recognition. Firstly, preprocessing is used to obtain the facial expression and posture sequences. Secondly, TSLBPM is utilized to extract the features of the facial expression and posture sequences. The minimum Euclidean distances are selected by calculating the features of the testing sequences and the marked emotion training sets, and they are used as independent evidence to build the Basic Probability Assignment (BPA). Finally, according to the rules of Dempster-Shafer evidence theory, the expression recognition result is obtained by fused BPA. The experimental results on the FABO expression and posture dual-modality emotion database show the Temporal-Spatial Local Binary Pattern Moment feature of the video image can be extracted quickly and the video emotional state can be effectively identified. What’s more, compared with other methods , the experiments have verified the superiority of fusion.
video emotion recognition; dual-modality emotion recognition; temporal-spatial lbp moment; Dempster- Shafer evidence theory
1003-501X(2016)12-0154-08
O438
A
10.3969/j.issn.1003-501X.2016.12.024
2016-01-28;
2016-05-11
国家自然科学青年基金项目(61300119);国家自然科学基金重点项目(61432004);安徽省自然科学基金项目(1408085MKL16)
王晓华(1976-),女(汉族),河南漯河人。博士,副教授,硕士生导师,主要研究方向为数字图像处理、情感计算等。E-mail:xh_wang@hfut.edu.cn。
