计算机海量数据处理SLIQ算法研究
2016-10-12高华
高 华
(大连艺术学院 文化艺术管理学院, 辽宁 大连 116600)
计算机海量数据处理SLIQ算法研究
高华
(大连艺术学院 文化艺术管理学院, 辽宁 大连116600)
探讨云计算在SLIQ算法中的应用,研究结果显示,云计算下的SLIQ算法能够对计算机海量数据存储中的节点失效问题有效解决,并且显著提升计算机数据处理效率,进一步降低数据处理难度与复杂度,还可以快速挖掘海量数据信息。
云计算; 海量数据;SLIQ算法
0 引 言
数据挖掘中的海量数据处理及计算是不可忽视的问题,处理技术及海量计算直接影响到数据挖掘速度,以前主要是针对小规模数据量采取相应的计算方法,而现在数据量有了显著增加,还使用原来计算方法将极大地降低计算速度,数据挖掘也无法正常进行,这是数据挖掘过程中存在的问题[1]。云计算加入其中将能够很好地解决这个问题,能够有效地对海量数据信息进行处理,提升了数据处理速度。云计算能够以更为快捷的方式向用户提供相应的计算资源,提升云计算下的计算机处理能力,减少用户终端的数据处理负担,简化计算机数据终端,使其成为一种输入输出设备,云计算的计算处理能力非常强大,能够满足用户的多种需求[2]。其中云计算涉及内容主要有网络计算、并行计算以及分布式计算等,它借助了网络方式整合一些较低的计算实体,最终使用户终端具备强大的计算能力,经过商业模式得到推广应用[3]。云计算下的并行SLIQ算法指的是在云计算技术平台基础上构建分布式时空数据库,并建立具有海量数据计算机系统的数据挖掘模型,而且在云计算技术下,计算机海量数据不容易出现成批或成片丢失、错误状况,有效地解决了海量数据存储中的节点失效几率,提高了计算机数据的安全性。其中云计算技术下海量数据挖掘系统主要分为四层,分别是平台应用层、数据分析中间件层、分布式计算层以及分布式文件系统层。
不同层的具体作用如图1所示。
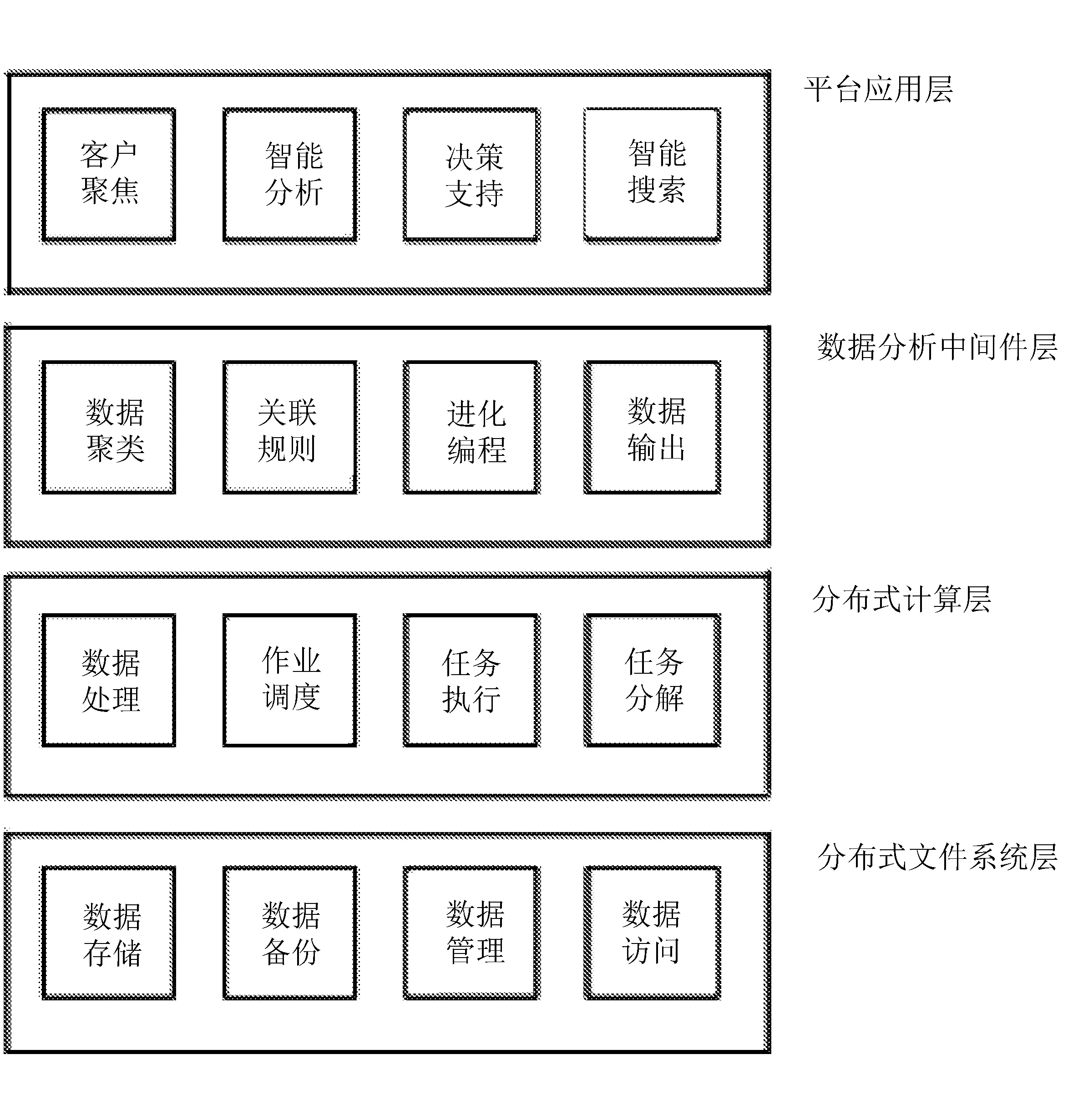
图1云计算技术下海量数据挖掘系统体系架构
1 计算机海量数据处理中SLIQ算法和改进设计
1.1SLIQ算法分析
SLIQ算法最早在1996年提出,是一种用来对数据进行挖掘与分类的算法,旨在对那些数据量巨大且不能够全部进内存的数据进行处理,迅速而准确地完成决策树需求。预排列思路在这种算法中得到了极大体现,解决了数据量大、无法存入磁盘的数据排序问题,离散及连续字段也得到了很好处理。产生决策树时,应使用预排序技术,降低数值性属性及消耗资源,进而提升海量数据的处理速度。刚开始处理数据时,应将所有样本划分成属性节点,扫描每个数据集合,构建属性列表,同时还要构建一个类别表[4]。因为数据样本与属性表中的记录内容全都是一一对应的,因此,可以将样本数值与类表索引存储起来,根据属性值对连续型属性表格中的数据进行排列组合。每个样本类型表中的类别标签与决策树节点索引值都需要存储起来,并只能存储在内存中[5]。SLIQ算法应用于决策树叶节点存储类型图中时,对需要分类判断信息进行统计,将属性类别表依据类别及频率构成二元组。决策树算法以往多使用构造优先方式,扫描每个节点并完成节点分裂工作,而SLIQ算法则利用了广度优先方式构建决策树,扫描每层节点上的属性表,找到当前最优的分裂方式。对形成新节点的分裂属性取值,并更新相应列表类型中的节点信息,SLIQ算法在计算最佳分裂点方面是折中方案,属性取值如果是小于某个阀值,应做到遍历子集选择方案,如果大于其值,应该找到最佳分割点近似解[6]。
1.2SLIQ在MapReduce中的改进
SLIQ算法的改进是在MapReduce编程模式基础上的,详细的改进步骤如下:
1)使用MapReduce函数记录所有根节点数据,并对其划分,集合产生的M个规模相似的子数据,将数据块划分成InputSplit。
2)格式化处理划分产生的多个数据子集,出现的对应的
3)实施Map操作主要是扫描输入记录,并划分归类输入记录,归结好key相同的,将其写入对应文件中,还要借助模计算配置文件到特定的Reduce中。
4)将有一定顺序的连续行数据段进行排序,并画出直方图,设定初始阶段为零,每个Reduce对应任务是极端分裂点的Giniindex值,类对应直方图应该实时更新;离散对应数据不需要排序,也不需要更新直方图。数据进行过第一次扫描后,能够使用类直方图,将自己对应的Giniindex值计算出来。
5)Reduce的不同操作中,还会依据分裂点生成哈希表,这个表能够转化成键值相对应的数据结构:
6)分裂点完成后,需要比较输出Reduce,将最小Giniindex数值对应属性及分裂点选择出来,还要选择相应的哈希表将其作为分裂的原始数据表,将上述这些及节点N产生的N1及N2节点一同放入集合中去。
对于Hadoop分布式云计算环境且基于高性能计算机系统而言,结合命名节点的形式,也即是Namenode,其中数据节点主要有12个,也即是Datanode,任一数据节点中的各种节点应用,结合6路四核刀片的形式。通过应用Linux操作系统,并应用Redhat5.5系统结构,应用Hadoop版本模式,注重分布式环境的部署,将后台进程启动,并对相关例程运行,将集群启动进而实现计算的过程。
对于分布式文件系统层而言,主要是结合HadoopHDFS将高可靠的一种分布式数据文件存储功能实现。在电子商务平台中海量数据的分布存储过程中实现多台计算机集群处理,并做好文件的有效性分块存储,将容错自动分块复制功能实现。这种平台上的一种HDFS管理节点的实现过程,结合12个数据节点构成。节点管理过程对管理文件系统的名字空间进行负责,在客户端文件的访问中,实现数据节点数据存储的应用,对客户端读写请求及时处理,做好数据块的有效性创建以及删除,实现数据块的基础复制。在HDFS这种上层分布式的一种计算层应用,将数据输入提供,并结合中间结果的实现,将数据载体充分实现,并对可伸缩性的具体优势充分发挥,在业务系统的联系阶段实现分布式文件系统的有效性管理以及访问。
对于分布式计算层而言,在MapReduce中相关模式的应用,结合分布式并行计算模型的应用,做好数据的有效性挖掘,尽可能地结合任务分布式的主要形式,实现数据节点的合理调度计算,并做好海量数据的有效性处理和分析。在数据分析中间件层的分析过程,将实现聚类分类的一种协同过滤数据挖掘算法,这种允许扩展的应用过程实现了平台应用层业务相关需求分析,对钢化膜电子商务平台中的一种Mahout算法库进行定制,在服务形式的结合下,实现应用层的基础调用和分析。这种云计算平台中的一种Hadoop应用,将云计算中的一种中间件进行协调和整合。对于平台应用层的相关分析,将实现原材料信息分析模式,基于竞价参考的形式,结合目标客户的一种聚焦过程,实现商业智能分析,在决策性的支持应用过程中,结合智能搜索的基础应用,将采用电子商务应用模式,进而有效满足了钢化膜电子商务的业务需求。
在SLIQ算法中,则一定要具有预排序及广度优先增长策略,同时再将其最佳分割计算出来的时候,也就会有新的子节点产生,之后则需要更新对类表,将其和之前的节点子节点相对应,具体的算法代码则如下:
UpdateLabels()
foreachattributeAusedInasplitdo
traverseattributelistofA
foreachvaluevintheattributelistdo
findthecorrespondingentryintheclasslist(saye)
findthenewclassctowhichvbelongsbyapplyingthe
splittingtestatnodereferencedfrome
updatetheclasslabelforetoc
updatenodereferencedinetothechildcorrespondingto
theclassc
SLIQ算法在实际应用中计算过程不但复杂,还必须不断更新,一方面影响计算效率,另一方面也影响实际应用价值。
2 云计算在计算机数据处理中的SLIQ算法中的应用
2.1构建云服务平台
云计算技术现在日益发展,已经应用在数据处理中的SLIQ算法,基于云计算的计算机海量数据处理中的SLIQ算法则需要涉及到“云服务”,那么也就需要进行云服务平台构建,基于计算机公共标准及开发网络平台,对计算机数据资源进行有效分类、管理,为云端数据安全性提供有效保障,并基于用户实际需求提供云服务,从而满足用户实际需求,并提高数据平台开发质量,充分发挥计算机在数据处理中的应用价值。云服务平台构建时,应选择合适的数据分析模型关联规则,并在此基础上构建数据仓库,实现关于数据清理、消减以及转换等各种操作,SLIQ算法在云计算技术中的有效应用,能够显著提升数据管理质量。
2.2云计算下服务分层细化
云计算技术在数据处理硬件设计中具有重要应用价值,同时也和 “云端”、计算机系统和局域网等形式具有关联,以此显著提高数据系统硬件开发质量。云计算功能在硬件开发中的应用对于计算机数据处理速度有显著提升作用,同时也可以有效防范重复开发现象的呈现;同时在内存管理中也能够有效满足用户需求,显著提高虚拟存储管理能力,实现任务调度在软件设计过程中其创建新任务的功能,在进行服务分层过程中,也必须要具有中断管理、时间管理功能,在云计算数据处理基础上,同时也一定要完成基础编程始时钟程序的构建。
2.3云计算下的SLIQ算法实现
SLIQ算法中关于云计算技术的应用,主要是在MDL剪枝原理、编码数据的基础上生成的初始树,对其训练集S的子树T确定,在此基础上能够有效提高计算机系统在应用中的数据处理能力。但是在SLIQ算法中还有问题,例如SLIQ算法中,类别列表存在于内存中,在云计算过程中,因为计算机内存具有一定限制,所以对于数据集大小也具有影响。
在云计算环境下SLIQ算法主要应用的是预排序技术,本身这种算法就比较复杂,同时还需要受到数据结构线性的可伸缩性限制。在进行数据库内数据转换的时候,第一步则需要对数据具体参数及定义等基础内容确定;第二步是预排列数据,这里以部分学生的成绩为例,进而确定数据结构及树节点信息,得到的类型字段直方图如图2和图3所示。
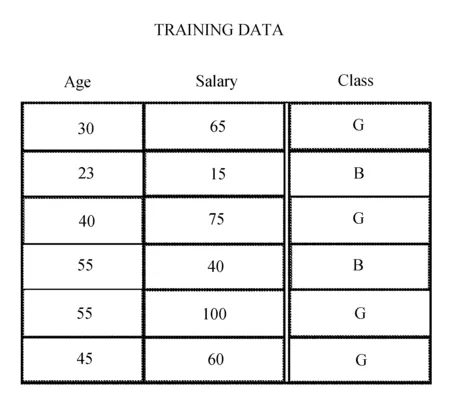
图2 数据结构
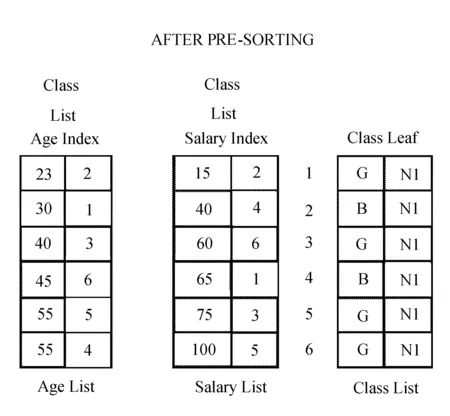
图3 直方图
在SLIQ算法基础上,需要依照数据处理的实际需要实现SLIQ算法改进,以此减少对云计算决策树中每个节点指数频繁计算,降低每个节点计算的复杂性,以此显著提升计算结果分类效果。云计算技术决策树建立过程中,最大信息增益值算法代码可以编写出来,而且建树过程中,必须要对“确定最佳分裂”的可伸缩性显著提升,对多耗费的开销计算降低,最后明确数值型字段,并在此基础上确定最佳子集[7]。之后在独立数据集的应用基础上,获取导致错误率最低,并且准确度高的决策树。最后依照所得决策树遍历整个程序,得出海量数据的计算处理结果。
其中云计算决策树中每个节点的指数计算如图4所示。
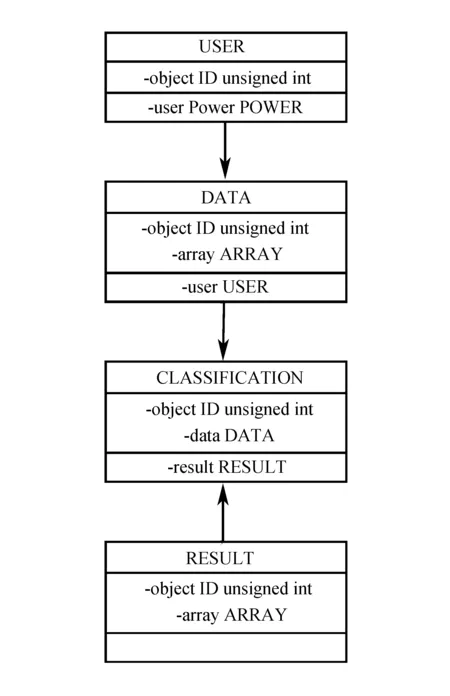
图4 类图
2.4效益分析
分析基于云计算的计算机海量数据处理中的SLIQ算法效益,这里使用的SLIQ算法处理数据,对之前海量数据管理模式有显著改善,传统的手工管理工作均可以借助于计算机技术实现网络化管理,显著提升数据处理效果及安全性。对于云计算在海量数据中的应用,则能够显著提高数据处理方便性及安全性,在互联网上不管是硬件还是软件资源均能够实现自由流通,降低了数据丢失问题发生率,并显著降低了计算机海量数据处理人员的工作量,数据设备、处理管理得到了加强,开支有效地被缩小,工作效率及准确率得到了极大提升[8]。
3 结 语
实施数据处理的重要技术是云计算,基于云计算下的海量数据处理中用到了SLIQ算法,它能够处理不同数据类型及格式的信息,计算机数据处理难度也随之降低,处理效率随之提高,是一种先进的信息技术。文中重点分析云计算下的计算机海量数据处理中的SLIQ算法,首先,明确云计算技术的特点及优势;然后,分析数据处理中的SLIQ算法并给予改进;最后,将云计算技术应用在数据处理中的SLIQ算法中,实现计算机的快速查询与处理。
[1]杨长春,沈晓玲.基于云计算的SLIQ并行算法研究[J].计算机工程与科学,2012,34(3):62-66.
[2]李晓飞.云计算环境下Apriori算法的MapReduce并行化[J].长春工业大学学报:自然科学版,2013,34(6):736-740.
[3]耿家礼,王会颖.云计算技术在数据SLIQ算法中的应用[J].通化师范学院学报,2015,36(10):8-10,93.
[4]余先昊.计算机海量数据SLIQ算法中云计算技术的应用研究[J].科学导报,2015(10):257.
[5]王嘉佳.云计算技术在计算机海量数据SLIQ算法中的应用[J].数字通信世界,2015(10):251-251,317.
[6]毕丛娣.关于“云计算”的探究[J].长春工业大学学报:自然科学版,2011,32(4):413-416.
[7]王晓嘉,余建坤.基于类标签变化的改进SLIQ算法研究[J].微型电脑应用,2015(10):27-31.
[8]张薇.一种基于改进SLIQ决策树分类算法的应用研究[J].苏州大学学报:工科版,2010,30(1):72-77.
SLIQ algorithms in massive data processing
GAO Hua
(School of Management, Dalian Art College, Dalian 116600, China)
TheapplicationofcloudcomputinginSLIQalgorithmshowthatitcansignificantlysolvenode-failureproblemindatastorage,improvetheprocessingefficiencyandsimplifythedatacalculation.Alsomassivedatainformationcanbemined.
cloudcomputing;massivedata;SLIQalgorithm.
2016-03-20
辽宁省教育厅科研课题(W2012253)
高华(1975-),女,汉族,辽宁大连人,大连艺术学院副教授,硕士,主要从事计算机应用技术及电子商务方向研究,E-mail:gao_hua@foxmail.com.
10.15923/j.cnki.cn22-1382/t.2016.4.18
TP312
A
1674-1374(2016)04-0406-05
