用于不平衡数据分类的模糊支持向量机算法
2016-10-12鞠哲,曹隽喆,顾宏
鞠 哲, 曹 隽 喆, 顾 宏
( 大连理工大学 控制科学与工程学院, 辽宁 大连 116024 )
用于不平衡数据分类的模糊支持向量机算法
鞠 哲,曹 隽 喆,顾 宏*
( 大连理工大学 控制科学与工程学院, 辽宁 大连116024 )
作为一种有效的机器学习技术,支持向量机已经被成功地应用于各个领域.然而当数据不平衡时,支持向量机会产生次优的分类模型;另一方面,支持向量机算法对数据集中的噪声点和野点非常敏感.为了克服以上不足,提出了一种新的用于不平衡数据分类的模糊支持向量机算法.该算法在设计样本的模糊隶属度函数时,不仅考虑训练样本到其类中心距离,而且考虑样本周围的紧密度.实验结果表明,所提模糊支持向量机算法可以有效地处理不平衡和噪声问题.
支持向量机;模糊支持向量机;模糊隶属度;不平衡数据;分类
0 引 言
支持向量机(support vector machine,SVM)是建立在统计学习中的VC维理论和结构风险最小化原则基础上的一种机器学习方法,能有效地处理小样本、高维数据、非线性等问题.作为一种常用的机器学习技术,SVM[1-2]已经被成功地应用到各种实际分类问题中.然而,真实的数据集常常含有噪声或野点.传统的SVM算法等同地对待所有训练样本并赋予它们统一的权值,因此SVM算法对训练样本中噪声和野点非常敏感[3].为了克服噪声数据对SVM分类结果的影响,Lin等[4]首次提出了模糊支持向量机(FSVM) 算法.在FSVM算法中,训练集中不同的训练样本被赋予不同的模糊隶属度(即权值)来衡量样本对分类器的重要程度.Lin等[4]认为如果一个样本离其类中心越近,那么它就越有可能属于该类,需分配给该样本一个较高的模糊隶属度;相反,如果这个样本远离其类中心,那么它就越有可能是噪声或野点,需分配给该样本一个较小的模糊隶属度.FSVM算法是对传统SVM算法的一种改进,在一定程度上降低了SVM算法对噪声或野点的敏感度.然而,FSVM算法在设计模糊隶属度时只考虑了样本到其类中心的距离作为衡量样本的重要性指标.对于不规则分布的数据集,这种方法可能会将噪声样本当作正常样本进行训练,因而影响了算法的精度.随后,一些改进的FSVM算法被相继提出,如文献[5]利用核方法将FSVM算法在核空间中实现;文献[6]提出了一种基于样本间紧密度的FSVM算法;文献[7]提出了一种利用样本到其类内超平面来设计模糊隶属度的FSVM 算法;文献[8]提出了一种基于类向心度的改进FSVM算法,算法在设计模糊隶属度时不仅考虑到样本到类中心的距离,而且考虑到样本之间的内在联系.
此外,尽管SVM算法在平衡数据集上具有良好的性能表现,但当数据不平衡时SVM算法的分类效果不佳.SVM算法偏向于保证多数类的分类精度,而在少数类上分类效果往往较差.目前,许多算法被用来处理基于不平衡数据的分类问题,以便提高SVM算法在不平衡数据集上的分类性能.从数据层面,将SVM算法和欠采样或过采样技术相结合来平衡正负类的样本比例[9].但采样方法实际上通过增加少数类样本或减少多数类样本来调整数据集的不平衡性,具有一定的盲目性,结果的稳定性难以得到保证,而且不适用于不平衡比例较大的数据集.从算法层面,对SVM算法本身进行改进来处理不平衡数据分类.如文献[10]提出了一种基于实例重要性的不平衡SVM分类算法.算法首先将数据按其重要性排序,选择最重要的数据训练初始分类器,然后算法循环迭代.该算法在数据样本太大或太小时效果较差.文献[11]通过赋予正负类样本不同的惩罚因子(different error costs,DEC)来降低不平衡数据给SVM算法带来的影响.一个简单有效的处理方法是将惩罚因子直接设置为正负类数据的不平衡比率[12].文献[13]提出了一种改进近似支持向量机算法,该算法不仅赋予正负类样本以不同的惩罚因子,且在约束条件中增加新的参数,使分类面更具灵活性,提高了算法精度.
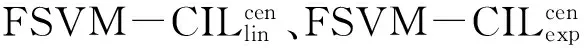
1 SVM简介
对于二分类问题,SVM的基本思想就是在样本(核)空间寻找一个最优超平面,使得两类样本的分类间隔达到最大.给定训练集(X,T)={(xi,ti),i=1,2,…,l},其中xi为样本,ti为样本xi的标签,ti∈{-1,1};引入非线性映射Φ(x),将训练集映入高维空间(Φ(X),T)={(Φ(xi),ti),i=1,2,…,l};选取适当的核函数K(x,y)=Φ(x)TΦ(y);引入松弛变量ξi≥0,i=1, 2, …,l.标准支持向量机的一般形式可以表示为

s.t.ti(ωTΦ(xi)+b)≥1-ξi
ξi≥0,i=1,2,…,l
(1)
求解优化问题(1)的对偶问题:
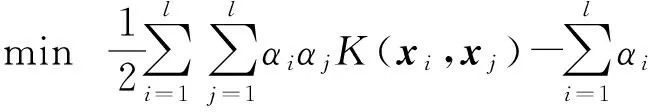
0≤αi≤C, i=1,2,…,l
(2)
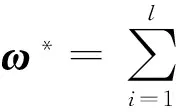
2 用于不平衡数据分类的FSVM算法
传统的SVM算法认为,每一个样本的重要性是相同的,算法分配给每一个样本相同的权值.在实际应用中,数据往往是不平衡的,而且包含噪声.因此,一个合理的做法是根据样本不平衡性和样本重要性来分配不同的权值.对于二分类问题,给定训练集(X,T)={(xi,ti),i=1,2,…,l},其中xi为样本,ti为样本xi的标签,ti∈{-1,1}.不失一般性,假设前p个样本是正类样本(即ti=1,i=1,2,…,p),剩下后l-p个样本是负类样本(即ti=-1,i=p+1,p+2,…,l).不平衡FSVM的一般形式可以表示为
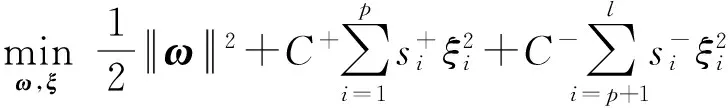
s.t.ti(ωTΦ(xi)+b)≥1-ξi
ξi≥0,i=1,2,…,l
(3)
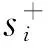
2.1模糊隶属度设计
在文献[4]中模糊隶属度被定义为

(4)

(5)

图1 带有一个噪声点的椭圆分布数据示意图
基于上述观察,本文除了考虑样本到类中心的距离,还将样本周围的紧密度作为设计模糊隶属度的依据.一个简单的K-近邻准则用来衡量样本的紧密度.如图1所示,噪声点x5到其3-近邻{x6,x7,x8}的平均距离要远远大于正常样本点x1到其3-近邻{x2,x3,x4}的平均距离.因此,对于一个正样本xi,它周围的紧密度可以定义为
(6)
(7)


i=1,2,…,p
(8)

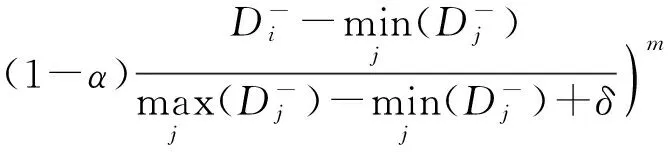
i=p+1,p+2,…,l
(9)
其中α∈[0,1],m>0,δ是一个很小的正数来保证分母大于0.在本文中,δ取值为0.000 1,α的选择范围是{0,0.1,…,1.0},m的选择范围是{0.1,0.2,…,1.0}.此外,为了节省算法的训练时间,本文模糊隶属度中K统一设置为10.
2.2惩罚因子设置
一般来说,DEC算法[11]通过赋给少数类以较大的权值、多数类以较小的权值,可以有效地减小不平衡性对SVM算法的影响.然而DEC算法中,没有根据样本的重要性对类内样本加以区分,使得DEC算法很容易受到噪声或野点的影响.而本文将模糊隶属度和惩罚因子结合起来,不仅可以较好地处理不平衡数据分类问题,而且可以克服噪声数据对SVM分类结果的影响.根据文献[11-12]的结果,当C+/C-设置为多数类与少数类样本个数的比值时,SVM算法可以得到较好的分类结果.本文中惩罚因子C+设置为C(l-p)/p,C-设置为C(C> 0).
3 实验与结果分析
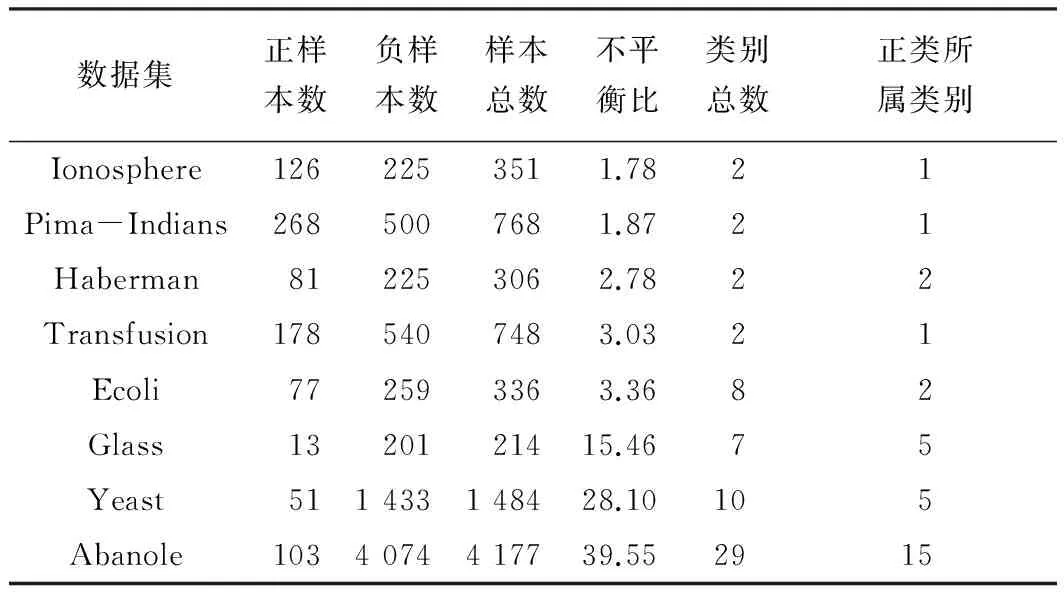
表1 UCI数据集及其相关属性
采用3个常用的分类器性能评价指标用来评价算法的表现,分别是敏感性Sn、特异性Sp和几何平均值Gm,定义如下:
(10)
(11)
(12)
其中Tp、Tn、Fp和Fn分别表示真阳性样本个数、真阴性样本个数、假阳性样本个数和假阴性样本个数.Sn和Sp分别反映了分类器正确预测正负类样本的比率,显然Sn和Sp的值越大表明分类器性能越好.然而Sn和Sp相互制约,尤其当数据不平衡时,很难同时用这两个指标反映分类器的性能.于是引入它们的几何平均值Gm来反映分类器在不均衡数据上的性能.Gm的值越大,表明分类器的综合性能越好.
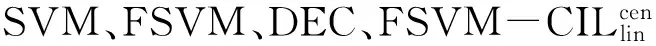

表2 8个UCI数据集上的分类结果比较

表3 各种算法在8个UCI数据集上的最优参数
4 结 语
本文提出了一种新的用于不平衡数据的FSVM 算法.该算法不仅可以有效地降低不平衡数据对SVM造成的影响,而且可以降低数据中噪声和野点的干扰,进而提高分类器精度.UCI数据集上的数值实验验证了该分类方法的有效性.然而需要指出的是,该算法在提升分类精度的同时,需要优化的参数也随之增多.下一步的研究工作是设计有效的参数选择策略来缩短算法的训练时间.
[1]Vapnik V N. The Nature of Statistical Learning Theory [M]. New York:Springer, 1995.
[2]Cristianini N, Shawe-Taylor J. An Introduction to Support Vector Machines and Other Kernel-based Learning Methods [M]. Cambridge:Cambridge University Press, 2000.
[3]ZHANG Xue-gong. Using class-center vectors to build support vector machines [C] // Proceedings of the 1999 IEEE Signal Processing Society Workshop. Madison:IEEE, 1999:3-11.
[4]LIN Chun-fu, WANG Sheng-de. Fuzzy support vector machines [J]. IEEE Transactions on Neural Networks, 2002, 13(2):464-471.
[5]JIANG Xiu-feng, YI Zhang, LV Jian-cheng. Fuzzy SVM with a new fuzzy membership function [J]. Neural Computing & Applications, 2006, 15(3):268-276.
[6]张 翔,肖小玲,徐光祐. 基于样本之间紧密度的模糊支持向量机方法[J]. 软件学报, 2006, 17(5):951-958.
ZHANG Xiang, XIAO Xiao-ling, XU Guang-you. Fuzzy support vector machine based on affinity among samples [J]. Journal of Software, 2006, 17(5):951-958. (in Chinese)
[7]杜 喆,刘三阳,齐小刚. 一种新隶属度函数的模糊支持向量机[J]. 系统仿真学报, 2009, 21(7):1901-1903.
DU Zhe, LIU San-yang, QI Xiao-gang. Fuzzy support vector machine with new membership function [J]. Journal of System Simulation, 2009, 21(7):1901-1903. (in Chinese)
[8]许翠云,业 宁. 基于类向心度的模糊支持向量机[J]. 计算机工程与科学, 2014, 36(8):1623-1628.
XU Cui-yun, YE Ning. A novel fuzzy support vector machine based on the class centripetal degree [J]. Computer Engineering and Science, 2014, 36(8):1623-1628. (in Chinese)
[9]Estabrooks A, Jo T, Japkowicz N. A multiple resampling method for learning from imbalanced data sets [J]. Computational Intelligence, 2004, 20(1):18-36.
[10]杨 扬,李善平. 基于实例重要性的SVM解不平衡数据分类[J]. 模式识别与人工智能, 2009, 22(6):913-918.
YANG Yang, LI Shan-ping. Instance importance based SVM for solving imbalanced data classification [J]. Pattern Recognition and Artificial Intelligence, 2009, 22(6):913-918. (in Chinese)
[11]Veropoulos K, Campbell C, Cristianini N. Controlling the sensitivity of support vector machines [C] // International Joint Conference on AI. Stockholm:IJCAI Press, 1999:55-60.
[12]Batuwita R, Palade V. Class imbalance learning methods for support vector machines [M] // HE Hai-bo, MA Yun-qian, eds. Imbalanced Learning:Foundations, Algorithms, and Applications. Hoboken:Wiley-IEEE Press, 2013:83-99.
[13]刘 艳,钟 萍,陈 静,等. 用于处理不平衡样本的改进近似支持向量机新算法[J]. 计算机应用, 2014, 34(6):1618-1621.
LIU Yan, ZHONG Ping, CHEN Jing,etal. Modified proximal support vector machine algorithm for dealing with unbalanced samples [J]. Journal of Computer Applications, 2014, 34(6):1618-1621. (in Chinese)
[14]Batuwita R, Palade V. FSVM-CIL:Fuzzy support vector machines for class imbalance learning [J]. IEEE Transactions on Fuzzy Systems, 2010, 18(3):558-571.
[15]Chang C C, Lin C J. LIBSVM:A library for support vector machines [J]. ACM Transactions on Intelligent Systems and Technology, 2011, 2(3):27.
A fuzzy support vector machine algorithm for imbalanced data classification
JUZhe,CAOJun-zhe,GUHong*
( School of Control Science and Engineering, Dalian University of Technology, Dalian 116024, China )
As an effective machine learning technique, support vector machine (SVM) has been successfully applied to various fields. However, when it comes to imbalanced datasets, SVM produces suboptimal classification models. On the other hand, the SVM algorithm is very sensitive to noise and outliers present in the datasets. To overcome the disadvantages of imbalanced and noisy training datasets, a novel fuzzy SVM algorithm for imbalanced data classification is proposed. When designing the fuzzy membership function, the proposed algorithm takes into account not only the distance between the training sample and its class center, but also the tightness around the training sample. Experimental results show that the proposed fuzzy SVM algorithm can effectively handle the imbalanced and noisy problem.
support vector machine (SVM); fuzzy support vector machine; fuzzy membership; imbalanced data; classification
1000-8608(2016)05-0525-07
2016-03-30;
2016-04-11.
国家自然科学基金资助项目(61502074,U1560102);高等学校博士学科点专项科研基金资助项目(20120041110008).
鞠 哲(1986-),男,博士生,E-mail:juzhe1120@hotmail.com;顾 宏*(1961-),男,教授,博士生导师,E-mail:guhong@dlut.edu.cn.
TP181
A
10.7511/dllgxb201605013
