基于自然语言处理的计算机专业数学课程教学研究
2016-10-10何苑郝梦岩
何苑,郝梦岩
(长治学院计算机系,山西长治046011)
基于自然语言处理的计算机专业数学课程教学研究
何苑,郝梦岩
(长治学院计算机系,山西长治046011)
针对计算机专业相关数学课程教学中存在的学生学习难度大、兴趣不高的问题,从数学方法在自然语言处理方面的应用入手,讨论了将相关数学概念、方法与应用相结合的教学方法。教学实践表明,口述方法可激发学生学习兴趣,改善教学效果。
计算机专业;数学课程;自然语言处理;推荐系统;教学研究
1 引言
计算机科学与技术的相关专业基础课程中有多门数学基础课程,如高等数学Ⅰ、高等数学Ⅱ、线性代数、概率统计及离散数学等,学生在这些课程的学习过程中普遍存在学习难度大、兴趣不高的问题。学生只有在进入研究生阶段的学习或在工作当中才逐渐体会到数学作为一种工具的作用。如何在有限的课时内,既做到数学抽象思维能力的培养又能和专业应用较好地结合,引入难易复杂程度适中而且学生易于理解的应用问题,一直是相关数学课程教学中的难点。而计算机科学是一门从实践中发展提炼出来的学科,自然语言处理作为其中的研究方向之一,包含许多以这些数学概念和方法为基础的相关内容。
2 自然语言处理领域的应用
针对上述问题,文章从自然语言处理方面的相关研究入手,把这些课程中包含的如线性代数中的“向量计算”、概率论中的“条件概率”、离散数学中“图论”、“布尔代数”等基本内容与自然语言处理领域中的应用联系起来[1],加深学生概念理解的同时,培养其理论联系实际的能力,激发其学习兴趣。同时在地方性高校向应用型大学转型过程中,如何将应用和理论的有机结合的课程教学改革探索,具有十分重要的现实意义[2]。
2.1推荐系统和向量计算
在线性代数课程中,通过向量概念和各种定理的学习,要求学生掌握基于向量运算的线性方程组的求解方法,并在随后的数值分析课程中学习了各种求解线性方程组的近似算法。学生在学习的过程中往往局限于对各种定义定理的记忆,并不能很好理解这些定义和定理在实际应用中的意义。而在计算机应用的研究中存在大量相关的应用,例如图形图像处理中特征值和特征向量的运用、向量计算机的研制等,在自然语言处理领域,许多应用问题都可以转化成对向量的处理。
在移动互联普及应用的今天,推荐系统已经融入了学生的生活当中,作为一个成熟商业系统的标准配置之一,也是学生日常接触较多非常容易理解的一个应用[3]。通过推荐系统,学生可以找到和自己兴趣相同的人群,或者找到适合自己的书籍、音乐、电影等各种产品。
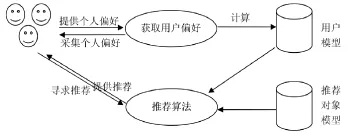
图1 推荐系统通用模型
推荐系统的通用模型如图1所示,各种推荐系统的基础是各类对象的相似性,这种相似性既可以是指用户已购买产品和其他未购买产品的相似性,也可以是与其他用户兴趣品味的相似性。在将对象进行向量化表示后,可以通过对向量距离的度量来进行计算。基于用户相似度的算法中,用户的属性可以用一个特征向量来表示,特征向量中元素的值可以用用户对已购买商品的评分来表示,而未购买商品则可以表示为0。用户相似度计算转化为代表用户属性的特征向量相似性的计算。简单的计算向量距离的方法有标准化欧式距离和表示两个向量相似程度的余弦夹角[4]。
2.2图论和网络爬虫
在离散数学课程中,要求学生理解许多图论方面的相关定义和定理,掌握用各种矩阵表示图的方法,并学习一些特殊图如欧拉图、汉密尔顿图的判定定理。同时在数据结构课程中对图的实现和遍历做了进一步的学习。在这些学习的过程中,学生往往侧重于对定义定理的记忆,对于其在实际生活中的应用并不是特别的清楚,因此影响了学习的效果。
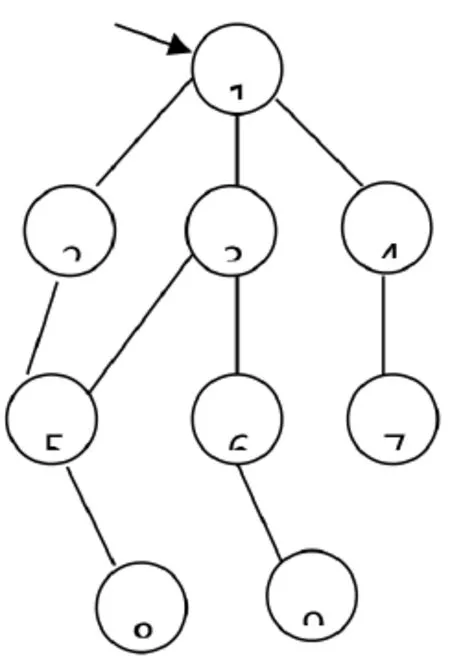
图2 反映页面链接关系的图
谷歌、百度等搜索引擎是学生在学习生活中使用最多的一种互联网应用,其中就可以看到图论的应用。要通过搜索引擎在庞大的互联网上快速找到相关资源和内容的链接和页面,首要对所有网页进行搜集。负责该基础性工作的程序是网络爬虫,它是基于图论中的基本原理进行工作。网络爬虫在上万台通过高速互联网络连接的集群服务器上运行,完成对互联网页面的采集工作。在对如图2所示的由页面链接关系构成的图进行遍历时按其访问顺序的不同可分为宽度优先遍历和深度优先遍历两种遍历方法。
为了在有限的时间内采集尽可能多的重要页面,负责完成待下载网页优先级排序的调度系统就是基于这两种方法的特点实现的[5]。首先从网站设计的特点来说,重要的网页与首页的距离较普通网页更近一些,从这一点出发采用宽度优先遍历更容易抓取到重要页面。在图2中自顶向下页面的重要性逐级下降,因此页面采集的顺序应为1、2、3、4、5、6、7、8、9。但是从数万台机器组成的分布式的爬虫结构,采用深度遍历的方式能有效的能有效的降低网络通信成本,一台或几台服务器针对一个网站的进行专门下载。例如在图2所示结构中根据深度优先遍历由第1台服务器负责2、5、8节点,第2台服务器负责节点3、6、9,第3台服务器负责节点4和7。上述遍历策略通过不同的调度算法来实现。通过与一些实际问题的结合能使学生对于各种方法的特点及在实际应用中的效果有更好的了解。
2.3文献检索和布尔代数
在布尔代数的学习中,定义了对0和1两个元素的与、或和非三种运算,由于过于简单使得学生对于其解决问题的有效性有很强的质疑。但在实际应用中,该简单的理论却非常有效的解决了许多应用问题[6]。例如布尔代数将所有的数学运算通过转换成二值的布尔运算,通过开关电路实现,使得布尔代数成为数字电路的理论基础。同时在文献检索领域基于索引的布尔运算可以实现高效的查询。
在文献检索领域,可以通过判断用户输入的关键词是否在文献中出现,给予该文献一个逻辑值0(不出现)或1(出现)。当考虑多个关键词时,查询可以通过二值的布尔运算进行实现。基于索引结构可以加快上述运算的速度,其中最简单的索引结构由关键字及其是否出现在某篇文档中,出现记为1,未出现记为0。这样索引就表示为一个超长的二进制串,串的长度由文档的个数决定,而查询就变成了两个二进制串的布尔运算。
2.4网络垃圾检测和条件概率
在概率论与数理统计课程的教学中,学生往往停留在对概率、随机变量、参数估计和假设检验等各种定义和定理学习中,虽然有举例说明各种定义定理的使用,但由于专业相关性的缺乏,效果并不明显。在自然语言处理领域,基于统计的方法得到了广泛的应用并取得了非常好的效果。其中基于条件概率的朴素贝叶斯方法,由于其简洁性在分类问题中常作为一种基准方法被广泛采用。网络垃圾的检测如垃圾邮件检测、垃圾博客检测[7]、垃圾网页检测等作为二分类问题是非常好的实际应用。
朴素贝叶斯分类法[8]是基于条件概率的分类方法,使用朴素贝叶斯分类法进行按类别分类,其中二分类是最简单的分类。假定要决定样本X属于类别C1还是C2,首先在训练集计算类别C1和C2的各种特征的先验概率,在条件独立性假设的条件下通过全概率公式计算最大后验概率概率P(C1|X)、P (C2|X),即分别计算出X属于不同类别的概率,如果P(C1|X)>P(C2|X),则样本属于类别C1,否则属C2。图3描述了垃圾博客检测中朴素贝叶斯方法的训练和检测过程。
3 总结和展望
文章从自然语言处理方向应用的角度出发,通过在相关课程中引入推荐系统、搜索引擎、文献检索和网络垃圾检测中数学知识的应用,使学生对相关内容有了更好的理解。通过让学生在学习中体会数学作为一种工具在实际中的应用,特别是在计算机领域中解决实际问题中的应用,既可以提高学生理论与应用结合的能力,又能提高学生的专业素养,激发学生的学习兴趣,从而改善学习的效果。
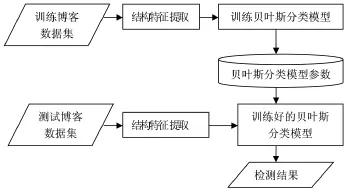
图3 基于朴素贝叶斯分类方法的训练及检测过程
[1]D.Manning,Hinrich Sch tze著.苑春法等译.统计自然语言处理基础[M].北京:电子工业出版社, 2007,(4):330-354.
[2]钟秉林.中国大学改革与创新人才教育[M].北京:北京师范大学出版社,2008,(1):1-5.
[3]孟祥武,胡勋,王立才,张玉洁.移动推荐系统及其应用[J].软件学报,2013,24(1):91-108.
[4]Haralambos Marmanis,Dmitry Babenko著,陈刚译, Algorithms of the Intelligent Web[M].北京:电子工业出版社,2011,(11):74-80.
[5]李晓明,闫宏飞,王继民.搜索引擎—原理、技术与系统[M].北京:科学出版社,2008,(4):45-47.
[6]吴军.数学之美[M].北京:人民邮电出版社,2012,(6):81-87.
[7]何苑,谭红叶.基于多结构特征的垃圾博客识别研究[J].计算机工程与设计.2010,(22):4932-4935.
[8]Jiawei Han,Kamber[M].范明,孟小峰,译.数据挖掘:概念与技术.北京:机械工业出版社, 2007,200-204.
(责任编辑张剑妹)
TP301
A
1673-2014(2016)02-0086-03
山西省高校科技开发项目(20121117);长治学院教学研究项目(2011205)。
2016—02—24
何苑(1981—),男,山西新绛人,讲师,硕士,主要从事中文信息处理和数据挖掘研究。
郝梦岩(1979—),女,山西武乡人,讲师,硕士,主要从事网络协议安全研究。
