一种高速URL过滤算法的研究与应用
2016-09-23黄诚
黄诚
(四川大学计算机学院,成都 610065)
一种高速URL过滤算法的研究与应用
黄诚
(四川大学计算机学院,成都610065)
0 引言
当前,大量涉黄涉暴网站盛行,同时每天有成千上万的网页更新、上线,传统的防火墙对于URL的过滤功能基于给定的规则库,并由管理人员去进行人工管理。因此,对于当前有害URL的过滤工作,当前传统防火墙显得能力不足。而且,当前的URL过滤算法设计相对简单,对于大量用户访问网站时,过滤效率明显不足。通过使用网络爬虫去爬取网页并对爬取得网页内容进行文本分析,从而建立黑、白名单,使得黑白名单的规模快速扩大,自动化的扩容黑白名单,减轻管理员的工作压力也使得过滤系统能够过滤更多的URL。
当黑白名单的容量过大时,简单的使用HashMap结构用于URL过滤,将无法满足系统对于实时性的要求。因此,设计出结合 Bloom Filter算法的改进HashMap结构,用于提高URL的过滤效率。由于URL地址在整个网络空间中是唯一的,根据这一特性,可以将其转化为另外一种表现方式。同时,一般情况下,存储URL长度会大于16字节,使用MD5对URL计算摘要值之后URL将转化为16字节长度的字符,可以明显的减少存储URL时所占用的内存,既节省空间,也能够提高URL的匹配效率,从而提高整个系统性能。
1 系统架构
本文中的URL过滤系统分为四个独立模块,分别为网络爬虫模块、文件缓冲区、敏感词过滤模块和URL过滤模块,模块间关系如下图所示:

图1
工作步骤如下:
网络爬虫模块:使用网络爬虫,从互联网上面去爬取网页,并将爬取回来的网页存放在文件缓冲区中,作为敏感词过滤模块的输入。
文件缓冲区模块:是在系统磁盘上开辟一块大的空白区域,用来存放网络爬虫爬取的网页内容,解决网络爬虫爬取网页速度过快与敏感词过滤模块处理速度不一致的问题。
敏感词过滤模块:将文件缓冲区中存放的网页进行敏感词过滤,结合给定的敏感词库判定相关联的URL是否非法,如果为非法则将结果添加到URL过滤模块的黑名单中,否则,将结果加入到URL过滤模块的白名单。
URL过滤模块:将黑白名单中的所有结果作为输入,使用MD5算法逐条对URL计算摘要值,将摘要值添加到改进的HashMap结构中,用于URL过滤。
2 URL过滤模型
当局域网中用户在浏览器中输入URL地址完毕,并向外发送请求之后,部署在网关设备将URL内容捕获,并将URL值传递给URL过滤模块,开始URL过滤过程,匹配流程如图2所示:
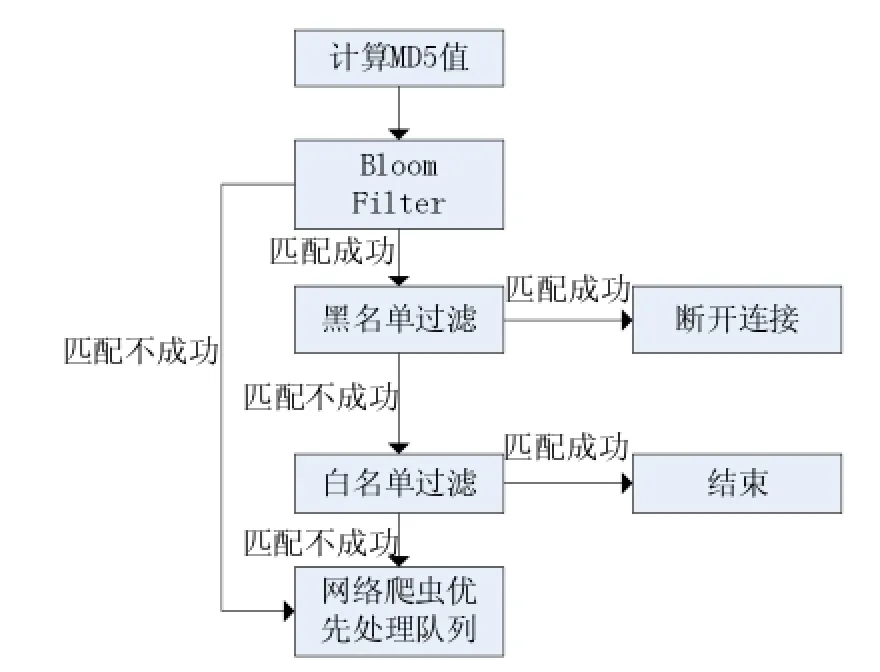
图2
URL过滤模块获取到输入之后,首先计算出MD5摘要值,将计算出的摘要值进行布隆过滤,如果匹配失败,表示该URL还未加入到黑白名单中,直接将该URL放入网络爬虫优先处理队列;否则,进行黑名单过滤。
为了提高访问效率,将摘要值进行黑名单过滤(非法网址数量远远效率合法网址数量),如果不在黑名单中,则允许用户访问该网址。
再将该URL进行白名单过滤,如果出现在白名单中,此次过滤过程结束。否则,将该URL反馈给网络爬虫模块,优先对该URL进行爬取,爬取完毕之后迅速进行敏感词过滤,并将结果添加到URL过滤模块的黑白名单中。
3 主要工作
Bloom Filter[1]是一种二进制向量数据结构,被用来检测一个元素是否是集合的一个成员,具有很高的时间效率和空间效率。它采用一个长度为m的向量来的表现一个大小为n的集合S,并能判断一个元素是否的集合S中。向量m中所有位初始值为0。Bloom Filter采用t个相互独立的hash函数h1,h2,…,ht将集合中的每个元素散列到1到m的范围中。对于给定的元素,位置为hi(x)的比特位都置为1,其中 。判断元素y是否属于集合S时,只需要分别计算hi(y),如果所有向量上对应的比特位位置为1,则认为 ,否则认为 。由Bloom Filter的特点,如果y元素判定不在集合S中,则y元素一定不在集合S中。如果y元素判定在集合S中,则y元素不一定在集合S中,设Bloom Filter误判的概率为f。
f是关于m,n,t的函数,表示为:

我们对用户访问互联网采取“第一次允许策略”[2],即当用户访问的URL不在黑白名单中时,我们首先是让用户继续访问网页,同时将该URL进行优先处理,当任何用户第二次输入该URL访问网页时,则可对此URL进行黑白名单过滤。
此处引入Bloom Filter的主要有以下作用,我们用给定的黑白名单对Bloom Filter的位图进行初始化,当进行URL过滤时,我们首先用Bloom Filter进行一次过滤,如果匹配失败,由Bloom Filter的特点,如果y元素判定不在集合S中,则y元素一定不在集合S中,则直接将URL加入爬虫优先处理队列,减少无效的黑白名单匹配。如果匹配成功,则继续URL模块中所设定的过滤流程。
Hash表可以看成一个数组,数组的每个元素称为“桶”(Bucket),每个Bucket使用一个链表来处理节点冲突,假设Hash表有m个Bucket和n个元素,那么在表中查找一个元素的平均时间的复杂度是O(m/n)。采用更大的哈希表可以获得更好的性能。当 m>>n时,复杂度趋向于O(1)。另外,好的哈希函数能够将元素更均匀地分布在各个Bucket上,从而提高Hash表的性能。
从以上的介绍中可以得知,使用Hash进行元素查找时,可以提高查找性能,同时,在同一个“桶”(Bucket)所对应的冲突链上进行元素查找时,假设冲突链长为l,则查找性能为O(l),这表示查找性能有提高的空间。
位图法,就是用一个bit来存放某一种状态,用0 和1来表示。一般情况下,会在系统内存中开辟一块空间,然后初值全部置为0。设开辟的空间有n个bit位,当第k(1≤k≤n)为置为1时,表示序号为k的元素存在。
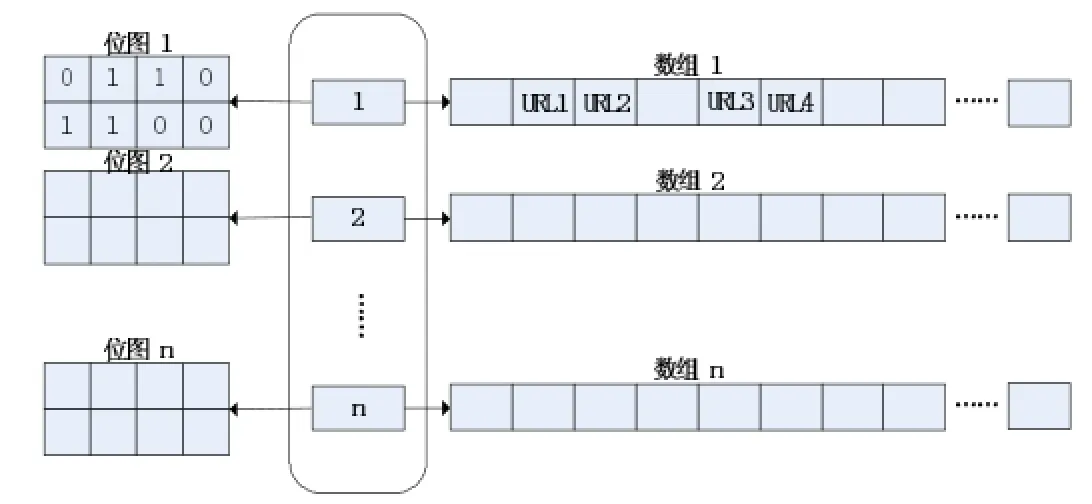
图3
在改进的hash[3-4]表中,以URL地址的MD5摘要值作为输入参数,设附加在桶(Bucket)一侧的位图大小为w,数组预分配的空间大小为M,空间内可容纳的摘要值个数为p,则有:M=p*16B,w≤p。
在本文所描述的系统中,所有的URL地址将转化为MD5摘要值进行处理。设URL为MD5的输入参数,输出结果为R,则R的长度为128Bytes,R可由16B的内存空间进行存储。
在改进的hash表中,在“桶”(Bucket)的一侧附加了一个容量为w的位图,为了解决冲突,使用的是一个内存空间连续的数组,用数组了取代链表结构。对hash表初始化时,设MD5摘要值的大小为16Bytes,数组预分配的空间大小为M,空间内可容纳的摘要值个数为p,则有:M=p*16B,w≤p。
引入位图的作用在于以下两点:
对于将要插入到hash中的URL而言,此URL的MD5摘要值为m,第一步:我们对将要插入hash表中的url进行下面的处理,hash(m)%n=k,找出该URL将要插入第k个数组上。第二步:我们使用哈希函数,进行如下处理 ,此时如果在第k个位图中,第i位值为0时,表示对应数组第i个元素为空,可直接将m值写入该位置。如果第i位的值为1,表示此时产生了hash冲突,我们从i开始朝后遍历数组,直到找到某一位数组元素为空时,将m值写到此位置。如果一直到数组末尾仍然没有发现为空的元素,则重新申请数组空间,空间大小为p*r,其中r为我们定义的扩充因子且r>1,再将原来数组复制到新的数组中,复制完毕之后,释放原来的数组空间。
对于要在该改进的hash表中过滤的指定的url是否存在时,此URL的MD5摘要值为q,第一步:我们对将要中的过滤URL进行下面的处理,hash(q)%n=z,找出该URL可能存在的第z个数组。第二步:我们使用哈希函数H,进行如下处理H(q)%w=c,如果此时,第z位图上第c位为0,则表示匹配失败,如果第z位图上第c位为1,则从数组的第c位开始往后遍历,如果和数组中的元素完全匹配,则返回匹配成功;如果遇到数组上某个元素为空、直到数组末尾任然未匹配完成,则返回匹配失败。
4 仿真实验和实验分析
由于是进行仿真实验,用程序生成了多条URL,将生成的URL缓存在内存空间中,分别用普通hash表和改进的hash表来构建黑白名单且黑白名单的大小均为10000条URL,每个hash表中的Bucket数目均为100,然后进行URL过滤,比较普通hash表和改进hash表对于的比较次数和比较时间上的区别。
通过以上的实验结果可以看出,使用改进的hash表结构进行URL过滤,在比较次数和比较时间上比传统hash过滤方式在比较,减少了比较次数和比较时间,提高了过滤效率。
5 仿真实验和实验分析
本文通过使用设计了一种局域网内URL过滤系统,主要的工作在于对于URL过滤效率的改进,因为黑白名单的只能覆盖极少数的网页,使用Bloom Filter对于URL进行第一次过滤时,可以将不在黑白名单中的网页立刻加入优先处理队列,从而减少了无效的黑白名单匹配。利用位图法改进的hash表在URL的匹配过程中能够做到一定程度的随机访问,与链表从头到尾的匹配方式相比,减少了在黑白名单中的比较次数。该方法相对于Bloom Filter,杜绝了误判的可能。和传统的hash表进行URL过滤相比,减少了无效匹配的次数,极大地提高了匹配效率。

图4
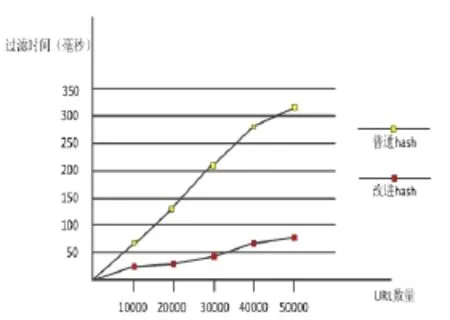
图5
[1]刘庆.一种基于并行的Bloom Filter的高速URL查找算法[J].电子学报,2015(9),1833-1840
[2]徐剑.面向分布式查询认证的分层hash链表[J].计算机研究与发展,2012(3),1533-1544
[3]李晓明.两种对URL效果很好的散列函数[J].软件学报,2004(2),179-185
[4]刘燕兵.一种面向大规模URL过滤的多模式串匹配算法[J].计算机学报,2014(5),1160-1168
URL filter;Web Crawler;Sensitive Word Filtering;Bloom Filter;Hash Table;MD5
Research and Application of a High Speed URL Filtering Algorithm
HUANG Cheng
(College of Computer Science,Sichuan University,Chengdu610065)
1007-1423(2016)03-0013-04
10.3969/j.issn.1007-1423.2016.03.003
黄诚(1987-),男,湖南常德人,硕士研究生,研究方向为信息安全
2015-12-21
2016-01-10
当前,传统防火墙的URL过滤方式只是对于规则库中的URL进行过滤,对于新增的涉黄涉暴网站无能为力,或者管理员响应迟钝。针对当前这种现状,提出一种局域网内URL过滤系统,基于网络爬虫和敏感词过滤技术通过爬去网页文本和对于网页文本分析来判断指定URL是否合法。考虑到匹配效率和本过滤系统所使用的内存空间,使用MD5 对URL计算摘要值,在此之上建立黑白名单,再结合Bloom Filter算法和改进的Hash表数据结构用以实现对URL的高速过滤。
URL过滤;网络爬虫;敏感词过滤;Bloom Filter;Hash表;MD5
Recently,traditional URL filtering firewall rule base only for URL filtering,for the new added website involving violence powerless,or the administrator unresponsive.For this view of the current situation,proposes a URL filtering system within a local area network,which is based on climbing web pages for text and analyzing text to determine the lawfulness of the specified URL,considering the matching efficiency of the words and the use of memory space in this system,uses the MD5 digest value calculated on the URL,builds on top of this black and white lists,combining Bloom Filter algorithm with improved HashMap data structure to achieve high speed for URL filtering.
