大数据时代的车牌汉字识别
2016-09-21沈文枫张建蕾周丁倩陈圣波上海大学计算机工程与科学学院上海200444
沈文枫,张建蕾,周丁倩,陈圣波,邱 峰(上海大学计算机工程与科学学院,上海200444)
大数据时代的车牌汉字识别
沈文枫,张建蕾,周丁倩,陈圣波,邱峰
(上海大学计算机工程与科学学院,上海200444)
在大数据时代,交通信息成为网络数据量最大的数据来源之一,智能交通成为必然需求.车牌识别是智能交通的基础,可广泛应用于车库管理、交通监控等工程中,然而识别的准确率还有待加强,已有算法对于字母、数字的识别准确率都非常高,而对于中国特有的汉字识别却效果不佳.提出用受限玻尔兹曼机组成的深信度网络算法来识别车牌字符,大大提升了汉字识别的准确率,使准确率达到99.44%.
车牌汉字识别;深信度网络;受限玻尔兹曼机;深度学习
在大数据时代,交通信息成为网络数据量最大的数据来源之一,每天每个地市的每个十字路口要通过数以万计的车辆,包含各种车型和牌照.随着科技和经济的高速发展,购置汽车的人与日俱增,然而日益增多的车辆在给人们的出行带来便捷的同时,也使得交通问题日益突出,因此发展智能交通系统(intelligent transportation system,ITS)成为迫切需要.对于交通堵塞和交通事故等问题,借助智能交通系统[1]能够实现交通的智能自动化管理,进而实现对交通环境的全面有效的监管,帮助缓解交通堵塞、交通安全等方面的问题.
车辆牌照识别(license plate recognition,LPR)技术[2]作为ITS的基础,已广泛应用于违章车辆稽查、城市监控系统、停车场、高速公路收费站等需要认证车牌的相关场合.该技术运用图像分割和识别理论,分析处理汽车牌照号码图案以确定其位置,并通过进一步提取和识别获取牌照字符信息,为科学有效地识别和管理车辆发挥积极作用,其重要性不言而喻.
车牌字符[3]包含汉字、字母和数字,相比字母和数字,汉字笔画多并且结构复杂,因此汉字识别是车牌字符识别的难点和重点.近几年,国内研究学者提出了多种车牌字符识别方法,但这些方法对字母和数字的识别率高于汉字.因此,研究车牌识别中的汉字识别方法,提高车牌汉字的识别率具有重要的理论意义和应用价值.
从车牌中提取的汉字易受车牌提取过程中外界环境以及车牌本身完整性及清洁程度的影响,因此会存在模糊、污损及变形等问题,增加了识别难度.本文针对这些问题,对车牌中的汉字识别方法展开探讨,主要贡献如下.
(1)车牌汉字预处理:从车牌中切割出来的汉字图像中,汉字所占比例的大小和所处位置均不相同,因此需要对图像进行大小归一化和位置归一化处理.将汉字图像统一调整为维度28×28,并保证汉字的大小和位置相同.
(2)汉字特征一维化:按维度8×28将汉字一维化为一个784维的特征向量,也就是本研究所使用的深度学习网络的输入层神经元个数.
(3)深度学习识别器设计:由于深度学习具有较强的抗干扰能力、容错能力和自学习能力,因此尝试利用深信度网络(deep belief network,DBN)对汉字的特征向量进行训练,而后采用训练好的模型进行汉字识别.与神经网络方法相比,深度学习方法具有更高的识别率和更强的抗干扰能力.
1 相关研究
自动车牌识别是交通领域中的一大应用.虽然车牌定位技术逐渐成熟,车牌上的字符识别准确率却远未满足要求.车牌字符识别的难点之一就是字符的特征提取,而国外的车牌都是由字母与数字组成,笔画简单,经过图像处理后的形变量较小,易识别.Wu等[4]利用BP神经网络算法识别车牌,字母识别准确率达到99.25%,数字识别准确率达到99.3%.Cheng等[5]利用一种混合算法对中国车牌中的汉字进行识别,准确率达到了95.96%.中国的车牌识别准确率关键在于对字符的识别.而在车牌字符识别中,与字母、数字识别相比,汉字的识别率是最低的,所以提高车牌中汉字的识别准确率,对于车牌识别准确率的提高将有很大的提升.由于汉字的笔画较多,笔画间的空隙较小,经过处理后会发生形变,如少笔画、多笔画、断笔、一块黑、一块白的情况,如图1所示的赣、津、京、鲁(1)、鲁(2)、闽、苏、皖、豫、粤,这使得车牌汉字识别的难度大大增加.最常用的直方图特征算法[6]在提取特征时,易出现两个纹理完全不一样的图被提取后其特征值一样的问题(见图2).

图1 摄像头拍摄的车牌汉字样本Fig.1 Camera samples of license plate character
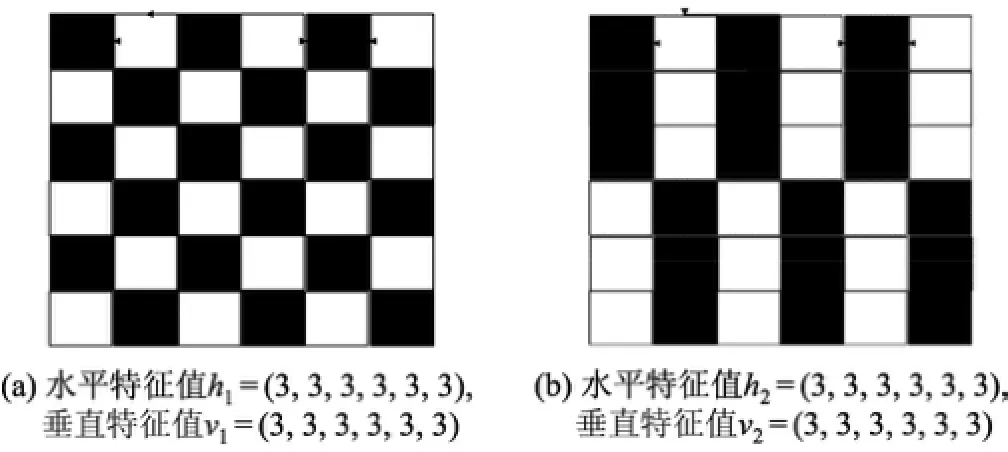
图2 直方图特征算法Fig.2 Histogram feature algorithm
汉字的特征比较复杂,很多字的直方图特征差异不大,而有些相同字的样本的直方图差异却特别大,如图1(d)和(e).直方图特征提取方法在识别数字和字母时,由于笔画少、纹理容易辨别,所以准确率较高;但在识别汉字时,由于汉字的结构复杂,笔画多且密集,在将拍摄的图片处理成汉字二值图时,已经出现缺笔画或黑白不均的现象,使得不同汉字的直方图特征可能相同,相同汉字的直方图特征却可能不同,说明该算法的鲁棒性较差.
在很多情况下,尺度不变特征转换(scale-invariant feature transform,SIFT)特征提取算法[7]被用来定位车牌,但该算法在车牌特征比较明显简单(矩形,有七个字符等特征)的情况下,识别效果比较理想.而对于汉字识别来说,由于拍摄的车牌汉字经处理后与正规车牌汉字差异较大,所以识别效果并不理想.
神经网络分类算法[4,8]的分类效果较好,但依赖于有效的特征提取方法,如果直接用图片像素直接进行分类,则训练参数会非常大,训练时间与训练难度会大大增加,且容易出现分类错误或者过拟合情况.另一方面,由于车牌的拍摄角度、字符分割等的情况,每个字符图像中字符的位置和倾斜程度不一,所以同一个汉字的不同样本的像素值分布差异较大,造成神经网络算法对于拍摄车牌的汉字的识别准确率难以提升.因此神经网络算法不太适合用作车牌的汉字识别.
Google的开源软件Tessact[9],是光学字符识别(optical character recognition,OCR)领域中准确率非常高的一款识别软件,对于打印的图片中字符(包括汉字)的识别率可以达到99.99%以上.但是对于手写的字或者摄像头拍摄的车牌的汉字识别,其测试准确率非常低,甚至不到80%.所以对于非规则字体,Tessact的识别准确率大幅下降.
综上所述,各种算法都存在一定的缺陷,使得对于中国车牌特有的汉字的识别率较低.本研究采用的方法是深度学习中的深信度网络算法,它由3个受限玻尔兹曼机和一个逻辑回归网络构成.
2 车牌汉字识别网络设计
深度学习[10-11]是模仿人脑进行分析学习的神经网络,试图模拟人脑的行为特征,对数据进行分析与解释.深度学习网络通常含有多个隐藏层,其排列分布与人脑相类似,通过对较低层特征的组合、分析、筛选,形成较高层的特征,以发现数据的分布式特征表示.
深信度网络[12-13]是深度学习网络的一种,通常由数个受限彼尔兹曼机(restricted Boltzmann machine,RBM)层以及一个全连接的分类器组成.一方面,深信度网络的权值共享网络结构使之更类似于生物神经网络,具有更低的模型复杂度与更少的权值,从而可以直接输入目标图像,省去了繁琐的特征提取过程;另一方面,深信度网络将图像的局部作为最低层输入,从而获取输入图像最为基础的特征,所以对目标物体或图像的形变、旋转具有较好的抵抗性.与传统的BP神经网络相比,深信度网络具有训练参数少、可直接输入二维图像等优点.受限玻尔兹曼机是深信度网络的主要构成部分,通过逐层特征提取得到所需结果.
2.1受限玻尔兹曼机
受限玻尔兹曼机[14-15]是由Hinton和Sejnowski于1986年提出的一种生成式随机神经网络(generative stochastic neural network),该网络由可见层和隐藏层构成,各层的变量都是二值变量,即其状态取{0,1}.整个网络是一个二部图,只有可见单元和隐藏单元之间才会存在边,而可见单元之间以及隐藏单元之间都不会有边连接(见图3).
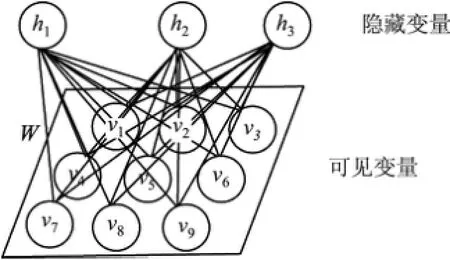
图3 受限玻尔兹曼机原型Fig.3 Prototype of RBM
由图3可见,RBM含有由9个可见单元构成的向量V={v1,v2,···,v9}和由3个隐藏单元构成的向量H={h1,h2,h3}.每个边都有权值,共9×3个边,用W矩阵表示,就是可见单元和隐藏单元之间的边的权重.
RBM是一种基于能量(energy-based)的模型,其可见变量v和隐藏变量h的联合配置(joint configuration)能量为
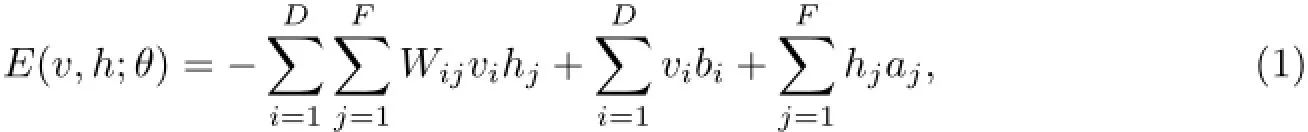
式中,θ为RBM的参数{W,a,b},W为可见单元和隐藏单元之间的边的权重,a和b分别为隐藏单元和可见单元的偏置(bias).
由v和h的联合配置能量可以得到v和h的联合概率为
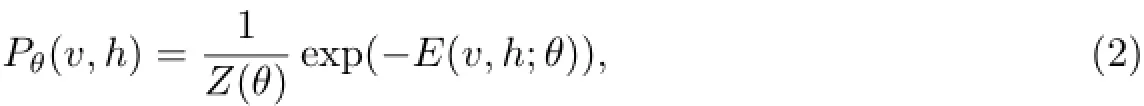
式中,Z(θ)为归一化因子,其函数原型为
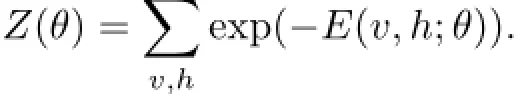
通过最大化观测数据的似然函数Pθ(v),可以使得RBM收敛,可由式(2)求Pθ(v,h)对h的边缘分布得到
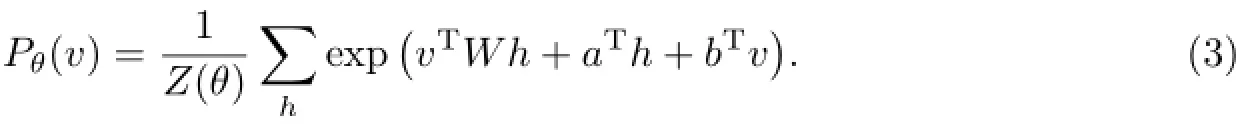
最大化Pθ(v)后即可得到RBM的参数.最大化Pθ(v)等同于最大化logPθ(v)=L(θ),即式中,N为RBM个数.这样,通过训练求得RBM的参数就可得到隐藏层,即特征提取层.
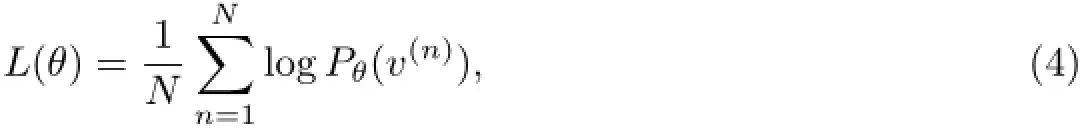
2.2深信度网络
深信度网络[15]是一个概率生成模型(见图4),与传统的判别模型的神经网络相比,生成模型是建立一个观察数据和标签之间的联合分布,对已知标签求观察数据的概率PO/L和已知观察数据求标签的概率PL/O都作了评估.而深信度网络的判别模型仅仅评估了后者,也就是PL/O.
基于浅度回收模式的发电厂接入价定价机制//丛野,张粒子,高磊,车文燕,陆继东,唐虎//(11):163
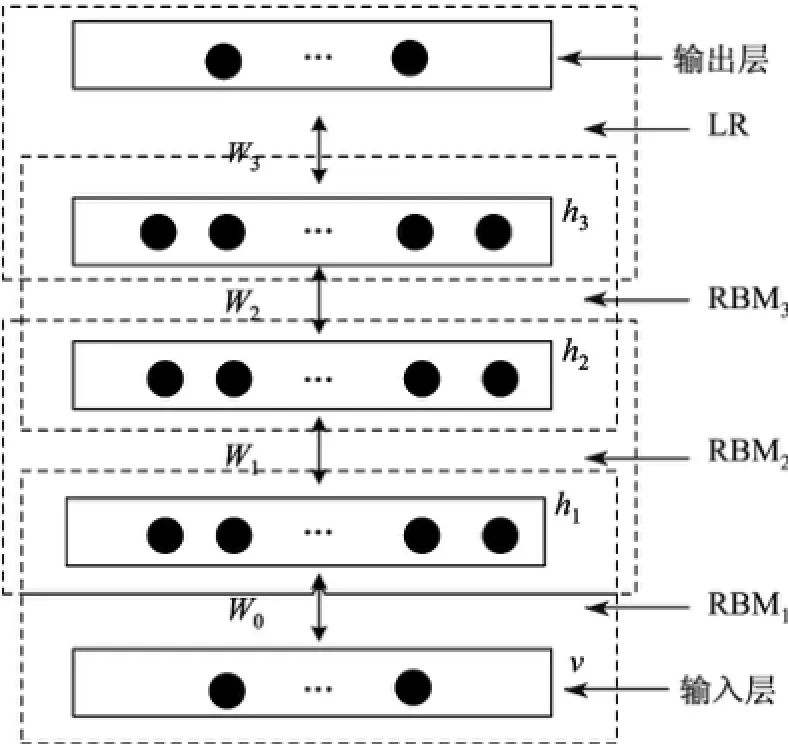
图4 深信度网络构成部件Fig.4 Deep belief network components
能量公式P(v,h1,h2,h3)=P(v|h1)P(h1|h2)P(h2|h3)由3个受限玻尔兹曼机层组成,这些网络被“限制”为一个可视层和一个隐藏层,层间存在连接,但层内的单元间不存在连接.隐藏单元被训练去捕捉在可视层表现出来的高阶数据的相关性.
初始通过一个非监督贪婪逐层方法预训练获得生成模型的权值,非监督贪婪逐层方法被Hinton等[13]证明是有效的,并被称为对比分歧(contrastive divergence).在这个训练阶段,在可视层会产生向量V,通过V将神经元的值传递到隐藏层.反之,可视层的输入会被随机选择,以尝试重构原始输入信号.新的可视的神经元激活单元将前向传递重构隐藏层激活单元,获得向量H.这些后退和前进的步骤就是Gibbs采样[16],而隐藏层激活单元和可视层输入之间的相关性差别就将作为权值更新的主要依据.
经预训练后,DBN可利用带标签数据通过逻辑回归算法对判别性能作出调整.这里,一个标签集将被附加到顶层,通过自下向上学习到的识别权值获得一个网络分类面.该性能比单纯的逻辑回归算法训练的网络更好.这可以很直观地解释为DBNs的逻辑回归算法只需要对权值参数空间进行局部搜索,这比前向神经网络的训练更快,而且收敛的时间也更短.
图5为深信度网络架构,可见输入层的神经元的值为一维化后的汉字二值图向量,通过边向上层传播,相邻两层构成RBM,通过逐个RBM的训练后得到整个深信度网络模型.
3 车牌汉字识别实验
实验数据来自摄像头拍摄的车牌.采集大量车牌后,从中提取汉字,形成训练集与测试集,数据来源过程如图6所示.
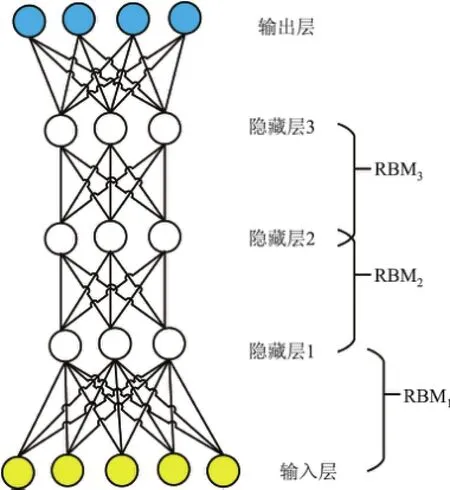
图5 深信度网络架构Fig.5 Deep belief network architecture
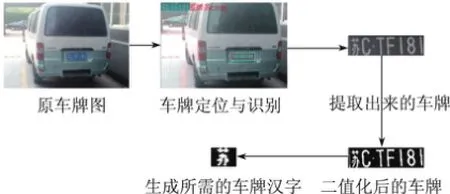
图6 拍摄车牌的汉字提取过程Fig.6 Chinese character extraction process for shooting license plate
将拍摄到的车牌经上述处理后,每个车牌可得到一个汉字样本,共收集到5 000张车牌图片,其中样本数比较少的车牌汉字样本(“川”、“赣”等)有十几个,样本数比较多的车牌汉字样本(“京”、“沪”)有数百个,构成可训练和可测试的数据集.在中国,车牌汉字样本种类有“军北南广沈成兰济空海京津冀晋蒙辽吉黑沪苏浙皖闽赣鲁豫鄂湘粤桂玉琼川贵云藏陕甘青宁新”共41个汉字.个别的“空”、“海”等汉字由于数量太少而不作训练,其他共34个字经训练处理后进行测试,验证识别准确率.
将所得样本重置大小为维度8×28,再进行一维化后生成一个784维向量,构成输入层,共784个神经元.此时,输入层和隐藏层1构成一个RBM1,输入层是RBM1的可视层,隐藏层1 为RBM1的隐藏层.同理,RBM1的隐藏层为RBM2的可视层,隐藏层2为RBM2的隐藏层(见图7).
输出层为34个神经元,每个神经元的值为0或1,且只有一个神经元的值为1,标注为1的神经元表示输出结果为该类别.若正确,则分类成功;若错误,则分类失败.
本研究提出的DBN算法基于Python的Theano科学计算库,实验环境是4核Intel(R)Core(TM)i5-4460 CPU@3.20 GHz,8 GB内存DDR3.训练过程如下:首先,通过预训练对网络参数进行初始化赋值;然后,进行调优,逐层训练生成网络的各个参数,达到可以分类的功能.网络由1 000×1 000×1 000的隐藏神经元组成,有Softmax层、RBM层和输入输出层.预训练的学习率为0.01,调优的学习率为0.10.测试车牌字符的汉字准确率达到了99.44%.
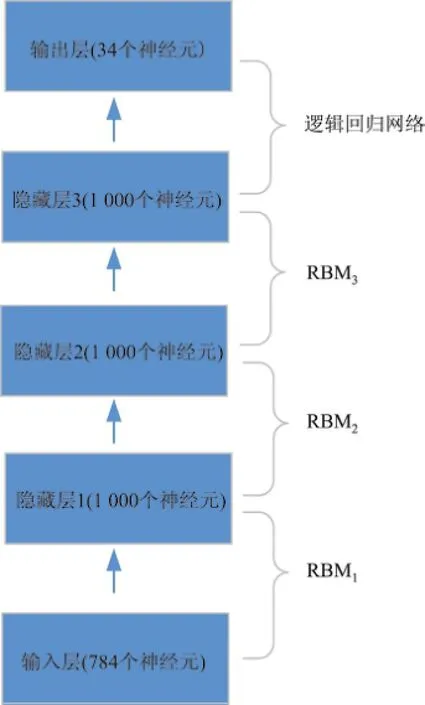
图7 深信度网络实验结构Fig.7 Experimental structure of DBN
图8中纵坐标为输出结果与标签的平方差的和,所以其值越小越好;横坐标为训练次数,可见随着训练次数的增加,深信度网络的代价函数值减小.通过预训练来减小代价函数值,将使得调优收敛快速且准确.在对网络模型进行参数调优训练时,训练次数与错误识别率的变化如图9所示.
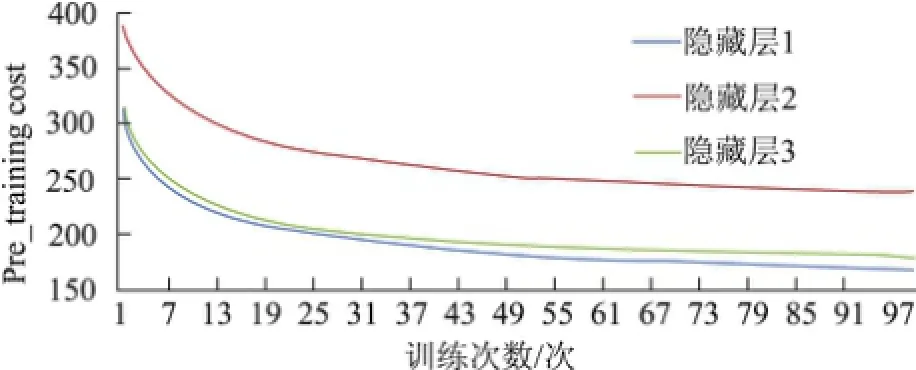
图8 预训练代价函数值变化Fig.8 Changes of Pre training cost function value with training
在用深信度网络对车牌汉字进行训练时,随着深信度网络训练次数的增加,错误识别率逐渐减小,深信度网络的识别准确率逐渐收敛于99.44%.在车牌汉字识别准确率方面,深信度网络算法与神经网络算法和Tesseract算法的对比结果如图10所示,训练时间对比情况如表1所示.

图9 错误识别率随训练次数的变化Fig.9 Change of error recognition rate with training
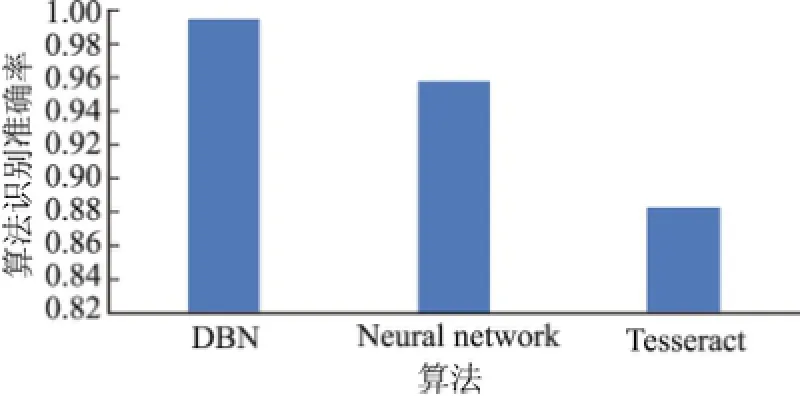
图10 DBN、神经网络、Tesseract三种算法的识别准确率Fig.10 Accuracy of DBN,Neural Network and Tesseract

表1 三种算法的训练时间对比Table 1 Training time comparison of three algorithms
可以看出,在保证识别准确率的情况下,深信度网络算法所消耗的训练时间比神经网络算法少得多.与神经网络算法和Tesseract算法相比,深信度网络算法的车牌汉字识别准确率要高得多.
深度学习在人工智能领域的应用已逐渐展开,在快速发展的信息时代,智能家居、智能交通等的发展也跟上了时代的脚步.车牌识别技术的发展为其在今后的车辆跟踪、交通监控等领域的应用打下了良好的基础.
4 结束语
为了迎接大数据时代的到来,交通领域作为大数据的基础部分,与其相关的大数据技术的研发成为重中之重.本研究分析了一些特征提取算法的优缺点,用RBM构建了DBN算法,通过在车牌汉字识别方面的应用,验证了所提出算法的准确率可达99.44%,比传统神经网络算法的准确率高得多,而且训练复杂度也大幅降低.
虽然本研究提出的深信度网络车牌汉字识别方法有较高的识别率,但仅限于PC机上的实验.对于车牌汉字这类少量种类的训练,完全可以将算法移植到树莓派等小型处理机上.下一步工作将继续改进算法,使算法准确率得到进一步提升的同时,加快训练速度和识别速度,这样有助于将算法移植到便捷式终端,使得智能车库、智能交通成为现实.
本研究为2015年度上海大学电影学高峰学科成果.
[1]王笑京,沈鸿飞,汪林.中国智能交通系统发展战略研究[J].交通运输系统工程与信息,2006(4):9-12.
[2]吴佳.车辆牌照识别系统的设计与实现[D].北京:北京交通大学,2015.
[3]中华人民共和国公安部.GA36—2014中华人民共和国公共安全行业标准:中华人民共和国机动车号牌[S].北京:中国标准出版社,2014.
[4]WU F,WANG Y G,HOU X W.License plate character recognition based on framelet[C]// International Conference on Wavelet Analysis and Pattern Recognition.2007:673-676.
[5]CHENG R,BAI Y P.A novel approach for license plate slant correction,character segmentation and Chinese character recognition[J].International Journal of Signal Processing Image Processing and Pattern Recognition,2014,7(1):353-364.
[6]汪启伟.图像直方图特征及其应用研究[D].合肥:中国科学技术大学,2014.
[7]蔺海峰,马宇峰,宋涛.基于SIFT特征目标跟踪算法研究[J].自动化学报,2010,36(8):1204-1208.
[8]CIRESAN D,MEIER U,MASCI J,et al.A committee of neural networks for traffic sign classification[C]//International Joint Conference on Neural Networks.2011:1918-1921.
[9]Google Tessact[EB/OL].[2015-10-19].http://sourceforge.net/projects/tesseract-ocr/.
[10]BENGIOY,COURVILLEA,VINCENTP.Representationlearning: areviewandnew perspectives[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(8):1798-1828.
[11]BENGIO Y.Learning deep architectures for AI[M]//JORDAN M.Foundations and trends in machine learning.Boston:Now Publishers Inc,2009:1-127.
[12]HINTON G E,OSINDERO S,TEH Y W.A fast learning algorithm for deep belief nets[J].Neural Computation,2006,18(7):1527-1554.
[13]HINTON G E.Deep belief networks[J].Scholarpedia,2009,4(5):5947.
[14]FISCHER A,IGEL C.Training restricted Boltzmann machines:an introduction[J].Pattern Recognition,2014,47(1):25-39.
[15]LE R N,BENGIO Y.Representational power of restricted Boltzmann machines and deep belief networks[J].Neural Computation,2008,20(6):1631-1649.
[16]刘忠,茆诗松.分组数据的Bayes分析——Gibbs抽样方法[J].应用概率统计,1997(2):211-216.
Recognition of Chinese characters on license plates based on big data
SHEN Wenfeng,ZHANG Jianlei,ZHOU Dingqian,CHEN Shengbo,QIU Feng
(School of Computer Engineering and Science,Shanghai University,Shanghai 200444,China)
Today,traffic provides sources of huge scale data sets on the network,calling for the development of intelligent traffic.The license plate recognition(LPR)techniques are an important basis of intelligent traffic,and widely applied in applications such as garage management and traffic monitoring.However,the current LPR algorithms are imperfect in terms of recognition accuracy.Although working well in recognizing English letters and digits,they are unsatisfactory in recognizing Chinese characters.This paper proposes a license plate recognition algorithm using a deep belief network(DBN)algorithm consisting of restricted Boltzmann machines(RBM).It greatly improves the quality of Chinese character recognition with accuracy rate up to 99.44%.
license plate of Chinese character recognition;deep belief network;restricted Boltzmann machine;deep learning
TP 391.4
A
1007-2861(2016)01-0088-09
10.3969/j.issn.1007-2861.2015.04.019
2015-11-30
上海市科委资助项目(14DZ2261200)
沈文枫(1968—),男,副研究员,博士,研究方向为并行计算、高性能计算、心电仿真计算. E-mail:wfshen@mail.shu.edu.cn
