面向大数据应用的多层次混合式并行方法
2016-09-21支小莉郑圣安上海大学计算机工程与科学学院上海00444上海交通大学计算机科学与工程系上海0040
黄 磊,支小莉,郑圣安(.上海大学计算机工程与科学学院,上海00444;.上海交通大学计算机科学与工程系,上海0040)
面向大数据应用的多层次混合式并行方法
黄磊1,支小莉1,郑圣安2
(1.上海大学计算机工程与科学学院,上海200444;2.上海交通大学计算机科学与工程系,上海200240)
基于很多大数据应用存在对数据进行多种并行处理的需求,提出两层混合式并行方法,即执行单元的混合并行和计算模型的混合并行.通过在同一个计算节点上执行单元的混合并行,充分挖掘基础设施的计算能力,从而提高数据处理性能;采用在同一个执行引擎中集成多个计算模型的并行方法,以适合应用多样异质处理模式.不同的混合并行方法可以契合不同的数据和计算特点,以满足不同的并行目标.介绍了混合式并行方法的基本思想,并以前期开发的并行编程模型BSPCloud为基础,阐述了进程和线程混合并行、BSP和MapReduce混合并行的主要实现机制.
混合并行;编程模型;整体同步并行(bulk synchronous parallel,BSP);MapReduce
在物联网、电子商务、电信、医疗和金融等诸多应用领域,数据已经从TB级迅速发展到PB级甚至更高的数量级,且仍以指数速度增长,信息数量及复杂程度与日俱增[1-2].通过对数据的分析和处理掌握未来的发展趋势,使数据创造出更大的价值已经成为一个亟需解决的问题[3-6].
大数据的并行处理需求催生了以Hadoop,Dryad,Pregel,Hama,All Pairs,Oivos,KPNs,Storm和Spark等为代表的并行处理平台.每一种大数据并行处理平台适合于特定的数据类型,能高效地处理某一类数据[7],例如Hadoop适合处理易于用键值对表示的数据密集型数据,Storm适合于处理流数据,Pregel适合于处理大规模图数据,Hama适合于处理大规模科学计算.
随着大数据应用的扩展及其处理要求的变化,计算模型也随之不断创新和优化,不断产生新的各种面向领域的处理技术和处理平台[8].从横向上看,针对不同的数据类型,计算模型呈现出不断扩散的趋势,基于这些模型的Dryad,Pregel,All Pairs,Orleans平台均适合于处理某一领域的数据;从纵向上看,处理平台呈现出不断演化的趋势,HadoopDB,Pig Latin,Sawzall,Oivos,KPNs和Spark等平台皆由MapReduce模型演化而来,Pregel和Hama等平台则是基于整体同步并行(bulk synchronous parallel,BSP)模型发展而来的.
由于应用领域的多元性、数据类型的复杂性、数据处理方式以及流程等的多样性,研究混合并行计算方法,以适应大数据应用的处理方式多样性和异构性,已成为一个迫切需要解决的问题.需要使用不同的技术手段、利用异构的基础设施和异质的计算特征来获取性能优势.
1 研究现状
已有的关于混合并行计算的研究基本上是在异构多核的硬件架构上的混合并行,例如CPU和GPU的并行执行、多CPU系统中的进程级和线程级的并行[9].这类混合并行方法已在各领域的计算密集型应用中获得广泛使用.从本质上说,这种混合计算主要从硬件角度来观察,将同一个并行计算模型的不同实现方法或实现机制进行混合,或者利用硬件组成部分的异构性来实现异质的并行.例如,基于消息的分布内存的消息传递接口(message passing interface,MPI)并行和共享内存的线程级OpenMP的混合并行.文献[10]认为未来的系统是混合系统,即同构多核处理器+GPU+其他加速器.从程序执行角度看,这种混合并行通常体现为多重硬件所支持的多种或多个执行单元(execution unit)的并行,例如多进程和多线程的并行.
本研究侧重于更高层次的混合并行,即计算模型的混合并行.目前,国内外相关研究主要集中在对单一并行编程模型的创新或改进,对混合计算模型及混合式编程模型的研究比较鲜见.孟丹等[11]提出一种Transformer编程架构,该架构基于两个简单的主类型send()和receive()范式建立程序模型,试图以一种统一的方式来构建不同的并行编程模型.Pace[12]对MapReduce模型和BSP模型进行了分析,指出MapReduce模型本身缺乏坚实的理论基础,并需要与其他模型(如BSP,PRAM等)建立关系,同时指出用MapReduce来实现BSP是可行的,但没有考虑MapReduce和BSP混合并行的问题.潘巍等[13]介绍了为分布式大图算法设计的一个改进的MapReduce并行计算框架,将BSP嵌入到Map或Reduce阶段.通过将迭代过程内化到Map或Reduce阶段的BSP超级步间,从而减少多轮作业调度的开销.本研究的编程模型中没有把BSP限制到MapReduce的内部,而是由应用自行决定BSP和MapReduce这两种模式的关系.同时本研究还修改了一些BSP和MapReduce对输入输出和中间数据的处理方式,使其能灵活选择内存或文件形式,从而改善编程模型对更多应用的支持能力.Fegaras[14]提出一个新的框架,将数据分析应用的描述性查询翻译成MapReduce和BSP的评估计划,根据运行时的资源决定采用哪个模型.若资源足够,就采用BSP模型,完全在内存中计算查询,否则,采用MapReduce模型.这项工作给本研究带来一定启示:BSP和MapReduce在内存数据是否能跨越迭代步这一点上,截然不同的做法会对不同特点的应用产生很大的性能影响.
目前的大数据并行编程模型大多是针对特定类型的数据进行某种模式的处理,缺乏有效的混合方案,难以适应大数据应用的异构数据处理的需求.
2 两层混合式并行方法
由于应用存在复杂多样的并行计算特征,使得多种并行方式共存成为必需.这些混合并行方式能够在同一个编程模型中实现,可以更灵活方便地支持应用开发.混合并行主要从以下两个层次来实现:①执行单元(execution unit)的混合,以挖掘异构多核硬件的计算能力;②计算模型的混合,以适合应用的多样化数据处理模式.
2.1执行单元层次的混合并行
一个并行任务,可以实现为进程或线程等形式在处理器上执行.执行单元的混合并行主要体现为多进程和多线程的混合执行.通过充分利用多核异构硬件的计算资源,合理安排节点内和节点外的数据使用策略,能够显著加快数据处理速度.特别是目前多核处理器在集群中的普遍使用,使得这种对计算密集型应用效果明显的混合并行成为必然的趋势.
集群是大数据应用通常采用的基础设施,集群中的节点可以是普通物理机,或者是云(虚拟)主机.集群一般具有如图1所示的逻辑结构.每个节点机本身可以是一个异构系统,可能具有多个同质的CPU核和若干异质核(如GPU,DSP等)(见图2).
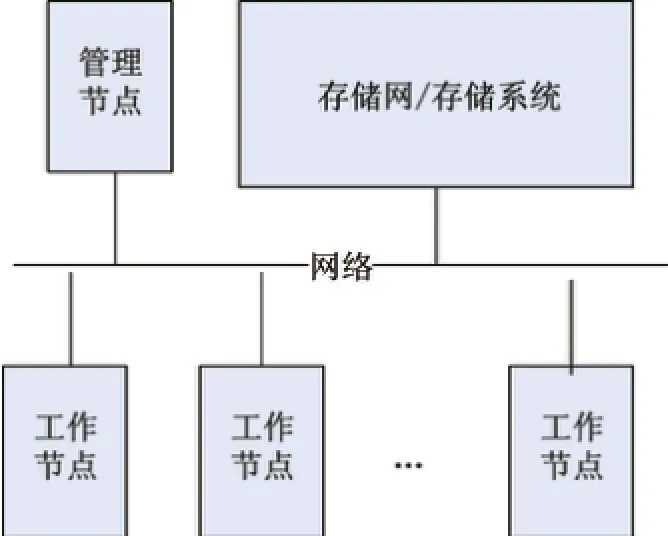
图1 集群的逻辑结构Fig.1 Logical structure of the cluster
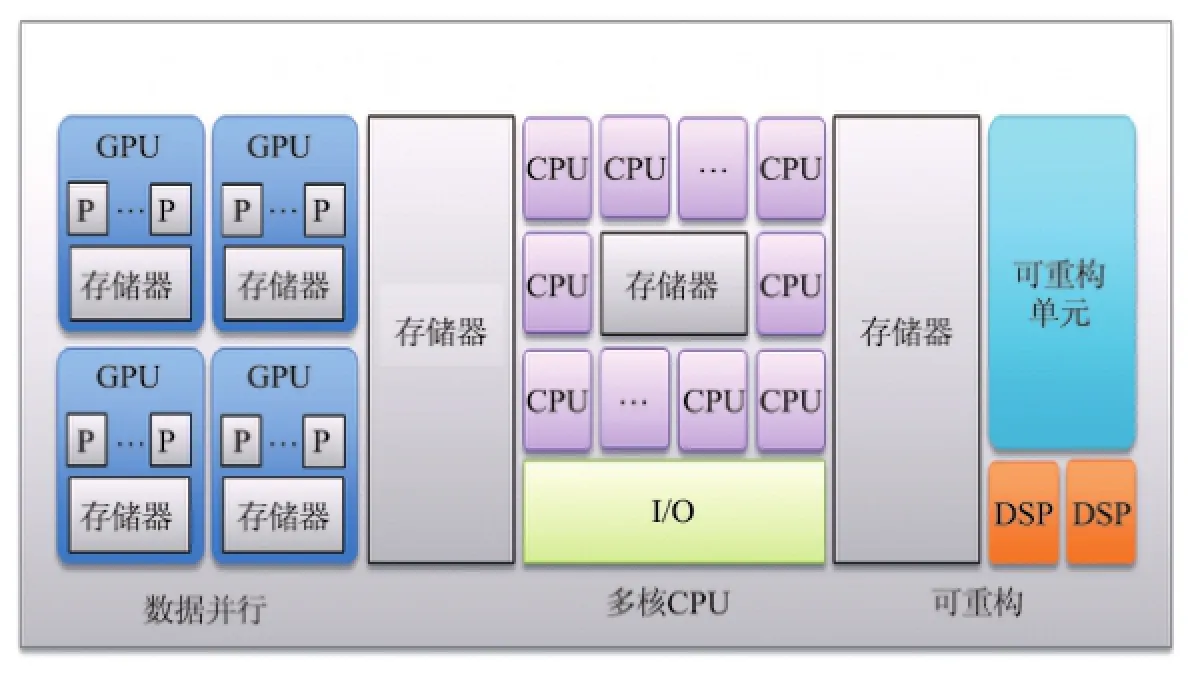
图2 节点机的异构多核架构Fig.2 Heterogeneous and reconfigurable computer architecture
多核硬件的存在使单个节点内可以存在多层次的线程级并行任务.图3(a)是适用于同质处理器核的两级并行.图3(b)是异质处理器核CPU+GPU的两级并行,CPU线程可以等待GPU线程执行完毕,也可以与之同时执行.基于此,集群很方便就能实现至少两级的混合并行:进程级的并行和线程级的并行(见图4).这两级并行实质上是分布内存级的并行和共享共存级的并行.在共享共存级的并行中,并行任务(线程)共享一个全局地址空间,数据交换接近零代价;在分布内存级的并行中,并行任务(进程)行为独立,需要显式通信.
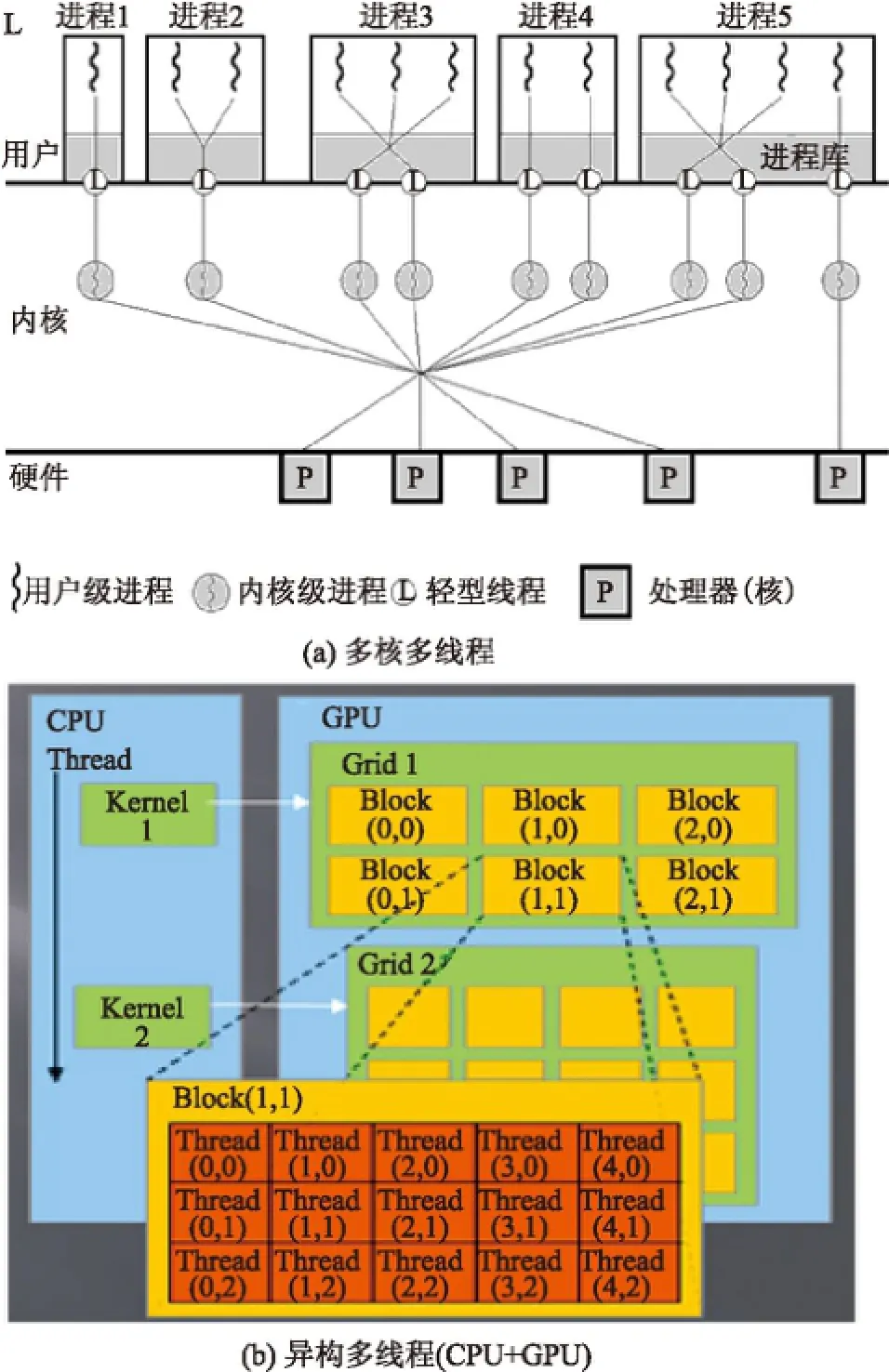
图3 多线程并行Fig.3 Multi-threaded parallel
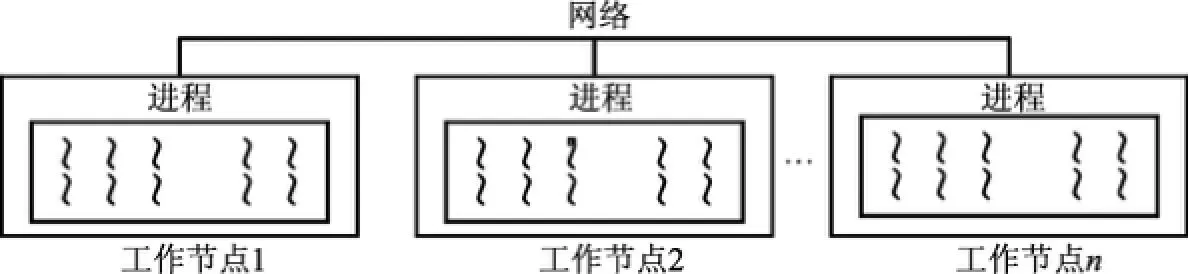
图4 多进程与多线程并行Fig.4 Multi-process and multi-threaded parallel
进程级和线程级的混合并行在传统高性能计算中应用较多,例如MPI/OpenMP混合编程模型,虽然在大数据应用中易被忽视,但这种混合并行对大数据应用也具有普遍的提升处理速度的效果.
2.2计算模型层次的混合并行
并行计算模型通常代表某类典型的数据处理模式.计算模型的混合能满足同一个应用的处理模式的多样化需求,使应用开发更自然流畅.每个并行编程模型中都蕴涵了某种计算模型,最普遍的是MapReduce,BSP和有向无环图DAG等.下面首先研究BSP和MapReduce混合的可能性和实现机制,然后再考虑其他计算模型如有向图或数据流模型的混合.
MapReduce是目前使用最广泛的大数据计算模型[15-16],其优点在于借用函数式语言的Map和Reduce原语,使得底层复杂的并行处理细节被屏蔽,应用开发者只需关注Map和Reduce的处理逻辑本身,其余复杂的并行事务交由系统来完成,因此系统的可拓展性较好,并且可在廉价的集群上高效运行.但MapReduce采用单输入单输出、基于键值对的计算模式,对应用存在较强的限制性,不适合需要迭代、重复的控制流程的应用.MapReduce的另一个主要缺点是不在内存中保存跨越连续的MR任务数据,这在复杂MR工作流中会引起不能容忍的高开销.
BSP模型是由Valiant[17]提出的一种并行计算模型,该模型由很多被称为超步的计算过程组成,一个超步由计算阶段、全局通信阶段和路障同步阶段组成,其优点在于模型简单易编程、性能可预测、能避免死锁等.由于BSP在内存中保留了中间数据,且超步内各任务可以进行通信,故BSP可用于具有复杂迭代过程的图、矩阵等计算.除了用于传统的高性能并行计算,BSP还可用于面向大数据应用的并行计算,例如Google的Pregel[18],Apache HAMA[19]和Yahoo Giraph[20].
BSP和MapReduce各具优势,可以根据数据处理特点结合使用(combined use),发挥各自所长(见图5).
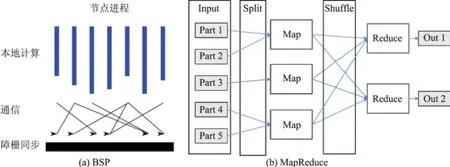
图5 BSP和MapReduce的执行模型Fig.5 Execution models of BSP and MapReduce
3 HyBSPCloud的实现机制
目前已出现很多大数据并行编程模型,但支持混合式并行的模型较少.虽然HAMA可以支持BSP引擎和MapReduce引擎,但这两个引擎是独立的,基本上没有关注BSP和MapReduce的有机结合的相关研究.本研究在前期开发的并行编程模型BSPCloud[21]的基础上,探索混合式并行方法的实现机制,并改善编程模型对大数据的支持.
与已有的编程模型相比,BSPCloud具有以下优点:
(1)性能可预测,开发人员在编写应用时,有一个可依赖的性能消耗模型,可以预先对应用程序的时间复杂度等进行分析;
(2)不仅适合计算密集型计算,也适合数据密集型计算;
(3)应用的执行进度可动态显示,可以对总执行时间和剩余时间进行预测.
BSPCloud包含能实现管理、计算、通信、进度等功能的22个类的源代码.本研究在BSPCloud的基础上,将之改进成为HyBSPCloud,使其增加了以下优点:①支持两个层次上的混合并行;②改善处理大数据的能力.
3.1进程级和线程级混合并行
HyBSPCloud采用如图6所示的分布式内存和共享内存混合并行模型(即进程级和线程级的混合并行).实现结构如图7所示.
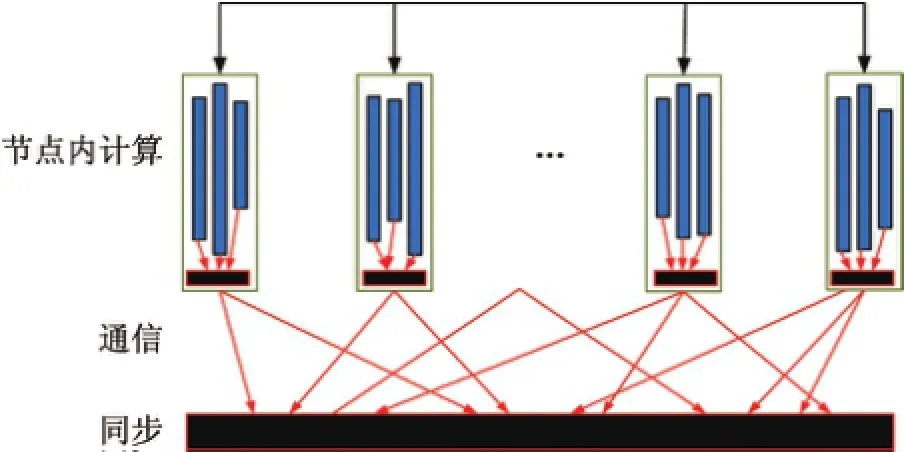
图6 HyBSPCloud的进程级和线程级混合并行模型Fig.6 Mixture parallel model of process-level and thread-level in HyBSPCloud
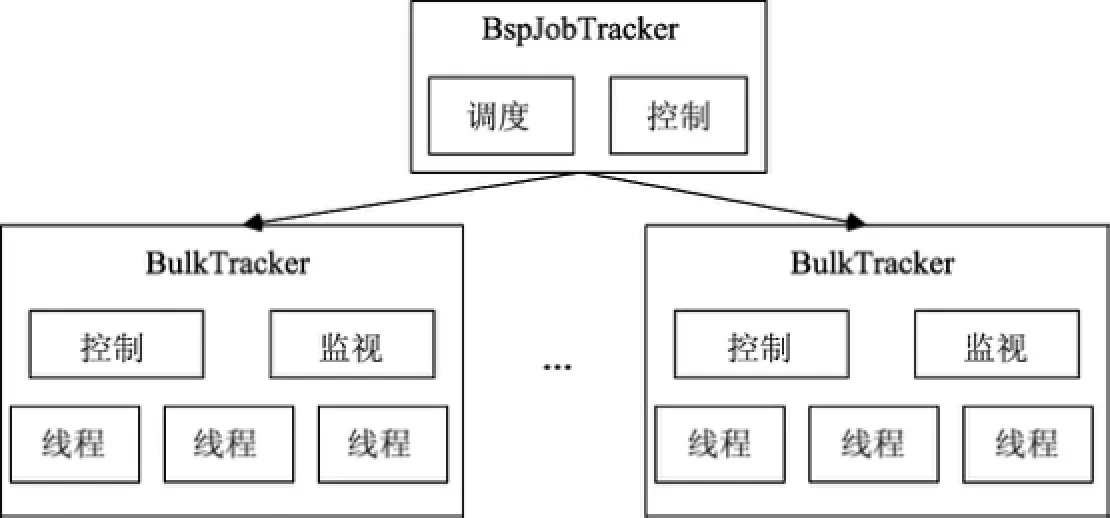
图7 HyBSPCloud中进程级和线程级混合并行的实现Fig.7 Hybrid parallel implementation of process-level and thread-level in HyBSPCloud
图7中的BspJobTracker负责作业的调度和控制作业的运行,当用户提交一个作业到云平台后,由调度器Schedule模块负责调度作业运行.当调度器取出一个作业后,BspJobTracker将作业划分成若干子任务,并将这些子任务分配到节点机(虚拟机或物理机),由BulkTracker负责调度运行.
BulkTracker启动若干个线程,由这些线程完成细粒度任务计算.异构处理器(如GPU)的线程由BulkTracker启动的线程来管理.各个节点上的Control负责实现节点间的同步、负载均衡、容错等功能.Monitor负责向BspJobTracker报告节点内的运行状态.
BulkTracker之间是进程级并行.如图8所示,进程间通信(inter process communication,IPC)可以采用消息传递、同步、共享内存和远程过程调用等技术.HyBSPCloud使用socket实现节点间并行任务的通信,对节点内的并行进程也支持共享内存的通信方式.BulkThread之间是线程级并行.HyBSPCloud使用全局变量、消息传递、参数传递和线程同步这4种方式实现线程间通信(inter thread communication,ITC),从而实现线程级并行管理.对于应用开发者,一般采用全局变量方式就可达到线程间交换数据的目的.
3.2BSP和MapReduce的混合并行
HyBSPCloud在原来的BSP基础上,增加了MapReduce的实现.BSP和消息传递功能不嵌入在Map和Reduce(缩写为MR)内部,MR也不嵌入在BSP的超步中实现.而是由应用开发者决定BSP和MapReduce这两种模型在执行时的关系:BSP可以嵌入在MR内,MR也可以嵌入到BSP的bulk中.图9为BSP和MR运行时3种关系的示例:①将MR嵌入在BSP超步中的计算阶段(算法见表1);②将BSP嵌入在Map阶段(算法见表2),此方法与文献[13]类似;③先执行MR,再执行BSP.
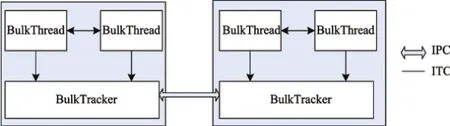
图8 HyBSPCloud的并行任务间的通信Fig.8 Communication between parallel tasks in HyBSPCloud
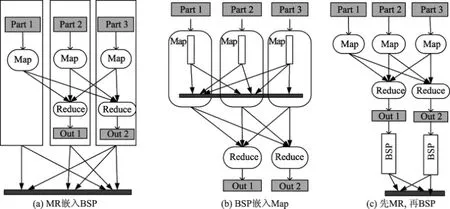
图9 BSP和MapReduce运行时的三种关系Fig.9 Three relationships of BSP and MapReduce when running

表1 MR嵌入在BSP超步中的计算阶段Table 1 Embed MR into calculation stage of BSP

表2 BSP嵌入在Map阶段Table 2 Embed BSP into Map stage
另外,HyBSPCloud的BSP的中间结果不局限于内存,其输入输出和中间数据均可使用分布式文件系统.同时,为了更好地支持复杂计算并行应用,提供MR的变形版本,即MR的中间结果可以“粘”在内存中,而不是必须导出来持久化到分布式文件系统中.
3.3HyBSPCloud对大数据的支持
本研究采用3种方案来改善HyBSPCloud对大数据的支持.
(1)利用开源分布式文件系统来存放输入数据、输出数据,允许计算的中间数据自动持久化到文件中,这是目前支持大数据处理最通用的方法.若待处理数据不用分布式文件系统支持,完全加载于分布式内存,会导致无法满足海量数据的实际应用需求.开源分布式文件系统及其特点如表3所示.从开放性和成熟性来看,首选HDFS作为HyBSPCloud的文件系统.为支持大量并发访问的应用,HyBSPCloud也支持PVFS作为数据存储系统.

表3 开源分布式文件系统及其特点Table 3 Open source distributed file systems with their characteristics
(2)虚拟内存数据结构(vmstruct).HyBSPCloud提供应用运行时对vmstruct的源码解释支持.应用将vmstruct作为一般的全局数组来使用,但不同的是,vmstruct将大部分数据存放在外存,而只占用小部分内存堆空间,根据需要再进行新旧数据的替换.这种结构在一次性顺序地操作少量数据的应用中,可以解决由于内存限制导致大数据应用不能执行的问题.
(3)网络数据流(netdataflow).HyBSPCloud支持应用运行时访问netdataflow对象,将其作为一个不断流出或流入新数据的通道.数据的另一端点可以设置为持久化的文件、网络信道.
在现有的集群环境下,增加硬件存储容量并部署高性能的文件系统是解决并行大数据处理的基本方式.由于这种方式依靠文件系统的操作来访问数据,因此时间开销较大.若关于新型非易失存储介质、大容量新型混合内存体系结构等的内存计算技术能取得关键性进展,则大数据的并行处理技术也会得到突破.
3.4实验测试
为了检验所提出的两层混合并行的可行性,本研究设计了一个混合并行的综合实验.假设两个矩阵相乘C=A×B,且B的值已知,A的值需要通过分类统计数据集X得到.本例的一个应用解释如下:某地区有若干个工厂,每个工厂生产一种以上产品;每个工厂生产每种产品的月产量的信息存放在数据集X中,通过X可以得到该工厂生产每种产品的年产量A;每种产品的单价和单位利润存放在矩阵B中;求各工厂的总收入和总利润,即C.
为实验方便,假设A和B是浮点方阵,X中的值也默认为浮点数,X和B中的值都由随机函数生成.实验使用了如表4所示的硬件资源,程序采用HyBSPCloud并行编程库来开发.

表4 硬件参数Table 4 Hardware parameters
所有物理机运行版本为ubuntu 12.04的64位操作系统,虚拟化软件采用Xen hypervisor 4.1.2,客户操作系统采用ubuntu 10.04.4的32位操作系统.
从Host1上申请2个虚拟机(virtual machine,VM),Host2和Host3分别申请一个VM,每个虚拟机的vCPU为4个.为了更好地反映硬件资源的利用情况,实验中特别指定从特定物理机申请的虚拟机数量.
对于C=A×B的计算,有两种BSP程序版本:①用4个VM,每个VM上用1个thread来计算,即进程级并行;②用4个VM,每个VM上用4个thread来计算,即进程和线程混合并行.
版本①和②代码的不同点仅在于前者在每个VM上用直接法(单线程处理)计算子阵At×Bt(At,Bt分别是矩阵A和B的子阵),而后者在每个VM上把子阵At和Bt再分块后用4个线程并行计算.版本②使用了表5中的函数来管理多线程.

表5 共享内存模型主要函数Table 5 Main operational functions of shared memory model
用上述两种计算矩阵乘的BSP版本,分别进行规模2000×2000和4000×4000的实验,运行时间如图10所示.
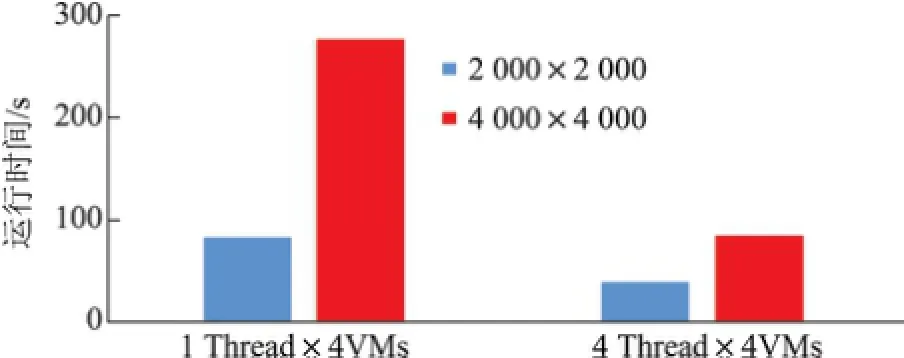
图1 0进程和线程混合并行的运行时间Fig.10 Running time of processes and hybrid parallel threads
上述计算A×B的BSP程序是完整计算C=A×B过程的一部分,该过程有以下3种版本.
(1)用MapReduce计算矩阵A的元素值,再用BSP计算A×B.
(2)调用BSP分块计算A×B,在BSP超步中,当用到每个A子块时,用MapReduce计算A子块的元素值.
(3)调用MapReduce计算A′(A′为A的部分值),在每个Map步后,调用BSP计算C′= A′×B,再对C′进行加操作的Reduce,最终得到C.
通过对上述3种版本产生的矩阵C进行比较,最终结果是一致的.由实验结果可以得出,两层混合并行是可行的、方便易用的.混合并行的性能分析和比较将是下一步的研究内容.
4 结束语
本研究针对同一个大数据应用的异质并行计算问题,提出两个层次上的混合并行方法.在执行单元层次的混合并行,即进程和线程的混合并行时,可以充分利用多核同构/异构硬件的计算资源,显著加快数据处理速度,这种混合并行对于具有密集计算的应用效果明显.计算模型层次的混合并行能适合应用的多样异构处理模式,使开发和部署运行过程更自然简洁.BSP 和MapReduce这两种计算模型在同一个编程框架HyBSPCloud上的实现,表明在充分考虑模型之间并行计算的流程连续和动态数据传递的前提下,计算模型混合并行是可行的.
另外,本研究还提出了3种方案以改善HyBSPCloud对大数据应用的支持,包括用分布式文件系统来存放中间输入/输出数据、采用虚拟内存数据结构来解决内存限制、通过网络数据流(netdataflow)来封装流动的数据通道.目前,本研究主要关注BSP和MapReduce这两种典型的大数据计算模型混合并行的可行性,下一步将进行这种混合方法的性能分析和性能优化技术研究,还将对其他计算模型的混合并行甚至统一并行模型的可能性进行探索.
[1]LYNCH C.Big data:how do your data grow?[J].Nature,2008,455(4):28-29.
[2]GOLDSTON D.Big data:data wrangling[J].Nature,2008,455(4):15.
[3]WANG S,WANG H J,QIN X P,et al.Architecting big data:challenges,studies and forecasts[J].Chinese Journal of Computers,2011,34(10):1741-1752.
[4]QIN X P,WANG H J,LI F R,et al.New landscape of data management technologies[J].Journal of Software,2013,24(2):175-197.
[5]ZHANG Y S,JIAO M,WANG Z W,et al.One-size-fits-all OLAP technique for big data analysis[J].Chinese Journal of Computers,2011,34(10):1936-1946.
[6]GONG X Q,JIN C Q,WANG X L,et al.Data-intensive science and engineering:requirements and challenges[J].Chinese Journal of Computers,2012,35(8):1563-1578.
[7]MA K,YANG B.Log-based change data capture from schema-free document stores using Map-Reduce[C]//2015InternationalConferenceonCloudTechnologiesandApplications (CloudTech).2015:1-6.
[8]JUNG G,GNANASAMBANDAM N,MUKHERjEE T.Synchronous parallel processing of bigdata[C]//2012 IEEE fifth International Conference on Cloud Computing.2012:811-818.
[9]LIU X,GAO W,HU Z Y.Hybrid parallel bundle adjustment for 3D scene reconstruction with massive points[J].Journal of Computer Science and Technology,2012,27(6):1269-1280.
[10]FEINBUBE F,SOBANIA J A,TR¨OGER P,et al.Light-weight programming of hybrid systems[J]. Parallel&Cloud Computing,2012,1(2):34-44.
[11]WANG P,MENG D,HAN J Z,et al.Transformer:a new paradigm for building data-parallel programming models[J].Micro IEEE,2010,30(4):55-64.
[12]PACE M F.BSP vs.MapReduce[J].Procedia Computer Science,2012,9:246-255.
[13]潘巍,李战怀,伍赛,等.基于消息传递机制的MapReduce图算法研究[J].计算机学报,2011,34(10):1768-1784.
[14]FEGARAS L.Supporting bulk synchronous parallelism in Map-Reduce queries[C]//High Performance Computing,Networking,Storage and Analysis(SCC).2012:1068-1077.
[15]QIN X P,WANG H J,DU X Y,et al.Big data analysis-competition and symbiosis of RDBMS and MapReduce[J].Journal of Software,2012,23(1):32-45.
[16]DING L L,XIN J C,WANG G R,et al.Efficient skyline query processing of massive data based on MapReduce[J].Chinese Journal of Computers,2011,34(10):1785-1796.
[17]VALIANT L G.A bridging model for parallel computation[J].Communication of the ACM,1990,33(8):103-111.
[18]MALEWICZ G,AUSTERN M H,BIK A J C,et al.Pregel:a system for large-scale graph processing[C]//Proceedings of the 2010 International Conference on Management of Data.2010:135-145.
[19]HAMA-a general BSP framework on top of Hadoop[EB/OL].[2015-10-20].http://hama. apache.org.
[20]AVERY C.Giraph:large-scale graph processing infrastructure on Hadoop[C]//Proceedings of the Hadoop Summit.2011:1-8.
[21]LIU X D,TONG W Q,FU Z R,et al.BSPCloud:a hybrid distributed-memory and sharedmemory programming model[J].International Journal of Grid and Distributed Computing,2013,6(1):87-98.
Multilevel hybrid parallel method for big data applications
HUANG Lei1,ZHI Xiaoli1,ZHENG Shengan2
(1.School of Computer Engineering and Science,Shanghai University,Shanghai 200444,China;2.Department of Computer Science and Engineering,Shanghai Jiao Tong University,Shanghai 200240,China)
Many large data applications require a variety of parallel data processing.This paper presents a two-layer hybrid parallel method,i.e.,hybrid parallel of execution units and hybrid parallel of computing model.By hybrid parallel of execution units on the same computing node.The computing power of infrastructure can be fully taped,and thus data processing performance can be improved.By integrating several calculation models into the same execution engine in a parallel way,diverse heterogeneous processing modes may be applied.Different hybrid parallel ways can meet different data and calculation characteristics,and meet different parallel objectives as well.This paper introduces the basic ideas of hybrid parallel methods,and describes main implementation mechanisms of hybrid parallelism.
hybrid parallelism;programming model;bulk synchronous parallel(BSP);MapReduce
TP 391
A
1007-2861(2016)01-0069-12
10.3969/j.issn.1007-2861.2015.04.017
2015-11-19
上海市科委科研计划资助项目(15DZ1100305)
支小莉(1974—),女,副研究员,博士,研究方向为并行计算、软件定义网络. E-mail:xlzhi@mail.shu.edu.cn
