一种上下文感知的E-commerce评级大数据赋权方法
2016-09-21齐连永窦万春周毓明南京大学计算机科学与技术系南京20093曲阜师范大学信息科学与工程学院山东日照276826
齐连永,窦万春,周毓明(.南京大学计算机科学与技术系,南京20093;2.曲阜师范大学信息科学与工程学院,山东日照276826)
一种上下文感知的E-commerce评级大数据赋权方法
齐连永1,2,窦万春1,周毓明1
(1.南京大学计算机科学与技术系,南京210093;2.曲阜师范大学信息科学与工程学院,山东日照276826)
电子商务(E-commerce)的飞速发展,产生了大量针对商品的在线评级数据,通过分析评级数据,用户可以对商品的质量进行评估.然而,评级数据的海量性和差异性使得用户难以快速而准确地评估商品的质量.鉴于此,提出一种基于E-commerce评级的上下文感知赋权方法(context-aware weighting approach,CWA),以选出少数“重要”的评级数据并抛弃大多数“不重要”的评级数据,从而确保商品质量评估的快速性和准确性.最后,通过一组实验验证了CWA的有效性.
E-commerce;用户评级;大数据;赋权;上下文
1 E-commerce评级大数据及其面临的挑战
网络技术的普及推动了电子商务(E-commerce)的飞速发展,越来越多的用户通过在线购物网站进行消费,例如天猫商城在2015年11月11日(双十一)的日销售金额达到921亿元.然而,由于电子商务的虚拟性,用户无法直观地了解在线商品的质量,这给用户对商品进行选择带来了巨大困难.目前,电子商务领域主要采取用户评级的方式(如常用的1*~5*评级)[1],对商品质量进行反馈,以供新用户参考.这样,通过分析历史的用户评级数据,新用户可以对商品质量进行评估,进而作出购买决策.
然而,目前基于用户评级的商品质量评估存在如下两方面的挑战.
(1)评级数据的“海量性”.随着电子商务的发展,在线购物逐渐成为广大用户的首选消费方式,从而导致目前关于商品的在线评级数据量非常庞大.例如,在2015年10月这一个月中,“小米红米Note2”在天猫商城的月销售量高达670 372台,相对应的在线用户评级数据高达166 184条.如此海量的评级数据使得新用户的商品评估及选择成本急剧上升.
(2)评级数据的“差异性”.在线评级系统的众多评级数据中,评级时间、评级用户、评级分值等方面存在较大差异.这种差异性使得新用户难以准确评估商品的真实质量,进而难以作出购买决策.
鉴于上述两方面挑战,本研究提出一种针对用户评级的赋权方法,在进行商品评估时,仅仅选取对新用户“较为重要”的少数评级数据,而抛弃绝大多数“不重要”的评级数据,从而确保新用户可以较为准确快速地进行商品质量评估,在评估准确性和评估速度之间取得一个合理的“折衷”.
2 用户评级的赋权方法
2.1影响评级权重的上下文分析
对于新用户而言,对于某一评级数据的重视程度取决于该评级的多种上下文因素.本研究考虑如下3种上下文因素.
(1)评级时间.一般而言,商品(或服务)的质量不会一成不变,而是在不断变化,因此同一商品(或服务)的多条评级数据在时间上符合“挥发效应”[2],即越“新”的评级越能反映商品(或服务)当前的真实质量,而越“旧”的评级则没有过多参考价值.
(2)评级用户与新用户的偏好相似度.用户对商品(或服务)的评级数据是一种掺杂了个人主观偏好的“非客观”数据,因此如果一条评级数据所对应的历史用户和新用户具有相似的偏好,那么该条评级数据对于新用户的商品评估具有较高的指导意义,反之亦然.
(3)评级分值.目前,电子商务领域主要采用1*~5*的评级体系,而评级分值的大小和该评级的重要程度往往具有相关性.例如,极端评级(好评5*和差评1*)往往对用户的选择决策影响较大.而且由于用户评级经常出现“偏正向”的特点,新用户往往更重视较差的评级,而轻视较好的评级.
2.2CWA——基于多维上下文因素的评级赋权方法
基于上述3种影响评级权重的上下文因素,下面介绍一种针对用户评级的上下文感知赋权方法(context-aware weighting approach,CWA),具体研究框架如图1所示.
2.2.1基于评级时间的评级赋权
如前所述,一个评级越“新”,越能反映商品(或服务)的最新质量,其对于新用户的参考价值也就越大.此外,根据评级时间对用户评级进行赋权时,还应考虑时间的“边际效应”[3-4],即在“权重-时间”曲线的边际部分,权重的变化应趋缓(例如“最新”的两个评级的权重应差异不大,而“最旧”的两个评级的权重也往往比较接近).基于上述分析,采用arctan函数
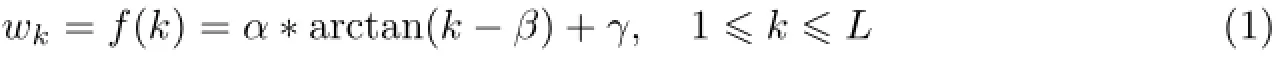
来刻画评级“权重-时间”之间的相关关系(见图2,借鉴文献[6]中的单边“嗅觉退化曲线”).式中,L代表同一商品(或服务)的评级总数,k代表该商品(或服务)的第k个评级(按时间先后排序,k越大代表评级越“新”,反之亦然),wk表示第k个评级的权重(仅考虑评级时间),α,β,γ为3个参数.
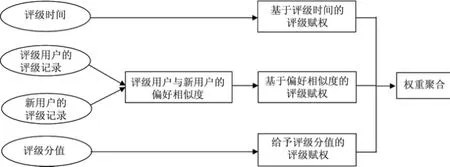
图1 CWA的研究框架Fig.1 Research framework of CWA
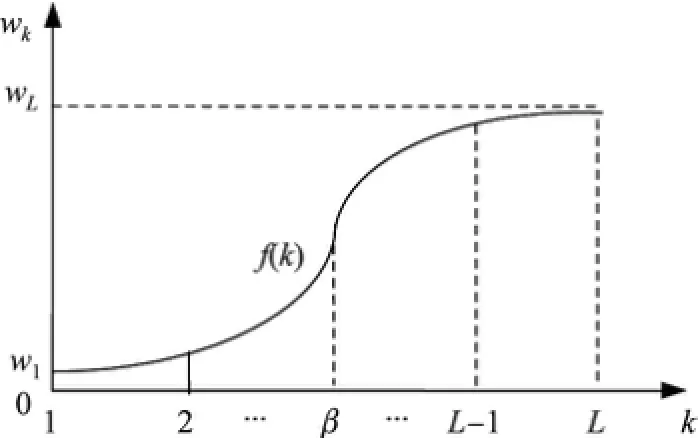
图2 用户评级的“权重-时间”关系Fig.2 Relationship of“weight-time”for user ratings
接下来介绍如何求解3个参数α,β,γ的值.首先,根据图2曲线的对称性,可得

其次,根据权重的意义,L个评级的总权重等于1,可得

再者,根据心理学的Miller法则(人脑的短期记忆能力是有限的,每次最多处理7±2件事情)[5],最新的9个评级数据对新用户的参考价值最大,这里结合“20/80法则”[6],设置前9个评级的权重和为0.8,可得

这样,联立式(1)~(4),可以求得参数α,β,γ的值,进而根据式(1),可以求得各个评级的权重wk(仅考虑评级时间).
2.2.2基于偏好相似度的评级赋权
根据评级用户的历史评级记录、新用户的历史评级记录,可以度量这两种用户的偏好相似度.这里采用经典的协同过滤技术来计算新用户Usernew和历史评级用户Userk(即第k个历史评级所对应的用户)的偏好相似度,记为Sim(Usernew,Userk),即
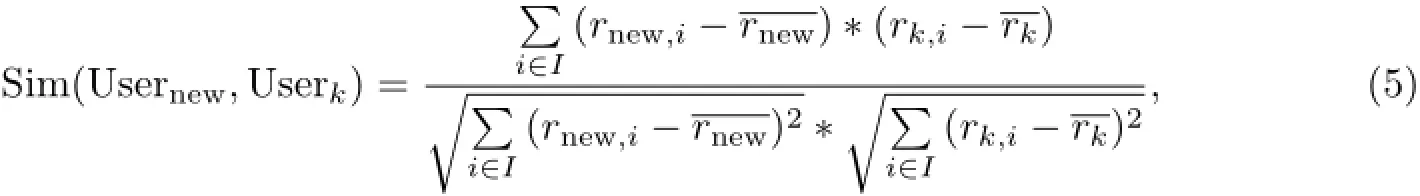
式中,集合I代表Usernew和Userk共同评价过的商品(或服务)的集合,rnew,i和rk,i分别代表Usernew和Userk对商品i的评级分值,代表Usernew评价过的所有商品的评级均值,而则代表Userk评价过的所有商品的评级均值.
一般而言,Userk与Usernew的偏好越相似,Userk的历史评级对Usernew的参考意义就越大,二者之间存在一种“正相关”的关系.本研究采用下式所示的简单线性相关来建模这种“正相关”关系,即
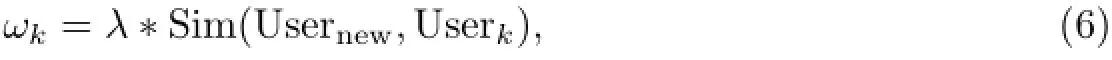
式中,ωk代表第k个历史评级的权重(仅考虑用户的偏好相似度),λ为参数(λ>0).此外,根据权重的意义,可得

这样,联立式(6)和(7),可以求得参数λ的值.进而根据式(6),可以求得各个评级的权重ωk(仅考虑用户的偏好相似度).
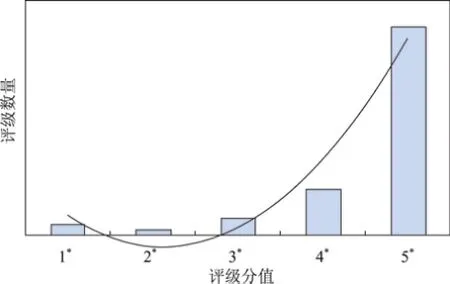
图3 E-commerce用户评级的分值分布Fig.3 User rating score distribution in E-commerce
2.2.3基于评级分值的评级赋权
在E-commerce领域,极端评级(好评5*和差评1*)对于新用户的选择决策往往影响更大.此外,用户的在线评级往往呈现“双峰J形分布”(见图3)及“偏正向”(即用户倾向于给予好评,而非差评;当用户未进行评级时,系统往往默认好评)的特点[7].因此,对于新用户而言,差评往往比好评更具有参照意义.为了克服评级分值的“双峰J形分布”对可信评估的不利影响,本研究采用如表1所示的分段等差数列来刻画五种评级分值的相对重要性(以差评1*作为参考基准,其相对重要性Score(1*)设为1).表1中,rk代表第k个评级的分值(rk∈{1*,2*,3*,4*,5*}),权重ψk代表第k个评级的权重(仅考虑评级的分值),p为参数(p>0).
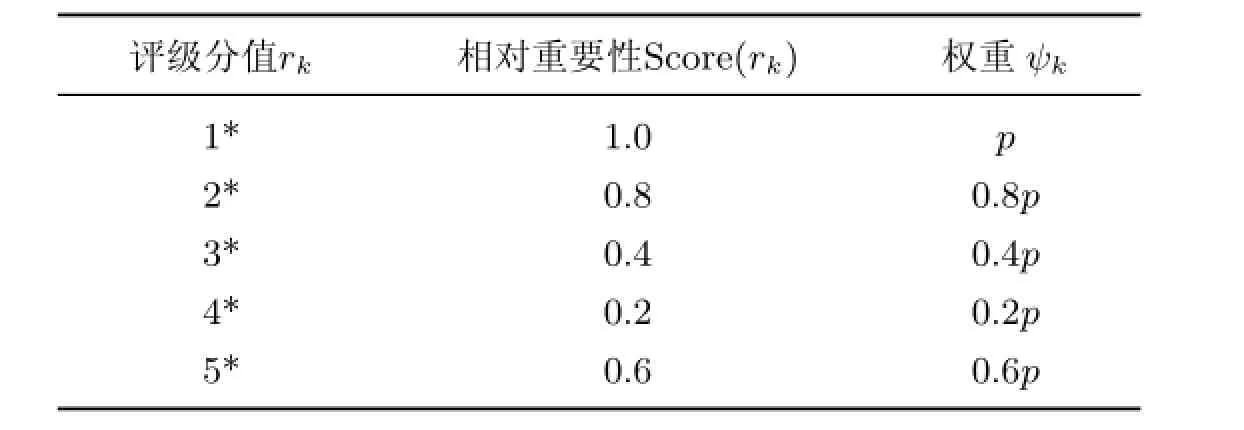
表1 五种评级分值的权重设计Table 1 Weight design of five rating scores
那么根据权重的意义,可得

通过求解式(8)可得参数p,进而根据表1可以求得各个评级的权重ψk(仅考虑评级的分值).
2.2.4权重聚合
前面分别得到了第k个评级的分权重:wk(仅考虑评级时间)、ωk(仅考虑用户的偏好相似度)和ψk(仅考虑评级的分值).接下来将通过线性加权的方式,对上述3种分权重进行聚合,进而得到第k个评级的综合权重Wk,即

式中,a,b,c为聚合系数,且满足条件a+b+c=1(0<a,b,c<1).
3 实验评估
下面将设计一组实验来验证所提出的CWA的有效性.
3.1实验数据集及实验部署
本实验采用美国Minnesota大学计算机科学与工程学院的GroupLens项目组创办的MovieLens 1M Dataset[8].该数据集收集了6 000名用户对4 000部电影的超过100万条历史评级记录,是目前在线推荐系统所广泛采用的标准实验数据集之一.在实验中,随机选取100部电影,即Movie-set={M1,M2,···,M100};对于其中每部电影Mi(i=1,2,···,100)(假设Mi拥有L个历史评级,且已按时间先后进行排序),将第L个评级的真实分值rL,i作为实验的评估基准(即benchmark),而用前面的L-1个历史评级来预测第L个评级的分值rp,i;然后,利用平均绝对误差(mean absolute error,MAE)来评估预测结果的准确性,MAE越小,说明预测越准确,其计算公式如下:为了评估参数L对预测准确性的影响,取L=100,200,300,400,500.实验硬件环境为Lenovo笔记本(2.50 GHz CPU,1.0 GB RAM),软件环境为Windows XP,Matlab7.0.每个实验执行10次并取其平均实验结果.
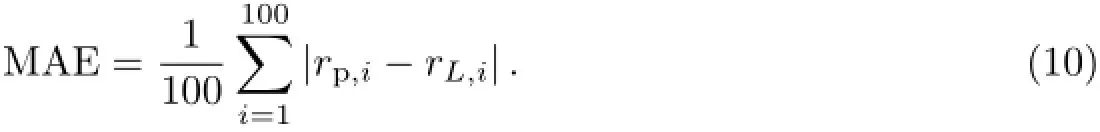
3.2实验结果
将CWA与另外两种赋权方法Average[9]和Last-K[10]进行实验比较,其中Average方法考虑商品(或服务)的所有评级并赋予相同的权重,Last-K方法仅考虑最新的K个评级(默认K=4),并为这K个评级赋予相同的权重.而CWA仅考虑权重排名前9的评级(基于Miller法则),且取式(9)中a=b=c=1/3.接下来分别比较3种方法的预测准确性、时间开销,以及新用户在评估商品时需要参考的评级数量.
3.2.1预测准确性
根据3种评级赋权方法(CWA/Average/Last-K),可以预测benchmark评级的分值,进而根据式(10)计算该赋权方法的平均绝对误差MAE,MAE值越小,说明预测越准确.实验结果如图4所示,其中历史评级的数量L=100,200,300,400,500.从图4可以看出,Average方法的预测准确性较差,这是因为该方法并未考虑各历史评级的上下文差异,而对所有评级同等对待;Last-K方法由于仅考虑了历史评级的时间信息,使得其预测准确性较Average方法有所提高;而CWA的预测准确性最高,这是因为CWA综合考虑了历史评级的时间、用户偏好、评级分值等上下文信息,能够更好地契合新用户的商品(或服务)选择偏好和习惯.
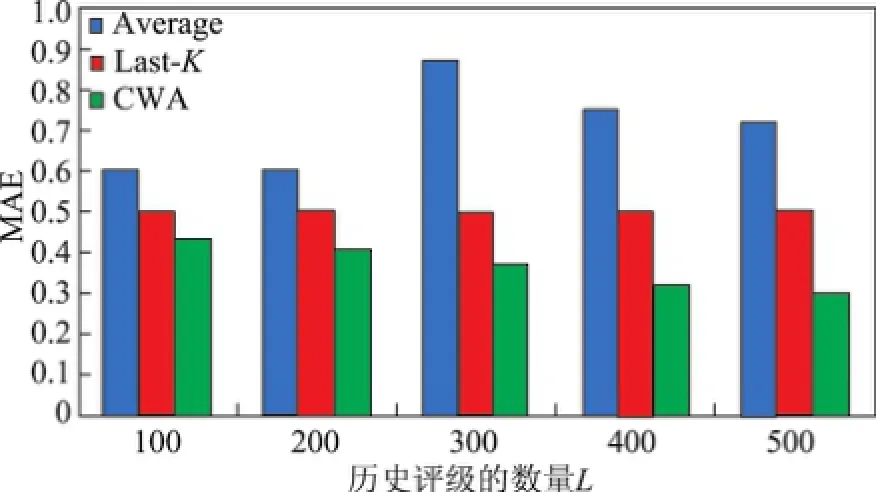
图4 3种评级赋权方法的预测准确性比较Fig.4 Prediction accuracy comparison of three rating weighting approaches
此外,图4揭示了3种方法的预测准确性随历史评级数量L的变化趋势.具体而言,当L增大时,Average方法的预测准确性不稳定;Last-K方法仅考虑K(默认K=4)个历史评级,所以其预测准确性保持不变;而CWA方法的预测准确性随L的增大而略微提高,这是因为当L增大时,CWA方法所选出的9个历史评级的权重更高,更加契合新用户对商品(或服务)的选择偏好.
3.2.2时间开销
比较3种赋权方法的时间开销随历史评级数量L的变化趋势,结果如图5所示.从图5可以看出,Last-K方法的时间开销最低,且与L无关,这是因为该方法仅考虑最近的K(默认K=4)个历史评级,而忽略剩余的L-K个历史评级;Average方法与CWA的时间开销均随L的增大而呈现近似线性的增长趋势,这是因为两种方法在赋权时考虑了所有的L个历史评级;此外,CWA的时间开销较Average方法更大,这是因为前者在计算各评级的具体权重时需要花费较多的时间.不过,CWA的时间复杂度近似线性,且时间开销属于“毫秒”级,基本能够满足E-commerce领域中大多数用户的响应时间要求.
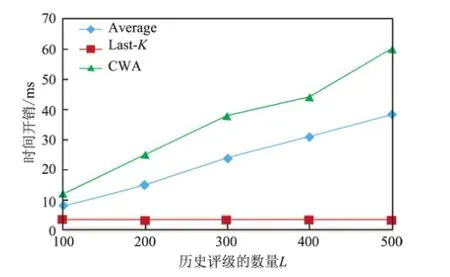
图5 3种评级赋权方法的时间开销比较Fig.5 Time cost comparison of three rating weighting approaches
3.2.3新用户在评估商品时需要参考的评级数量
假设一个商品(或服务)拥有L个历史评级,而将新用户在评估该商品(或服务)的质量时需要参考的评级数量记为n(显然0<n≤L).比较3种赋权方法的n值(见图6),可见Average方法中新用户需要参考所有的L个评级,才能评估一个商品(或服务)的质量,即n=L;Last-K方法中新用户仅需参考最近的K(默认K=4)个评级,即n=4;而在CWA中,新用户仅需参考权重最高的9个评级(基于Miller法则),即n=9.
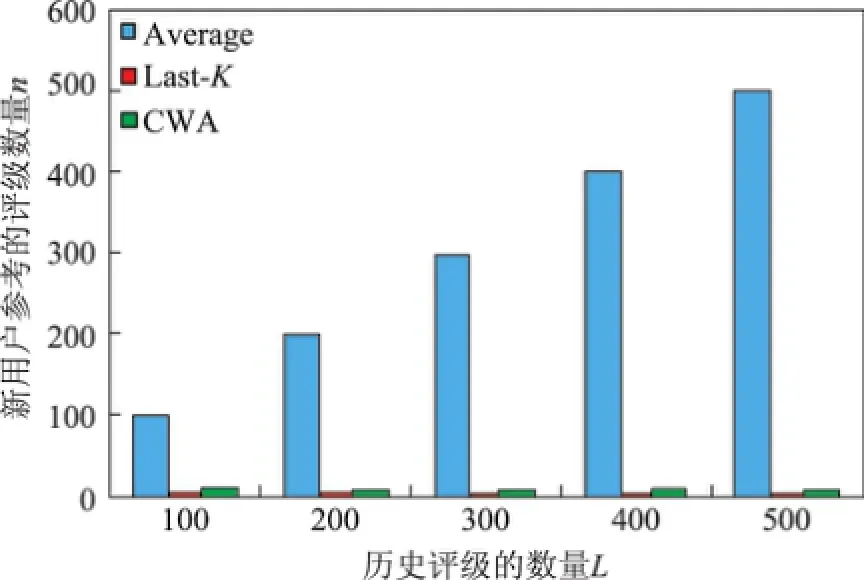
图6 3种评级赋权方法中新用户需要参考的评级数量比较Fig.6 Comparison of referenced rating number by new user of three rating weighting approaches
综上所述,本研究所提出的CWA实际上是对Average方法和Last-K方法的一种“折中”,虽然CWA耗费了较多的运行时间(见图5),但却减轻了用户端的负担,大大降低了新用户在评估商品质量时的决策成本(见图6),同时保证了评估结果的正确性(见图4).
4 相关工作及对比分析
E-commerce的飞速发展使得商品(或服务)的在线评级数据量越来越庞大,如何有效利用这些历史评级数据来为新用户的商品(或服务)评估提供决策支持,成为目前E-commerce领域的热点研究问题之一.而由于商品历史评级的海量性和差异性,使如何对各个历史评级进行合理赋权和优化筛选,以确保商品评估的准确性和快速性,成为目前E-commerce领域所面临的一大挑战.许多学者对这一问题进行了大量的研究,并取得了部分阶段性成果.
文献[11]分析了服务时间与权重之间的相关关系,但是缺少定量的权重计算模型.文献[9]采用平均化的Average方法来评估商品(或服务)的质量,但是该方法平等对待所有的历史评级,并未考虑各个评级的上下文差异.文献[2]和[12]分析了评级权重与评级时间之间的相关关系,认为用户评级呈现某种“挥发效应”(volatile effect),即随着时间的推移,一个评级将会变得越来越不重要.但是,上述文献仅仅对用户评级的“权重-时间”关系进行定性描述,并未给出量化的权重模型.文献[10]采用Last-K方法对用户的历史评级进行赋权,对最近的K个评级赋予相同的权重1/K,而剩余评级的权重置为零,该方法考虑了用户评级的“挥发效应”,强调了最近评级的重要性.文献[4]和[13]分别采用等比数列和等差数列,按照用户评级的时间先后对评级进行赋权,取得了较好的效果.但是,上述文献仅仅考虑了用户评级的时间信息,并未考虑其他评级的上下文信息.
此外,文献[7]经过大量的统计分析,发现用户评级呈现偏正向的“双峰J形分布”,因此为了弱化用户评级的“偏正向”效应,将评级的分值大小作为评级权重的设计依据.但是,文献[7]侧重于对用户评级的“偏正向”现象进行解释和分析,而并未给出具体的偏正向校正方案.
本研究在上述研究工作的基础之上,提出了一种上下文感知的用户评级赋权方法,不仅综合考虑了用户评级的时间、用户偏好、评级分值等多种上下文信息,而且给出了定量的权重计算模型.通过实验进一步验证了CWA的有效性,实验结果表明:CWA的时间开销虽然稍大,但却大大降低了新用户对商品(或服务)的评估成本,同时获得了较高的评估准确性,从而在时间开销、评估成本、评估准确性之间了实现了良好的“折中”.
5 结束语
E-commerce评级数据的海量性和差异性使得新用户难以快速而准确地评估商品(或服务)的质量.鉴于此,本研究提出了一种上下文感知的评级大数据赋权方法,本方法综合考虑了用户评级的时间、用户偏好、评级分值等多种上下文信息,以选出少数“重要”的评级数据,并抛弃大多数“不重要”的评级数据,从而确保新用户可以对商品(或服务)进行快速而准确的质量评估.最后,通过一组实验验证了CWA的有效性.
在下一步的研究工作中,将在CWA中引入更多的评级上下文信息,以进一步提高权重设计的合理性和准确性;此外,E-commerce评级数据的更新速度很快,未来将对用户评级的时效性问题进行更加深入的讨论和分析.
[1]YIN H Z,CUI B,CHEN L,et al.Modeling location-based user rating profiles for personalized recommendation[J].ACM Transactions on Knowledge Discovery from Data,2015,9(3):1-41.
[2]WAN Y.The Matthew effect in online review helpfulness[C]//15th International Conference on Electronic Commerce.2013:38-49.
[3]VICKREY W.Measuring marginal utility by reactions to risk[J].Econometrica,1945,13(4):319-333.
[4]WU Y,YAN C G,DING Z J,et al.A novel method for calculating service reputation[J].IEEE Transactions on Automation Science and Engineering,2013,10(3):634-642.
[5]MILLER G A.The magical number seven plus or minus two:some limits on our capacity for processing information[J].Psychological Review,1956,63(2):81-97.
[6]GIBBARD A.A Pareto-consistent libertarian claim[J].Journal of Economic Theory,1974,7(4):388-410.
[7]HU N,KOHB N S,REDDY S K.Ratings lead you to the product,reviews help you clinch it?The mediating role of online review sentiments on product sales[J].Decision Support Systems,2014,57:42-53.
[8]Minnesota University.MovieLens 1M Dataset[EB/OL].[2015-11-10].http://grouplens.org/ datasets/movielens/.
[9]QI L Y,YANG R T,LIN W M,et al.A QoS-aware web service selection method based on credibility evaluation[C]//IEEE International Conference on High Performance Computing and Communications.2010:471-476.
[10]SONG R,LI B,WU X,et al.A preference and honesty aware trust model for web services [C]//APSEC.2012:61-66.
[11]ZHONG Y,FAN Y,HUANG K,et al.Time-aware service recommendation for mashup creation in an evolving service ecosystem[C]//IEEE International Conference on Web Services.2014:25-32.
[12]龙军,刘昕民,袁鑫攀,等.一种基于信任推理与演化的Web服务组合策略[J].计算机学报,2012,35(2):298-314.
[13]LIU J,BAI Y J,PATIL M,et al.Selecting a list of network user identifiers based on long-term and short-term history data:U.S.,US8527526 B1[P].2013-09-03.
A context-aware weighting approach for big data of quality ratings in E-commerce
QI Lianyong1,2,DOU Wanchun1,ZHOU Yuming1
(1.Department of Computer Science and Technology,Nanjing University,Nanjing 210093,China;2.School of Information Science and Engineering,Qufu Normal University,Rizhao 276826,Shandong,China)
With the fast development of E-commerce,large amounts of quality rating data for commodities are generated online.By analyzing the rating data,users can evaluate the commodities'quality.However,due to the massiveness and diversity of the rating data,it is a challenge for users to evaluate the commodity quality quickly and accurately.To this end,a context-aware weighting approach for E-commerce ratings,context-aware weighting approach(CWA)is proposed.With CWA,a few important rating data are selected and most unimportant data dropped.Thus the commodity quality can be evaluated quickly and accurately.A series of experiments validate effectiveness of the proposed CWA.
E-commerce;user rating;big data;weighting;context
TP 311.5
A
1007-2861(2016)01-0036-09
10.3969/j.issn.1007-2861.2015.04.021
2015-11-30
国家自然科学基金资助项目(61402258);江苏省重点研发计划资助项目(BE2015154);国家电网公司科技资助项目;中国博士后科学基金资助项目(2015M571739);江苏省自然科学基金资助项目(BK20130014)
窦万春(1971—),男,教授,博士生导师,研究方向为服务计算、大数据、云计算.E-mail:douwc@nju.edu.cn
