互联网商品匹配算法
2016-09-21上海交通大学电子信息与电气工程学院上海200240南通大学计算机科学与技术学院江苏南通22609
顾 颀,朱 灿,曹 健(.上海交通大学电子信息与电气工程学院,上海200240;2.南通大学计算机科学与技术学院,江苏南通22609)
互联网商品匹配算法
顾颀1,2,朱灿1,曹健1
(1.上海交通大学电子信息与电气工程学院,上海200240;2.南通大学计算机科学与技术学院,江苏南通226019)
实体解析是指识别同一实体的不同描述形式的过程,旨在保障数据质量,是数据清理、数据集成及数据挖掘中的关键技术.随着电子商务的不断发展和成熟,商品的多样性和消费者灵活的购买方式,使得对网络商品的精确识别和匹配成为大数据时代亟待解决的问题.与传统实体解析主要针对结构化数据不同,网络数据具有非结构化、异构和海量的特性,为此设计了综合相似度算法(synthesized similarity method,SSM)来计算网络商品数据间的相似度,同时引入凝聚的层次聚类框架,以匹配来自不同数据源的异构商品.此外,为了解决大数据环境下对执行效率的要求,从字符串相似度缓存、约束知识库和分块策略三个方面对SSM进行优化,基于真实数据集的实验结果验证了SSM的执行效率和有效性.
实体解析;大数据;非结构化数据;商品匹配
电子商务的持续发展给人们带来了庞大的数据总量以及复杂的数据形式,数据的关联形态正在发生变化,这些都给数据处理带来了极大的挑战.以互联网环境下丰富的网络商品为例,随着商品多样性的提升,同一网络商品在不同网络平台往往以各种形式存在着,相似商品信息散落在各个网络平台,网络商品的搜索空间不断增加,使得消费者在感兴趣的商品信息的搜索与整合上耗费了大量精力.如将散落在各个网络平台的商品信息关联起来,势必有利于商品信息的搜索与整合,从而免去消费者繁重的搜索工作.而为了将来自不同网络平台的商品信息进行关联,首要任务是完成商品的匹配,即从不同网络平台中找出同一网络商品的不同表述,将这一过程称为实体解析(entity resolution)[1],或称为记录连接(record linkage)、对象匹配(object matching)、重复检测(duplicate detection)等[2].
实体解析是以数据为中心的各项工作(如数据清理、数据集成、数据挖掘等)中至关重要的步骤,是数据质量的保障.不同网络平台(数据提供方)对同一网络商品(实体)可能会有不同的描述,如数据格式、表示方法等.将实体的描述称为实体的引用,实体解析是指从引用集合中解析并映射到现实世界中实体的过程.传统的实体解析方法可以分为成对实体解析[3]、集合实体解析[4]和时态实体解析[5].这三种实体解析方法适用于结构化数据的解析,例如一般关系数据库中的元组.事实上,在真实的网络商品匹配中,需处理的数据没有统一的模式,也没有预定义的“键”和“值”,将这样的数据称为非结构化数据,其匹配策略与传统的面向结构化数据的解析方法相比有很大差别.本研究正是以此为切入点,对现有商品匹配算法存在的不足进行了深入剖析,并提出了有效的解决方案.
目前常用的面向网络商品匹配的算法主要有WHIRL(word-based heterogeneous information retrieval logic)算法[6]和TMWM(title model words method)[7].WHIRL算法主要采用TF-IDF以及向量空间模型对商品引用进行建模,并计算商品之间的相似度;TMWM结合了商品名称间的归一化编辑距离,以及从名称中抽取的“模式词”集合之间的相似度.WHIRL算法和TMWM存在以下两个缺陷:①网络商品往往遍布于不同的网络平台,算法只能处理来自两个数据提供方的商品数据,而无法处理来自多个网络平台的商品数据;②网络商品数据具有非结构化、异构性等特征,算法只能针对结构化数据进行商品名称的比对,而无法对非结构化商品数据计算相似度.
为了应对网络商品数据给商品匹配带来的挑战,本研究提出了一种基于凝聚层次聚类框架的商品匹配方法,使用综合相似度算法(synthesized similarity method,SSM)计算商品之间的相似度.SSM将从商品名称中获取的信息以及从商品属性的键值对中获取的信息有效结合起来,构造综合的相似度计算方法,最终根据相似度的值确定商品是否匹配.引入的凝聚层次聚类(agglomerate hierarchical clustering,AHC)框架可以在不影响匹配准确度的前提下实现多源商品数据匹配.为了解决大数据对执行效率的要求,从以下三个方面对所提出算法进行了优化:使用字符串相似度缓存、添加约束知识库以及应用分块策略.最后,基于真实数据集的实验结果验证了所提出算法的执行效率和有效性.
本研究的主要工作及贡献可总结如下.
(1)提出了基于凝聚层次聚类的商品匹配框架,解决了传统算法无法处理多源商品匹配的问题.
(2)基于非结构化网络商品数据设计开发了综合相似度算法,将商品的有效信息充分结合起来,提高了商品匹配的准确度.
(3)为了适应大数据环境下对执行效率的要求,从三个方面对所提出算法进行优化,通过大量实验表明了所提出算法在性能上有明显提升.
1 相关工作
1.1实体解析概念
1946年,Dunn[8]提出了记录链接(record linkage)的概念;其后,Newcombe等[9]在1959年提出了实体解析的概念;之后,Fellegi等[10]将这个问题规范化并进行深入研究.经过几十年的发展,实体解析技术已经广泛应用于国民医疗系统、人口普查、多媒体数据库整合以及银行信贷系统等各个领域.常用的实体解析方法包括成对实体解析、集合实体解析以及时态实体解析.
1.1.1成对实体解析
成对实体解析通过计算一对记录各属性间的相似度衡量记录是否匹配.衡量方法包括基于规则、基于属性权重以及基于机器学习(包括决策树、支持向量机、嵌套分类器、条件随机场等).成对实体解析适用于对数据库内重复记录的检测以及数据库间的记录匹配.
1.1.2集合实体解析
成对实体解析通过引入领域知识、机器学习等方法提高了匹配准确度,然而独立的求解过程无法区别不同实体拥有相同属性这一情形.集合实体解析使得求解过程不再独立完成,而是借助关系的引入,使得更多关联信息被用于解析过程中.
1.1.3时态实体解析
传统的实体解析方法往往忽略了时态信息,而实际数据记录中常用时间戳描述现实世界实体在特定时间的状态.时态实体解析通过定义与时间间隔相关的“衰变率”,来减少对高相似的奖励和对低相似的惩罚,从而利用时态信息为实体解析提供更多的“证据”.
1.2商品匹配算法
随着网络商品数据的急速累积,网络商品的搜索空间不断增加,商品匹配变得愈发重要.目前,常用的网络商品匹配算法主要有WHIRL算法和TMWM.
1.2.1WHIRL算法
WHIRL算法由Cohen[6]于1998年提出,该算法利用向量空间模型对商品信息进行建模,并计算商品之间的相似度.在向量空间模型中,现实世界中商品的自然语言描述可以用词项构成的文本向量表示.向量中的成分对应文本中的某个词项,成分值与该词项在文档中的“重要性”相关联,词项越重要则对应的成分值越大.如果两个文档具有很多相同的“重要性”相近的词项,则可以认为它们是相似的.对词项赋予权重的方法有很多,其中TF-IDF(term frequency-inverse document frequency)方法经过改进后可以很方便地在向量空间模型中引用[6].尽管文本向量通常很长也很稀疏,但已有很多方法可以高效处理稀疏向量.
1.2.2TMWM
TMWM由Vandic等[7]于2012年提出,该算法结合了商品名称间的归一化编辑距离以及从名称中抽取的“模式词”集合之间的相似度.编辑距离是指将一个字符串转换成另一个字符串所需进行的最少操作数,已广泛应用于字符串相似度或差异度的计算中.由于未考虑字符串的长度,这样的编辑距离也称为绝对编辑距离.通过对绝对编辑距离进行归一化,可以处理长度较短的字符串.首先,计算两个商品名称间的余弦相似度,若相似度值高于阈值α,表明两个商品为同一商品,返回“true”;若相似度低于阈值α,则分别提取两个商品的模式词形成相应的模式词集合,再将两个集合中的模式词对进行逐一比较,如果存在一个模式词对的非数字字符近似而数字字符不同,那么这两个商品为不同商品,返回“false”,如果非数字字符和数字字符都一致,则更新两个商品名称之间的相似度,即求出两个商品名称的余弦相似度和两个商品名称所产生的两个模式词集合间的平均编辑距离相似度的加权和,最终相似度如果大于预设的阈值ε,则两个商品为同一商品,返回“true”.
2 基于凝聚层次聚类的商品匹配框架
2.1凝聚层次聚类(AHC)方法
WHIRL算法和TMWM适用于分析两个网络商店的商品(假设同一网络商店内没有重复商品).事实上,商品搜索往往涉及多个数据源,为此需要将算法的输出从两个商品间的相似度变为存储不同商品间的距离,或称为相似度矩阵,在该矩阵上运行聚类算法.k-means算法和层次聚类算法是最常用的聚类算法.k-means算法将全部集中的个体分成k个子集,但在网络商品搜索的应用背景下,无法预知确切的k值;层次聚类算法则不需要额外的先验知识.传统的层次聚类算法主要分为两大类:①分离(自顶向下)的层次聚类,即初始时将所有的点视为一个簇,之后将簇的一部分分离出来形成一个新簇,重复这一过程直至每个簇中只包含单独的点,此类算法需要确定哪个簇应该被分离以及如何被分离;②凝聚(自底向上)的层次聚类,即初始时将每个点作为单独的簇,之后合并最相邻的两个簇,重复这一过程直至最后只剩下一个簇,此类算法需要预先定义簇之间的距离,以此作为簇合并的依据.这两种层次聚类方法中凝聚的层次聚类较为常用.
凝聚层次聚类中的关键问题是簇间距离的计算.不同的簇间距离计算方法又将凝聚层次聚类分为以下三种模式:单链模式(MIN)、全链模式(MAX)和组平均(group average)模式.单链模式又称最小值模式,簇间距离等于簇中成员间的最短距离.这种策略容易造成“Chaining”效应,即两个实际离得较远的簇由于簇中个别距离较近的点而合并,使得离得较远的点因为若干离得较近的“中介点”而被链接起来,并且这种效应可能会逐渐扩大.全链模式又称最大值模式,簇间距离等于簇中成员间的最远距离,与单链模式相反,全链模式中离得较近的簇可能因为其中个别离得较远的点而无法合并.组平均模式是单链模式和全链模式的折中策略.本研究使用基于组平均策略的凝聚层次聚类作为商品匹配算法的框架.
2.2综合相似度算法(SSM)
TMWM通过分析商品名称判断商品是否匹配,该算法要求将商品名称以某种特定的方式进行编码,尽可能将有辨别性的信息体现在商品名称中.然而这一要求对真实数据却过于严苛,在大多数情况下真实数据的商品名称只提供商品的型号信息.显然,在实验数据集上仅仅利用商品名称信息进行匹配,结果并不能让人满意.因此,本研究提出了综合相似度算法(synthesized similarity method,SSM),也可将其看作是对TMWM的改进,即添加了更具体更详细的商品信息比对,如商品属性等.以相机为例,添加了相机的一系列参数比如相机像素、显示屏尺寸、传感器尺寸、光学变焦、感光元件类型等.显然,相比单纯利用商品名称信息,这些额外信息能够获得更好的匹配结果.
所有商品属性可以以键值对(key-value pair,KVP)的形式来表示,如“相机像素”、“2 000万”.将从商品名称中获取的信息以及从商品属性的键值对中获取的信息结合起来,得到综合相似度
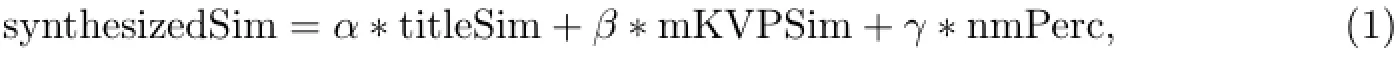
式中,α+β+γ=1.综合相似度算法共分三部分:titleSim,mKVPSim,nmPerc,其中第一部分titleSim是两个商品名称间的相似度,该相似度取自TMWM;第二部分mKVPSim和第三部分nmPerc是针对商品属性键值对计算的相似度.SSM中的符号注释如表1所示.

表1 算法符号注释Table 1 Algorithm notations
SSM假设同一网络平台没有重复商品,若两个商品来自同一平台,则它们之间的距离disti,j为∞;否则,继续比较商品的属性键值对.为了利用属性键值对信息,选择q-gram算法[11]衡量相似度,该算法能很好地应对拼写错误,并且不需要额外的标签.q-gram算法设置了一个大小为q个字符的滑动窗口,这些长度为q的子串构成一个子串集合,然后比较两个字符串生成的子串集合的相似度:假设字符串s1和s2相应的子串集合分别为C1和C2,则s1和s2的q-gram相似度为
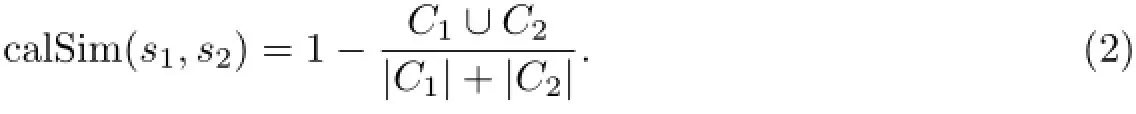
根据calSim的定义可以看出,即使是部分匹配也会为最后的相似度作出贡献,这在处理拼写错误以及缩写时很有优势.应用calSim计算相似度后,如果两个键的相似度大于阈值µ,则计算这两个键对应值的相似度:假设商品i和j的键值对集合分别为Ki和Kj,则Ki和Kj的相似度为
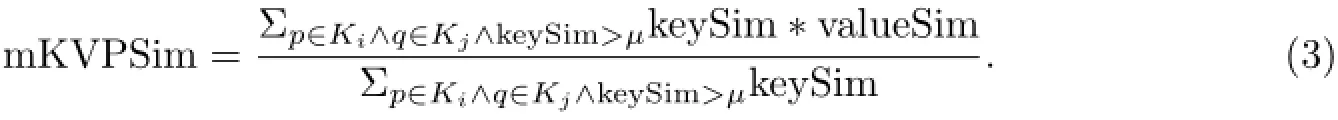
找出所有键匹配的键值对并计算相似度后,分析剩余的未匹配键值对.此时忽略这些键值对的键,分别抽取商品属性值中的所有模式词生成模式词集合,接下来计算这两个集合中匹配的模式词所占比例为
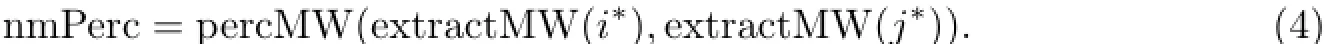
由式(3)和(4)计算得到mKVPSim和nmPerc后,再采用TMWM计算商品名称间的相似度titleSim.接着,按照式(1)计算得到综合相似度,并将相似度转换成距离.最后,使用凝聚层次聚类方法求得聚合后的簇集合.算法1总结了完整的构造过程.

3 实验结果与分析
3.1实验设置
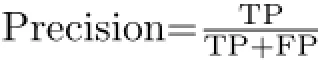
3.2商品匹配实验结果分析
3.2.1SSM结果分析
SSM共有3个参数µ,γ和ε需要训练,使用网格搜索训练ε的最佳值,范围为0.1~0.9,步长为0.1.在50个训练集上,µ,γ和ε最佳值的平均值为0.792,0.638和0.612,将其应用于测试集后得到平均Precision为0.627,平均Recall为0.583,平均F1-measure为0.609.与WHIRL和TMWM两个算法相比较可知:改进后的SSM在各方面效果都有所提升,详细的算法性能比较如表2所示.
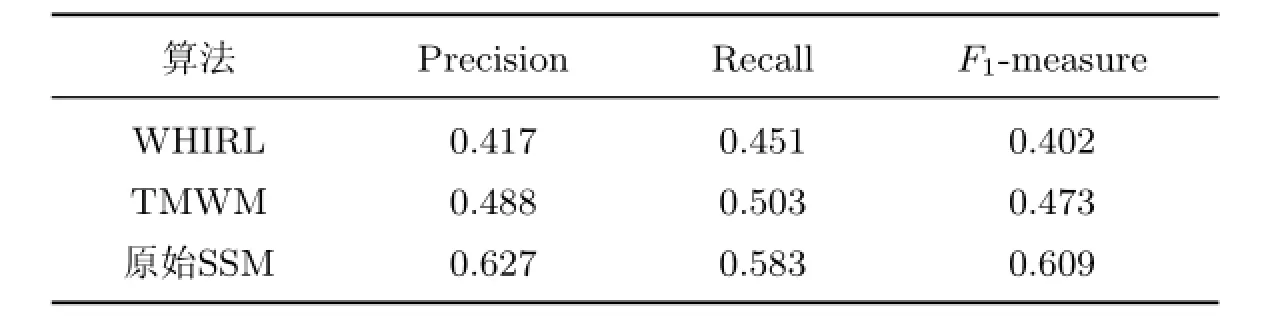
表2 3种算法的评价指标对比Table 2 Performance metrics of three different algorithms
3.2.2基于字符相似度缓存的算法实验结果分析
WHIRL算法,TMWM和SSM的复杂度主要都集中在字符串间相似度的计算上,实验中令每种算法在同一个数据集上运行50次,每个样本都将数据集划分为不同的训练集和测试集.如果每次运行新样本都要重新计算所有字符串间的相似度,显然这会浪费大量的时间.因此,预先计算所有字符串间的相似度并保存在一个global cache中,之后每次运行时直接从global cache中读取所需相似度,将会大大提高运行效率.为了预防系统崩溃或者重复测试,还可将global cache中的数据格式化地存储在硬盘当中.在实验数据集上应用此方法后,总运行时间从35 h 37 min减少到了6 h 19 min,速度为原来的5.63倍,可见添加global cache之后大大缩短了算法的运行时间,尤其是重复在同一数据集上运行时其优势更加明显.
3.2.3基于添加知识约束的算法实验结果分析
为提高算法准确性并避免多余计算,本研究为算法添加了根据常识或统计数据建立的约束库,也称知识库.知识库作为额外组件可灵活地参与到运算中,也可以根据新的数据和知识进行更新(扩充和改进),将参与到运算中的数据和知识统称为知识约束(knowledge constraints,KC).在计算一对引用间的相似度之前,可以先使用约束知识库的相关条目对目标引用对进行核查,若不符合其中任意一条约束,则终止比较,从而避免多余计算,缩短算法的运行时间.表3给出了应用于算法的知识库中的几个例子.
约束知识库能为算法提供更多的信息,或者说是证据.这些信息不同于字符串相似度,它们更直接也更可信.尤其值得注意的是,约束知识库给出的通常是一些必要条件,即不满足条件的引用对绝不可能指向相同的实体,应用这些知识约束可以筛除一些潜在的FP结果,从而提高算法的Precision.表4给出了SSM添加约束知识库前后的性能对比.

表3 知识约束类型和例子Table 3 Types and examples of knowledge constraints
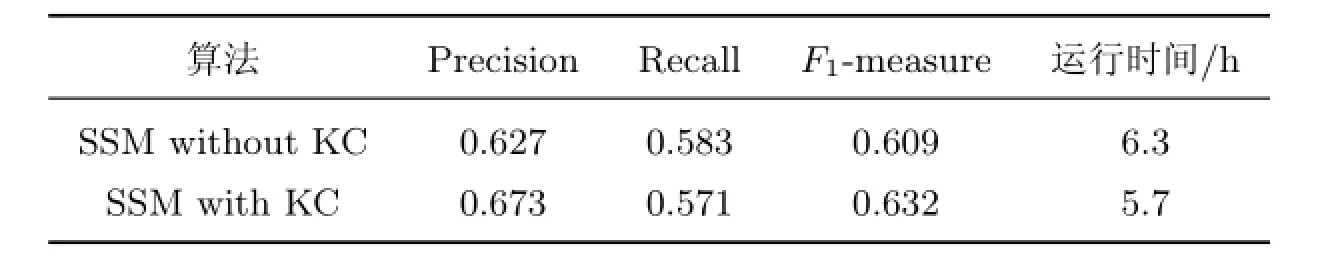
表4 SSM添加KC前后的性能对比Table 4 Performance comparison between SSM without and with KC
从表4可以看出,知识约束对算法的贡献主要体现在Precision上.尽管添加约束知识库后SSM的效率和性能均得到了提升,但不可否认的是,知识库依赖于领域知识.由于不太可能复用跨领域的知识库,不严谨或是过于严苛的约束又无疑将对算法产生负面影响(例如过于严苛的约束可能会增加FN的数目并影响Recall,从表3中可以看出Recall有轻微下降),因此领域知识库的建立需要领域专家的参与.
3.2.4基于分块策略的算法实验结果分析
本研究采用的真实实验数据集共有1 933条相机数据,计算规模(主要指字符串比较)已经达到了千万数量级,不难想象在大数据集上应用算法时将会面临效率问题.为此引入分块技术(block technique)对数据进行预处理,即根据某种知识或规则将数据集分成规模更小的数据块(block),在数据块里再进行商品匹配.
(1)基于hash函数的分块.
定义一个关于商品的一项或多项属性的hash函数,每个块都有一个hash值标识,将所有商品按照属性求hash值后归入互不相交的块中,商品匹配在块内完成.hash函数的种类多种多样,往往需要量身定制,可以将简单的规则合并以满足复杂的需求.minHash算法[12]就是基于多种hash键值进行分块的算法.根据实验数据集的特点,本研究选取品牌、像素以及显示屏尺寸三个参数作为minHash算法的键值列表.表5为应用minHash算法进行分块前后的SSM性能比较.

表5 SSM应用minHash算法进行分块前后的性能对比Table 5 Performance comparison between SSM without and with minHash algorithm
应用minHash算法进行分块后,算法运行速度从5.7 h缩短到3.5 h,提高了62.3%,但在Precision,Recall以及F1-measure三个性能指标上都有不同程度的降低.性能下降可能是由分块错误造成的,即同一商品被分到不同块中.在实验数据集上,运行时间尚在可承受范围之内,但若是面对极其庞大的数据集,这种性能与速度之间的权衡将至关重要.
(2)基于相似度与距离的分块.
McCallum等[13]提出Canopy算法来加速重复检测的过程.Canopy算法的基本思想是利用一些计算简便的参数为依据,将所有引用划分成互相部分重叠的簇(Canopies).将引用集合中的每一条引用都映射到空间中的一点,再根据空间中各点的位置将聚集的点划分到一个块中.应用Canopy算法前需要预先设计一个距离函数,如果使用之前计算的商品相似度作为分块依据,则函数代价太大,不妨以部分相似度或一些简单参数为依据,因此选择商品名称的q-gram相似度作为分块依据(q=3).实验中选择k-means算法以及凝聚层次聚类方法.表6给出了应用k-means算法进行分块前后的SSM性能比较.
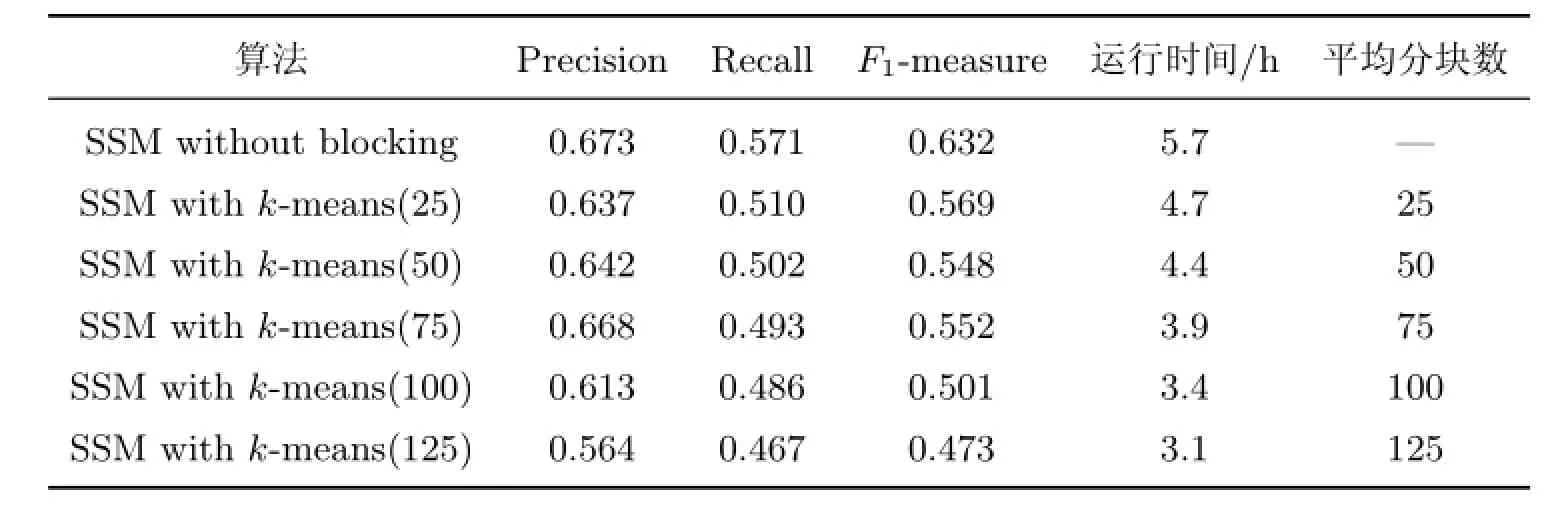
表6 SSM应用k-means算法进行分块前后的性能对比Table 6 Performance comparison between SSM without and with k-means algorithm
从表6可以看出,随着k值(簇的个数)的增大,Precision的变化呈现波形(当k=75时达到最大值),并且波形的前半段上升比较平缓,而后半段下滑明显加剧.这可能是由于选取商品名称的相似度作为分块依据在实验数据集上有较好区分度,并且在k=75时恰好与应该划分的簇个数等同.另一方面,当k=100及125时,由于簇的个数超出理想簇个数过多,聚类的过程变得不稳定,从而产生一系列连锁反应,导致产生很多FP.随着k值的增大,Recall逐渐下降并且趋于稳定,这是由于随着簇个数的增加,两个应该指向同一实体的引用被划分到同一个簇中的可能性减小,从而导致算法产生的FN逐渐增多,Recall逐渐减小.综合Precision与Recall,F1-measure的变化也呈现波形.因此,在利用k-means算法进行分块时,簇个数的设定需要根据数据集的特点以及对算法运行时间的要求进行权衡.不同分块策略的性能比较如图1所示.
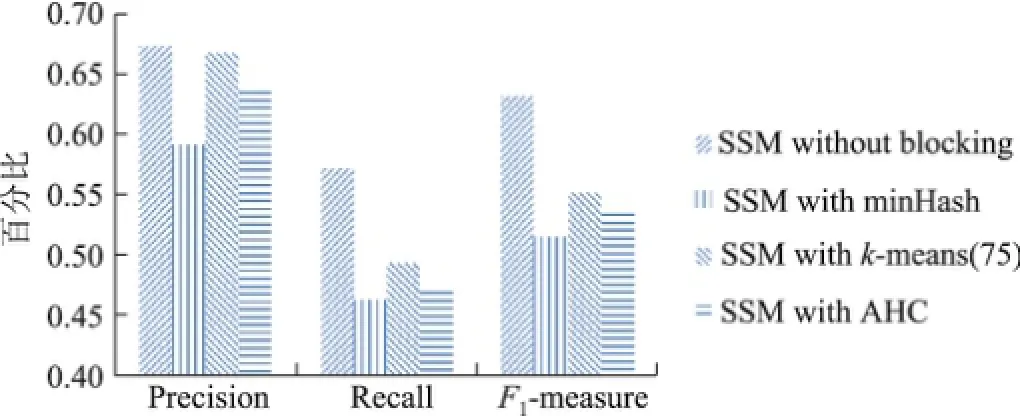
图1 不同SSM应用AHC后的评价指标比较Fig.1 Performance metrics of different SSM with AHC
从图1可以看出,在总体表现上,使用AHC算法进行分块的效果优于minHash算法,而与k-means算法相当.AHC算法相对于k-means算法的优势在于其通用性,一方面,AHC算法无需指定k值而且比k-means算法更稳定;但是另一方面,如果事先确定了k值,则使用k-means算法可能会得到更好的效果.
4 总结与展望
实体解析是数据预处理过程中的重要步骤,为了解决网络环境下非结构化商品数据的匹配问题,本研究提出了基于凝聚层次聚类框架的综合相似度算法,以识别不同网络平台的同一商品,本算法适用于非结构、多来源的商品匹配.同时,引入字符串处理、添加约束及分块策略的优化方法,目的是在现有方法的基础上提高大数据环境下商品匹配的执行效率.在大量真实数据集上的实验验证了本算法的有效性.
目前,虽然商品匹配算法较多,但仍缺少有效的评价方法,用于测试的大规模真实数据集的缺失也是目前亟待解决的问题.在接下来的工作中,应着重设计新的衡量方法或指标来减少人工检测带来的资源浪费,同时构造一个优质的大规模真实数据集,进一步提升算法与现实需求的契合度.
[1]ELMAGARMID A K,IPEIROTIS P G,VERYKIOS V S.Duplicate record detection:a survey[J]. IEEE Transactions on Knowledge and Data Engineering,2007,19(1):1-16.
[2]CHRISTEN P.Data matching:concepts and techniques for record linkage,entity resolution,and duplicate detection[M].Berlin:Springer Science and Business Media,2012.
[3]CHRISTEN P.Automatic record linkage using seeded nearest neighbour and support vector machine classification[C]//Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.2008:151-159.
[4]BHATTACHARYA I,GETOOR L.Collective entity resolution in relational data[J].ACM Transactions on Knowledge Discovery from Data(TKDD),2007,1(1):5.
[5]LI P,DONG X,MAURINO A,et al.Linking temporal records[J].Proceedings of the VLDB Endowment,2011,4(11):956-967.
[6]COHEN W W.Integration of heterogeneous databases without common domains using queries based on textual similarity[C]//ACM SIGMOD Record.1998:201-212.
[7]VANDIC D,VAN DAM J W,FRASINCAR F.Faceted product search powered by the Semantic Web[J].Decision Support Systems,2012,53(3):425-437.
[8]DUNN H L.Record linkage[J].American Journal of Public Health and the Nations Health,1946,36(12):1412-1416.
[9]NEWCOMBE H B,KENNEDY J M,AxFORD S J,et al.Automatic linkage of vital records computers can be used to extract“follow-up”statistics of families from files of routine records[J].Science,1959,130(3381):954-959.
[10]FELLEGI I P,SUNTER A B.A theory for record linkage[J].Journal of the American Statistical Association,1969,64(328):1183-1210.
[11]UKKONEN E.Approximate string-matching with q-grams and maximal matches[J].Theoretical Computer Science,1992,92(1):191-211.
[12]BRODER A Z,CHARIKAR M,FRIEZE A M,et al.Min-wise independent permutations[J].Journal of Computer and System Sciences,2000,60(3):630-659.
[13]MCCALLUM A,NIGAM K,UNGAR L H.Efficient clustering of high-dimensional data sets with application to reference matching[C]//Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.2000:169-178.
Product matching based on Internet and its implementation
GU Qi1,2,ZHU Can1,CAO Jian1
(1.School of Electronic Information and Electrical Engineering,Shanghai Jiao Tong University,Shanghai 200240,China;2.School of Computer Science and Technology,Nantong University,Nantong 226019,Jiangsu,China)
Entity resolution identifies entities from different data sources that refer to the same real-world entity.It is an important prerequisite for data cleaning,data integration and data mining,and is a key in ensuring data quality.With the rapid growth of E-commerce,diversity of products and flexible buying patterns of consumers,product identification and matching becomes a long-standing research topic in the big data era.While the traditional entity resolution approaches focus on structured data,the Internet data are neither standardized nor structured.In order to address this problem,this paper presents a synthesized similarity method to calculate similarity between different products.An agglomerate hierarchical clustering method is used to identify products from different sources.Also,the approach is optimized to improve efficiency of execution in three aspects:global cache,knowledge constraints,and blocking strategies.Finally,a series of experiments are performed on real data sets.The experimental results show that the proposed approach has a better performance compared with others.
entity resolution;big data;unstructured data;product matching
TP 391
A
1007-2861(2016)01-0058-11
10.3969/j.issn.1007-2861.2015.04.016
2015-11-30
国家自然科学基金资助项目(61272438,61472253,61300167);上海市科委资助项目(15411952502,14511107702)
曹健(1972—),男,教授,博士生导师,博士(后),研究方向为服务计算、网络计算、大数据分析.
E-mail:cao-jian@cs.sjtu.edu.cn
