情绪波动方程下微信息推介演变模型*
2016-09-14王东,孙彬
王 东, 孙 彬
(1. 新疆财经大学 计算机科学与工程学院, 乌鲁木齐 830012; 2. 新疆教育学院 计算机职业教育分院, 乌鲁木齐 830033)
情绪波动方程下微信息推介演变模型*
王东1,2, 孙彬1
(1. 新疆财经大学 计算机科学与工程学院, 乌鲁木齐 830012; 2. 新疆教育学院 计算机职业教育分院, 乌鲁木齐 830033)
为有效地捕捉微信息用户情绪,准确把握用户的兴趣倾向,使用最大信息熵估计法建立情绪波动方程,确定刺激力和内趋力参数方案.在衡量微信息情绪状态的前提下,描述出微信息用户情绪演变系统,建立及时激励推荐型的情绪导引模型,实现了情绪预测和情绪信息准确推荐的目的.结果证明,信息熵估计可以介入准确的情绪符号,提高微信息导引策略的适用性,达到稳定用户情绪、导引网络正能量的效能,对建立公信力和平抑小众情绪起到积极的作用.
信息熵; 情绪识别; 推荐; 导引模型; 激励法; 监测; 微信息; 正能量
微信息(微博、贴吧和微信等)的用户行为和文字记录具有强烈的情绪特征,反映了用户对社会现象的兴趣偏好和倾向特征.通过对微信息数据进行情绪导引,能改变人们被动接受网络负信息、管理部门主动引导低效的不利局面.从微信息用户的角度来分析,需要一种能贴近用户情绪、能有效导引用户访问兴趣和行为的方法.
1 研究背景
微信息情绪识别要求针对每个用户的具体个性特征进行情绪归类和倾向评价活动.微文本应用涉及社会生活的各个方面,其具备如下特点:从百姓日常生活到社会时事评论,所有信息内容都附带着用户个人的情绪色彩[1];用户所提交的交互信息和交互行为都是基于兴趣的[2];用户与兴趣之间往往是多对多的关系[3];微文用户的兴趣爱好符合艾宾浩斯遗忘曲线,随着时间的推移,用户兴趣逐渐衰落[4].微信息的情绪识别工作被多领域的工作者广泛关注,同时微信息的情绪识别工作也面临着许多技术难题,例如,大数据特征使得信息管理部门与用户都力不从心,无暇顾及舆情的情绪特征,很难把握正确的情趣导引举措[5-6];微博微信的对抗性批评降低了,激烈的舆情有所减少,舆情的隐性化使监测成为难题[7].
微文内容分析包括概率图模型提取[8]、情绪词节点映射[9]、语义特征向量最相似选取[10]、聚类特征主题识别[11]、改进LDA(latent dirichlet allocatlon)模型模糊识别兴趣主题[12-14]等方法,而在用户兴趣发现的诸多方法中,从识别效率和降维技术的方面来看,模糊识别具有独特的优势.
本文结合信息熵技术,建立情绪波动方程获得适用的微信息情绪特征,突破了情绪识别技术瓶颈,实现微信息用户的情绪推介服务.
2 情绪计算
情绪计算为试图创建一种能感知、识别和理解用户情绪的过程,实现情绪特征值的捕捉.情绪计算存在着两个层次的问题和挑战,即规范层与实现层.规范层为合成情绪推介服务提供良好的演化模型;实现层通过对用户情绪结构及交互规则的描述,为用户的情趣和级性特征测量提供语法分析上的支持.如果缺乏对情绪信息的有效控制分析,微信系统应用就无法在情绪约束条件下实现复杂服务的有效推广.
2.1情绪指标设计
关于用户情绪特征的测量指标,可先推荐一组主题倾向特征,并对每一主题倾向特征定义强度指标,使得每个情绪主题指标都相当于一种情绪空间的分量.把情绪描述预定为三类问题:
1) 主被动分类,即区分出情绪内容是主动性刺激还是被动性情绪对抗;
2) 维度分类(又称为主题倾向性分类),即判别信息内容的情绪方向,例如:快乐、悲伤和犹豫等;
3) 强度分类,即判定情绪的强弱程度,如无、微、中、强、极强等级别.
采集用户数据集,通过随机训练,根据评价结果估计主被动参数,再改变情绪特征的时序,重新估计主被动参数,如此循环直到获得适用的情绪期望指标及主被动参数.情绪指标及各种参数越是接近用户的期望特征,则用户的满足度越高.
2.2最大情绪熵计算
本文利用信息熵方法来直观地度量情绪,反映了用户兴趣演变过程.假设情绪空间(π)有多个情绪状态,并且某一时刻处于第t个时序状态,那么,情绪空间的演变概率就构成了一个情绪状态的动态随机过程.考虑到情绪的连续性,情绪恢复到平静的过程不是一个大的阶越过程,而应该是一个缓慢发展的过程[13].
采用最大信息熵来描述这一演变过程:假设某用户有m种情绪(维度分类),并且每种情绪强度划分为n个级别,那么就具有nm个情绪状态.将此情绪空间(π)中的某个情绪状态分布定义为Pij,即第i种情绪维度下第j种强度的状态分布,则情绪熵表示为

(1)
式中,C为与对数单位有关的调节常数.如果情绪空间中,每一个情绪状态的分布函数均出现相同的概率,则最大情绪熵值[15]为
H(P)max=-mClogPij=mClogn
(2)
H(P)max代表了情绪空间内情绪复杂程度的最大值,即H(P)max是情绪熵上界,越接近此数值,就越具有情绪平稳的特征.实际中,分布平均出现是不可能的,所以情绪熵上界是不能达到的.当复合情绪与各基本情绪概率相近时,则认为心情为平静状态.在情绪熵达到较大值时,即认为情绪处在较大稳定状态,但并不意味着Pij分布能达到均值.
2.3情绪波动方程
借鉴艾宾浩斯遗忘曲线,一个用户的兴趣如果没有持续的激励,兴趣强度的波动必然随着时间的延续不断地衰减.假定在大多数时间内,微信息用户处于平静心态,当看到一个微文消息时,便产生了情绪波动.随着微信息人机交互的不断持续进行,用户的情绪一直处于变化状态中,依照情绪反应规律,情绪将逐渐积累和叠加.用户情绪状态的概率分布随着时间发生连续变化,表示为P(t).外界刺激对P(t)直接发生作用,用A表示刺激力参数,相应情绪强度的变化量为AP(t),即A与兴趣强度变化率有一定的正比例关系;用B表示惰性的内驱力参数,表现出用户本能的情绪对抗力,由于情绪强度随时间的延续,最终会趋于极低的强度水平(平静状态),借鉴遗忘曲线原理设计对抗项为BP2(t).综合以上分析得到情绪波动方程为

(3)
当B≥0,A≥0,且有初值条件P0限制时,该方程解为
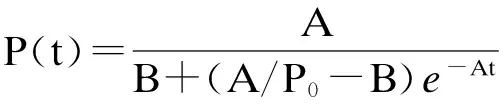
(4)
当t→∞时,P(t)→A/B,情绪最终将衰落,趋于稳定.B值越大,则A/B的值越小,则可认定情绪惰性大,不易情绪激动;反之,B值很小时,A/B值就大,可认定为情绪易激动,容易发生激烈活动.假定有m种基本主题类型,则至少可确定m个情绪波动方程(k=1,2,…,m),即
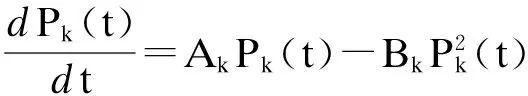
(5)
2.4刺激力参数
通常可以设计8种刺激,且每种刺激有5种情绪强度.由此设计评价规则,评价的指标集可划分如下:
1) 8种刺激主题:{快乐、崇拜、好奇、嫉妒、厌恶、惧怕、悲伤、愤怒};
2) 5种情绪强度等级:{无、微、中、强、极强},对应数值:{1,2,3,4,5}.
选定一种交互型微信息系统,并随机抽取一批交互数据,按照上述8种刺激和5种情绪强度进行归类训练.例如:对于“快乐”这一情绪指标,10%的微文样本等级是“无”,40%的微文样本是“微”,20%的微文样本是“中”,20%的微文样本是“强”,10%的微文样本是“极强”,于是确定A1(快乐)的值为
E(A1)=0.1×1+0.4×2+0.2×3+
0.2×4+0.1×5=2.8
(6)
按照同样的方法可得获得其他基因维度的期望值E(A2),E(A3),…,E(Am).
2.5内驱力参数
内驱力参数B本质上是用来表征人的情绪惰性,也是一个多维的向量调控因素,与当事群体连续遭受的刺激力有关.内驱力参数的取定需要通过大量有外界刺激的数据集训练来估定.一般情况下,外界刺激A在哪一个分量上数值大,内驱力B在该分量上的值也会相应要大一些,B表现出惯性衰落的特征.A与B的对应分量不是正比的关系,B分量夹杂着自然性衰落的惰性对抗性.
内驱力参数B的隶属函数可根据多种形态曲线来确定,本文采用情绪衰落函数来得到内驱力参数B的适用值.以特征曲线标记各个情绪刺激信号,反复训练情绪数据集便可得到与衰落性近似吻合度更好的衰落函数.
2.6情绪演化模型
情绪推介服务要求能自动推断和捕获用户的情绪需求变化,推荐出一个满足当前需求的情绪特征项,并参与到用户交互活动中去.掌握用户偏好,分类进行情绪激励是在线互动和个性推荐系统中的一种重要目标.在社会网络的信息传播过程中,通过对用户微信短信和行为日志的分析,可以预测用户偏好对不同主题的情绪强度和变化率,这对自媒体网络舆情传播的控制管理有重要的导引作用.
假设:借鉴生物体细胞核中染色体的组成原理,将情绪演变结构表示为基因序列,即一个长度为L的染色体:π={ξ1,ξ2,…,ξL},第i个基因(ξi)上存在一系列等位强度基因,表示为ξi={ai1,ai2,…,aiki},那么所有情绪状态(等位强度基因)的组合就构成了情绪空间的整体结构,即

(7)
对于现实存在的任意情绪(染色体)实例S必然为π的一个真子集,即S∈π,当S演变到t阶段时,标识为S(t).关于情绪实例S(t)对环境F(t)的适应性描述,采用正实数序列来表示,假设刺激力参数A和内驱力参数B相等,设t时段环境F(t)所提供的信息为I(t),那么在适当调节因子τt的作用下,S(t)演化成新的情绪实例S(t+1)描述为
F(t)∶S(t)I(t)→S(t+1)
(8)
情绪演化过程中,不可能隔断历史性的惯性衰落作用.F(t)与其历史过程有着直接的遗传关系,所以在新的情绪实例S(t+1)生成时,不仅要考虑即时发生的环境信息I(t),还必须考虑到环境的历史惯性MF(t).历史环境提供的动态信息列表为MF(t)={I(1),I(2),…,I(t)},可以看作是在环境F(t)下,情绪实例S(t)发生情绪变化时必须遭受的惯性衰落性内驱阻力.
综合考虑环境F(t)、情绪实例S(t)、动态信息I(t)、历史信息列表MF(t)和智能调整适应性激励参数A等因素,流程可以看作是情绪实例S(t)在现实环境F(t)下的理性选择或推介过程,反映了t阶段情绪变量的可调控性能.随着情绪实例S(t)的情绪结构和环境F(t)的演化,情绪状态分布μt的内容随着t进行适应性调整,所以情绪激励的逻辑τt描述为
τt∶μt-1[S(t-1)I(t)]→μt
(9)
式中,μt、μt-1为情绪整体空间π中的一个情绪基因的分布状态(μt、μt-1都为正数).将μt对应于情绪概率分布P(t),可形成式(3)波动方程.
在整个情绪适应过程中,情绪波动过程与历史惯性序列MF(t)紧密相关.在候选情绪调节指令集中挑选优良方案,投入到微信息圈,增加刺激力,那么整个情绪过程的适应性可以表示为
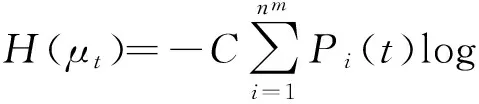
(10)
考虑到情绪适应随机的性质,t时刻波动过程的情绪适应度表示为

(11)
环境变化历程表示为
J(S)=Max(H(μt))≥mClogn-ε
(12)
式中,ε为阈值.
将上述描述加以汇总,可以得到情绪演化过程的数学模型为
(13)
上述情绪演化模型中,对环境刺激力与历史惯性(内驱力)发生作用进行了规范描述.在缺乏假设问题先验信息的情况下,系统在不同阶段所处的环境F(t)只是一种理论性的假设,其与情绪实例S(t)和适应计划τt相关.
情绪推荐方案不仅与问题的即时动态情绪信息有关,也和整体环境的历史惯性有关,环境刺激力与惯性内驱力的设计与选择策略是实施该情绪波动与演化激励模型的关键.
2.7情绪调整过程
计算过程中,首先通过先验文本训练确定用户特征值(测算时段次数、刺激力参数、内驱力参数和阈值等),然后设计情绪调整的对话策略.情绪参数的训练算法如下:
1) 确定微信息圈及若干用户对象,并定义情绪主题和情绪强度等级,将其情绪文字词归类采集,形成训练数据集X0.
2) 变量初始化.根据第t0时段的数据集确定适应性参数值,包括刺激力参数、内驱力参数和阈值等.
3) 时段循环测试.将新发生的动态信息I(t)以主题倾向(同类归并)的形式加入到训练数据集Xt;基于当前用户的信息变动,调整情绪刺激力参数;基于用户的历史信息列表,调整阈值和内驱力;由情绪熵极值条件获取可行参数,如果达到最后时段则结束循环.
4) 遍历各个时段,挑选具有最大熵的时段ti,对应的舆情数据集为Xi.
5) 从Xi数据集中挑选活跃情绪元素,然后按照舆情正能量调节需要组成情绪调整候选指令项.
6) 计算Γ(t)和J(X),若情绪调整计划参数未达到预定的期望值,转步骤3);否则转步骤7).
7) 总结该用户情绪特征,生成最优情趣推荐列表,并翻转为对应的情绪文字,虚拟执行相关微信息行为.
3 实验结果与分析
本实例根据用户兴趣样本,筛选和过滤相关信息项,把相同或相近兴趣特征用户所浏览的感兴趣信息进行同类归并,然后合成进化推荐数据列表,引导用户活动.用户浏览活动的不确定性被降低,正能量导引目的性被加强.总结用户情绪推介序列的关键环节如下:
1) 收集用户己浏览的信息,根据其情绪偏好类型生成用户习惯情绪特征;
2) 核对同类微信息数据集;
3) 找出具有关联关系的情绪调节候选项,构造当前的情绪推荐列表;
4) 捕获当前用户的习惯性情绪特征,修正情绪适应度.
针对最流行的几种微信息交互服务系统,在用户情绪许可采集的条件下,将用户访问过的情趣主题、关注行为、访问次数和情绪词类等动作捕捉,对应到预定的用户兴趣指标,并直接换算为情绪强度,合成用户兴趣趋向概率分布.锁定一组经常上网的用户进行情绪样本采集,采集到12 300多条情绪微文本,去除情绪信息无效的部分,有效微文本数据9 803条,情绪特征分布结果如表1所示.经过波动方程迭代计算,与该类用户最合拍的情绪推荐特征是:(快乐、崇拜、惊奇、惧怕、悲伤、厌恶、兴趣、愤怒)=(0.21,0.22,0.45,0.20,0.35,0.23,0.23,0.13).
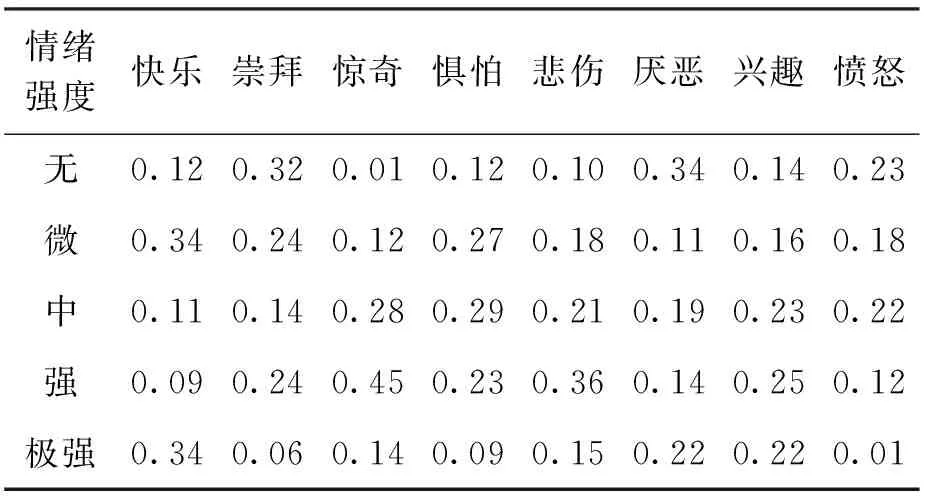
表1 情绪特征分布Tab.1 Distribution of emotional characteristics
在实验中,将情绪候选子集的规模从10逐步调整到60.情绪推介活动显示:客户情绪熵与种类子集规模的关系密切,如图1所示.可观察到通过250次时段的情绪演变,随着子集规模的增加,情绪推介活动使得情绪熵先是逐渐增加,然后又逐渐衰落.腾讯微信用户的熵值最低,微博用户的熵值居中,百度贴吧的熵值较高,显然,微信系统在网络上的情绪波动性最强列,同时情绪调整子集数要达到20~25个才能完成情绪推介的需要.

图1 情绪熵与子集规模的关系Fig.1 Relationship between emotional entropy and subset size
将情绪候选子集个数定位在22个,情绪信息I(t)不断叠加,时段序列t由1时段逐步演变到500时段,采集实验数据结果如图2所示.由图2同样可以看出,微信在网络上的情绪波动性最大.
根据用户情绪波动特点,对预测微信息用户的情绪喜好进行定性辅导,将有助于微信息网络的深层次应用,对舆论导控具有较大的潜在价值.
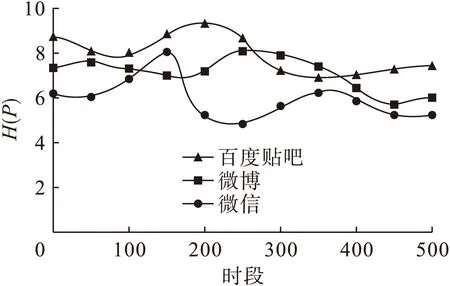
图2 情绪熵与情绪调整序列关系Fig.2 Relationship between emotional entropy and emotional adjustment sequence
4 结 论
情绪波动方程下的微信息推介演变模型能面对微信息交互系统,获得用户交互情绪特征,保持信息圈兴趣的适应度,可提高面向客户的主动性,用户不再僵化于被动性浏览.情绪识别与及时推介是一个复杂的信息波动检测过程,通过信息熵及适应度最优的迭代挑选进程能够获得一个真实的、合适的情绪文字态度,以更好的角色融入到目标信息圈中,能亦步亦趋地传递正能量情绪信息,可使信息管理者越来越接近客户情绪需求,最终自动进行适用的情绪微信息推介工作.
[1]张剑峰,夏云庆,姚建民.微博文本处理研究综述 [J].中文信息学报,2012,26(4):21-27.
(ZHANG Jian-feng,XIA Yun-qing,YAO Jian-min.A review towards microtext processing [J].Journal of Chinese Information Processing,2012,26(4):21-27.)
[2]索勃,李战怀,陈群,等.基于信息流动分析的动态社区发现方法 [J].软件学报,2014,25(3):547-559.
(SUO Bo,LI Zhan-huai,CHEN Qun,et al.Dynamic community detection based on information flow analysis [J].Journal of Software,2014,25(3):547-559.)
[3]张辉,刘奕群,马少平.文本情绪分类中生成式情绪模型的发展 [J].计算机应用研究,2014,31(12):3521-3526.
(ZHANG Hui,LIU Yi-qun,MA Shao-ping.Development of generative model in text sentiment classification [J].Application Research of Computers,2014,31(12):3521-3526.)
[4]蒋逸,张伟,赵海燕.互联网环境中基于环境激发效应的协同式概念建模 [J].计算机科学,2015,42(11):228-233.
(JIANG Yi,ZHANG Wei,ZHAO Hai-yan.Stigmergy-based collaborative conceptual modeling in web environment [J].Computer Science,2015,42(11):228-233.)
[5]王东.大数据技术在精准化营销中的应用 [J].中国流通经济,2014(7):90-93.
(WANG Dong.The application of big data technology to precision marketing [J].China Business and Market,2014(7):90-93.)
[6]吴纯青,任沛阁,王小峰.基于语义的网络大数据组织与搜索 [J].计算机学报,2015,38(1):1-17.
(WU Chun-qing,REN Pei-ge,WANG Xiao-feng.Survey on semantic-based organization and search technologies for network bid data [J].Chinese Journal of Computers,2015,38(1):1-17.)
[7]张玉亮.突发事件网络舆情信息流风险模糊综合评价研究 [J].情报科学,2015,33(11):100-106.
(ZHANG Yu-liang.Research on fuzzy comprehensive evaluation model construction of information flow on network public opinion of sudden events [J].Information Science,2015,33(11):100-106.)
[8]张宏毅,王立威,陈瑜希.概率图模型研究进展综述 [J].软件学报,2013,24(11):2476-2497.
(ZHANG Hong-yi,WANG Li-wei,CHEN Yu-xi.Research progress of probabilistic graphical models [J].Journal of Software,2013,24(11):2476-2497.)
[9]刘德喜,万常选.社会化短文本自动摘要研究综述 [J].小型微型计算机系统,2013,34(12):2764-2771.
(LIU De-xi,WAN Chang-xuan.Survey on automatic summarization of socialized short text [J].Journal of Chinese Computer Systems,2013,34(12):2764-2771.)
[10]苏雪阳,左万利,王俊华.基于本体与模式的网络用户兴趣挖掘 [J].电子学报,2014,42(8):1556-1563.
(SU Xue-yang,ZUO Wan-li,WANG Jun-hua.Web user interest mining based on ontology and patterns [J].Acta Electronica Sinica,2014,42(8):1556-1563.)
[11]徐恪,张赛,陈昊,等.在线社会网络的测量与分析 [J].计算机学报,2014,37(1):165-183.
(XU Ke,ZHANG Sai,CHEN Hao,et al.Measurement and analysis of online social networks [J].Chinese Journal of Computers,2014,37(1):165-183.)
[12]李小林,张力娜.基于直觉模糊理论的混合多属性Web服务选择 [J].沈阳工业大学学报,2014,36(6):676-680.
(LI Xiao-lin,ZHANG Li-na.Hybrid multi-attribute Web service selection based on intuitionistic fuzzy theo-ry [J].Journal of Shenyang University of Technology,2014,36(6):676-680.)
[13]徐军,钟元生,郑也夫.一种多维集成直觉模糊信息的信任评价方法 [J].计算机工程与科学,2015,37(9):1768-1775.
(XU Jun,ZHONG Yuan-sheng,ZHENG Ye-fu.A trust evaluation approach of multi-dimensional integrated intuitionistic fuzzy information [J].Computer Engineering & Science,2015,37(9):1768-1775.)
[14]张福勇,赵铁柱.采用路径IRP的Windows恶意进程检测方法 [J].沈阳工业大学学报,2015,37(4):434-439.
(ZHANG Fu-yong,ZHAO Tie-zhu.Windows malicious process detection method with path IRP [J].Journal of Shenyang University of Technology,2015,37(4):434-439.)
[15]陈小辉,张功萱.基于信息熵的符号属性精确赋权聚类方法 [J].重庆邮电大学学报(自然科学版),2014,26(6):850-855.
(CHEN Xiao-hui,ZHANG Gong-xuan.Symbol pro-perty accurate weight clustering method based on information entropy [J].Journal of Chongqing University of Posts and Telecommunications(Natural Science Edition),2014,26(6):850-855.)
(责任编辑:景勇英文审校:尹淑英)
Model for promotion and evolution of micro-message based on emotional fluctuation equation
WANG Dong1, 2, SUN Bin1
(1. College of Computer Science and Engineering, Xinjiang University of Finance and Economics, Urumchi 830012, China; 2. Computer Vocational Education Branch, Xinjiang Education Institute, Urumchi 830033, China)
In order to effectively capture the emotion of micro-message user and accurately grasp the interest tendency of user, the emotional fluctuation equation was established with the maximum information entropy estimation method, and the parameter scheme for both stimulation and internal forces was determined. Under the premise of measuring the emotional states of micro-message, the emotional evolution system of micro-message user was described, the emotional guidance model for timely incentive recommendation type was established, and both emotional prediction and accurate emotional information recommendation were achieved. The results show that the information entropy estimation can get involved in the accurate emotional symbols, and the applicability of micro-message guidance strategy can be improved. Therefore, the efficiencies in stabilizing the user emotion and guiding the network positive energy can be achieved. The information entropy estimation can play a positive role in establishing the popular credibility and stabilizing the clique emotion.
information entropy; emotion recognition; recommendation; guidance model; incentive method; monitoring; micro-message; positive energy
2015-12-25.
国家自然科学基金资助项目(61562080; 61363082); 教育部人文社会科学研究规划基金项目(14YJA860017).
王东(1966-),男,新疆乌鲁木齐人,副教授,主要从事计算机信息安全等方面的研究.
10.7688/j.issn.1000-1646.2016.04.13
TP 292.1
A
1000-1646(2016)04-0434-06
*本文已于2016-05-12 13∶56在中国知网优先数字出版. 网络出版地址: http:∥www.cnki.net/kcms/detail/21.1189.T.20160512.1356.004.html
