具有不确定数据的XML数据编码设计*
2016-09-14姜岩,李欣,金鑫
姜 岩, 李 欣, 金 鑫
(1. 沈阳工业大学 a. 软件学院, b. 信息科学与工程学院, 沈阳 110870; 2. 沈阳合兴检测设备有限公司 技术部, 沈阳 110180)
具有不确定数据的XML数据编码设计*
姜岩1a, 李欣1b, 金鑫2
(1. 沈阳工业大学 a. 软件学院, b. 信息科学与工程学院, 沈阳 110870; 2. 沈阳合兴检测设备有限公司 技术部, 沈阳 110180)
为了解决模糊数据对XML文档中各元素造成的内容和结构上的改变,使得XML数据模型中的不确定信息能够被有效地管理,提出了一种基于前缀编码的四元组编码方案.在语法分析器XML Schema中,根据模糊数据的特征,利用增加的元素对XML文档中的模糊元素进行约束,进而为每一个元素建立一个四元组,其参数由文档号、遍历序号、元素模糊性及组内标志符构成.通过大量的实验对比分析,验证了该编码方案的有效性,其更适用于具有较低XML树高度的XML文档.
模糊数据; 不确定信息; 四元组编码; 语法分析器; 增加的元素; 模糊性; XML树高度
随着人们对Web要求的不断提高,XML(eXtensible Markup Language)数据库引入了模糊数据这一概念[1-3],用户可以通过数据的编码判断XML文档中各节点的结构关系[4].然而,目前的编码方案多数针对于精确数据[5-9],即使是预留空间的编码方案也不能体现出模糊数据的模糊性,往往只能满足对模糊数据多种情况的存储,此外,需要完成模糊数据在XML的两种语法分析器XML DTD(Document Type Definition)和XML Schema中的定义,才能完成模糊XML文档中的数据规范.
近年来,很多XML研究工作致力于模糊数据在其语法分析器XML DTD中的定义[10-11],前人提出了在XML DTD中增加两个元素用来规范XML文档中模糊数据的方法,然而,只完成模糊数据在XML DTD中的定义并不能够完全解决XML中模糊数据的问题,XML DTD有很多缺点,最重要的就是不能支持对数据类型的定义.例如,有些城市的电话区号是三位,而有些城市的是四位,XML DTD是不能完成此功能的.此外,XML DTD不支持命名空间,每一个XML文档只能有一个DTD,XML DTD以其自身语法规定了相应XML文档的语言信息,不支持继承,因此,必须完成对模糊数据在XML Schema中的定义,XML Schema本身就是格式良好的XML文档,在管理上也更有优势.
在完成了模糊数据在语言分析器中的规范后,必须要了解数据的编码方式,XML文档中任意两个节点之间的结构关系都是通过编码来确定的.目前的相关编码工作主要针对于精确数据的预留空间编码方案,大致分为基于路径及基于区间两种,无论哪种编码方案都不能较好地完成XML文档中模糊数据的编码.针对编码方案的不足,本文在模糊集理论的基础上,提出了一种能够直接对模糊数据进行编码的方案,它能够对XML文档中的模糊节点进行更全面的表示,不仅能判断各节点的结构关系,还可以知道各元素的模糊性、层次等信息.该方法对层次较低文档具有更高效率,对用户更透明,更符合用户要求,提高了用户和系统之间的交互能力.
1 XML Schema中的模糊数据
1.1模糊数据
在XML文档中,模糊数据有两种存在形式,一种模糊是元组的模糊,例如一名叫李莎莎的学生信息元组是否属于三年二班这个班级;另一种模糊是属性的模糊,进一步分析属性的模糊又可以分为模糊吸取和模糊合取.模糊吸取正如一个人的年龄属性,取值为一个集合,可以取{20,21,25,29,30}中的某一个值;模糊合取正如邮箱地址属性取值,一个人可以有多个邮箱.元组模糊表示为具体的元组属于相应类实例的隶属度;属性模糊表示属性取值的不确定性,模糊吸取代表其模糊值仅能取可能值中的一个,模糊合取代表可以取多个可能值[12].
1.2XML Schema中模糊数据的定义
XML Schema是一种格式良好的XML文档,可以使用XML编辑器来编辑,功能是对XML文档进行语言规范,决定XML文档中可以添加哪些元素、属性、相同元素的数量及出现顺序等信息.为适应模糊信息的引入,XML Schema必须做出修改以完成XML文档中节点结构关系的判定.
XML Schema对模糊数据的处理方法是:对于每一个具有元组模糊的元素在其XML Schema定义中添加一个chance元素,其数据类型为浮点类型,取值范围为[0,1],用来表示元组属于相应类实例的隶属度,具体语法如下:
type=”xs:float”/> 对于每一个具有属性模糊的元素在其XML Schema定义中增加Forms元素与Fuzzytype元素,Forms元素用来引导属性的多种可能取值,Fuzzytype标志着属性模糊是模糊吸取还是模糊合取,数据类型为布尔型,具体语法如下: type=”xs:boolean”/> 每一个Forms元素包含多个Table元素,具体语法如下: Table元素是一个二元组,由属性P和Value构成,表示相应的多种可能值以及每种可能值的隶属度,其语法构成如下:
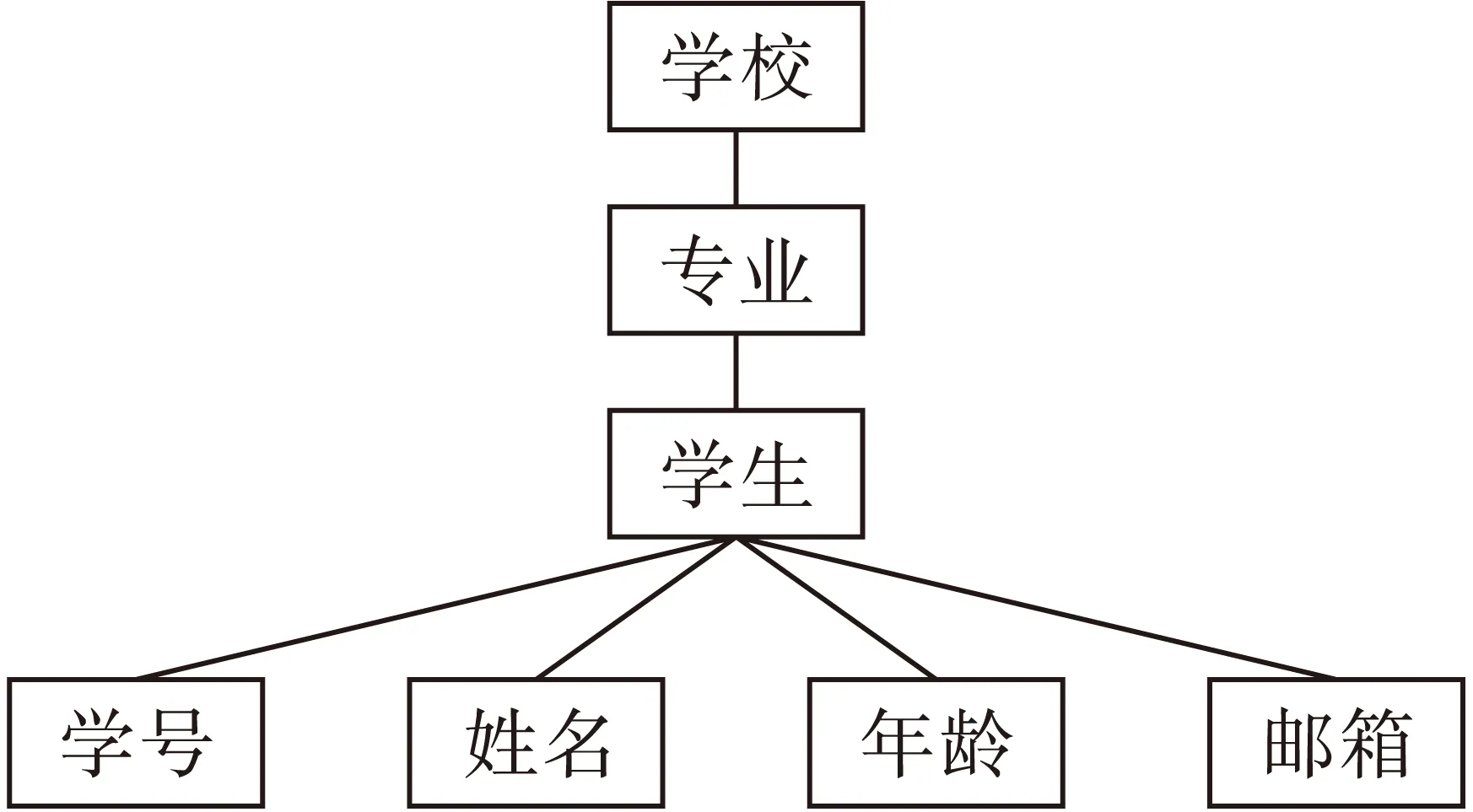
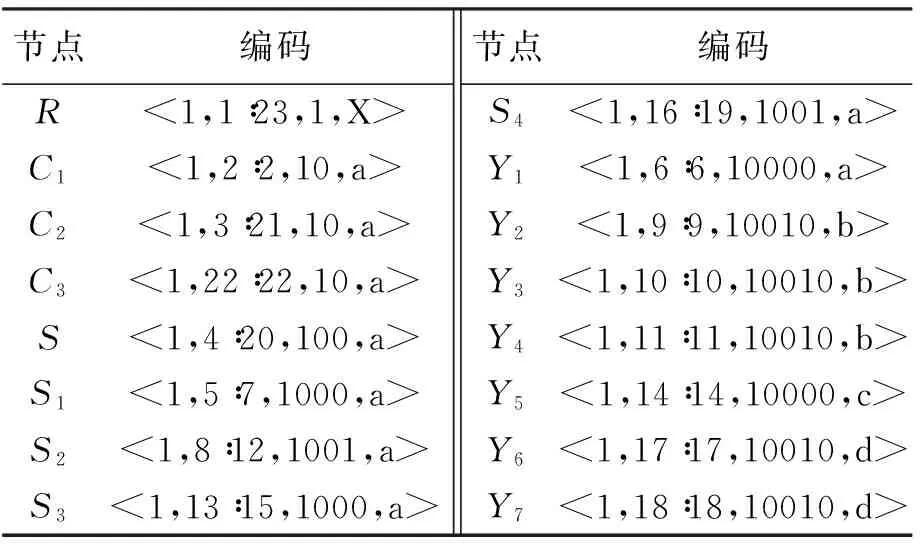
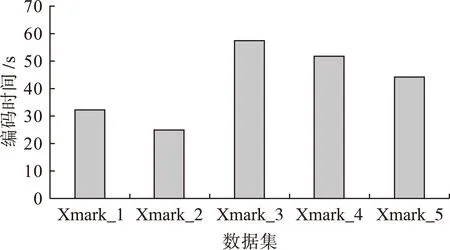
type=”xs:string”/> 为适应模糊数据的引入,本文提出了一种直接支持模糊数据的编码方案. 2.1编码规则 定义1在对含有模糊元素的XML文档进行编码时,可以为每一个元素建立一个四元组,即 1) “Docld”是文档的标志符; 2) “LeftPos”与“RightPos”是对XML文档进行先序遍历时的开始序号和结束序号; 3) “FuzzyNumber”是文档的模糊号,其位数由其所在层次决定,根元素有一位,末位表示当前元素的模糊性,0表示当前元素为精确值,1表示当前元素为模糊值,其它位取值继承其双亲节点; 4) X是组内标志,相同的兄弟节点放在同一组. 2.2判断节点的结构关系 定义函数h为h→int,返回参数“FuzzyNumber”中0和1的数量总和,即获取当前元素所在层次. 定义函数f为f→int,返回参数“FuzzyNumber”中的末位数,即获取当前元素的模糊性. 定义2祖先/后裔关系(ancestor-child).假设节点u,v∈N,N为节点集合,C(u)和C(v)为其编码,且满足条件: 1)C(u).Docld=C(v).Docld; 2)C(u).LeftPos 3)C(u).RightPos>C(v).RightPos; 4) ∀k∈(u+1,v-1),∃C(u+1).f∧C(k).f∧C(v-1).f=0. 则称u是v的祖先节点. 定义3双亲/孩子关系(parent-child).假设节点u,v∈N,N为节点集合,C(u)和C(v)为其编码,且满足条件: 自由贸易区是目前世界上政策最为宽松的特殊经济区,自由贸易港是基于自贸区的改革开放升级版,将成为我国对外开放的新高地。汪洋副总理在人民日报署名文章指出,我国即将出炉的自由贸易港将瞄准全球最高开放水平、货物资金人员进出自由、绝大多数商品免征关税等标准而建,致力于打造开放层次更高、营商环境更优、辐射作用更强的开放新高地[1]。 1)C(u).Docld=C(v).Docld; 2)C(u).LeftPos 3)C(u).RightPos>C(v).RightPos; 4)C(u).h-C(v).h=1. 则当节点u、v都是精确节点时,u是v的精确双亲节点,否则u是v的模糊双亲节点. 定义4兄弟关系(brother).假设节点u,v∈N,N为节点集合,C(u)和C(v)为其编码,且满足条件: 1)C(u).Docld=C(v).Docld; 2)C(u).h=C(v).h; 3)C(u).X=C(v).X. 则称u是v的兄弟节点. 2.3性质 2) 对于∀u∈N,如果存在C(u).h=A,那么节点u位于第A层,根节点位于第1层; 3) 对于∀u∈N,如果其编码C(u).FuzzyNumber中有n位1,那么从根节点到该节点的分支上有n位模糊元素; 4) 对于∀u∈N,如果其编码C(u).FuzzyNumber末位为1,那么当前元素为模糊数据,否则为精确数据. 2.4编码实例 图1是一棵存储学院信息的XML文档树,图2是针对图1 XML文档树的具体实例进行编码的方案.表1列出了XML文档树中各节点的具体编码. 图1 学院信息的结构文档树 图2 编码方案 表1 XML文档树节点编码 学院有计算机系、法律系及机械系,和学院之间存在元组模糊.每个系有多名学生,具体每名学生有学号、姓名、年龄以及邮箱地址属性.其中年龄属性为模糊吸取数据,取值{20,25,30},可以是集合中的任意一个,分别对应的隶属度为0.2,0.4,0.7.也就是说模糊数据“年龄”一词可以用模糊集的语言来表示,邮箱地址属性为模糊合取数据. 图2中,根节点R与C1节点和C3节点存在元组模糊,R与C1双亲节点的隶属度是0.6,表示法律系属于该学院的隶属度为0.6,同理,机械系属于该学院的隶属度为0.2.由于R是一个模糊节点,R与C2之间是精确双亲关系,所以R与C2之间的隶属度为1.缺省值默认为1,表示的是计算机系精确属于该学院.此外,C2是S2的祖先节点,C2是S的精确双亲节点,S是S2的模糊双亲节点,S2是S3的兄弟节点. 为了检验本文所提出的针对模糊数据编码方案的适用性,设计了相应的实验.实验电脑CPU为2.53 GHz Intel双核处理器,内存为4 GB,操作系统为Windows 7,实验环境采用Visual C++6.0,选用的测试数据集由XML自动生成工具Xmark生成,文档树的节点数和深度的信息如表2所示,图3为5个数据集平均编码位长对比图,图4为5个数据集编码时间对比图. 表2 XML测试数据集 图4 数据集编码时间对比 由图3与图4可以看出,并不是节点总数越多的数据集编码位长越多,时间越长,说明模糊数据的编码效率与深度有关.图5绘制出了XML文档层次与平均编码时间曲线图. 图5 层次分布与平均时间曲线 本文对引入了模糊数据的XML文档进行了编码设计,提出了将模糊性体现在编码中的方法.对XML文档进行先序遍历,并记录访问时的开始和结束序号,这是判断节点之间结构关系的关键.本文编码方案不仅可以得出元素所在层次及当前元素模糊性,还可以知道根节点到当前节点所在分支的模糊元素个数及位置等信息.同时,在实验空间有限的情况下,对多组数据进行了实验,验证了该种方案的可行性,并且得出了编码的效率与文档层次有关的结论. [1]朱兴统,许波.一种面向XML文档的模糊关联规则算法 [J].科学技术与工程,2011,11(26):5467-5470. (ZHU Xing-tong,XU Bo.A fuzzy association rules algorithm for XML document [J].Science Technology and Engineering,2011,11(26):5467-5470.) [2]Chris T,Khamisy W,Toan V.University fuzzy system representation with XML [J].Computer Standards & Interfaces,2004,28(5):218-230. [3]Elisabetta B,Ignazio G,Cristina G,et al.An integra-ted fuzzy logic and web-based framework for active protocol support [J].International Journal of Medical Informatics,2007,77(8):256-271. [4]姜岩,潘平,袁琳,等.面向方面的XML结构连接算法的改进 [J].沈阳工业大学学报,2010,32(4):427-431. (JIANG Yan,PAN Ping,YUAN Lin,et al.Improvement of aspect-oriented XML structural join algorithm [J].Journal of Shenyang University of Technology,2010,32(4):427-431.) [5]文华南,刘先锋,李文峰,等.高效查询的XML编码方案 [J].计算机应用,2010,30(3):831-834. (WEN Hua-nan,LIU Xian-feng,LI Wen-feng,et al.XML coding scheme for efficient query processing [J].Journal of Computer Applications,2010,30(3):831-834.) [6]姚保峰,马程,谢娜,等.基于分数的动态前缀XML编码方案 [J].商丘师范学院学报,2014,30(3):71-74. (YAO Bao-feng,MA Cheng,XIE Na,et al.Dynamic prefix XML encoding scheme based on fraction [J].Journal of Shangqiu Normal University,2014,30(3):71-74.) [7]冯少荣,陈天烁.基于向量的动态XML编码方法研究 [J].计算机工程,2012,38(13):64-66. (FENG Shao-rong,CHEN Tian-shuo.Research of dynamic XML coding method based on vector [J].Computer Engineering,2012,38(13):64-66.) [8]刘先锋,周舟,刘萍,等.一种分数前缀XML编码方案 [J].计算机工程,2012,38(12):29-31. (LIU Xian-feng,ZHOU Zhou,LIU Ping,et al.Fraction and prefix XML encoding scheme [J].Computer Engineering,2012,38(12):29-31.) [9]郭丽红,王箭,杜贺.一种基于同心圆切割的XML编码方案 [J].计算机工程,2013,39(6):52-54. (GUO Li-hong,WANG Jian,DU He.An XML encoding scheme based on concentric circular cutting [J].Computer Engineering,2013,39(6):52-54.) [10]严丽,刘健.一种模糊XML模型的概念设计方法 [J].计算机科学,2011,38(12):157. (YAN Li,LIU Jian.Conceptual design methodology for fuzzy XML model [J].Computer Science,2011,38(12):157.) [11]孟祥福,张霄雁,马宗民,等.一种基于领域知识的XML数据模糊查询 [J].智能系统学报,2012,7(6):527-528. (MENG Xiang-fu,ZHANG Xiao-yan,MA Zong-min,et al.An XML fuzzy query answering approach based on domain knowledge [J].CAAI Transactions on Intelligent Systems,2012,7(6):527-528.) [12]严丽,马宗民,刘健,等.基于关系数据库映射的模糊数据XML数据建模 [J].计算机学报,2011,34(2):292-300. (YAN Li,MA Zong-min,LIU Jian,et al.XML modeling of fuzzy data with relational databases [J].Chinese Journal of Computers,2011,34(2):292-300.) (责任编辑:景勇英文审校:尹淑英) Design for XML data encoding with uncertain data JIANG Yan1a, LI Xin1b, JIN Xin2 (1a. School of Software, 1b. School of Information Science and Engineering, Shenyang University of Technology, Shenyang 110870, China; 2. Technology Department, Shenyang Hexing Testing Equipment Co. Ltd., Shenyang 110180, China) In order to solve the change in both content and structure of each element in the XML document caused by fuzzy data and make the uncertain information be effectively managed in the XML data model, a quadruple encoding scheme based on the prefix encoding was proposed. In the syntactic analyzer XML Schema, the fuzzy elements were restrained with some added elements according to the characteristics of fuzzy data, and then each element could be created with a quadruple, where the parameters were consisted of document number, traversal number, element fuzziness and mark in group. Though the contrast and analysis for a great amount of experiments, the effectiveness of this encoding scheme is proved. The results show that the proposed coding scheme is more suitable for XML document with lower height of XML tree. fuzzy data; uncertain information; quadruple encoding; syntactic analyzer; added element; fuzziness; height of XML tree 2015-07-06. 辽宁省科技厅自然科学基金资助项目(2013020032). 姜岩(1977-),男,辽宁沈阳人,副教授,博士,主要从事XML数据管理、智能控制等方面的研究. 10.7688/j.issn.1000-1646.2016.01.12 TP 311 A 1000-1646(2016)01-0069-05 *本文已于2015-12-07 16∶16在中国知网优先数字出版. 网络出版地址: http:∥www.cnki.net/kcms/detail/21.1189.T.20151207.1616.012.html2 支持模糊数据的XML编码方案

3 模糊数据编码方案的性能分析


4 结 论
