基于ABC优化MVDR的语音情感识别研究
2016-09-13孙志锋
孙志锋
(陕西师范大学 计算机科学学院,陕西 西安 710062)
基于ABC优化MVDR的语音情感识别研究
孙志锋
(陕西师范大学 计算机科学学院,陕西 西安710062)
语音情感特征的提取和选择是语音情感识别的关键问题,针对线性预测(LP)模型在语音情感谱包络方面存在的不足。本论文提出了最小方差无失真响应(MVDR)谱方法来进行语音情感特征的提取;并通过人工蜂群(ABC)算法找到最优语音情感特征子集,消除特征冗余信息;利用径向基函数(RBF)神经网络对CASIA汉语情感语料库中的4种情感语音即生气、平静、高兴、害怕进行实验识别。实验结果表明,该方法比线性预测法有更高的识别率和更好的鲁棒性。
最小方差无失真响应;人工蜂群算法;语言情感识别;线性预测
人类说话除了表达基本的文字信息以外,还表达了说话人的情感和情绪等信息。所以,我们可以依据语音来识别人类的情感。语音情感识别主要包括情感特征参数的提取、选择和识别,其中情感特征的好坏直接影响着情感识别的识别率,所以好的情感特征提取与选择算法能够实时地、高效地反映情感状态特征。
在特征参数提取技术方面,最常用的是用于计算全极点参数的线性预测(LP)谱,该谱能较好地表征频谱的峰值信息,然而对其它信息忽略过多,导致不能很好地表征语音情感谱包络,最终使得语音情感识别率较低。最小方差无失真响应(MVDR)谱最早由Capon提出[1],并被Lacoss证明它提供了对一个信号谱成分的最小方差无失真估计[2],当前该方法在阵列信号处理方面得到了广泛的应用。Cox等人针对导向向量失配问题,提出了对角加载稳健性的MVDR方法,但加载量大小的选择对算法的稳健性影响较重,加载量大小的选择比较困难[3]。Murthi和Rao等人最早将MVDR方法作为一种谱包络估计技术引入到语音识别中[4],Yapanel等人提出MVDR感知倒谱系数(PMCCs)用于语音特征提取,先将语音频谱通过mel滤波器组,计算得到感知自相关系数,再依据这些参数估计MVDR系数[5]。Md提出了一种正规化最小方差无失真相应(RMVDR)方法代替基于离散傅立叶变换直接谱估计来提取鲁棒性语音特征[6]。相比LP方法,MVDR方法可以计算语音情感的全极点谱,解决了LP谱对基音周期较高的浊音信号的频谱估计不准的问题。
在特征参数选择技术方面,当前特征选择算法主要有:穷举法,主成分分析法(PCA),线性判别法(LDA),启发式算法包括顺序向前选择(SFS)、顺序向后选择(SBS)、优先选择(PFS)、顺序浮动前进选择(SFFS)等,随机算法有蚁群算法(ACO)和神经网络分析法等,熵值法等,取得了一定的效果,但也存在不足。针对当前选择算法中存在的部分不足,本文提出了人工蜂群的特征选择语音情感识别算法。
本文首先采用最小方差无失真响应(MVDR)方法提取语音情感特征,提取出来的特征为语音情感信号功率谱特征,由16维的MVDR谱系数及一阶、二阶差分组成48维特征参数。然后运用人工蜂群算法对提取出来的情感特征进行分析,算法得到10维的最优特征子集,最后用径向基函数(RBF)神经网络进行模式匹配和情感识别。
1 MVDR谱估计算法
MVDR谱估计实际上是设计出满足下列条件下的滤波器组,M阶的FIR滤波器h(n)要求满足约束条件[7]:
1)无失真条件:
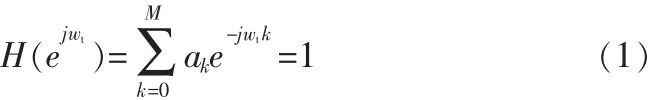
也可以写成矩阵形式

其中 ET(wt)=[1,ejwt,ej2wt,…,ejMwt],a=[a0,a1,…,aM]T,H 为矩阵的厄密共轭。也就是说,在感兴趣wt的频率的频率响应具有单位增益,使wt无失真地通过滤波器。
2)最小化h(n)的输出能量:

其中RM+1是输入信号的(M+1)行(M+1)列的自相关矩阵。
这个条件的最优问题的解是:

3)对a输出信号进行能量估计:

其中PMV(wt)为信号的MVDR功率谱,suu(ejw)表示信号的能量谱,H(ejwt)为滤波器在wt处的冲击响应。
无失真条件确保由频率wt组成的输入信号能够无失真地通过滤波器,使输出能量最小化达到抑制除感兴趣以外的其它频率信号和噪声的目的。所以MVDR方法能够解决LP方法对谐波频率处包络能量估计不足的问题。
按照上面的情况,MVDR方法好像必须为wt单独设计一个h(n),但在实际中进行信号频率估计时,可以直接由下式计算[8]:

2 ABC算法
ABC算法是一种模拟蜜蜂觅食行为的群智能优化方法。为解决多变量函数优化问题,Karboga于2005年提出的[9]。
在基本的ABC算法中,蜂群包括引领蜂、跟随蜂和侦察蜂3种个体。引领蜂对应一个确定的食物源(解向量)并在循环迭代中对该食物源的邻域进行搜索;跟随蜂根据食物源的收益度(适应值大小)采用轮盘赌方式搜索新的食物源;侦察蜂随机搜索新的食物源,使算法跳出局部最优解,即如果食物源多次更新没有改良,则舍弃该食物源。
3 基于ABC优化MVDR的语音情感识别
文中所设计的识别系统框图如图1所示,先对输入的语音情感信号进行预处理(预加重、端点检测、分帧、加窗等),再运用MVDR谱估计方法对情感信号进行特征参数提取,并对参数归一化处理,然后采用ABC方法对语音情感特征向量降维,最后在得到的情感特征子集向量上建立RBF分类识别模型并得到最终的识别结果和识别率。
文中算法的具体步骤如下:
1)逐一对语音情感信号样本进行预加重、端点检测、分帧、加窗等预处理,其中窗函数采用汉明窗,帧长为256,帧移为128。
2)按顺序根据公式6提取每一帧语音情感信号的MVDR谱系数,其中自相关矩阵的阶数M=16(阶数越高,谱分辨率越高)。
3)对MVDR谱系数按如下公式进行归一化处理。

4)运用ABC算法对归一化后的MVDR谱系数进行特征选择,选择出最优语音情感特征子集。
①ABC算法参数初始化。主要参数有人工蜂群大小Nc,引领蜂数量Ne,跟随蜂数量No,舍弃食物源参数limit,最大循环次数MCN,种群中解的个数Ns,每个解向量Xi=(Xi1,Xi2,…,XiD)(i=1,2,…,SN)都为D维向量(D为优化参数个数,SN为食物源数目)。
其中Nc,Ne,No,Ns满足Nc=2Ne=2No=2Ns,在初始阶段根据以下公式随机产生初始解Xi(i=1,2,…,SN),

其中j∈{1,2,…,D},Xmin,j与Xmax,j分别表示Xij中的下限与上限。
在本文识别模型中初始值设定分别为:Nc=20,Ne=No=Ns= 10,Limit=100,MCN=30。
②根据下列式子计算每个解Xi的适应度值:,i=0,1,2,

③引领蜂记录自己目前为止的最优食物源,并根据记忆在当前食物源邻域内展开搜索产生一个新的食物源,然后采用贪婪准则在记录中的最优食物源与新的食物源之间进行抉择,即当新的食物源优于记录中的食物源时,则用新的食物源替换旧的,否则,保留旧的食物源。
第i只引领蜂搜索邻域产生新的食物源Vj的公式为:

其中,j∈{1,2,…,D},k为[1,SN]之间产生的随机整数,并且k≠i;φij∈[-1,1]之间的随机数,代表邻域的搜索范围。
④当所有的引领蜂完成搜索过程后,将食物源的信息通过舞蹈区与跟随蜂分享。跟随蜂根据轮盘赌方式以一定概率选择食物源。跟随蜂选择食物源的概率公式为:

其中,fit(Xi)表示第i解的适应值对应食物源的收益度。收益度越高的食物源被跟随蜂选择的概率越大。
同样,跟随蜂也要根据公式(8)进行一次邻域搜索,并与引领蜂一样,选择较好的食物源。
⑤当某食物源保持迭代limit次没有改进时,则表示该食物源陷入局部最优,则应当舍弃该食物源,同时将该食物源对应的引领蜂转变为侦察蜂,并按⑺式随机产生一个新的食物源代替旧的。
⑥判断是否达到最大迭代次数(MCN),若达到,则循环结束,输出最优食物源;否则返回继续执行C,D,E。
(5)将上述得到的每个语音情感信号样本的最优特征子集作为RBF分类器的输入参数,经RBF识别后,得到每类情感的识别结果并统计出每类情感的平均识别率。

图1 基于ABC优化MVDR的语音情感识别流程图Fig.1 Process of based on ABC optimization MVDR speech emotion recognition
4 实验结果与分析
本文所采用的语音库为CASIA汉语情感语料库,由中国科学院自动化研究所录制,共包括4个专业发音人(2男2女),6种情感,我从中选择angry,fear,happy,neutral 4类基本情感进行研究,并将每人每类情感语句中的前30个作为训练样本,后20个作为测试样本。语音资料以wav格式存储,采样率为16 000 Hz,采样精度为16 bit,信噪比约为35 db。实验平台为CPU 2.40 GHz/2 GB,MATLABR2013a。分别用MVDR谱方法与LP谱方法对四种情感语音库进行特征参数提取,特征维数都为48维,包括16维的一阶差分与16的二阶差分。识别模型采用RBF。实验得到结果如表1所示。

表1 MVD与LP参数提取方法的识别率和识别时间Tab.1 Recognition rate and recognition time of MVD and LP parameter extraction method
从表1第3行的实验结果,我们不难看出,基于MVDR的语音情感新特征对实验的4种情感具有较高的区分能力,4种基本情感的识别率都达到了 60%以上,其中 fear和neutral的识别率较高,而angry与happy的识别率就相对较低。happy容易被错误的归类fear中去,而angry主要与neutral存在一定的混淆,这主要是因为情感强度类似的语音在发音时的许多生理特性存在一定的类似,容易混淆。从整个表1我们可以知道,用MVDR谱方法比用LP谱方法提取特征参数,4种基本情感的识别率都有所提高,其中angry,fear,happy,neutral的识别分别提高了 6.45%,5.6%,6.4%,11.1%,以至平均识别率提高了7.44%,从而进一步证明了MVDR提取情感特征的有效性,但是MVDR谱方法会使得识别系统的平均识别时间提高,所以文中提出了用ABC算法找到最优特征子集,消除特征冗余。实验得到的结果如表2所示。

表2 MVDR与MVDR+ABC方法的识别率与识别时间Tab.2 Recognition rate and recognition time of MVDR and MVDR+ABC methods
从表2中的实验结果,我们可以看出经ABC算法特征选择的平均识别时间比单独MVDR方法缩短了很多,并且在识别率方面也有一定的提高,angry,fear,happy,neutral的识别率分别提高了8.5%,2.3%,6%,0.85%,致使平均识别率提高了4.55%,所以相对于单独的MVDR方法,ABC算法在情感识别率与系统性能上都有较大的提高。
5 结束语
针对传统的LP方法过于强调谐波频率上的能量,使得语音情感谱包络形状尖锐,本文提出了MVDR谱方法用于提取特征参数,并用RBF进行识别。实验结果显示,该方法比传统LP谱方法明显提高了识别率,但增加了平均识别时间,所以提出了ABC算法用于特征选择,消除特征冗余。结果表明,ABC算法不仅减少了平均识别时间,而且提高平均识别率,使得语音情感识别系统鲁棒性增强。所以证明了本文算法的有效性。
[1]Capon J.High-resolution frequency-wavenumber spectral analysis[C]//Proceedings of the IEEE.USA:IEEE,1969,57:1408-1418.
[2]Lacoss R T.Data adaptive spectral analysis methods[J]. Geophysics,1971,36:661-675.
[3]Cox H.Robust adaptive beamforming[J].IEEE Transactions on Acoustic Speech and Signal Processing,1987,35(10):1365-1375.
[4]Dharanipragada S.Feature extraction for robust speech recognition[C]//IEEE International Sympo-sium on Circuits and Systems.USA:IEEE,2002:855-858.
[5]Yapanel U H,Dharanipragada S.Perceptual MVDR-based cepstral cosfficients(PMCCs)for noise robust recognition[M]. In:IEEE ICASSPO3,2003.
[6]Md.Jahangir Alam,Patrick Kenny,Douglas O'Shaughnessy,RegularizedMVDR Spectrum Estimation-based Robust Feature Extractors for Speech Recognition[J].Proc.INTERSPEECH,Lyon,France,2013.
[7]Ntalampiras S,Fakotakis N.Modeling the temporal evolution of acoustic parameters for speech emotion recognition[J]. IEEE Transactions on Affective Computing,2012,3(1):116-125.
[8]Haykin S.Adaptive Filter Theory[M].Englewood Cliffs,NJ:Prentice Hall,1991.
[9]KARABOGA D.An idea based on honey bee swarm for numerical optimization[R].Erciyes:Erciyes University,Engi-
Speech emotion recognition based on ABC optimization MVDR
SUN Zhi-feng
(School of Computer Science Shaanxi Normal University,Xi’an 710062,China)
It is a crucial problem to extract and choose the features of speech emotion.To solve the problem of Linear Prediction in speech emotion spectrum envelope,this paper puts forward to extract the features of speech emotion with Minimum Variance Distortionless Response(MVDR)spectrum method.In order to eliminate redundant information,it uses Artificial Bee Colony(ABC)algorithm to obtain the optimal subset of the features.Then the experiment recognise four speech emotions namely:angry,neutral,happy,fear,in the Casia Chinese Emotion Corpus through Radial Basis Function(RBF)Neural Network method.The results show that the approach in this paper has higher rate of recognition and is more robust.
minimum variance distortionless response;artificial bee colony algorithm;speech emotion recognition;linear prediction
TN710.9
A
1674-6236(2016)03-0011-03
2015-03-15稿件编号:201503196
孙志锋(1989—),男,江西上饶人,硕士研究生。研究方向:信号处理,模式识别。
