基于高维数据优化聚类的长周期峰谷时段划分模型研究
2016-09-13张文月王玉玮
李 娜,王 磊,张文月,王玉玮,舒 艳,张 超
(1.国网天津市电力公司经济技术经济研究院,天津 300171;2.国网天津市电力公司,天津 300010; 3.华北电力大学,北京 102206)
基于高维数据优化聚类的长周期峰谷时段划分模型研究
李娜1,王磊1,张文月2,王玉玮3,舒艳3,张超3
(1.国网天津市电力公司经济技术经济研究院,天津300171;2.国网天津市电力公司,天津300010; 3.华北电力大学,北京102206)
0 引 言
峰谷分时电价是需求侧管理中一种有效的经济手段,因此合理科学地引入需求侧管理来设计峰谷分时电价,通过运用价格信号有效调整电力用户的用电习惯和用电计划,对提高资源利用率、优化资源配置、实现削峰填谷、降低发电成本、促进电源与电网的协调发展以及推动整个电力行业健康发展起着决定性的作用。
峰谷分时电价制定的恰当与否跟峰谷时段的划分和用户需求响应密切相关[1]。峰谷时段的划分是峰谷分时电价的定价基础,其划分方法的选取直接影响用户的需求响应程度,从而影响电价的实施效果。因此,制定合理的峰谷分时电价的首要任务是科学合理地进行峰谷时段的划分。
目前已有的关于峰谷时段划分的方法主要有:文献[1,2]以日负荷曲线分布为基础,结合模糊聚类分析技术,构建了峰谷时段划分模型;文献[3]基于密度聚类算法,对年持续负荷曲线中各负荷所对应的持续时间进行聚类分析,然后通过分布集边界所对应的负荷大小划分峰谷时段;文献[4]采用因素分析法,将其与原始负荷电量相结合,构建峰谷时段划分模型;文献[5]提出了一种基于不同时段供电成本差异的时段划分模型。
在上述研究成果的基础上,本文着重考虑峰谷时段划分结果的客观合理性及其是否能在一个较长时间周期(如1a)内适用这两个问题。为此,本文提出以下研究思路:首先,通过数据高维化的处理方法构建涵盖较长时间周期(例如1a)内所有负荷信息的数据样本集;其次,以K-均值算法为聚类分析工具,在高维数据样本集上构建峰谷时段划分模型;最后,结合某区全年负荷数据,对所构建的模型进行算例仿真,在验证模型的合理性基础上,最终输出时段划分结果。
1 峰谷时段划分的理论依据
对全天进行峰、平、谷时段划分,其基本原理就是根据各时点(通常做法是将全天分为24个时点或时段)上所采集的负荷数值大小,将负荷取值相对大的各时点统一划分为全天的峰时段、将负荷取值相对小的各时点统一划分为全天的谷时段、将负荷取值相对中等的各时点统一划分为全天的平时段。由此可见,基于峰、平、谷时段划分原理的各类算法本质上属于数据挖掘中聚类分析(无导师学习)的范畴,划分效果的好坏主要取决于以下两点:
① 包含基本信息的数据样本集合如何构造,使对其进行时段划分的最终结果适用于一个较长的时间周期(一季、一年或者更长);
② 判断各样本点取值(相当于各时点负荷值)相对大小的分类标准如何确定,使据此进行时段划分的结果最大限度地反映出峰、平、谷各时段在负荷取值方面的差异。
对以上两点问题的合理解决将是本文论述的关键。数据样本点的高维化和聚类算法可通过迭代自动收敛于最优分类标准是这些目标实现的基础。接下来分别就数据样本点的高维化和K-均值聚类算法展开研究。
2 基于高维度量空间的数据样本集构建
为了使最终的时段划分结果适用于一个较长的时间周期,仅使用某天的各时点负荷数据构造数据样本集合显然是不合理的。这是因为,在一个较长的时间周期内(例如1a),各日负荷曲线的形状差异会比较明显,且这种差异程度会随着周期加长而增大,从而适用于某日的峰、平、谷时段划分结果并不一定适用于另一日。面对这一问题,比较直观的处理方法是:
① 在一个较长的时间周期内(以下称其为全周期),分别以每一日的时点负荷数据为样本集,采用一定的聚类方划分出各日的峰、平、谷时段;
② 根据各日的时段划分结果统计出24个时点分别被划分为峰、平、谷各时段的天数;
③ 根据最大天数原则,判断某个时点最终应当被划分于峰、平、谷某一时段,从而得到了考虑全周期所有日负荷时间分布特点的峰、平、谷时段划分结果。
上述方法在所选全周期长度较小时比较可行,但是当周期长度(天数)增加时,该方法的迭代次数会随之成倍增长,且一旦出现某一时点被划分于峰、平、谷各时段天数相等的情况,则最大天数原则失效,算法无法输出最终的划分结果。
为此,本文建立如下考虑全周期各日负荷信息的数据样本集构造方法。
设所分析全周期内共含天数为n(n∈N,n>0),在第t(t=1,2,…,24)个时点上,所研究地区n天中对应的负荷数据可组成如下向量:
(1)
式中:xt,i表示第i(i∈N,0 定义如下集合: (2) 则向量S为集合Rn中的可数子集。Rn为 向量S即为所构造的用于时段划分的数据样本集合,该集合包含了全周期内各个时点t上所有日的负荷数据。 但是,上面定义的样本集S并不能直接用于时段划分的计算,其原因是集合中没有表示元素之间“远近”的概念,因此无法进行分类,需要做如下处理: 不影响最终分析结果,在集合Rn中定义如下欧式距离,从而Rn构成n维实欧式空间: (3) 式中:d(x,y)∈R表示空间Rn中任意两点x,y之间的欧式距离。因S为Rn的子集,因此,S中任意两个元素(样本)之间的距离可表示为 (4) 式中:t1,t2=1,2,…,24。 定义距离概念之后,就可以根据距离的大小来判断空间Rn中任意两点的“远近”程度。显然,这种“远近”的概念同样适用于S中的元素。 以上方法所构造的数据样本集S具有以下两项优点: ① S中包含了全周期各时点上所有负荷数据,从而在S上进行合理的聚类分析,可得到适用于全周期的峰、平、谷时段划分结果; ② S中的元素,即样本点是以n维向量的形式给出的,这种将数据高维化的构造方式避免了算法迭代次数因全周期天数增加而成倍增长的不足,可适用于较长时间跨度(数年)全周期上峰、平、谷时段的划分。 本文依据所建样本集S中的数据(样本点)具有高维度、数值型、无标记等特点,选取K-均值算法(以下用K-means表示)作为分析工具,对样本集S进行峰、平、谷时段划分。 K-means是最常用的聚类算法之一,能有效地处理规模较大和高维的数据集合,能对大型数据集进行高效分类。该算法按照定义的划分标准,把数据分成几组,使得同组内数据相对聚拢,相异组之间数据相对疏散,按这样的方法所形成的每一组就称作一个聚类(或聚簇)。在K-means中,划分准则常常采用误差平方和准则函数来描述。此算法是通过迭代寻找K个聚类的一种划分方案,使得用这K个均值来代表相应各类样本时所得到的总体误差最小。 对于不同的聚类方案,误差平方和准则函数值J一般是不相同的。使J值最小的聚类方案即为在误差平方和准则下的最优聚类结果。 误差平方和J无法用解析的方法最小化,只能采用迭代的方法,通过不断的调整样本的类归属情况来获得最优解。 K-means的效率较高,其缺点是只能处理数值型数据。然而,峰谷时段划分问题实质上就是根据各时点上负荷数值的大小进行聚类划分,因此,该问题正好属于该算法的适用范畴。 运用K-means进行峰谷时段划分的原理及基本步骤如下: 如上节所述,所构造的数据样本集S中每一个样本点xt即为一个n维向量(n为所选全周期中的总天数),S的样本容量为24(即24个时点),需要将这24个样本点重新划分为峰时段、平时段、谷时段3类。因此,该算法运用到本文所构建的样本集S上进行峰、平、谷时段划分的问题即可描述为:令K=3,即将24个样本点(数据对象)划分为3个聚类以便使得所获得的聚类结果满足同一聚类中的对象相似度较高,而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中所有样本点的均值所获得一个“聚类中心”来进行计算的。 第一步:在样本集S中随机选K=3个初始聚类中心X1,(1),X2,(1),X3,(1),其中括号内的序号为寻找聚类中心的迭代运算次序号。聚类中心的向量值可任意设定,例如可选开头的3个模式样本集中的向量值作为初始聚类中心。 第二步:逐个将S中的样本点xt按最小欧式距离准则分配给3个初始聚类中心中的某一个Xj,(1)(j=1,2,3)。对所有的xt,如果在第k次迭代中,xt到Xj,(k)的欧式距离比到其他任何中心点都近,则xt∈Sj,(k)。其中,Sj,(k)表示经第k次迭代后所形成的第j(j=1,2,3)个聚类。其聚类中心为Xj,(k)。 第三步:在每一次形成新的聚类结果S1,(k)、S2,(k)、S3,(k)后,进一步按类内均值线性变换的方法计算各个聚类中心的新的向量值Xj,(k+1),类内均值线性变换的具体公式为 (5) 式中:lj,(k)为Sj,(k)中所包含的样本点个数。并在新的聚类中心基础上,重新按照最小欧式距离准则形成新的聚类结果S1,(k+1)、S2,(k+1)、S3,(k+1),即完成第k+1次迭代。 第四步:在每一次迭代完成后以均值向量作为新的聚类中心,可构造如下误差平方和准则函数: (6) 迭代的目的是为了使J值达到极小,当第k+1次迭代后的J(k+1)值与第k次迭代后的J(k)值相等,则迭代停止,输出的S1,(k+1)、S2,(k+1)、S3,(k+1)即为使得同一聚类中的对象相似度最高,而不同聚类中的对象相似度最小的最优聚类结果,各类按所含元素负荷值大小区分为对应的峰时段聚类、平时段聚类以及谷时段聚类。否则,应返回第二步开始新一轮的迭代计算。 以某地区负荷数据为例,利用以上所构建的模型,对该区峰谷时段划分进行实例分析。 首先,为了验证所构建模型的合理性与可行性,在全年数据中选择日期相隔较远的两天数据,各自单独进行仿真分析。图1、图2分别是该区2013年7月1日和9月1日基于K-means单日时段划分模型的仿真结果,分析方法可做如下简要介绍: 图1 7月1日峰谷时段划分仿真图像 图2 9月1日峰谷时段划分仿真图像 以对7月1日各时点(24个时点)负荷数据进行峰、平、谷时段划分为例。第一步,将该日数据构造成维度为1(1d),样本点数量为24个(24个时点,每个样本点均按所在时点进行编号)的数据样本集S;第二步,在数据样本集上运用第3节中所构建的K-均值数据挖掘模型进行聚类迭代运算(将K值设为3),并最终将S中所包含的所有样本点划分为S峰、S平、S谷3个聚类,其中,相对应,S峰类中所包含的各样本点的时点编号组成峰时段,S平类中所包含的各样本点的时点编号组成平时段,S谷类中所包含的各样本点的时点编号组成谷时段。 从对以上2日各自的分析结果中可以看出,7月1日时段划分结果(图中阶梯线表征,其中最低梯级线表示谷时段的位置与长度,中间梯级表示平时段的位置与长度,最高梯级表示峰时段的位置与长度)明显与9月1日存在差异(主要差异体现在下午14-15点的划分类别不同),这主要是由于这两日各自具体的负荷曲线形状不同所引起的。 类似地,若希望将一个日峰、平、谷时段划分结果够推广到至少1a的时间周期内长期使用,则得到这个划分结果的过程中必须同时考虑到在1a的时间周期内,各日整点负荷数值的大小分布情况,这显然不是简单进行某个单日数据的分析所能得到的。上述仿真分析验证了本文第2节一开始便提出的结论:为了使最终的时段划分结果适用于一个较长的时间周期,仅使用某天的各时点负荷数据构造数据样本集合显然是不合理的。 其次,为了解决上述问题,得到一组可以在1a的时间周期内推广的日峰、平、谷时段划分结果,本文以该地区2013年全年的负荷数据进行仿真,如图3是全年峰谷时段划分的仿真图像。分析方法可做如下简要介绍: 第一步,将全年整点负荷数据构造成维度为365(365d),样本点数量为24个(24个时点,每个样本点均按所在时点进行编号)的数据样本集S;第二步,在数据样本集上运用第3节中所构建的K-均值数据挖掘模型进行聚类迭代运算(将K值设为3),并最终将S中所包含的所有样本点划分为S峰、S平、S谷3个聚类,其中,相对应,S峰类中所包含的各样本点的时点编号组成峰时段,S平类中所包含的各样本点的时点编号组成平时段,S谷类中所包含的各样本点的时点编号组成谷时段。 图3中,阶梯线依然表征峰、平、谷各时段的位置及长度,曲线簇代表该地区2013年全年各日(365d)按整点数据所绘制的负荷曲线。本文模型所得出的峰谷时段划分结果如下: 峰时段:10:00—14:00,15:00—21:00;平时段:8:00—10:00,14:00—15:00,21:00—23:00;谷时段:0:00—8:00。 图3 全年峰谷时段划分仿真图像 该区2013年的时段划分情况如下: 峰时段:8:00—11:00,16:00—21:00;平时段:6:00—8:00,11:00—16:00,21:00—22:00;谷时段:22:00—6:00。 将以上两种时段的划分结果进行对比分析可知:峰谷时段的划分是以“三平两峰一谷”的形式存在,仿真结果比实际的时段划分更加合理。可举例说明:从图3中全年各日负荷曲线分布上可以看出(图中曲线簇),在中午12时左右的负荷水平基本处于全天的最高峰(不符合这一规律的日负荷曲线在该地区2013年全年中未找到),即便从直观上分析,亦理应将该时点划分于全天的峰时段才更合适。 最后,通过算例仿真结果可知,本文所建模型的输出结果(即峰、平、谷时段划分结果),既可在一个较长的时间周期内适用,同时又客观地反映出所分各时段之间的负荷差异,其合理性与可行性在一定程度上得到了验证。 本文通过研究可得以下结论: ① 通过数据高维化处理所构造的峰谷时段划分数据样本集S具有以下两项优点: a.其包含了一个较长时间周期(如1a)内24个时点上的所有负荷信息,从而为得到长期适用的峰谷时段划分结果提供了完整的数据依据。 b.样本集S将全周期中相同时点上浩繁的负荷数据整合为同一向量(样本点)上不同的坐标分量,这样一来大大简化了样本容量(无论所研究周期有多长,S的样本容量总是为24个样本点),从而降低了模型的迭代次数并保证了其一致收敛性。 ② 引入K-means进行建模克服了处理高维度、数值型样本聚类问题难以收敛的困难,并且算法的迭代过程本身就是一个时段划分的优化过程,上述两点可保证得到同一聚类中的对象相似度最高,而不同聚类中的对象相似度最小的峰、平、谷时段划分优化结果。 ③ 通过算例仿真,除了验证模型的合理性以及得到针对某地区全年负荷数据的最优时段划分结果外,还可以看出,针对某一日负荷数据得到的时段划分结果与针对全年数据得到的时段划分结果不同,这一点从实验的角度验证了本文所提出的观点:为了使峰谷时段划分结果能够客观反映出各时段的负荷差异,且能够在一个较长的时间周期(例如月、季、半年、年等)内适用,因此在高维数据样本集的基础上引入K-means来构建适用于一定周期内的时段划分模型。 [1]连振洲,温步瀛,江岳文.基于负荷曲线分布特征的峰谷时段划分和修正策略研究[J].电网与清洁能源,2014(7):15-19. [2]丁宁.基于DSM的峰谷时段划分及分时电价的研究[D].南京:南京理工大学,2002. [3]乔慧婷.基于密度聚类的峰谷时段划分方法研究[D].北京:华北电力大学,2011. [4]刘菁菁.基于因素分析法的峰谷时段划分的研究[D].天津:河北工业大学,2006. [5]林旻,朱艳卉,胡百林.基于供电成本的峰谷时段划分及分时电价研究[J].华东电力,2005(12):90-91. [6]赵娟,谭忠富,李强.我国峰谷分时电价的状况分析[J].现代电力,2005,22(2):82-85. [7]戴诗容,雷霞,程道卫等.电动汽车峰谷分时充放电电价研究[J].电网与清洁能源,2013,29(7):77-82. [8]翟娜娜.基于用户需求响应的峰谷时段划分研究[D].北京:华北电力大学,2011. [9]李泓泽,李婷婷.峰谷分时电价对供需双方的影响分析[J].现代电力,2008(4):87-92. [10]刘严,谭忠富,乞建勋.峰谷分时电价设计的优化模型[J].中国管理科学,2005,13(5):87-92. [11]周东华.数据挖掘中聚类分析的研究与应用[D].天津:天津大学,2006. (责任编辑:林海文) Research on the Partition Model of Long Period Peak and Valley Time Based on High Dimensional Data Clustering LI Na1,WANG Lei1,ZHANG Wenyue2,WANG Yuwei3,SHU Yan3,ZHANG Chao3 (1.State Grid Tianjin Economic Research Institute,Tianjin 300171,China;2.State Grid Tianjin Electric Power Company, Tianjin 300010,China;3.North China Electric Power University,Beijing 102206,China) 为了使峰谷时段划分结果客观反映出各时段的负荷差异,且能够在一个较长的时间周期(例如1a)内适用,本文提出一种以数据样本集高维化处理和K-均值聚类分析相结合的时段划分模型。首先,通过数据高维化的处理方法构建涵盖较长时间周期(例如1a)内所有负荷信息的数据样本集;其次,以K-均值算法为聚类分析工具,在高维数据样本集上构建峰谷时段划分模型。最后,结合某区全年负荷数据,对所构建的模型进行算例仿真,在验证模型的合理性基础上,最终输出时段划分结果。 时段划分;聚类分析;K-均值算法;数据高维化 In this paper,in order to make the results of peak and valley time division reflect the load difference of each period objectively and be applicable in a long period of time (e.g.,1 year),a time division model is presented by combining processing of high-dimension data sampling set and K-means clustering analysis.First of all,a data sample set covering all load information within a long period of time (e.g.,1 year) is built by using the processing method of high-dimension data.Secondly,the peak and valley time division model based on the high-dimension data sample set is built by using K- means clustering analysis.Finally,the numerical simulation of proposed model is carried out by combining the load data of the whole year in certain district,and the final division result of the peak and valley time can be output on the basis of verifying the rationality of the model. peak-valley-time division; clustering analysis; K-means clustering algorithm; high-dimensional data 1007-2322(2016)04-0067-05 A TM715 国网天津市电力公司科技项目(KJ15-1-28) 2015-08-26 李娜(1985—),女,博士,工程师,研究方向为电力市场理论与应用技术研究,E-mail:linajiamie@163.com; 王磊(1981—),女,博士,工程师,研究方向为电力市场理论与应用技术研究,E-mail:leiwendy@126.com; 张文月(1982—),女,工程师,研究方向为电力市场理论与应用技术研究,E-mail:zhangwenyue2005@126.com。3 时段划分模型构建
4 算例仿真
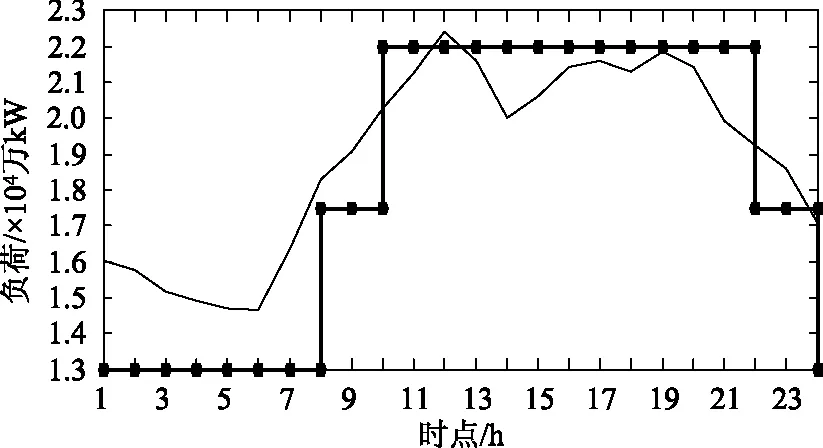
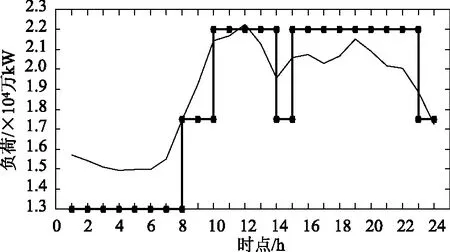

5 结 论
