面向移动时空轨迹数据的频繁闭合模式挖掘*
2016-09-13郭鑫颖秦学斌
王 亮,汪 梅,郭鑫颖,秦学斌
(西安科技大学 电气与控制工程学院,陕西 西安 710054)
面向移动时空轨迹数据的频繁闭合模式挖掘*
王亮,汪梅,郭鑫颖,秦学斌
(西安科技大学 电气与控制工程学院,陕西 西安 710054)
移动泛在感知设备的广泛普及为移动轨迹数据的大规模采集、存储与分析开拓了广阔的空间。通过对用户的移动轨迹数据进行分析挖掘,发现其中所蕴含的有价值的行为模式与特征,对于基于位置的服务(Location-based Service,LBS),城市交通管理,精准广告营销等领域均具有重要的价值。文中针对移动轨迹频繁模式规模过大、信息冗余问题定义了频繁闭合移动轨迹模式,以经典闭合序列模式挖掘算法为基础提出了适应于移动轨迹数据的频繁闭合模式CloseTraj算法,分别通过对仿真数据与真实数据的实验测试,结果显示文中所提出的CloseTraj算法对于频繁闭合移动轨迹模式挖掘问题具有较强的适用性,同时在运行效率方面具有显著优势。
移动轨迹;数据挖掘;频繁闭合模式
0 引 言
随着移动通信与定位技术的不断发展,通过携带便携式设备对移动轨迹数据进行采集、传输与存储成为可能。利用数据挖掘、机器学习等相关技术对所收集的移动轨迹数据进行挖掘与分析,进而从中发现有价值的信息与知识,对于理解移动行为模式、揭示移动行为规律、预测移动行为趋势均具有十分重要的价值与意义。此外,在应用方面,所发现的价值信息可以为基于位置的服务、城市公共管理、移动社交网络、精准广告营销等领域提供决策依据。
然而,移动轨迹数据由于其中所蕴含的时间-空间交叉演化关系以及背景知识约束(城市路网,区域功能定位等方面),同时移动轨迹背后所隐含的是移动者的行为特征,也即“人的特征”,这种“以人为中心”的场景对于行为特征的提取与行为模式的挖掘分析带来了极大的挑战。作为时间连续的行为序列数据,频繁模式集中易出现多个挖掘模式多项集重合、冗余的现象,而现实社会中同一社区群组相近移动行为特征的普遍存在更是在一定程度上凸显了这一问题,为此,文中定义了面向移动轨迹的频繁闭合模式,在序列数据频繁闭合模式挖掘的经典算法的基础上,提出了适应于移动轨迹数据的频繁闭合模式挖掘算法CloseTraj算法,在对移动轨迹数据进行模式挖掘时最大程度的缩减所挖掘的模式规模,从而使行为模式挖掘过程所产生的模式集合在包含相同信息的前提下,规模得到最大程度的约简。
与文中相关的研究工作主要有以下2类:①频繁闭合模式;②移动轨迹模式挖掘。在频繁闭合模式挖掘方面,针对项目集数据,Pasquier等于1999年首次提出了频繁闭合项集挖掘问题[1]。 Pei等利用压缩频繁模式树FP-Tree结构,提出了CLOSET算法以挖掘频繁闭合项集。Zaki与Hsiao等提出了CHARM算法以挖掘频繁闭合模式[2]。针对序列数据的模式挖掘问题,Yan等提出了CloSpan算法以挖掘频繁闭合序列模式,CloSpan算法利用剪枝策略与非频繁序列剔除策略,通过对投影数据库的搜索,将所挖掘的频繁闭合序列模式存储在晶格结构中[3]。Han等学者提出了两方向搜索投影数据库的BIDE算法以有效提升闭合模式挖掘的效率[4]。
在移动轨迹模式挖掘方面,F.Giannotti等学者在文献中定义了一种称之为T-Patterns的带时间注释的移动轨迹序列模式。同时其提出了热点空间区域ROI(Region of Interesting)以表示移动对象频繁访问的一类空间区域。通过分别以静态和动态的方式检测发现热点空间区域,利用类PrefixSpan 算法对频繁时间注释移动轨迹模式进行抽取与挖掘[5]。台湾地区Anthony J.T.Lee 等学者在中提出了一种基于图的频繁时空轨迹模式挖掘算法GBM。通过构建Mapping 图和轨迹信息List,GBM 算法以深度优先搜索策略对Mapping图进行遍历搜索以发现频繁轨迹模式集合[6]。然而,GBM 算法中所使用的移动轨迹数据集合是一种简单的离散相邻单元序列数据,因而无需对连续空间域进行离散化划分或是近似处理。新墨西哥州立大学的曹惠萍等学者提出了以移动轨迹分段简化方法解决频繁时空序列模式挖掘问题[7]。在文献[7]中,原始移动轨迹被转换为分割线段表示的序列数据集合,进而以基于距离的方法提取频繁轨迹线段,以及采用改进的类Apriori算法与substring tree的结构进行频繁模式挖掘。Chung等学者在文献[8]中使用基于Apriori的挖掘算法以发现移动轨迹序列数据中的频繁移动模式。Arthur.A.Shaw等在中基于Apriori算法对以二维空间坐标表示的移动轨迹数据的频繁模式进行了挖掘分析研究[9]。
1 时空移动轨迹频繁模式
移动轨迹数据可以表示为如下所示的四元组形式:
对于移动轨迹数据频繁模式的定义为移动轨迹频繁模式具有如下形式:
且其支持度大于预先给定的最小支持度阈值。频繁移动模式反映的是移动用户群体在移动行为上具有相同的特征或是规律,其表征的是移动用户在上一时刻位于
假设通过移动模式的挖掘之后,产生了2个不同的移动模式,分别为模式(1)
2 闭合频繁移动轨迹模式挖掘
基于Pasquier等于1999年所提出的频繁闭合项目集的概念,定义了频繁闭合移动轨迹模式。
定义3:频繁移动模式Tpi属于频繁闭合移动模式,其必须满足如下条件,即在频繁移动模式集合中不存在这样的一个模式Tpj,使Tpj与Tpi具有相同的支持度值,且Tpj为Tpi的超集。即在所获取的频繁移动轨迹模式集中,不存在任一模式Tpj,满足Tpj≻Tpi,且support(Tpj)≥support(Tpj)。
与频繁闭合项目集的性质相似,频繁闭合移动轨迹模式集合仅仅是频繁移动轨迹模式集的一个有限子集,但其包含了所有频繁项目集的完整信息。根据频繁闭合移动轨迹模式集可以产生频繁移动轨迹模式全集,然而在数量上频繁闭合移动轨迹模式集合较频繁移动轨迹模式集有了显著的减少,有效减缓了挖掘过程的运算代价。
文中以频繁闭合序列模式挖掘经典算法CloSpan为基础,以FP-Tree表示模式支持度,通过对移动数据库的深度优先搜索以挖掘频繁闭合移动轨迹模式,设计并实现了适应于移动轨迹数据的频繁闭合移动轨迹模式挖掘算法CloseTraj算法,CloseTraj算法的伪代码如下所示:

算法:频繁闭合移动轨迹模式挖掘算法CloseTraj输入:移动轨迹数据库D;用户自定义最小支持度阈值σ,用户设定的空间区域范围大小ε;输出:频繁闭合移动轨迹模式集合S1.基于空间聚类的移动轨迹数据转化f(x,y,ε);2.计算聚类空间集合中的元素频繁度并移除非频繁聚类空间项;3.以长度为1的频繁聚类空间集合构建晶格结构LS;4.对于每一个晶格集合LS中的元素ls5.搜索以ls为前缀的投影数据库Dls,同时扩展生成新的频繁模式;6.剔除非闭合频繁移动轨迹模式;7.更新频繁模式晶格结构LS.
如图1所示为频繁闭合模式挖掘的基本流程:首先对GPS移动轨迹数据进行数据的预处理过程,包括针对冗余数据的基于速度比较的合并约简、缺失数据的线性插值以及噪声数据的卡尔曼滤波剔除等,经过数据清洗过程之后生成分段语义轨迹数据集合,进而对所覆盖的空间区域进行近邻聚类操作以实现对连续空间区域的离散化处理过程,最后实现对闭合频繁模式的挖掘过程。需要注意的是,在空间区域聚类部分,基于空间语义近邻函数以及移动轨迹数据的空间分布点密度进行连续空间区域的聚类处理,定义空间语义近邻函数为f(x,y,ε),其中x和y表示空间坐标轴的横坐标与纵坐标,也即经纬度信息,ε为用户设定的空间区域范围大小,该参数的大小表征语义轨迹中空间粒度的粗细程度。

图1 移动轨迹数据频繁闭合模式挖掘流程Fig.1 Closed pattern mining process of mobile trajectory data
3 实验分析
实验运行环境的CPU为Intel(R)Core(TM)i3-311M @2.40 GHz,内存为4.00 GB,操作系统为Win7,所有的实验采用C++实现。实验数据分别采用仿真数据与真实数据,其中仿真数据为随机移动轨迹数据与自定义频繁移动轨迹数据的合成数据集,其中随机轨迹数据的产生如下:假设移动个体初始随机定位于某一空间位置,其次以某一随机概率向其近邻的若干个网格迁移或是继续停留在当前所处的移动网格单元之内,轨迹的长度服从Poisson 分布规律,轨迹平均长度从12到20不等,数据规模为12 M,相应的实验结果如图2~图4所示。真实数据为雅典某学校校车GPS轨迹数据,数据集规模为352 M,相应的实验结果如图5所示。
对上述算法进行仿真数据测试试验,第一个实验为移动轨迹数据的空间聚类实验,即基于空间近邻函数关系的连续空间离散化聚类,ε参数在随机数据集与真实GPS数据集中的值分别设置为2个单位与125 m,最终的聚类结果如图2所示为64个互不重合的空间区域,图示为64个离散空间区域之间基于移动轨迹数据的关联矩阵可视化结果,所获取的关联矩阵中元素mi,j表示实验数据中从离散区域i到j的轨迹个数。第二个实验为ColseTray算法的效率测试,即不同最小支持度阈值下算法的运行时间测试。第三个实验为ColseTray算法的扩展性测试,具体为平均轨迹长度下算法的运行时间测试。

图2 移动轨迹空间近邻聚类结果图示Fig.2 Neighbor clustering result of mobile trajectory spatial
图3所示为分别基于不同的搜索方式:深度优先搜索与广度优先搜索实现的频繁闭合移动轨迹模式挖掘效率实验,深度优先搜索算法为CloseTraj算法,其中最小支持度分别为0.5%到1%之间均匀取值,从图中可以看出,随着支持度的不断增大,2种算法的时间消耗呈指数规律递减,同时与广度优先搜索相比较,采用深度优先搜索方式的CloseTraj算法其运行时间更短。
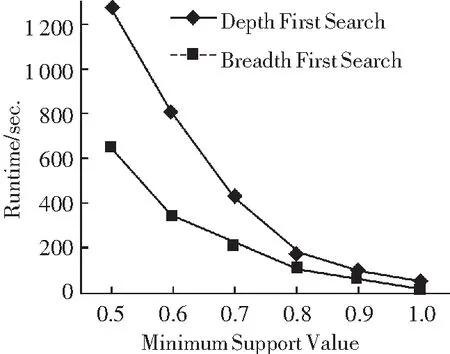
图3 2种不同搜索方式下的算法运行时间Fig.3 Algorithm running time of two different search methods
图4 所示为不同移动轨迹平均长度在最小支持度分别为0.5%,0.6%以及0.7%下的算法运行时间结果图示。由图可以看出,随着移动轨迹平均长度的不断增加,其算法运行时间呈线性增长趋势;且相同平均长度的移动轨迹在最小支持度越小的条件下其运行时间越长,增长越快。
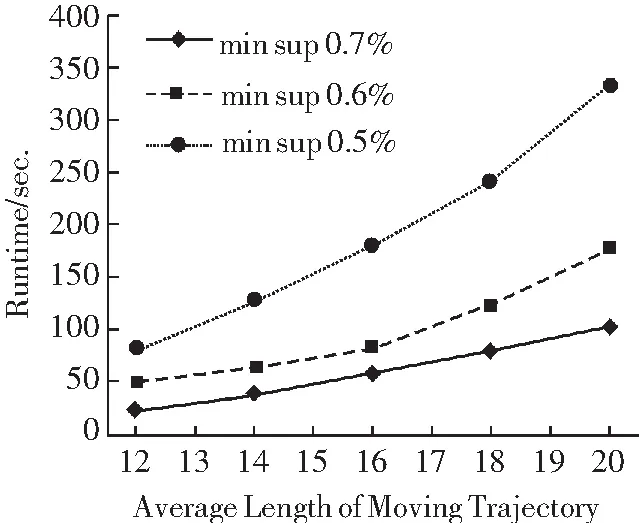
图4 不同平均移动轨迹长度下的算法运行效率Fig.4 Algorithm running efficiency of different average length mobile trajectories
此外,利用CloseTraj算法对雅典市真实车辆GPS移动轨迹数据进行了闭合频繁移动模式挖掘实验测试,如图5所示为所挖掘的闭合频繁模式集合中的一个模式Google Earth可视化结果,图中红色的气泡图标表示的是所在的空间位置,由图中可见,该闭合模式长度为3,方向从下向上移动。

图5 频繁闭合移动轨迹模式的Google Earth图示Fig.5 Google Earth picture of frequent closed mobile trajectory patterns
4 结 论
文中针对移动轨迹数据的频繁闭合模式挖掘问题展开研究,利用深度优先搜索方式,基于经典序列数据的频繁闭合模式挖掘算法提出了适用于上述问题的CloseTraj算法,分别进行了基于仿真数据与真实数据的算法运行实验。在算法运行效率方面,实验结果显示随着支持度的不断增大,算法运行时间呈指数规律递减;在时间可扩展性方面,随着移动轨迹平均长度的增加,算法运行时间呈线性增长趋势,即所提出的算法在效率性及可扩展性方面均具有较好的性能。
References
[1]Pasquier N,Bastide Y,Taouil R,et al.Discovering frequent closed itemsets for association rules[C]//Database Theory-ICDT’99.Springer Berlin Heidelberg,1999:398-416.
[2]Zaki M J,Hsiao C J.CHARM:An efficient algorithm for closed itemset mining[C]//SDM,2002(2):457-473.
[3]Yan X,Han J,Afshar R.CloSpan:Mining closed sequential patterns in large datasets[C]//In SDM,2003:166-177.
[4]Wang J,Han J.BIDE:Efficient mining of frequent closed sequences[C]//Data Engineering,2004.Proceedings.20th International Conference on.IEEE,2004.
[5]Fosca Giannotti,M.Nanni,F.Pinelli,D.Pedreschi,Trajectory pattern mining[C]//In:Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Scan Jose,California,USA,2007.
[6]Anthony J T Lee,Yi-An Chen,Weng-Chong IP.Mining frequent trajectory patterns in spatial-temporal database[J].Information Sciences,2009,179(13):2 218-2 231.
[7]Huiping Cao,Nikos Mamoulis,David W.Cheung,Mining frequent spatio-temporal sequential patterns[C]//In:Proceedings of the Fifth IEEE International Conference on Data Mining,ICDM,2005.
[8]Jae Du Chung,Oh Hyun Paek,Jun Wook Lee,et al.Temporal pattern mining of moving objects for location-based service[C]//In:Proceedings of the 13th International Conference on Database and Expert Systems Applications,331-340.
[9]Arthur A Shaw,Gopalan N P.Frequent pattern mining of trajectory coordinates using apriori Algorithm[J].International Journal of Computer Application,2011,22(9):1-7.
Frequent closed patterns mining for mobile trajectory data
WANG Liang,WANG Mei,Guo Xin-ying,QIN Xue-bin
(CollegeofElectricalandControlEngineering,Xi’anUniversityofScienceandTechnology,Xi’an710054,China)
Thankstothewidespreadpopularityofmobileubiquitoussensingdevices,theacquisition,storageandanalysisoflarge-scalemobiletrajectorydatahavebroadprospectsfortechnologyapplications.Bythemeansofanalysisandminingforusers’mobiletrajectoryhistory,wediscovermeaningfulbehaviorpatternsandcharacteristicsbehindtherecordedtrajectories.Theabove-mentioneddiscoveredknowledgeisofgreatvalueforlocation-basedservices,urbantrafficmanagement,targetadvertisingandmanyotherareas.Inthispaper,aimedattheover-sizedissueandinformationredundancyprobleminfrequentmovementtrajectorypatterns,aconceptionoffrequentclosemovingtrajectorypatternisproposed.Moreover,basedonclassicalclosedsequentialpatternminingalgorithm,afrequentclosepatternapproach,namelyCloseTrajalgorithm,isdevisedundertheconditionofmovingtrajectorydata.Basedonthesimulationandrealdataset,thecorrespondingresultsshowthatourproposedCloseTrajalgorithmhasstrongadaptabilitytotheaforementionedproblemwithsignificantadvantagesintermsofoperationalefficiency.
mobiletrajectory;datamining;frequentclosedpattern
10.13800/j.cnki.xakjdxxb.2016.0419
1672-9315(2016)04-0573-04
2016-04-20责任编辑:刘洁
国家自然科学基金(61402360)
王亮(1984-),男,陕西宝鸡人,博士,E-mail:liangwang0123@gmail.com
TP 311
A
