基于层次聚类分析的上市公司利润操纵识别*
2016-09-10合肥工业大学经济学院张本照郄亚美王海涛
合肥工业大学经济学院 张本照 郄亚美 王海涛
基于层次聚类分析的上市公司利润操纵识别*
合肥工业大学经济学院张本照郄亚美王海涛
利润操纵识别是企业各方利益相关者十分关注的一个问题。本文在考虑识别指标所含信息准确性和完备性的基础上,引入股权结构指标优化指标体系。同时由于现有模型将利润操纵行为人为地划分为{0,1},而利润操纵是盈余管理超过了一定范围的连续行为,本文运用层次聚类将利润操纵分为严重、轻微两种类型,对企业利润操纵行为的描述更加符合实际。最后,对层次聚类后的两组上市公司配对样本,运用Logistic模型分别进行识别分析,模型的识别率分别达到82.6%和90%,有效改善了传统识别模型。
股权结构 利润操纵 层次聚类分析 Logistic模型
一、引言
证券市场成立至今,国内外的利润操纵案件接连不断,严重影响了证券市场的健康发展。虽然我国对利润操纵行为加大了处罚力度同时也实行了更加严苛的审计程序,但利润操纵行为并没有明显减弱的趋势,反而是上市公司为了获取非法利益,使得利润操纵手段越来越复杂和隐蔽,外部信息使用者很难了解公司的真实经营状况。因此,对利润操纵行为识别的研究具有非常重要的意义。关于利润操纵的概念会计界存在两种观点:第一种观点是将利润操纵等同于西方会计文献中的盈余管理,即公司管理层为实现自身效用或公司市场价值最大化等目的进行会计政策选择,从而调节公司盈余的一种行为。第二种观点是将公司管理层出于某种动机,利用法规政策的空白或灵活性,甚至违法违规等各种手段对公司利润或获利能力进行操纵的行为称为利润操纵。结合Healy和Wahlen(1999)提出的盈余操纵是管理当局运用职业判断编制财务报告和通过规划交易以变更财务报告,旨在误导那些以公司经营业绩为基础的利益关系人的决策或影响那些以会计报告数字为基础的契约后果,本文拟采用第二种观点,即将利润操纵理解为为达到自身目的虚增利润的恶性行为。恶性的利润操纵行为严重影响财务报表的信息披露的真实性及资本市场的运行,而改进利润操纵识别模型有助于报表利益相关者更好的识别企业报表的真实性。本文研究的主要目的是建立相对简单的模型有效改善现有模型提高利润操纵识别率。
二、文献综述
(一)国外研究Scott L.Summers和John T.Sweeney (1998)利用内部交易活动作为模型识别指标,运用分层Logistic回归建立了内部人交易因素的识别模型,较早的建立了利润操作的识别模型,为利润操纵识别研究的发展奠定了基础。Charalambos T.Spathis(2002)利用单变量和多变量统计技术建立了包含Z计分值以及不包含Z计分值的模型来识别利润操纵行为,选取10个用来检验虚假报告的财务指标,用该模型检验了希腊上市公司的财务数据,达到了较高的准确率。Demski(2008)回顾了利润操纵的各种实证研究,研究了利润操纵的各种模型,利润操纵研究趋于定量化。前期的识别指标均局限于财务指标,但Igan和Pinheio(2010)对公司治理与利润操纵的关联性进行了研究,认为利润操作行为与企业管理人员的行为显著相关,应加强内部管理及内部审计委员会与外部审计师的监督。
(二)国内研究闫达伍、王建英(2001)利用选取的8个财务指标对样本进行配对检验,发现利润操纵公司普遍存在通过非营业活动、增加投资收益及采用关联交易来虚增利润的做法。李延喜、姚宏等(2006)设计17组会计指标,通过对利润操纵公司与其配对样本进行显著检验,构建指标的“安全区域”和“警戒区域”,初步建立了利润操纵识别模型,使得利润操纵由定性研究转为定量研究。姜金玲、李延喜(2008)运用Logistic回归模型构建上市公司利润操纵模型,这些模型的识别率均在70%-80%,识别率均不是很高。此外,部分学者也研究了非财务指标与利润操纵之间的关系,将影响因素进行了有效扩展、完善,有效提高了模型的识别率。林长泉、张跃进和李殿富(2000)从产权背景、会计准则因素以及外部审计监督等方面分析了国有股权背景下的利润操纵行为,揭示了股权背景对利润操纵的影响。郭太平、姜素萍和李明(2007)分析了上市公司利润操纵与股权结构的关系,得出利润操纵和公司股权结构存在显著的相关性。国有控股、第一大股东持股比例、第二大股东持股比例、第一大流通股股东持股比例和第二大流通股股东持股比例与利润操纵存在显著负相关关系。针对此前建立的基础识别模型,部分学者开始着手对利润操作识别模型进行改进。李双杰、陈星星(2013)利用粗糙集简化利润操纵的识别指标,通过蒙特卡洛模拟,提出基于BP神经网络的中国上市公司利润操纵的识别模型,进一步引入DEA效率指标,将非财务指标与财务指标相结合,有效提高了模型的判别率。梁鸿旭(2013)认为利润操纵是盈余管理超过了一定的范围所形成的连续行为,将模糊数学理论与线性规划有机结合,在一定程度上改善了将润操纵行为人的划分为{0,1}所带来的界限不清问题。
国外学者对于利润操纵行为的研究主要集中于利润操纵的原因、方法手段以及模型的建立和实证分析上。国内学者则集中于会计准则变化下利润操纵的原因、手段等理论研究,研究利润操纵识别的模型较少。且从现有文献来看,大部分学者的识别指标体系均局限于财务指标。但利润操纵企业与无利润操纵企业的股权结构存在显著差异,股东尤其是大股东对企业报表的真实性产生至关重要的影响,而且股权集中度对企业管理层产生的制约程度有一定差异,进而会对企业的利润操纵产生一定的影响,股权结构与利润操纵行为具有显著的关联性。同时,利润操纵是盈余管理超过了一定的范围所形成的连续行为,利润操纵行为的严重程度有较大的差异,简单的分为{0,1}使得分析结果不够严谨。因此,本文在前人研究的基础上改善现有模型,力求有效提升利润操纵行为的识别率。
三、研究设计
(一)样本选取与数据来源本文从CSMAR数据库的上市公司违法违规数据库中选取2000~2013年间有利润操纵行为的77家上市公司作为研究样本,并对样本进行筛选和配对。样本筛选原则为:金融业与其他行业经营差异较大,剔除金融业企业;由于对利润操纵行为的识别需要利用企业前期的指标数据,因此剔除三年内有连续舞弊的企业;剔除已经退市和数据严重缺失的企业。为了消除行业类型及会计政策差异等因素造成的影响,本文按照1:1的比例选取与利润操纵组相互匹配的对照组,配对原则如下:按照证监会行业分类,对照组与利润操纵组所属行业相同;对照组与利润操纵组总资产规模差距不超过20%;对照组经营状况正常,治理结构合理,上市信息披露及时;对照组在利润操纵组舞弊期间,没有受到证监会的违规处罚。经过筛选,最终剩余56家样本企业,剔除不能配对的3家公司,得到53组配对样本。
(二)利润操纵识别指标的选取徐浩萍(2005)认为控股股东为了保持上市公司的融资资格或是为了获取最大收益,会选择利润操纵,控股股东持股比例对利润操纵有一定的影响;于鹏(2007)研究得出分散化的股权结构以及国有股权对公司管理层的制约性相对较差,从而使得公司进行盈余操纵的可能性更大。因此,本文在已有研究的基础上,考虑识别指标所含信息的准确性和完备性,并综合考虑利润操纵的成因、手段、表现方式等因素引入股权结构指标优化了指标体系。本文选取了22个财务指标和6个体现股权结构的指标如表1所示。
四、实证结果与分析
(一)描述性统计本文最终选取了利润操纵组及对照组共106家上市公司的指标数据作为研究对象。搜集了这106家上市公司以利润操纵当年为时点的t-1、t-2、t-3三个时期的指标数据(由于上市公司被证监会披露为利润操纵企业的时点具有滞后性,部分上市公司的财务指标在披露的前三年便有利润操纵迹象)。同时对这三个时期的指标数据分别进行配对样本T检验与Wilcoxon符号秩检验,T检验与Wilcoxon符号秩检验结果(两个检验结果只需其中一个显著即可,由于篇幅所限,本文未将检验结果列出)显示,在0.05的显著水平下,选取的指标中X1、X2、X3、X4、X9、X10、X11、X13、X14、X15、X16、X17、X18、X19、X20共15个财务指标指标,X24、X25、X26、X274个股权结构指标在53组双样本中具有显著差异。确定显著性指标后,对选取的指标进行相关性分析。通过对各时期样本指标的相关性分析可知,去掉显著相关的变量X1、X4、X15、X16、X19、X20、X25、X26,其他变量在显著水平0.05下不相关。本文选取的识别指标如表2所示。

表1 利润操纵识别指标
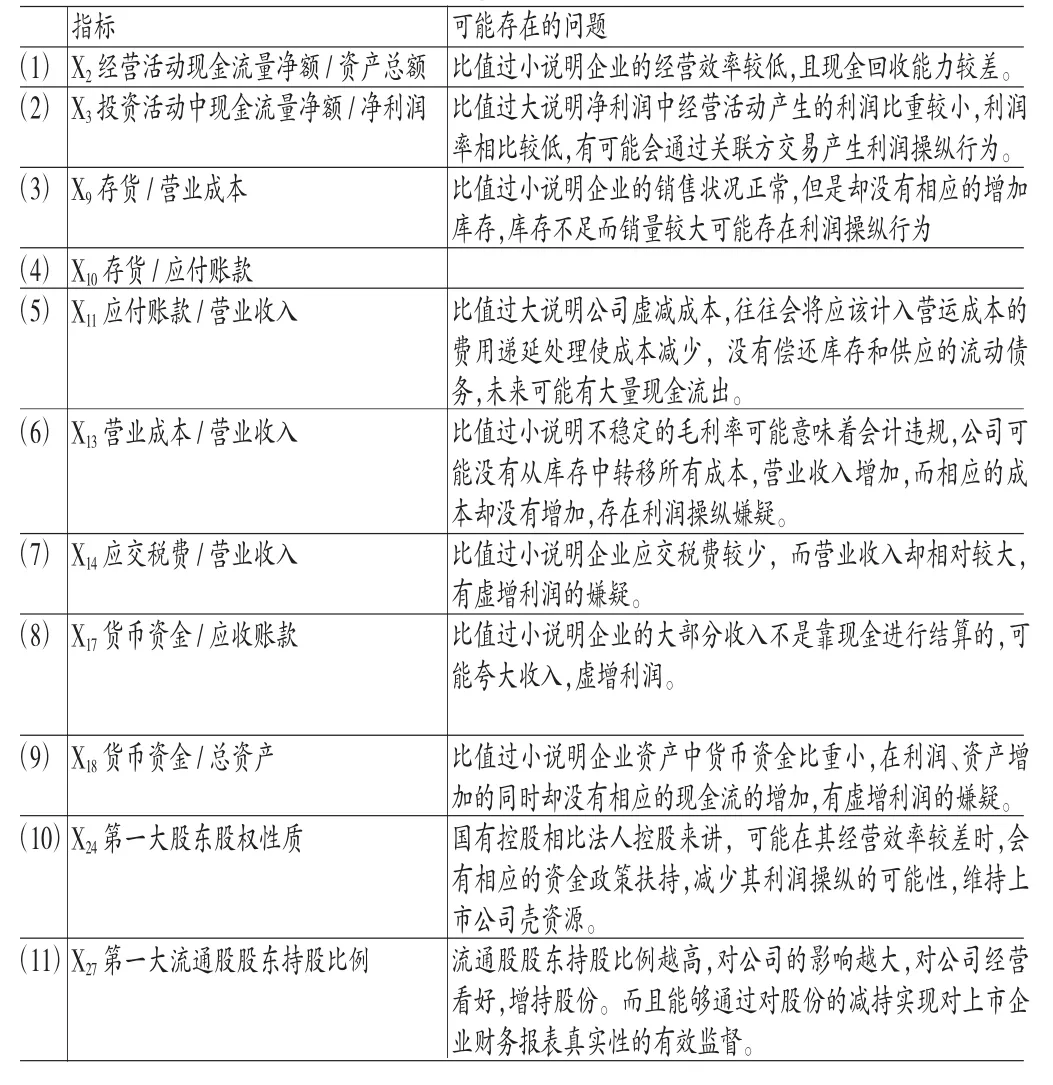
表2 显著的指标
(二)回归分析
(1)基于财务指标的Logistic实证结果。Logistic回归是处理定性因变量的常用统计分析方法,相比于多元回归分析,其不要求变量服从正态分布,因此模型相对稳健。本文将利润操纵行为作为虚拟变量引入模型,其中有利润操纵行为的取值为1,无利润操作行为的取值为0,运用SPSS17.0统计分析软件将上述配对检验中的9个显著的财务指标及相应的样本数据带入Logistic回归模型,预测结果如表3所示。由表3可知,共106个样本,其中有利润操纵行为的上市公司与无利润操纵行为的上市公司各53家,模型能正确识别的上市公司为78家,模型的正判率为73.6%,超过了70%。因此,本文构建的上市公司利润操纵模型具有较好的预测效果。但模型整体的识别率不高,后文将进一步完善。

表3 Logistic回归模型的预测结果
(2)加入股权指标后Logistic实证结果。将上述配对样本检验中的9个显著的财务指标和2个显著的股权指标及相应的样本数据带入Logistic回归模型,估计及预测结果如表4和表5所示。
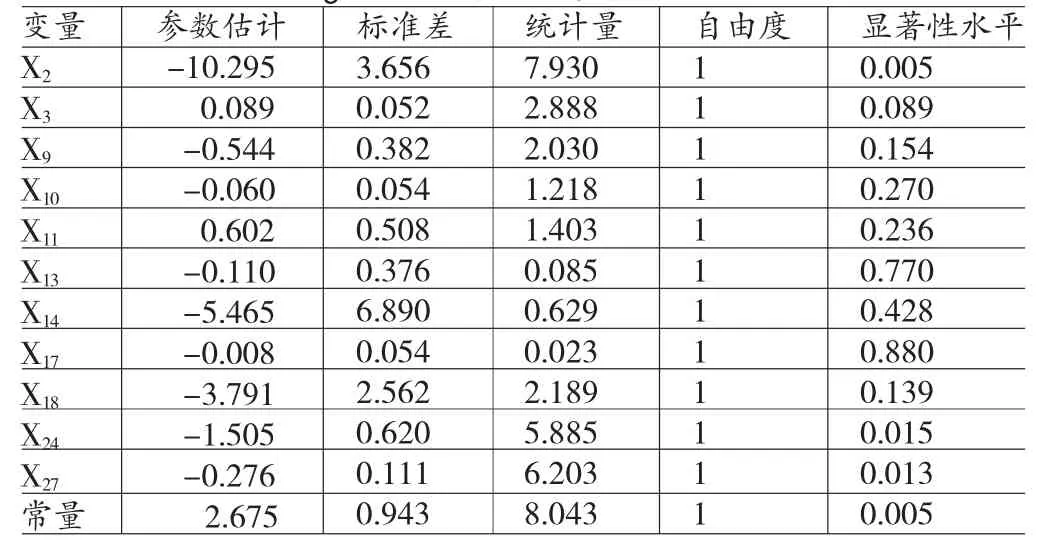
表4 Logistic模型估计及检验结果
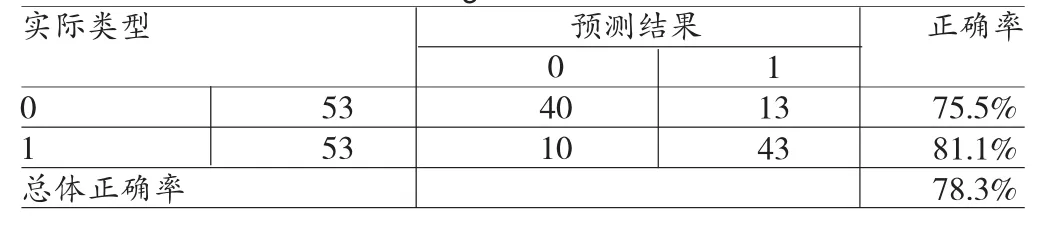
表5 加入股权指标的Logistic回归模型的预测结果
由表5可知,加入股权结构指标后,模型对于无利润操纵公司的识别的正确率提高到75.5%,对利润操纵公司的识别正确率提高到81.1%,总体的正判率有一定程度的改善,达到78.3%。这表明股权结构指标对于识别利润操纵行为十分有效。更为详细地,本文对两个体现股权结构的指标呈现出的显著性作出如下解释:第一,第一大股东股权性质对利润操纵行为影响显著。可以解释为第一大股东为国有背景时,相关政府部门能为企业投入资金、政策支持,能够更加有效地改善企业自身的经营,而且国有产权背景的上市公司的上市盈利压力相对较小,且公司管理效率较低,对利润操纵的能力有所欠缺,一定程度上反而能够维护报表利益相关者的切身利益,能有效抑制利润操纵行为。相比而言,民营企业大股东为改善公司形象、获取非法利益、避免行政处罚,会选择进行利润操纵。第二,第一大流通股东持股比例与利润操纵之间呈现显著的负相关关系。流通股股东大部分为自然人股东,其持股比例越高,表明其对公司的经营状况看好,不会短期抛售股票,公司盈利能力相对较强,同时反过来能够加强对上市公司的监督,能有效抑制利润操纵对自身带来的巨额损失。
(三)层次聚类分析现有的利润操纵行为识别模型均将利润操纵行为分为有利润操纵行为和无利润操纵行为,对结果进行了离散化处理。而实际上利润操纵是盈余管理超过了一定的范围,是操纵程度上的连续行为,利润操纵有程度上的差异,有些操作行为可能非常轻微,有些可能非常严重。梁红旭(2013)通过将模糊数学的相关理论与线性规划结合建立一个全新的利润操纵模型,该模型在一定程度上克服了将利润操纵行为人为的划分为{0,1}所带来的界限不清问题。上述利润操纵模型在一定程度上能够识别利润操纵行为,但整体识别正确率不高,主要是因为利润操纵企业舞弊程度、舞弊手法具有一定的差异,笼统的将所有样本分为一类,可能会影响识别的准确性。层次聚类分析是对样品或指标进行分类的一种多元统计分析方法,其讨论的对象是大量的样品,要求能合理地按各自的特性将数据分类到不同的类或者簇,同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。鲍新中(2013)通过层次聚类方法将财务状况分为5类,更符合实际状况,同时验证了该方法的有效性。
上述模型中显著的指标对具有严重利润操纵行为的识别效果较好,但对某些利润操纵手段复杂或行为轻微的企业却无法有效识别。为了有效克服将利润操纵行为人为的划分为{0,1}所带来的界限不清问题。本文利用表4中回归显著的指标X2、X3、X24、X27对初始样本进行层次聚类分析。层次聚类划分为两层,识别率较高的43家样本划分为一层,即大样本组;识别率低的10家企业划分为一层,称为小样本组。对两个样本组数据指标重新进行配对检验。
(1)大样本组利润操纵识别。对大样本组中的43家样本中各个指标重新进行配对样本T检验与Wilcoxon秩检验,结果显示,X2、X3、X9、X10、X11、X13、X14、X17、X18、X24、X27在0.05的显著水平下具有显著差异,对这11个指标进行相关性检验,剔除相关性水平较高的变量X9,余下的变量在显著水平0.05下不相关。对不相关的变量运用Logistic模型进行回归,结果如表6所示。由表6可知,检验的样本共有86个,采用层次聚类后的Logistic模型回归,模型能正确识别出的上市公司数量为71个,模型的总体正判率达到82.6%。相比前文的模型,该模型在去除舞弊轻微或操纵手法高明的企业后,识别率提高,进一步验证层次聚类的有效性,需要对剩余的样本进行单独识别。
(2)小样本组利润操纵识别。对该样本组中的10家企业的指标数据单独进行配对样本T检验与Wilcoxon符号秩检验,由于其自身利润操纵行为程度较为轻微或是手段越来越复杂、高明,其与正常的配对企业之间的显著性差异不大,结果显示在显著水平0.1下,X1、X2、X4、X6、X11、X14、X15、X19、X20、X21具有显著差异,而对于股权结构来说却没有明显的差异,由于该组样本量较小,本文运用Logistic回归模型时,采用Forward:Wald变量进入方法,可以在一定程度上自动克服变量之间共线性问题,其中变量进入标准是:P≤0.05进入,p≥0.1移出。模型预测结果如表7所示。检验的样本共有20个,采用层次聚类后的Logistic回归模型,模型能正确识别的上市公司数量为18个,模型的总体正判率达到了90%。
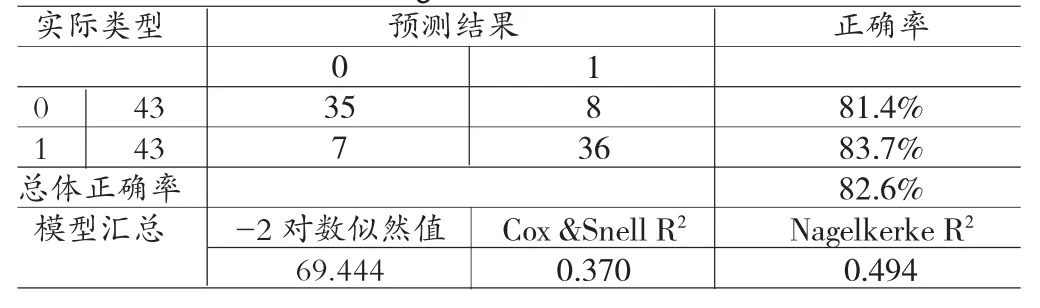
表6 层次聚类后的Logistic模型预测结果(大样本组)
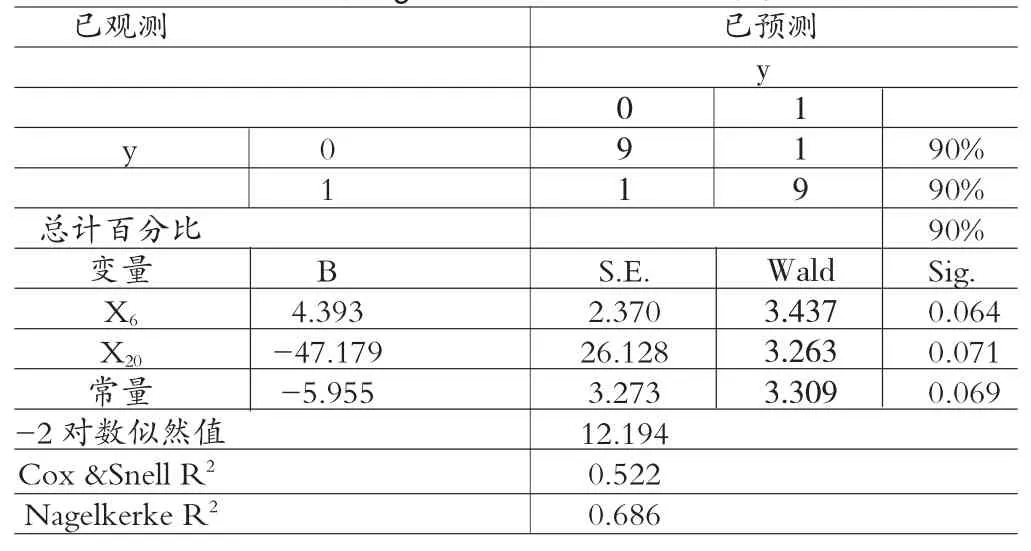
表7 层次聚类后的Logistic模型预测结果(小样本组)
对于两个利润操纵程度不同的样本组,层次聚类后识别率显著提高,说明利润操纵公司的严重程度有一定的差异,且部分上市公司手段越来越高明,针对不同的利润操纵程度及手段,研究者应运用不同的方法来识别,对于一些利润操纵程度较轻,手段隐晦且与正常公司在财务指标与股权结构指标无较大差异的公司,传统的识别指标无法进行有效识别进行识别,对这类配对样本组重新进行显著性检验后,从回归结果中可以看出,主要通过X6经营活动中产生的现金流出小计/营业成本、X20息税前利润/平均总资产两个指标来识别。X6值越大,利润操纵的可能性越大,即所有的营业成本支出中用经营活动现金支付的比例较大,企业经营能力较差,现金流动水平较低,企业进行利润操纵的可能性越大。X20值越小,表明企业的投入产出水平较差经营效率较低,企业进行利润操纵的动机越强。对于这类利润操纵公司而言,其股权结构不存在显著的差异,且较难通过利用某些操纵手段修改数据形成的异常指标来进行识别,这类企业的一般财务指标较正常但是企业经营效率指标却相对较差,可结合其他因素增强对该类利润操纵企业的识别。
五、结论
上市公司的利润操纵行为严重损害了广大的利益相关者的权益,严重影响证券市场的良好的运行,随着中国证券市场的繁荣发展,市场规范与监管力度逐渐加大。建立高效、简洁的利润操纵识别模型是亟待解决的问题。本文研究发现上市公司利润操纵程度、造假手段具有显著差异,实际上利润操纵行为是盈余管理超过了一定的范围,是操纵程度上的连续行为。因此本文通过运用层次聚类方法,对不同程度的利润操纵上市公司分别进行识别,有效改善了笼统识别的弊端,对不同利润操纵程度上市公司运用不同的识别指标,对于两组样本的识别率分别达到了82.6%、90%,大大提升了模型的识别准确率。
层次聚类后的模型利润操纵公司识别正确率提高,主要是由于某些公司利润操纵程度比较微弱或是手段比较隐蔽,与正常经营的企业进行一定幅度的盈余管理水平相差不多,降低了对操纵企业的有效识别。层次聚类后,针对不同的类别,运用不同的指标,能够更加切实准确的识别。
*本文系中央高校基本科研业务费专项(项目编号:2013HGXJ0264)阶段性研究成果。
[1]阎达五、王建英:《上市公司利润操纵行为的财务指标特征研究,《财务与会计》2001年第10期。
[2]李延喜、姚宏、高锐:《上市公司利润操纵行为识别模型研究》,《管理评论》2006年第1期。
[3]姜金玲、李延喜、高锐:《基于Logistic的上市公司利润操纵行为识别模型研究》,《经济管理》2008年第9期。
[4]林长泉、张跃进、李殿富:《我国国有企业及上市公司的利润操纵行为分析》,《管理世界》2000年第3期。
[5]郭太平、姜素萍、李明:《上市公司利润操纵与股权结构关系探讨—基于我国制造业的分析》,《证券经纬》2008年第3期。
[6]徐浩萍:《控制股东利润操纵的动机及其监管研究》,《财经研究》2005年第2期。
[7]Healy M,Wahlen M.A Reviewof the Earnings ManagementLiteratureandItsImplicationsforStandard Settings.Accounting Horizons,1999.
[8]Charalambos T.Spathis.Detecting False Financial Statements Using Published Data:Some Evidence from Greece. Auditing Journal,2002.
[9]Igan D,Pinheiro M.Incentive to Manipulate Earings and its Connection to Analysts'forecasts,Trading and Corporate Governance.Journal of Economics and Finance,2010.
(编辑朱珊珊)
