基于市场情绪挖掘的PSM_Black_Litterman资产配置模型
2016-09-10朱碧颖赵爽
朱碧颖 赵爽

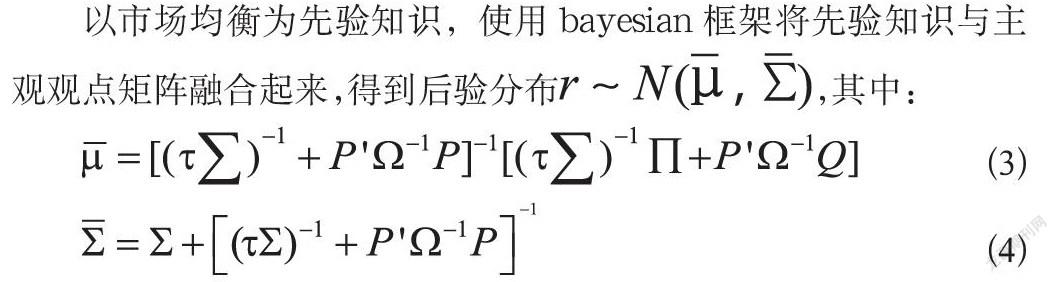



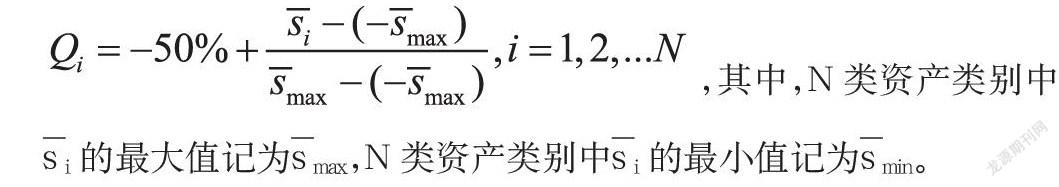
【摘要】投资中自上而下的分析方式是被广泛认可的,资产在行业间的配置问题,对整体投资效果的影响举足轻重。Black_Litterman模型改进于传统的Markowitz模型,自提出后逐渐为人们所接受,并得到推广。本文结合计算机技术,提出一种基于文本挖掘算法,使用网络爬虫抓取互联网中行业热点情绪,形成Black_Litterman模型的投资者观点矩阵、以及观点置信度,进而确定行业资产配置权重的PSM_Black_Litterman(public sentiment mining Black_Litterman)模型。进行实证分析,以申万行业作为行业分类标准,进行资产行业间配置,与流通市值行业配置、传统Markowitz模型资产配置进行比较。实证结果表明,本文所提模型可有效提高资产配置的平均收益率与几何收益率,并减小方差。
【关键词】资产配置 Black_Litterman模型 文本挖掘 市场情绪 网络爬虫
在选择金融产品进行投资时,普遍采用自上而下(Top-to- Down)的研究方式。在选股方面,首先确定资产在行业间的配置比例,再在各行业中进行个股选择是常用的方式。本文旨在Markowita模型、Black_Litterman模型的基础上,提出一种利用文本挖掘方法挖掘舆论热点,得到市场情绪作为观点矩阵,继而得到资产在行业间的配置方案的方法。克服了Black_Litterman模型存在的对分析师主观态度难于量化表示的缺点。
一、Markowitz与Black_Litterman资产配置模型
(一)Markowitz资产配置模型
Markowitz在1952年发表论文《PORTFOLIO SELECTION》,在论文中提出了均值-方差模型,这篇论文标志着现代投资组合理论的开端。Markowitz理论的思想基础是:把资产投资收益率看做随机变量,研究其期望与方差。Markowitz资产配置模型基于五条假设:证券市场具有有效性;投资者是风险厌恶的;投资者进行资产配置选择的依据是投资收益率的概率分布,而这个概率分布是可知的;用期望收益率衡量未来的收益水平,用方差衡量收益的不确定性,即收益的风险;市场是无摩擦的。
设市场存在n种风险资产,将第i种风险资产的的收益率记为ri,r=(r1,r2,…,rn)’,期望收益率记为μ=Er,资产间的协方差矩阵记为Σ,Σ=Var(r),无风险收益率记为rf,n种风险资产的投资比例为ω=(ω1,ω2,…,ωn)’。那么资产组合的期望收益率为μω=ω’μ,资产组合的风险为σ2ω=ω’Σω。
那么,当资产组合中仅存在风险资产时,均值-方差模型记为:
当资产组合中可以存在无风险资产时,均值-方差模型记为:
使用拉格朗日乘数法则,可直接求得上述均值-方差模型的最优解。投资者可以依据个人偏好的无差异曲线找到对应的最优组合。此模型同时表明,最优组合的选择往往并非单独取决于单个资产的数字特征,同时也取决于资产间的相关性。
Markowitz资产配置模型是在一系列严格的假定条件下推导出来的。因此,模型从面世之日起,众多学者便提出由于模型的假定条件与实际金融环境存在差异,导致构建的投资组合存在难以理解、对输入的参数过于敏感、以及估计误差被放大等问题。
(二)Black_Litterman资产配置模型
在高盛银行任职的Fischer Black和Robert Litterman于1990年提出了Black_Litterman模型,于1992年又在《金融分析》期刊上对Black-Litterman模型作了详细说明。他们将Markowitz的均值-方差模型最优化理论和bayesian估计相结合,并且基于资本资产定价模型(Capital Asset Pricing Model,CAPM)以及夏普提出的逆最优化理论建立了Black_Litterman资产配置模型。在国外理论界,Bevan和Winkelmann,He、Litterman,Satchell和Scowcroft、Drobetz都对Black-Litterman模型做了进一步的完善,并对国际资产配置做了实证分析。在实际投资运作中,很多大型投资机构将Black-Litterman模型运用在全球资产配置中,并已取得了丰厚收益。
Markowitz的均值-方差模型模型的主要投入要素为预期报酬率及方差。投资者必须利用长期的历史资料,提出对投资组合所有的预期报酬率的看法,而这些看法皆为100%的信心水准,Black和Littermam认为投资者的看法在实际情况下,很难达到完全预测正确。在Black-Litterman资产配置模型中,投资者可以将自己的观点和对这种观点的信心程度量化并输入模型中。
Black-Litterman资产配置模型的另一大优点在于它的输入是非常具有弹性的。投资者可以输入对某些资产预期收益的一种观点或者几种观点,也可以不输入任何观点。这样就减少了投资人观点设定的随意性。需要指出的是,因为模型加入了主观观念,使模型的估计变得相对复杂。这也成为现阶段该模型研究的主要方向。
以市场均衡为先验知识,使用bayesian框架将先验知识与主观观点矩阵融合起来,得到后验分布,其中:
其中,τ表示的是资本资产模型的不确定性度量,当τ趋近于0时,Black-Litterman计算出的权重将趋近于市场均衡权重;Σ代表各资产超额收益的协方差矩阵;Π表示隐含均衡收益向量,Π=δΣωeq,δ为风险规避系数,ωeq为市场基准配置权重向量。P是一个K×N维矩阵,每一行代表投资者的一个观点对应的相关资产的权重,相对观点的权重和为0,绝对观点的权重和为1;Q是一个K×1维向量,分别对应于P矩阵中的每个观点的期望收益;Ω是一个K×K维对角矩阵,表示投资者对每个观点的信心程度。
举一个简单的例子,一个投资者对三个资产的主观观点是:资产1的收益率被高估了2%,资产2的收益率会比资产3的收益率低3%,他对自己这两个观点的信心程度分别是w11和w22。那么,对应的P、Q、Ω分别为:
运用Black-Litterman资产配置模型,投资者可以输入关于任何投资类别的任意数量的观点,并与市场均衡状态相结合,输出最优投资组合权重和预期收益。
本文致力于寻求一种更具普适性的,更易于量化的得到投资人观点矩阵(即得到P、Q、Ω)的方法,即基于网络文本挖掘的市场情绪度量方法。
二、基于网络爬虫的文本挖掘算法
本章阐述基于网络爬虫技术得到传统Black_Litterman资产配置模型观点矩阵以及置信度矩阵的方法。
(一)数据源的选择
本文旨在使用网络上的市场情绪作为分析依据,得到Black_ Litterman模型观点矩阵以及置信度矩阵。那么必然对要分析的新闻文本具有一定要求,需要慎重选择文本来源。文本来源选择的是否适当,将直接关系到black_litterman模型的输入,进而左右模型整体效果。数据源的选择既要符合文本挖掘技术数据源的一般性要求,也要符合金融新闻类市场情绪文本的特殊性要求。笔者认为,至少需要具有全面行、权威行、和实效性。全面性保证得到的市场情绪可以代表多数人的观点,减小偏差;权威性保证观点来源于金融专业知识相对完备、经验相对丰富的分析师,而且他们的观点将会通过多种途径传播,进而影响大众观点,成为大众情绪;实效性保证情绪文本的及时性,减少滞后偏差。
鉴于此,本文选择“搜狐证券—研究报告—行业研究”(网址:http://stock.sohu.com/hyyj/) 中的新闻标题短文本作为研究对象。它来源于各知名券商研究报告或者权威报刊,根据行业分类进行过整理,新闻标题短文本后给出了新闻发布时间,符合全面行、权威行、和实效性准则。
(二)网络爬虫获取文本
已经选定数据源,接下来使用网络爬虫技术抓取网页上的新闻标题短文本。网络爬虫(Network Spider),是一种按照预先给定的规则,在运行中自动地抓取万维网信息的程序或者脚本。它将一个网页URL作为起始,读取此页面内容,并通过此页面上的超级链接作为线索找到另一个或多个与之有关联的网页。重复此操作,遍历网络页面,依次将其文本和URL存入到网页数据库中。
爬虫基本工作流程如下:
Step1.选取种子URL;
Step2.将这些URL放入待抓取URL队列;
Step3.将URL队列中对应的网页内容抓取下来,存储到已抓取网页库中,并将这些URL放到已抓取URL队列中;
Step4.对已经抓取到的URL队列中的URL进行分析,试图从中分析出待抽取的新URL,将这些URL放入待抓取的URL队列,从而进入下一次循环。
使用网络爬虫技术,以网址:http://stock.sohu.com/hyyj/ 作为起始URL,抓取此URL对应页面的HTML文本,存入文本文件中。其中除所需新闻短文本标题外,还包含了大量的HTML标记,以及非新闻标题短文本以外的文字类信息,需要将其过滤掉。使用XPath与正则表达式技术,通过分析DOM结构,使用正则表达式定位到具体位置。
(三)中文分词
通过网络爬虫抓取得到待处理文本之后,需要对其进行中文分词。中文分词包括三类算法:基于字符串匹配的分词;基于理解的分词;基于统计的分词。将一个中文句子进行拆分,从一个句子中解析出名词、动词、形容词、副词等。这样做的目的是:拆分出的名词部分,可作为本条文本的对象词,匹配数据库中的申万行业类别表,从而得到这条文本是描述的哪个行业的市场情绪的;拆分出的形容词(副词)部分,可作为本条文本的情绪词,匹配数据库中的通过调研得到的情感极性词极性表,从而得到这条文本是正面情绪还是负面情绪,以及情绪的强弱程度。
本文使用中科天玑的ICTCLAS词法分析系统,由张华平博士历经多年开发研制,开源,并提供了多种开发语言接口,包括C/C++/C#、Java、Python、Hadoop等,可以用于对需要进行分析处理的文本做初始分词。具体算法分为三个步骤,即原子切分;找出所有可能的原子间组词方案;N-最短路径选择算法。各步骤的具体算法在ICTCLAS词法分析系统主页http://ictclas.nlpir.org/ docs可以得到。
例如,将“房地产业:房产税谣言四起,楼市温和上行”进行分词,效果如图1所示。
将结果匹配数据库中的申万行业表和情感极性表。以“房地产业:房产税谣言四起,楼市温和上行”为例:得到这条文本是表述“房地产”行业市场情绪的;“谣言”是负极性词,极性强度是-1,“上”是正极性词,情感极性是+2,故而这条文本的综合情感是正极性的,综合情感极性是+1。
由于中文反义句多以“反义词+形容词(副词)”的形式出现,需设计否定词处理模块,当遇到否定词(如“不”,“没”,“别”,“非”,“无”,“未”,“反”等)时,这个否定词的作用对象取它后面最邻近的一个情感极性词,将其极性取反处理。
(四)构建观点矩阵及观点置信度矩阵
以上是为了得到Black-Litterman资产配置模型中的P、Q、Ω,其中P代表了观点与观点对应资产的匹配关系,分为绝对收益和相对收益两种、Q代表了对应于P矩阵中的每个观点的期望收益、Ω代表了对每个观点的信心程度。
至此,得到了Black-Litterman资产配置模型的输入矩阵P、Q、Ω。
三、实证研究
在国内A股申万一级行业间使用本文所提PSM_Black_Litterman模型进行实证分析。设两组对照,以市值为权重进行资产配置;使用传统Markowitz资产配置模型得到的权重进行资产配置。
(一)数据
从申万一级行业28个分类中,选择相关系数较小的13个行业;选择自2010年2月至2015年1月61个月的行业指数数据,以及各行业类别中所含流通股市值,数据来源东方财富Choice数据。这样共13*61个样本内数据。样本外取自2015年2月至2015年12月进行实证分析。
(二)市场情绪P、Q、Ω
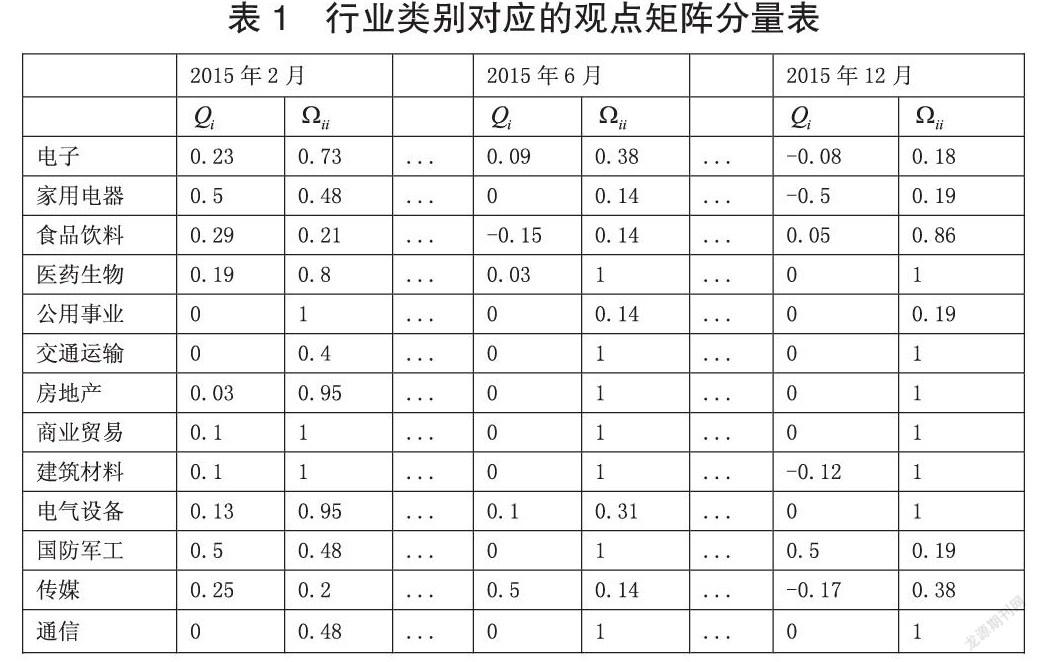
在本文应用背景下的P为N×N单位矩阵,可不再做计算;Q为N×1维向量,设第i种行业类别对应的分量为Qi,Ω为N×N维对角矩阵,设第i种行业类别对应的分量为Ωii。当月数据由上月数据计算得到,见表1。
(三)PSM_Black_Litterman模型效果分析
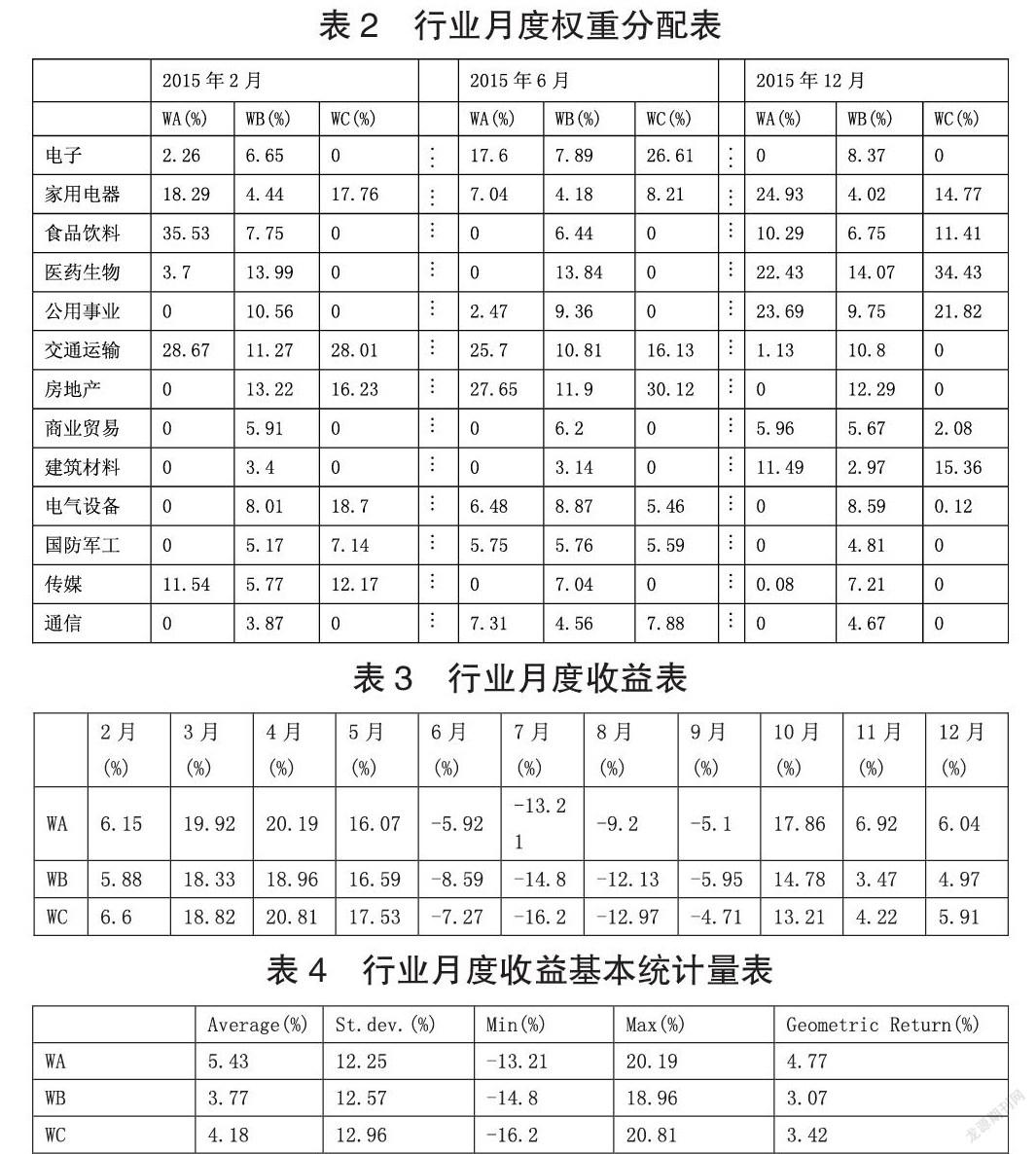
使用上一小节得到的P、Q、Ω矩阵数据,计算各行业类别的最优资本权重,即由PSM_Black_Litterman模型得到的资本权重,记为WA;另外,由流通市值计算而得的权重记为WB;由Markowitz资产配置模型计算而得的权重记为WC。并计算当按照这样的权重进行投资时的组合月度收益率。当月权重由上月数据计算得到。增加不许做空限制。见表2。
根据三种方式得到的行业配置权重WA、WB、WC,计算2015年2月至2015年12月,共计11个月各自收益情况如下表所示。见表3和表4。
可见,使用由Markowitz资产配置模型计算得到的权重WC为依据进行行业配置,在收益率均值、几何收益率角度,优于由流通市值计算而得的权重WB为依据进行的资产配置;但方差效果却劣于它。而使用本文所提PSM_Black_Litterman模型,利用由网络热点新闻作为权重调节方式得到的权重WA进行资产配置,其收益率均值、方差、几何收益率均优于传统Markowitz模型,同时优于由流通市值计算而得的权重WB为依据进行的资产配置。
四、结论
Black_Litterman模型的关键问题之一是需要输入分析师观点,本文通过网络爬虫技术,抓取门户网站内的相关行业情绪,使用文本挖掘技术,提出一种将市场情绪量化为Black_Litterman模型所需P、Q、Ω矩阵的方法,由此提出一种PSM_Black_Litterman(public sentiment mining Black_Litterman)模型。通过实证分析,该模型可有效提高资产配置的平均收益率与几何收益率,并减小方差。在后续的研究中,笔者希望通过过滤无效新闻、扩充情感词库等方法,致力于进一步提高模型效果。
参考文献
[1]H.Markowitz.1952.PORTFOLIO SELECTION[J].JOURNAL OF FINANCE,7(1):77-91.
[2]温琪.金融市场资产选择与配置策略研究[D].中国科学技术大学,2011.
[3]南方基金管理有限公司 柯晓.Black-Litterman模型的初步介绍及应用[N].上海证券报,2008-12-10007.
[4]E.C.B.Bekaert G,Harvey C R,et.1998.al.Distributional characteristics of emerging market returns and asset allocation[J].Journal Portfolio Management,24(2):102-116.
[5]S.S.S.A.2000.demystification of the Black-Litterman model:managing quantitative and traditional construction[J].Journal of Asset management,1(2):138-150.
[6]D.W.2001.How to avoid pitfalls in portfolio optimization?putting the Black-Litterman approach at work[J].Financial Markets Portfolio Managemen,15(1):59-75.
[7]韩正宇.现代投资组合理论述评[J].经济研究参考,2013,60:53-61.
[8]孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术,2010,15:4112-4115.
[9]王强,武港山.对XPath模式定位能力的扩充[J].计算机研究与发展,2001,06:674-678.
[10]周程远.中文自动分词系统的研究与实现[D].华东师范大学,2010.
[11]张华平,刘群.基于N-最短路径方法的中文词语粗分模型[J].中文信息学报,2002,05:1-7.
[12]李存青.中文意见挖掘中的特征词提取以及情感倾向分析[D].重庆大学,2010.
作者简介:朱碧颖(1990-),女,汉,北京,硕士研究生,研究方向:文本挖掘,资产配置;赵爽(1990-),男,汉,北京,硕士研究生,主要研究方向:宏观经济、计量经济。
