基于MapReduce的海量文件检索方法研究
2016-09-02谭黔林莫春娟
谭黔林, 莫春娟
(河池学院 计算机与信息工程学院, 广西 宜州 546300)
基于MapReduce的海量文件检索方法研究
谭黔林, 莫春娟
(河池学院计算机与信息工程学院, 广西宜州546300)
在文件检索的方法中,目前主要是基于数据库进行检索。但是,当待检索的数据量变得非常大的时候,再使用这种检索方式,大量的检索操作就会集中在一台主机上进行,这会导致检索效率降低。基于这种情况,拟采用分布式系统来解决这个问题。在分布式系统中进行资源检索时,可以基于MapReduce架构来实现检索,这样,检索操作的压力将分散到分布式系统的各个节点中,这样可以有效降低机器的压力,大大提高检索的效率。采用传统方式检索100万条数据,需要耗时500 s,而采用基于MapReduce架构的分布式系统的方法来检索100万的数据,只需要花费40 s,相对于传统检索方法采用基于MapReduce架构的分布式系统检索可使检索效率提升接近12.5倍。
大数据;MapReduce;检索;分布式系统
0 引言
大规模数据如果集中在一台机器上进行检索,其检索速度将十分缓慢,如何解决这个问题至关重要。目前很多文件检索的方式都是基于数据库系统进行[1],当数据量较大的时候,检索的效率将会变得相当低,因此,海量数据背景下,研究一种大规模数据集下的检索方式至关重要。
1 基于MapReduce的系统设计
1.1MapReduce的概述
MapReduce定义为一种编程模型,用于大规模数据集的并行运算[2]。在对分布式并行编程不熟悉的情况下,Mapreduce极大地方便了编程人员将程序在分布式系统上运行。
1.2MapReduce架构应用
J.Dean和S.Ghemawat在“MapReduce:Simplied Data Processing on Large Clusters”一文中讲述了MapReduce框架的具体实现[3]。Hadoop主要为MapReduce提供了数据存储以及计算的环境。
要提高分布式系统中文件检索的效率,就要实现在分布式系统中,各个节点对数据流的并行处理,在MapReduce框架中可以用Map来实现在分布式系统中各个节点的并行处理。Map阶段中,用户向系统提交请求,jobtracker主线程接收这些请求,之后对数据集进行划分,使每个分片都能并行运行。Map接到指令后将分片分解为键值对(key-value),并会根据定义的Map函数对这些键值对进行处理,之后生成相对应的中间结果,并将这些中间结果进行分区和排序。
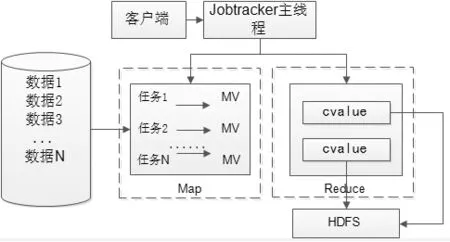
图1 MapReduce处理过程
实现了分布式系统中各个节点的并行处理后, 还应当把分布式系统各个节点中处理的数据汇总到一起,汇总的过程可以用Reduce实现,将这些处理过的中间结果传递给Reduce进行再次处理[4-7]。在Reduce阶段中,Reduce会接收到归档后的中间键值对,并根据这些接收到的数据进行相关计算,最后得到计算结果终键值对(ckey-cvalue),过程如图1所示。
利用MapReduce框架,可以实现分布式系统中各节点的并行处理,这样可以提高分布式系统资源检索的效率。
上述过程用代码表示如下:
Map阶段:(key,value)-->list(mkey,mvalue)
Reduce阶段:(mkey,list(mvalue))-->list(ckey,cvalue)
1.3文件资源系统
在分布式系统中最常用的是Hadoop分布式文件系统,即HDFS文件系统,Reduce部分的计算结果Cvalue最终存储在HDFS中,如图1所示。
HDFS文件系统的特点[8]主要有以下几个方面:
(1)处理超大文件;
(2)运行于廉价机器上;
(3)流式数据访问。
2 基于MapReduce的海量文件检索方法的实现
2.1文件检索相似度的计算
检索时,首先需要进行检索词与索引数据库词相似度的计算。在计算相似度的过程中,需要根据待搜索的关键字与文件资源的文件名特征和内容特征的相近程度进行相应的计算,同时还要考虑待搜索关键字的同义词、文件资源库里文件名特征和文件内容特征。
特征提取过程即根据对应特征的定义去计算该文本的特征值,比如,统计某个词出现多少次,然后按照以下提及的特征值公式并以算术方法去计算。
假设需要检索的文件为file0,在整个文件库中,有若干的文件,这些文件可以表示为file[n],n为文件库中文件的总数量。
如果要对文件库中的某一个文件file[x]进行特征提取,则需要进行四类特征提取:文件名特征、文件内容特征、检索同义词文件名特征、检索同义词内容特征。假设文件名特征用FM表示,文件内容特征用FC表示,检索词同义词文件名特征用CFM表示,检索词同义词内容特征用CFC表示,最后根据查询、分析原理对文件的四类特征进行提取[10]。
待检索关键词与文件名的相似程度,用该关键词在文件名中出现的次数按比例进行计算,该特征可用关键字在文件名中出现的字数总和除以文件名字数总和进行计算。例如,需要检索的关键词是“心理”,检索库中存在文件名是“心理学心理书”的文件,那么待检索的关键词与该文件的相似程度为4/6,该相似程度即为文件名特征。假设关键词在文件名中出现的字数总和是Kall,而文件名字数总和是FNall,那么有如下公式:
FM=Kall/FNall
(1)
根据2IDF算法中,关键词的出现次数与文章字数权重关系,在文本特征提取过程中,通过关键词在文本中出现的次数与文本字数之间的比例关系来确定。比如,假设 需要检索的关键字是“心理”,检索库中某一文件内容为“一个人的心理,如果每一颗心都是有是好的,那么,心理学也不错”,那么检索关键词与文件内容的相似程度就是2/26,即“心理”这个关键词在内容中出现了两次,而内容总字数为26字。假设关键词在内容中出现的总次数用Ktall表示,文章内容的总字数用Fcall表示,那么有如下公式:
Fc=Ktall/Fcall
(2)
接下来 将讨论待检关键词的同义词的相关特征计算。文件检索过程中,检索与一个关键词相关的文件,不仅要考虑该关键词,还要考虑该关键词的同义词,比如 “心理”,那么其关联词可能是“心理学”、“心理健康”、“心理咨询”等。所以,在计算同义词特征时,需要依次计算关键词的每个同义词。
假设待选关键词的同义词个数一共有n个,同义词i(1≤i≤n)字数是Call,同义词i在文件内容中出现的次数是Ctall次,那么将有如下公式:
(3)
(4)
以上(1)~(4)式是计算文件库中的每个文件与检索词相似的特征的计算方法。
计算出各文件的特征值之后,需要综合计算出某个文件与待检索关键词的相关性,相关性的计算方式如下:
Sim=FM*w1+Fc*w2+CFM*w3+CFC*w4
(5)
其中,w1+w2+w3+w4=1,w1,w2,w3,w4分别为文件名特征、文件内容特征、检索词同义词文件名特征、检索词同义词内容特征的权重值。最终由公式(5)对每个文件求得一个值,该值是该文件与待检索关键词的相关性,由此,可以按数字从大到小对文件进行排序即得到按相关性从大到小进行排序的文件。
2.2Map与Reduce算法
在MapReduce核心是Map和Reduce算法,其算法描述过程如下。
Map算法,首先,读取需要检索的关键词及读取文件库中某文件的数据;其次,获取文件库中现在读取的文件的地址,如果满足检索条件,则比较关键词与文件名的相似度、比较关键字与文件内容的相似度、比较关键词同义词与文件名的相似度、比较关键词同义词与文件内容的相似度,随后,综合四种特征计算总相似度;最后,提交相似度与文件地址。
Reduce算法,首先对各文件按相似度从大到小进行排序,然后提交经过排序后的文件相似度和文件地址。
在MapReduce架构中,Map算法主要执行待检文本的关键词提取,计算文本数与待检索关键词的特征向量,得出向量指标后,根据每项特征的权重指标,用各项特征乘以对应的权重再相加,再将该文件的综合相似度指标提交给Reduce进行化简操作。
2.3匹配
上面的论述中,分析了检索的原理以及Map和Reduce实现的过程,但没有具体涉及匹配的过程,本节将会具体阐述匹配的各项过程与任务,具体的实现过程如下。
(1)检索请求的提交阶段:匹配过程中,首先需要进行检索请求的提交,即用户提交检索请求的过程,检索请求提交标志着任务的开始,是进行匹配步骤的第一阶段,完成后方可执行后续阶段。
(2)作业分配阶段:系统收到请求后,由JobTracker执行。JobTracker执行各项任务的分配,将检索任务合理地分配到各个节点之上,为各节点之间的并行运行提供了基础。
(3)Map阶段:分配任务之后,会调度各项Map任务并行处理,Map任务的并行执行,可以提高分布式系统检索的效率。
(4)Reduce阶段:完成Map任务之后,Reduce会收集Map阶段产生的中间结果。
(5)任务完成阶段:Reduce计算之后,通过Internet返回给用户,实现过程结束。
3 实验分析
3.1Hadoop分布式系统搭建
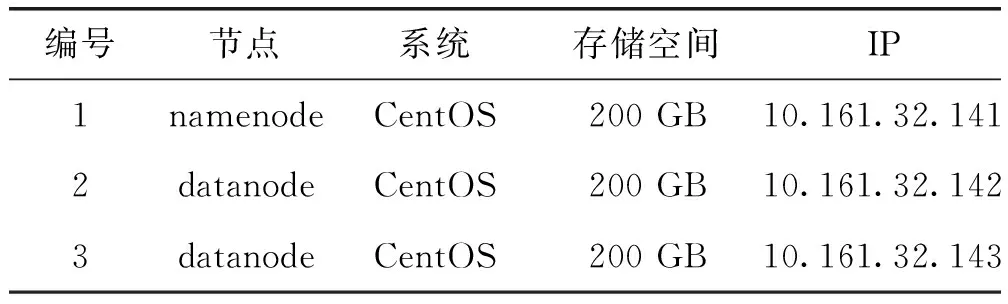
表1 服务器配置信息表
Hadoop为MapReduce提供了分布式存储和计算环境。我们将在Hadoop中进行MapReduce相关的试验。
在阿里云平台上搭建Hadoop环境,机器数量为三台,编号1为传统方法,编号2为2个数据节点的MapReduce检索方法,编号3为3个数据节点的MapReduce检索方法,分别配置如表1所示。
3.2性能分析
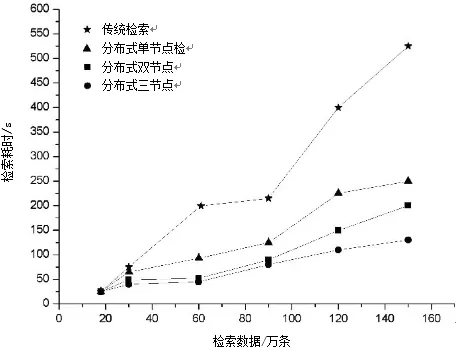
图2 传统方式检索效率与分布式方式检索效率的性能对比
在测试该分布式系统的性能时,采用不同的数据集以及不同的节点数来进行测试,测试结果如图2所示。
(1)当数据在15和30万条时,传统方式所消耗的时间稍长,此时检索所消耗时间差距并不大;
(2)随着数据量的增大,Hadoop系统的性能优势越明显。当数据量超过30万条时,用传统方式进行检索所耗时间急速上升,相比之下利用MapReduce架构进行检索时,节点数越多检索所消耗的时间就越少;
(3)随着数据量的增大,在MapReduce架构下的多结点检索系统的优势越突出,并且检索效率随着节点数的增加而提高;
(4)对比分布式系统常规检索方法(单节点)的检索效果与经过优化的检索方法的检索效果,可以看得出,经过优化的检索方法比常规检索方法的检索效果要优越很多,并且效果随着优化的节点数的增加而增强。
4 结论及展望
使用MapReduce在分布式系统上进行文件检索的相关操作,核心部分是待检索关键词与文件相关性的计算,本文算法在实现过程中根据文件名检索、根据文件内容来检索、根据本关键词来检索以及根据关键词的同义词来进行检索,在一定程度上提高了文件检索的准确率。本文实现了基于MapReduce在分布式系统中进行文件的高放检索,检索峰值测试优化检索算法,以提高分布式系统的检索效率,是下一步所要开展的研究。
[1]陈立博,李金友,毕建伟,黄灏.基于数据库检索信息的一种实现方法[J].黑龙江科技信息,2015,11(2):156.
[2]宋杰,刘雪冰,朱志良等.一种能效优化的MapReduce资源比模型[J].计算机学报,2015(1):59-73.
[3]应毅,刘亚军.MapReduce并行计算技术发展综述[J].计算机系统应用,2014(4):1-6,11.
[4]荀亚玲,张继福,秦啸.MapReduce集群环境下的数据放置策略[J].软件学报,2015(8):2056-2073.
[5]宋杰,王智,李甜甜,于戈.一种优化MapReduce系统能耗的数据布局算法[J].软件学报,2015(8):2091-2110.
[6]韩海雯.MapReduce计算任务调度的资源配置优化研究[D].广州:华南理工大学,2013.
[7]江务学,张璟,王志明.MapReduce并行编程架构模型研究[J].微电子学与计算机,2011(6):168-170,175.
[8]黄斌,许舒人,蒲卫.基于MapReduce的数据挖掘平台设计与实现[J].计算机工程与设计,2013(2):495-501.
[9]李伟卫,赵航,张阳,王勇.基于MapReduce的海量数据挖掘技术研究[J].计算机工程与应用,2013(20):112-117.
[10]赵辉,杨树强,陈志坤,尹洪,金松昌.基于MapReduce模型的范围查询分析优化技术研究[J].计算机研究与发展,2014(3):606-617.
[Abstract]In the document retrieval method, the key is built on the database search. However, when the amount of data to be retrieved becomes very large, using this search method, a large number of retrieval operations will be concentrated on a single host, which can result in reduced efficiency of retrieval. Under this background, a distributed system can be used to solve the problem. Retrieving resources in a distributed system can be based on MapReduce architecture to achieve retrieval. Thus, the pressure of retrieval operation will be allocated to each node in a distributed system, which can effectively reduce the pressure of the machine and greatly improve the retrieval efficiency. Using the traditional way, retrieving 1 million data consumes 500 seconds, while using the method based on MapReduce architecture for distributed systems to retrieve one million data only needs 40 seconds. Compared with traditional search method, method of distributed systems based on MapReduce architecture can promote efficiency to 12.5 times.
[Key words]big data; MapReduce; searching; distributed system
[责任编辑刘景平]
Research on Massive File Retrieval Method Based on MapReduce
TAN Qian-lin, MO Chun-juan
(School of Computer and Information Engineering, Hechi University, Yizhou, Guangxi 546300, China)
TP311
A
1672-9021(2016)02-0101-05
谭黔林(1983-),男,贵州凤冈人,河池学院计算机与信息工程学院教师,主要研究方向:数据挖掘与信息分析研究。
广西高校科学技术研究项目(LX2014320);CALIS广西壮族自治区文献信息服务中心预研项目(LALISGX2014006)。
2016-01-07
