基于网格自适应加密技术的GPU 高效运行实现研究
2016-08-17许卫明
许卫明
(马鞍山师范高等专科学校,安徽马鞍山243041)
基于网格自适应加密技术的GPU 高效运行实现研究
许卫明
(马鞍山师范高等专科学校,安徽马鞍山243041)
针对传统解算器未能实现GPU上运行网格自适应加密过程,造成GPU与CPU之间繁琐的数据交换的问题,本文发展优化了一种GPU加速的基于非结构自适应加密网格的解算器VA2DG。利用加密网格表的方式实现网格自适应加密过程在GPU上高速运行,并通过原子操作并行生成网格加密表,对废弃的网格及时回收,节约存储空间,加快运行速度。
GPU;自适应加密;网格;解算器
0 引言
GPU做运算起始于计算机图形学语言编程的实现,早期由于架构上的设计,在科学计算领域只做一些粒子算法,随着GPU计算的优势被发觉,开始将GPU设计成流式结构,使之更适合通用计算,不再依赖计算机图形学,使得程序设计更加容易。在各种学科特别是流体力学方面的数值方法,通过GPU运算实现了加速[1]。基于网格的CFD方法在GPU上实现时,运算性能跟网格的类型有很大关系,网格自适应加密可以得到动态网格,有利于提升计算精度和速度,但是传统的自适应加密只能对截断误差较大的网格进行加密,同时GPU与CPU之间交流频繁,消耗的计算机资源较多,严重影响程序的性能。因此发展一种能在GPU上高效运行的自适应加密方法对于加速GPU高效运行是非常必要的。
1 VAS2D解算器算法简介
1.1 网格与自适应加密原理
VAS2D解算器采用的是非结构自适应四边形网格,网格结构如图1所示,网格自适应通过Cell-Face网格结构将网格和边联系起来,网格和邻边发生通信,与相邻网格不直接通信[2]。每一个网格会把自己的邻边储存在表Neighbor edge list中,而每条边将其相邻的网格存放在Neighbor cell list之中,这种基于Cell-Face数据结构的通信方式适用于并行计算,易扩展到多维度的计算,计算时对网格和边做循环即可。
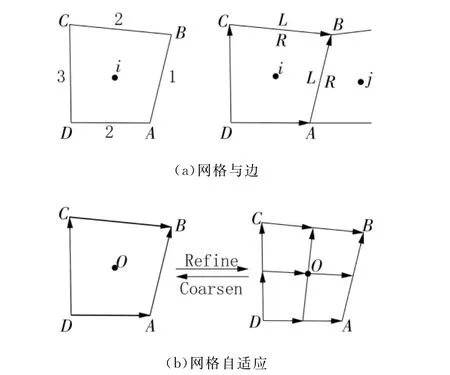
图1 非结构自适应四边形网络
在自适应加密的各种方法中,基于网格的自适应加密技术使用的网格数量最少,在加密的过程中,以一个网格为例,将原网格命名为Father,将原边命名为Mother,加密运行时,该网格分成4个小网格,小网格成为son,加密的同时,网格的4条边也会各自分成两条子边,称这些子边为daughter,加密完成后,将网格的编号编入Father list之中[2],将网格的边编入Mother list中,加密后网格和边所带的信息不变,只是被稀疏。
网格的截断误差决定了网格是否被加密,在VAS2D解算器中,采用二阶导数对网格截断误差进行估算,公式如下所示:
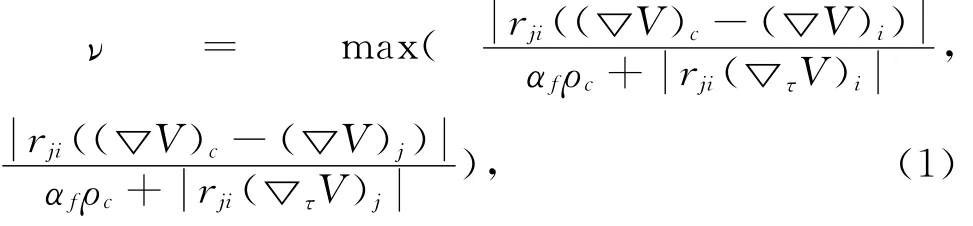
式中:V为原始变量;αf为常数通常取0.03;i,j为编号;rji为网格之间的向量;ρc为网格的平均密度;为网格的梯度为网格梯度在网格向量的投影。
计算出截断误差之后,取4条边的最大值,判断自适应的依据如下,其中ετ是判断加密的依据,一般取0.08,εο为网格稀疏的阈值,一般取0.05。
Refine,ν>ετ;Coarsen,ν<εο
1.2 控制方程和解算器
在可压缩流动计算的应用中,根据Euler方程[3],解算器的控制方程为
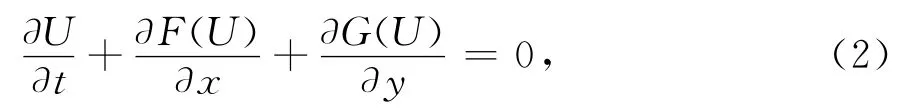
其中U、F、G分别为
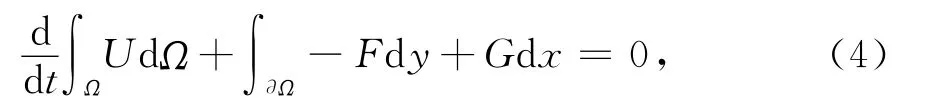
利用近似原理达到时空二阶精度,网格上的变化有网格的四条边的通量决定。

数值通量为Fi,k,其值的大小由边的左右状态得出。
2 VAS2D解算器算法映射
在计算机进行计算时应该尽量避免GPU和CPU之间的数据传输,此次设计旨在将解算器的计算全部放在GPU上,从而达到提升计算速度的目的,计算的流程如图2所示,计算之前先分配出一定的空间预留数据,之后对网格信息进行读取,完成数据的初始化,并进行自适应的初始化,将数据传输给GPU,执行解算器中的kernel函数的计算,数据处理完成后再将数据传输回去进行输出。
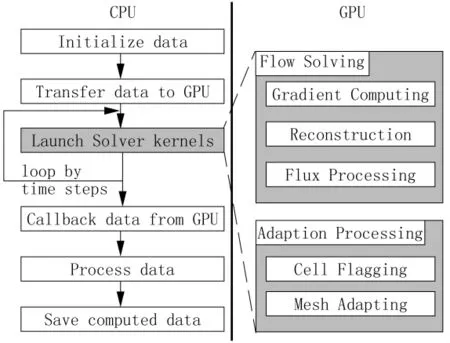
图2 GPU程序执行步骤
2.1 流场解算
在GPU上进行流场的计算相对容易,1.1中对网格的自适应中网格和边采用的是Cell-Face的数据结构,计算时只需分别对网格和边进行循环计算即可[4]。可以将流场的计算分为3部分:梯度计算、初始变量重构、通量计算。
在计算梯度时,先完成网格边的并行处理,对每条边相邻网格的初始变量的差值进行储存,将所有值的计算完成后,利用最小二乘法来计算梯度。在初始变量重构的过程中,利用MINMOD限制器对网格的梯度进行限制,并对网格中心的原始变量进行推测,然后由中间向两边进行差值计算,求各个边的形态,之后采用AUFS格式进行通量计算。
2.2 自适应处理
本次设计中的自适应处理分为网格标记和网格自适应,步骤结构框图如图3所示。在网格标记的过程中首先进行网格截断误差的估计,将加密的网格标记的为Refine,稀疏的网格标记为Coarsen,选择网格邻边中最大作为网格的截断误差,之后按程序运行Father list得到父网格编号,并用加密依据进行判定,满足加密条件标记的为Refine,不满足的则标记为Coarsen。利用截断误差判定网格是否加密并不是唯一的方式,有时候还取决于网格的级别(level)限制,网格的level需在设定的范围内,同时,若一个网格被加密或者稀疏,level和相邻的网格的level值相差必须满足≤1[5]的条件,正是因为网格标记的步骤对于所有网格各边是单独运算的,因此才容易在GPU上实现并行运算。
网络的自适应在GPU上较难实现并行运算,传统的算法证明了通过对表进行处理实现部分向量化可以实现网格的自适应,但传统的算法并不能实现这一功能,主要在两方面难以克服:实现向量化的表是通过串行操作的,程序处理起来难以实现,同时,废旧的网络不做任何处理使得内存的消耗越来越严重[6]。本文利用原子操作将表生成并行化,同时对不用的表进行回收,降低内存消耗,这样克服了传统算法的不足,实现的网格自适应在GPU上高速运行。
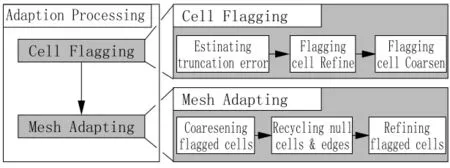
图3 网络自适应步骤
网格自适应过程分为稀疏被标记的父网格,回收废弃的网格和边,同时加密被标记的网格。在稀疏被标记的父网格过程中,将Coarsen的网格从Father list中选出放入Temp list中,之后将Father list压缩,被选出来的进行稀疏,取出内部4条边,对于子边能去除的去除,去除的边或网格标记为Null,之后更新物理量,如果去除4个网格,则将其父网格标记为Non,同理,去除边的母边从Mother list中去除,之后进行压缩,然后进行废弃网格和表的回收。回收的具体算法如下:


网格加密的过程最为复杂,包括以下3步:
1)增加子网格。将标记的Refine的网格导入临时表Temp list中,在Temp list中的网格均被加密,形成父网络,然后将其导入Father list,新形成的父网格形成新的子网格和边。
2)分裂标记过的边。对标记为Refine的需要分裂的进行分裂,分裂产生两条子边,被标记加入Mother list之中新产生的边的信息由母边计算得到。
3)完成子网络的构建。由于重新产生了子边,需要重新更新邻居关系,当新的边和网格的邻居关系产生之后,就可以通过邻边的信息计算新产生的网格的信息。
3 结语
采用原子操作表生成并行化可以避免串行操作生成表的程序瓶颈,实现表的向量化,同时在运算中增加回收废弃网格和边的操作,降低了内存的消耗,使得网格自适应加密过程在GPU上高效、高速的运行。
[1]曹建,曾丽娟,陈建军.面向粘性绕流计算的二维混合网格生成算法[J].计算机工程,2013(10):290-293.
[2]杨猛,刘金刚.一种稳定、高效且保持细节的粘性流模拟算法[J].软件学报,2011(12):2994-3003.
[3]李立,白文,梁益华.基于伴随方程方法的非结构网格自适应技术及应用[J].空气动力学学报,2011(3):309-316.
[4]卢风顺,宋君强,银福康,等.CPU/GPU协同并行计算研究综述[J].计算机科学,2011(3):5-9.
[5]刘莹,菅立恒,梁莘燊,等.基于CUDA架构的GPU的并行数据挖掘技术研究[J].科研信息化技术与应用,2010(4):38-51.
[6]何冰,封卫兵,张武,等.基于非结构网格的Gas-Kinetic方法[J].计算机辅助工程,2009(1):14-17.
The Research and Implementation of GPU Based on Grid Adaptive Encryption Technology
XU Wei-ming
(Maanshan TeacherCollege,Maanshan Anhui 243041,China)
Aiming at the problem that the traditional solution can not implement the adaptive encryption of GPU,which results in the complex data exchange between CPU and GPU,this paper develops a kind of speed GPU based on unstructured adaptive encryption mesh VA2DG.It is to realize that the grid adaptive encryption process can be fast running on CPU by using encryption grid table,and the grid encryption table can be generated by atomic operations.The waste is collected in time to save the storage space and increase the running speed.
GPU;adaptive encryption;grid;solution
TP301
A
1009-8984(2016)02-0116-03
10.3969/j.issn.1009-8984.2016.02.029
2015-11-17
许卫明(1981-),男(汉),安徽怀宁,讲师主要研究计算机网络、软件技术。
