一种精确篡改定位的数字语音取证算法
2016-08-09刘正辉周新建祁传达
王 静,刘正辉,周新建,祁传达
(信阳师范学院 数学与信息科学学院,河南 信阳 464000)
0 引言
随着数字信号处理技术的发展,数字信号代替了传统的模拟信号,在人们日常生活中扮演着越来越重要的角色,成为信息传播的主要载体.同时,多媒体编辑工具的丰富,使人们制作个性的、满足自己需要的数字多媒体内容成为现实.然而,生活中不乏一些犯罪分子,为了个人的利益和其他不可告人的目的,对一些多媒体数据进行精心的伪造和篡改,并肆意传播,破坏他人利益,给人们的生活增加了诸多不和谐的因素,也使数字证据的可信度和认可度受到严重威胁.
数字语音信号是经常被采用的传递信息的数字载体之一,广泛应用在新闻报道、语音通讯等方面.同时,也作为电子证据,应用在医疗记录和法庭举证等环节.在这些应用当中,语音信号的真实性和完整性是保证其法律效益的前提.一般而言,被攻击语音信号表示的内容和原始内容将有很大的区别,若被攻击信号的指令被人们采用和执行,将会带来严重的后果.大量存在的被篡改、伪造的语音信号,已经影响了数字语音信号表示的数字证据和新闻报道的可信度和认可度.数字语音内容真实性和完整性取证问题已成为当前多媒体信息安全领域的研究热点[1].
基于数字水印的方法提供了一种鉴别语音真实性和完整性的方法.目前,数字水印技术已经在版权保护方面取得了丰硕的研究成果[2-6],但在语音取证方面则相对较少[7-9].现有的基于数字水印的音频取证技术已解决了部分问题,如水印嵌入过程考虑了人类听觉系统,算法满足了水印不可听性的要求;部分算法对于恶意篡改能够有效检测,并定位被攻击的内容.这些都为该技术走进人们的日常生活奠定了基础.然而考虑到应用的多样性以及攻击的不可预测性,目前该技术还存在几个问题需要解决:(1)数字语音取证常见的篡改定位方法是在数字语音各帧中嵌入标识信息,验证端通过提取标识信息来定位各帧的位置.而标识信息的嵌入是通过量化多个样本点组成“一段”信号的特征来实现的.由于数字语音的短时稳定性,只要组成该段信号的样本点大部分不变,提取的特征就和原来的相同.这意味着组成该段的内容向前或向后偏移少量样本点将不影响标识信息的提取.从而,此类定位方案只能定位被攻击内容的大概位置,而不能精确定位被攻击的位置[4-6];(2)部分基于公开特征的水印算法,由于采用特征的易获取性,使算法存在被攻击的安全隐患[8,10].
针对上述问题,本文研究了当前水印算法不能精确篡改定位的原因,提出了一种安全的精确篡改定位数字语音取证算法.将语音信号分帧,对每帧内容进行置乱操作.将由帧号和信号系数自相关生成的水印嵌入到置乱信号中,水印信号可以通过反置乱来获得.
1 本文算法
将原始语音信号记为A={al|1≤l≤L},其中L表示语音信号的长度,al表示第l个样本点.
1.1 预处理
1)将A等分为P帧,每帧的长度即为L/P.第i帧记为Ai,1≤i≤P.
2)将第i帧Ai中的样本点置乱(本文采用基于混沌地址索引的方法).混沌序列由Logistic混沌映射[11]来生成,其定义如式(1).
xj+1=μxj(1-xj),x0=k1, 3.5699≤μ≤4,
(1)
其中,k1是混沌序列的初值,作为水印系统的密钥.由式(1)生成的混沌序列记为X={xj|j=1,2,…,L/P}, 将X中的元素从大到小排列,排列后的第j个元素记为xhj,如式(2).
xhj=ascend(xj),i=1,2,…,L/P,
(2)
Ai中的样本点置乱后的信号记为Si,Si={sj|1≤j≤L/P},其中sj=ahj.
3)将Si等分为4段,分别记为S1i,S2i,S3i和S4i.S1i和S2i的长度为N,S3i和S4i的长度为L/2P-N.
1.2 水印生成和嵌入
1)将第i帧的信号i分解,如式(3).
i=w1N·10N-1+w1N-110N-2+…+w11,
(3)
记W1i={w1N,w1N-1,…,w11}为第i帧的标识,分别嵌入到S1i和S2i中.
2)S1i中N个样本点的小数点后第二位的值分别用w1N,w1N-1,…,w11代替,以此方法将W1i嵌入到到S1i和S2i中.
3)将S3i和S4i等分为M个子段,分别记为S3i,m和S4i,m,1≤m≤M.由S3i生成的水印记为W2i={w2m|1≤m≤M},w2m的生成步骤如下:
Step1 计算S3i,m的系数自相关[12],记为C3m,如式(4).
(4)
其中T=|S3i,m|表示信号S3i,m的长度.
Step2 根据以下规则来生成w2m,
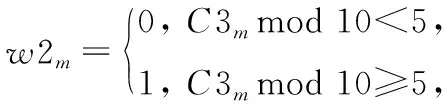
(5)
W1i和W2i即为第i帧生成的水印信息.
4)将w2m嵌入到S4i,m中,方法如下:
Step1 由式(4)的方法计算S4i,m的系数自相关,记为C4m.
Step2 量化C4m来嵌入w2m,量化方法如下:
如果w2m=0,则
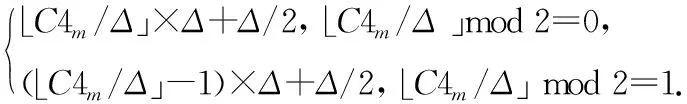
(6)
如果w2m=1,则
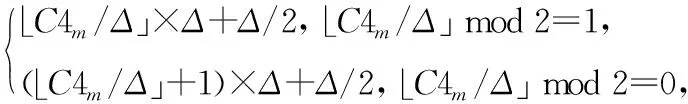
(7)
其中:Δ表示量化步长,Q4m为量化后的值.
Step3 将S4i,m中的样本点缩放α倍,完成水印的嵌入,其中α由式(8)得到.
(8)
采用以上步骤将W2i嵌入到S4i中.将嵌入水印的信号反置乱操作,即可得到含水印的语音信号,水印生成和嵌入过程如图1所示.

图1 水印生成和嵌入过程框图
1.3 内容取证和篡改定位
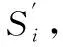
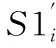
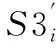
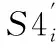
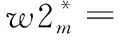
(9)
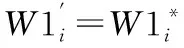


图2 内容取证过程框图
2 性能分析
选取40段语音信号作为测试样本来测试本文算法的性能.测试样本为16位量化、采样频率为22.5 kHz、WAVE格式的单声道数字语音信号.分为4种类型,分别为在安静的办公室、讨论会、嘈杂的车站和空旷的野外录制,记为Type 1、Type 2、Type 3和Type 4.实验采用的软件为Matlab 2010 a,仿真系统为,CUP:Core i5-3470,内存:4 GB,64位的Windows操作系统.其他实验参数分别为L=60 600,P=30,N=10,M=5,k=0.279 3,μ=3.925 7.
2.1 不可听性
不可听性要求嵌入的水印不被听觉所感知,它体现了水印的嵌入对原始信号的改变程度.本文分别采用主观和客观两种评价方法来测试本文算法的不可听性.主观的评价方法是将原始语音信号及含水印的语音信号提供给一组听众,由听众根据主观感觉来区分两个信号之间的差别,并按照主观区分度SDG(Subjective Difference Grades)来打分.将这一组听众最后打分的平均值作为原始语音信号和含水印语音信号主观听觉质量测试的结果.客观评价是利用测试工具PEAQ(Perceptual Evaluation of Audio Quality)得到听觉质量客观区分度ODG(Objective Difference Grade),根据ODG值来测试水印的不可听性.SDG值和ODG值的评分标准见表1[7].
对40段语音信号测试所得的SDG值和ODG值见表2所示,其中SDG值由10位听众现场打分所得.由表2测试结果可以看出本文算法具有较好的不可听性.
2.2 篡改定位能力
1)基于同步码定位方法存在的不足
对音频水印算法而言,去同步攻击会导致水印不能被正确地提取,该攻击被认为是最难抵抗的攻击方法之一[6].当前,最常见的抗去同步攻击的方法是在音频信号中嵌入同步码,通过提取同步码来定位含水印的内容[4-6].考虑到应用的深入,此类算法存在以下几个问题有待解决:

表1 SDG值和ODG值的评分标准
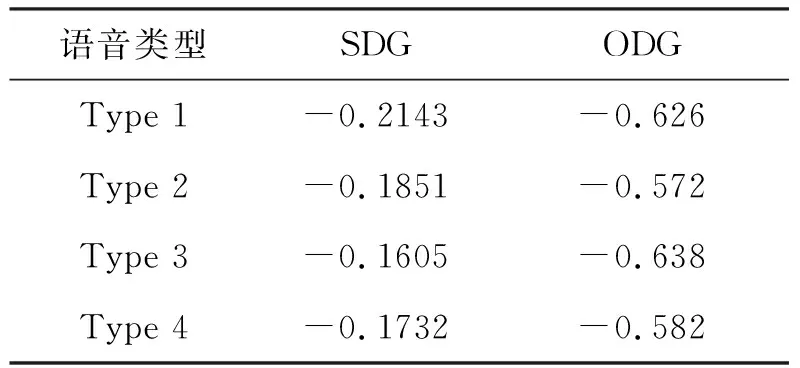
表2 不同类型语音信号的SDG值和ODG值
(1)只能定位含水印的内容,而对定位到的含水印内容不具有鉴别其真伪的能力;(2)各帧嵌入的同步码完全相同,若互换含同步码的内容,系统将检测不到;(3)由于语音信号的短时稳定性,同步码和语音信号之间是一对多的关系.这意味着能正确提取同步码的语音段不唯一,导致基于同步码的定位算法定位精度不精确.下面通过实验来验证以上的几个问题.
随机选取一段长度为3000的语音信号,并记C={1010011101}为要嵌入的同步码.将选取的语音信号分为3帧,并将同步码C嵌入到第1帧和第3帧中,嵌入后的信号如图3所示.
a)图3所示的信号中,如果第2帧的内容被攻击(比如插入、删除、替换等攻击),单单通过提取第1帧和第2帧的同步码将不能检测被攻击的内容.因为基于同步码的方法仅能定位到被攻击的内容是含水印的部分,对于定位到的内容不能进行真伪鉴定[8,10].图4给出了攻击后的信号,可得,只要第1帧和第3帧的同步码能够正确提取,则第2帧即被认为是含水印的内容,却不能检测是被攻击的内容.
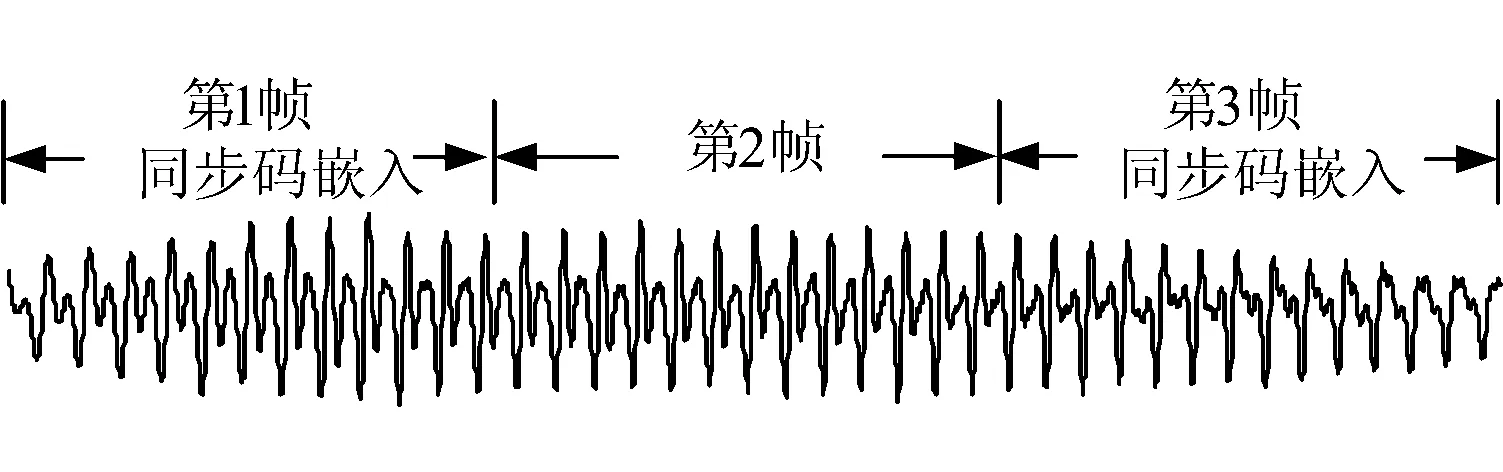
图3 嵌入同步码后的语音信号

图4 攻击后的含同步码语音信号
b)在图4所示的语音信号中,搜索含同步码的语音帧.结果表明,从第1帧附近的样本点中均可正确提取同步码,如图5中位于矩形框内的信号.于是,由同步码定位含水印内容的方法,仅能实现大致的定位而非精确定位.
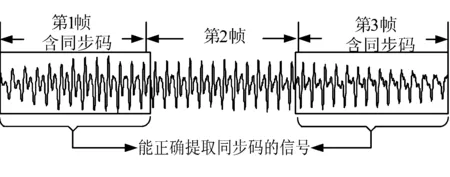
图5 可以正确提取同步码的信号
以上分析表明,基于同步码定位含水印的方法,一方面,对定位到的含水印的内容缺乏真实性和完整性取证的能力;另一方面,对含水印内容的定位不够精确.
2)本文算法精确篡改定位能力
本文算法中,帧号作为用于定位的水印信息,嵌入在各帧信号的第一段和第二段中.一个整数位嵌入到一个样本点中,N个整数位嵌入到了N个样本点中.若含水印的内容被攻击,通过搜索到第一段和第二段提取帧号完全相同的语音帧来对被攻击内容的篡改定位(详见第1部分).对本文算法而言,N个整数位完全相同的概率为1/10N,也是本文算法定位出错的概率.故,本文算法对被攻击内容能够精确篡改定位的概率为1-1/10N.
2.3 安全性
对基于公开特征的水印算法而言,由于其采用特征的公开性,导致水印算法易受替换攻击[8,10].本文中,对各帧语音信号进行置乱处理,将水印信息嵌入到置乱信号中.然后反置乱操作,来获取含水印的语音信号.验证端在内容取证时,依据密钥获取置乱后的信号,并对置乱后的信号进行取证.对攻击者而言,在没有密钥的情况下,很难获得正确的置乱结果,也就无法采用文献[8,10]的攻击方法来实施有针对性的攻击.若攻击者随机选取密钥攻击含水印的内容,该攻击被检测到的概率Pa为
(10)
基于以上分析,表3给出了本文算法和其他水印算法[1,3,4-6]相关性能的对比结果.其中,A1表示安全性,A2表示精确篡改定位能力.从对比结果可见,与现有水印算法相比,本文算法在安全性和精确篡改定位能力等方面均得到了提高.

表3 本文算法和其他水印算法的性能对比
2.4篡改检测和篡改定位
下面测试本文算法对不同类型攻击的篡改检测和定位能力.随机选取一段含水印的语音信号,如图6所示.对含水印信号进行删除、替换、插入三种类型的攻击,然后给出对不同类型攻击信号的篡改检测和篡改定位结果,在篡改定位结果中,Ti=1表示第i帧的内容是真实、完整的.
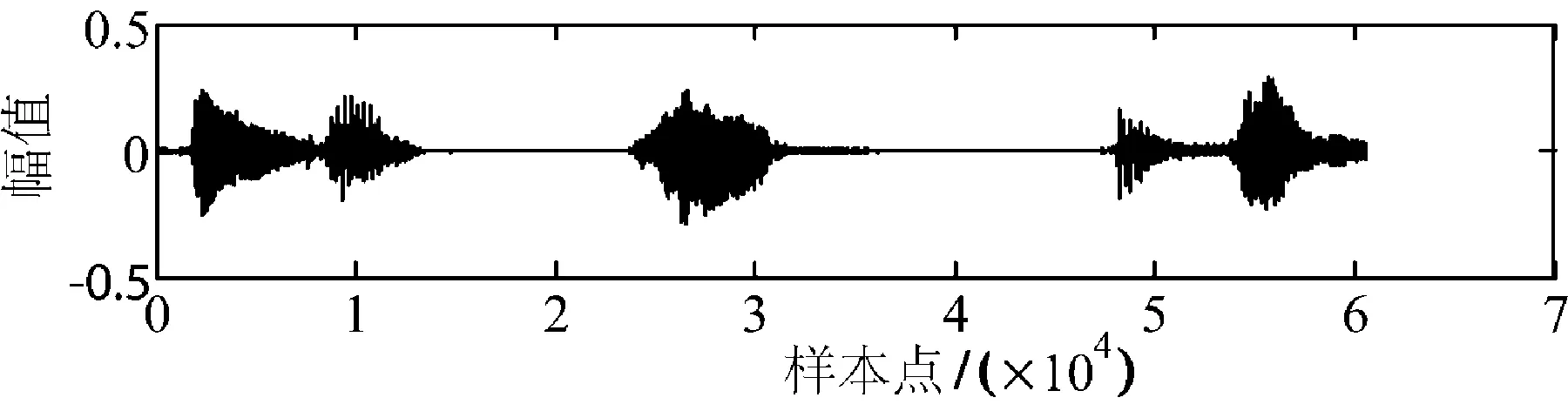
图6 含水印语音信号
1)删除攻击
删除6000个(第8501到第14 500个)含水印信号的样本点,删除后信号如图7所示,对应的篡改定位结果如图8所示.由篡改结果易得,第5帧到第8帧的内容是不能通过认证的部分.
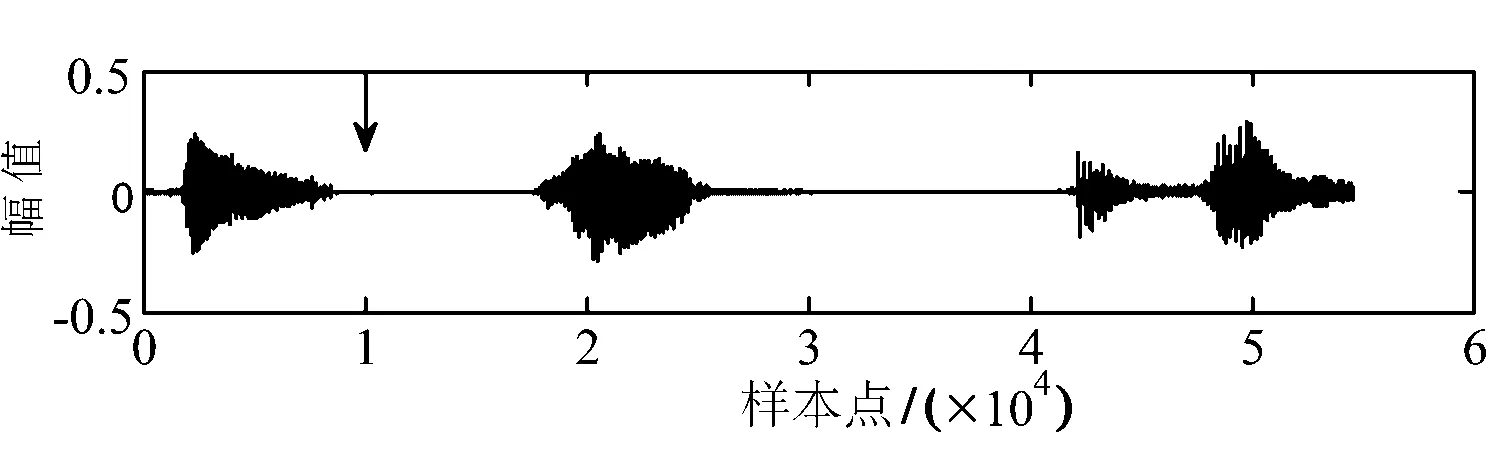
图7 删除攻击的含水印语音信号
图8 对删除攻击的篡改定位结果
2)替换攻击
选取含水印语音信号第74 000到81 000个样本点,并用其他语音信号进行替换,替换后的信号如图9所示,图10给出了对该替换攻击的篡改检测和定位结果.根据检测结果得到,第7到第10帧的内容是被攻击的部分.
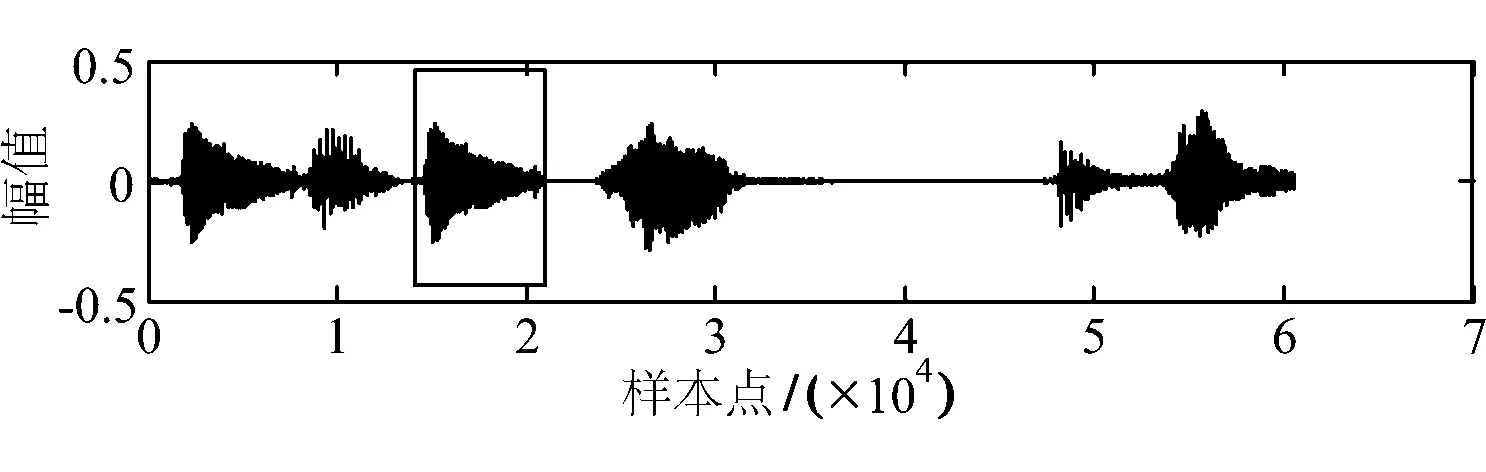
图9 替换攻击的含水印语音信号
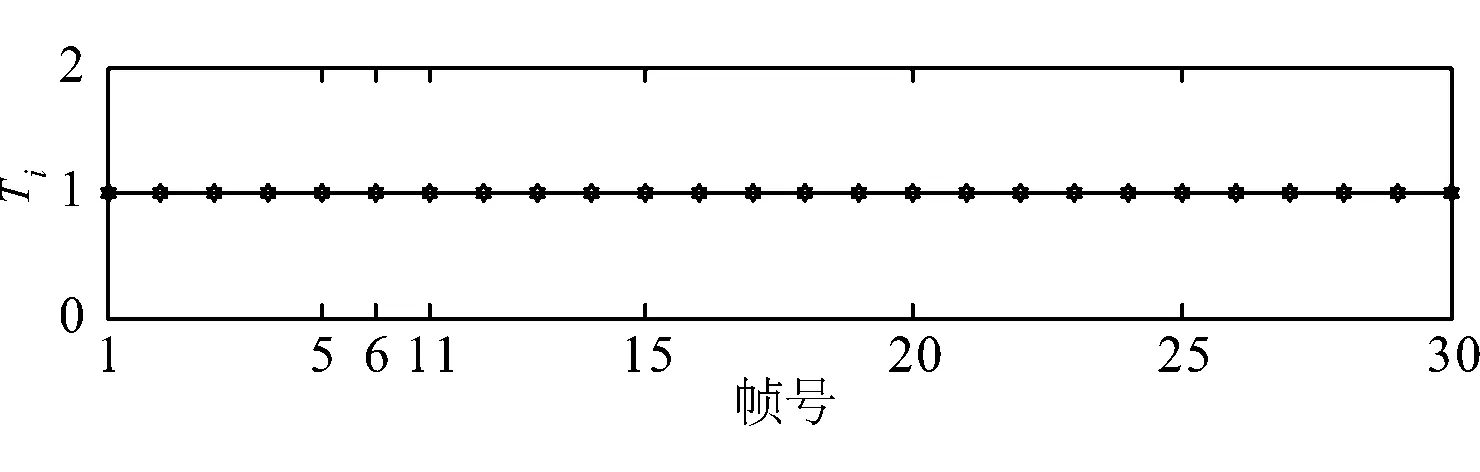
图10 对替换攻击的篡改定位结果
3)插入攻击
在含水印语音信号第40001个样本点处插入6000个样本,插入攻击后的信号如图11所示,对应的篡改定位结果如图12所示.由篡改检测结果可得,第20帧和21帧是被攻击的内容.
以上性能分析结果表明,本文所给算法具有较好的不可听性,能够对恶意攻击有效地篡改检测,同时提高了水印嵌入的安全性.
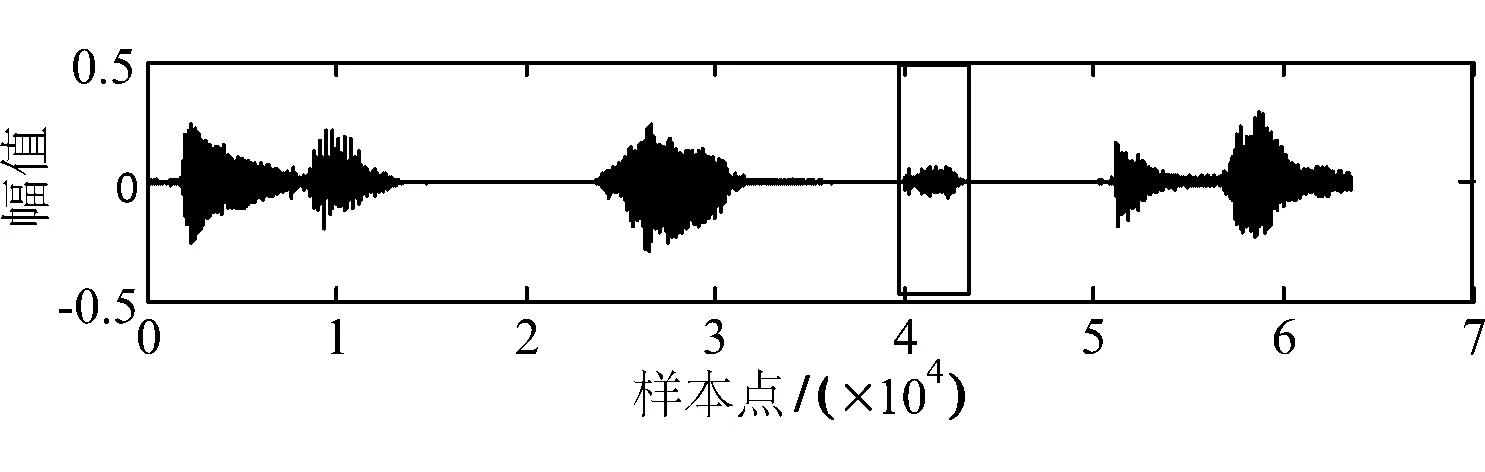
图11 插入攻击的含水印语音信号
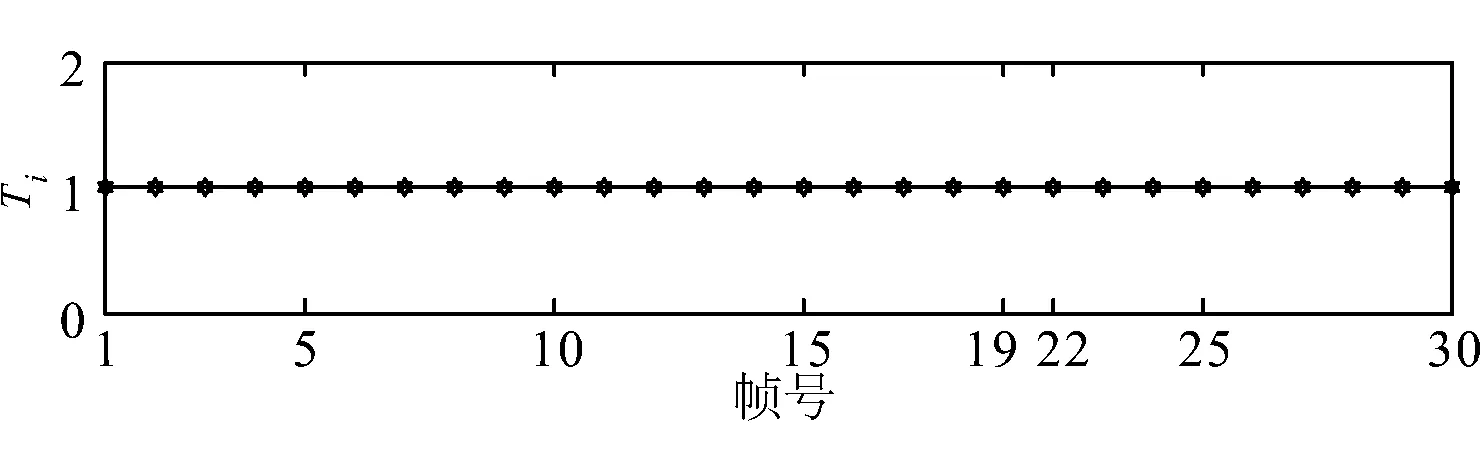
图12 对插入攻击的篡改定位结果
3 结论
提出了一种精确篡改定位的数字语音取证水印算法.原始语音信号分帧后,对各帧信号进行置乱操作.水印由帧号和信号系数自相关生成,并嵌入到置乱信号中.其中,帧号用来精确地篡改定位,系数自相关用来认证各帧的内容.实验分析结果表明,所提算法具有较好的不可听性,能够对恶意攻击进行有效的篡改定位,同时提高了整个水印系统的安全性.
