云计算环境下格陵兰海盐度数据提取算法研究
2016-08-05朱晓辉任红健
朱晓辉 瞿 波 任红健
1(南通大学计算机科学与技术学院 江苏 南通 226019)2(南通大学理学院 江苏 南通 226019)
云计算环境下格陵兰海盐度数据提取算法研究
朱晓辉1瞿波2*任红健1
1(南通大学计算机科学与技术学院江苏 南通 226019)2(南通大学理学院江苏 南通 226019)
摘要海洋盐度与海洋浮游植物和海洋温度具有紧密联系,是研究海洋环流和海洋对气候影响的重要参量。以美国NOAA全球海洋信息数据库为数据来源,以经度65°N -85°N、维度20°W -10°E之间的北极格陵兰海地区为研究区域,详细讨论盐度数据的提取,提出时间复杂度为O(n)的盐度数据分步归并算法。利用微软Azure公有云按需付费、动态扩展的特点,获取廉价、便捷的计算资源,大大提升了计算效率。该算法具有很强的可扩展性,可以根据实际计算需求动态调整所需的计算资源,从而能满足不同计算规模的需求。实验结果表明,该算法可以对海量原始盐度数据进行快速分析和归并,生成经纬度、时间、盐度三个维度上的数据。
关键词盐度格陵兰海经纬度数据提取归并算法云计算
0引言
海洋盐度是研究海洋环流和海洋对气候影响的重要参量。目前,由于技术限制和人们对盐度遥感的认识不足,盐度遥感观测技术远远滞后于研究的需要,盐度遥感的研究几乎处于停滞不前的状态。近年来,一些盐度数据库纷纷兴起,但盐度数据提取方法的研究在国内还属于初级阶段。由于盐度资料在时空分布上的不足,对盐度的研究带来了困难。
一些研究者试图用各种方法来处理盐度数据。陈建等[1]用Matlab对基于二进制的混合文件格式的盐度数据的处理做了读写操作方法的研究;朱江等[2]介绍了一个三维变分海洋资料通话系统的设计方案,在海面高度资料同化中引入了一个新的考虑了背景场误差的垂直相关性和非线性的温-盐关系的同化方案,结果有效地改进了对海洋温度和盐度的估计。
为研究北极的盐度数据,我们利用美国NOAA网站数据库,采用归并算法[5]思想,并利用云计算按需申请、动态分配、快速部署等特点,多步骤依次对数据进行归并处理,第一次对盐度数据在云计算环境下的提取作了尝试性研究。该研究成果可以很方便地应用于其它海洋数据的提取和处理,为课题所需的其它基础数据的获取和分析打下了坚实基础。
1技术背景
美国NOAA网站数据库保存了全球海洋盐度数据,用户可以通过设定经纬度、日期、测量值类型(例如:风力,温度,盐度等)、下载数据文件格式等不同的查询参数来获取不同地区、不同类型的数据,并通过FTP服务供用户下载。
1.1数据提取
因本课题主要对北极地区生态系统进行研究,所以我们只需提取位于经度为65°N -85°N、纬度为20°W -10°E之间的盐度数据。由于盐度数据量非常庞大,为方便数据处理,我们以5度为一个经度单位,分4次依次提取65°N-70°N,70°N-75°N,75°N-80°N,80°N-85°N之间的数据。
1.2数据分析
对下载的数据初步分析后发现,不同区域的数据量各不相同,同一区域数据还具有多种数据格式,不同格式数据文件的数据量也不一样,有的只有几万条记录,而有的多达几十万条记录。考虑到数据的精确性,在每个区域中我们选择数据量最大的数据文件进行数据分析和统计。原始的数据文件格式如图1所示。
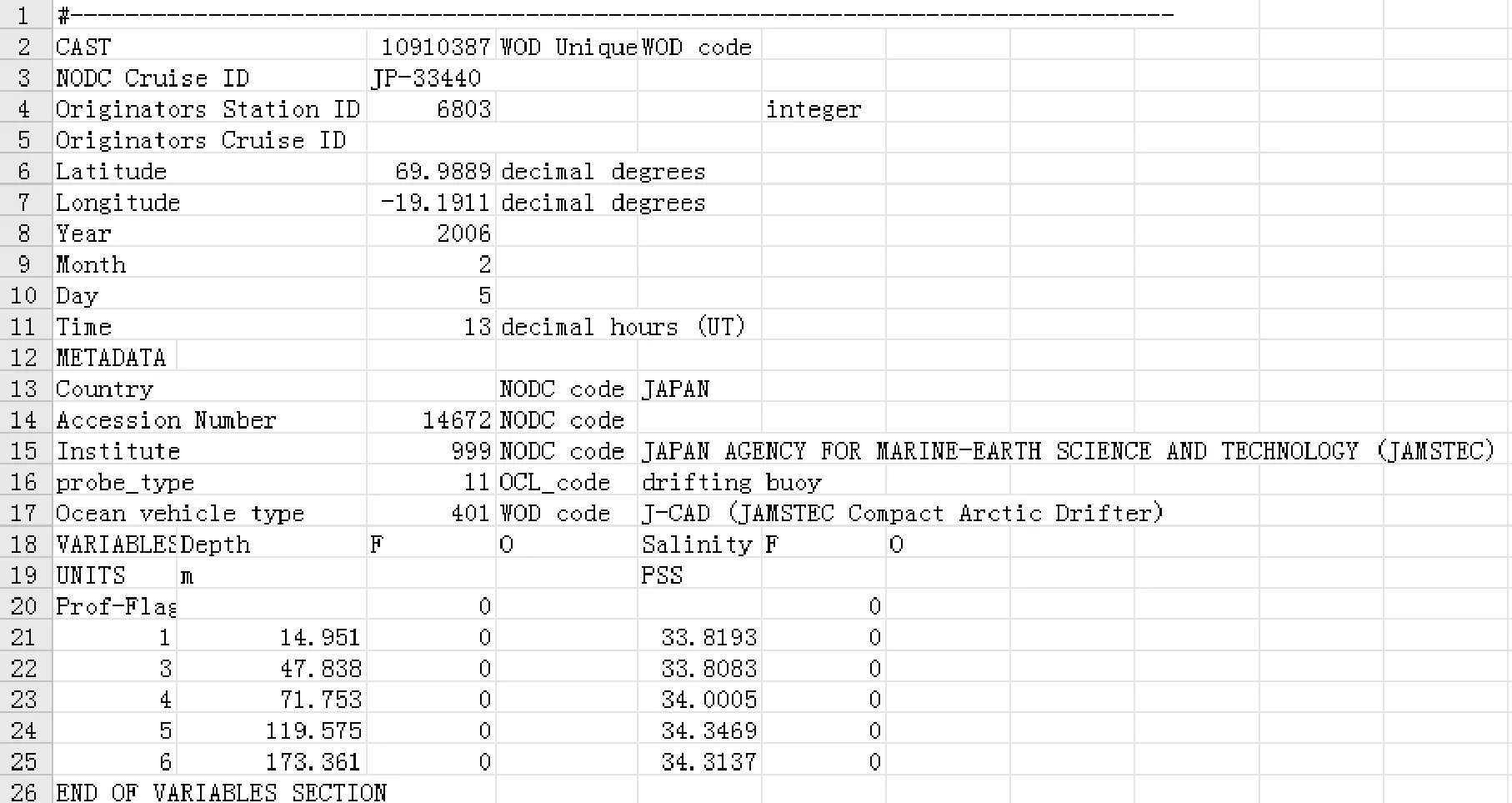
图1 原始数据文件格式
虽然不同格式数据文件中数据量各不相同,但其数据格式基本与图1类似。每个盐度数据都以“#------”开始,以“END OF VARIABLES SECTION”和“#------”结束。每个数据都包含有经纬度、日期、海水深度、盐度等信息。
1.3云计算
云计算是信息平台和服务的一种业务模式, 是通过网络统一组织和灵活调用各种ICT 资源,实现大规模计算的信息处理方式[8]。其所特有的按需付费、高可用性、高可靠性和高可扩展性等特点使其逐渐成为继水、电、气及通信技术之后的第五大公共平台,成为一个战略性新兴产业[9],是一种面向未来的新的计算模式[10-12]。与传统的分布式计算相比,其具有:可以根据计算规模的大小动态租用云计算资源,并能实现分布式环境的快速部署和复制;可以根据计算时间实现按需付费;避免用户购买昂贵的硬件设施,极大降低计算成本,提升计算效率等多种优势。
由于我们在数据提取过程中获取了海量的盐度数据,为提升数据处理效率、降低数据处理成本,同时避免自己搭建分布式计算环境的麻烦,我们尝试利用微软Azure公有云计算平台来实现对盐度数据的处理,并对其进行分析和评估,为后续工作中需要提取和处理其它类型的海量数据积累经验。
2技术背景
2.1数据提取格式
根据盐度数据研究的实际要求,需要对图1中的数据进行分析和提取,形成如表1所示的规整盐度数据。其中,经度和纬度字段需通过四舍五入操作转换成整数。
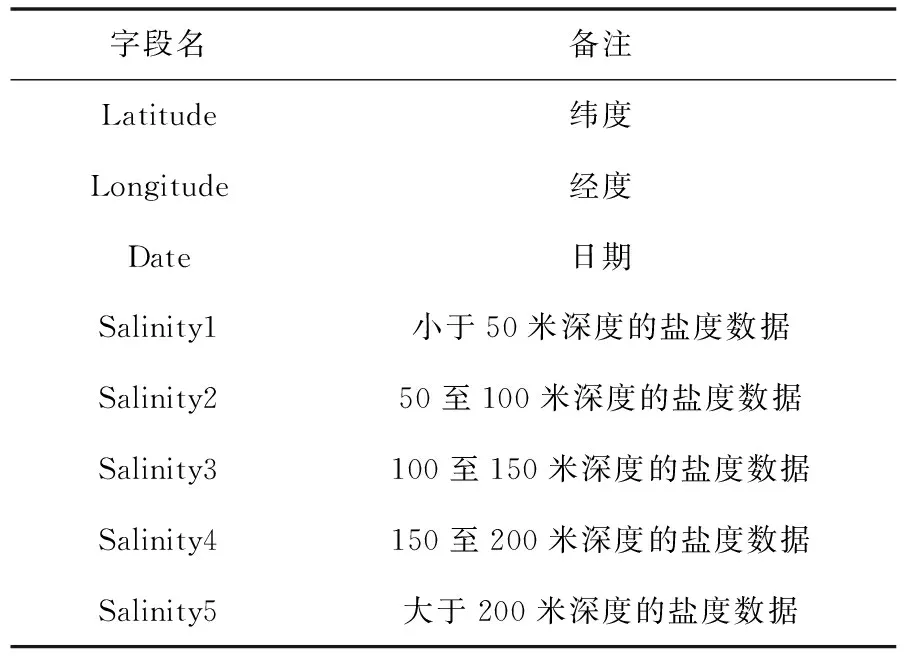
表1 盐度数据主要字段
2.2数据提取难点
由于原始盐度数据格式的复杂性,生成如表1所示的格式规整的盐度数据有以下几个难点。
(1) 数据格式不规范:虽然大部分盐度数据格式和字段数量都相同,但有少数盐度数据与其他正常盐度数据相比会多几个或少几个字段,有的甚至只有测量时间和地点,却没有相应盐度数据。由于盐度数据量巨大,因此无法逐一人工排查和删除非规范盐度数据,这为数据归并算法的设计带来了很大挑战。
(2) 各测量点的随机性:原始数据中,各测量点经纬度坐标具有很大随机性,有的经纬度坐标相隔较远,通过四舍五入取整后可以归类到不同的经纬度坐标。有的经纬度坐标相互间靠得非常近,通过四舍五入取整后,需要归类到同一个经纬度坐标,这就需要对这些盐度数据进行合并后求其平均值。
(3) 测量深度的随机性:有的测量点以1米为深度间隔,同一个测量点记录了数千个不同海水深度的盐度数据;有的测量点以几十米至几百米的深度为间隔,同一个测量点只记录少量的不同海水深度的盐度数据;还有的测量点只记录海水深度,却没有记录相应的盐度数据。这为数据按海水深度归并成表1所示的5个不同深度的盐度数据带来了困难。
(4) 测量时间的随机性:有的测量点一个月内进行了多次测量,有的测量点上可能只测量了很少的几次甚至没有测量。同一个测量点上,在不同的时间段内,其测量的次数也具有随机性和不确定性,这为数据按时间维度进行归并带来了困难。
(5) 盐度数据量巨大:由于每个测量点上都可能有数千条不同深度的盐度数据,因此整个区域的数据量非常巨大,即使把北极的格陵兰海地区分为4个区域分别下载原始的盐度数据,每个区域的盐度数据的CSV文件都有几十MB大小,近百万条记录。这就对数据处理算法提出了很高的要求,需要设计出能快速处理海量盐度数据的算法和处理程序。
2.3数据提取算法
为提高数据处理效率,降低算法复杂性,本文设计了分步数据归并算法[6]。与常规的数据归并算法一般先要对数据进行分块和排序,然后再进行归并[7]不同,本文的归并是对现有的数据进行计算并根据计算的结果对数据进行合并操作,即把一个大的数据集经过多次归并运算后得到一个小的结果集。基本步骤如下:
(1) 按测量深度进行数据归并:把每个测量点上不同深度的盐度数据归并为“小于50米”、“50至100米”、“100至150米”、“150至200米”、“大于200米”共5个不同深度盐度数据。
(2) 按测量点进行数据归并:对归并后的盐度数据按经纬度和测量时间排序,然后再对各测量点的经纬度进行四舍五入取整操作,并对归类到相同经纬度坐标上同一天的盐度数据进行合并。
(3) 按测量时间进行数据归并:对二次归并后盐度数据按时间排序,并按照系统设定的时间间隔把小于间隔时间并且经纬度相同的盐度数据再次归并。
2.3.1按测量深度进行数据归并的算法
对图1所示的原始盐度数据的格式进行分析发现盐度数据格式有以下几个特点:
(1) 测量点的数据以“#---”开始,以“#---”结束。其中,盐度数据以“Prof-Flag”标识开始,以“END OF VARIABLES SECTION”结束。
(2) 每个测量点都有经度、维度、测量年份、测量月份、测量日期等几个字段信息。但因数据格式及每个测量点上数据量不固定,其在数据记录中的位置也不尽相同。
(3) 个别盐度数据只记录了海水深度,但却无对应的盐度数据。
根据以上盐度数据的特点,本文设计了按测量深度进行数据归并的算法,算法流程如图2所示。
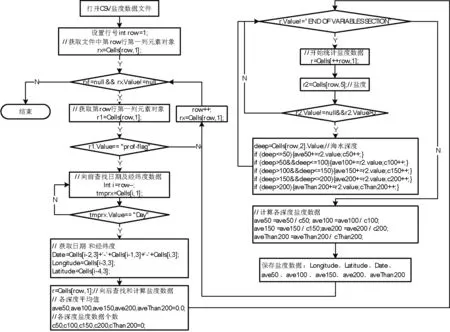
图2 按测量深度的数据归并算法流程
算法执行步骤如下:
(1) 打开数据文件设定行号row=1;
(2) 获取第row行,第1列元素rx=Cells[row,1];
(3) 若rx==null,则为最后一行记录,算法运行结束,否则转步骤(4);
(4) r1= Cells[row,1],若r1= =“prof-flag”,则该测量点有盐度数据,转步骤(5),否则该测量点无盐度数据,转步骤(10);
(5) 从第row行开始,向上搜索日期信息“Day”、“Month”、“Year”以及经纬度“Longitude”和“Latitude”,并保存;
(6) 从row+1行开始依次获取不同海水深度的盐度数据r=Cells[row,1];
(7) 若r!=“END OF VARIABLES SECTION”,则获取该盐度数据所对应的海水深度,并按表1所示,分别对5个盐度数据进行汇总统计,否则直接转入步骤(9);
(8) 获取下一个盐度数据r=Cells[++row,1],转步骤(7);
(9) 保存该测量点经纬度、时间及各海水深度的平均盐度数据信息;
(10) rx=Cells[++row,1],转步骤(3);
以上算法流程可以看出,该算法从数据文件的第一行开始,按序进行数据处理,整个算法只用了一个单层循环语句,时间复杂度为O(n)。该时间复杂度也是对数据进行批量处理的最优时间复杂度,因此该算法具有很好的处理性能。
2.3.2按测量点进行数据归并的算法
按测量深度归并后,以各测量点及测量时间为单位形成了规整的数据记录。由于各测量点经纬度坐标具有随机性,这就需要对通过四舍五入取整归类到同一个整数经纬度坐标上的盐度数据再次进行合并,并求他们的平均值。按测量点进行数据归并的算法流程如图3所示。
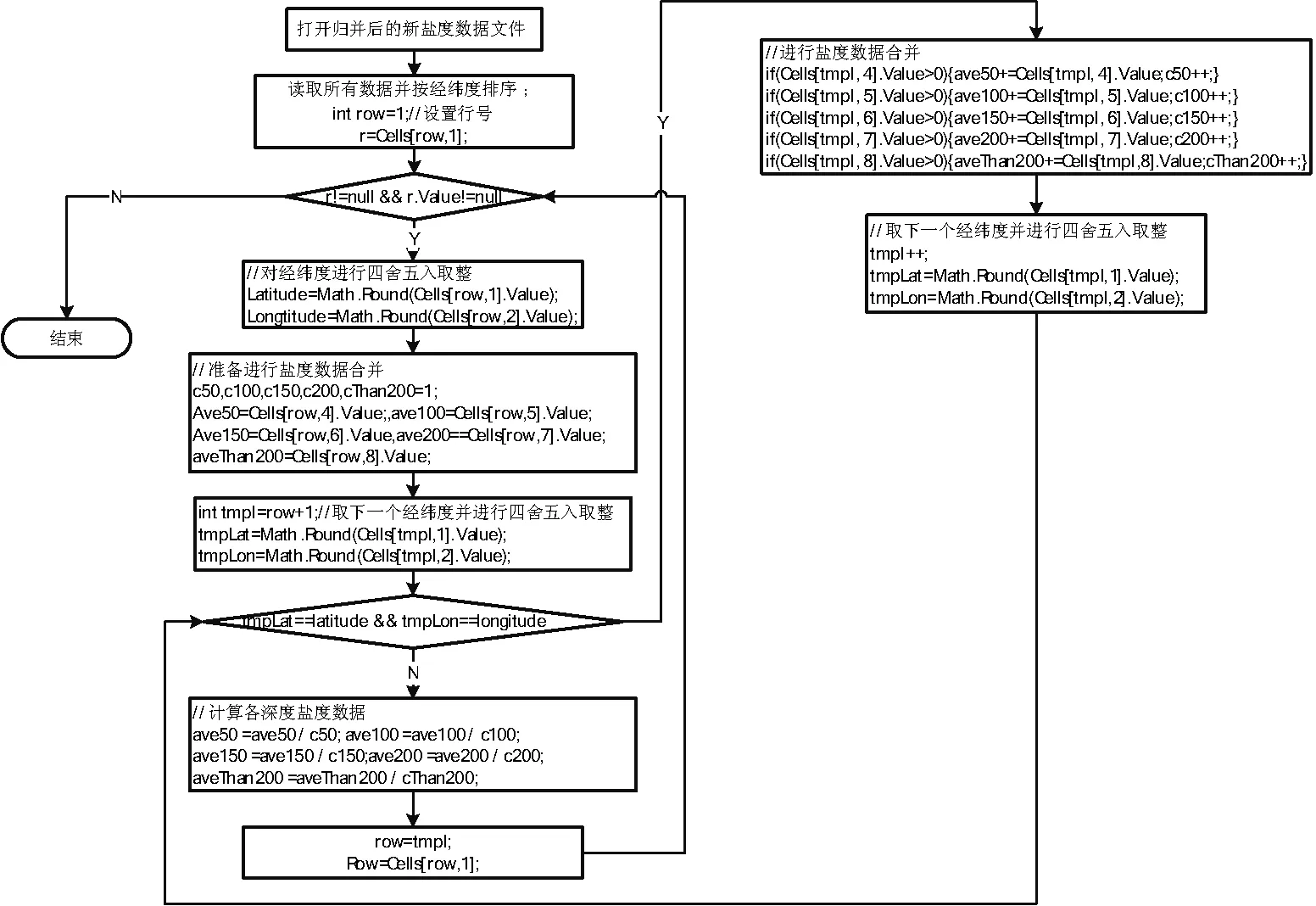
图3 按测量点的数据归并算法流程
其算法基本执行步骤如下:
(1) 打开按测量深度进行归并后的盐度数据文件;按经度和维度进行排序;
(2) 设row=1;取第row行第一列元素r=Cells[row,1];
(3) 若r等于空,则表示已处理完全部数据,程序结束,否则进入步骤(4);
(4) 对当前行的经纬度进行四舍五入取整,并设定临时变量tmpI=row;
(5) tmpI++, 取下一行数据的经纬度并进行四舍五入取整;
(6) 若两个经纬度不完全相同,则无需合并,转入步骤(9),否则转入步骤(7);
(7) 对盐度数据进行合并运算;
(8) 转入步骤(5);
(9) row=tmpI; r=Cells[row,1]转入步骤(3)。
从上面算法流程可以看出,该算法的时间复杂度也为O(n)。按测量时间进行数据归并的算法与以上两个算法类似,这里不在赘述。通过分析不难得到,其算法时间复杂度也为O(n)。
3系统实现
3.1系统架构
整个系统由数据库服务器、文件及配置服务器、主计算节点和若干个子计算节点组成,其架构如图4所示。

图4 系统架构
(1) 文件及配置服务器:保存原始盐度数据文件及系统配置信息,所有计算子节点都根据本服务器系统配置信息获取相应盐度数据文件并进行计算和处理。
(2) 数据库服务器:所有计算节点把从原始盐度数据文件获取的基础数据保存到数据库服务器中,方便将来进行其它形式处理时无需再重复访问原始数据文件。
(3) 子计算节点:从文件及配置服务器上下载相应的盐度数据文件,并自动维护和修改相应配置信息,根据2.3节的数据归并算法完成对该盐度数据文件的处理和归并。
(4) 主计算节点:用于接收从各计算子节点处理完毕的盐度数据,并完成最后的数据排序和合并。
系统部署和运行流程如下:
(1) 在Windows Azure中创建四台虚拟机分别作为文件和配置服务器、数据库服务器、主计算节点和一个子计算节点。
(2) 所有的原始数据文件保存到文件和配置服务器,并在配置文件中设置所有文件的保存路径、文件名、是否已被处理等信息。
(3) 把数据归并算法程序部署到子计算节点,并为其设置文件和配置服务器、数据库服务器和主计算节点的地址信息,使子计算节点能自动获取、处理、保存和上传数据。
(4) 用虚拟机复制技术来快速部署多个子计算节点。
(5) 子计算节点被部署和运行后,自动访问文件和配置服务器,并下载还未被处理的原始盐度数据文件,读取数据,保存到数据库,并进行归并处理。
(6) 子计算节点的数据处理完后,自动提交到主计算节点,并再次访问文件和配置服务器获取下一份还未处理的数据文件。
(7) 主计算节点每次接收到子计算节点的数据后验证接收数据的次数和文件和配置服务器中的原始文件数是否相等,若相等则表示已经接收到所有的数据,则开始进行最后的排序和归并,并输出结果,若不相等则继续等待。
整个系统架构可以根据实际数据量的大小来动态调整子计算节点的个数,可以把原始数据划分成多个数据文件,分发给多个子计算节点同时计算。
3.2系统实现
算法程序基于微软.NET Framework 4.5平台,采用C#语言开发。实验运行环境为:Windows Azure公有云,虚拟机为AMD双核,2GB内存,Windows Server 2012 64位操作系统,Sql Server 2012数据库。整个系统共由6个虚拟机构成,分别为1个主计算节点、3个子计算节点、一个数据库服务器和一个文件及配置服务器。
4实验结果与分析
4.1算法效率分析
以对经度65°N -70°N,维度20°W -10°E之间的盐度数据进行处理为例。我们把这些数据大致均分到6个单独的数据文件,分别采用1个子计算节点、2个子计算节点和3个子计算节点来重复处理这些数据,实验发现用2个子计算节点比1个子计算节点节约了大约45%的时间,3个子计算节点比1个子计算节点节约了大约62%的时间。以上可以看出,利用云计算技术,我们可以快速部署相应虚拟机来实现分布式计算,有效提高计算效率、降低计算成本,同时又避免了自己搭建分布式计算环境的麻烦。
该区域原始盐度数据量为1 002 773条记录,首先按测量深度进行归并后得到11 250条有效数据,再经按测量点进行盐度数据归并运算后得到1082条记录,最后按测量时间以月为单位归并后得到513条有效数据。容易看出,算法第一次执行归并时,数据量从百万级别降低到万的级别,执行第二次归并后从万的级别降低到千的级别,最后降低到百的级别。而每次归并算法的时间复杂度都为O(n),因此整个算法的时间复杂度主要取决于第一次的数据归并算法,即为O(n)。
4.2盐度在北极格陵兰海地区的分布
我们提取了2003-2012年北极格陵兰海地区65°N -85°N、20°W -10°E的全部盐度数据。由于北极很大一部分时间是处于极夜,所以我们注重于从每年的第72天到第272天(3~9月)的数据。最后得出所研究区域10年内的数据分布情况。
图5是研究区域盐度在10年内的年平均值。图6是研究区域在10年内的月平均值,这里都是取的1200米的深度平均。从图5可以看出,2003年盐度最低,其次就是2006年的盐度相对比较低。从图6可以看出,盐度在3月到5月整体稳定,但在6月出现明显下降,之后从7月到9月持续增长,上升趋势明显。 图7给出了盐度在研究区域10年内的平均分布三维图,从图中可以看出,盐度整体处于相对稳定的状态, 起伏幅度不大。
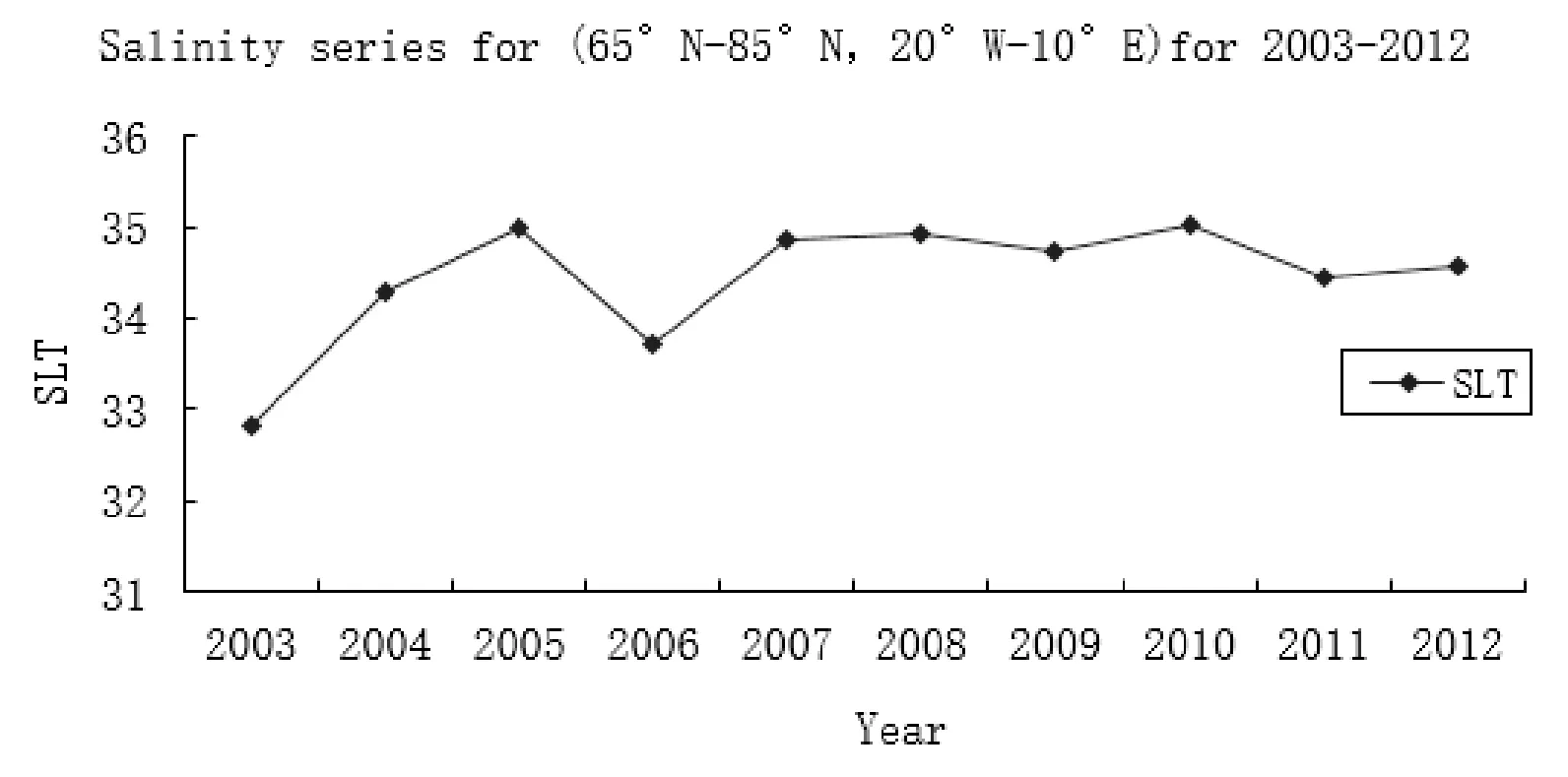
图5 盐度在研究区域的10年的年平均值
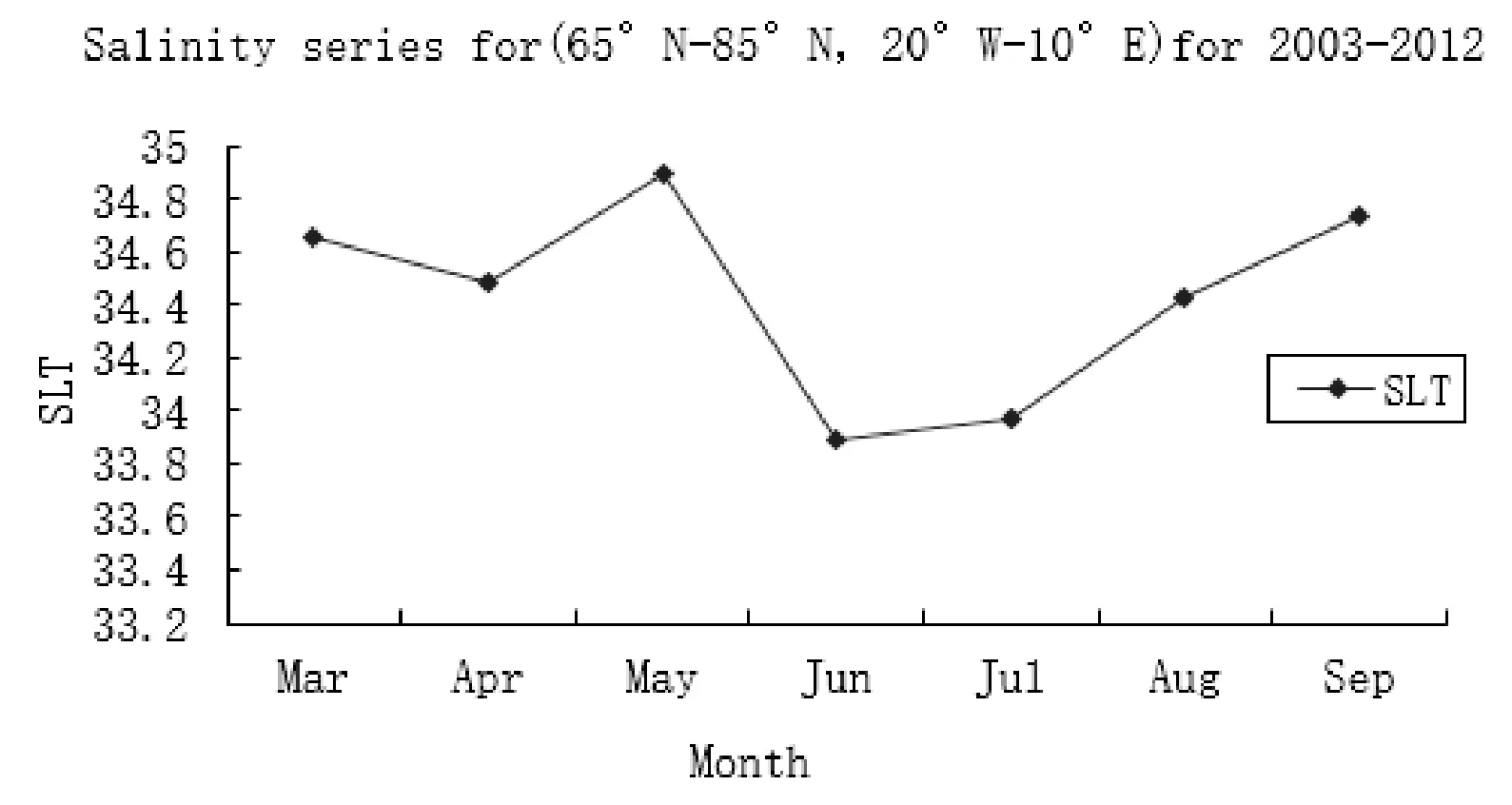
图6 盐度在研究区域的10年的月平均值
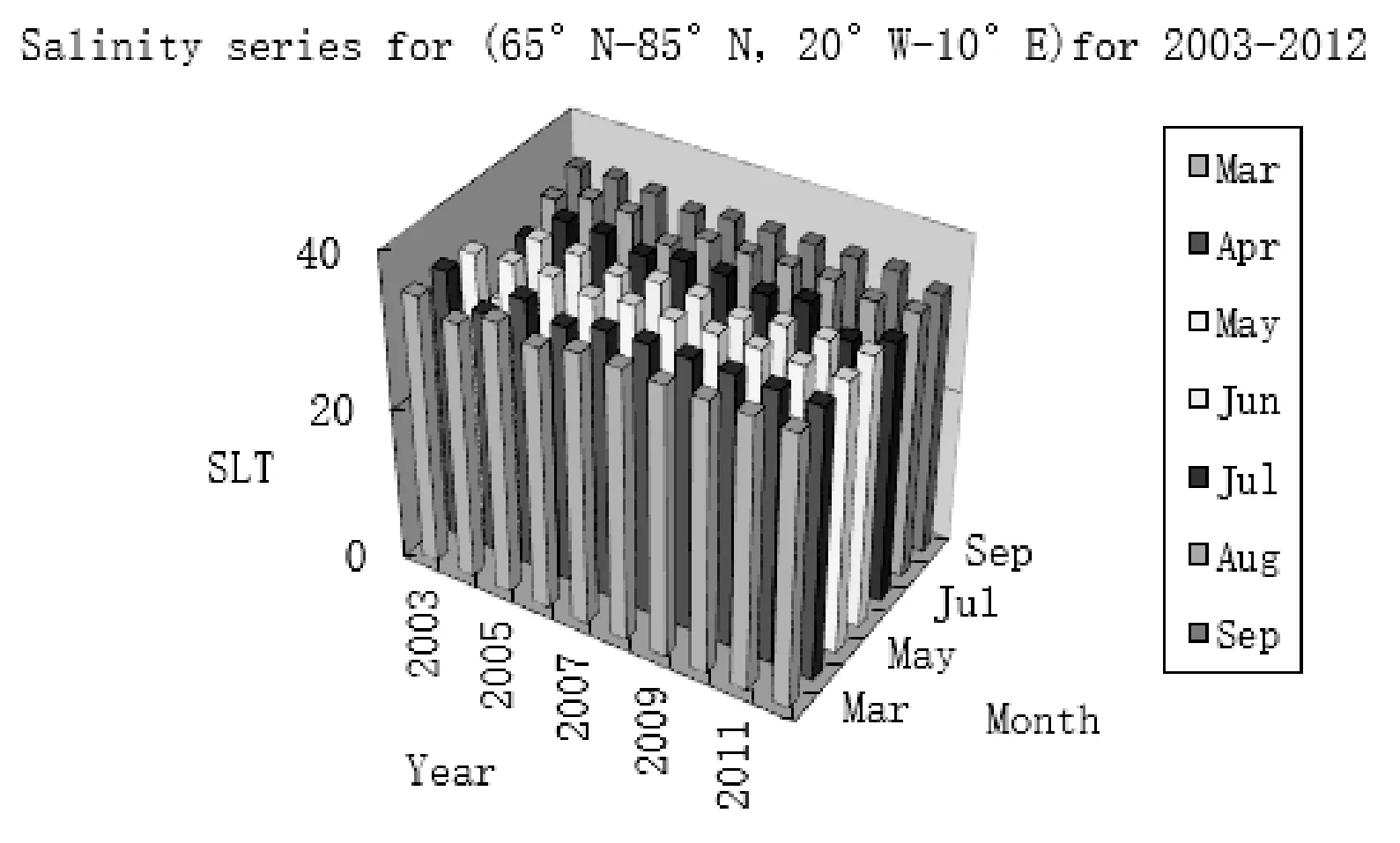
图7 盐度在研究区域的整体平均值分布
通过对原始的海量盐度数据进行归并计算后,我们以非常直观的图形,描绘出了10年来格陵兰海地区的海水盐度的变化,为后续研究提供有力的数据支持。
5结语
海洋盐度数据量非常庞大,而受制于北极气候条件和现有科考条件等限制,北极地区的盐度数据无论是在时间跨度、经纬度特征还是数据采样分布等属性上都不规整,这为数据的提取带来了很大难度。本文对北极海洋盐度数据的提取只是一个初步的尝试,但为温度、浮游生物等后续数据的提取有重要的借鉴意义。对于特别巨大的数据,可以利用本文的方法把原始数据划分为多个数据集,并利用云计算技术同时进行分布式归并运算,最后把归并后的数据再集中到一起进行总的归并后得到最终结果。云计算按需付费、高可扩充性、廉价等特点尤其适合用于开展地理和环境方面大规模的科学计算和研究,不但可以大大提升数据处理效率,还有效避免了自己建立传统的分布式计算环境的复杂性、降低计算成本。本文的研究成果为后续海洋温度数据和海洋浮游植物数据的提取以及三者之间关系的研究打下了良好的基础。
参考文献
[1] 陈建,张韧,王辉赞,等.Matlab对基于二进制-XML混合格式的SMOS盐度数据的提取方法与实现[J].海洋通报,2011(6):692-696.
[2] 朱江,周广庆,闫长香,等.一个三维变分海洋资料同化系统的设计和初步应用[J].地球科学(D辑),2007,37(2):261-271.
[3] Stroeve J,Holland M M,Meir W,et al.Arctic sea ice decline: faster than forecast[J].Geophysical Research Letters,2007,63(1):1-11.
[4] Qu B,Gabric A J,Matrai P A.The Satellite-Derived Distribution of Chlorophyll-a and its Relation to Ice Cover,Radiation and Sea Surface Temperature in the Barents Sea[J].Polar Biology,2006,29:196-210.
[5] 王颖,李肯立,李浪,等.纵横多路并行归并算法[J].计算机研究与发展,2006,43(12):2180-2186.
[6] 范时平,汪林林.一种基于数据分块的快速原地归并算法[J].计算机科学,2004,31(8):204-208.
[7] 姜忠华,徐文丽,刘家文,等.智能归并排序[J].电子设计工程,2011,19(21):53-55.
[8] 工业与信息化部电信研究院.云计算白皮书[R].2012.
[9] 李国杰.应用为先,统筹规划——关于云计算发展策略的思考[M]//中国信息化形势分析与预测.社会科学文献出版社,2012:107-120.
[10] Antonio,Corradi,Mario,et al.VM consolidation:A real case based on OpenStack Cloud[J].Future Generation Computer Systems,2014,36:118-127.
[11] Amazon EC2 Instances-Cluster Networking[EB/OL].http://aws.amazon.com/ec 2/instance-types.
[12] Armbrust M,Fox A,Griffith R,et al.A view of cloud computing[J].Communications of the ACM,2010,53:50-58.
收稿日期:2014-12-08。国家自然科学基金项目(41276097,4130 1514);江西省高性能重点实验室项目(PKLHPC1303)。朱晓辉,副教授,主研领域:计算机软件与理论。瞿波,副教授。任红健,副教授。
中图分类号TP391
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.07.021
RESEARCH ON SALINITY DATA EXTRACTION ALGORITHM FOR GREENLAND SEA IN CLOUD COMPUTING ENVIRONMENT
Zhu Xiaohui1Qu Bo2*Ren Hongjian1
1(SchoolofComputerScienceandTechnology,NantongUniversity,Nantong226019,Jiangsu,China)2(SchoolofScience,NantongUniversity,Nantong226019,Jiangsu,China)
AbstractOcean salinity has close relationship with ocean temperature and marine phytoplankton, and is one of the important parameters in the study of the influence of ocean circulation and ocean on climate. This paper discusses in detail the extraction of salinity data, of which the world ocean information database of American National Oceanographic Data Centre (NOAA) is used as the data resource, and the area of the Greenland Sea in Arctic within 20°W - 10°E, 65°N - 85°N is taken as the studying region. We propose a multi-steps merging algorithm for salinity data with a time complexity of O(n), it utilises the characteristics of Microsoft Azure public cloud that pay-on-demand and dynamic expansion to capture the cheap and convenient computation resources, and greatly improves computation efficiency. The algorithm has strong scalability and is able to dynamically adjust the required computation resources according to actual computation demand, therefore can meet the demands of different computation sizes. Experimental result shows that this algorithm can fast analyse and merge massive original salinity data and creates the formatted salinity data in 3 dimensions: longitude and latitude, time and salinity.
KeywordsSalinityGreenland seaLongitude and latitude coordinatesData extractionMerging algorithmCloud computing
