用于表情识别的半监督学习自适应提升算法
2016-07-19吴会丛贾克斌
吴会丛 贾克斌 蒋 斌
1(河北科技大学信息科学与工程学院 河北 石家庄 050018)2(北京工业大学电子信息与控制工程学院 北京 100124)
用于表情识别的半监督学习自适应提升算法
吴会丛1贾克斌2蒋斌2
1(河北科技大学信息科学与工程学院河北 石家庄 050018)2(北京工业大学电子信息与控制工程学院北京 100124)
摘要针对半监督人脸表情识别算法在表情来源多样、姿态不一时准确率低的问题,在迁移学习自适应提升算法的基础上,提出一种新的半监督学习自适应提升算法。该算法通过近邻计算由训练集中的已标记样本求出未标记样本的类别,并借助AdaBoost.M1算法分别对多数据源的人脸表情样本和多姿态人脸表情样本展开识别,实现样本的多类识别任务。实验结果表明,与标号传递等半监督学习算法相比,该算法显著提高了表情识别率,且分别在多数据库和多姿态数据库上获得了73.33%和87.71%的最高识别率。
关键词人脸表情识别半监督学习自适应提升
0引言
近年来,人脸表情识别作为一种生物特征识别技术,已成为多媒体信息处理、人机交互、图像处理与模式识别等领域的重要研究课题[1,2]。在人脸表情识别过程中,样本标记起到了重要的作用,但是并不容易获取。由于半监督学习[3]能够利用少量的标记样本和大量的未标记样本构建学习模型,研究者将其应用于人脸表情识别领域以解决标记样本不足的问题,提高人脸表情识别的实用性。
半监督学习的目的是借助大量的未标记样本参与训练以弥补训练样本不足的缺陷。然而,专业数据库中人脸表情图像数量的不足限制了半监督学习在表情识别中的发展。因此,需要寻找一种方案来解决数据量不足的问题,以便更好地完成半监督学习在人脸表情识别中的应用。解决问题的思路有两个:其一是将多个数据库放在一起使用,进行多数据库联合实验。该方法具有以下两个优点:第一,能够收集大量的未标记样本,方便研究者复原实验过程,使得在该数据库上得到的实验结果更具有说服力;第二,在实际生活中,我们面对的人群是多种多样的,多数据库有利于我们模拟实际情况。所以使用多数据库进行半监督学习实验的做法,具有很大的优势。其二是将多姿态图像作为样本,参与半监督人脸表情识别。该方法对于在现实环境中识别多姿态的人脸表情图像具有重要的实际意义。
目前,针对多数据库、多姿态表情识别的半监督学习的研究还处于起步阶段。针对多数据库条件下的表情识别问题,文献[4]提出了一种新的迁移子空间学习算法,在JAFFE、CK和Feedtum数据库两两组合成的数据集上取得了一定的效果。对于多姿态条件下的表情识别问题,主要通过改进特征提取方法来提高样本识别的正确率。文献[5]采用了张量脸结合流形学习的方法来解决多姿态条件下的人脸识别问题。文献[6]提出了基于正交鉴别向量的算法来克服人脸姿态变化对识别造成的干扰。文献[7]将基于子空间的人脸表征看作一个回归问题,因此采用了岭回归和线性回归的方法来处理人脸的姿态变化问题。文献[8]使用嵌入式马尔科夫模型方法处理人脸的不同姿态,获得了比传统的基于构件的分类器更好的识别率。
为进一步提升多数据库、多姿态条件下的表情识别率,本文引入了迁移学习自适应提升(TrAdaBoost)[9]算法中的知识迁移方式,提出了一种新的基于半监督学习的自适应提升(SSL-AdaBoost)算法。选择引入TrAdaBoost算法有以下两点原因:其一,该方法是迁移学习理论的代表性算法,既能保证知识迁移效果,又具有结构简单、便于操作的优点;其二,该方法以AdaBoost算法为基本框架。而在半监督学习中出现了不少基于AdaBoost框架的算法,如SemiBoost[10]算法、ASSEMBLE[11]算法以及RegBoost[12,13]算法等,为TrAdaBoost算法改进为半监督学习算法提供了可能性。
1算法原理分析
1.1TrAdaBoost算法原理
TrAdaBoost算法的基本原理如下:
设Xs表示源域内和目标域数据分布相同的样本,Xd表示源域内和目标域数据分布不同的样本。令X=Xs∪Xd,Y={0,1}表示样本标记,c表示将X映射到Y的布尔函数,c(x)表示样本x的标记。
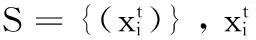
如果符合t≤N、εt<0.5的条件,算法开始循环:
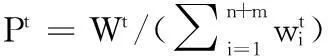
(2) 依据分布Pt,采用WeakLearn得到样本的分类结果ht:X→Y;
(4) 设参数βt=εt/(1-εt);
(5) 更新权重向量:
(1)
如果达到收敛条件,算法结束,否则继续执行。
最后,输出最终分类器hf(x):
(2)
其中,「⎤是上取整函数,「N/2⎤表示不小于N/2的整数中最小值。

1.2SSL-AdaBoost算法原理
本文提出的SSL-AdaBoost算法在保留TrAdaBoost算法的知识迁移能力的同时,对TrAdaBoost算法进行两方面的改进:一方面,TrAdaBoost算法属于监督学习算法,算法需要训练样本的标记信息,而SSL-AdaBoost算法是一个半监督学习算法。按照半监督学习的要求,训练集由标记样本和未标记样本组成。因此,需要选取一定比例的训练样本为未标记样本,余下的为标记样本,从而兼顾了半监督学习的要求和算法的分类性能。为了进一步消除未标记样本对分类的不利因素,借助SemiBoost和ASSEMBLE等算法的处理方式,利用训练集中的已标记样本,通过近邻计算求出训练集中未标记样本的类别。另一方面,TrAdaBoost算法用于解决二类分类问题,而人脸表情识别却需要完成多种表情的识别任务。由于TrAdaBoost算法可以看作AdaBoost算法的扩展,而AdaBoost算法是二类分类方法,本文可以借助一种用于实现多类分类任务的AdaBoost算法,即AdaBoost.M1算法,完成样本的多类识别。
SSL-AdaBoost算法的基本原理如下:
令Xs表示源域内和目标域数据分布相同的样本,Xd表示源域内和目标域数据分布不同的样本。令X=Xs∪Xd。
(3)
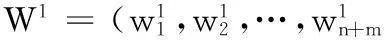
如果符合t≤N、εt<0.5的条件,算法开始循环:
(2) 依据分布Pt,采用WeakLearn得到样本的分类结果ht:X→Y;
(4) 设参数βt=εt/(1-εt);
(5) 更新权重向量:
(4)
如果达到收敛条件,算法结束,否则继续执行。
最后,输出最终分类器hf(x):
(5)
2实验结果及分析
本文实验以人脸表情识别为应用背景,共分为两部分:多数据库条件下的半监督学习实验和多姿态条件下的半监督学习实验。
2.1多数据库人脸表情识别实验
多数据库条件下的半监督学习实验采用180幅日本女性人脸表情数据库JAFFE(JapanFemaleFacialExpression)[14]的图像、240幅美国卡内基梅隆大学动作单元编码数据库CK(Cohn-KanadeAU-CodedDatabase)[15]的表情峰值图像以及荷兰内梅亨大学人脸数据库RaFD(RadboudFacesDatabase)[16]的57个成年人的342幅正面像。待分类样本分别具有生气、厌恶、恐惧、悲伤、高兴和惊奇表情,各数据库中每种表情的图像数量基本相等。因为要进行多数据库联合实验,所以在获取人脸图像后,对所有人脸图像进行尺度归一化,将图像大小设为168×120。然后,采用直方图均衡的方法对图像进行光照补偿。最后,通过PCA将数据维数降至40维,运用LDA实现对表情图像的特征提取。
为验证SSL-AdaBoost算法的效果,实验采用AdaBoost.M1算法、ASSEMBLE算法、RegBoost[12]算法和标号传递(LP)算法[17]作为基线算法。实验以k近邻分类器作为AdaBoost.M1、RegBoost和SSL-AdaBoost算法的基础分类器。设k值为11,算法的最大循环次数为10次。
首先,以JAFFE数据库为源域、CK数据库为目标域开展分类实验。按照表情类别,随机选取r比例的目标域样本和源域样本组成训练集,其中r分别取10%、20%、30%、40%和50%。因为实验采用180个JAFFE样本和240个CK样本,所以选取的目标域样本数量为r×180,余下的240-r×180个目标域样本组成测试集。令训练集中标记样本和未标记样本的比例为1。每个比例的样本数据各生成10组,算法识别率取10次实验的平均结果,实验结果如表1所示。从表1中可以看出,SSL-AdaBoost算法在不同比例下的平均识别率高于AdaBoost.M1和RegBoost算法。再以CK数据库为源域、JAFFE数据库为目标域进行对比实验,结果如表2所示。从表2中可以看出,各算法的识别率普遍不高,原因在于JAFFE数据库中的表情个体为日本女性,民族和性别情况单一,对同一种表情的表达强度近似。CK数据库中的个体以欧美人群为主,民族及性别情况十分复杂,对同一种表情的表达强度不一。所以将CK数据库作为源域,极大地增加了识别难度,但是本文提出的SSL-AdaBoost算法仍在10%~30%的比例下保持了最高的平均识别率。
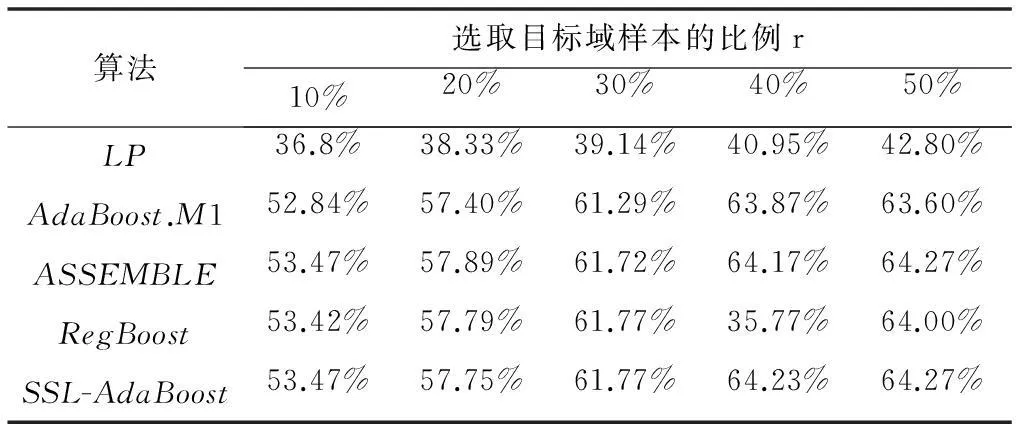
表1 JAFFE与CK数据库的识别率

表2 CK与JAFFE数据库的识别率
其次,以JAFFE数据库为源域、RaFD数据库为目标域开展分类实验,结果如表3所示。从表3中可以看出,在不同的数据库下,SSL-AdaBoost算法在不同比例下的平均识别率高于基线算法。再以RaFD数据库为源域、JAFFE数据库为目标域进行对比实验,结果如表4所示。实验结果表明,表3和表4的识别率高于表1和表2,原因在于JAFFE数据库和RaFD数据库的民族比较单一,前者为日本女性,后者为白种人。相比之下,CK数据库包含了世界各地的民族,所以数据的特征空间和数据分布不一致的问题更严重,干扰了半监督学习算法的识别效果。
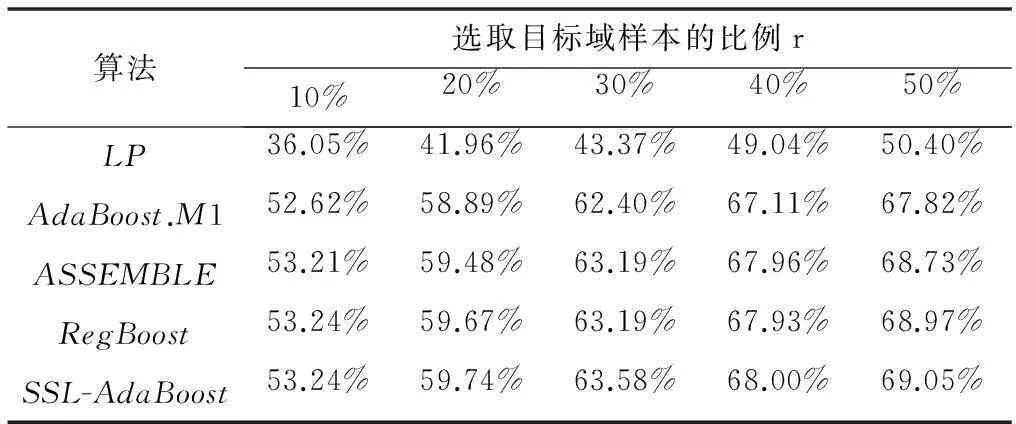
表3 JAFFE与RaFD数据库的识别率

表4 RaFD与JAFFE数据库的识别率
最后,以CK数据库为源域、RaFD数据库为目标域开展分类实验,结果如表5所示。再以RaFD数据库为源域、CK数据库为目标域进行对比实验,结果如表6所示。实验结果表明,SSL-AdaBoost算法在40%和50%比例下,相对于基线算法在识别率上仍具有优势。CK数据库和RaFD数据库均以西方人为主,西方人对同一种表情的表达方式比较丰富,因此增加了识别的难度。
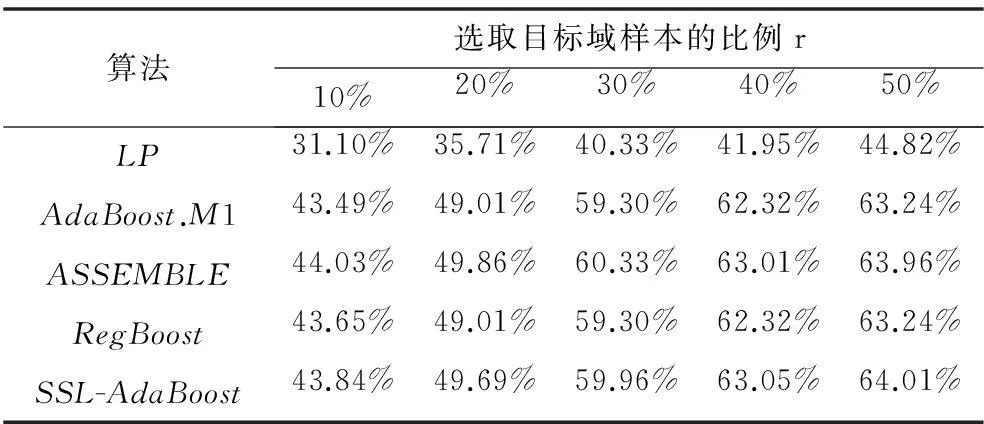
表5 CK与RaFD数据库的识别率
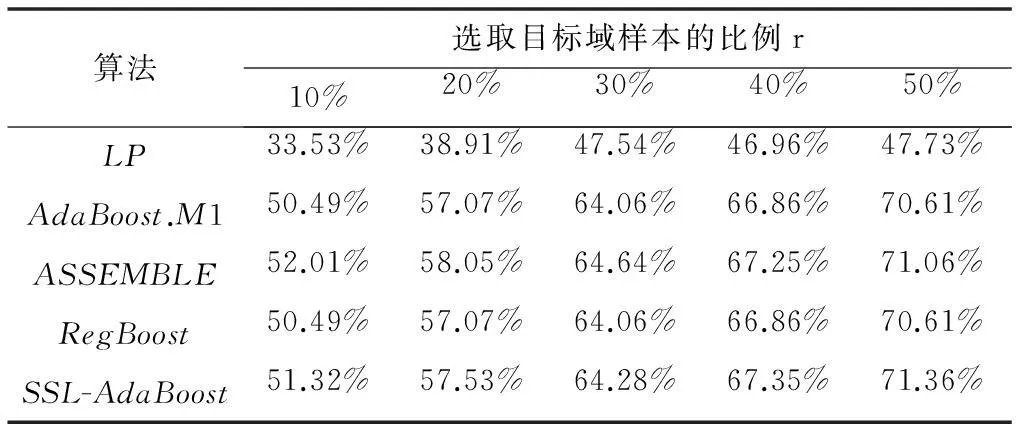
表6 RaFD与CK数据库的识别率
综上所述,SSL-AdaBoost算法在一定程度上克服了不同数据环境下的个体差异性对表情识别的干扰,有效地实现了对未标记样本的训练。与基线算法相比,SSL-AdaBoost算法在多数情况下具有更好的鲁棒性和识别率,对比实验证明了算法的有效性。
2.2多姿态人脸表情识别实验
多姿态条件下的半监督学习实验选择RaFD数据库和BHU数据库为实验对象。前者选取了57个人的6种基本表情、3个水平旋转角度(正面、135°和180°)的人脸图像,每个角度的图像数量为342幅。后者选取了8个人的两种表情(生气、高兴)、2个水平旋转角度(正面和水平旋转30°)的人脸图像。每个角度的图像数量为480幅。每种表情的图像数量相同。
首先,实验依靠图像处理软件,通过人工切分的方法,以前额发迹线到下颚为人脸的纵向切分范围,获取人脸图像,所有人脸图像的大小归一化为64×64。其次,通过直方图均衡化方法,对图像进行光照补偿。预处理后的实验样本如图1和图2所示。其中,图1从上到下分别为正面、135°和180°旋转角度的RaFD数据库的表情图像;图2从上到下分别为正面和30°旋转角度的BHU数据库的表情图像。最后,采用LDA算法作为样本的特征提取算法。

图1 RaFD数据库的实验样本

图2 BHU数据库的实验样本
实验采用AdaBoost.M1算法、ASSEMBLE算法、RegBoost算法以及LP算法作为基线算法。分别以k近邻分类器(k-NN)或反向传播神经网络分类器(BP-NN)作为算法的基础分类器。从中选取识别率高的分类结果作为最终的实验结果。算法的最大循环次数设为10次。
首先,以RaFD数据库的正面样本为源域、135°样本为目标域开展分类实验。采用k-NN作为基础分类器,设k值为3。随机选取r比例的目标域样本和源域样本组成训练集,其中r分别取10%、20%、30%、40%和50%。因为实验采用了正面及135°样本各342个,所以选取的目标域样本数量为r×342的整数,余下的342-r×342个目标域样本组成测试集。令训练集中标记样本和未标记样本的比例为1。每个比例的样本数据各生成10组,算法识别率取10次实验的平均结果,实验结果如表7所示。
其次,以RaFD数据库的正面图像为源域、180°图像为目标域进行对比实验。实验采用BP-NN作为基础分类器。实验结果如表8所示。
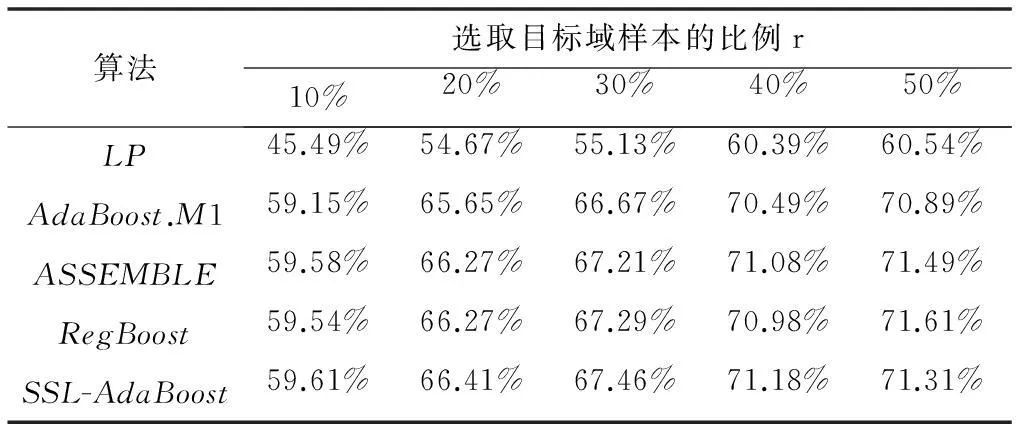
表7 RaFD数据库中正面和135°图像的算法分类正确率

表8 RaFD数据库中正面和180°图像的算法分类正确率
表7和表8的实验结果表明:一方面,算法识别率随着偏转图像在训练集中比例的增加而提高。既说明了特征空间和数据分布相同的样本在分类中起到了很大作用,也说明了在样本特征空间和数据分布不同的情况下,基线算法仅依靠抑制误分类样本无法获得更好的识别效果。而SSL-AdaBoost算法依靠知识迁移,有效地运用正面图像的表情特征,克服了样本特征空间和数据分布差异对半监督学习造成的干扰,在大部分比例下取得了比基线算法更高的识别率。另一方面,偏转造成了人脸器官的遮挡以及大量表情信息的缺失,严重影响了算法的识别效果。基线算法在信息缺失与噪声干扰的情况下,仅依靠少量偏转图像的表情特征不能更好地完成半监督学习任务。SSL-AdaBoost算法通过知识迁移,将正面图像的表情特征迁移到偏转图像的分类器构建之中,降低了信息缺失造成的干扰。在多姿态条件下,SSL-AdaBoost算法具有较好的鲁棒性。
最后,以BHU数据库的正面图像为源域、30°图像为目标域开展分类实验。实验设置与表7相同。实验结果如表9所示。从表9中可以看出,在BHU数据库上,SSL-AdaBoost算法依然在识别率上保持了优势。多姿态条件下的实验结果证明了SSL-AdaBoost算法的有效性。
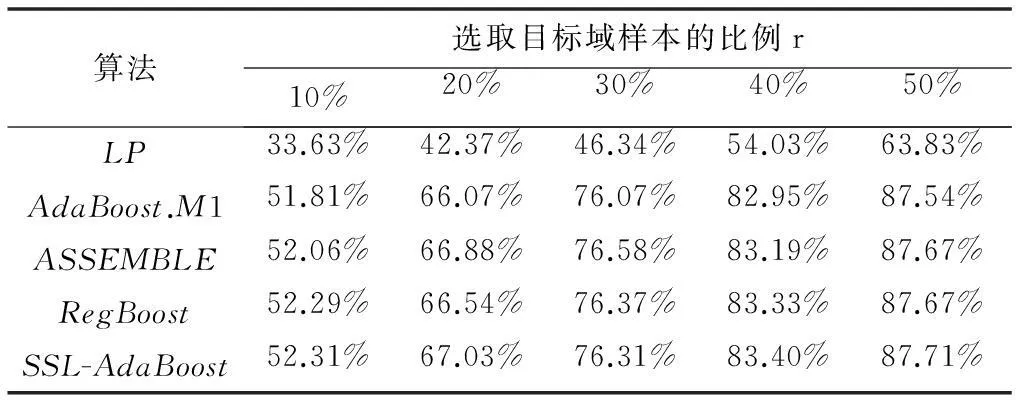
表9 BHU数据库中正面和30°图像的算法分类正确率
3结语
本文提出一种新的半监督学习自适应提升算法。该算法借助迁移学习理论中的知识迁移方法,在多数据库条件下将数据分布不同的样本表情特征迁移到分类器的构建中,在一定程度上克服了不同数据环境下的个体差异性对表情识别的干扰,有效地实现了对未标记样本的训练。此外,在多姿态条件下将正面图像的表情特征迁移到偏转图像的分类器构建中,降低了信息缺失造成的干扰。实验结果表明,本文算法在多数据库条件下有效地提高了算法的表情识别率;在多姿态表情图像上取得了比基线算法更高的识别率。
参考文献
[1] 刘帅师,田彦涛,王新竹.基于对称双线性模型的光照鲁棒性人脸表情识别[J].自动化学报,2012,38(12):1933-1940.
[2] 易积政,毛峡,IshizukaM,等.基于特征点矢量与纹理形变能量参数融合的人脸表情识别[J].电子与信息学报,2013,35(10):2403-2410.
[3]ChapelleO,SchölkopfB,ZienA.Semi-supervisedlearning[M].Cambridge:MITPress, 2006.
[4]YanHB,AngJrMH,PooAN.Cross-datasetfacialexpressionrecognition[C]//ProceedingsofIEEEInternationalConferenceonRoboticsandAutomation,Shanghai, 2011:5985-5990.
[5]LiWQ,ChenDS.Multi-posefacerecognitioncombiningtensorfaceandmanifoldlearning[C]//ProceedingsoftheIEEEInternationalConferenceonComputerScienceandAutomationEngineering.Shanghai:IEEEPress, 2011:543-547.
[6]WangJH,YouJ,LiQ,etal.Orthogonaldiscriminantvectorforfacerecognitionacrosspose[J].PatternRecognition, 2012,45(12):4069-4079.
[7]LiAN,ShangSG,GaoW.Coupledbias-variancetradeoffforcross-posefacerecognition[J].IEEETransactionsImageProcess, 2012, 21(1):305-315.
[8]LeePH,HsuGS,WangYW,etal.Subject-specificandpose-orientedfacialfeaturesforfacerecognitionacrossposes[J].IEEETransactionsonSystems,Man,andCybernetics-PartB:Cybernetics, 2012, 42(5):1357-1368.
[9]DaiWY,YangQ,XueG,etal.Boostingfortransferlearning[C]//Proceedingsofthe24thInternationalConferenceonMachineLearning,Corvallis, 2007:193-200.
[10]MallapragadaP,JinR,JainA,etal.SemiBoost:Boostingforsemi-supervisedlearning[J].IEEETransactiononPatternAnalysisandMachineIntelligence, 2009,31(11):2000-2014.
[11]BennettKP,DemirizA,MaclinR.Exploitingunlabeleddatainensemblemethods[C]//Proceedingsofthe8thACMInternationalConferenceonKnowledgeDiscoveryandDataMining,Edmonton:ACMPress, 2002:289-296.
[12]WangSH,ChenK.Ensemblelearningwithactivedataselectionforsemi-supervisedpatternclassification[C]//ProceedingsofInternationalJointConferenceonNeuralNetworks,Orlando,Florida,USA, 2007.
[13]ChenK,WangSH.Semi-supervisedlearningviaregularizedboostingworkingonmultiplesemi-supervisedassumptions[J].IEEETransactiononPatternAnalysisandMachineIntelligence, 2011,33(1):129-143.
[14]SuwaM,SugieN,FujimoraK.Apreliminarynoteonpatternrecognitionofhumanemotionalexpression[C]//Proceedingsofthe4thInternationalJointConferenceonPatternRecognition,Kyoto,Japan:InstituteofElectricalandElectronicsEngineers, 1978:408-410.
[15]MaseK,PentlandA.Recognitionoffacialexpressionfromopticalflow[J].IEICETransactions,1991,E74(10):3474-3483.
[16]EssaI,PentlandA.Coding,analysis,interpretationandrecognitionoffacialexpressions[J].IEEETransactiononPatternAnalysisandMachineIntelligence,1997,19(7):757-763.
[17]ZhuXJ,GhahramaniZ.Learningfromlabeledandunlabeleddatawithlabelpropagation[R].TechnicalReportCMU-CALD-02-107,CarnegieMellonUniversity,2002.
AN ADAPTIVE BOOSTING ALGORITHM WITH SEMI-SUPERVISED LEARNINGFORFACIALEXPRESSIONRECOGNITION
Wu Huicong1Jia Kebin2Jiang Bin2
1(College of Information Science and Engineering, Hebei University of Science and Technology, Shijiazhuang 050018, Hebei, China)2(College of Electronic Information and Control Engineering, Beijing University of Technology, Beijing 100124,China)
AbstractTo address the low recognition rate of traditional facial expression recognition algorithm with semi-supervised learning caused by diverse expressions sources and different face attitudes, we propose a novel semi-supervised learning adaptive boosting (SSL-AdaBoost) algorithm based on transplanting learning adaptive boosting algorithm. The algorithm determines the categories of unmarked samples by calculating the marked samples concentrated in training through near neighbour, and recognises by means of AdaBosst.M1 algorithm the facial expression sample with multi-data sources and the facial expression sample of multiple attitudes respectively to realise the multi-category recognition task of samples. Experimental results show that the algorithm significantly improves the expression recognition rate in comparison with the label propagation method and many other semi-supervised learning methods. Besides, it achieves the highest recognition rate by 73.33% on multiple databases and 87.71% on multi-attitude database respectively.
KeywordsFacial expression recognitionSemi-supervised learningAdaptive boosting
收稿日期:2015-03-03。河北省自然科学基金项目(F201420 8113)。吴会丛,博士生,主研领域:数据挖掘,演化计算。贾克斌,教授。蒋斌,博士生。
中图分类号TP391.4
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.06.065
