云资源状态监控研究综述
2016-07-19彭甫阳王东霞
洪 斌 彭甫阳 邓 波 王东霞
1(北京系统工程研究所 北京 100101)2(信息系统安全技术重点实验室 北京 100101)
云资源状态监控研究综述
洪斌1彭甫阳1邓波1王东霞2
1(北京系统工程研究所北京 100101)2(信息系统安全技术重点实验室北京 100101)
摘要云计算通过网络共享成功实现了计算资源的高效利用。云资源分配的动态性、随机性、开放性使得云平台的服务质量保障难题日益突出。云环境下资源状态的监控技术通过深入挖掘分析监控数据,及时发现计算资源的异常运行状态。根据历史运行数据等对资源的未来使用状态做出预测。以便及时发现潜在的性能瓶颈和安全威胁,为用户提供可靠稳定的云服务。结合实例介绍了在资源状态监控方面有代表性的研究方法,包括概率分析、方程拟合、聚类分析等方法,并对比了各类方法的性能特点及局限性。最后讨论了云资源状态监控技术在数据复杂度和规模等方面所面临的技术挑战,并指出了原始数据去冗降维、算法设计突出非监督化、计算任务向终端推送、分析结果协同增效等未来发展趋势。
关键词云计算虚拟资源状态监控
0引言
继分布式计算、网格计算、对等计算之后,云计算作为一种高效的新型资源共享模式,已经被众多用户接纳和使用。云服务的核心是服务商通过网络,向用户提供包括计算、存储、网络、应用软件等计算资源,并向用户保障一定的服务质量。由于消费者需求波动的难以预测性和软硬件故障等原因,运营商需要实时监控全局的资源使用情况并动态地调整相关资源的配置,为用户提供稳定可靠的云计算资源。
目前,国内外主流云服务提供商均已经将资源运行状态数据作为一种关键服务向用户开放,但这些资源状态反馈往往止步于资源运行数据的实时反馈和简单告警,并不提供针对这些数据的深入挖掘分析,更无法为用户提供有效的异常状态告警和未来资源使用情况预测。因此,云服务SLA(Service-Level Agreement)违约甚至宕机等事件时有发生,给运营商和用户造成的损失难以估量。
2014年8月全球最大的云服务供应商Amazon连续发生两次“宕机”事件(注:指云计算服务中断),导致全球范围的消费者无法通过Amazon.com、Amazon移动端以及Amazon.ca等网站进行购物。据推测两次宕机致使Amazon损失了约700万美元。同时,数以万计的AWS(Amazon Web Service)用户所遭受的损失更是难以估量。而近年来,微软、IBM、谷歌等云计算领域的领军企业也同样遭受着宕机的困扰和威胁。如何利用数据分析手段,及早发现云环境中的资源状态异常,甚至提前预测未来时间内资源状态的变化趋势,成为备受关注的焦点问题。
云资源状态监控研究通过深入挖掘分析监控数据,及时发现计算资源中的异常状态,并根据历史运行数据等对资源的未来使用状态作出预测。云资源状态监控服务为运营商和用户提供准确可靠的资源运行状况反馈,使其能够及时采取应急措施规避云服务宕机或资源不可用等严重后果。
1云资源状态分析概述
云计算通过互联网和终端将动态的资源通过“按需付费”的形式提供给用户,实现了大规模资源的高效利用。然而,资源动态分配带来的天然弊端就是资源运维难度增大,计算资源可靠性成为挑战。成千上万的用户同时访问和使用云资源时,云服务提供商必须合理地分配和调度资源以保证服务质量,避免由于违背SLA协定而遭受损失。
云环境资源出现异常状态的原因包括管理员操作不当、软硬件故障、资源使用过量、恶意用户行为等。云资源状态分析的主要研究内容是收集并分析资源监测模块测得的CPU利用率、服务响应时间等基础数据,正确识别出资源所处的状态,及时掌握云计算平台的全局资源使用状态,并帮助云服务提供商及早地发现云服务性能瓶颈并定位故障节点等。而通过分析资源的历史使用情况和用户使用需求特征,动态地对资源未来的使用情况和变化趋势进行预测,有助于在异常发生前采取资源调度和负载均衡等措施,避免服务异常造成损失。
云计算环境下资源状态分析作为运维决策基础,为计算资源状态反馈、优化配置、服务性能预测以及异常状态防范提供核心技术支持。
1.1云资源状态监控
通过网络,云计算服务提供商向用户提供的计算资源和软件服务包括计算、存储、网络、应用软件等。同时,云服务提供商必须保障这些资源或服务达到用户要求的性能指标,否则其将为此向用户支付损失赔偿。例如,当用户租用若干台虚拟机进行Map-Reduce任务计算时,这些性能指标就可能包括每台虚拟机必须拥有的CPU计算速度和内存容量等。如果在云计算资源使用的高峰时期,这些虚拟机的性能指标就可能出现下滑,导致计算任务超时完成,甚至无法进行。严重时,甚至可能出现大片区域范围云服务宕机等现象,给用户带来灾难性损失。为了避免这种情况的出现,云服务商必须对其管理的所有的物理资源、虚拟资源的运行状态进行实时监控。这些监控指标包括计算速度、存储容量、网络延迟、软件可用性等。
通过将各类分布式监控系统部署在提供云服务的服务器或物理计算节点上,便能实现云环境下资源的CPU、内存、I/O、网络等实时性能监控数据的采集。在此基础上,云环境下资源状态的监控与分析才得以展开。为方便描述,本文将云环境下资源的运行状态划分为正常、可疑、异常、数据不足等4个状态类别如下:
• 正常状态:当云环境下各种资源足够满足SLA中提出的功能和性能要求,并且短期内不存在使用失败的风险时,称此时资源处于正常状态。
• 异常状态:当云端所提供的资源不能满足SLA所协定的服务需求,并已经导致用户使用资源失败时,则称资源处于异常状态。
• 可疑状态:如果云端提供的资源虽然暂时未给用户使用带来明显影响,但资源性能不稳定或存在违背SLA协定的风险时,称资源处于可疑状态。
• 数据不足:如果当前可供分析的监控数据不足以获得可靠结论或进行预测,则称之为数据不足。
云环境下资源状态监控的任务是,对监控数据采集系统获得的原始数据进行预处理与分析,进而判断资源的使用状态(正常可疑异常数据不足),及时发现计算资源的异常状态。而云环境下资源状态预测的任务则是分析未来时间的资源使用状况变化趋势,实现云环境下资源异常状态的提前告警。其对及早采取措施规避SLA违约、保障云服务的可靠性有积极意义。
1.2监控系统框架
一般而言,云环境下资源状态监控系统的框架如图1所示,由资源状态监控数据采集和存储系统、监控数据分析模块以及分析结果反馈展示模块构成。
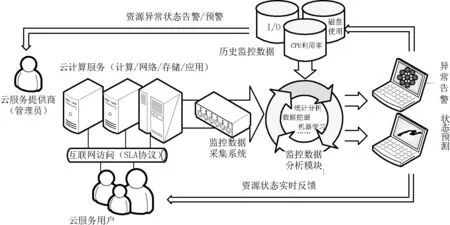
图1 云环境下资源监控系统框架
其中,资源状态数据采集系统负责采集云环境下计算、网络、存储、应用等各类资源的使用状态。随后基于这些数据,状态分析系统确定各类模型参数,并据此作出资源数据实时状态的判断,并对已经出现或可能出现的异常提出告警,为云服务供应商和租用云服务的用户提供资源状态报告和异常预警。
1.3云监控服务现状
云计算发展至今,全球范围内的云计算市场生态已经逐步成形。传统IT巨头纷纷通过提供云计算服务,向用户提供有偿的计算、存储和网络资源。同时,为了保障服务质量,各公司也研发了相应的云环境下资源监控与告警工具,如表1所示。
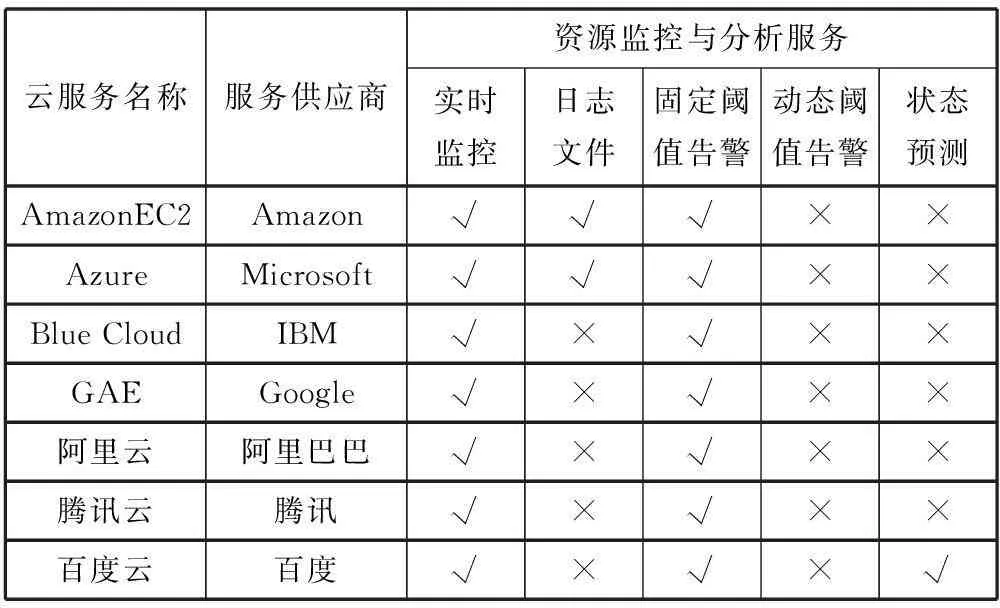
表1 国内外主要云服务资源监控与告警情况
亚马逊云服务Amazon EC2(Amazon Elastic Compute Cloud)作为全球范围最大的云服务提供商,其产品已于2014年3月正式通过美国国防部云安全模型认证,这标志着其云服务的性能已达到军事应用标准。Amazon EC2推出资源监控工具CloudWatch能为用户提供其所购买资源使用情况的详细信息,包括CPU利用率、网络流量、Web服务响应时间等。用户可以通过设定相应的固定阈值来触发告警,甚至触发服务器自动停机等异常响应措施。此外,当云服务状态发生异常并导致用户损失时,CloudWatch也为用户提供系统操作运行的日志文件和简单索引、统计等功能,但并不提供对日志文件数据的深入挖掘工具。用户无法基于这些原始数据进行异常起因溯源机制、资源未来状态预测等分析。Microsoft云服务Azure向用户开放的资源监控服务、Google公司推出的谷歌应用引擎GAE(Google App Engine),以及IBM公司推出的多层次云服务蓝云(Blue Cloud)等为用户提供的资源监控功能与Azure基本一致。
截至2014年11月,百度云用户日前总数已突破2亿人次。其资源监控模块“云监控BCM”旨在为用户提供关于磁盘空间、内存、流量等关键指标的实时监控和未来预测,用户还可以据此自定义资源报警策略。但BCM起步较晚,实际上仍处于公测阶段,资源监控技术尚不成熟。阿里云为用户提供了较为完整的资源监控与告警服务,但其异常状态判断仅仅基于与预设固定阈值的简单比较。例如,对云主机的CPU利用率进行连续采样,当五个采样周期获得的平均值均高于90%时,则通过邮件形式向用户发出告警。
综上,目前国内外的大型公有云服务提供商推出的资源监控服务,往往止步于提供资源使用现状的实时反馈。相应的资源使用告警也是普遍基于固定阈值的简单判断。这种基于固定阈值的告警机制需要事先设定警告阈值,其依据往往是基于经验或历史数据,资源告警阈值与资源的实际使用场景脱离,容易造成异常状态的迟报、漏报或误报,准确率较低。此外,当前主流云服务提供商提供的监控服务基本属于响应式异常状态感知,不能实现对未来资源使用情况的预测,告警意义亦十分有限。
2云资源状态监控技术
为了获取云环境下资源的使用情况,往往需要对监控数据采集系统获得的原始数据进行预处理与分析,进而判断资源的使用状态(正常可疑异常数据不足)。对数据作预处理的目的是为了提高后续数据分析的准确性,而对现有状态数据进行异常识别则是异常监测技术的核心问题。
在这方面,当前主流技术的理论基础包括概率分析、数据分类、最近邻分析、聚类分析等。下面分别介绍各类方法的前提假设、基本思路、应用实例和其相应的性能分析。
2.1基于统计分析的状态监控技术
基于统计分析的云资源状态监测技术的基本假设是,云环境下用户对资源的正常使用情况符合特定统计分布规律,能用统计模型加以描述,而资源的异常状态是该统计模型中的小概率事件。这种方法原理较为直观,在线异常识别只需将新数据带入模型计算便可获知结果,算法复杂度一般为O(1)。但云环境下资源伸缩弹性大,分析历史数据获得的统计模型难以适应资源状态不断变化的分布特征。此外,为了获得精确的统计模型,我们往往需要将训练数据中的异常状态点剔除。
文献[3]提出了一种基于EM(Estimation-Maximization)算法的贝叶斯概率计算模型,利用无标签数据集来估计监控模型的参数,实现资源状态判断。该监控模型首先给出资源状态的分类(正常/可疑/异常)并将数据点随机分类完成初始化。随后,使用EM算法迭代计算,围绕贝叶斯准则循环计算不同状态出现的概率p(State)、各状态下产生某数据点的概率p(Data Point|State)和某数据点出现时资源处于各状态的概率p(State|Data Point)等,如式(1),直至算法收敛。
(1)
当监控数据采集模块获得新的资源状态数据时,便可根据上述概率模型给出资源所处的状态及相应概率估计,即p(State|Data Point)。这种模型以大量迭代计算的代价,摆脱了其对标签数据的依赖。其不足之处在于,在准确实现状态判断的同时,需要避免增大计算量。
2.2基于数据分类的状态监控技术
基于数据分类的云环境资源状态异常监测技术的基本假设和思路是:通过学习已分类的资源使用情况数据,能够获得有效的分类模型,而异常数据点不属于任何分类,据此识别异常状态,文献[1]中给出的示意如图2所示。在云资源状态监控中,可以使用的分类原理包括基于神经网络、贝叶斯网络、支持向量机、决策树等多种方法。基于数据分类的状态异常监测可用分类算法较多,而且每次判断实时资源状态时,只需将数据点带入事先确定的分类模型即可获得结果,计算量小,可扩展性较强。
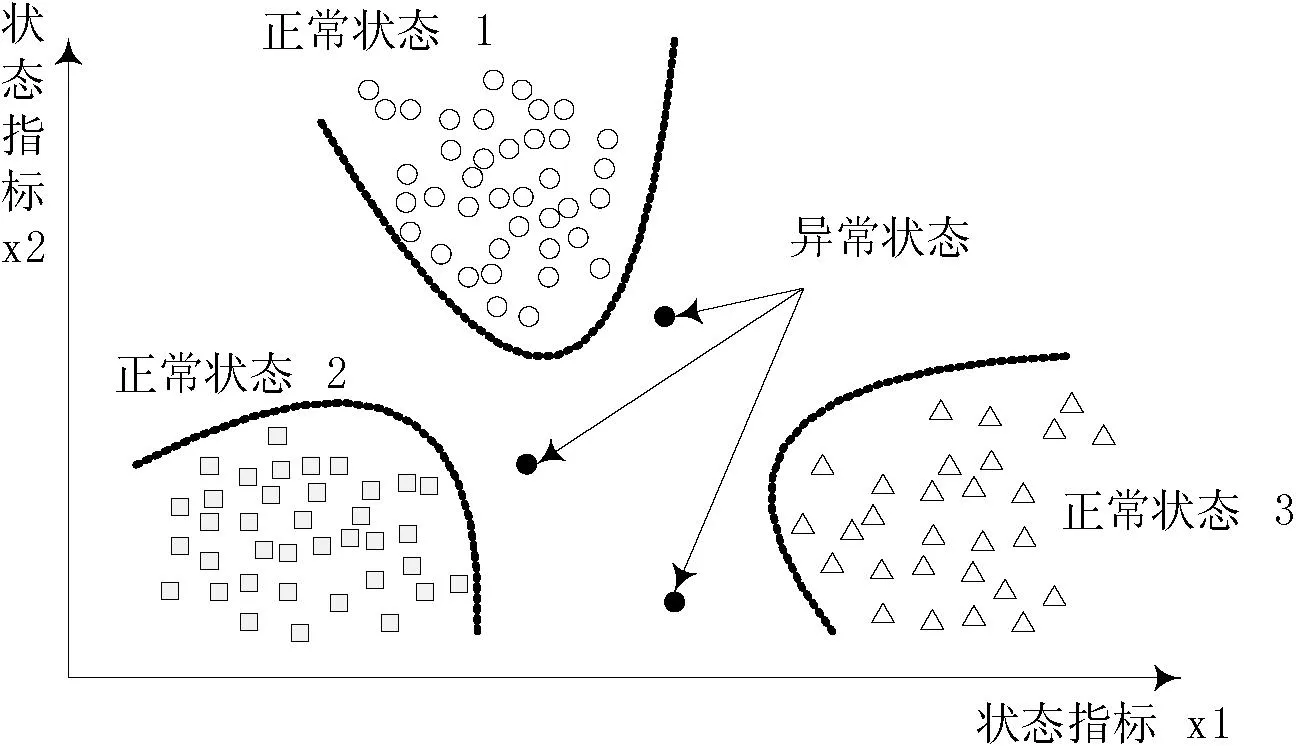
图2 基于数据分类的异常状态识别
这类方法的局限在于,其一般属于半监督式学习法,需要获得已分好类别的正常状态数据集,这点在云环境下往往难以实现。
2.3基于最近邻分析的状态监控技术
基于最近邻分析和聚类分析的云环境资源状态异常监测技术的基本假设和思路相近,其中最近邻法认为:正常资源状态对应的数据点的邻居节点稠密,距离其他数据点距离相对较近,而异常数据点的邻居节点稀疏,距离其他数据点距离相对较远。基于最近邻分析的方法包括k最近邻法、自组织图法SOM(Self-Organizing Maps)和相对密度法等。k最近邻法计算最近的k个状态数据点的距离均值,超过阈值则认为是异常状态。而相对密度法则计算指定范围内临近状态数据点的个数,低于设定阈值则认为是异常状态。基于聚类分析的方法与最近邻的主要区别是,其是根据计算当前数据点与聚类核心节点的距离来识别正常与异常数据点,主要包括DBSCAN和K-means方法等。
文献[4]介绍了一种基于自组织图的资源异常状态监控的方法,称为UBL(Unsupervised Behavior Learning)方法。如图3所示,UBL首先将不同时刻资源状态值向量映射为状态图上不同的神经元点,并通过相似度迭代计算等方法使得经常出现的正常数据点距离邻居节点近,而“有异常趋势”或已经处于“异常”状态的点由于出现次数少,训练结果就是其距离邻居节点较远。当有点进入异常区的时候,就会触发异常告警。UBL通过动态调度空闲计算资源运行计算,在较小的额外开销下实现了较高复杂度的计算,状态监控效果较为理想。但随着监控数据维度增多,该方法的计算量将成倍增长。
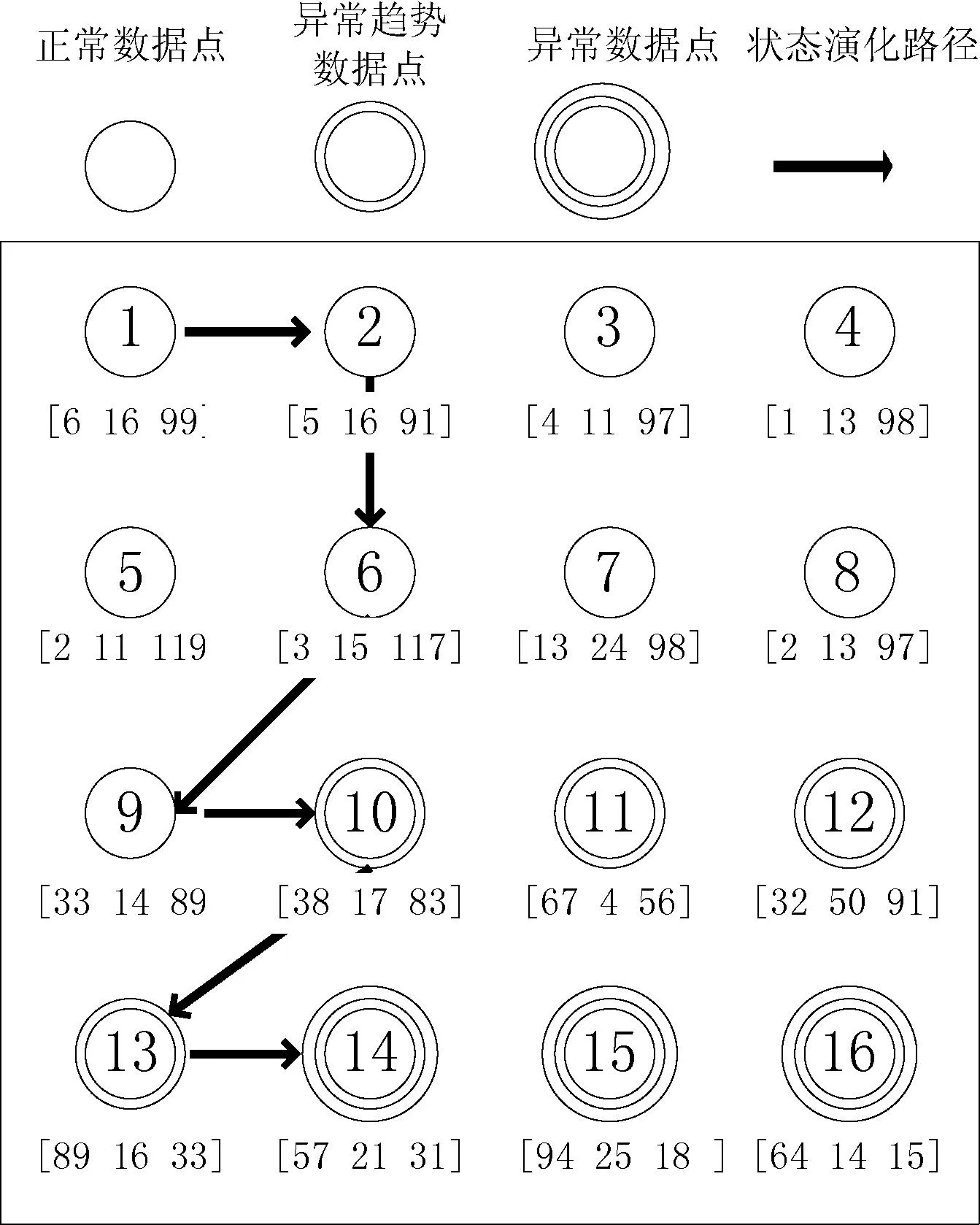
图3 基于自组织图的异常状态识别
文献[12]基于DBSCAN聚类算法,提出了一种适用于云环境的演化聚类算法。该算法考虑到云计算资源动态伸缩的特征,通过定义惩罚代价函数Cost(t)修正静态聚类算法产生的分类结果,从而实现适应云计算资源伸缩的动态状态分类。
这类非监督式学习法的优势在于无需事先对训练数据集进行分类,能够识别云环境下资源的各类异常状态。但这类方法在训练阶段计算量相对较大,对于有N个数据点的训练集,其算法复杂度为O(N2)。
总结本节内容可以发现,云环境资源监控分析技术研究的核心内容是数据点的“正常/可疑/异常”状态辨识。云计算资源动态变化的特征给传统的统计学分析方法带来挑战,而机器学习方法则大多因对标签数据集的需求而难以扩展。在将来,轻量级、高时效、非监督的异常状态识别算法将获得更多关注,例如滑动时间窗口的引入就能改进很多现有算法时效性差的局限。
2.4基于概率分析的状态监控技术
基于概率分析的资源状态监控技术涉及理论范围较广,其核心是利用历史积累数据的统计特征分析来实现状态预测。但这类方法普遍的局限在于,各种概率统计理论[5]的适用范围往往局限于某特定领域,在预测不同云资源状态时,不具备良好的可迁移性,亦不能综合考虑多种资源状态来判断云服务的整体状态。
文献[7]基于马尔科夫链模型,给出了更为简化的方法。该研究直接根据资源状态指标的不同数值区间范围,对资源状态进行分类,每个分类对应马尔科夫链中的一个状态点。随后,再通过统计各个状态之间的状态转移频率来估计各状态点之间的转换概率,完成预测模型构建并基于当前系统状态给出未来时刻的状态预测和可信度估计,如图4所示。这些方法原理简单,计算复杂度低,可实现短期内较好的状态估计,但由于未考虑云环境下资源增减等的动态变化情况,参数固定的监控模型不具备良好的时效性。

图4 基于马尔科夫链的CPU使用率状态转换图
2.5基于方程拟合的状态监控技术
基于方程拟合的资源状态监控是指通过选取资源状态某些指标数据作为输入数据,并设计拟合方程、进行参数优化,从而根据确定的状态方程检测异常状态。通过分析多种与资源状态相关的参数指标(如在线用户数量、数据包收发量等),判断当前资源状态是否处于“有异常趋势”状态。
文献[8]基于“系统状态指标与系统出现异常的概率之间存在函数关系”的假设提出一种基于方程拟合的方法,来实现计算机系统异常状态的预测。该方程的输入为计算机系统的CPU利用率、I/O带宽、内存使用率等数据,方程输出为“异常出现”的概率,并以此作为 “有异常趋势”程度的指标。这种方法可移植性强,能够适应云环境下多种场景的资源状态识别,但其缺点在于同样需要对训练数据集进行“异常/正常”标注,对未知异常不敏感。
时间序列方程拟合则是以时间为自变量,对一段历史时间内某资源状态指标变化直接进行方程拟合。文献[9]中提出一种针对某特定状态指标的预测方程拟合方法,并考虑了日期等时期因素的影响。假设待预测的指标参数为v,则有拟合方程如式(2):
v=vaverge+αDay+βWeek+γMonth+∑Day Week Month
(2)
其中vaverage表示该检测指标的统计均值,αDay表示一日内不同时刻对该检测指标的影响,βWeek表示周内不同天次的影响,γMonth表示月内不同日期的影响,∑Day Week Month则表示上述各参数的综合波动因素。这种拟合方程独到地考虑到云计算资源使用周期性的特点,值得借鉴。
2.6基于机器学习的状态监控技术
基于机器学习的资源状态监控是指通过使用贝叶斯分类、决策树、自组织图等机器学习方法,通过训练系统模型,并根据当前资源状态的数据,将资源状态分为“有异常趋势”和“无异常趋势”等类别,实现资源异常状态的监控。
文献[10]使用基于阈值的简单决策树,对当前资源状态的多种相互独立的指标进行组合分析,并判断是否即将发生异常。该研究采集训练集中每一个“异常”资源状态之前某段时间范围内的状态值,将这些数据标注为“有异常趋势”,并据此确定决策树的判定阈值,如图5所示。
此外,该研究还通过优化预报准确率(例如,最大化True Positive Rate等),调整“有异常趋势”数据的采集半径,并确定决策树的判定条件组合。为了适应云环境资源动态变化的特性,该研究通过计算递归算法 “最优子结构”界定了资源不同的状态期(例如高峰时段、空闲时段等),并针对每个状态期给出了不同的决策树,如图6所示。

图5 采集“异常趋势”的状态点 图6 资源状态分类决策树
在随后的实时监控中,该研究再使用朴素贝叶斯分类,确定资源状态,并结合该状态期对应的决策树作出下一时刻的状态预测。该研究结合多种分类方法优化状态预测过程,实验效果较好,但缺点在于大量复杂的计算可能给系统带来过量的额外开销,且这种监督式学习方法同样存在可扩展性差的问题。
2.7基于事件感知的状态监控技术
基于事件感知的资源状态监控法区别于上述几种数据驱动的监控方法,其引入了“任务事件”作为资源使用状态监控的重要考虑因素。例如,Web服务在售票服务开启或即将结束时,都可能是访问请求高峰。虽然在云环境下,许多资源使用者的行为细节对云服务供应商是透明的,但对于用户来说,这些使用细节则是已知的。因此,基于事件感知的资源状态监控主要部署在私有云管理端或公有云的客户端。
文献[11]提出一种基于事件感知的服务负载预测算法。已知某系统经受突发事件考验的时间段,利用数据库中类似事件的发生时的资源使用变化情况,来预测本次事件资源访问量达到高峰的时间段。该算法简单利用了等比例缩放的方法进行类比,实现未来时刻的资源使用状态预测,其对资源使用情况变化的内在原因进行了溯源分析,具有独特的参考意义。
综上,当前云环境资源状态感知研究的主流方法是统计学分析和机器学习,而算法复杂度、算法可扩展性、训练集标注需求等因素是衡量这些方法优劣的关键指标。这就要求在不造成过量的额外资源开销的同时,算法设计尽可能考虑不同资源的使用特点,降低对人工干预的依赖,提高资源状态预测精度。基于方程拟合和事件感知的预测算法研究的理论基础相对薄弱,但其涉及到的诸如云服务使用周期性、事件驱动预测等思想,都十分值得借鉴参考。在将来,根据云环境具有的资源规模大、使用情况复杂的特点,异常状态监控系统的设计也应该针对不同资源、不同场景分别设计不同的动态预测子模型,以期能实现指标覆盖全面、高效准确的资源异常预测。
3技术挑战与发展趋势
第2节中介绍的异常数据检测及预测技术的适用范围相对广泛,对数据来源并无特殊限制。实际上,有别于普通状态监控,云环境下的资源状态数据具有以下两点明显特点。首先,相对于网格计算等静态环境下的资源,云计算共享模式具有动态性、随机性、开放性等特点,监控对象的状态更加复杂多变,资源使用情况的不确定因素增加,不同监控数据之间相互耦合,数据处理难度前所未有。其次,规模庞大的云计算资源在运行过程中产生的状态数据体量远远超出普通分布式计算,数据分析的效率和速度成为关键挑战。因此,云资源状态分析研究发展趋势包括原始数据去冗降维、算法设计析突出非监督化、计算任务向终端推送、分析结果协同增效等新的方向。
3.1原始数据去冗降维
云环境下虚拟资源数目庞大且类型繁多,成千上万的物理机、虚拟节点之间相互耦合。监控数据采集系统获取的数据不仅数量十分庞大,而且相互之间关系也比较复杂。同一般数据处理过程一样,云计算资源状态数据预处理过程也包括数据清洗、数据集成、数据规约等过程。但由于云资源状态数据处理的时效性要求较高,且其自身必须避免过量消耗计算资源,加强数据规约(去冗降维)成为研究发展的重要趋势。
例如,主成分分析法对可能存在冗余的原始数据进行降维处理。利用现有各类监控工具收集到的监控数据,诸如CPU利用率、CPU空闲时间、内存使用率、I/O操作情况等,往往相互之间具有较强的相关性。使用PCA技术可以使降维后的数据项之间相互独立,获得对资源使用现状更为简洁有效的描述,进而方便后续数据分析。需要指出的是,使用PCA降维后的监控数据的基准特征向量可能不再具有明确的物理意义。例如,其可能描述的是CPU利用率与空闲时间的组合特征,而不再仅仅对应CPU使用率或CPU空闲时间这样的独立特征。
此外,簇抽样处理能够基于不同区域位置的邻近程度定义“簇”,从而得到若干簇的简单随机抽样,有效降低数据量。例如,某用户租用的若干虚拟资源所依赖的物理机位于北京、成都等不同地区,则可以据此将其分簇,进而实现资源监控数据抽样。
3.2算法设计突出非监督化
监督式机器学习方法在云资源状态监控中已经得到广泛应用,但其大多依赖于标签数据集的获取。使用者必须首先对样本数据集中的数据点类型进行人工划分,定义正常、异常等数据标签。在云环境中,基于监督式方法的状态监控存在两个问题:其一,在无后续人工标注数据的情况下,该模型无法识别新出现的异常状态。其二,当前监控模型的建立基于固定的历史数据集,不能实现模型的实时修正与更新。随着时间推进,许多新出现的数据被忽略,云资源状态的最新变化态势因而也被忽略。因此,基于监督式学习的状态监控方法存在异常状态漏报率、误报率高等问题。
可以考虑将非监督式分类法(如近邻分析、聚类分析等)与监督式学习(决策树、贝叶斯模型等)融合,通过非监督式分类法对动态时间窗口内的数据进行实时分类分析。在此基础上,利用监督式学习法从训练数据集中统计规律,进而实现云环境资源状态的实时监控。这种考虑能够兼顾非监督式学习的可扩展性和对新异常类型的敏感性,以及监督式学习的高预测精度。但这种方法需要解决计算量增长的问题,这在云资源“按需付费”的使用模式下是十分必要的。
此外有别于监督式方法,非监督式学习无需区分出所有聚类的环节,即可实现对离群点(异常状态)的直接识别,能够有效降低计算负载。在分布式的状态监控系统下,这将有利于分散的虚拟机(或虚拟机群)实现轻量级的异常状态监测,独立地保证自身资源状态稳定。
3.3计算任务向终端推送
为了适应云计算资源动态伸缩的特点,资源状态数据分析系统必须具备良好的可扩展性,以最小的计算资源成本完成各种规模的数据处理分析任务。应该看到,云环境中分散者大量的空闲计算资源,其本身可以用于完成各类计算任务。如果将数据采集、预处理、挖掘分析等资源监控子任务按照“统一分配,分散处理”的方法,向各虚拟机群推送,在不影响其正常完成用户计算任务的同时,灵活地利用空闲资源参与监控数据处理,将能够较好地解决可扩展性问题。
例如,状态监控中心(固定计算集群)可以实时按照虚拟资源分布现状对其进行树状结构的层次划分,逐层采集、精简并分析监控数据,最终实现虚拟资源状态反馈汇总。状态监控中心在设计数据分析任务推送方案时,必须预留适当富余资源,以保证在监控分析任务与用户任务冲突时 ,监控系统仍能正常实现预期的基本功能,维持资源状态监控的稳定性。
此外,当监控中心下达资源状态监控任务时,系统允许各部署在云环境中的分布式监控系统的计算节点能够根据自身负载状态灵活控制监控数据分析任务计算量,避免影响其他计算任务的完成。例如,可以考虑采用均方差等统计学方法衡量资源状态数据的波动程度,并据此动态调整滑动时间窗口的大小。对于数据波动明显、变化剧烈的时段,延长数据采集窗口以获取更多数据特征信息。相反,对于资源状态平稳变化的时段,则缩小时间窗口,减少计算负载,避免不必要的额外开销。
3.4多种结果协同增效
通用的异常识别方法适用范围广泛,对数据来源并无特殊限制,例如数据离群点识别等。但其无法有效针对各类监控数据源本身的特征实现高精度状态监控。多层次监控协同增效是指根据不同层次的监控对象分别设计独特的数据分析方案,最后综合考虑,互为补充,实现各层次监控结果的协同增效。例如,CPU利用率、服务请求响应延时等虚拟资源性能指标变化规律互不相同,因此适合用不同的计算模型来实现监控预测。但虚拟服务器的CPU利用率是导致相应服务请求响应延迟的可能原因,二者的结合将有助于提高异常状态检测的精度和可靠性,甚至有助于实现异常成因推断等更深层次的分析。
具体而言,云环境中的虚拟磁盘使用率的变化具有连续、非突变的特征,而CPU的使用率则可能在短时间内急剧变化[12]。考虑到云环境资源数量、性能、状态常处于动态变化中,如果用方程描述其动态变化的状态,该方程的参数也将随时间不断变化。而卡尔曼滤波器恰好适用于有限观测间隔的非平稳过程,能够适应模型未知参数和观测数据都随时间变化的情况。使用卡尔曼滤波器进行虚拟磁盘使用率数据预处理,不仅能对数据描述对象过去和现在的状态数据进行平滑,还能够预测其在未来时刻的状态数值。因此,可以考虑使用卡尔曼滤波模型实现虚拟磁盘使用率的提前预测。但卡尔曼滤波方法显然不适用于对虚拟机CPU利用率的预测,因为其自身的突变型不满足卡尔曼滤波模型的基本假设。
在实际应用中,不同的用户对云计算资源的使用要求各异,云服务提供商必须向用户提供包括CPU、内存、磁盘以及网络等虚拟资源的完整监控服务。为了保障各类监控指标异常状态的准确识别和有效预测,必须在监控数据分析系统中融入多种面向不同监控数据类型的分析模型,并整合各类分析结果,获得统一的异常识别与预测结论,推送给用户或云服务供应商,尽早排查云环境中潜在的资源状态异常。
4结语
本文在分析现有云资源状态监控技术研究的基础上,较为全面地总结了状态监控的各类方法,分别就其前提假设、基本思路、应用实例和其相应的性能进行了归纳。本文归纳提炼了概率分析、数据分类、最近邻分析、聚类分析等四类云资源状态监控研究方法以及概率分析、方程拟合、机器学习、事件感知等四类云资源状态预测方法,并结合近几年较为出色的相关研究成果进行了深入分析。应该指出,当前云环境资源状态感知研究的主流方法是统计学分析和机器学习,而算法复杂度、算法可扩展性、训练集标注需求等因素是衡量这些方法优劣的关键指标。
本文针对现有算法的不足之处,对本研究领域的发展趋势提出了包括原始数据去冗降维、算法设计突出非监督化、计算任务向终端推送、分析结果协同增效等几点发展趋势的预测。在不造成过量的额外资源开销的同时,算法设计尽可能考虑不同资源的使用特点,降低对人工干预的依赖,提高资源状态预测精度。虽然基于方程拟合和事件感知的预测算法研究的理论基础相对薄弱,但其涉及到的诸如云服务使用周期性、事件驱动预测等思想,都十分值得借鉴参考。在将来,根据云环境具有的资源规模大、使用情况复杂的特点,异常预测系统的设计也应该针对不同资源、不同场景分别设计不同的动态预测子模型,将能够实现指标覆盖全面、高效准确的资源异常预测。
本文研究还存在若干问题需要进一步解决。首先,云环境下资源状态监控技术虽然目标不同,但二者均涉及到对监控数据的处理分析以及异常识别等内容。除了本文中单独讨论的两类研究的理论方法以外,应该进一步探讨考虑二者的融合、互为补充的可能,进而减轻计算负载。此外,云计算环境下,不同层次的云计算服务模式资源使用变化规律亦有所区别。随着服务模式层面的上移,用户获得的资源使用权限增加,其状态波动因素也随之改变。进一步的研究应该深入探讨如何结合这些特征,选择或设计资源状态监控算法模型。
参考文献
[1] Chandola V,Banerjee A,Kumar V.Anomaly detection:A survey[J].ACM Computing Surveys (CSUR),2009,41(3):15.
[2] Salfner F,Lenk M,Malek M.A survey of online failure prediction methods[J].ACM Computing Surveys (CSUR),2010,42(3):10.
[3] Guan Q,Zhang Z,Fu S.Ensemble of bayesian predictors for autonomic failure management in cloud computing[C]//Computer Communications and Networks (ICCCN),2011 Proceedings of 20th International Conference on.IEEE,2011:1-6.
[4] Dean D J,Nguyen H,Gu X.Ubl:unsupervised behavior learning for predicting performance anomalies in virtualized cloud systems[C]//Proceedings of the 9th international conference on Autonomic computing.ACM,2012:191-200.
[5] Dalmazo B L,Vilela J P,Curado M.Predicting Traffic in the Cloud:A Statistical Approach[C]//Cloud and Green Computing (CGC),2013 Third International Conference on.IEEE,2013:121-126.
[6] Ahmed W,Wu Y W.Reliability Prediction Model for SOA Using Hidden Markov Model[C]//ChinaGrid Annual Conference (ChinaGrid),2013 8th.IEEE,2013:40-45.
[7] Mallick S,Hains G,Deme C S,et al.An Alert Prediction Model for Cloud Infrastructure Monitoring[J].Performance,2013(1):6-35.
[8] Hoffmann G A,Trivedi K S,Malek M.A best practice guide to resource forecasting for computing systems[J].Reliability,IEEE Transactions on,2007,56(4):615-628.
[9] Vilalta R,Apte C V,Hellerstein J L,et al.Predictive algorithms in the management of computer systems[J].IBM Systems Journal,2002,41(3):461-474.
[10] Tan Y,Gu X,Wang H.Adaptive system anomaly prediction for large-scale hosting infrastructures[C]//Proceedings of the 29th ACM SIGACT-SIGOPS symposium on Principles of distributed computing.ACM,2010:173-182.
[11] Sladescu M,Fekete A,Lee K,et al.Event aware workload prediction:A study using auction events[M].Springer Berlin Heidelberg,2012.
[12] Zhang Y,Hong B,Zhang M,et al.eCAD:Cloud Anomalies Detection From an Evolutionary View[C]//Cloud Computing and Big Data (CloudCom-Asia),2013 International Conference on.IEEE,2013:328-334.
[13] Montes J,Sánchez A,Memishi B,et al.GMonE:A complete approach to cloud monitoring[J].Future Generation Computer Systems,2013,29(8):2026-2040.
[14] Perez-Palacin D,Calinescu R,Merseguer J.log2cloud:log-based prediction of cost-performance trade-offs for cloud deployments[C]//Proceedings of the 28th Annual ACM Symposium on Applied Computing.ACM,2013:397-404.
[15] Bermudez I,Traverso S,Munafo M,et al.A Distributed Architecture for the Monitoring of Clouds and CDNs:Applications to Amazon AWS[J].Network and Service Maragement,2014,11(4):516-529.
[16] Guan Q,Fu S.Adaptive Anomaly Identification by Exploring Metric Subspace in Cloud Computing Infrastructures[C]//Reliable Distributed Systems (SRDS),2013 IEEE 32nd International Symposium on.IEEE,2013:205-214.
[17] Dalmazo B L,Vilela J P,Curado M.Predicting Traffic in the Cloud:A Statistical Approach[C]//Cloud and Green Computing (CGC),2013 Third International Conference on.IEEE,2013:121-126.
[18] Guan Q,Zhang Z,Fu S.Ensemble of bayesian predictors for autonomic failure management in cloud computing[C]//Computer Communications and Networks (ICCCN),2011 Proceedings of 20th International Conference on.IEEE,2011:1-6.
[19] Huang T,Zhu Y,Zhang Q,et al.An LOF-Based Adaptive Anomaly Detection Scheme for Cloud Computing[C]//Computer Software and Applications Conference Workshops (COMPSACW),2013 IEEE 37th Annual.IEEE,2013:206-211.
[20] Guan Q,Fu S,DeBardeleben N,et al.Exploring Time and Frequency Domains for Accurate and Automated Anomaly Detection in Cloud Computing Systems[C]//Dependable Computing (PRDC),2013 IEEE 19th Pacific Rim International Symposium on.IEEE,2013:196-205.
[21] Amazon EC2 User Guide[EB/OL].http://aws.amazon.com/cn/documentation/ec2/.
[22] AWS.Amazon Cloudwatch Developer Guide[EB/OL].http://aws.amazon.com/cn/cloudwatch/.
[23] GAE.Google GAE Developer Guide[EB/OL].https://cloud.google.com/appengine/docs.
[24] Microsoft Corporation.Microsoft Azure[EB/OL].http://azure.microsoft.com/en-us/documentation/articles/cloud-services-how-to-monitor/.
[25] IBM Corporation.IBM BlueCloud Security[EB/OL].http://www.ibm.com/cloud-computing/us/en/security.html.
[26] 百度开放云.百度云监控BCM开发指南[EB/OL].http://bce.baidu.com/Product/BCM.html.
[27] 阿里云计算有限公司.阿里云监控CMS用户指南[EB/OL].http://help.aliyun.com/view/13444036.html?spm=5176.383732.9.2.4vJntr.
[28] 腾讯云平台.腾讯云监控关键指标说明[EB/OL].http://wiki.qcloud.com/wiki/%E7%9B%91%E6%8E%A7%E6%9C%8D%E5%8A%A1#2._.E7.9B.91.E6.8E.A7.E6.A6.82.E5.86.B5.E9.A1.B5.E9.9D.A2.E5.85.B3.E9.94.AE.E6.8C.87.E6.A0.87.E8.AF.B4.E6.98.8E.
[29] OpenStack.OpenStack Admin Guide[EB/OL].http://docs.openstack.org/admin-guide-cloud/content/.
[30] Ganglia.The Ganglia Distributed Monitoring System Design Implementation and Experiment[EB/OL].http://ganglia.sourceforge.net/.
[31] Nagios.Nagios Overview[EB/OL].http://library.nagios.com/about/overview.
A SURVEY ON STATE MONITORING OF COMPUTATIONAL RESOURCES IN CLOUD
Hong Bin1Peng Fuyang1Deng Bo1Wang Dongxia2
1(Beijing Institute of System Engineering,Beijing 100101,China)2(NationalKeyLaboratoryofScienceandTechnologyonInformationSystemSecurity,Beijing100101,China)
AbstractCloud computing successfully achieves the efficient use of computational resources through internet sharing. The characteristics of cloud resources allocation such as the dynamics property, randomness and openness make the difficulty in QoS (Quality of Service) assurance be increasingly noticeable. Through mining and analysing in depth the monitoring data, the monitoring technologies for resource state in cloud environment find timely the abnormal operation states in those computational resources, and make the prediction on resources usage state in the future according to historical operation data so as to timely discover potential performance bottlenecks and security threats, these provide the reliable and stable cloud services to users. In combination with instances, in the paper we introduce some representative research approaches in regard to resources states monitoring, including probability analysis, equation fitting and clustering analysis, etc., and compare the performance features and limitations of different methods. In end of the paper, we discuss the technical challenges encountered by the monitoring technologies for cloud resource states in the aspects of data complexity and scale, and point out the future development trend such as redundancy removal and dimensionality reduction of primitive data, non-supervision highlighting in algorithm design and analysis, pushing the computational tasks to terminals, and synergies of analysis results, etc.
KeywordsCloud computingVirtualised resourcesState monitoring
收稿日期:2015-01-20。国家自然科学基金项目(61271252);国家高技术研究发展计划项目(2013AA01A215)。洪斌,硕士生,主研领域:云计算资源监控。彭甫阳,研究员。邓波,研究员。王东霞,研究员。
中图分类号TP393.0
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.06.001
