基于证据可信度的D-S理论改进方法
2016-07-19胡海亮钟求喜
胡海亮 钟求喜
(国防科学技术大学计算机学院 湖南 长沙 410073)
基于证据可信度的D-S理论改进方法
胡海亮钟求喜
(国防科学技术大学计算机学院湖南 长沙 410073)
摘要针对当前D-S理论改进方法中可信度计算不够准确的问题,通过引入证据源可靠度,提出一种新的证据可信度计算方法。给出基于新可信度计算方法的三个改进合成公式,能够处理高度冲突的证据,并快速收敛到合理结果。通过算例对可信度计算方法的准确性和改进合成公式的有效性进行了验证。
关键词证据理论合成规则冲突证据可信度
0引言
Dempster-Shafer(D-S)证据理论首先由Dempster[1]于1967年提出,后经Shafer[2]系统化完善,成为一种重要的不确定性推理方法。证据理论是对经典概率论的推广,具有坚实的数学基础,能够清楚地表示“不知道”和“不确定”的数据信息。在精确反映证据聚合程度方面具有很强的灵活性,并能得到较好的融合结果,已成为信息融合、模式识别和决策分析等领域重要的信息处理工具[17-20]。
但D-S证据理论存在一个突出问题,就是无法有效处理高度冲突的证据。国内外学者针对这一问题进行了大量研究和改进,本文在总结分析现有研究成果的基础上,给出了基于可信度的三个改进的证据合成公式。这三个公式在处理高度冲突证据时,都能得到比较直观合意的结果。
1D-S证据理论及改进方法概述
在D-S证据理论中,辨识框架Θ={θ1,θ2,…,θn}是一个元素互不相容的可列集,基本概率赋值(BPA)是一个函数m:2Θ→[0,1],并满足以下条件:
不同的证据具有不同的基本概率赋值,当有多条证据时,就可以通过Dempster合成规则进行证据合成,合成公式如下:
(1)
其中A∈2Θ,A≠φ,表示证据中的焦元,K∈[0,1],被称为冲突因子,表示证据间的冲突程度。
由上述合成公式可知传统的D-S证据理论无法合成K=1时的证据。但当K→1时,也可能得到不合理的结果。Zadeh[3]给出了一个经典的例子。两个医生对同一个病人进行诊断,病人所患病症可能为脑膜炎(M)、脑挫伤(C)和脑肿瘤(T),则辨识框架Θ={M,C,T},两个医生的诊断结果分别为:
m1(M)=0.99m1(T)=0.01
m2(C)=0.99m2(T)=0.01
此时K=0.9999,合成结果为:m(T)=1,很明显不合理。
对式(1)进行变换可得:
(2)
从式(2)可以看出Dempster合成规则将冲突因子(实际上就是合成后空集的基本概率赋值),按照非空焦元所占的不同比重进行了再分配。这样做是因为D-S证据理论是基于闭世界的假设,合成后空集的基本概率赋值要置零。由于冲突证据在合成的过程中会相互削弱对应焦元的基本概率赋值,相应焦元在冲突因子分配时得到的份额就会很少,特殊情况下为零。这也是Zadeh特例产生的根本原因,即在证据合成中出现了一票否决的现象。
针对上述问题,国内外学者提出了大量改进方法,但基本思想可以分为三类。第一类是修改Dempster组合规则。根据修改程度的不同又可以分为以下几种:①完全推倒重建,如文献[4,5]等,虽然这些方法在处理冲突证据时表现出了更好的效果,但缺乏坚实的数学理论支撑;②基于开世界假设的方法,打破传统的认知框架,把冲突因子分配给了空集,如文献[6]等,他们认为D-S证据理论中的辨识框架不够完备,空集包含了尚未认识的元素,这些方法超出了人们的认知范畴,也不能从根本上解决问题;③在闭世界假设下修改冲突因子分配方式的方法,如文献[7],把冲突因子全部分配给了辨识框架,处理方式显得保守,Dubois等[8]把冲突因子只分配给了产生冲突的焦元,孙全等[9]、李弼程等[10]则把冲突因子按一定比重分配给了所有焦元,效果都要优于文献[7]。第二类是修改证据模型。文献[11-13],基本思想是通过平均或加权的方式重置证据的基本概率赋值,削弱证据之间的冲突程度,但文献[11]没有考虑证据的重要性问题,导致收敛速度慢,文献[12,13]虽然都考虑了证据权值,但单纯基于证据体本身计算出的权值不一定可靠。第三类方法是修改组合规则和证据模型相结合的方法。如文献[14,15],这些方法都是先计算证据的可信度,根据证据的可信度修正基本概率赋值函数,在合成时再按照一定的比重分配冲突因子,但在证据可信度的计算上仍是基于证据体本身,忽略了证据源的可靠性。
针对现有方法中存在的问题,本文给出了证据可信度新的计算方法和三种改进的合成公式,并用算例验证了它们的有效性。
2综合证据源可靠度的可信度计算方法
当前很多研究基于证据之间的距离计算出证据的可信度[21-25],但是这个可信度只能反应每个证据在一次融合中与其他证据的相似程度,没有考虑证据来源的可靠性,即证据的历史可信度。因此并不能准确反应证据的可信程度,应该综合这两个方面来计算证据的可信度。我们把基于证据距离的可信度称作证据体支持度,记为Su,把历史可信度称作证据源可靠度,记为Re,最终的证据可信度记为Cr。
2.1证据体支持度的计算方法
证据体的支持度同现有文章中基于证据距离的可信度是一个概念,因此可以采用同样的计算方法,本文采用Jousselme[16]距离,它能够很好地刻画不同证据之间的差异性。
设辨识框架Θ={θ1,θ2,…,θn},2Θ={A1,A2,…,A2n},N个证据e1,e2,…,eN及其基本概率赋值函数m1,m2,…,mN,证据体支持度的计算方法如下:
第1步计算证据之间的Jousselme距离:
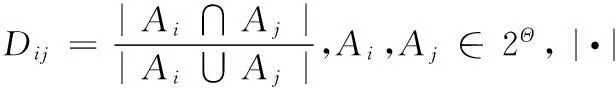
第2步计算证据之间的相似度sij及每个证据的总相似度Si:
第3步进行归一化处理,得到每个证据的证据体支持度:
2.2证据源可靠度的计算方法
一个可靠性高的证据源应总能以较大概率辨识目标,并具有很强的抗干扰能力。我们可以通过构造训练数据,测试出证据源的辨识正确率,用其表示证据源可靠度。假设数据集Da={o1,o2,…,oλ},N个证据源,则证据源可靠度的计算方法如下:
第1步从Da中任取一目标oi,经N个证据源辨识得到N个辨识函数;
第2步判断每个辨识函数中目标焦元的基本概率赋值是否最大,若是,相应证据源的辨识成功数加1;
第3步重复第1步、第2步,直到所有的目标辨识完毕,得到每个证据源总的辨识成功数nj;
2.3证据可信度的计算及BPA的修正
证据体支持度反映的是此次融合的每条证据的可信程度,而证据源可靠度可以看成每条证据的历史可信度,综合这两个方面给出证据可信度的计算公式:
(3)
其中,α+β=1,α≥0,β≥0。α,β是权值,可以根据我们对证据体支持度和证据源可靠度的看重程度调整大小,如α=0,此时只考虑证据源可靠度,反之β=0,则只考虑证据体支持度。
根据每个证据可信度可按照Shafer折扣法修正证据的基本概率赋值函数:
(4)
3证据合成公式改进
借鉴文献[10]方法,给出的第一个合成公式:
(5)
第二个改进的合成公式是基于修改证据模型和合成规则相结合的思想,通过式(4)修正证据模型后的公式:
(6)
第三个改进合成公式类似文献[13]方法:
(7)
4算例验证
下面用算例来验证这三个改进合成公式的有效性。对于Zadeh给出的例子,在不考虑证据源可靠度的情况下,式(5)和式(6)都能够得到比较合理的融合结果,但式(7)需要额外证据的支持。现在假设获得了两个医生的历史诊断成功率分别为:0.95、0.65。根据证据源可靠度的定义,历史诊断成功率可以作为他们诊断结果的证据源可靠度,由于两条证据的相互距离是相等的,在证据可信度的计算中可以不考虑证据支持度,令α=0,则用三个改进公式得到的融合结果如表1所示。
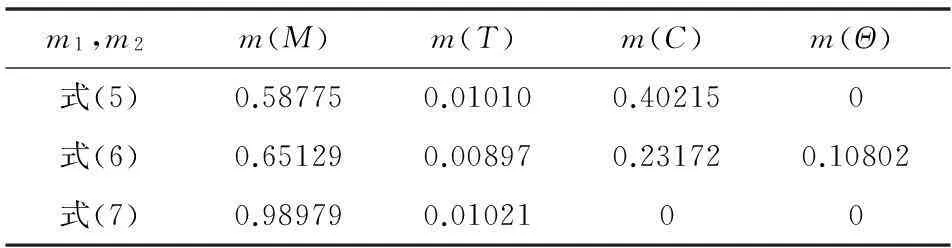
表1 对Zadeh特例的融合结果
三个改进公式给出融合结果都比较合理,其中式(7)的收敛速度最快,但对肿瘤的基本概率赋值略有增大,式(6)收敛速度居中,对肿瘤的基本概率赋值也有所下降,相对更为合理。
第二个算例的数据来自文献[13],为计算简单,令β=0,这时证据可信度就等于证据体支持度,式(7)退化为文献[13]。假设融合系统的辨识框架为Θ={A,B,C},框架中各命题元素表示目标类型,5条证据的基本概率赋值函数如下:
利用本文的三种改进合成公式和其他方法的合成结果如表2所示。
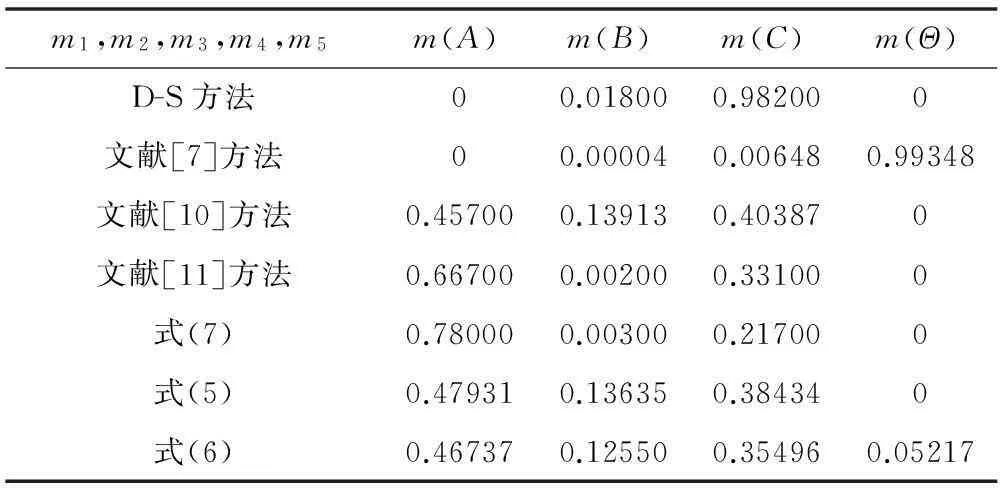
表2 β=0时的融合结果
由于第二条证据的存在,整个证据体的冲突因子很大,但证据体总体上支持辨识目标为A。从融合结果上看,D-S方法、文献[7]方法都不能得到好的融合结果。其他融合方法中目标A的基本概率赋值都是最大。由于引入了证据可信度,相比文献[10]方法,本文式(5)的收敛速度要快,第二个改进公式虽然从修改证据模型和组合规则两个方面进行了改进,但融合效果不是太好。在此次融合中比较三类修改方法,修改证据源的方法效果最好,换成其他数据是否还是这样的结果有待验证。
在上面的证据中第二条证据同其他证据的差异较大,但这并不能说明该证据是错误的,还要看其证据源可靠度。如果该证据的证据源可靠度也很低,则可推断其是一条错误的证据。而我们通过引入证据源可靠度就能更好地削弱错误证据的干扰,假设五条证据的证据源可靠度分别为:{0.8,0.6,0.9,0.9,0.9},同时令:α=β=0.5,由于其他融合算法都没有考虑证据源可靠度,它们的融合结果不会改变,而用本文的三种方法得到的融合结果如表3所示。很明显,通过引入证据源可靠度,表2比表3的融合效果都要更好。

表3 β≠0时的融合结果
上述计算是假设第二条证据的证据源可靠度很低,但这并不一定成立。相反,可能第二条证据的证据源可靠度很高,而其他证据源的可靠度很低。考虑一种极端情况,产生第二条证据的证据源总能成功识别目标,其他证据源成功辨识目标的概率都很低,假设五条证据的证据源可靠度分别为:{0.3,1.0,0.3,0.3,0.3},此时正确的目标就很可能是C,其他的算法都不能得到合理的结果,若令α=0,则用式(5)会得到如下的结果:
m(A)=0.31159m(B)=0.15809m(C)=0.53032
融合结果比较合理。虽然这是极端情况,但从一定程度上反映了引入证据源可靠度的必要性和新方法计算出的证据可信度的准确性。
5结语
传统的D-S证据理论在处理高冲突证据时常会得到反直观的结果。本文基于证据可信度提出的三种改进方法在冲突证据的处理上能够得到较好的融合效果,而且在证据可信度的计算中考虑了证据源的可靠性。相较其他方法中的证据可信度能够更加准确地衡量每个证据的可信程度,也使融合系统更加灵活。
理论上通过调整证据体支持度和证据源可靠度的权值总能得到合理的融合结果,但如何确定权值还需要寻找一个客观的计算方法。三个改进公式总体上都是有效的,但在不同的场景表现效果有些差别,需要根据实际情况和具体需求选择合适的改进公式。
参考文献
[1] Dempster A P.Upper and lower probabilities induced by a multivalued mapping[J].Annals of mathematical statistics,1967,38(2):325-339.
[2] Shafer G.A mathematical theory of evidence[M].Princeton:Princeton University Press,1976.
[3] Zadeh L.A Review of books:A mathematical theory of evidence[J].AI Magazine,1984,5(3):81-83.
[4] Tazid Ali,Palash Dutta,Hrishikesh Boruah.A New Combination Rule for Conflict Problem of Dempster-Shafer Evidence Theory[J].International Journal of Energy, Information and Communications,2012,3(1):35-40.
[5] 郑孝勇,姚景顺,刘维国,等.一种数据融合算法的初步提出[J].数学的实践与认识,2003,33(1):54-59.
[6] 王俊松,李建林.D-S证据理论改进方案综述[J].信息化研究,2011,37(6):4-6.
[7] Yager R.On the Dempster—Shafer framework and new combination rules[J].Information Sciences,1987,41(6):93-137.
[8] Dubois D,Prade H.A survey of belief revision and updating rules in various uncertainty models[J].International Journal of Intelligent Systems,1994,9(6):61-100.
[9] 孙全,叶秀清,顾伟康.一种新的基于证据理论的合成公式[J].电子学报,2000,28(8):117-119.
[10] 李弼程,王波,魏俊,等.一种有效的证据理论合成公式[J].数据采集与处理,2002,17(1):34-36.
[11] Murphy C.Combining belief functions when evidence conflicts[J].Decision Support systems,2000,29(7):1-9.
[12] Deng Y,Shi W K,Zhu Z F,et al.Combining belief functions based on distance of evidence[J].Decision Support Systems,2004,38(3):489-493.
[13] 刘海燕,赵宗贵,刘熹.D-S证据理论中冲突证据的合成方法[J].电子科技大学学报,2008,37(5):701-704.
[14] 邢清华,刘付显.基于证据折扣优化的冲突证据组合方法[J].系统工程与电子技术,2009,31(5):1158-1161.
[15] 李仕峰,杨乃定,张云翌.区分证据重要性及分配证据冲突的新方法[J].系统工程理论与实践,2013,33(7):1867-1872.
[16] Jousselme A L,Grenier D,Bosse E.A new distance between two bodies of evidence[J].Information Fusion,2001,2(2):91-101.
[17] 肖人彬,王雪,费奇,等.相关证据合成方法的研究[J].模式识别与人工智能,1993,6(3):227-234.
[18] 徐从富,耿卫东,潘云鹤.面向数据融合的DS方法综述[J].电子学报,2001,29(3):393-396.
[19] 尹慧琳,王磊.D-S证据推理改进方法综述[J].计算机工程与应用,2005,41(4):22-24.
[20] 韩德强,杨艺,韩崇昭.DS证据理论研究进展及相关问题探讨[J].控制与决策,2014,29(1):1-11.
[21] 王进花,吴迪,曹洁,等.基于证据分类的加权冲突证据组合[J].计算机科学,2013,40(1):247-250.
[22] 张克芳,王万请,生拥宏,等.一种新的证据复合折扣合成方法[J].信息工程大学学报,2014,15(2):219-225.
[23] 张盛刚,李巍华,丁康.基于证据可信度的证据合成新方法[J].控制理论与应用,2009,26(7):812-814.
[24] 李仕峰,杨乃定,张云翌.区分证据重要性及分配证据冲突的新方法[J].系统工程理论与实践,2013,33(7):1867-1872.
[25] 黄青,陈以,陈燕兰.一种改进的基于权重系数的证据合成方法[J].传感器与微系统,2012,31(7):14-16.
AN IMPROVED METHOD FOR D-S THEORY BASED ON EVIDENCE CREDIBILITY
Hu HailiangZhong Qiuxi
(School of Computer,National University of Defence Technology,Changsha 410073,Hunan,China)
AbstractAiming at the inaccuracy of credibility calculation in current D-S theory improvement methods, we propose a new calculation method for evidence credibility by introducing evidence source reliability, and then gave three improved synthetic formulas, which are based on new method, capable of handling the highly conflicting evidence and fast converging to a reasonable outcome. Through numerical examples we verified the accuracy of credibility calculation method and the effectiveness of improved synthetic formulas.
KeywordsEvidence theoryCombination rulesConflicting evidencesCredibility
收稿日期:2014-11-21。国家自然科学基金项目(61202482,6147 2437);国家高技术研究发展计划项目(2012AA01A5060)。胡海亮,硕士生,主研领域:信息融合,信息安全。钟求喜,研究员。
中图分类号TP3
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.06.003
