基于大数据的K-means聚类算法在网络安全检测中的应用
2016-07-19郑志娴
郑志娴,王 敏
(福建船政交通职业学院 信息工程系, 福州 350007)
基于大数据的K-means聚类算法在网络安全检测中的应用
郑志娴,王敏
(福建船政交通职业学院 信息工程系, 福州 350007)
摘要:随着云时代的到来,大数据的应用受到了越来越多的关注。大数据的核心在于挖掘数据中蕴藏的价值链,为决策提供可借鉴参考。聚类算法是数据挖掘的一种归类方法,K-means则是基于划分的聚类方法。在网络安全检测中,应用K-means建立网络异常检测模型,可有效提高大数据环境下集中选取数据准确性的能力,控制检测误报率,缩短网络异常数据选取时间。但是,传统的K-means聚类算法在数据类型预处理、初始中心选取和K值确定等方面存在不确定性,导致对入侵检测的效率降低。本文提出一种改进的K-means算法,并通过利用KDDCup99数据集进行仿真实验,证明改进后的K-Means算法的检测准确率与检测效率要优于传统算法。
关键词:大数据;网络安全检测;K-means聚类算法
网络安全是网络应用研究永恒的话题,面对复杂多变的网络环境,对网络异常的检测是维护网络安全的热点之一。网络安全检测首先要设定网络正常状态下的行为模型,预设模型阈值,如果在网络应用中,检测到用户行为超出预设模型阈值,则判定其为网络入侵[1]。由此,设置网络正常状态的的行为模型和预设模型阈值是网络安全检测的核心,这就需要在大量的网络数据中有效的筛选出正常用户行为模式,因此,将正常行为与异常行为进行归类划分是网络安全检测的关键,所以采用K-means聚类算法进行网络安全检测具有一定的可行性。
1大数据环境下的K-means聚类算法
在网络应用越来越普及、越来越多样化的今天,网络数据不仅数量庞大而且数据结构非常复杂,在如此环境下,对大量的数据和不同数据类型和结构的数据进行准确、高效、快速的挖掘是一件非常困难的事,由此,对于网络异常检测和网络安全防护来讲具有非常大的压力。这里以数据活动训练集中具有代表性的数据进行分析,采用有效的数据挖掘算法,来提高网络检测的准确性就具有非常重要的作用。聚类算法[2]是一种以群分析的数据挖掘算法,其将数据集划分为若干模式子集,并将具有较高相似度的数据集中在同一集合中,不同集合之间具有较为明显的属性差异性。而K-means算法是聚类算法思想中的一种,K-means算法是根据数据的层次将数据分类划分,每一类数据都具有极高的相似度,以其相似度的平均值为标准将其划分为k个聚类[3]。
大数据环境下K-means 算法[4]的工作过程说明如下:
首先,在网络安全检测中,所检测的数据不仅数量多,而且结构复杂,这正符合大数据的形态。所以要从网络大数据n个对象中随机选择 k 个对象作为初始聚类中心,并要求每一个对象的属性都具有较为鲜明的特点,彼此之间存在较大的属性差异化,将所有对象按照与k对象的距离划分聚类,以到k个对象的距离为划分标准,分别将这些对象分配给与其最为相似的聚类;其次,通过计算获取新的聚类,并对新聚类所有对象的中心求均值,此计算过程反复的重复,不断的形成新的距离,再求均值,直到均方差所标记的标准测度函数开始出现收敛为止,以达到最佳准确度的均值。由此可以看出,K-means算法是一种基于样本间相似性的聚类算法。此算法以k为参数,将在网络大数据中所随机提取的n 个对象分为k个簇,这些簇的特点是具有较高的属性相似度,并且簇之间的属性具有明显的不同,以此为方法对每一个簇中的对象求平均值,已达到将其归为某一准确类。
在传统的K-Means算法中,通常采用均方误差作为标准测量函数[5],即:
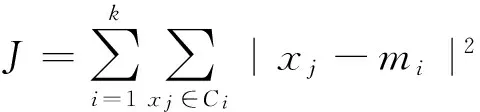
当聚类数据对象为密集型数据,并且所有数据对象各个类之间具有较大明显区别时,采用传统K-means进行聚类效果较好,能满足网络安全检测需求。但是在实际应用中,入侵检测网络数据包[6]通常都为随机实时抓取的,因此要事先确定出聚类数,进行初始聚类中心选取则较为困难,而K值不准确,则聚类结果不稳定。另一方面,传统的K-means算法只能处理连续型数值,不能处理离散型数值,应用范围狭窄。
2K-means算法改进
本文提出K-means的改进方案,用以解决网络安全检测过程中,数据预处理、初始中心选取和K值确定这三个方面的问题。
(1)数据预处理。网络数据包中的属性值有连续型和离散型[7](比如协议和服务名称等都属于字符型离散属性),为了使数据更有利于进行数据挖掘处理,需要将离散型数据预处理转化为数值型。参照文献[8][9][10],需要定义如下:
定义1 报警数据库D所包含有n个警告记录集T={T1,T2,…,Tn}(n≥1)。其属性集X由m个特征属性组成,X={X1,X2,…,Xm},满足原则X=Xc∪Xd且Xc∩Xd=φ且,其中Xd为数值属性子集,Xc为字符型属性子集。每个警告记录Ti由m维属性组成,即:Ti=(xi1,xi2,…,xim)。
对象间的相似度可以用对象间的距离来计算,这里使用欧式距离来计算。
定义2假设Ti,Tj为警告记录中的任意两条,则Ti与Tj之间相似度距离为:
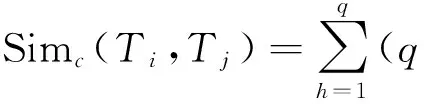
定义3假定聚类集C={Ci}(i=1,2,…,K);Ci={Tf,Tr,…Tg}为包含r个记录的第i个聚类。
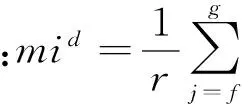
定义5警告记录Ti与当前聚类Cj相似度用其与聚类中心mj相似度距离表示为:
Sim(Ti,mj)=Simd(Ti,mj)+Simc(Ti,mj)。
最小距离为:
Min(Sim(Ti,C)=Min(Sim(Ti,Cj))
定义6任意两个聚类Ci和Cj之间最小相似度距离SBC=min(Sim(mi,mj))(i≠j)
包含r个数据对象的第Ci类内数据对象相似度平均值SWCi可表示为:
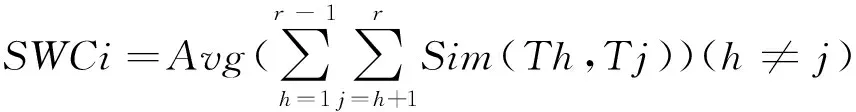
定义7所收到的警告记录与某一类的最大相似度为标准,对其进行归类,按照距离最近的原则,某类的最大相似度距离为:SWC=Max(SWCi)(i=1,2,...k)
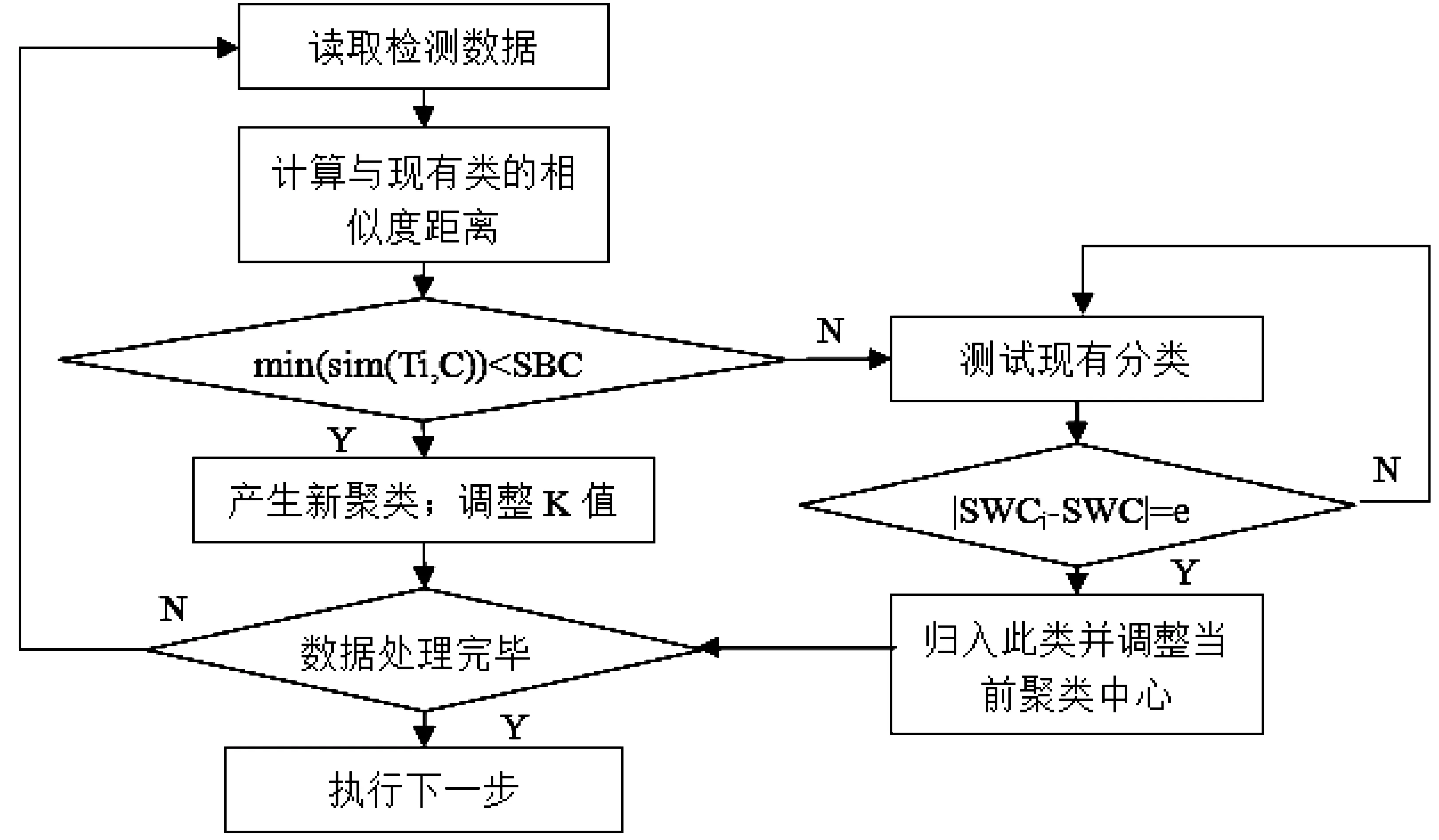
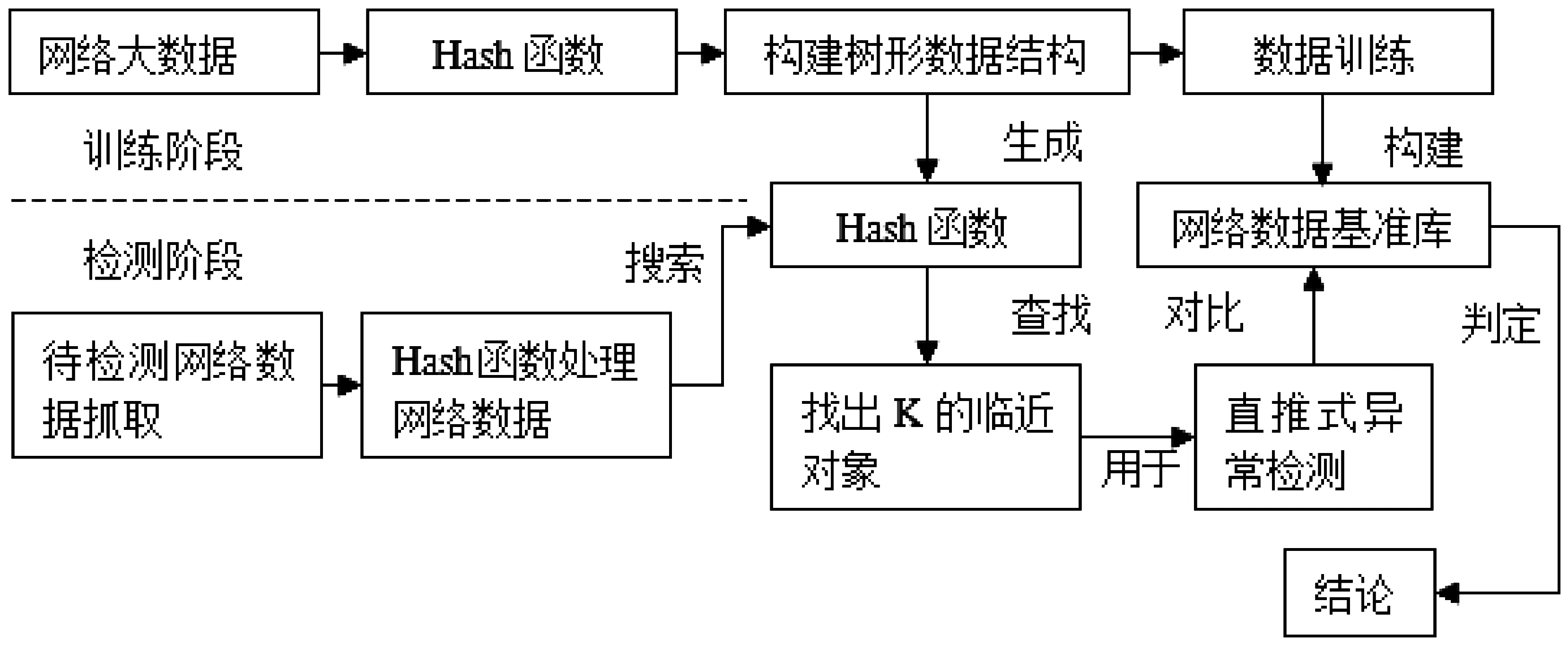
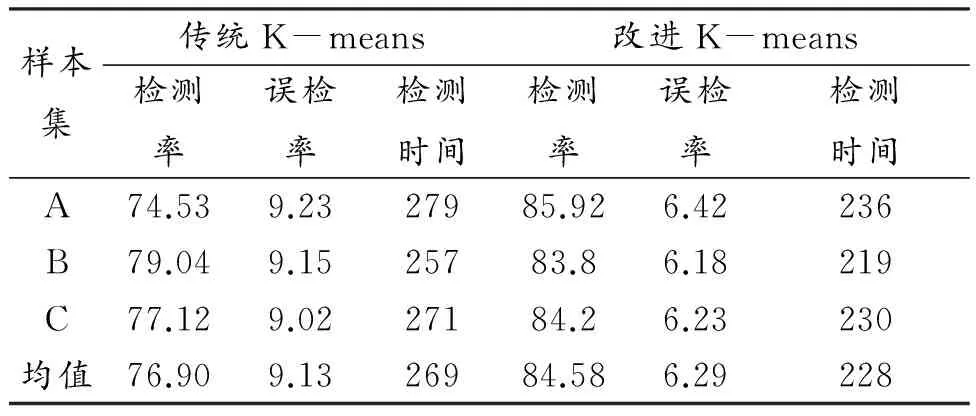
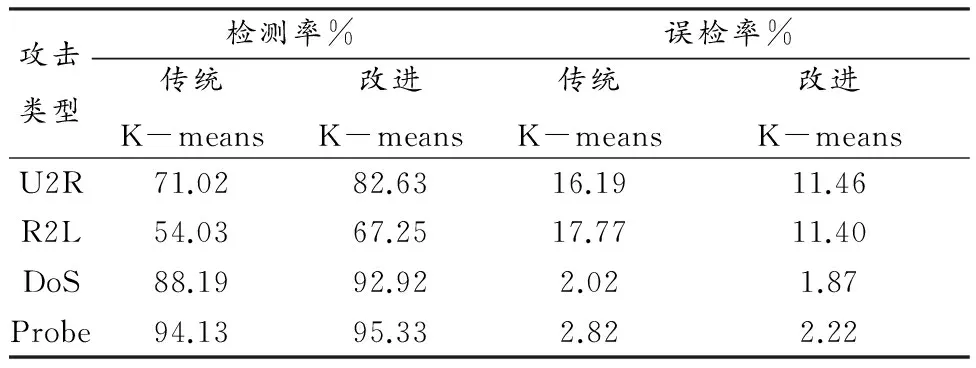
(2)对初始聚类中心进行确定。选择符合类中心的样本点密度较高且类中心间相似距离较大的聚类,考虑密度和相似度距离对初始聚类中心的影响,从警告数据库D(包含n条记录)中随机抽取q个数据子集D1,D2,…Dq,每个子集包含n’条记录,n’=(l,n’< FindM(D,q,n’)函数具体步骤: 首先对随机抽取的q个数据子集Dj(1≤j≤q)进行遍历,根据定义8计算出Dj各记录的分布密度di(1≤i≤n’), mj=Max(di),并根据定义4得出{mj}的聚类中心设为m1。然后根据定义2计算sim(m1,mj),得出Max(Sim(m1,mj))设为m2。同理,计算Sim(m2,mj),m3=Max((Sim(m1,mj)+Sim(m2,mj)),输出初始聚类中心m1、m2、m3。 (3)生成新聚类和确定K值。通过多次迭代计算出类间相似度距离最小和类内相似度距离最大。在聚类过程中,以动态的方式调整K值,使其能够以类内最近和类间最远为标准进行归类,算法流程如图1所示: 图1 生成新聚类和确定K值流程 3基于大数据的K-means聚类算法网络安全检测模型设计 在K-means算法中,首先,随机选取k个对象,根据对象相对聚类质心距离最近的方式对其进行聚类;其次,重复计算对象的聚类质心,直到簇内均方差准测度函数收敛为止。 基于大数据的K-means聚类算法网络安全检测模型如图2所示: 图2 基于大数据的K-means聚类算法网络安全检测模型 在基于大数据的K-means聚类算法网络安全检测模型设计中,可分为两个阶段,一个是训练阶段,一个是检测阶段。 在训练阶段首先要对网络中的正常数据进行抓取,对于能反映网络正常状态的特征数据进行筛选,为构建网络安全检测模型准备正常行为数据集。其次,将所采集到的正常行为数据集特征通过Hash函数进行处理,将特征数据转换为模型可以识别和处理的数据,以便于进行算法分析。然后,运用K-means聚类算法对数据进行分类,构建数据树形结构,对数据进行训练,完成正常行为数据的基准库建立。 第二阶段是检测阶段,首先对网络中所采集到的原始正常行为数据进行监控,以保证所抓取的待检网络数据的可用性。其次,应用Hash函数对网络数据进行处理,主要是将数据特征进行转换,在进行算法分析。然后,以K-means聚类算法将数据按照数据特征进行分类,利用在训练阶段所构建的树形结构找出K邻近的对象(K-Nearest、Neigh-bors)。最后,将数据带入直推式(transduction)异常检测算法,对比正常网络数据基准库,计算出P值,由此判断网络中的数据是否存在异常。 直推式异常检测算法[11]是对所采集到的网络样本通过训练所获得的数据随机性检测,并进行置信度估算,用P值定义为待分类的数据进行空间概率分析,如果P值相对于正常网络数据基准库的空间值越大,则表明其类属于网络正常行为的可能性就越大。 4网络安全检测模型应用测试分析 以网络安全评测基准评测数据集KDD Cup99[12,13]为模型数据采集参考,攻击类型主要包括:DoS、Probe、R2L、U2R。在检测模型中,记录的属性值包括34个,字符属性包括7个。其中,正常数据占18.69%,异常数据占81.34%。在网络数据库中,以随机的方式抽取10个数据子集,其中每条子集都包含有1000个记录,用此进行安全检测模型应用测试。在进行性能评估时,在这些数据中随机抽取3组,作为样本数据。其中,每个数据子集都包含有10000条记录,其中已知异常记录数约为1.8%-2.0%。数据样本如表1所示: 表1 样本 传统K-means算法与改进后的K-means算法在检测率、误检率、检测时间上的试验结果比对如表2所示: 表2 检测结果比对 通过表2可以看出,改进后的算法在检测率上提高了约为7.68%,误检率降低了2.86%,检测时间减少了15%。 传统Kmeans与改进后的Kmeans对不同攻击类型检测的效率试验如表3所示: 表3 传统Kmeans与改进后的 由表3可知,改进后的K-means算法的入侵检测的效果都明显优于传统K-means算法的检测效果,对DOS、Probe入侵类型入侵攻击的检测率比较高,但对于U2L和U2R的检测效率较低。U2L和U2R的检测率较低主要是因为测试数据集中这2种入侵记录数较少,训练时对其分类处理不太理想从而导致后期检测效果差,而且这2种入侵方式都是伪装成合法用户身份进行入侵攻击,其表现特征与正常网络数据包的特征十分相似,容易造成较低的检测率。另一方面,改进后的K-means算法在误检率方面都比传统的K-means算法来得降低,但训练时很多R2L入侵记录混进了正常聚类,造成了其攻击类型的误检率普遍较高。 综合模型的检测结果分析,K值的取值对于网络安全检测的准确性和识别率具有关键性的作用,所以在实际应用中应结合各方面的因素,进行K值的选择,已达网络安全检测最优结果。 在大数据时代,对网络安全检测中异常数据与正常数据的归类以K-maeans聚类算法所设计的网络安全检测模型具有一定的可行性和实用型。值得注意的是,在模型的数据选择方面应充分考虑数据特征的代表性,避免数据冗余而造成算法效率的降低,同时在训练时,要采用分层训练的方式,提取少量关键数据进行运算,逐步提高训练的难度,以增强训练的逻辑性,减少训练的耗时。 参考文献: [1] Nikolova E, Jecheva V. Some similarity coefficients and application of data mining techniques to the anomaly-based IDS[J].Telecommunication Systems,2012,50(2): 127-135. [2]谢卓.基于聚类学习算法的网络入侵检测研究[J].现代电子技术,2012,35(2):91-93. [3]费欢,李光辉.基于K-means聚类的WSN异常数据检测算法[J].计算机工程,2015,(7). [4]王祥斌.数据挖掘技术在入侵检测系统中的应用研究[J].计算机测量与控制,2012,(2). [5]刘长骞.K均值算法改进及在网络入侵检测中的应用[J].计算机仿真,2011,(3). [6] Bahraani B, Moseley B, Vattani A, et al. Scalable K-means++ [J]. Proceedings of the VLDB Endowment, 2012, 5(7): 622-633. [7]傅涛,孙亚民.基于PSO的K-means算法及其在网络入侵检测中的应用[J].计算机科学, 2011,38(5):54-55. [8]李红岩,胡林林,王江波,周红芳.基于K-means的最佳聚类数确定方法研究[J].电脑知识与技术,2014,(01). [9]王茜,刘胜会.改进K-means算法在入侵检测中的应用研究[J].计算机工程与应用,2015,(17). [10]杜强,孙敏.基于改进聚类分析算法的入侵检测系统研究[J].计算机工程与应用,2011, 47(11):106-108. [11]李向军,张华薇,郑思维,霍艳丽,张新萍.基于相对领域熵的直推式网络异常检测算法[J].计算机工程,2015,8(8):132-139. [12]Tavallaee, M.,Bagheri, E., Lu, W., & Ghorbani, A. A. (2009). A detailed analysis of the KDD cup99 data set. In Paper presented at the IEEE symposium on computational intelligence in security and defense applications (CISDA2009). [13]王洁松,张小飞.KDDCup99网络入侵检测数据的分析和预处理[J].科技信息,2008,15 (9): 443-494. The Application of K-means Clustering Algorithm Based on Big Data in Network Security Detection ZHENG Zhi-xian, WANG Min (Information Engineering Department, Fujian Chuanzheng Communications College, Fuzhou 350007, China) Abstract:With the advent of the cloud era, the application of big data has attracted increasingly great attention. The core of big data is to mine the hidden value chain in data, thus providing reference for decision-making. The clustering algorithm is a classification method of data mining, K-means is a clustering algorithm based on partition. In the network security detection, the establishment of network anomaly detection model based on K-means can effectively improve the ability to centrally select data with accuracy in large data environment, control the detection false alarm rate and shorten the time for network anomaly data selection. However, the traditional K-means clustering algorithm has its uncertainty in the aspects of the selection of data type pretreatment, the selection of initial center and determination of K value and so on, which leads to lower efficiency in intrusion detection. This paper proposes an improved K-means algorithm, and uses the KDDCup99 data set to carry out the simulation experiment, which proves that the improved K-Means algorithm is better in the detection accuracy and detection efficiency than the traditional algorithm. Key words:big data; the network security detection; K-means clustering algorithm 收稿日期:2016-01-02 基金项目:福建省教育厅B类科技项目(JB13292) 作者简介:郑志娴(1979-),女,福建福州人,讲师,硕士,研究方向为计算机技术。 中图分类号:TP311 文献标识码:A 文章编号:1674-344X(2016)02-0036-05 王敏(1976-),女,重庆人,副教授,硕士,研究方向为计算机技术。