基于跨平台的连续最大流图像分割并行实现
2016-07-14章柳燕郭春生
章柳燕,郭春生
(杭州电子科技大学通信工程学院,浙江 杭州 310018)
基于跨平台的连续最大流图像分割并行实现
章柳燕,郭春生
(杭州电子科技大学通信工程学院,浙江 杭州 310018)
摘要:针对连续最大流算法计算效率不高且平台局限的特点,提出了基于OpenCL的连续最大流算法并行实现.在算法并行特征分析基础上,将迭代求解最大流优化问题并行实现.合理调用异构平台的CPU和GPU,实现算法在不同硬件平台的高性能与平台移植.实验结果表明,在保证图像分割质量下,算法的GPU并行实现较CPU实现有数量级的提升;算法在AMD,Nvidia和Intel三大主流平台上通用计算运行,验证了算法的有效性和平台的可移植性,基本满足实际应用的要求.
关键词:OpenCL;并行计算;图割;连续最大流;跨平台
0引言
图像分割是更高层次图像与视频分析的基础.传统的图像分割算法对低分辨率简单图像具有很好的实时性,但随着图像分辨率的不断提高,以及类型多样性和内容复杂性,对图像分割的实时性需求也随之提高.近年来,随着开放式计算语言(Open Computing Language,OpenCL)异构编程框架的提出,使用CPU,GPU和其他处理器进行通用目的的并行编程引起了广泛关注.如文献[1]基于OpenCL实现FFT算法,在最佳异构平台上,使功耗减少了48%,性能提升了58%.目前最大流模型已逐渐成为图像分割领域的主流工具,连续最大流方法相对离散方法具有度量误差小和可并行实现的优点.文献[2-3]研究了连续最小流问题,而文献[4]提出的连续最大流方法相对上述方法具有收敛速度快、参数选取广泛的优点,文献[5]在文献[4]工作的基础上进行了改进.然而到目前为止,连续最大流算法计算效率并没有得到实质性的提升,且有平台局限性.因此,本文通过深入分析连续最大流算法并行特性,结合OpenCL编程模型,将迭代求解连续最大流在OpenCL跨平台框架下并行实现,基本满足图像分割的实时性要求.
1连续最大流算法
基于能量泛函的图像分割方法已得到广泛应用,其中连续最大流/最小割是解决这类问题的重要手段之一.连续的最大流/最小割算法[4]可以表示为:
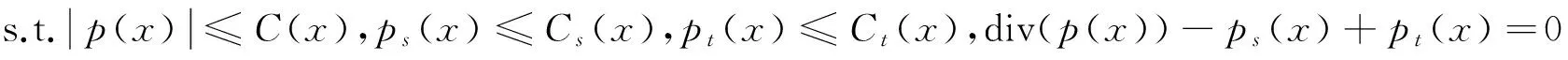
(1)
式中:Ω∈R2为闭区域,s和t分别为源点和汇点.对于任意x∈Ω,设点x的空间流为p(x),源流为ps(x),汇流为pt(x).C(x)为空间流的容量限制,Cs(x)为源流的容量限制,Ct(x)为汇流的容量限制.
对于约束优化问题,引入拉格朗日乘子λ将其转化为与式(1)等价的极大极小值对偶问题可得:
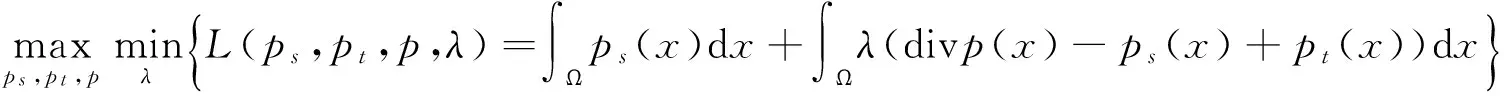
(2)
若定义罚参数c并构造增广拉格朗日函数,则式(2)的目标函数转化为:
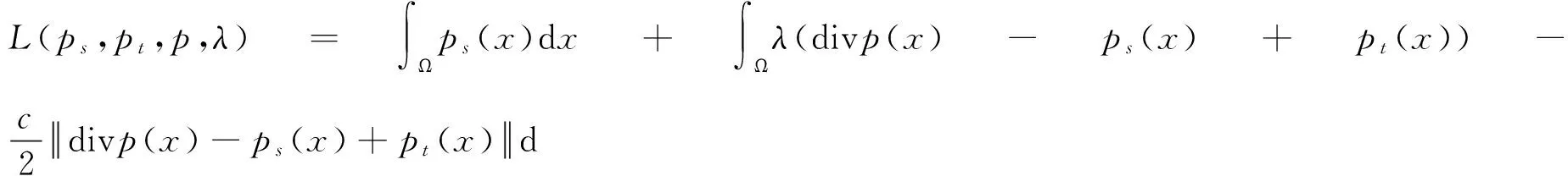
(3)
2基于OpenCL的算法并行实现
2.1算法的并行特征分析
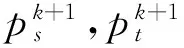
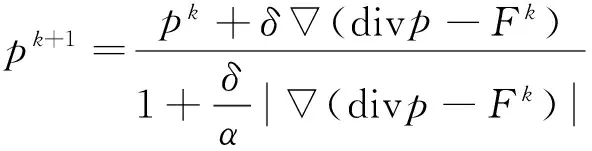
(4)
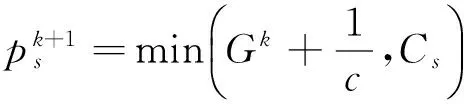
(5)
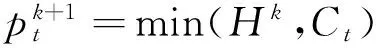
(6)
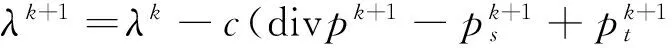
(7)
每一次求解运算数据输入都是上一次输出的更新值,即k+1次迭代更新运算只能串行执行.但在每一次更新求解各个分量时,都需对待分割图像的所有像素点进行遍历.而每个像素点之间处理相关度低,利用这种性质,可以对图像像素的处理实现并行运算.
2.2内核任务划分
在算法并行特征分析的基础上,首先将子问题优化求解过程定义成内核来实现.设计在设备端定义10个内核,其中7个内核对应空间流更新内核模块,其他3个分别对应源流更新内核模块、汇流更新内核模块以及拉格朗日乘子更新内核模块.具体实现过程如下:
1)空间流更新内核对应式(4),其中空间流p=(p1,p2),3个内核对应空间流按选取的合适步长进行梯度下降,对应式pk+1=pk+δ(divp-Fk).1个内核对应求解投影,满足式(4)的约束条件∞≤α,这是最小化问题有解的必要条件.之后,3个内核将按照式(4)对空间流p进行半隐式迭代和散度divp的更新.
2)按阈值方法设计2个内核完成源流和汇流的更新,其中源流内核更新对应式(5),汇流内核更新对应式(6).按式(7)设计1个内核完成拉格朗日乘子更新.
定义完成10个内核的具体任务后,每个内核结合OpenCL数据并行模型,完成数据并行规划.下面具体分析单个内核处理的数据并行划分过程,每个内核需要针对整幅图像进行处理,内核被提交命令在设备上执行后,系统会创建1个整数索引空间(NDRange),对应索引空间中的各个点称为工作项(work-item).如图1所示,将待分割的原始图像映射到二维索引空间上,为充分利用GPU并行特性并考虑算法涉及差分运算,设置2个维度上工作项的数量分别为图像的高度(H)+1和宽度(W)+1,每个维度都以像素点的形式给出,通过获取工作项的全局索引对应数据在向量中的位置,如指定的某个工作项全局ID为i×H+j(i≤图像的宽度W,j≤图像的高度H),取出相同位置的数据进行相应操作.尽管指令序列相同,但通过全局ID选择的数据不同,因此各个工作项的行为也不同.工作项可以组织为工作组(work-group),设计默认,让OpenCL自动分析决定如何在设备上的处理单元间分配工作项.划分完成后,每个OpenCL工作项都执行相同的指令并按照当前的索引读取存储的数据来求解更新,从而实现并行计算.
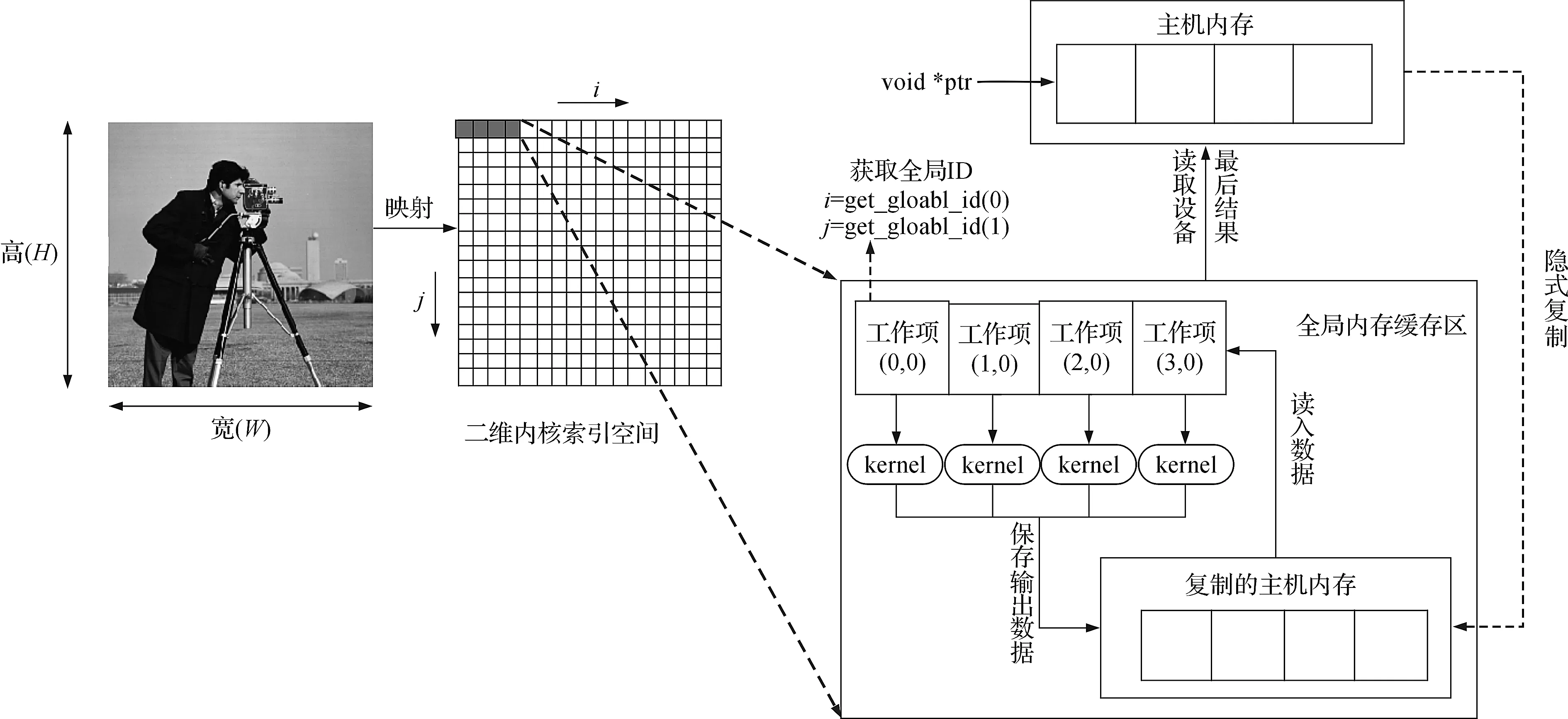
图1 内核数据并行划分示意图
在10个内核顺序执行时,数据要在主机内存和设备内存之间来回传输,但数据的频繁传输或数据量很大时,运算速度会明显降低.为优化性能,设计在设备上建立全局内存缓冲区,如图1中选取了4个工作项进行示意,访问性设为可读可写,并在全局内存缓冲区开辟新的内存区,将主机端的数据隐式复制过来,使数据更加可靠地传输.工作项根据全局索引号依次读取数据并执行相同的内核操作,输出结果保存在新开辟的内存区.迭代执行上述步骤直到达到收敛精度.最后将数据从设备端传输回主机端.
2.3OpenCL程序实现
基于OpenCL实现算法并行,主机端主要负责OpenCL编程框架的搭建以及图像数据的输入和结果的输出.整个过程的计算都在设备端利用GPU并行执行.
实现OpenCL程序的第1步就是平台初始化.程序实现时将自主选取主流平台Intel,Nvidia和AMD,并调用clCreateContext创建上下文,提供平台上共享和使用资源的环境.主机和设备进行数据传输需要建立相关的内存区域,通过调用clCreateBuffer创建缓存对象来保存内核的数据.设备要执行内核,首先要构建内核.调用clCreateProgramWithSource创建程序对象后,读取内核源码进行编译链接.之后调用clCreateKernel创建内核,并调用clSetKernelArg向内核函数传递参数,参数设置与内核函数的形参表一一对应.程序实现关键部分就是内核的执行.命令队列是主机和设备间通信的纽带,接收到要在设备上完成的内核命令后,按先入先出原则发送到设备.调用clEnqueueNDRangeKernel对设备上的各种处理资源进行合理部署并顺序执行相应内核模块.每执行完1次4个内核模块,判断是否达到收敛精度,否则继续迭代直到满足收敛条件跳出循环.通过调用clEnqueueReadBuffer将结果从设备内存中读取到主机内存,最后进行资源的释放.
3实验分析
为了验证提出算法的可行性,分别选取标准测试图像(238×238)、现实图像(246×300)和自然图像(128×160)进行分割实验,如图2所示.硬件平台是2台装有不同OpenCLSDK的计算机,测试机1的开发环境为VisualStudio2010+NVIDIAOpenCL;测试机2的开发环境为VisualStudio2012+AMDOpenCL,具体测试硬件设备如表1所示.为验证平台的可移植性,测试平台分别选择测试机1的CPU+NvidiaGPU、测试机1的CPU+IntelGPU和测试机2的CPU+AMDGPU.分割结果如图3所示.从实验效果来看,本文算法的分割结果基本和单线程C代码运行效果基本一致,整体轮廓大致清晰,保证了算法的分割质量.

图2 不同类型原图

图3 OpenCL分割效果图
并行算法设计目的在于保证算法运行正确的同时尽可能提高计算效率,因此对运行时间的评估是评价并行算法性能的重要因素.对上述3幅原图在测试机1的CPU单线程运行时间和3个不同异构平台(CPU+GPU)下运行的时间进行对比,因图像复杂度和分辨率大小的不同,在不同异构平台并行执行相对CPU串行执行时间不一致,但都有数量级的加速效果,结果如表1所示.
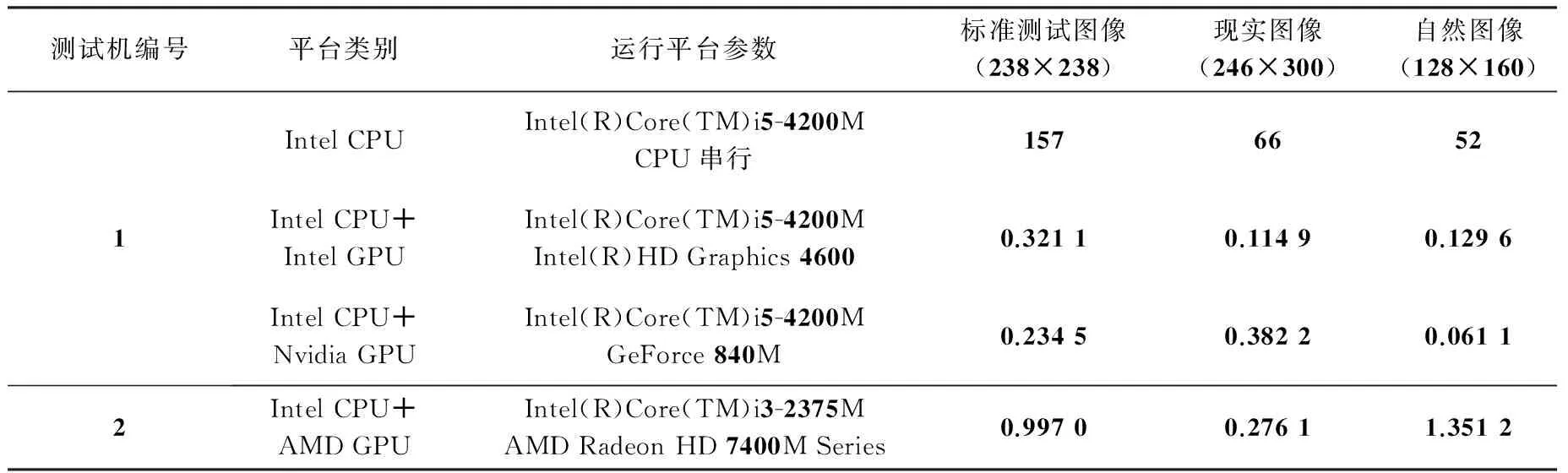
表1 不同类型大小的图像在不同平台下运行时间 ms
4结束语
高性能并行计算可以解决大量计算问题.本文对连续最大流并行特征展开了研究,将每一次迭代更新各个分量中对图像所有像素点的处理对应于设备GPU上多个工作项的并行执行.通过OpenCL搭建跨平台计算框架,使算法具有平台无关性和可移植性.在保证图像分割效果下,显著提升了图像分割速度,实时性好,在工程上具有一定的应用价值.
参考文献
[1]UKIDAVE Y, ZIABARI A K, MISTRY P, et al. Quantifying the energy efficiency of FFT on heterogeneous platforms[C]//Performance Analysis of Systems and Software (ISPASS), 2013 IEEE International Symposium on. IEEE, 2013: 235-244.
[2]STRANG G. Maximal flow through a domain[J]. Mathematical Programming, 1983, 26(2): 123-143.
[3]CHAN T F, ESEDOGLU S, NIKOLOVA M. Algorithms for finding global minimizers of image segmentation and denoising models[J]. SIAM Journal on Applied Mathematics, 2006, 66(5): 1632-1648.
[4]YUAN J, BAE E, TAI X C. A study on continuous max-flow and min-cut approaches[C]//Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010: 2217-2224.
[5]杨晓艺,王小欢,宋锦萍.连续最大流图像分割模型及算法[J].中国图象图形学报,2013,18(11):1462-1467.
[6]CHAMBOLLE A. An Algorithm for Total Variation Minimization and Applications[J]. Journal of Mathematical Imaging and Vision, 2004, 20(1-2): 89-97.
Parallel Implementation of Continuous Max-flow Image Segmentation Based on Cross-platform
ZHANG Liuyan, GUO Chunsheng
(SchoolofCommunicationEngineering,HangzhouDianziUniversity,HangzhouZhejiang310018,China)
Abstract:Aiming at the problem of the low computing and platform limitation on continuous max-flow algorithm, an OpenCL-based parallel implementation of continuous max-flow algorithm is proposed in this paper. The optimization problem of iterative solving max-flow is parallelly implemented based on parallel characteristics of algorithm analysis. High efficiency of algorithm as well as platform transition is achieved on different hardware architectures by reasonably invoking GPU and CPU. The experimental results show that the parallel algorithm achieved a significant improvement of computing speed compared with the CPU serial algorithm on the premise of ensuring the quality of image segmentation; the algorithm runs successfully on three main platform including AMD, Nvidia and Intel, which effectively verifies the validity and the cross-platform ability of the proposed algorithm in the paper, basically meet the practical application.
Key words:OpenCL; parallel implementation; graph cut; continuous max-flow; cross-platform
DOI:10.13954/j.cnki.hdu.2016.04.004
收稿日期:2015-11-25
基金项目:国家自然科学基金资助项目(61372157)
作者简介:章柳燕(1991-),女,浙江嵊州人,硕士研究生,电子与通信工程.通信作者:郭春生副教授,E-mail:guo.chsh@gmail.com.
中图分类号:TN911.73
文献标识码:A
文章编号:1001-9146(2016)04-0015-05
