基于R语言的数据挖掘课程实验设计
2016-07-07岳强胡中玉文瑾赵卿
岳强,胡中玉,文瑾,赵卿
基于R语言的数据挖掘课程实验设计
岳强,胡中玉,文瑾,赵卿
摘 要:大数据时代的到来,让数据挖掘知识和技术得到了快速的发展和应用。针对该课程实验存在的问题,设计了关联、分类和聚类实验方案,研究了Apriori关联算法、ID3分类算法和K-Means聚类算法,在R语言环境下实现了这些算法并对实验结果做出分析。通过教学实践表明,该课程实验有效地激发了学生的学习兴趣,培养了学生使用数据挖掘方法分析和解决问题的能力。
关键词:实验设计;数据挖掘;R语言;关联;分类;聚类
0 引言
数据挖掘是计算机科学与技术、软件工程等信息技术类专业一门非常重要的专业技术课程,在信息技术类专业的人才培养方案中占有重要地位。数据挖掘技术是一门综合性非常强的交叉学科,融合了数据库、人工智能、机器学习、统计学和模式识别等学科的内容[1]。为了让学生全面掌握数据挖掘原理和技术,必须将理论教学和实验教学良好结合,既要强调理论知识的讲解,更要重视实验内容的组织和设计,这样才能让学生真正掌握数据挖掘的精髓,达到学以致用的目的,提高专业核心技能。
1 课程实验存在的问题
1.1 学生知识结构存在缺陷
由于数据挖掘是一门交叉学科,所以要求学生也要具备多方面的知识和技能结构。一方面学生要具有良好的数理基础,另一方面也要具备优秀的程序设计能力。数据挖掘中的相关定义会涉及到大量的数学公式,数学基础比较薄弱的学生容易退缩,失去学习的兴趣。算法的实现过程又需要使用递归、多重迭代和集合操作等较复杂的编程技术,所以学生普遍感觉该课程内容晦涩难懂,实验任务难以完成,从而对课程产生畏难情绪[2]。
1.2 实验内容组织有待改进
数据挖掘是从海量的数据中获取知识的过程,实验开展时理想的情况是从大型的数据库中分析数据和挖掘知识,但受限于课程学时,各高校一般为该课程开设的学时数为32至48,实验学时只占课程学时的三分之一,所以在实验中不可能也没有必要使用海量数据,这就考核到了教师的教学组织能力,课堂教学内容需要优化整合,实验内容要真正做到“精练”。教师首先需要收集和整理一批数量和维度适中的案例数据,最好是能激发学生学习兴趣的,其次设计实验时应该提高设计性和综合性实验的比重,减少验证性和演示性实验的数目,让学生在有限的实验学时内训练到最重要的核心技能。另外,实验环境和软件工具的选取也非常重要,对时间、人力和实验资源都起到节约的作用。
2 基于R语言的数据挖掘课程实验设计
R语言是一款优秀的数据挖掘软件,和其他数据挖掘软件相比,它是一个免费的开源软件,简单实用,语句格式易于理解,只需具备基础的程序编制能力,就能快速上手,而且提供了功能强大的统计计算和图形绘制功能,有利于将挖掘结果图形化显示,方便学生观看实验效果[3]。下面以数据挖掘中最典型的3种关键技术关联分析、分类和聚类为例,使用R语言作为软件工具,设计了关联分析、分类和聚类的实验方案。
2.1 关联分析实验设计
关联是从数据集中发现频繁出现的项目集合模式,反映一个事件和其他事件的依赖关系,如果两项或多项属性间存在关联,那么其中一项的属性值就可以对其他属性值进行预测[4]。常用的关联算法有Apriori算法。
2.1.1 实验原理
关联规则是描述在一个事务中项目之间同时出现的规律的知识模式。一个事务中的关联规则挖掘可以描述如下:
设I={i1,i2,…,im}是一个项目集合,其中的每个元素i称为项目。数据集D={T1,T2,…,Tn}是一个事务数据库,其中每个事务T⊆I。每个事务都有一个标识符,称之为TID。
定义1 若A是项目集,当且仅当A⊆T时,则事务T包含了A。一条关联规则是形如A=>B的蕴含关系,其中A⊂I,B⊂I且A∩B=ϕ。
定义2 支持度表示的是事务集中包含A和B的事务数与所有事务数之比,记为support(A=>B)=P(A∪B)。支持度反映关联规则在数据集中的重要程度。
定义3 置信度表示的是包含A和B的事务数与包含A的事务数之比,记为confidence(A=>B)=P(A | B)。置信度衡量关联规则的可信程度。
Apriori算法是一种经典的关联规则挖掘算法,其他算法均是在此算法基础上进行改进。算法的核心思想是不断的扫描事务集,直到找出所有频繁项集。基于频繁项目集性质的先验知识,使用从下至上逐层搜索的迭代方法,k项集用于搜索k+1项集。
2.1.2 Apriori算法描述
输入:数据集D,最小支持度m in_support。输出:频繁项目集L。L1={large 1-itemset};
For (k=2;Lk-1≠ϕ;k++){Ck=Apriori-gen(Lk-1);For all transactions t∈D {Ct=subset(Ck,t);
For all candidates c∈Ctc.count++;}Lk={ c∈Ck| c.count ≥min_support}}Return L=∪Lk。
2.1.3 实验结果
实验数据采用模拟某超市的商品销售记录事务集,共50条记录,该事务集的部分数据,数据使用CSV格式存储,便于读取和修改[5]。如表1所示:

表1 超市商品销售事务部分数据
调用apriori()函数来挖掘关联规则,例如挖掘出支持度最小阈值为0.07,置信度最小阈值为0.5的关联规则,核心代码如下,结果如图1所示:

图1 关联规则挖掘结果
rule0=apriori(tr,parameter=list(support=0.07,confidence=0 .5))
从运行结果可以看出,此次共挖掘出11条关联规则,其中支持度最高的规则为{面包}=>{牛奶}这条规则(支持度为0.22)。
通过控制支持度和置信度来调整显示规则的数目,如将支持度最小阈值调整为0.1,算法挖掘出6条规则,结果如图1(b)所示:使用扩展软件包arulesViz,可以将关联规则图形化显示,关联规则的散点图如图2所示:
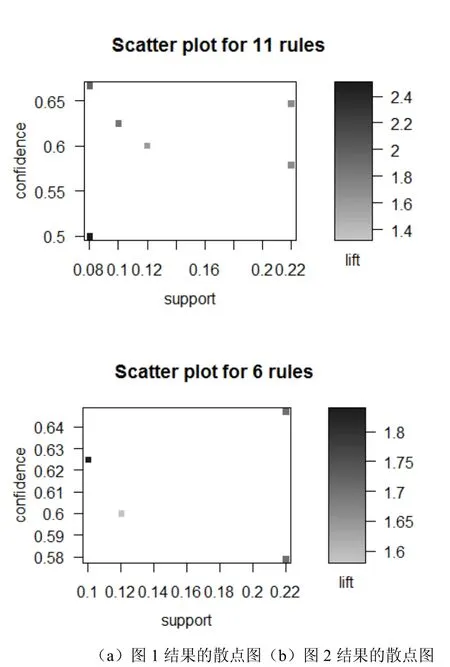
图2 关联规则散点图
2.2 分类实验设计
分类是按照分析对象的属性、特征,建立不同的组类来描述事物。分类过程分为两个阶段,第一阶段通过训练数据构造模型,可以使用分类规则描述该学习模型。第二阶段使用构造的模型进行分类,并评估模型的预测准确率[6]。常用的关联算法有ID3算法和C4.5算法。
2.2.1 实验原理
定义4信息熵:信息熵用来描述信息的不稳定程度,定义如公式(1):
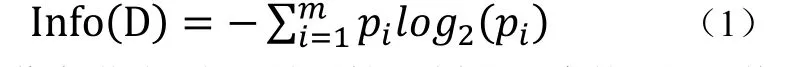
定义5 信息增益:假设按属性A划分D中的元组,其中属性A根据训练数据的观测具有v个不同值{a1,a2,…,av}。可以用属性A将D划分为v个子集{D1,D2,…,Dv},其中Dj包含D中的元组,它们在A上具有值Aj。这个量由下式度量如公式(2):
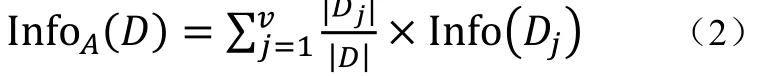
Gain(A) = Info(D) - InfoA(D) (3)
ID3算法是一种典型的决策树算法,主要针对如何选取属性。决策树算法通常分为两个步骤:决策树生成和决策树剪枝。构造决策树采用的是自上而下的递归方法。首先选择训练数据的某个属性作为根结点,对测试属性的每个值(离散化)创建一个分支,然后选择信息增益值最大的属性做为分裂属性,并据此划分样本。算法使用同样的过程,递归形成每个分支下的子分支。
2.2.2 ID3算法描述
输入:训练数据T,类别属性C,非类别属性集合R。
输出:决策树。
Begin
If (T is Empty) Then Return(null);
If T是由其值均为相同类别属性值的记录组成 Then返回一个带有该值的单节点;
If (R is Empty) Then返回一个单节点,其值为在T的记录中找出的频率最高的类别属性值;
将R中属性之间具有最大Gain(D)值的属性赋给D;将属性D的值赋给{dj∣j=1,2,…,m};
将分别由对应于D的值为dj的记录组成的T的子集赋给{Tj∣j=1,2,…,m };
返回一棵树,其根标记为D,树枝标记为d1,d2,…,dm;
再分别构造以下树:ID3(T1,C,R-{D}),ID3(T2,C,R-{D}),…,ID3(Tm,C,R-{D});
End
2.2.3 实验结果
实验部分数据如表2所示:

表2 样本数据集部分数据

20..35 High No Fair No 20..35 High No Excellent No 35..50 High No Fair Yes >50 Medium No Fair Yes >50 Low Yes Fair Yes
记录了用户的年龄、收入、信用等级和是否有购车意愿等一些信息。以“是否购车”属性做为类别属性,通过调用分类算法建立决策树。
调用J48()函数来产生决策树,J48()函数实现了C4.5分类算法,C4.5算法的核心函数是ID3分类算法,核心代码如下,运行结果如图3所示:
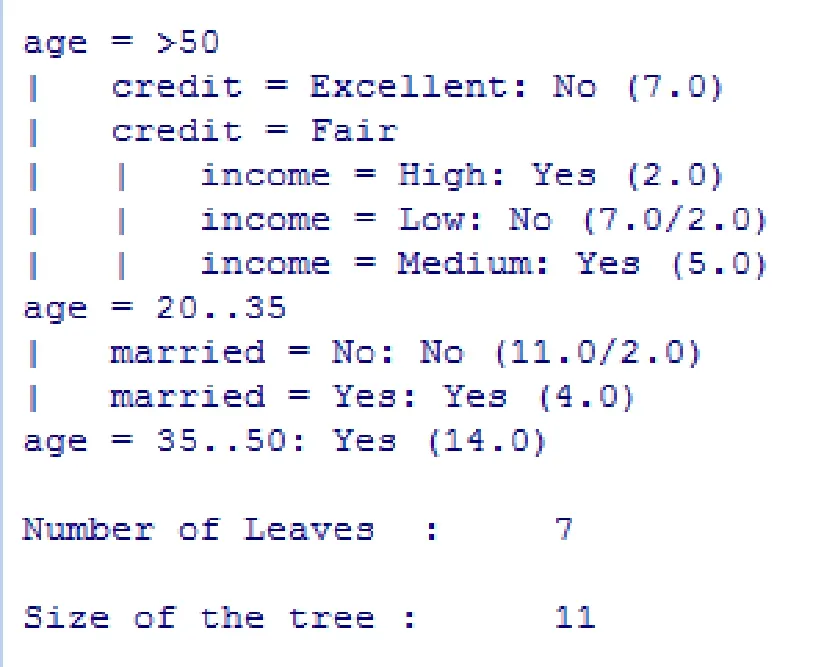
图3 分类结果图
formula=class$buy_car~age+income+married+credit
c45=J48(formula,data=class)
结果以缩进的方式显示决策树的层次结构,从结果中可以看出此次产生的决策树共有11个结点。从根结点出发到达叶结点就形成一条形如If…Then结构的分类规则,如第一条分支代表的分类规则是If age>50 and credit=Excellent Then buy_car=No。使用扩展软件包partykit,将结果决策树绘制成树形形状,如图4所示:
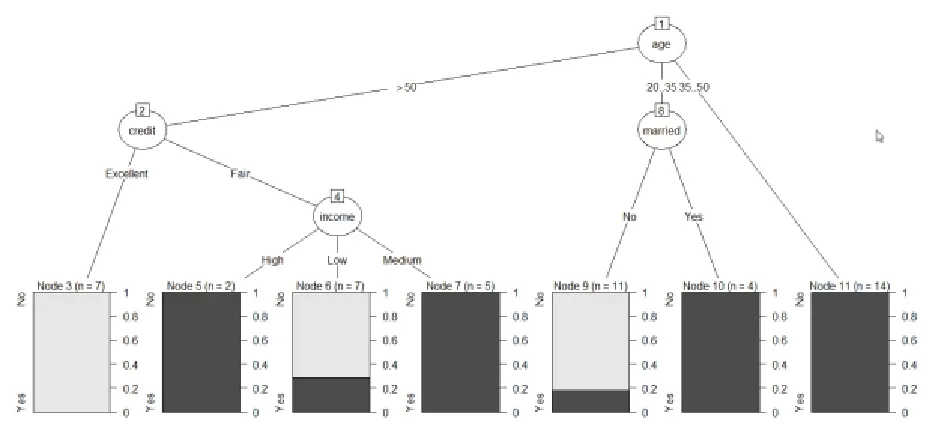
图4 决策树
2.3 聚类实验设计
聚类是将数据对象分成为多个类或簇,划分的原则是在同一个类中的对象之间具有较高的相似度,而不同类中的对象差别较大。与分类不同,聚类划分的类是未知的,类的形成是由数据分析得到的。常用的聚类算法有K-Means算法、K-Medoids算法等。
2.3.1 实验原理
聚类分析是一个活跃的研究领域,已经涌现出大量的聚类算法,这些算法按照分析思路划分,可以分为(1)划分法,如K-Means算法;(2)层次法,如DIANA算法;(3)基于密度的算法,如DBSCAN算法;(4)基于网格的算法,如STRING算法;(5)基于模型的算法,如SOM算法[7]。每类算法本身并无优劣之分,使用者要根据数据特性来选择合适的聚类算法。
定义6 给定一个有n个对象的数据集,聚类将数据进行k个划分,每一个划分乘坐一个簇,k≤n。这k个划分满足下列条件:(1)每个簇至少包含一个对象;(2)每一个对象属于且仅属于一个簇。
K-Means算法是使用的最广泛的聚类算法,它将n个对象划分成k个簇,簇内的对象具有较高的相似度,而簇间的对象的相异度较高 。相似度根据一个簇中所有对象的平均值来计算。算法首先随机选取k个对象,这些对象被认为是它所在簇的中心,计算剩余对象与各个簇中心的距离,将它归到最近的簇,然后重新计算每个簇的平均值。重复这个过程,直到准则函数收敛[13-15]。
定义7K-Means算法的准则函数定义为公式(4):
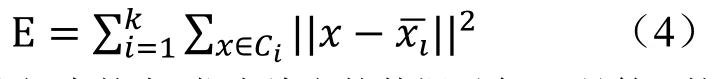
其中x是空间中的点,代表给定的数据对象,xi-是簇Ci的平均值。
2.3.2 K-Means算法描述输入:数据集D,要划分的簇的数目k。输出:k个簇的集合。从D中随机选取k个对象做为初始簇的中心;Repeat;根据簇中对象的均值,将每个对象分配到最相似的簇中;重新计算每个簇中对象均值;计算准则函数E;Until 准则函数不再发生变化。
2.3.3 实验结果
实验数据来自某年我国各省市的出生和死亡情况,数据如表3所示:
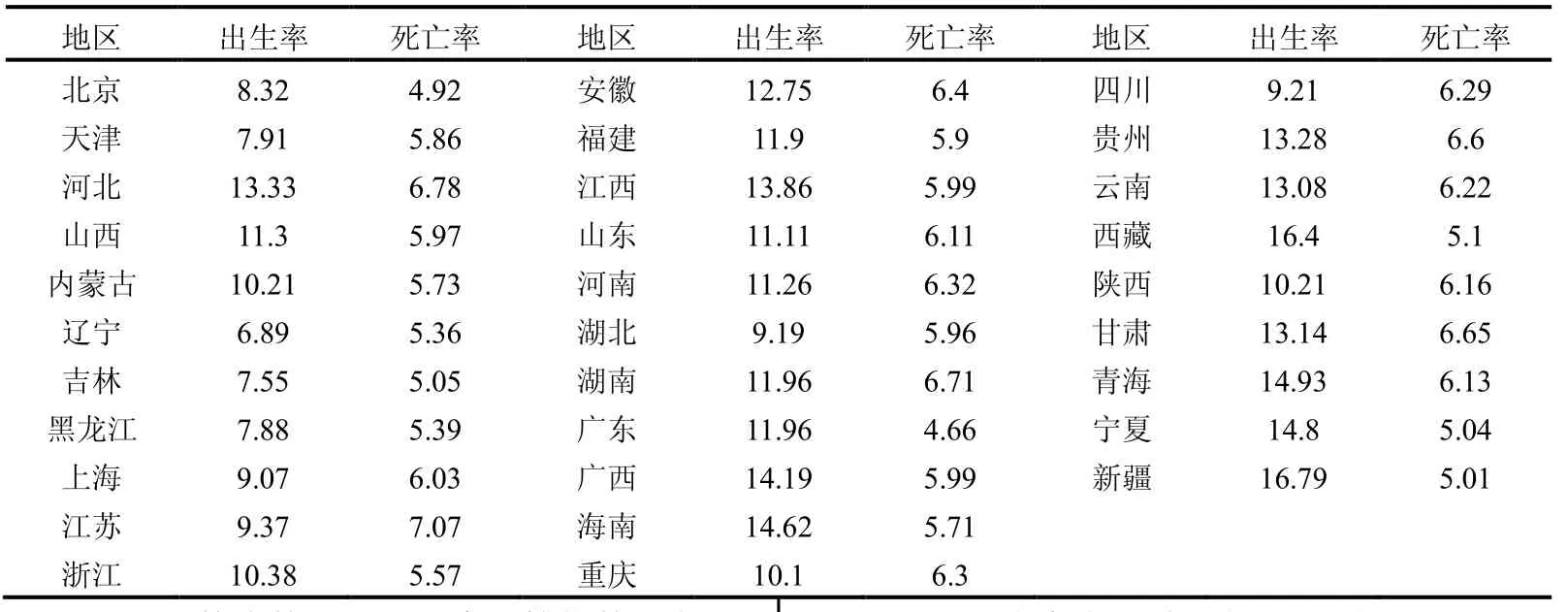
表3 全国各省市出生死亡情况统计数据
调用kmeans ()函数将数据进行分类,簇的数目定位3,即将数据分为3类,核心代码见下,运行结果如图5所示:

图5 聚类结果图
km1=kmeans(pv[,-1],center=3)
以上结果显示了3个类别所含的样本数,分别为9、10 和12,每个类别的出生率和死亡率的均值,以及每个样本所属的类别。
将每个样本图形化显示,横坐标为出生率,纵坐标为死亡率,用不同的符号代表不同的聚类,星号“*”代表每个聚类的中心,可以认为3个类别分别代表低、中、高出生率的省市。为使图中显示的内容更加直观,选取每个聚类的样本点以及出生率最低和最高的样本点强调显示,并在样本点下方显示出省市名,结果如图6所示:
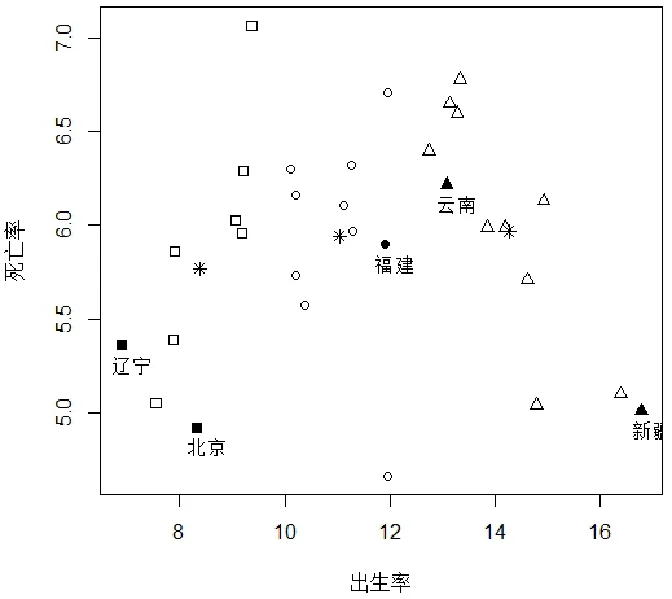
图6 显示名称的样本分布图
聚类的数目是不确定的,以上实验的聚类数取值为3,要选择出最好的聚类数,可以使用聚类优度来度量。聚类优度用下式计算如公式(5):

实现代码如下:
count=nrow(pv)-1
opt=rep(0,count)
for (i in 1:count)
{
km1=kmeans(pv[,-1],center=i)
opt[i]=km1$betweenss/km1$totss
}
round(opt,2)
运行结果如图7所示:

图7 聚类优度结果图
从结果中可以分析得出,当聚类数小于等于8时,随着聚类数的增加,聚类优度的值变化明显,从0.68快速增长到0.97,相应的聚类效果越来越好。但聚类数大于8后,聚类优度变化缓慢,其变化趋势如图8所示:
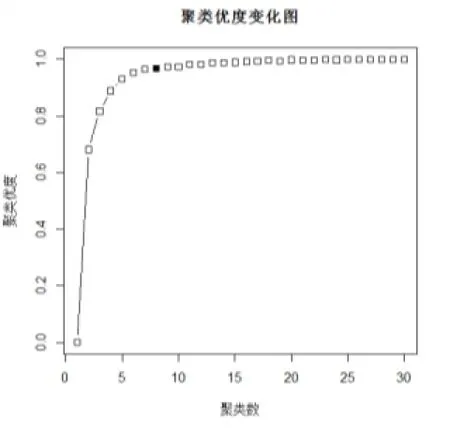
图8 聚类优度变化趋势图
3 总结
为解决数据挖掘课程教学过程中出现的问题,在收集和组织实验数据的基础上,本文设计了关联、分类和聚类3个重要的数据挖掘实验方案,分析了Apriori关联算法、ID3分类算法和K-Means聚类算法,使用R语言实现了这些典型算法,对实验结果做出分析,并以图形化的方式直观显示实验结果。通过教学实践,取得了良好的教学效果,激发了学生学习该课程的兴趣,培养了学生知识发现和创新能力。大数据时代的到来,让数据挖掘技术得到快速发展和应用的良机,高校的师生更应抓住契机,熟练掌握数据挖掘的技能,提升专业核心竞争力。
参考文献
[1] Jiawei Han,M ichelineKamber.数据挖掘概念与技术[M].北京:机械工业出版社,2003.
[2] 胡中玉,岳强,徐东霞.基于Matlab的方波分解与合成仿真实验设计[J].实验技术与管理,2014,31(9):44-46.
[3] 黄文,王正林.数据挖掘:R语言实战[M].北京:电子工业出版社,2014.
[4] 岳强,刘渝妍.基于主-子表的挖掘模式存储方法研究[J].昆明大学学报,2006,17(4):44-47.
[5] 岳强,胡中玉,刘渝妍.基于数据挖掘的自适应入侵检测模型研究[J].软件,2015,36(9):48-51.
[6] 孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2018,19(1):48-61.
[7] 刘猛.一种基于云计算的高效数据挖掘框架研究[J].微型电脑应用,2015,31(6):15-19.
Experiment Design of Data M ining Course Based on R Language
Yue Qiang, Hu Zhongyu, Wen Jin, Zhao Qing
(Kunming University, Kunming 650214,China)
Abstract:With the com ing of Big Data, know ledge and technology of data mining develop very quickly. In view of the problems in the data mining experiments, plans about association, classification and clustering are designed. The Apriori algorithm, ID3 algorithm and K-Means algorithm are researched. These algorithms are realized by using R language, and experimental result is analyzed. Through the teaching practice, the experiments can inspire students' interest in learning effectively, and train ability of students to analyze and solve problems by using data mining method.
Key words:Experiment Design; Data mining; R language; Association; Classification; Clustering
中图分类号:TP18;TP311
文献标志码:A
文章编号:1007-757X(2016)05-0031-04
基金项目:云南省教育厅科学研究基金项目(201Y237)、昆明学院科学研究项目(XJL15013)
作者简介:岳 强(1977-),男,昆明市,昆明学院,讲师,硕士,研究方向:数据挖掘、软件工程,昆明,650214胡中玉(1981-),女,昆明市人,昆明学院,讲师,硕士,研究方向:计算机仿真,昆明,650214 文 瑾(1963-),男,昆明市人,昆明学院,副教授,学士,研究方向:软件测试技术,昆明,650214 赵 卿(1979-),男,昆明市人,昆明学院,讲师,硕士,研究方向:软件工程,昆明,650214
收稿日期:(2016.02.10)
