FP-grow th算法改进与分布式Spark研究
2016-07-07邓玲玲娄渊胜叶枫
邓玲玲,娄渊胜,叶枫
FP-grow th算法改进与分布式Spark研究
邓玲玲,娄渊胜,叶枫
摘 要:频繁项集的挖掘一直是数据挖掘领域重要的研究方向之一。FP-grow th算法作为无剪枝算法的代表算法被广泛应用于事务数据集的挖掘中。但是FP-grow th算法对计算和数据集的规模是敏感的,一方面构建FP-tree过程中查找操作作为主要耗时操作时间复杂度较高,另一方面在数据集的横向或纵向维度较大时将使挖掘效率降低甚至失败。解决以上问题的高效而广泛使用的策略是降低搜索时间复杂度和应用分布式计算。提出了一种基于Spark框架和改进FP-grow th算法的分布式DFP算法,试验结果表明,相比于基于MapReduce框架的PFP算法、基于Spark框架和原始FP-grow th算法实现的PFP_SPK算法,DFP算法更加高效,集群和数据伸缩性更好。
关键词:频繁项集;FP-grow th;Spark;效率;
作者介绍:邓玲玲(1990-),女,南通,河海大学,计算机与信息学院,硕士研究生,研究方向:云计算、数据挖掘,南京,211100娄渊胜(1968-),男,延津,河海大学,计算机与信息学院,副教授,博士,研究方向:分布式应用集成、软件复用及软件体系结构,南京,211100 叶 枫(1980-),男,山东,南京航空航天大学,计算机科学与技术学院,博士研究生,河海大学,计算机与信息学院,讲师,研究方向:数据挖掘、机器学习,南京,211166
0 引言
关联关系是一种反应事物间的关联或者依赖的知识,关联规则的挖掘[1]试图在数据集中寻找隐含的或者令人感兴趣的关联关系,是数据挖掘领域重要的研究方向之一。在诸多关联规则算法中,FP-grow th算法[2]是一种无剪枝算法,采用分而治之的思想将构造的FP-tree分解为若干条件模式子树,每个条件子树都对应着一个频繁项集,通过递归地挖掘这些条件子树从而得到事务数据库的频繁项集。当前,文献[4-8]已经对FP-grow th算法进行了很多的研究,但是该算法依然存在如下导致效率低下甚至挖掘失败缺陷:第一,当事务的横向或纵向维度很大时,由于构建的FP-tree过大无法放入内存而导致频繁项集挖掘的失败;第二,在对FP-tree的递归挖掘过程中,频繁地构建条件模式基使得空间复杂度过高造成挖掘失败;第三、扫描项头表和FP-tree节点的时间复杂度太高。所以需要一种较为合理的方案优化或者解决以上问题。Spark分布式计算框架能很好地适用于数据挖掘与机器学习。因此,本文提出了一种分布式Spark改进算法DFP,可大幅地提高频繁项集的挖掘效率。
1 相关工作
不少学者从各个角度对算法提出了优化或改进。如文献[5]中都提到通过对原始数据库的分解达到对大型数据库挖掘的支持目的,但是这种做法无法实现并行化,随着数据量的增加,其处理的时间也在增加。文献[7-8]通过扫描一次事务数据库构建出事务库的模式矩阵,然后利用该矩阵进行频繁项集的挖掘。但是在内存装载不下这个矩阵的时候,将导致挖掘的失败。在单机无法承载大型数据库的挖掘时,并行化FP-grow th算法实现则成了众多学者研究的内容。例如文献[4、6、8]等提出了MapReduce环境下FP-grow th算法的实现途径。其中文献[6]的实现基于数据本地化的思想减少了网络通信量。而其他几个文献的核心都是基于PFP算法思想,只是在具体实现上进行了优化。
综上,虽然以上介绍的相关工作从各个角度对算法进行了优化或者改进,但是在大数据环境下,依然不够理想,对此本文提出了一种Spark环境下FP-grow th算法的改进算法DFP,通过优化项头表和FP-tree的数据结构降低搜索时间复杂度,将挖掘过程拆为局部频繁项集的生成和全局频繁项集剪枝两个阶段来解决海量数据并行分析问题,并基于UCI数据集进行了对比试验,结果表明,DFP算法在执行效率上更加高效。
2 FP-grow th分析与改进
FP-grow th算法借助FP-tree实现无候选项集的频繁项集挖掘,算法详细描述如文献[2]中,该算法在挖掘过程中每插入一条事务均需要对该事务按照项头表中项目的顺序进行排序,时间复杂度为O(n2),而将每个项目插入到FP-tree中同样需要将项目与节点的子节点进行比较,搜索时间复杂度高。
(2)构建全局候选项集。通过Spark算子collect收集所有节点的局部频繁项集,取后并集作为候选项集分发到各个节点,统计出候选项集中候选项目集的出现次数,通过与最小支持度m in_sup比较得出最后的全局频繁项集。
曼香罗驾乘壶天晓的灰色翼龙,像小飞虫似的从一个暗洞里钻进去,又从另一个暗洞里钻出来。飞鼠追兵紧随其后,在云洞里穿梭。频繁地闪来躲去,让大家都有些晕头转向,因此谁也没敢先发第一枪,以免误伤同伴。开始还和曼香罗并驾齐驱的宴西园,不一会儿便去向不明,他乘着棕色翼龙,再也没有出现在云团之外。或许,他又迷路了。

1 事务数据库D示例
FP-grow th算法中用到的两种数据结构为Header Table 和FP-tree。结合对FP-tree的挖掘过程,可以总结出Header Table的如下3个用处:
2)构建FP-tree时获取节点链;
1)扫描事务数据库D时,作为对事务的剪枝和排序依据;
1993年4月6日,我带着6岁的儿子从北京出发,乘坐东航MU583班机经上海飞往美国洛杉矶。那是架麦道MD11型客机。途中,飞机飞行一直很平稳,到高度为10100米时,大家觉得似乎已经平安抵达,人人脸色轻松。不料,飞机忽然抖动了一下,我的头顶被一巨大的平板状物体猛拍一记,一瞧,是飞机天花板!我飘浮在空中,身不由己,处于严重失控失重状态。后来才得知,这可能是飞行员起身时,无意中碰到了升降控制按钮。
3)对FP-tree进行挖掘时,保证挖掘的顺序性以及获取节点链构建条件模式基。
从以上功能可以看出Header Table结构直接影响到FP-grow th算法的性能。本文针对Header Table工作特点,对原始数据结构做出的修改以表1事务数据库D为示例数据,如图1所示:
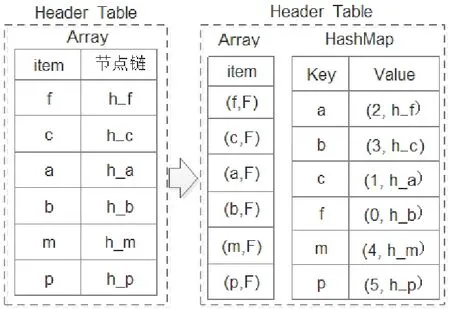
图1 Header Table数据结构修改示意图
改进体现在如下方面:
(1)原始数据结构中只有一个数组,其中数组元素是一个二元组:项目名和节点链头地址。修改后,相应数组变为了右图Array标签处所示的结构,其中二元组的第二个元素变为了布尔类型;
在时间复杂度上,以扫描一个事务并插入到FP-tree中为例,假设一个事务含有k个元素,则依据左图对其排序需用次数k· m,而将其插入到FP-tree中,需要检索m次,共需要比较m· m次,时间复杂度为,而根据右图的结构,排序时先根据项目名查找HashMap,找出下标值,并将右图数组中对应元组的布尔变量设置为True,时间复杂度为O( k),然后读取数组中布尔变量为True的项目名(并重置为False以便扫描下一条事务),将其插入到FP-tree中时间复杂度为O( m)。综合起来时间复杂度为,时间复杂度比改进前降了一个数量级。
综合可知,将一条数据库的事务从提取到插入FP-tree中,时间复杂度由改进前的O( m3)降低到了O( m),所以,改进的数据结构可以提高算法执行的效率。为了接下来的描述,本文将改进后的算法命名为IPF算法。
在空间复杂度上,假设单位存储为1,共有m个项目,其中左图结构占用的容量为2m,而右图结构占用容量为5m,相当于改进前的2.5倍容量,但是由于通常m较小,所以改进是可以接受的。
优质护理管理模式一种新兴起来的全新狐狸服务模式,优质护理管理模式的出现与近几年来人们经济建设和文明进步息息相关,当然,还有一点非常重要的原因是患者对医疗卫生服务要求的不断提高也是其中的一项重要因素[1]。为了探究优质护理管理模式在临床护理当中的应用效果,本文对2018年3月到2018年5月期间本院选取的其中112例皮肤科患者实施优质护理管理模式,并与传统常规护理效果进行简要的分析和对比。
聚氨酯防水涂料以异氰酸酯与多元醇、多元胺以及其他含活泼氢的化合物进行加工,生成的产物含氨基甲酸酯,因此被称为聚氨酯。聚氨酯防水涂料是防水涂料中最重要的一类涂料,无论是双组分还是单组分,都属于以聚氨酯为成膜物质的反应型防水涂料。
在集群伸缩性的表现性能上,本文进行如下实验:保持数据集支持度不变,集群节点数从1到5规模递增,其中一个Master节点,所有节点均为Salve节点,同时设定数据集的拷贝数变动范围为0~5,则对DFP算法的测试结果如图5所示:
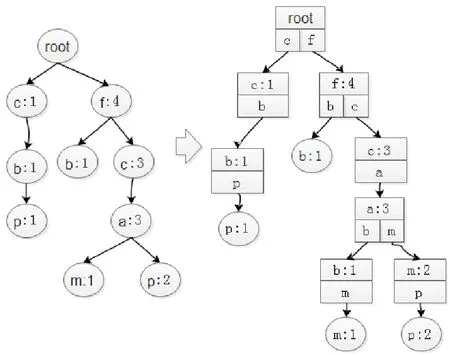
图2 FP-tree数据结构修改示意图
由于对子节点列表进行查询的时间复杂度为O( m),所以为了使查询效率增高,本文对每个节点的子节点数组进行修改,将其结构改为HashMap结构,如上右图所示,在这种情况下,查询的时间复杂度将变为O(1),时间复杂度降低了一个数量级。
(2)增加了一个HashMap类型元素,其中Key为右图所示数组中的项目名,Value是二元组:第一元素为项目名所在元组在数组中的下标,第二个元素为节点链头指针地址。
3 DFP算法实现研究
在数据量大、数据维度高的情况下,将整个数据库压缩到一颗FP-tree中很容易导致内存溢出。所以将IPF算法的运行放在分布式环境下,对数据分片分别运行IPF算法,最后合并局部频繁项集再进行一次全局的统计剪枝。这样不仅提高了数据分析效率,也解决了单机无法或高效处理海量数据的情况。
本文采用“搬运算”的方式对并行化IPF算法——DFP进行实现。可以将求取频繁项集的操作分为如下两个阶段进行:
两组患者不良反应情况对比,治疗过程中,对照组有1例患者出现皮肤瘀点、2例患者出现胃肠道反应、2例出现轻度牙龈出血;观察组中有1例患者出现皮肤瘀点、2例患者出现胃肠道反应、1例患者出现轻度牙龈出血。两组患者均出现了不同程度的不良反应,针对患者出现的不良反应并未给予特殊处理,均自行消退。组间不良反应发生情况对比,差异无统计学意义(P>0.05)。
(1)产生局部频繁项集。在分布式集群的m个节点运行IFP算法,求出每个节点的局部频繁项集;
针对存在的不足,本文将给出相应的改进方案,并加以实现形成一种新的FP-grow th改进算法:IFP。为了更好地进行描述,事务数据库D作为描述数据进行算法阐述,如表1所示:
为了使频度统计工作更加高效,算法再次在每个数据节点上构建FP-tree,通过对FP-tree的挖掘来统计项集的局部频度。以表1事务数据库D所构建的FP-tree为例,假设候选项集集合中有一个候选项集a={c,p},则有效的路径为标注的粗体部分路径图,如图3所示:
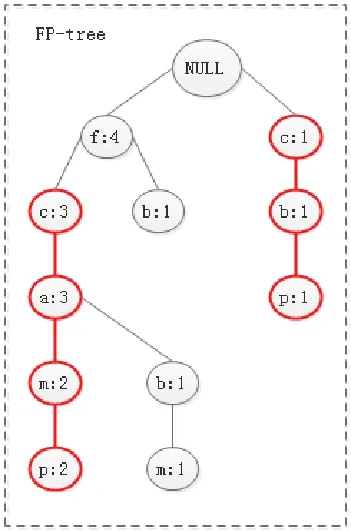
图3 有效查询路径
根据FP-tree的特点可知,除根节点以外,每个节点有且仅有一个父节点,所以算法采用自底向上进行搜索,确定相对p于FP-tree中出现频度最小的项目p ,根据Header Table和定位FP-tree中的所有项目名为的节点,从节点向上搜索。具体的匹配过程转换为最长公共子序列问题,所以一个候选项集与一条路径匹配的时间复杂度为,其中|α |为候选项集长度,|path |为路径所有节点个数,时间复杂度为线性的。
下面将以伪代码的形式给出DFP算法的实现过程,如下表2所示:

表2 Spark环境下DFP算法执行过程
4 实验结果与评估
为了验证本文实现的分布式算法SPFP的有效性,本文使用5台计算机(Intel Core i5,CPU 2.4GHz,内存为2GB)组成的分布式Spark集群。其中Spark集群的环境参数为:操作系统Ubuntu14.04,Hadoop版本Hadoop2.4.1,Spark版本为Spark1.2.0,算法的实现语言为Scala 2.10.4,JDK版本为JDK 7u55,其中Spark集群采取的主从式架构,一台计算机作为Master节点,其他4台计算机作为Salve节点。其中实验所使用的测试数据集为Accidents[3]数据集,数据来自比利时国家统计局获得的佛兰德地区1991年至2000年交通意外统计数据,数据集共340184条数据实例,含有572种不同的属性值,平均每条事务约含45个属性值。
本文采用了多次取平均的方式来消除单次试验带来误差。对以上3种数据集分别应用PFP_HDP、PFP_SPK和DFP算法,其中PFP_HDP算法是一种基于MapReduce架构的并行化FP-grow th算法,PFP_SPK算法是一种基于原始FP-grow th算法实现的基于Spark的并行化算法。则实验结果如图4所示:
入摩入富比例提升,国际资金加速涌入A股市场。根据MSCI的披露,2019年底将A股纳入份额由目前的5%提升到20%,届时A股占整个MSCI新兴市场指数将由目前的0.7%提升至3%。同时今年9月富时宣布将分三个阶段把A股1249只股票纳入富时全球市场指数,第一阶段将从2019年6月开始,到2020年中国A股将占富时新兴市场指数的5.6%。随着中国股市逐步融入国际市场,海外资金将通过北上渠道源源不断流入A股。高盛预计2019年因为MSCI纳入比例提升和纳入富时罗素导致的北上资金将达到650亿美元,相对于2017、2018年的300亿美元和400亿美元有较大增长。
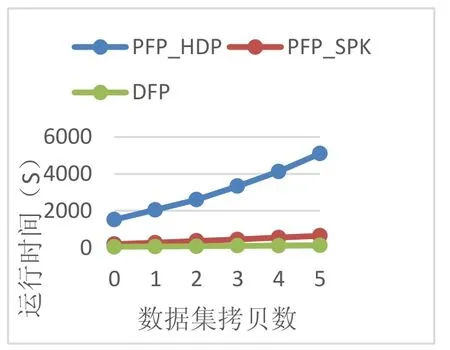
图4 Accidents:m in_sup=20%
分析可知,3种算法的执行时间与数据集的拷贝数增长呈正相关上升关系,其中PFP_HDP算法的上升幅度最为明显,由于PFP_HDP算法在运行过程中,在集群中存在大量的数据传输,同时由于MapReduce模型的高延迟、迭代特性支持不足等短板,导致算法的执行时间以几乎线性的方式增长,相比较,其他两种算法几乎保持水平方式增长。而得益于DFP算法改进的数据结构,DFP算法效率高出PFP_HDP算法20~50倍,比PFP_SPK算法也高出几倍。
全区三级地共24158.77公顷,占全区耕地面积的29.09%。其中,以孙岗镇最多,其面积为4279.67公顷,占三级地17.71%,东河口镇和张店镇次之且相差不大,清水河街道没有分布三级耕地。三级地主要分布在海拔较高且地形起伏相对较大,路网不够发达,土壤中微量元素含量较缺,农田基础建设一般满足或者很难满足的地区。这些农用地受主次干道的影响较小,受支路的影响较大。这些耕地远离人口聚集区,农产品与生产资料的交易受到一定限制。
同样地,针对FP-tree构建原理,以表3-1事务数据库D为示例数据,本文对FP-tree结构修改如图2所示:
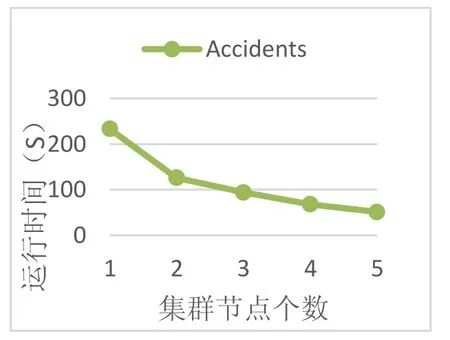
图5 Accidents:min_sup=20%
从图5的结果中可以看出,运行时间随节点的增多而有下降趋势,在节点少时下降幅度很大,随着节点变多,其几乎以线性方式递减,并有趋于水平的趋势。
本文通过对设备点检的重要性进行简单的阐述,进而分别从设备点检分类管理、设备点检分工管理、设备点检记录管理、设备点检检查管理4个方面对设备点检在大型养路机械管理中的应用进行详细的研讨与探究,并分别从设备保养与维护、设备点检人员的能力培训、制定全面的设备点检流程3方面对设备点检在大型养路机械管理中的应用要点进行详细的研究与思考。经过本文研究表明,在该设备点检的应用领域依旧存在着较多问题。因此,在未来的研究生活中,应进一步对设备点检在大型养路机械中的应用进行详细的研究与分析,希望本文能为设备点检在大型养路机械管理中的应用研究提供几点借鉴,并为大型养路机械管理的健全提供积极的推动作用。
综合可得,本文的实现算法DFP比其他算法的执行效率更高的同时,还具有良好的数据伸缩性和集群伸缩性。
5 总结
本文分析了传统关联规则挖掘算法FP-grow th的不足,并针对算法的不足分别从项头表和FP-tree数据结构的实现上、优化单路径问题等角度提出了优化。基于优化的FP-grow th算法,提出了Spark环境下的分布式实现算法DFP算法。最后分别从数据伸缩性和集群伸缩性两个角度对算法进行了对比试验,结果证明DFP算法是一种高效的频繁项集生成算法。
基于本文工作,下一步将考虑如何将本文实现算法应用在实际问题的分析中,尝试对现实的股票数据或者购物篮数据进行分析,并从中找出有意义的规则或关系。参考文献
[1] Fayyad U.,. Piatetsky-Shapiro G, and Smyth P., “From data mining to know ledge discovery in databases”[J], AI magazine, vol. 17, no. 3, p. 37, 1996.
[2] Jiawei Han, Jian Pei, Yiwen Yin. M ining frequent patterns w ithout candidate generation. Proceedings of the 2000 ACM SIGMOD International conference on Management of Data SIGMOD'00. Dallas[J], Texas, United States: ACM Press, 200, 29(2): 1-12P.
[3] Frequent Itemset M ining Dataset Repository[EB/OL].[20 -12-10-21]. http://fim i.ua.ac.be/data/, 2012.
因此,加强综合研究,对中国共产党生态文明思想的形成背景、发展历程、主要内容、经验措施等问题进行系统而深入的分析和探讨,将有可能成为学术界研究此问题的未来趋势。
[4] 杨勇,王伟. 一种基于MapReduce的并行FP-grow th算法[J]. 重庆邮电大学学报(自然科学版),2013,25(05): 651-657.
[5] 朱涛. 基于FP-grow th关联规则挖掘算法的研究与应用[D].南昌大学,2010.
[6] 章志刚,吉根林. 一种基于FP-Grow th的频繁项目集并行挖掘算法[J]. 计算机工程与应用,2014,02:103-106.
研究组并发症总发生率为6.82%,低于常规组15.91%,差异具有统计学意义(P<0.05)。详情见表2。
[7] 邓丰义,刘震宇. 基于模式矩阵的FP-grow th改进算法[J].厦门大学学报(自然科学版),2005,05:629-633.
由式(4)第1式、式(11)、式(12)、以及图1的△OA1B1、△OA2B2知,当φ为φ1、φ2时,φ为0、180,δ为δmax、δmin,α为α1、α2,注意到式(13)即知φ1、φ2是αmax可能出现位置。
[8] 陈兴蜀,张帅,童浩,崔晓靖. 基于布尔矩阵和MapReduce 的FP-Grow th算法[J]. 华南理工大学学报(自然科学版),2014,01:135-141.
Improvement and Research of FP-grow th Algorithm Based on Distributed Spark
Deng LingLing1, Lou Yuansheng1, Ye Feng1,2
(1. College of Computer and Information, Hohai University, Nanjing 211100, China;
2 College of Computer Science and Technology, Nanjing University of Aeronautics and Astronautics, Nanjing 210016, China)
Abstract:FP-grow th algorithm as the representatives of non-pruning algorithms is w idely used in mining transaction datasets. But it is sensitive to the calculation and the scale of datasets. When building FP-tree, the search operation as the major time-consuming operation has a higher complexity. And when the horizontal or vertical dimension of data set is larger, the mining efficiency w ill be reduced or even failed. To solve the above problems, reducing the complexity of search time and applying distributed computing are the w idely used strategies. This paper presents a distributed DFP algorithm based on Spark framework and improved FP-grow th algorithm. The results of tests show that, compared to the PFP algorithm based on MapReduce, the PFP_SPK algorithm based on Spark and original FP-grow th algorithm, DFP has high efficiency, cluster and flexibility.
Key words:Frequent Item Sets; FP-grow th; Spark; Efficiency
中图分类号:TP311
文献标志码:A
文章编号:1007-757X(2016)05-0009-03
基金项目:国家科技攻关计划(No. 2013BAB05B00 、No. 2013BAB05B01)
收稿日期:(2016.02.20)
