基于遗传聚类的配电变压器运行状态参数数据修复研究
2016-07-05朱江峰单林森黄建杨
朱江峰 单林森 黄建杨


摘 要:为了减少配网设备运行大数据在采集以及传输的过程中容易发生的丢失或者损坏,保证配网设备运行检修工作质量,提高整个电网的安全稳定性。本文结合了不完整信息系统原理、近邻传播聚类原理以及遗传优化算法原理,提出了一种面向配网设备运行状态的遗传聚类数据修复方法,充分有效的对大规模、复杂、不完整的配网设备运行参数进行分析以及修复。通过对实际配电变压器设备运行状态参数数据进行验证,结果表明所提出的方法有效的分析和修复了配电变压器设备运行状态参数数据,具有实际应用价值。
关键词:配网设备;运行参数;近邻传播聚类;遗传优化;数据修复
随着当代电力科学的迅速发展,电力行业的配电变压器设备运行状态参数正以前所未有的速度增长,配电变压器设备运行状态参数处于大数据时代。配网信息的大数据在采集以及传输的过程中都容易发生丢失或者损坏,导致配网设备运行检修工作质量下降,从而影响整个电网的工作质量。因此,针对配电变压器设备的不完整运行状态参数进行模式挖掘与填充修复的相关研究,有助于配电大数据信息的有效利用,对将强、健康智能电网的建设有着重要意义[ 1 ]。
传统数据填充方法没有充分考虑到数据对象之间的相关性,这就会导致填充的精度严重降低,如基于马氏距离的缺失值的填充算法、基于贝叶斯网络的缺失数据填充算法、决策树算法中属性缺失值的研究等[ 2-4 ]。上述传统数据填充方法通常简单的利用已有数据对缺失数据进行填充,并未考虑到数据对象的类别特征,使得填充值容易受到噪声的干扰,导致填充结果不精确。
本文提出了一种基于遗传聚类的不完整信息填充方法,通过把数据对象划分为完整数据集与不完整数据集,先对完整数据集进行聚类,聚类过程中利用遗传优化原理对聚类参数进行多次迭代优化得出聚类中心点。之后计算不完整数据点与每个聚类中心的相似度,把不完整数据点划分到相似度最大的类中,由于同一类数据相关性强,即可利用同一类数据中的完整数据对不完整数据进行填充,避免噪声对填充值的干扰,并有效提高缺失数据的填充精度。
1 基于遗传聚类的不完整数据修复理论
近邻传播(Affinity Propagation, AP)聚类算法是一种基于密度分布函数的方法的无监督聚类算法,是由Frey等人于2007年首次提出[ 5 ]。AP算法将所有数据样本均作为潜在聚类中心,自适应于数据样本进行聚类,无需预先设置类别数量。在程序运行中不断迭代搜索合适的聚类中心,自动识别聚类中心的位置以及聚类数目。其中,吸引度(Responsibility)表示以数据点k为数据点i聚类中心的适合程度,记做r(i,k)。而归属度(Availability)则表示数据点i选择数据点k为聚类中心的适合程度,记做a(i,k)。
AP聚类算法通过消息传播逐步实现对聚类中心的逼近,并通过如下更新规则对吸引度矩阵R=[r(i,k)]与归属度矩阵A=[a(i,k)]进行迭代更新[ 2 ]:
首先,计算N个数据点的相似度值,建立相似度矩阵S矩阵,同时设定偏向参数。其次,设置最大迭代次数maxits值,迭代计算吸引度矩阵R和归属度矩阵A,并根据r(k,k)+a(k,k)值判断是否为聚类中心(若(r(k,k)+a(k,k))>0则构成一个聚類中心;反之,则不是聚类中心)。最后,对于数据点i,选择r(i,k)+a(i,k)最大的数据点k为其真正聚类中心。值得注意的是,当迭代次数超过maxits值或多次迭代不发生改变时终止迭代。
遗传优化(Genetic Optimization)算法依据亲本初始化解,通过复制、交叉以及突变等操作产生子代的解,淘汰适应度较低的解以增加对最优解的逼近效果。本文引入遗传算法对传统近邻AP聚类中阻尼系数?姿、迭代次数最大值(maxits值)等聚类参数进行优化,用以提高聚类精度。遗传算法的具体过程包括编码方式及初始化、适应度函数设计、遗传操作、终止条件以及解码等五个环节[ 6 ]。在对数据进行聚类之后,由于同一类中的数据相似度高,不同类中的数据相似度低,本文利用与缺失属性的对象在同一个类当中的数据对象的相应属性的加权值作为该属性的预测值。这种方法的关键在于确定各数据对象的加权系数,为了能够客观准确的确定加权系数,本文采用信息论中熵值的概念,通过数据对象间的相似度提供的信息来确定加权系数。
2 仿真实例分析
2.1 基于遗传聚类的不完整数据修复的实现
为了验证本文所提出的遗传聚类算法对不完整数据的修复效果,本文使用基于PYTHON语言的仿真测试软件进行仿真测试,选取了国家电网公司某地区配网设备的运行台账数据中50个型号为S9-M-500/10,500kV配电变压器设备运行状态参数中的配电变压器短路阻抗、短路损耗、空载损耗、电压等级、绝缘介质以及额定容量等六类数据指标形成的指标向量作为样本数据。聚类时,根据遗传优化的结果,最大迭代次数maxits取10000次;聚类中心不变的最大迭代次数convits取50次;阻尼系数?姿取0.8。经过1468次迭代计算,聚类中心不变次数达到了最大值50次,停止迭代,计算得到样本聚类3个。
根据训练样本聚类情况,参考样本数据,并依据国际行业标准《ANSI/IEEE C57.123-2010 变压器损耗测量指南》以及《ANSI/UL 506-2008 专用变压器的安全标准》等文件对配电变压器设备运行状态的评定,样本聚类符合以下描述:
样本聚类1:以样本16为聚类中心,包括样本16、8、12、15、19、21、24、25、27、28、50等,此类样本设备服役时间为3年及3年以下,数据反映设备运行状况良好,稳定性较高。
样本聚类2:以样本35为聚类中心,包括样本1、2、3、4、6、7、9、10、13、14、17、20、22、23、26、29、30、31、32、33、34、36、37、38、39、40、41、42、43、44、45、46、48、49等,此类样本设备服役时间为4-8年,数据反映设备运行状况一般,存在着一定的设备损耗,稳定性与新设备相比,有所降低。
样本聚类3:以样本47为聚类中心,包括样本5、11等,此类样本设备服役时间为9年及9年以上,数据反映设备运行状况较差,设备损耗比较严重,设备运行稳定性较低。
根据对样本数据的有效聚类,本文选取了5个含有缺失数据的配电变压器设备运行状态参数数据数据样本进行修复填充。修复结果与原设备参数进行对比,修复样本1至5的修复精度分别为:98.73%、95.89%、94.38%、100%以及100%。
2.2 仿真对比实验结果分析
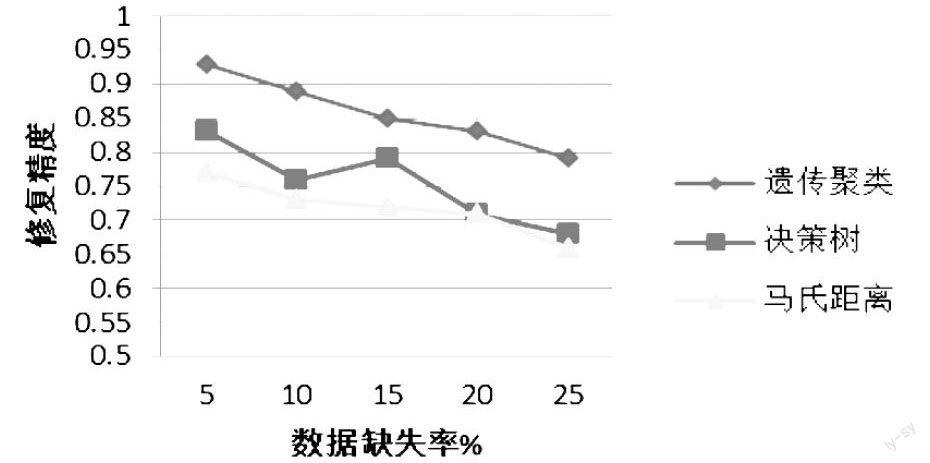
为了测试本文提出的算法的性能,将本文提出的算法同基于决策树的缺失数据修复算法、以及基于马氏距离的缺失数据修复算法进行比较,实验结果如图1所示。
由图1可知,随着数据缺失率的增长,基于决策树、基于马氏距离以及本文提出的基于遗传聚类三种数据修复算法的修复精度均有所下降。在以上三种算法中,本文提出的算法有效避免了不同類对象对数据填充的影响,因而修复精度明显高于另外两种算法。
除此之外,当数据缺失率超过15%时,随着缺失数据的增加,基于决策树的缺失数据修复算法以及基于马氏距离的缺失数据修复算法的修复精确度急剧降低,而本文提出的算法则比较稳定,充分说明本文提出的算法对待缺失率较高的数据集中依然能保持良好的效果。
3 结论
由于配电变压器设备运行状态参数数据在采集和传输过程中容易丢失,导致了大数据的不完整性,阻碍了大数据的分析精度。本文提出将一种直接针对不完整数据进行遗传聚类的方法应用于配电变压器设备运行状态参数数据分析上,给出了配电变压器设备运行状态参数数据的相似度度量方式,在此基础上利用遗传聚类算法对不完整配电变压器设备运行状态参数数据进行聚类。最后,利用数据聚类结果对不完整设计数据进行填充。
实验结果表明,本文提出的算法能够有效地对不完整配电变压器设备运行状态参数数据进行聚类,同时能够对不完整配电变压器设备运行状态参数数据进行有效填充。
参考文献:
[1] 田冰冰,刘念,刘琨等.基于改进蚁群算法的变压器诊断数据的约简[J].电力系统保护与控制,2011,39(1):96-99,122.
[2] 冷泳林,张清辰,鲁富宇等.基于AP聚类的不完整大数据填充[J].计算机工程与应用,2015,(10):123-127,141.
[3] 李宏,阿玛尼,李平等.基于EM和贝叶斯网络的丢失数据填充算法[J].计算机工程与应用,2010,46(5):123-125.
[4] 冷泳林,陈志奎,张清辰等.不完整大数据的分布式聚类填充算法[J].计算机工程,2015,(5):19-25.
[5] 刁赢龙,盛万兴,刘科研等.大规模配电网负荷数据在线清洗与修复方法研究[J].电网技术,2015,(11):3134-3140.
[6] 黄毅成,杨洪耕.改进遗传K均值算法在负荷特性分类的应用[J].电力系统及其自动化学报,2014,26(7):70-75.
作者简介:
朱江峰(1974-),男,汉族,浙江绍兴人,国家电网浙江省电力公司绍兴供电公司,高级工程师,硕士、研究方向:配电变压器检测、数据修复;
单林森(1981-),男,汉族,浙江绍兴人,国家电网浙江省电力公司绍兴供电公司,工程师,学士,研究方向:配电信息技术、模式识别;
黄建杨(1982-),男,汉族,浙江诸暨人,国家电网浙江省电力公司诸暨供电公司,工程师,硕士,研究方向:配电变压器检测、模式识别;
