结合全局特征的命名实体属性值抽取
2016-06-30伍大勇程学旗
刘 倩 伍大勇 刘 悦 程学旗 庞 琳
1(中国科学院计算技术研究所网络数据科学与技术重点实验室 北京 100190)2(中国科学院大学 北京 100049)3(国家计算机网络应急技术处理协调中心 北京 100029)(liuqian1104@126.com)
结合全局特征的命名实体属性值抽取
刘倩1,2伍大勇1刘悦1程学旗1庞琳3
1(中国科学院计算技术研究所网络数据科学与技术重点实验室北京100190)2(中国科学院大学北京100049)3(国家计算机网络应急技术处理协调中心北京100029)(liuqian1104@126.com)
摘要关注非结构化文本中命名实体属性值的抽取问题.当前主流有监督属性值抽取方法仅使用局部特征,抽取效果有限,开展了利用文本全局特征改善属性值抽取的研究.通过适用于中文属性值抽取的全局特征,用局部特征以外的有价值信息提高抽取效果.据此,提出结合全局特征的感知机学习算法,该算法能够方便地融合文本全局特征,并将全局特征和局部特征统一结合到模型学习过程中,使模型具有更好的特征表示能力.实验结果表明,所提出方法的整体抽取效果高于仅使用局部特征的CRF模型和平均感知机模型.该方法适用于开放领域的属性值获取,具有较好的泛化能力.
关键词实体属性;属性值抽取;命名实体;全局特征;平均感知机
命名实体是文本中承载信息的重要语言单位,命名实体识别一直是信息抽取和自然语言处理的重要研究领域之一.随着大量应用对文本深层次信息获取需求的增加,仅识别出实体的名称已经不足以满足需求,越来越多的研究工作开始关注命名实体的属性,如人物的籍贯、出生日期、党派;手机的内存容量、屏幕尺寸、摄像头像素等.命名实体的属性具有重要应用价值,在互联网搜索领域,利用已获取的实体属性能够识别诸如“iPhone6的屏幕尺寸”、“李娜退役时间”、“福克斯耗油”这类查询的意图,从而给出精确结果[1];在问答领域,实体属性作为普通知识的一种特例,预先获取这类知识能够提高通用问答系统的效果[2];在电商领域,商品的属性信息是倾向性分析、商品自动文摘[3]、推荐系统等许多应用的重要数据来源.如何获取命名实体的属性及其取值是一项具有重要意义却充满挑战的工作,在本文中我们重点关注命名实体属性值的抽取问题.
命名实体的属性值抽取是指自动识别给定命名实体在其所具有属性上的取值[4].由于属性值的类型和构成形式较为复杂,现有研究工作为了降低抽取复杂度多在限定条件下展开,例如面向电商[5]、医疗[6]等特定领域,人物[7]等特定实体类型,数量型[4,8]、实体型[9]等特定取值类型进行属性值的抽取.这些方法的实验性能达到了较高水平,但是扩展性具有较大的局限.本文的研究目标是开放式属性值抽取,即从开放领域的互联网非结构化文本中识别给定命名实体的属性值,为构建实体-属性知识库提供基础数据.
从非结构化文本中抽取属性值通常使用有监督的机器学习方法,利用最大熵(maximumentropymodel,MaxEnt)、条件随机场(conditionalrandomfield,CRF)、支持向量机(supportvectormachine,SVM)等判别式模型进行识别.相对于隐马尔可夫(hiddenMarkovmodel,HMM)等产生式的模型而言,判别式模型能够灵活地结合各种特征.但是为了可求解,这些模型仅能够使用局部特征.局部特征能够利用的信息有限,例如,对于某个实体的同一属性而言,在单个语句中不可能出现2个不同的取值,这一特点使用局部特征无法很好地进行表示.本文提出了结合全局特征的感知机学习算法,该算法能够在模型训练和预测过程中灵活地使用各种全局信息.
此外,命名实体的属性值抽取还与处理的具体语言相关,目前的研究工作主要集中在国外,通常面向英语语言,针对中文的属性值抽取工作比较欠缺.中、英文之间的差异导致许多英文上行之有效的方法不适用于中文,有必要针对中文研究属性值的抽取方法.本文的主要贡献如下:
1) 首次将全局特征引入到属性值抽取问题中,该类特征能够捕获属性值边界分布、属性值与属性名依赖关系等全局信息.与仅使用局部特征的基线系统相比,F值显著提升.
2) 提出结合全局特征的感知机学习算法,使得模型在加入全局特征的同时仍然可以使用维特比算法有效求解,降低了模型的计算成本,提高了实用性.
3) 提出一种通用的中文属性值抽取方法,该方法不限定领域,具有较好的泛化能力.
1相关工作
现有的属性值抽取方法大致可分为无监督、有监督和弱监督3类.
基于词汇-句法模式的属性值抽取方法是无监督方法的典型代表.其中“attributeofentityisvalue”模式(如“populationofChinais1.37billion”)是目前使用最广泛的抽取模式[10-12].此外还有一些面向特定领域的抽取模式,例如针对查询日志的“Whyisentity attribute”模式[13]、针对微博的“myattributeis”模式[14]等.Davidov等人[8]提出了抽取数量型属性值的“实体+系动词+量词+属性名”模式(如“KobeBryantis1.98mtall”),对于无法直接匹配到的属性值,通过相似实体的取值分布进行近似估计.目前主流的属性值抽取模式主要面向英文,在中文上无法使用.为了克服精确匹配导致的数据稀疏问题,基于模式的方法往往借助搜索引擎从大规模互联网数据中获取结果,搜索引擎对于查询次数的限制成为制约其实际应用的瓶颈.
从非结构化文本中抽取属性值的另一类方法是基于监督学习模型.Ye等人[7]首先从《知网》提取属性的触发词,然后利用触发词对语句进行分类,最后针对每个属性分别训练SVM模型,从而识别出包含属性值的语句并进行抽取.Huang等人[6]首先使用SVM将描述属性的语句和普通语句区分开,然后利用CRF从描述属性的语句中识别属性值.Putthividhya等人[9]对比分析了HMM,MaxEnt,CRF,SVM在属性值抽取上的效果.实验结果表明,除HMM的效果较差外,其余模型在使用相同特征时无明显优劣.Li等人[3]提出了skip-treeCRF模型,对连词2端属性的关系和句法树结构进行建模,在产品评论类数据中取得了较好的效果.
监督学习方法在实际应用中的局限是需要人工标注大量数据.为了降低标注数据的成本,一些研究工作提出了弱监督的属性值抽取方法.Wu等人[15]借助Wikipedia自动构建训练数据.该方法以信息框中的属性作为种子,利用启发式方法在正文中自动标注对应的语句,从而训练CRF模型识别属性值.Probst等人[5]将属性值抽取建模成词的分类问题,并提出co-EM的方法提高分类效果.该方法首先利用启发式方法和词的互信息从二元语法(bigram)中抽取形如“属性值+属性名”的文本片段,然后结合预定义的属性值词典对无标注数据进行匹配,从而获得标注数据.
此外,还有一些属性值抽取方法借助网页中的半结构化信息(如列表、表格、字体等)抽取命名实体的属性值[16-18].网页的半结构化信息具有很大的灵活性和语义不确定性,这将影响所抽取属性值的质量,该类方法处理的数据类型有限,不适用于非结构化文本.
2结合全局特征的属性值抽取方法
2.1问题定义
本文解决的问题是,给定一篇命名实体相关的描述文本,从中识别出感兴趣的该实体属性的取值,形式化描述如下:
已知命名实体集合E={e1,e2,…,en}和待抽取的属性集合A={a1,a2,…,am}.对于任意一篇描述ei的文本Ti={ei∈Ti∧obj(ei,Ti)=true}(obj(ei,Ti)表示ei是否为Ti描述的主要实体),我们的目标是识别出Ti中ei的所有属性值V={vj|vj=value(ei,aj)∧aj∈A}(value(ei,aj)表示实体ei在属性aj上的取值).
Ti中除ei以外的实体不予考虑,因为一篇描述性文本在提及多个命名实体时总会有一个更侧重.ei以外实体的属性可以在它们对应的描述文本中获取.命名实体的描述性文本较易获得,例如在线百科*中文在线百科有维基百科(http://www.wikipedia.org)、百度百科(http://baike.baidu.com)、互动百科(http://www.baike.com)等.、某些介绍性网站等.
2.2加入全局特征后的模型求解
我们将属性值抽取问题转化成序列标注问题,对每个待抽取的属性分别训练模型.目前主流的序列标注模型(如CRF)应用于属性值抽取时效果并不理想,其主要原因是:为使模型易求解,仅使用了局部特征.我们引入属性值的全局特征用于捕获局部特征以外的重要信息.关于局部特征和全局特征的含义及其在属性值抽取问题上的具体内容将在2.3节进行详细阐述.加入全局特征后的模型难以求解,通常的解决方法是n-best重排序.该方法仍然使用局部特征训练模型,但预测阶段分为2步:1)保留前n个较优的候选结果;2)利用全局特征对候选结果重新排序,选择重排后最优的候选作为最终结果.重排序的过程往往是无监督的,全局特征相关参数的确定需要人工干预.本文基于平均感知机模型,提出了结合全局特征的模型学习算法,将全局特征和局部特征的求解同时完成.
2.2.1平均感知机
平均感知机是由Collins[19]提出的可用于序列标注的判别式模型.序列标注的目标是输入一个语句x=[w1,w2,…,wm]∈X,输出其相应的标注结果y=[t1,t2,…,tm]∈Y,其中wi为x的第i个词,ti为词wi对应的标注.具体而言,对于一个待标注语句x,寻找一个满足下式的标注结果z:
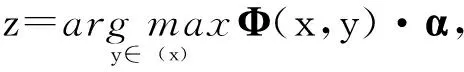
(1)
其中,Φ是特征映射函数,它将(x,y)映射成特征向量Φ(x,y)=(φ1(x,y),φ2(x,y),…,φd(x,y))∈d,α∈d是特征向量对应的权重向量,“·”是向量内积.权重向量α是需要被学习的模型参数.
Collins提出一种在线方式学习模型的参数,具体过程为
令D={(x(1),y(1)),(x(2),y(2)),…,(x(n),y(n))}为训练语句集合,初始化α全为0.遍历D,对于每个训练语句x(i),使用模型当前的参数求出最优的标注结果z.如果z与正确答案y(i)不同,则按照下面的方法更新参数:

(2)
上述过程迭代T轮后,对所有参数取平均值:
(3)
该模型学习方法已被证明是收敛的[19].平均感知机的一个关键问题是如何求解式(1).在实际应用中限定Φ(x,y)为局部特征,因此可以使用动态规划的方法进行求解,例如维特比算法、A*算法等.但是,当Φ(x,y)中包含全局特征时,这些算法不再适用,求解代价变得非常高,尤其对于词语数量较多的长句,求解过程甚至无法忍受.为了降低加入全局特征后模型的求解复杂度,提高方法的实用性,我们对平均感知机进行了改进.
2.2.2结合全局特征的感知机
假设Φ(x,y)包含全部的特征,其中局部特征记为ΦL(x,y),全局特征记为ΦG(x,y),它们的向量形式分别为
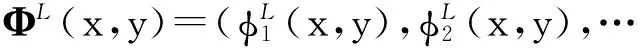
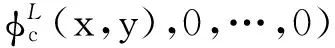

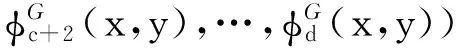
Φ(x,y)=ΦL(x,y)+ΦG(x,y)=
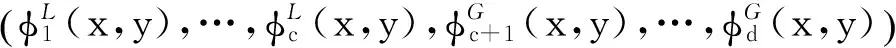
参数向量α=αL+αG也可以表示成相同的向量形式.显然,遍历所有可能的结果求解式(1)是不可行的.CRF在训练时所有可能的候选结果都需要计算,而平均感知机一次只考虑一个样本,每个样本只计算最优的一个候选结果,这一特性使全局特征求解变得可行.
通过实验分析我们发现,对于属性值抽取而言,模型的整体最优解在局部特征上也不会很差.换言之,对局部特征求解出的结果排序,排在前面的候选结果往往包含整体最优解.如果只对排在前面的这部分候选结果应用全部特征(局部特征和全局特征),则能够有效缩小搜索空间.因此,我们首先放宽求解目标,求出在局部特征上较优的前k个候选结果:
(4)
该步骤使用维特比算法可快速实现.
然后,我们在这k个候选结果中选择一个在全部特征上最优的结果作为式(1)的最终输出:
(5)
该步骤只需在k种可能的结果中搜寻.
最后,利用式(5)求解的结果按照式(2)对局部特征参数αL和全局特征参数αG同时进行更新.我们的方法与传统n-best重排序方法的不同在于,式(5)的结果是全部特征上的最优解,且全局特征的权重由训练得出,无需人工干预.算法1是模型求解的详细过程.
算法1. 融合全局特征的感知机学习算法.
输入:训练语料D={(x(1),y(1)),(x(2),y(2)),…,(x(n),y(n))}、迭代轮数T;
输出:模型参数α=(α1,α2,…,αd).
① 初始化α←0;
②fort←1toTdo
③fori←1tondo
④ 对于语句x(i),根据ΦL(x(i),y)·αL求出前k个候选标注结果{yk}(见式(4));
⑤ 遍历{yk},根据Φ(x(i),y)·α求出最优结果z(见式(5));
⑥ifz≠y(i)then
⑦ 更新局部特征参数αL=αL+
ΦL(x(i),y(i))-ΦL(x(i),z);
⑧ 更新全局特征参数αG=αG+
ΦG(x(i),y(i))-ΦG(x(i),z);
⑨endif
⑩endfor



2.3属性值抽取的特征
我们定义了2类用于属性值抽取的特征.
2.3.1局部特征
局部特征是指在一定长度的窗口范围内抽取的特征.在式(1)中,对于任意特征实例φj(x,y)∈Φ(x,y),均是一个将x和y映射到实数的函数φ:X×Y→,为便于计算,φ均被定义成指示函数.以语句“而处理器部分则采用三星电子自制之处理器”为例解释局部特征指示函数的表示方式(记为例句1,下划线部分为属性“处理器”的取值).例句1的一个局部特征实例表示为
该特征函数解释为,如果词wi是“核心”且wi被标注为“I-V”,则该特征的取值为1;否则,该特征的取值为0.
我们分别从词、词性和依存关系3个方面定义属性值抽取的局部特征(窗口长度为3),如表1所示:
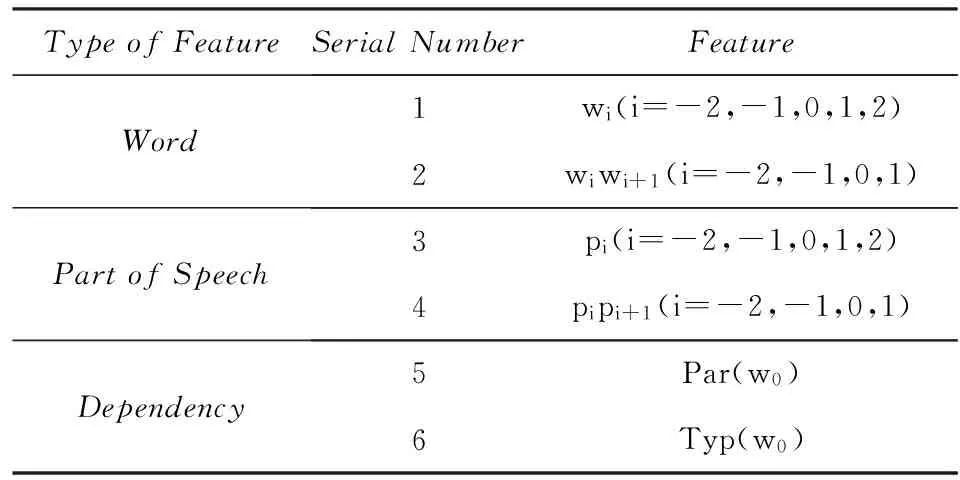
Table 1 Local Features for Attribute-Value Extraction
其中,角标i=0表示当前词,i=-2表示当前词左边第2个词,i=2表示当前词右边第2个词.特征1,3分别为词、词性的一元语法(unigram);特征2,4分别为词、词性的二元语法(bigram);特征5表示当前词在依存关系上的父节点;特征6表示当前词与其父节点的依存关系类型.
2.3.2全局特征
全局特征泛指超出窗口范围抽取的特征.通过大量的实验分析,我们发现识别错误的属性值主要有2个特点:1)属性值在句中的位置正确但边界错误;2)属性值与属性名的距离较远,它们之间的关系没有被捕获.这些现象对于任何仅使用局部特征的模型来说都无法很好地建模.为此,我们定义了表2中的全局特征,为保证特征表示的一致性,这些特征均为指示函数.
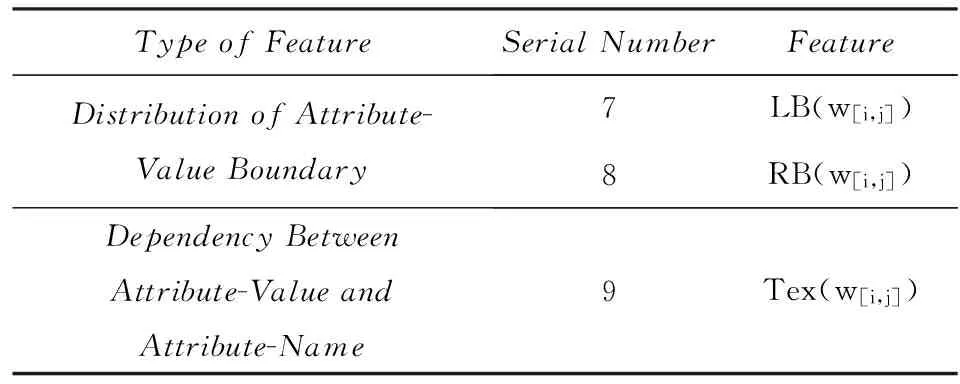
Table 2 Global Features for Attribute-Value Extraction
属性值边界分布:该类特征用于捕获属性值左边界(LB)和右边界(RB)的分布情况,以上述例句1为例,属性“处理器”的取值的左边界特征表示为
该特征函数解释为:如果短语w[i,j]被标注为属性值(w[i,j]的左边界在wi-1和wi之间),且左边界左侧第1个词为“之”,则该特征的取值为1.同理,RB(w[i,j])取右边界右侧第1个词.
属性值-属性名依赖关系:该类特征用于发现属性值与属性名之间存在的依赖关系,该特征的一个实例如下所示:
解释为:如果短语w[i,j]被标注为属性值,且该短语与属性名ak之间通过文本“:”相连,则特征取值为1.为克服数据稀疏问题,我们对连接文本Tex(·)进一步泛化,去掉停用词、数词、虚词等对属性值抽取意义不大的词,并且忽略词的顺序.
3实验与分析
3.1实验设置
我们使用中文维基百科的正文内容进行实验.选择该数据源的原因是维基百科的正文是实体描述性文本,并且开放易获取,便于其他研究者重现本实验.此外,不同来源的互联网数据差异主要体现在网页结构的不同,对于描述性文本而言,语言表达习惯基本相同,数据的来源并不会产生太大影响.
给定一个命名实体类别,首先根据百科页面的类别标签筛选出该类别所包含的实体描述页面;然后过滤掉信息框、表格等结构化内容,仅提取正文内容作为实验的目标数据集.中文分词、词性标注和依存分析使用开源的中文语言技术平台[20].对于每篇文本,以页面标题所对应的实体作为主要实体,人工标注每个待抽取属性的属性值.
为了分析本文方法的领域鲁棒性,在不同实体类别上分别进行实验,包括“手机”(mobilephone)、“全国重点大学”(Chinesekeyuniversity)、“中国篮球运动员”(Chinesebasketballplayer)和“中国科学院院士”(academicianofCAS).这些类别涉及人物、产品和机构3个常见领域,不同领域的实体差异较大,能够反映方法的泛化能力.其中“中国篮球运动员”和“中国科学院院士”是人物领域的2个子类,便于进一步考察方法对相近实体的属性值抽取效果.每个实体类别随机选择5个属性进行实验.表3给出了实体类别及待抽取属性的详细描述.
为了验证本文提出的结合全局特征的感知机(G-Per)的可竞争性,我们将G-Per方法与以下基线方法进行对比.
1)CRF.CRF是当前主流的序列标注模型,由于其难以加入全局特征,所以仅使用表1中的局部特征.
2)A-Per.A-Per是由Collins提出的平均感知机模型,与CRF存在同样的限制,仅能够使用表1中的局部特征.
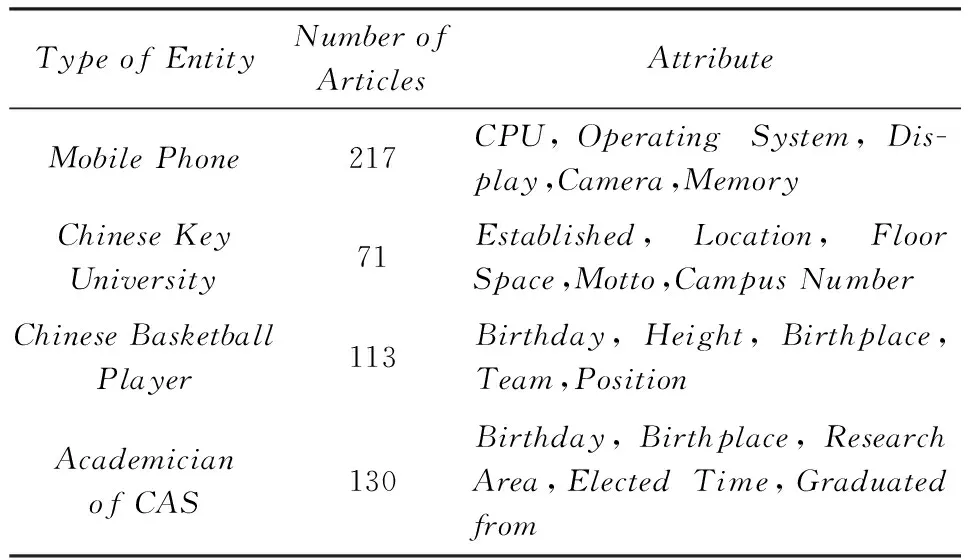
Table 3 Type of Entity and Attribute
本文提出的G-Per方法在使用表1的局部特征基础上增加表2中的非局部特征.由于G-Per在仅使用局部特征时退化为平均感知机,因此没有单独对G-Per使用表1的特征进行实验.每个类别下文本的60%用于训练、40%用于测试.采用准确率P、召回率R和F值来评价属性值抽取的效果.其中,只有当属性值的位置和边界同时正确,才认为该抽取结果正确.
3.2实验结果

Fig. 1 Average F on five kinds of attributes of different entities.图1 不同类别的命名实体在5个属性上的平均F值
图1给出了本文方法和基线方法在各个实体类别上的平均F值,可以直观地看出,不同领域的命名实体其属性值抽取的难度不同,人物属性相对产品属性和机构属性而言,较易抽取且效果较好.此外,由图1可知CRF和A-Per在使用相同特征时效果不相上下,而G-Per在不同领域的实体上均取得了最好的抽取效果.这说明本文提出的全局特征确实能够发现局部特征无法捕获的有价值信息.
表4~7详细列出了每个属性的抽取结果,其中黑体为每个属性的最优结果.通过对比分析各种属性的抽取结果可以发现,表达方式较固定的属性抽取效果较好,例如“Birthday”,“Height”;表达方式较灵活的属性抽取效果相对较差,例如“OperatingSystem”,“Motto”.本文提出的G-Per方法能够普遍提高属性值抽取的F值,尤其对于表达方式灵活多变的属性提升效果显著,例如“OperatingSystem”提高6%,“Motto”提高5%.这是因为这类属性值在文本中的局部信息并不明显,而G-Per方法能够有效利用窗口外的全局信息,从而弥补了局部特征的不足.
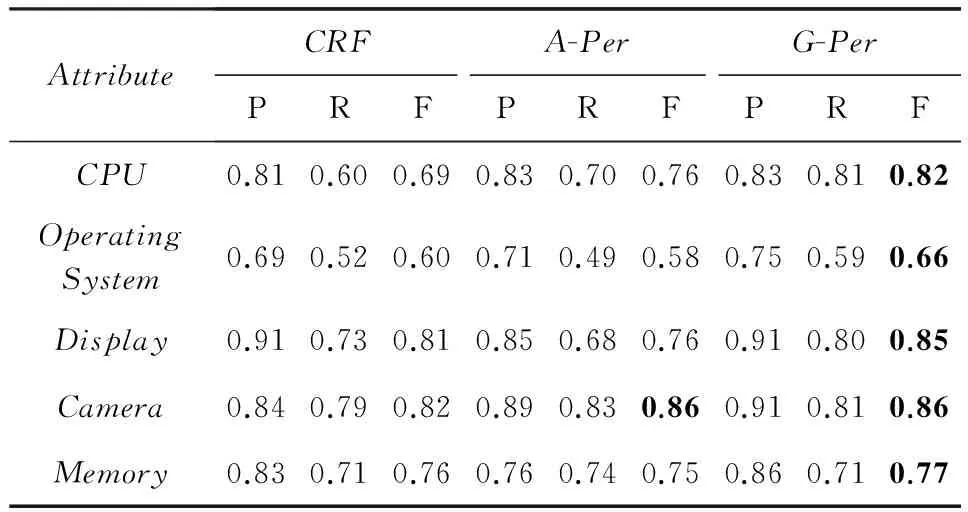
Table 4 Results of Attribute-Value Extraction (Mobile Phone)
Table5ResultsofAttribute-ValueExtraction(ChineseKeyUniversity)
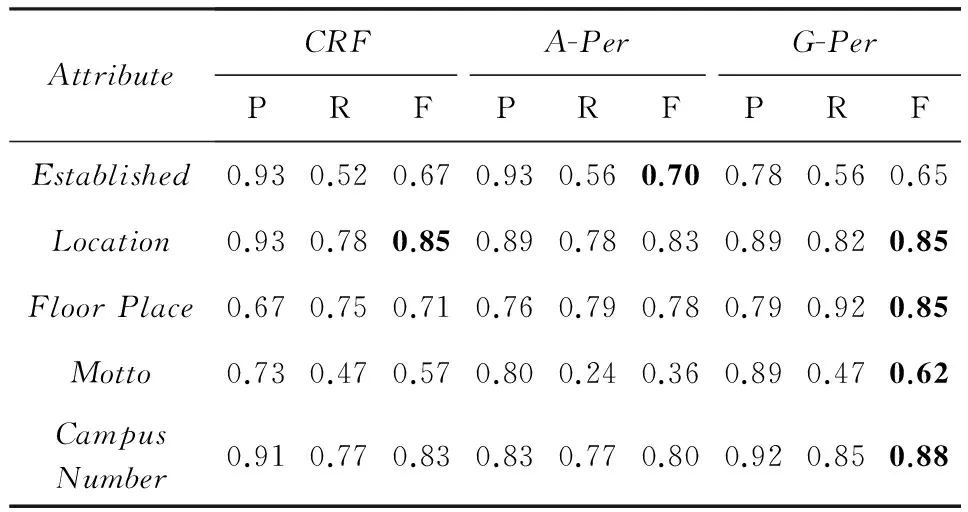
表5 属性值抽取结果(全国重点大学)
Table6ResultsofAttribute-ValueExtraction(Chinese
BasketballPlayer)
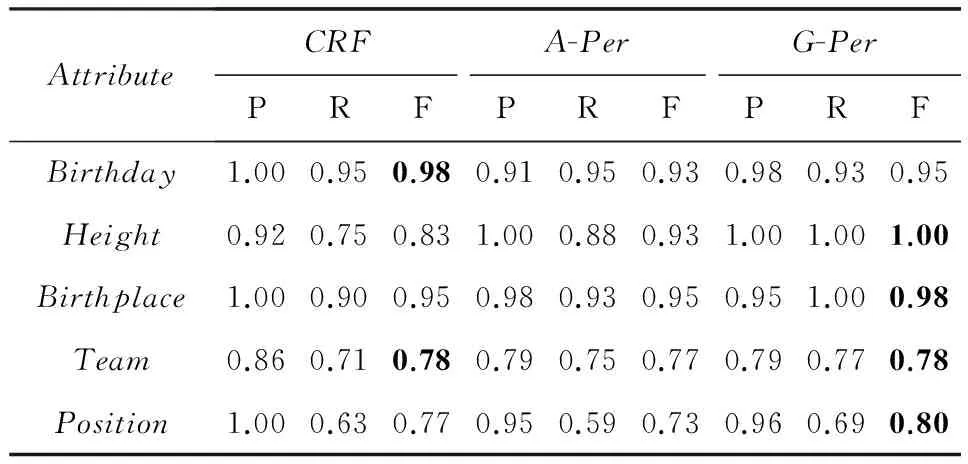
表6 属性值抽取结果(中国篮球运动员)
Table7ResultsofAttribute-ValueExtraction(AcademicianofCAS)
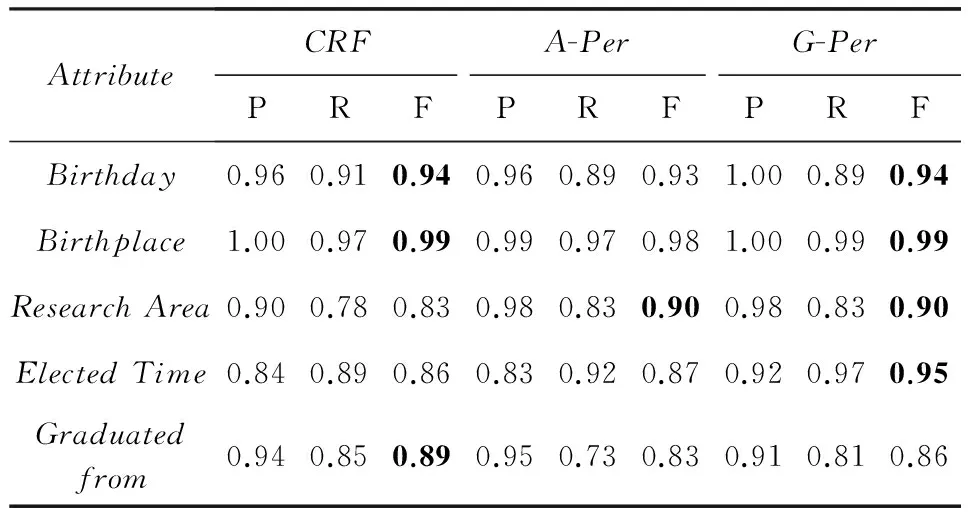
表7 属性值抽取结果(中国科学院院士)
结合全局特征的感知机方法有2个重要的参数:迭代轮数T和式(4)中的k.受篇幅所限,我们随机选择一个实体类别,对T和k分别进行分析.图2是“MobilePhone”的5个属性的学习曲线.由图2可见,结合了全局特征的平均感知机仍然是收敛的.虽然不同属性收敛所需的迭代轮数T不相同,但是从图2中得出大致范围在10~18轮.
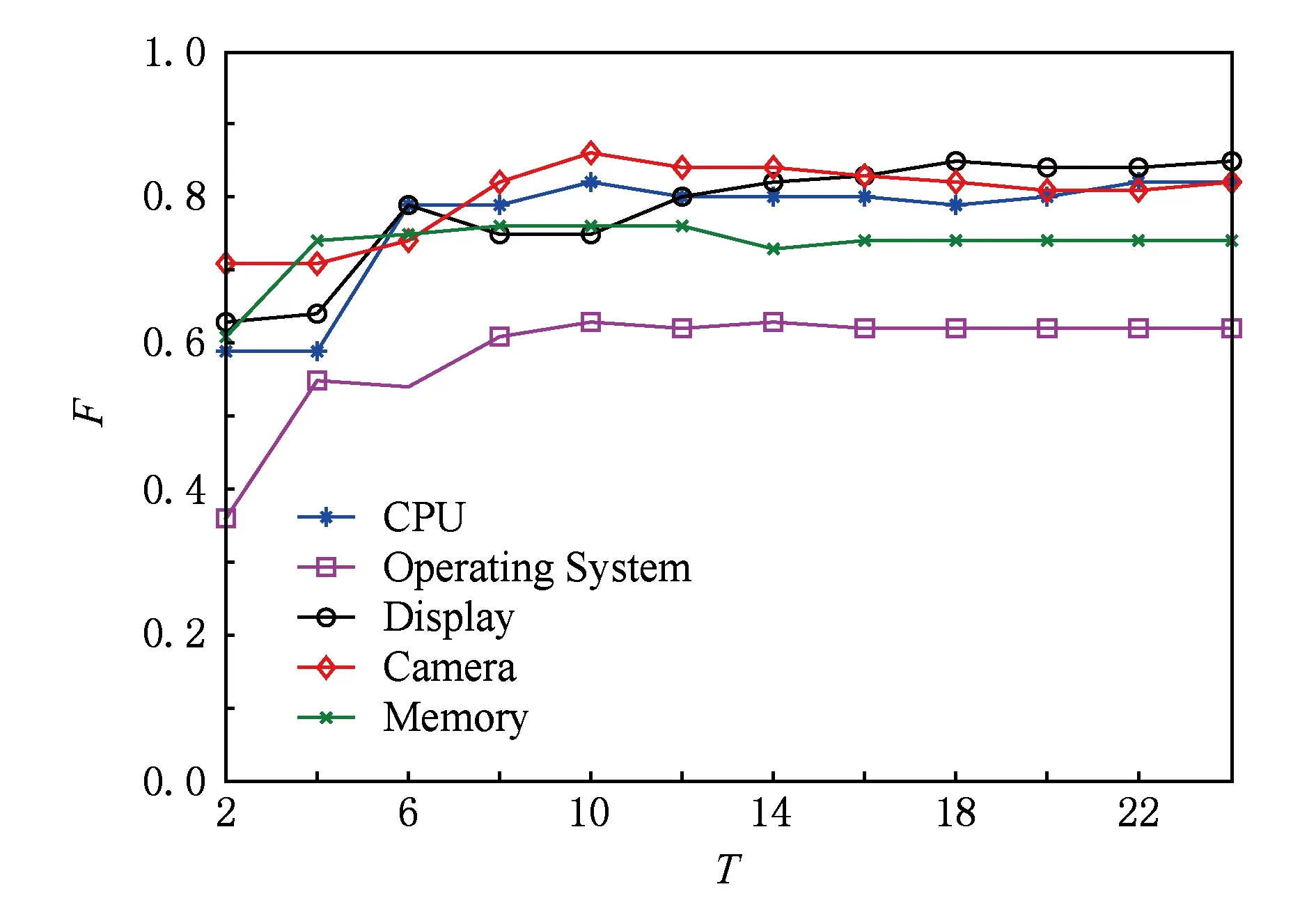
Fig. 2 Training curves of G-Per.图2 G-Per方法的学习曲线
表8对比了不同k值对属性值抽取结果的影响.其中,k=1时相当于仅使用局部特征,效果与平均感知机相同.此外,从表8可以发现k值并不是越大越好,当大于一定值时效果反而下降.这是因为过大的k引入了过多噪音,而且会增加模型训练时间.虽然不同属性的最优k值不尽相同,但由表8可得,k值最大的属性“处理器”也只需要15个候选结果就能够达到最优结果,这样的量级在实际应用中是可以接受的.
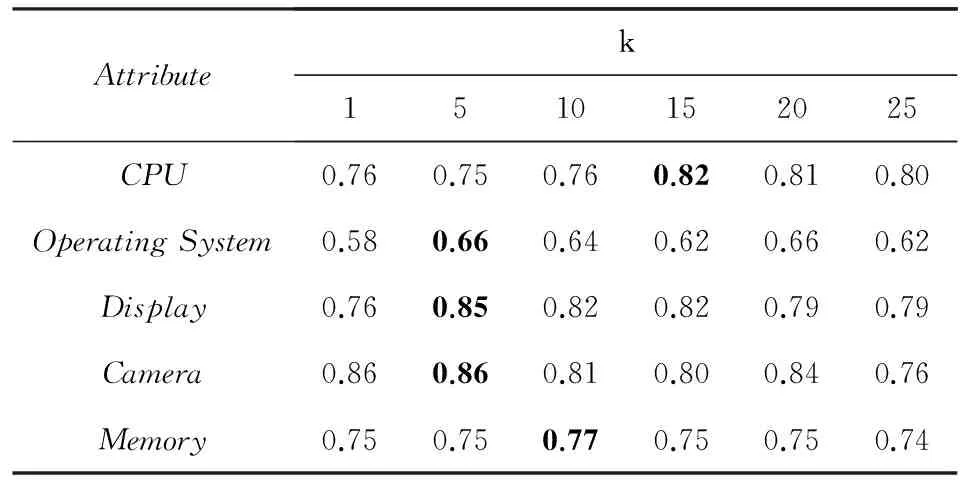
Table 8 Results of Attribute-Value Extraction with Different k
3.3错误分析
在实验中,边界错误是错误结果中占比重较大的一类.我们采用了较严格的判定方式,即属性值的位置和边界需要同时正确.而事实上,有些抽取结果的边界尽管和答案不完全相同,但也具有一定价值,在实际应用中仍然可以被使用,例如在上述例句1中,若处理器的识别结果为“4核心”或者“1.4GHz”也具有实用价值.
此外,本文提出的方法依赖于中文分词、词性标注和依存分析等自然语言处理工具输出的结果,这些预处理过程所产生的误差会直接累积到属性值抽取阶段.
4结束语
本文利用全局特征解决中文属性值抽取问题,并提出结合全局特征的感知机学习算法,降低了全局特征的求解复杂度.在不同领域的实体属性上进行抽取实验,结果表明全局特征能显著提高抽取的效果.由于监督学习方法普遍面临标注成本高的问题,在后续的研究中将考虑弱监督的方法,降低属性值抽取的标注成本,进一步提高方法的实用性.
参考文献
[1]KoplikuA,BoughanemM,Pinel-SauvagnatK.Towardsaframeworkforattributeretrieval[C] //ProcofCIKM2011.NewYork:ACM, 2011: 515-524
[2]TakahashiT.Computationofsemanticequivalenceforquestionanswering[D].Nara,Japan:NaraInstituteofScienceandTechnology, 2005
[3]LiF,HanC,HuangM,etal.Structure-awarereviewminingandsummarization[C] //ProcofColing2010.Stroudsburg,PA:ACL, 2010: 653-661
[4]LuHan,CaoCungen,WangShi.Implementationofameta-propertybasedquantityattribute-valueextractionsystem[J].JournalofComputerResearchandDevelopment, 2010, 47(10): 1741-1748 (inChinese)(卢汉, 曹存根, 王石. 基于元性质的数量型属性值自动提取系统的实现[J]. 计算机研究与发展, 2010, 47(10): 1741-1748)
[5]ProbstK,GhaniR,KremaM,etal.Semi-supervisedlearningofattribute-valuepairsfromproductdescriptions[C] //ProcofIJCAI2007.SanFrancisco,CA:MorganKaufmann, 2007: 2838-2843
[6]HuangR,RiloffE.Classifyingmessageboardpostswithanextractedlexiconofpatientattributes[C] //ProcofEMNLP2013.Stroudsburg,PA:ACL, 2013: 1557-1562
[7]YeZheng,LinHongfei,SuSui,etal.PersonattributeextractingbasedonSVM[J].JournalofComputerResearchandDevelopment, 2007, 44(Suppl): 271-275 (inChinese)(叶正, 林鸿飞, 苏绥, 等. 基于支持向量机的人物属性抽取[J]. 计算机研究与发展, 2007, 44(增刊): 271-275)
[8]DavidovD,RappoportA.ExtractionandapproximationofnumericalattributesfromtheWeb[C] //ProcofACL2010.Stroudsburg,PA:ACL, 2010: 1308-1317
[9]PutthividhyaDP,HuJ.Bootstrappednamedentityrecognitionforproductattributeextraction[C] //ProcofEMNLP2011.Stroudsburg,PA:ACL, 2011: 1557-1567
[10]PascaM,VanDurmeB.Whatyouseekiswhatyouget:Extractionofclassattributesfromquerylogs[C] //ProcofIJCAI2007.SanFrancisco,CA:MorganKaufmann, 2007: 2832-2837
[11]LeeT,WangZ,WangH,etal.Attributeextractionandscoring:Aprobabilisticapproach[C] //ProcofICDE2013.LosAlamitos,CA:IEEEComputerSociety, 2013: 194-205
[12]RajuS,PingaliP,VarmaV.Anunsupervisedapproachtoproductattributeextraction[C] //Procofthe31stEuropeanConfonIRResearchonAdvancesinInformationRetrieval.Berlin:Springer, 2009: 796-800
[13]PascaM.Attributeextractionfromconjecturalqueries[C] //ProcofColing2012.Stroudsburg,PA:ACL, 2012: 2177-2190
[14]BergsmaS,VanDurmeB.Usingconceptualclassattributestocharacterizesocialmediausers[C] //ProcofACL2013.Stroudsburg,PA:ACL, 2013: 710-720
[15]WuF,WeldDS.AutonomouslysemantifyingWikipedia[C] //ProcofCIKM2007.NewYork:ACM, 2007: 41-50
[16]RaviS,PascaM.Usingstructuredtextforlarge-scaleattributeextraction[C] //ProcofCIKM2008.NewYork:ACM, 2008: 1183-1192
[17]WuB,ChengX,WangY,etal.SimultaneousproductattributenameandvalueextractionfromWebpages[C] //Procofthe2009
IEEE/WIC/ACMIntJointConfonWebIntelligenceandIntelligentAgentTechnology.LosAlamitos,CA:IEEEComputerSociety, 2009: 295-298
[18]CrestanE,PantelP.Web-scaleknowledgeextractionfromsemi-structuredtables[C] //ProcofWWW2010.NewYork:ACM, 2010: 1081-1082
[19]CollinsM.DiscriminativetrainingmethodsforhiddenMarkovmodels:Theoryandexperimentswithperceptronalgorithms[C] //ProcofEMNLP2002.Stroudsburg,PA:ACL, 2002: 1-8
[20]CheWanxiang,LiZhenghua,LiuTing.LTP:AChineselanguagetechnologyplatform[C] //ProcofColing2010.Stroudsburg,PA:ACL, 2010: 13-16

LiuQian,bornin1984.PhD.Hermainresearchinterestsincludenaturallanguageprocessing,dataminingandinformationextraction.

WuDayong,bornin1977.PhDandassistantprofessor.Hismainresearchinterestsincludenaturallanguageprocessing,Webminingandinformationretrieval(wudayong@ict.ac.cn).

LiuYue,bornin1971.PhDandassociateprofessor.HermainresearchinterestsincludeinformationretrievalandWebmining(liuyue@ict.ac.cn).

ChengXueqi,bornin1971.PhDandprofessor.MemberofChinaComputerFederation.Hismainresearchinterestsincludenetworkinformationsecurity,large-scaleinformationretrievalandknowledgemining(cxq@ict.ac.cn).

PangLin,bornin1985.PhD.Hermainresearchinterestsincludeinformationretrieval,Webminingandsocialcomputing.
ExtractingAttributeValuesforNamedEntitiesBasedonGlobalFeature
LiuQian1,2,WuDayong1,LiuYue1,ChengXueqi1,andPangLin3
1(Key Laboratory of Network Data Science and Technology, Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190)2(University of Chinese Academy of Sciences, Beijing 100049)3(National Computer Network Emergency Response Technical TeamCoordination Center of China, Beijing 100029)
AbstractAttribute-value extraction is an important and challenging task in information extraction, which aims to automatically discover the values of attributes of named entities. In this paper, we focus on extracting these values from Chinese unstructured text. In order to make models easy to compute, current major methods of attribute-value extraction use only local feature. As a result, it may not make full use of global information related to attribute values. We propose a novel approach based on global feature to enhance the performance of attribute-value extraction. Two types of global feature are defined to capture the extra information beyond local feature, which are boundary distribution feature and value-name dependency feature. To our knowledge, this is the first attempt to acquire attribute values utilizing global feature. Then a new perceptron algorithm is proposed that can use all types of global feature. The proposed algorithm can learn the parameters of local feature and global feature simultaneously. Experiments are carried out on different kinds of attributes of some entity categories. Experimental results show that both precision and recall of our proposed approach are significantly higher than CRF model and averaged perceptron with only local feature. The proposed approach has a good generalization capability on open-domain.
Key wordsentity attribute; attribute-value extraction; named entity; global feature; averaged perceptron
收稿日期:2014-09-03;修回日期:2015-09-06
基金项目:国家“九七三”重点基础研究发展计划基金项目(2012CB316303,2014CB340401);国家自然科学基金重点项目(61232010);国家科技支撑计划基金项目(2012BAH39B02)
通信作者:庞琳(panglin@cert.org.cn)
中图法分类号TP391
ThisworkwassupportedbytheNationalBasicResearchProgramofChina(973Program) (2012CB316303,2014CB340401),theKeyProgramoftheNationalNaturalScienceFoundationofChina(61232010),andtheNationalKeyTechnologyResearchandDevelopmentProgramofChina(2012BAH39B02).
