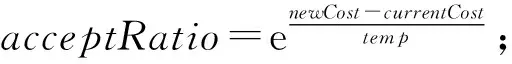基于代价估计的Hive多维索引分割策略选择算法
2016-06-30李锦涛虎嵩林
刘 越 李锦涛 虎嵩林
1(中国科学院计算技术研究所 北京 100190)2(中国科学院大学 北京 100049)3(中国科学院信息工程研究所 北京 100093)(liuyue01@ict.ac.cn)
基于代价估计的Hive多维索引分割策略选择算法
刘越1,2李锦涛1虎嵩林3
1(中国科学院计算技术研究所北京100190)2(中国科学院大学北京100049)3(中国科学院信息工程研究所北京100093)(liuyue01@ict.ac.cn)
摘要在能源互联网、智慧城市等新兴领域,智能终端采集的庞大数据往往需要多维分析,传统企业寻求借助互联网技术(如Hadoop和Hive)应对大数据问题.但是Hive当前的多维索引能力较弱,无法满足传统企业的需求.针对这一问题,提出了一种基于分布式网格文件的多维索引技术——DGFIndex,来提升Hive的多维查询处理能力.但是在创建DGFIndex时,需要用户指定各个索引维度的分割粒度,而分割粒度的大小与查询性能息息相关.在用户对数据与查询特征不熟悉时,很难选择较优的分割策略.为了解决这一问题,通过建立新的MapReduce代价模型,并使用两阶段模拟退火算法为DGFIndex搜索较优的分割策略,从而提升查询性能,减少查询集合的总耗时.实验结果表明:DGFIndex可以提升Hive多维查询性能50%~114%,对于固定的查询集合,与人工选定分割策略比较,基于代价估计的分割策略选择算法可以为DGFIndex快速选定较优的分割策略,并可以使整个查询集合的处理时间比人工方法最多减少30%.
关键词Hive;MapReduce;多维索引;代价模型;模拟退火
随着能源互联网、智慧城市等领域技术的发展,传统企业,如电力、通信、金融、制造等行业,需要处理的数据呈现爆炸式增长,以往依靠传统商业关系型数据库的解决方案遇到了瓶颈,其写入吞吐、横向扩展性与大数据分析能力都无法满足日益增长的数据存储与分析需求.因此,传统企业都在寻找应对大数据挑战的替代方案.而互联网领域已经出现了大量的大数据处理系统,如Hadoop,Spark[1],Storm等,但是由于互联网应用与传统企业应用各具特点,因此在将互联网技术应用于传统企业时会遇到诸多挑战[2-4].例如,传统企业往往需要对庞大的采集类数据进行快速的在线分析与离线批量计算,在这些计算逻辑中包含大量的多维查询[3],但是现有互联网领域的数据处理系统索引能力有限,无法满足需求.
具备灵活可扩展性、高可用性、良好容错性与低成本等优点的Hadoop已成为海量数据存储与分析的首选方案之一.而Hadoop之上的数据仓库工具Hive[5]为用户提供了类SQL查询语言HiveQL,这使传统企业的数据分析人员可以平滑地过渡到基于Hadoop的数据平台上.但是传统企业的数据分析逻辑包含大量的多维查询与统计值分析,而Hive只支持有限的索引技术,如Compact Index等,这些索引数据过滤粒度较大,会造成过多的冗余数据读取,查询性能较低.为此,我们提出了一种基于分布式网格文件的多维索引技术——DGFIndex(distributed grid file index)[3].DGFIndex使用网格文件将数据空间分为很多小单元,通过小单元坐标与对应数据片位置的映射关系达到细粒度索引的目的.
在创建DGFIndex时,用户需要指定每个索引维度的最小值与分割区间,但是在不熟悉数据与查询特征时,选择较优的分割策略比较困难.如果索引维度分区粒度过小,虽然索引可以更精确地定位查询相关数据,即减少冗余数据读取,但是数据读取性能较低;如果索引维度分区粒度过大,虽然数据读取性能较高[6],但是会造成读取过多的冗余数据,并且数据解析与数据过滤的CPU开销也会增大.因此,自动地为DGFIndex选择较优的分割策略对查询性能的提升至关重要,但是不同查询间的最优分割策略会相互影响与制约.在传统企业中,多数数据分析逻辑都以存储过程形式存在,即查询集合在一定时间内是静态的,所以本文要解决的问题是:对于固定的查询集合,如何为DGFIndex选择最优的分割策略,从而使查询集合耗时最短.为了解决该问题,本文首先建立了一种新的MapReduce代价模型来评估不同分割策略对查询开销的影响,然后基于该代价模型提出了一种基于模拟退火的两阶段搜索算法加速分割策略的搜索过程,最终为查询集合选择较优的DGFIndex分割策略,减小查询集合的总耗时.本文的主要贡献将是:
1) 根据采集类数据的特征与查询特点,提出了一种面向Hive的分布式网格文件索引——DGFIndex.该索引可以减少查询冗余数据读取量,提升查询性能.
2) 针对基于索引查询的MapReduce处理过程的特征,提出了一种新的MapReduce代价模型,并基于此提出了一种基于模拟退火的两阶段分割策略搜索算法.
3) 在实验中,本文使用不同的查询集合大小、数据集大小评测分割策略搜索算法的有效性,实验显示该算法可以快速地找到较优的分割策略,从而减少查询集合的总耗时.
1相关工作
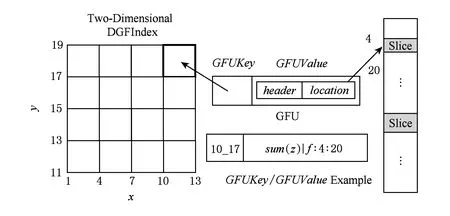
Fig. 1 DGFIndex structure.图1 DGFIndex结构
在Hadoop索引研究领域,现有的研究工作主要分为2类:1)应用于传统数据分析的索引研究,如Jiang等人[7]提出了一种HDFS上的基于排序文件的一维区间索引,该索引为每个固定大小的页建立一个索引项,索引表记录该页的最小值、最大值以及偏移量,而页的大小由用户指定.Dittrich等人[8]提出了Trojan Index和Trojan Join Index,前者为每个数据片保存最小值、最大值和记录数,该数据片的大小由用户指定,后者通过将欲连接的数据集按照连接维度共同分区存储到一起来加速多表连接操作.Eltabakh等人[9]提出了Eagle-eyed elephant系统,该系统提供了多种索引机制来加速数据读取,包括为每个数据片内的数值和日期类型建立区间索引、为字符串类型建立倒排索引等,该数据片的大小为HDFS块大小.Richter等人[10]提出了HAIL,该系统提供了一种静态索引与一种自适应索引,该索引为每个数据块副本建立不同的索引结构,在该研究工作中索引数据片的大小是固定的.2)应用于空间数据处理的索引研究,如Aji等人[11]提出的Hadoop GIS,该系统提出了一种2层的索引结构,全局索引保存维度值与对应数据片的映射关系,在每个节点为每个数据片根据查询类型按需建立局部索引.此外,Eldawy等人提出了Spatial Hadoop[12],该系统也提供了一种2层索引结构,首先使用Grid File,R-Tree或R+-Tree将数据划分为大小相同的块,然后为每个块建立局部索引,全局索引保存在主节点的内存中以加速索引的访问.从上面的描述可以看出现有的Hadoop索引相关的研究工作,索引粒度或者由用户指定或者设定为固定经验值,并没有考虑查询集合的影响.
在Hadoop代价模型领域,Herodotou[13]为Hadoop的MapReduce任务执行流程的各个阶段提出了详细的代价模型,该模型应用于Hadoop最优化参数选择[14].Wang等人[4]提出了一种面向Hive的代价模型,用于多表连接最优顺序选择.Lin等人[15]为MapReduce提出了一种向量形式的代价模型,并基于该代价模型估算任务耗时.Wang等人[16]针对偏斜数据的GroupBy查询和Join查询提出了估价模型.Song等人[17]针对MapReduce中二元连接查询提出了IO代价模型.但是以上工作没有考虑基于索引的情况,即其Map阶段的数据读取直接使用本地顺序读取或网络读取性能指标进行代价估计,但是我们发现数据读取性能不仅与数据片大小有关,还与读取的查询相关数据量有关.此外,每个Mapper读取的数据量不再等于HDFS块大小,而是经过索引定位后的数据量.并且,如果查询处理需要多遍Map阶段时,已有的工作往往使用一遍Map阶段的耗时与遍数的乘积作为估计,但是如果存在索引的话,各个Mapper读取的数据量是不同的,读取数据量少的Mapper可以快速执行完,后面未执行的Mapper可以利用空闲出的资源马上执行.总之,现有MapReduce代价模型无法直接应用于基于索引的MapReduce处理代价估计中.
2DGFIndex
2.1DGFIndex结构
图1展示了一个建立在索引维度x和y上的2维DGFIndex.DGFIndex使用网格文件将数据空间分为很多小单元,这些小单元称为GFU(grid file unit).这样,表中的记录会按照索引维度的值落在对应的GFU中,而所有落在同一个GFU中的记录会被连续地存储在数据文件中,称为数据片.每个GFU在索引表中以KeyValue的形式存储,GFUKey为GFU在数据空间中的左下角坐标,GFUValue由2部分组成:header和location.header为用户定义的预计算用户自定义函数(user-defined function, UDF),例如可以预计算每个GFU中数值列的sum,这样可以极大地加速聚集值查询;location记录该GFU对应数据片所在的文件名、开始偏移量和结束偏移量.例如,图1中GFU对应的GFUKey=10_17,如果在创建索引时预计算维度z的sum,则header为落在该GFU中所有记录的sum(z)值,location为存储所有落在该GFU中记录的数据片的位置信息.在本例中,文件名为f,开始偏移为4,结束偏移为20.数据片的粒度由用户在创建索引时给出的分割策略确定,分割策略包括每个索引维度的最小值和分割区间.如图1,在创建该索引时,指定索引维度x的最小值为1,分割区间大小为3;而索引维度y的最小值为11,分割区间大小为2.此外,为了加快索引表的读取,DGFIndex的索引表以KeyValue的形式保存在HBase中,这样可以以基于键值的方式快速读取索引信息.
DGFIndex可以良好地支持行式存储与列式存储.例如,对于TextFile存储格式,DGFIndex记录每个数据片在文件中的开始偏移量和结束偏移量;对于RCFile存储格式,每个数据片保存为其中的一个行组(row group),DGFIndex只需记录每个Row Group的开始偏移量.可以看出,在DGFIndex中数据片为最小读取单位.
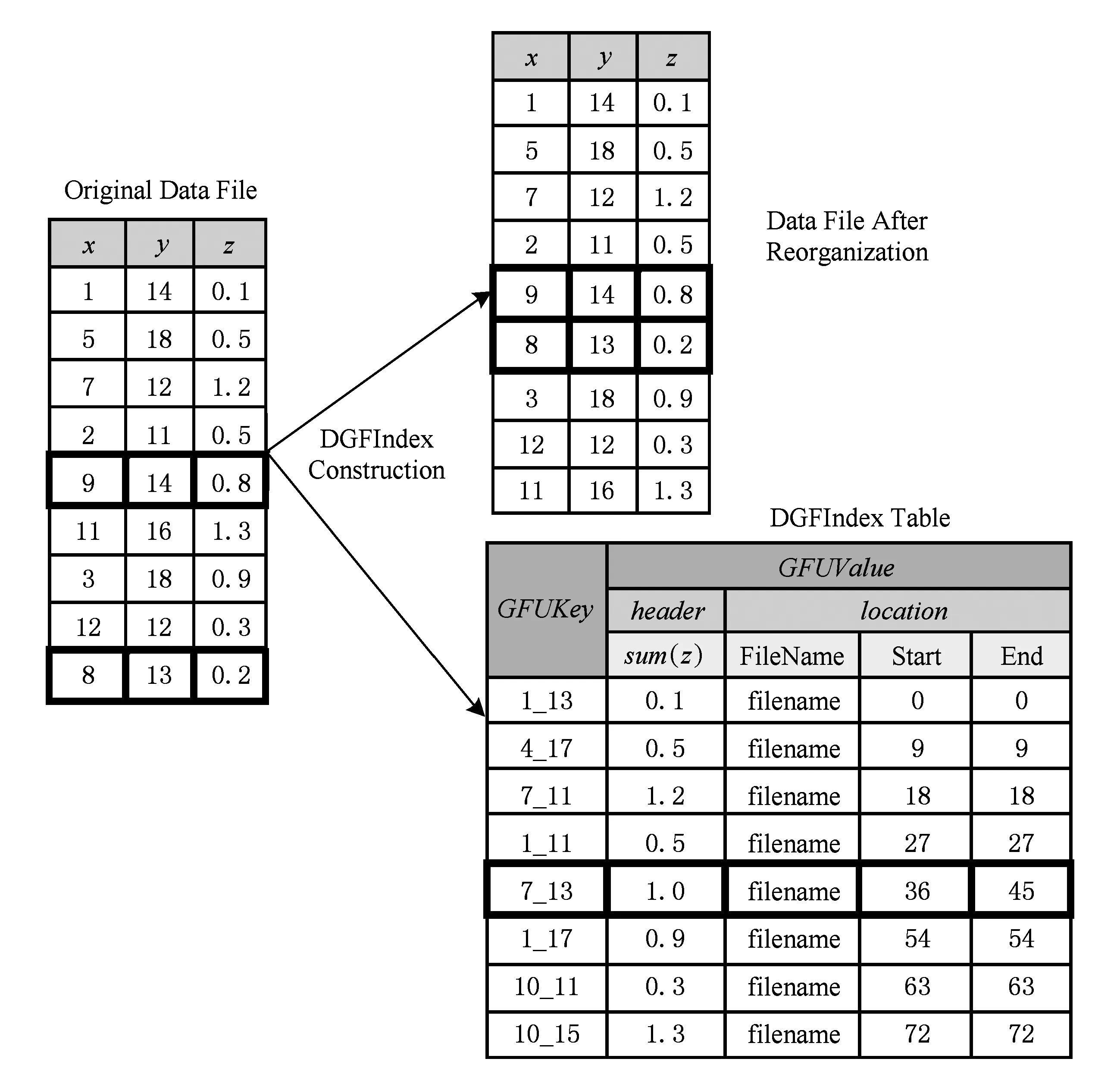
Fig. 2 An example of DGFIndex construction.图2 DGFIndex创建过程例子
2.2DGFIndex创建索引过程
DGFIndex的创建过程为一个MapReduce任务,Map阶段的计算逻辑如算法1所示,Reduce阶段的计算逻辑如算法2所示.
算法1. 创建DGFIndex的Map函数.
输入:键为记录在该数据块中的偏移量,值为记录record;
①idxDValues=getIdxDimValues(record);
②GFUKey=computeGFUKey(idxDValues);
③Emit(GFUKey,record).
在创建索引的Map阶段,对于每条记录,首先读取其索引维度的值(行①);然后根据索引维度的值与分割策略计算其所属的GFU,从而得到该条记录的GFUKey(行②);最后将GFUKey与该记录作为键值对发往Reduce函数(行③).
算法2. 创建DGFIndex的Reduce函数.
输入:键为GFUKey,值为具有相同GFUKey的record列表ListRecordrecordsList;
输出:存储在HBase中的索引表与重组之后的数据文件.
①startOffset=当前输出文件的偏移量;
②endOffset=-1;
③sliceSize=0;
④filename=当前输出文件的名字;
⑤header=null;
⑥ forrecordinrecordsListdo
⑦header=precompute(record,header);
⑧sliceSize+=sizeof(record);
⑨ end for
⑩endOffset=startOffset+sliceSize;


在创建索引的Reduce阶段,Reducer接收到具有相同GFUKey的记录列表,即属于同一个数据片的所有记录,最终目的是将每个数据片按序输出,并记录GFUKey与数据片在文件中位置的对应关系.同时,还需按照用户指定的UDF预计算每个GFU中记录对应的值.具体地,1)初始化数据片开始偏移、结束偏移、数据片大小、输出文件名与保存预计算值的header(行①~⑤);2)对于具有相同GFUKey的每条记录(行⑥),首先预计算其UDF值并累加到header中(行⑦),然后将当前记录的大小累加到sliceSize中(行⑧~⑨),待处理完整个记录列表,计算其结束偏移量(行⑩);3)计算GFUValue,并将GFUKeyGFUValue对写入HBase(行).至此,索引创建结束.
如图2所示,假设现有一个数据文件,使用图1中的分割策略创建DGFIndex,同时预计算sum(z),可以看到,DGFIndex索引创建的过程实际为数据重组织的过程,目的为将位于同一GFU中的记录存储到一起.如9,14,0.8与8,13,0.2位于同一个GFU,经过数据重组织后存储到数据文件的连续位置.同时,创建了包含GFUKey与GFUValue的索引项.
2.3基于DGFIndex的查询处理过程
基于DGFIndex的数据查询过程分为3步:1)索引表读取;2)HDFS数据块过滤;3)数据块内部的数据片过滤.下面分别详细描述各步骤.
算法3. 索引表读取.
输入:SQL查询qi;
输出:查询相关的数据片位置集合SLOCqi;
查询子结果SubRes,如果查询可以使用预计算的UDF时,在这一步可以通过读取索引表得到部分查询结果.
①idxPred=extract(qi);
②isUDFQuery=check(qi);
③ {innerKeySet,boundaryKeySet}=DGFIndex.search(idxPred);
④queryKeySet=boundaryKeySet;
⑤ ifisUDFQuerythen
⑥SubRes=KVStore.getHeader(innerKeySet);
⑦writeToTmpFile(SubRes);
⑧ else
⑨queryKeySet=queryKeySet∪InnerKeySet
⑩ end if


算法4. HDFS数据块过滤.
输入:输入文件列表fileList、保存SLOCqi的临时文件的路径;
输出:经过索引过滤后的查询qi相关的HDFS数据块集合chosenBlocksqi.
①chosenBlocksqi=∅;
②SLOCqi=readFromTmpFile();
③allBlocks=getSplits(fileList);
④ forblockinallBlocksdo
⑤ ifblock∩SLOCqi≠∅ then
⑥chosenBlocksqi=chosenBlocksqi∪block;
⑦ end if
⑧ end for
⑨ forblockinchosenBlocksqido
⑩slicesInBlock=getRelatedSlices
(SLOCqi);



步骤2. HDFS数据块过滤的步骤如算法4所示,算法4发生在InputFormat.getSplits函数中.首先初始化过滤后选定的数据块集合chosenBlocksqi为空(行①),并读取算法1输出的临时文件,得到查询相关数据片的位置信息(行②).然后根据输入文件列表得到所有需要处理的数据块(行③),对于每个数据块,判断其是否包含查询相关的数据片,如果包含则放入chosenBlocksqi,否则抛弃(行④~⑧).随后,为chosenBlocksqi中每个选中的数据块建立一个KeyValue对,Key为该数据块的ID,Value为该数据块内所有需要读取的数据片的偏移量,所有的KeyValue对保存在HBase一张临时表中(行⑨).最后,返回查询相关的数据块
步骤3. 数据块内部的数据片过滤发生在RecordReader.next函数中,该函数读取步骤2中HBase中的临时表,得到在该块中所有需要读取的数据片的偏移量,然后在读取数据时跳过不需要读取的数据片.如果某个数据片跨块存储,此时,假设其大部分存储在块A中,则让处理块A的Mapper处理该数据片,以最小化远程数据读取.当查询为聚集值查询,则待Hive得到边界GFU结果后,需要与算法3中内部GFU的子结果合并得到最终结果.
如图3所示,假设有一个SQL查询,形式如图3所示.1)先根据查询谓词,定位DGFIndex中的边界GFU与内部GFU,因为该查询为聚集值查询,对于内部区域直接查询HBase中header得到子结果,保存于临时文件中.对于边界区域,得到相关数据片在文件中的位置信息.2)根据数据片在文件中的位置信息过滤与查询无关的数据块,然后为每个候选数据块保存需要读取的数据片的偏移.3)在Mapper处理每个数据块时,跳过查询无关的数据片.最终得到的子结果与第1步中的子结果合并,得到最终结果.
SELECTsum(z)
FROMtable
WHEREx>5 ANDx<12 ANDy≥12 ANDy<16
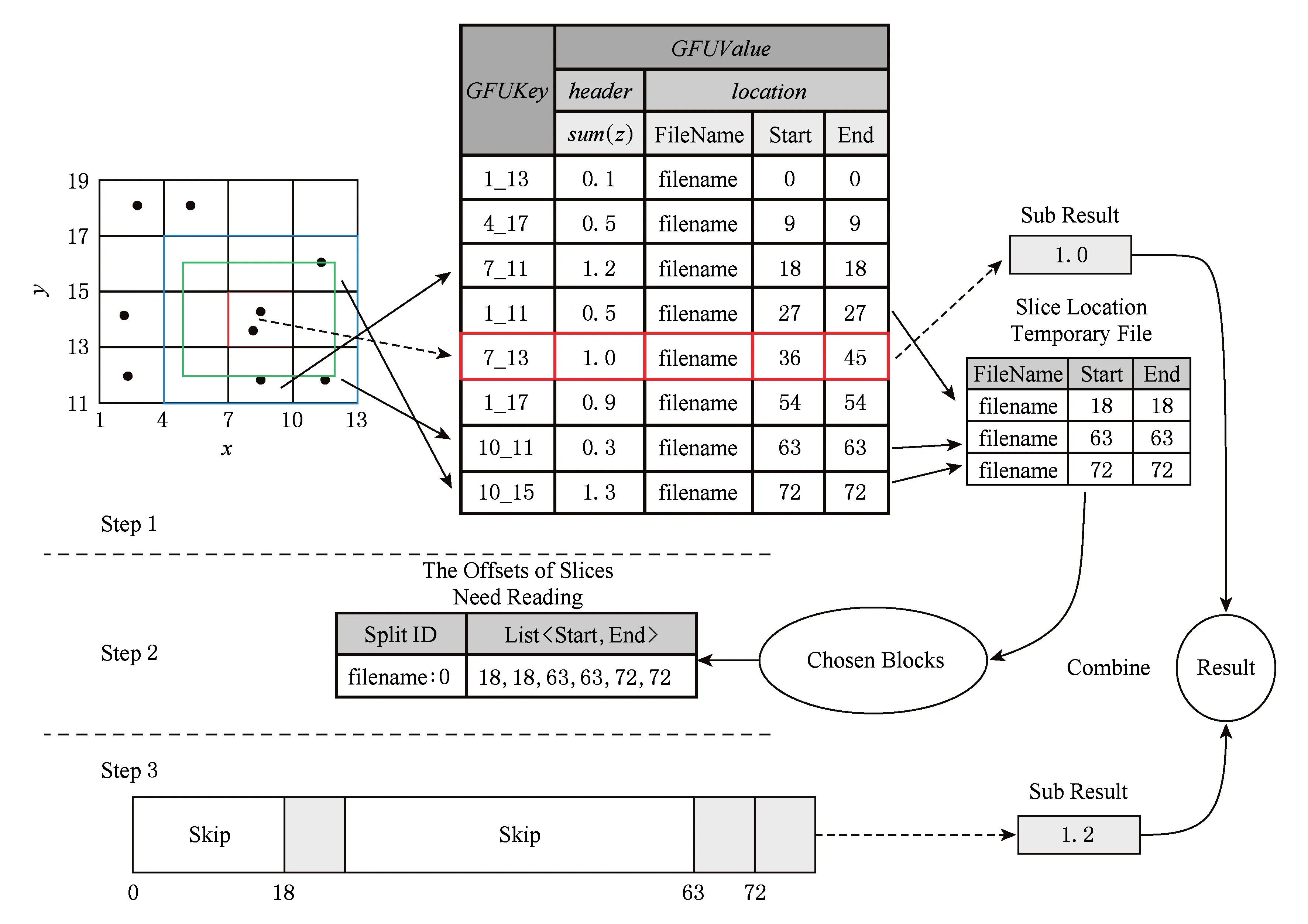
Fig. 3 An example of DGFIndex-based query.图3 DGFIndex索引查询例子
2.4DGFIndex分割策略选择问题
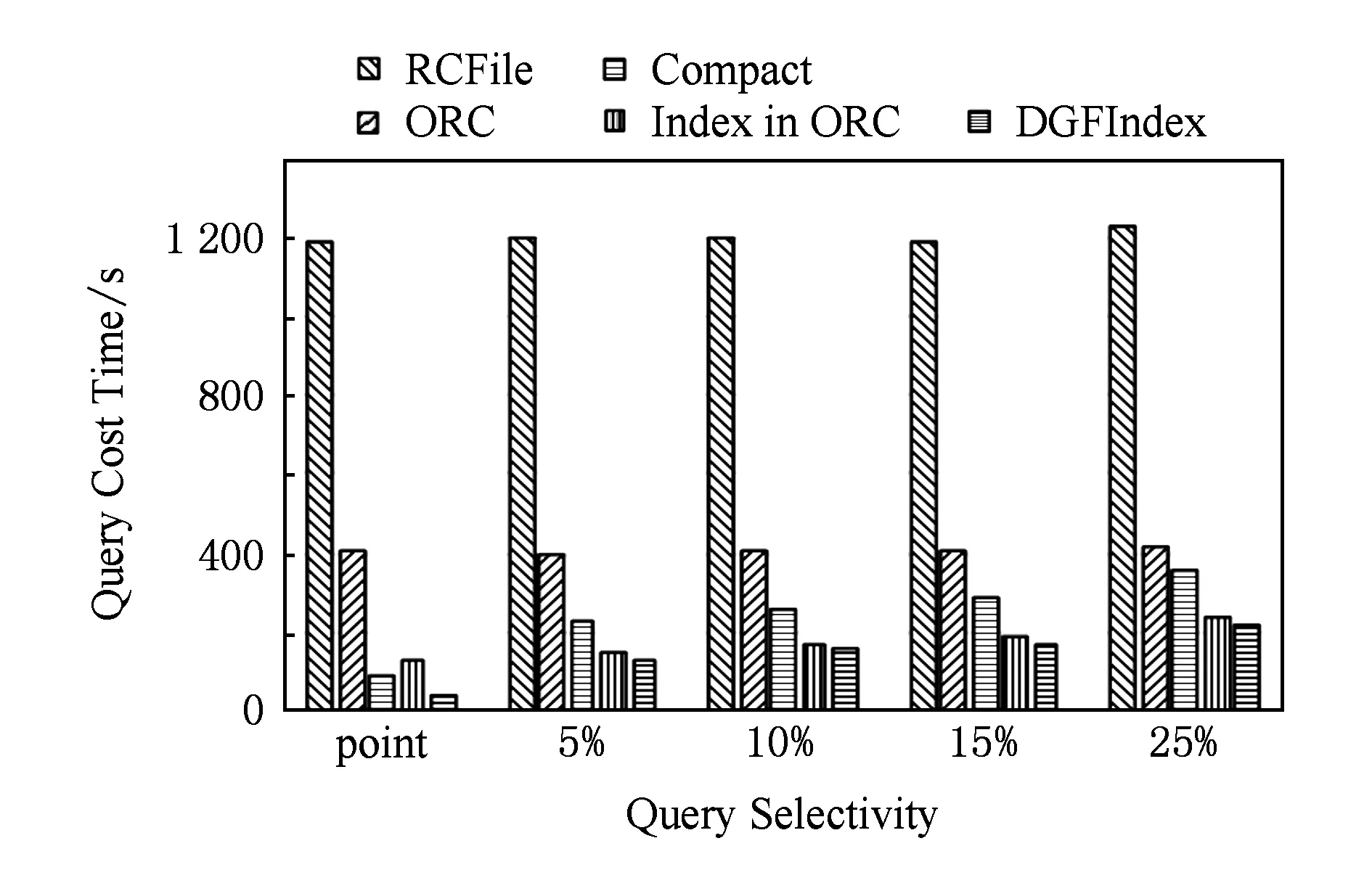
由2.2~2.3节可以看出,分割策略的选择与查询性能息息相关:如果选择细粒度的分割策略,查询边界区域会较小,即读取的冗余数据量较小,而且解析数据、过滤数据的CPU开销也较小.但是文献[6]指出,数据读取性能与数据片的大小成正比,即此情况下数据读取性能较低;相反,如果选择粗粒度的分割策略,虽然此时的数据读取性能较高, 但是由于查询边界区域会较大,造成读取过多冗余数据,而且,这也会造成解析数据、过滤数据的CPU开销较大.图4展示了不同数据片大小对查询性能的影响(该实验的数据集使用存储格式为RCFile的TPC-H lineitem表,大小为187 GB;查询使用TPC-H中的Q6,实验环境与第4节中的描述一致,HDFS数据块大小设置为256 MB).可以看出,对该查询而言,32 MB为较优的数据片大小,过小或过大的数据片都无法得到最优的查询性能.但是,由于不同的查询具有不同的查询谓词,即不同查询的最优数据片大小可能不同,这就造成查询间最优分割策略相互影响与制约.因此,如何为DGFIndex选择最优的索引分割策略以最大化地提升查询集合性能成为一项重要且具有挑战性的任务.

Fig. 4 Influence of different slice size on query performance.图4 不同数据片大小对查询性能造成的影响
3基于代价估计的分割策略选择算法
3.1问题描述
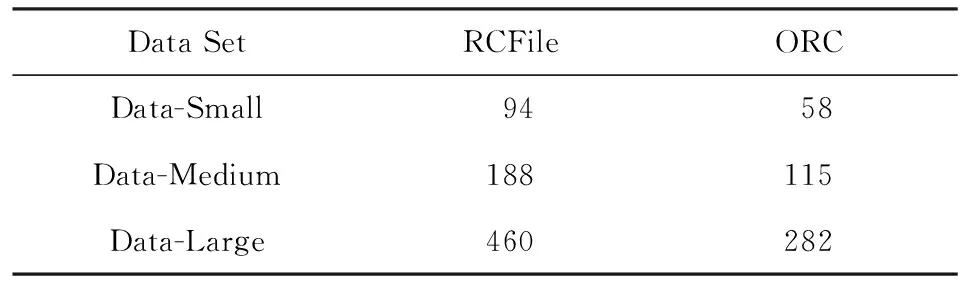
为了方便描述问题定义与代价模型,首先预定义一些形式化符号,如表1所示.avgFieldSizek和avgRecordSize的值可以通过运行涉及某个列的查询,然后根据MapReduce Counter的值得到.
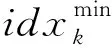
(1)
q∈Q:{q1,q2,…,qn},
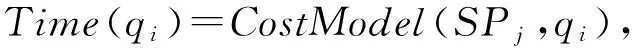
(2)
(3)
(4)

(5)
3.2代价模型
由问题描述可知,解决DGFIndex分割策略选择问题的关键为建立合理的代价模型以反映不同分割策略对查询的影响.MapReduce代价模型已经被众多学者广泛研究[4,13-17],但是现有工作中的代价模型无法直接应用于本工作,原因如下:
1) 以往的代价模型在建模Map阶段数据读取代价时,直接使用HDFS块大小与固定数据读取吞吐的商,没有考虑不同数据片大小对读取性能的影响与索引对数据的过滤作用.
2) 当查询使用的Mapper数大于集群容量时,以往的代价模型直接使用Map阶段运行的遍数与单遍代价的乘积作为Map阶段的代价估计.而在基于索引的查询处理时,由于每个Mapper读取数据量各不相同,数据量较小的Mapper可以快速执行完,第2遍的Mapper可以马上使用空闲的Mapper资源进行执行,以往的代价模型无法准确描述该特性.
因此需要建立新的基于索引进行数据处理的MapReduce代价模型.图5展示了Hive中操作符在Map阶段的数据处理流程及各操作符的作用.不同分割策略只会影响RecordReader与FilterOperator的性能:对于RecordReader,分割粒度越大其读取的数据量越大;对于FilterOperator,分割粒度越大其数据解析与数据过滤的CPU开销越大.而FilterOperator后输出的为符合查询谓词条件的记录,不同的分割策略并不会影响该值.所以,只需要构建Map阶段数据读取与数据处理的代价模型,即可反映不同分割策略对查询集合性能的影响.
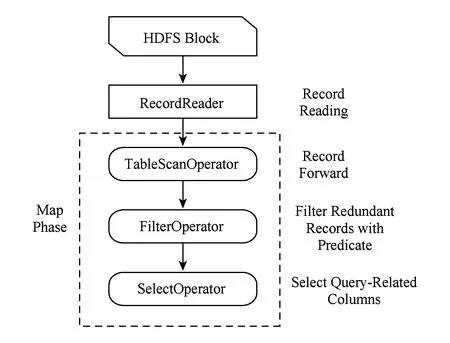
Fig. 5 Data process in Map phase.图5 Map阶段数据处理流程
查询qi在分割策略SPj下,使用DGFIndex处理的代价估计建模为式(7),MapRead(SPj,qi)表示Map阶段数据读取的代价,MapCPU(SPj,qi)表示Map阶段数据解析与数据过滤的CPU代价.
CostModel(SPj,qi)=

(7)
Map阶段数据读取的代价估计如式(8)所示,为查询相关的数据总量与数据读取吞吐的商,查询相关数据总量定义为式(9),数据片大小定义为式(10).对每个查询而言,不同的分割策略SPj导致了不同的查询相关的GFUKey集合与不同的数据片大小,从而导致不同的查询相关数据量.由于基于索引进行查询处理时,每个Mapper处理的数据量不同,因此处理数据量少的Mapper可以快速完成,这样未启动的Mapper可以继续使用空闲出来的资源进行处理.并且,由于每次Mapper处理的次序与调度算法和集群中各节点的负载相关,因此很难事先得到Mapper处理的次序.所以,这里使用读取查询相关全部数据的总耗时进行估计,这一点与以往的MapReduce代价模型不同.对于列式存储,如RCFile,只需要读取查询相关的列,所以读取的数据总量与查询相关列的总大小成正比.
MapRead(SPj,qi)=
(8)
(9)
(10)
式(8)中数据读取吞吐的建模过程如下:由图6,7可以看出(该实验使用与图4中实验相同的数据集、集群环境与参数设置),数据读取吞吐与数据片大小成正比,与查询相关数据量成反比.原因为当数据片增大时,随机读操作减少,数据的顺序读取性能提升;当查询相关数据量增大时,单节点启动的多个Mapper对磁盘IO产生竞争,造成读取吞吐降低,这种情况尤其会出现在磁盘读取为瓶颈时,例如同一台物理机上的多虚拟机实例.
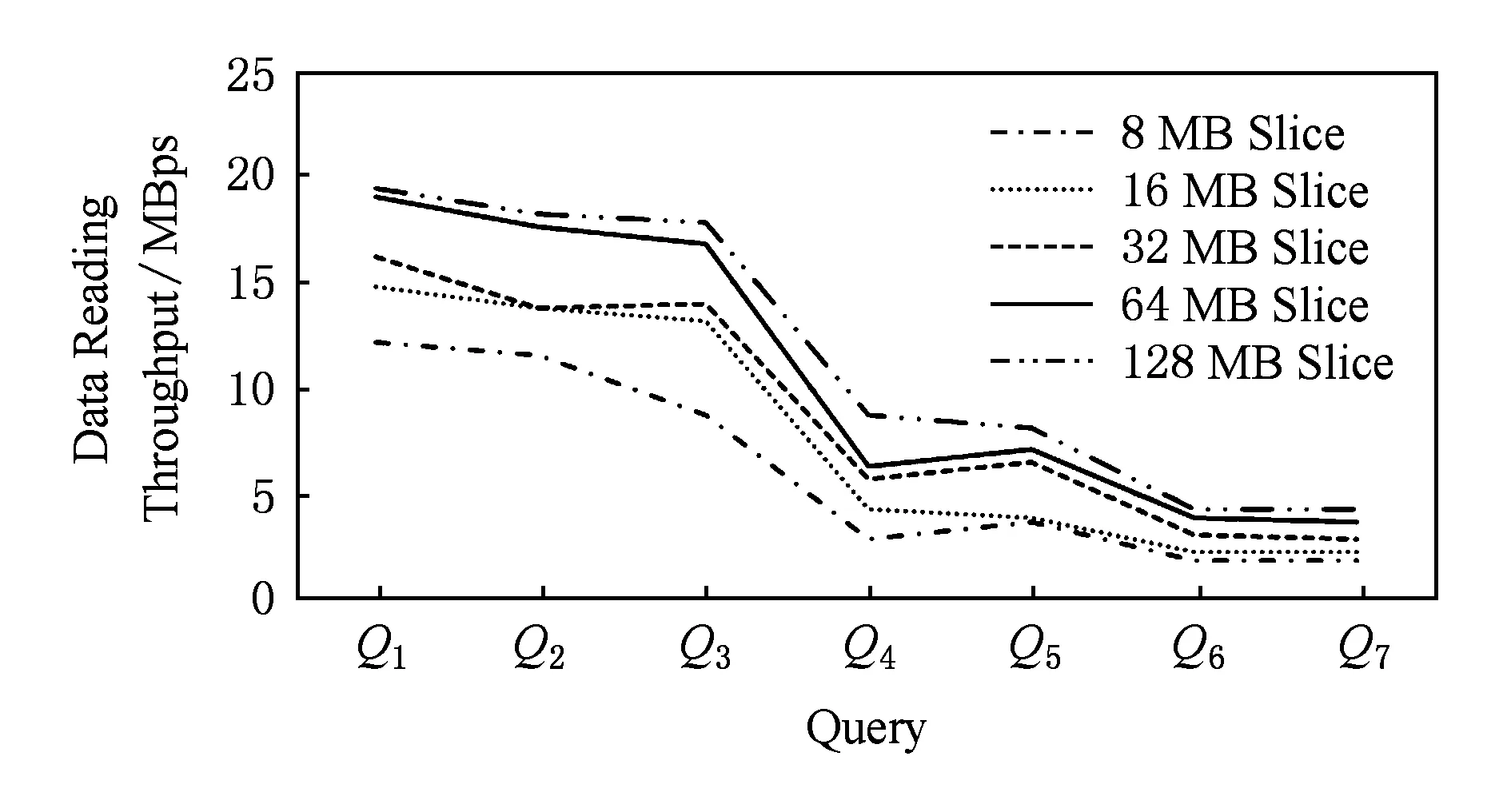
Fig. 6 Influence of query selectivity and slice size on data reading performance.图6 数据读取吞吐与查询选择度和数据片大小的关系
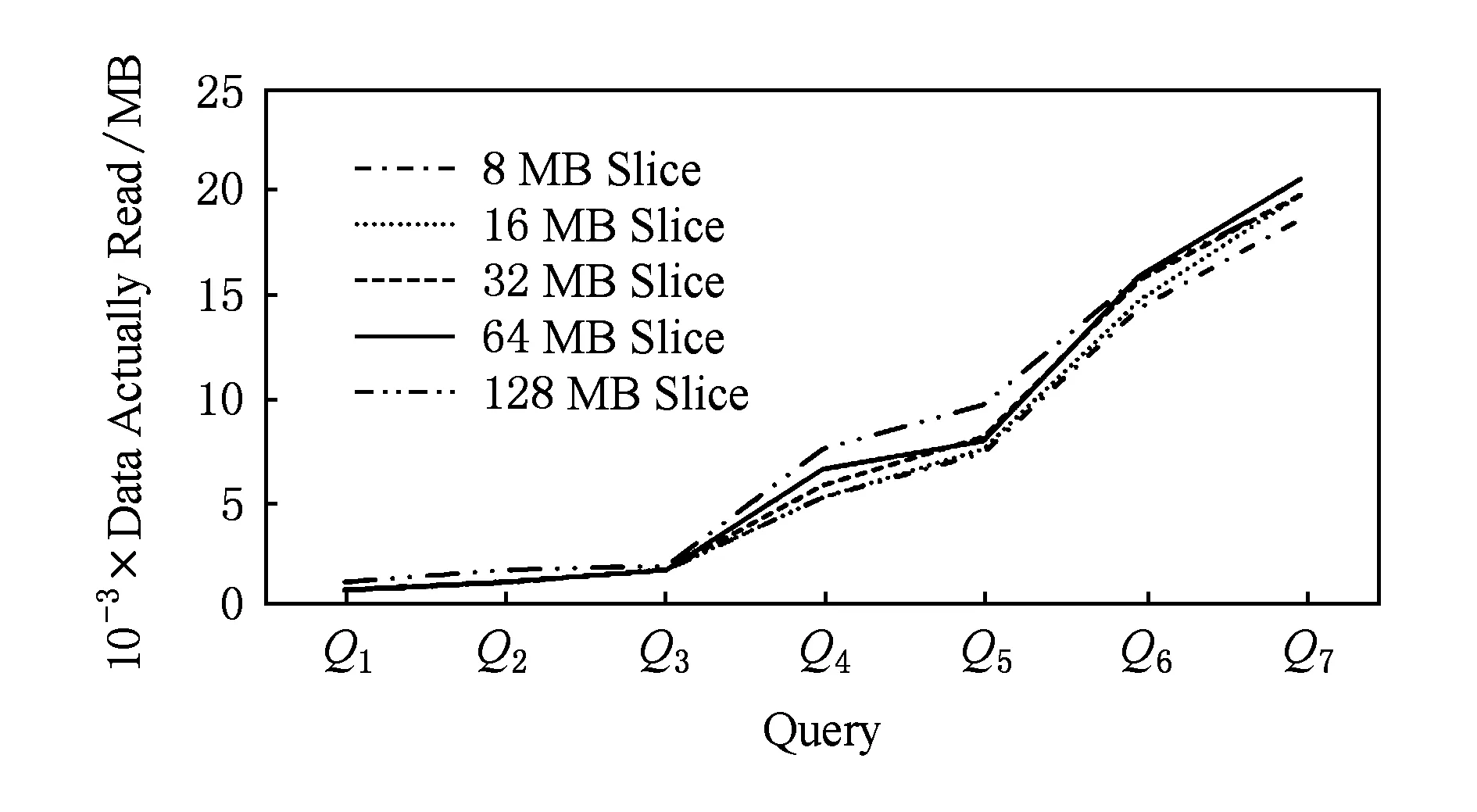
Fig. 7 Query related data size.图7 各查询相关数据量
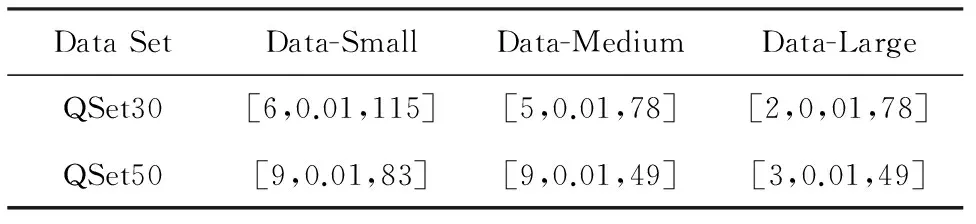
本文使用Profiling技术与多项式拟合方法建立数据读取吞吐与数据片大小和查询相关数据量之间的函数关系.具体地,首先随机生成不同查询选择度的查询集合,然后通过指定不同的分割策略为数据表建立不同数据片大小的DGFIndex,通过运行查询集合得到读取数据量大小与读取耗时(通过在RecordReader中添加Counter得到),从而得到对应的数据读取吞吐量,最后进行多项式函数拟合.
此外,本文在建模数据读取吞吐时,如果有数据片为跨块读取,并没有考虑网络远程读取,原因有2点:1)因为使用了存储大部分数据片的Mapper处理该数据片的优化技术,远程读取数据量较小,通过实验发现在使用8~128 MB数据片大小时,远程读取数据量约占总读取数据量的0~6%,因此对代价估计的影响有限.2)因为对于列式存储格式而言,如RCFile,数据片为其中的一个Row Group,而Row Group为最小读取单元,所以较难统计读取部分Row Group的时间.
Map阶段的数据解析与数据过滤的CPU代价估计如式(11)所示,即读取的记录数与每条记录消耗的CPU代价的乘积.经过实验发现,每条记录消耗的CPU代价为常量,不受其他变量的影响,在本文使用的实验环境中,该常量值约为3167 nsrecord.
MapCPU(SPj,qi)=
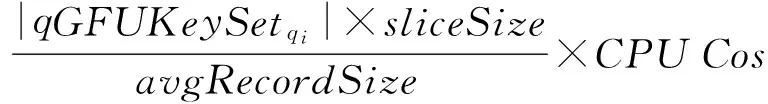
(11)
由3.2节的代价模型可以看出,首先,分割策略在2方面决定了Hive处理查询时读取的数据量:1)查询相关的数据片的数量,即给定索引维度的分割区间大小与查询谓词,就可以得到该查询相关的数据片数量;2)数据片大小,一旦各索引维度分割区间确定,就确定了数据片大小.其次,分割策略决定了数据读取吞吐,给定数据片大小与查询相关数据量,就可以根据拟合的函数得到数据读取吞吐.最后,分割策略还决定了Map阶段数据解析与过滤的CPU开销,因为其确定了读取数据量,也就确定了记录数.
由此可知,一旦给定分割策略SPj,就可以对查询集合Q中的每个qi进行代价估计,从而衡量分割策略的优劣.但是,由于候选分割策略的搜索空间大小正比于多个维度可选方案的乘积,并且对于每种分割策略,都要计算整个查询集合的代价估计,因此遍历搜索最优的分割策略将会花费较长的时间.为了加快搜索过程,本文提出了一种基于模拟退火的两阶段搜索算法来寻找较优的分割策略.
3.3基于模拟退火的两阶段分割策略搜索算法
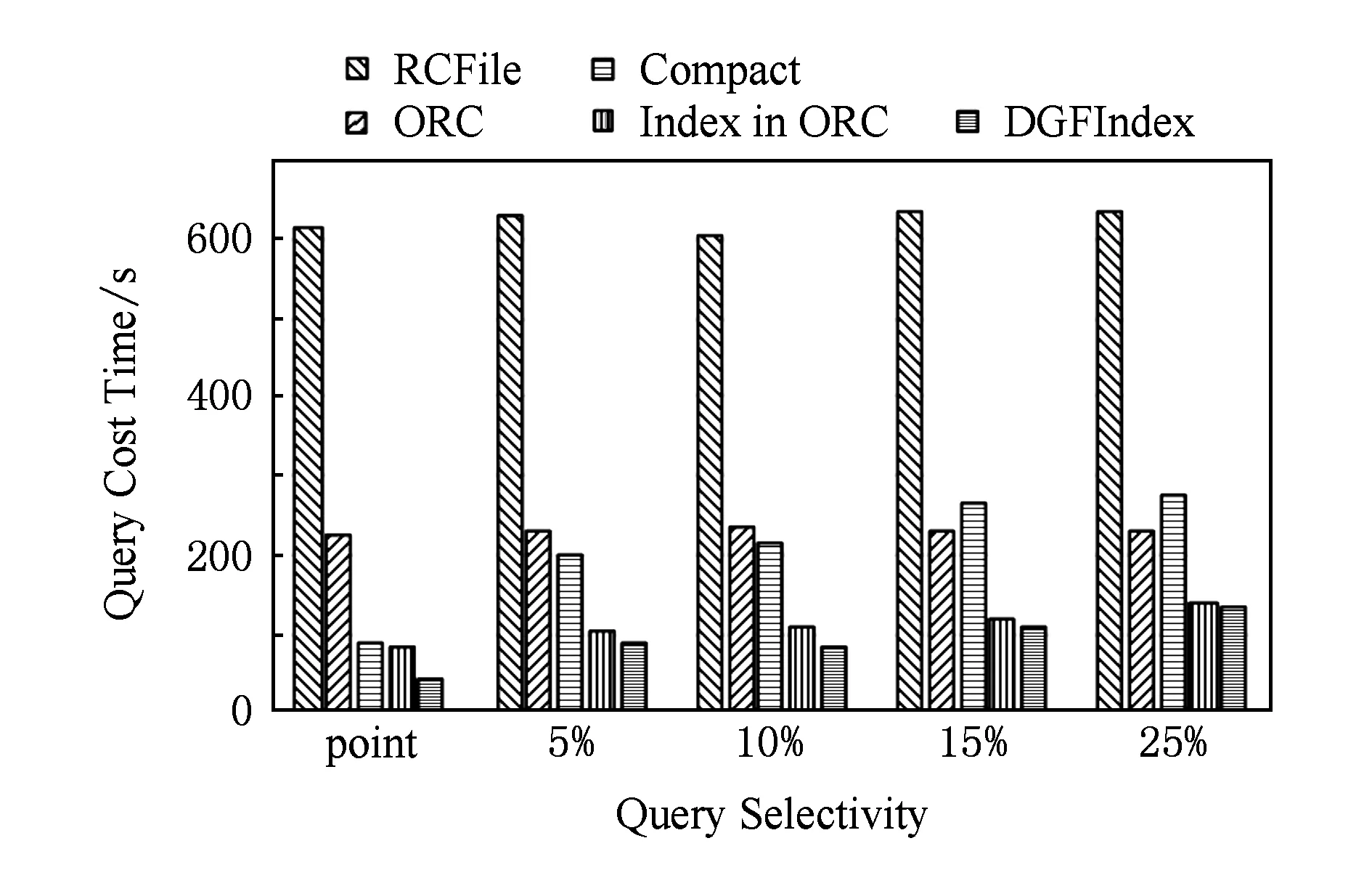
由于分割策略选择过程为多个索引维度分割区间选择组合问题,为了避免搜索陷入局部最优解,本文选择模拟退火算法进行搜索.基于模拟退火的分割策略搜索算法分为2个阶段:粗粒度近似搜索与细粒度精确搜索.第1阶段找到近似最优解,第2阶段减小搜索步长,在近似最优解周围搜索精确“最优解”.这里的最优解并非实际的最优分割策略,因为这取决于代价模型的准确性,而代价模型本身为估算值.
算法过程如算法5所示:
算法5. 基于模拟退火的两阶段搜索算法.
输入:查询集合Q;
输出:较优的分割策略.
①minIntrls=currentItrls=getInitial-
Interval();
②minCost=currentCost=getCost
(currentIntrls);
③ whiletemp>1 do
④newIntrls=getNeighbor(currentIntrls,temp);
⑤newCost=getCost(newIntrls);
⑥ ifnewCost ⑦acceptRatio=1; ⑧ else ⑩ end if 算法6. 得到当前分割策略的邻居算法. 输入:当前的分割策略currentIntrls、当前的温度temp; 输出:当前分割策略的邻居. ①newIntrls=clone(currentIntrls) ② iftemp>10 then ③ratio=1; ④ else ⑤ratio=0.1; ⑥ end if ⑦ forkthintrlinnewIntrls(kfrom 1 to idxNum) do ⑧random=random(); ⑨ ifrandom>0.5 then 从算法6过程可以看出,迭代次数由初始温度temp与冷却速率coolingRate决定:temp越小,coolingRate越大,迭代次数越少,收敛速度越快,但是可能得不到最优解;反之,则可能增加算法搜索时间.在下面的实验中,设置temp=200,coolingRate=0.01. 4实验结果与分析 4.1实验环境与测试集 1) 硬件环境.本次实验使用由32个虚拟机节点组成的集群环境,每个虚拟机节点具有12核CPU、26 GB内存、600 GB磁盘.其中一个节点作为MapReduce计算框架的主节点JobTracker,一个节点作为HDFS的主节点NameNode,一个节点作为HBase的主节点HMaster.其他节点作为从节点,运行DataNode,TaskTracker.Hive与NameNode运行在同一节点. 2) 软件环境.每个节点使用CentOS 7.0,JDK 1.7.0_65 64bit.使用Hadoop-1.2.1,HBase-0.94.23(用于存储DGFIndex的索引表).DGFIndex实现在Hive-0.14.0中.HDFS块大小设置为256 MB,Hadoop,Hive与HBase的其他配置参数都使用默认值. 3) 测试集.本实验使用TPC-H测试集中的lineitem表与Q6,使用被广泛使用的RCFile与ORC作为文件存储格式,不同数据集大小如表2所示.本实验为lineitem表在l_discount,l_quantity和l_shipdate上建立三维索引,各维度的基数如表3所示.查询集合由随机生成的Q6构成,集合中的查询具有不用的选择度,本实验使用2个查询集合:30个随机查询构成的集合QSet30与50个随机查询构成的集合QSet50.选择该测试集的原因有3点:1)TPC-H被广泛地用于数据仓库类系统的评测工作,因此使用该测试集的结果具有可比性;2)由于在Hive中,索引只作用于过滤单表读取时查询无关的数据,所以选择单表数据集足以评测索引的数据过滤性能,并且lineitem表是该测试集中最大的表;3)Q6是TPC-H中典型的多维查询,可以充分测试DGFIndex的多维数据索引能力.此外,在本实验中,在运行每个查询前都会清空操作系统的缓存并重启Hadoop,以保证索引定位的数据从磁盘读取,从而避免缓存对结果造成的影响.并且,查询集合中每个查询都会运行3次,在结果中使用3次结果的平均值,以减弱集群不稳定对结果造成的影响. Table 2 Data Size Table 3 Cardinality of Index Dimensions Fig. 8 Query cost time of Data-Medium.图8 Data-Medium上的查询耗时 4.2DGFIndex的性能 本实验中,在RCFile上创建Hive原生索引Compact Index与DGFIndex,此外,本实验还与ORC[6]中的索引进行对比.ORC是Hive目前最新的列式存储格式,内嵌了索引功能.Compact Index与ORC中索引的数据过滤效果与索引维度数值在文件中的分布有关,对于均匀数据集TPC-H来说,两者的性能较差.为了提升两者的索引性能,事先使用并行Order By对两者的数据表在索引维度上进行全排序预处理.图8,9展示了在不同数据集大小与不同查询选择度下的各种索引的查询性能. Fig. 9 Query cost time of Data-Large.图9 Data-Large上的查询耗时 从实验结果可以看出,相对不使用任何索引的RCFile,Compact Index可以提升2~7倍查询性能,DGFIndex可以提升4.7~15倍查询性能,并且,DGFIndex比Compact Index的查询性能提升了50%~114%.原因有2点:1)Compact Index只能在HDFS数据块级别过滤查询无关数据,这会造成读取过多的冗余数据;而DGFIndex可以在细粒度的数据片级别过滤查询无关的数据,从而大幅降低冗余数据的读取,提升查询性能.2)Compact Index读取索引的方式为启用额外的MapReduce任务全表扫描的方式,索引读取效率较低;而DGFIndex使用基于键值的方式,只需读取查询相关的键,读取效率较高.此外,相比于不使用索引的ORC,其内的索引提升1.6~2.6倍查询性能.DGFIndex比ORC中的索引查询性能提升了8%~28%,而对于点查询来说,分别提升了1.2倍和2.2倍.可以看出,DGFIndex在低选择度时的优势更明显,原因为:经过索引定位后,DGFIndex使用了比ORC更少的Mapper. 4.3分割策略选择算法的有效性 Fig. 10 Cost time of QSet30.图10 QSet30在不同数据片大小下的查询耗时 本实验使用RCFile作为底层存储格式.图10,11展示了不同数据量下基于代价估计的分割策略选择算法得到的分割策略的查询集合耗时与人工指定不同数据片大小的分割策略的查询集合耗时对比结果,其中后缀为opt的为本文提出算法选择的分割策略对应的数据片大小.Data-Small下人工指定的分割策略(对应索引维度l_quantity,l_discount,l_shipdate)分别为[2,0.01,60],[4,0.01,60],[4,0.01,120],[4,0.02,115]与[8,0.02,115].Data-Medium下人工指定的分割策略分别为[2,0.01,29],[2,0.01,58],[4,0.01,59],[8,0.01,58]与[12,0.01,73].Data-Large下人工指定的分割策略为[1,0.01,24],[2,0.01,24],[2,0.01,47],[4,0.01,52]与[4,0.01,97].由本文算法得到的较优分割策略如表4所示. Fig. 11 Cost time of QSet50.图11 QSet50在不同数据片大小下的查询耗时 DataSetData-SmallData-MediumData-LargeQSet30[6,0.01,115][5,0.01,78][2,0,01,78]QSet50[9,0.01,83][9,0.01,49][3,0.01,49] 由结果可以看出,人工指定分割策略方法在选择不同分割策略时性能各有差异,并且索引粒度太大或太小都无法得到较优的性能,因此在用户不熟悉数据与查询特征时较难选择较优的分割策略.相反,基于代价估计的分割策略选择算法可以根据查询集合自动地得到较优的分割策略,从结果可以看出与人工指定方法相比,最多可以减少查询集合耗时30%. 4.4基于代价估计的分割策略选择算法收敛速度 图12展示了基于遍历算法、模拟退火与人工选择分割策略选择算法的耗时,这里假设人工选择的耗时为1 s. Fig. 12 Cost time of splitting policy search algorithm.图12 分割策略选择算法耗时 从图12可以看出,基于模拟退火的算法比遍历算法快12~24倍,在短时间内搜索到较优的索引分割策略.此外,基于遍历算法的分割策略选择算法的耗时与多个索引维度基数的乘积成正比,因为其需要遍历每一种可能的分割策略的可行性.而在本实验中,索引维度的基数都较小,如果应用中遇到更大基数的索引维度,如浮点类型维度,则遍历算法的耗时是不可接受的.如果根据数据与查询特征人为选取分割策略,虽然可以快速选定,但是较难选择较优的分割策略. 5结束语 本文针对采集类数据与查询特征,提出了一种面向Hive的多维索引技术—DGFIndex,该索引以细粒度过滤查询无关的数据大幅减少冗余数据读取,其查询性能比Hive原生索引Compact Index提升50%~114%,比ORC中的索引提升8%~28%,并极大地提高了点查询的性能. 但是在创建DGFIndex时,需要人为指定各索引维度分割区间大小,在对查询与数据特征不熟悉情况下,用户很难选择最优的索引分割策略.针对该问题,本文首先提出了一种新的MapReduce代价模型,基于该模型提出了一种基于模拟退火的两阶段分割策略搜索算法,实验证明该算法可以在较短的时间内得到较优的分割策略. 本文提出的代价模型没有考虑数据分布维度,在数据分布不均匀时,对DGFIndex而言,各数据片的大小会出现不同.在这种情况下,使用查询相关GFUKey的数量估算查询相关数据量会不精确,需要得到数据片在文件中的布局来估算该值.但是由于需要记录更多的信息,因此代价估计计算的速度会减慢,分割策略的搜索速度也会大大减慢.在未来的工作中,我们将会在代价模型中引入数据分布维度,并优化在该种情况下分割策略搜索的速度. 参考文献 [1]Zaharia M, Chowdhury M, Franklin M, et al. Spark: Cluster computing with working sets[C] //Proc of the 2nd USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 2010). Berkeley, CA: USENIX Association, 2010: 10 [2]Hu Songlin, Liu Wantao, Rabl T, et al. DualTable: A hybrid storage model for update optimization in Hive[C] //Proc of the 31st IEEE Int Conf on Data Engineering (ICDE 2015). Piscataway, NJ: IEEE, 2015: 1340-1351 [3]Liu Yue, Hu Songlin, Rabl T, et al. DGFIndex for smart grid: Enhancing Hive with a cost-effective multidimensional range index[C] //Proc of the 40th Int Conf on Very Large Data Bases (VLDB 2014). New York: ACM, 2014: 1496-1507 [4]Wang Yue, Xu Yingzhong, Liu Yue, et al. QMapper for smart grid: Migrating SQL-based application to Hive[C] //Proc of the ACM SIGMOD Int Conf on Management of Data (SIGMOD 2015). New York: ACM, 2015: 647-658 [5]Thusoo A, Sarma J S, Jain N, et al. Hive: A warehousing solution over a map-reduce framework[C] //Proc of the 35th Int Conf on Very Large Data Bases (VLDB 2009). New York: ACM, 2009: 1626-1629 [6]Huai Yin, Ma Siyuan, Lee Rubao, et al. Understanding insights into the basic structure and essential issues of table placement methods in clusters[C] //Proc of the 40th Int Conf on Very Large Data Bases (VLDB 2014). New York: ACM, 2014: 1750-1761 [7]Jiang Dawei, Ooi B C, Shi Lei, et al. The performance of MapReduce: An in-depth study[C] //Proc of the 36th Int Conf on Very Large Data Bases (VLDB 2010). New York: ACM, 2010: 472-483 [8]Dittrich J, Quiane-Ruiz J A, Jindal A, et al. Hadoop++: Making a yellow elephant run like a cheetah (without it even noticing)[C] //Proc of the 36th Int Conf on Very Large Data Bases (VLDB 2010). New York: ACM, 2010: 515-529 [9]Eltabakh M, Ozcan F, Sismanis Y, et al. Eagle-eyed elephant: Split-oriented indexing in Hadoop[C] //Proc of the 16th Int Conf on Extending Database Technology (EDBT/ICDT 2013). New York: ACM, 2013: 89-100 [10]Richter S, Quiane-Ruiz J A, Schuh S, et al. Towards zero-overhead static and adaptive indexing in Hadoop[J]. The VLDB Jounal, 2014, 23(3): 469-494 [11]Aji A, Wang Fusheng, Vo H, et al. Hadoop GIS: A high performance spatial data warehousing system over MapReduce[C] //Proc of the 39th Int Conf on Very Large Data Bases (VLDB 2013). New York: ACM, 2013: 1009-1020 [12]Eldawy A, Mokbel M. A demonstration of spatial Hadoop: An efficient MapReduce framework for spatial data[C] //Proc of the 39th Int Conf on Very Large Data Bases (VLDB 2013). New York: ACM, 2013: 1230-1233 [13]Herodotou H. Hadoop performance models[R]. Pittsburgh, PA: arXiv preprint, 2011 [14]Herodotou H, Badu S. Profiling, what-if analysis, and cost-based optimization of MapReduce programs[C] //Proc of the 37th Int Conf on Very Large Data Bases (VLDB 2011). New York: ACM, 2011: 1111-1122 [15]Lin Xuelian, Meng Zide, Xu Chuan, et al. A practical performance model for Hadoop MapReduce[C] //Proc of 2012 IEEE Int Conf on Cluster Computing (Cluster 2012). Piscataway, NJ: IEEE, 2012: 231-239 [16]Wang Youwei, Wang Weiping, Meng Dan. Query optimization by statistical approach for Hive data warehouse[J]. Journal of Computer Research and Development, 2015, 52(6): 1452-1462 (in Chinese)(王有为, 王伟平, 孟丹. 基于统计方法的Hive数据仓库查询优化实现[J]. 计算机研究与发展, 2015, 52(6): 1452-1462) [17]Song Jie, Li Tiantian, Zhu Zhiliang, et al. Research on I/O cost of MapReduce join[J]. Journal of Software, 2015, 26(6): 1438-1456 (in Chinese)(宋杰, 李甜甜, 朱志良, 等. MapReduce连接查询的I/O代价研究[J]. 软件学报, 2015, 26(6): 1438-1456) Liu Yue, born in 1988. PhD candidate. Student member of China Computer Federation. His research interests include distributed system and database system. Li Jintao, born in 1962. Professor and PhD supervisor. His research interests include multimedia technology, virtual reality technology, and pervasive computing technology. Hu Songlin, born in 1973. Professor and PhD supervisor. Senior member of China Computer Federation. His research interests include service computing, distributed system and middleware. A Cost-Based Splitting Policy Search Algorithm for Hive Multi-Dimensional Index Liu Yue1,2, Li Jintao1, and Hu Songlin3 1(InstituteofComputingTechnology,ChineseAcademyofSciences,Beijing100190)2(UniversityofChineseAcademyofSciences,Beijing100049)3(InstituteofInformationEngineering,ChineseAcademyofSciences,Beijing100093) AbstractIn the domain of energy Internet, smart city, etc, the massive smart devices collect large amount of data every day, and traditional enterprises need to perform lots of multi-dimensional analysis on these data to support decision-making. Recently, these enterprises try to solve the big data problem with technologies from Internet companies, for example, Hadoop and Hive etc. However, Hive has limited multi-dimensional index ability, and cannot satisfy the requirements of high-performance analysis in traditional enterprises. In this paper, we propose a distributed grid file based multi-dimensional index—DGFIndex to improve the multi-dimensional query performance of Hive. However, DGFIndex needs user to specify the splitting policy when creating index, which is not trivial for user when they are not familiar with data and query pattern. To solve it, we propose a novel MapReduce cost model to measure the DGFIndex-based query performance on specific splitting policy, a two-phase simulated annealing algorithm to search for the suitable splitting policy for DGFIndex, and finally decrease the total cost time of query set. The experimental results show that, DGFIndex improves 50%~114% query performance than original Compact Index in Hive. For static query set, compared with manual-specifying partition policy, our algorithm can choose suitable interval size for each index dimension, and decrease the cost time of query set at most 30%. Key wordsHive; MapReduce; multi-dimensional index; cost model; simulated annealing 收稿日期:2015-12-21;修回日期:2016-02-02 基金项目:国家自然科学基金项目(61070027) 通信作者:虎嵩林(husonglin@iie.ac.cn) 中图法分类号TP311.132 This work was supported by the National Natural Science Foundation of China (61070027).