一种融合情景和评论信息的位置社交网络兴趣点推荐模型
2016-06-30余永红宋成芳丁永刚
高 榕 李 晶 杜 博 余永红 宋成芳 丁永刚,3
1(武汉大学计算机学院 武汉 430072)2(计算机软件新技术国家重点实验室 (南京大学) 南京 210046)3(湖北大学教育学院 武汉 430062)(gaorong198149@163.com)
一种融合情景和评论信息的位置社交网络兴趣点推荐模型
高榕1李晶1杜博1余永红2宋成芳1丁永刚1,3
1(武汉大学计算机学院武汉430072)2(计算机软件新技术国家重点实验室 (南京大学)南京210046)3(湖北大学教育学院武汉430062)(gaorong198149@163.com)
摘要随着位置社交网络(location-based social network, LBSN)的快速增长,兴趣点(point-of-interest, POI)推荐已经成为一种帮助人们发现有趣位置的重要方式.现有的研究工作主要是利用用户签到的历史数据及其情景信息(如地理信息、社交关系)来提高推荐质量,而忽视了利用兴趣点相关的评论信息.但是,现实中用户在LBSN中只对少数兴趣点进行签到,使得用户签到历史数据及其情景信息极其稀疏,这对兴趣点推荐来说是一个巨大的挑战.为此,提出了一种新的兴趣点推荐模型,称为GeoSoRev模型.该模型在已有的基于矩阵分解的经典推荐模型的基础上,融合关于兴趣点的评论信息、用户社交关联和地理信息这3个因素进行兴趣点推荐.基于2个来自Foursquare的真实数据集的实验结果表明,与其他主流的兴趣点推荐模型相比,GeoSoRev模型在准确率和召回率等多项评价指标上都取得了显著的提高.
关键词地点推荐;矩阵分解;社交关系;地理信息;评论文本
近年来,随着Web2.0技术的快速发展、移动设备的流行和定位方式的多样化,用户可以更加容易地获得他们的实时位置信息,同时也催生了基于位置的社交网络(location-based social network, LBSN)的出现,如Foursquare和 Facebook.这个变化也使得基于位置的社交成为了一种新的社交模式.如图1所示,数以百万的社交网络用户通过基于位置的社交网络(LBSN)以签到的形式与好友分享他们喜好的兴趣点(point-of-interest, POI)(如餐厅、博物馆等)和位置,并发表相关的评论.同时,基于位置的社交网络也能帮助人们更方便地了解周围的信息以探索周围的环境从而辅助自己的决策.为了达到这种目的,兴趣点推荐就成为了一种重要的方式.

Fig. 1 A location-based social network.图1 基于位置的社交网络
位置社交网络提供了大量的位置数据以及丰富的情景信息,这些情景包括:社交关系、类别信息等,表现出规模巨大(volume)、快速传播(velocity)、模态多样(variety)等大数据特性[1],具有重要的应用价值和研究意义[2].因此,兴趣点的推荐已成为了一个近年来非常热门的研究课题.目前,大多数的兴趣点推荐方法[3-8]都是根据用户基于兴趣点的历史签到信息及其情景信息(如评级、时间、地点、社交关系、标签、类别等)来挖掘用户对于尚未签到的兴趣点的偏好.而上述推荐方法都是基于用户对于兴趣点的签到频率可以明确反映用户对兴趣点的偏好程度这样一个前提.图2是来自Foursquare数据集[9]中基于一个用户对一个兴趣点的签到次数分布.如图2所示,用户对于兴趣点的签到并不是很积极,超过50%的兴趣点都由同一用户只签到一次.因此,仅仅利用稀疏的用户签到数据及其情景信息作为推荐模型的依据会对最终的推荐结果带来不小的偏差.

Fig. 2 Distribution of the number of a user’s check-ins in Foursquare[9].图2 用户在Foursquare[9]中签到次数的分布
现实中,用户的偏好除了可以通过分析用户的历史签到信息及其情景信息进行预测外,还可以分析用户对兴趣点的评论内容信息来挖掘用户偏好.例如:一个用户对一家餐厅的评价:“餐厅的味道不错,菜品口味偏辣!”从上述评论可以看出用户对这家餐厅的情感倾向是正面的、积极的,同时对这个餐厅的兴趣程度比较高.因此,鉴于用户历史签到数据的稀疏性,本文利用与用户对兴趣点签到信息相关的内容评价信息结合历史的签到信息及其相关情景信息来进行兴趣点推荐,从而提高兴趣点推荐的质量.然而,这对现有推荐模型而言是一个不小的挑战,因为需要找到一个有效的方法来融合来自多个异构数据源的数据进行兴趣点推荐.
概括起来,本文做出了3点对兴趣点推荐的贡献:
1) 根据对大规模数据的分析,本文发现这种用于做兴趣点推荐的数据不仅仅是一种隐式数据,同时也包含来自不同领域且结构不相同的多种数据.因此,本文提出利用矩阵分解来融合异构数据做兴趣点推荐,这也是基于大规模数据进行数据融合的一种技术上新的探索和尝试.
2) 由于用做兴趣点推荐的数据中除了包含签到数据的情景信息(即地理信息和社交关系信息),还包含用户对于兴趣点的评论信息.因此,本文提出一种全新的兴趣点推荐模型.该模型将评论信息与签到数据的情景信息(用户的社交关系和兴趣点的地理信息)融合,并将其纳入到同一的模型中发挥各自的长处,从而实现互补,最终实现对用户偏好更好的预测,并给出了具体求解过程.
3) 本文在一个大规模的位置社交网络数据上进行了评测.实验结果说明:相比其他主流先进推荐模型,本文提出的模型在推荐准确率和召回率等评测指标上得到了有效的提高.
1相关工作
本节主要回顾一些与本文相关的最新研究工作,这些工作大多都是围绕各种情景信息(即地理因素、社交关系等)和评论信息进行兴趣点推荐.
1) 基于情景信息的推荐.由于在LBSN中,用户的行为不相同,且随着情景(地理位置、社会关系等)变化,因此,LBSN的兴趣点推荐应当具有个性化,并且与情景相关.目前大多数兴趣点推荐也都是集中在如何利用各种情景信息(地理因素、社交关系等)来进行兴趣点推荐.Ye等人[10]受到好友之间会分享较多共同兴趣的观点启发,深入研究了基于LBSNs的地点推荐方法中用户之间的好友关系,通过分析来自Foursquare的数据集,发现好友关系与地理位置之间的强关联性,进而提出一种基于朴素贝叶斯算法来融合用户偏好、地理位置和用户社交关系的推荐模型.Cheng等人[11]将用户社交关系和地理位置融入概率矩阵分解模型.通过建立用户在位置上的签到概率模型作为多中心高斯模型来捕获地理影响力,继而把社交信息和地理信息融入到一个广义的矩阵分解模型中.Lian等人[12]提出利用加权矩阵分解模型来进行兴趣点推荐.由于在基于位置的社交网络的用户签到活动中用户存在空间聚集现象,因此,首先从二维核密度估计的角度来刻画空间聚集效应,并将它整合进矩阵分解模型中,然后解释为何对空间聚集效应的建模可以帮助应对用户-兴趣点矩阵稀疏性的挑战.
2) 基于评论内容信息的推荐.为了缓解用户历史签到数据及其情景信息稀疏对于兴趣点推荐模型的影响,研究者开始积极探索利用兴趣点评论信息进行兴趣点推荐.Cheng等人[13]通过22万用户收集到的2 200万个签到数据对空间、时间、社交和文本等相关用户信息进行定量分析来评估用户移动性模式.他们发现:①基于位置的社交网络用户遵循“Levy Flight”移动模式及周期性的行为;②地理和经济限制条件影响着移动的模式和用户的社会地位;③与签到相关的基于内容和情感的评论分析能够为更好地理解用户参与这些服务提供更加丰富的语境来源,也能够提高相关推荐的质量.Yin等人[14-15]利用著名的主题模型,即LDA模型,预测用户的兴趣程度以及基于本地的兴趣点(例如一个城市).个人兴趣和本地兴趣地点都被表示为一个混合主题,其中,每个主题都是基于兴趣点的独立概率分布,同时每个主题通过学习用户的签到历史数据和兴趣点的类别信息而得到.
总的来说,上述兴趣点推荐模型都取得了不错的推荐效果,但它们侧重评论内容信息或单一情景信息(如地理因素、社交关系等).基于情景信息的兴趣点推荐模型大多数都受到如下限制:1)相关模型和潜在空间缺乏容易理解的算法解释;2)模型中评级分数的假设条件与现实不太相符;3)冷启动问题上表现不尽如人意.而基于评论信息的兴趣点推荐则大多数因为缺乏对用户基于兴趣点签到行为中各种情景信息(如地理信息、用户社交关系)特点深入分析,而造成比较低的推荐质量.因此,本文通过对上述各种信息进行关联分析,同时考虑用户签到行为中的各种情景信息和评论信息,将其融入到推断用户对于兴趣点的偏好过程中.相比现有的推荐模型,本文提出的模型从评论中学习主题,这样可以更好地匹配用户的评级行为,同时在进行兴趣点推荐时将上述各种情景信息关联起来统一考虑,更能反映现实场景,贴合用户的真实行为.
2基于矩阵分解模型的兴趣点推荐
2.1问题描述
本文研究的问题与传统的基于位置推荐系统略有不同,传统的基于位置推荐系统只考虑用户-兴趣点矩阵,而本文还考虑了多个情景信息和评论内容语义依据.
假设共有m个用户ui和n个兴趣点lj,且用户u∈{u1,u2,…,um},兴趣点l∈{l1,l2,…,ln}.
定义1. 评级矩阵R.假设有m个用户和n个兴趣点(地点),矩阵R∈m×n描述用户ui对于兴趣点lj的偏好.每个元素Ri,j反映了用户对于兴趣点的访问次数.如果Ri,j=0,则并不代表用户从来没有访问过兴趣点,而是意味着用户不知道这个兴趣点.
为此,本文的目标是:基于那些用户没有访问过的兴趣点,如何有效地融合来自不同数据源的数据预测该用户对于尚未访问过的兴趣点偏好,从而按照兴趣点偏好为其推荐兴趣点.表1列出了本文的主要符号.

Table 1 Symbols
2.2基于矩阵分解模型的兴趣点推荐
矩阵分解方法得益于它们的准确率和扩展性,已经成为一种主流推荐方法[16].它们不仅用于高斯噪声的概率解释,而且对于推荐来说可以灵活地增加数据源.因此,本文基于矩阵分解模型来融合评论和情境信息进行位置社交网络推荐.将用户和兴趣点映射到一个潜在的低维k≪min(m,n)的隐空间上.在联合隐式空间上,把用户对兴趣点的偏好建模成它们在隐式空间中的点积,而偏好又与用户对兴趣点的签到频率有关,更高的签到频率体现了用户对兴趣点有更多的偏好.因此,如定义1,用户ui对于兴趣点lj的偏好近似采用用户和地点的潜在特征向量内积表示,如式(1)所示:
(1)
基于矩阵的稀疏性约束的考虑[12],在式(1)中加入用户和地点的偏置项以及全局偏置项,因此如式(2)所示:
(2)
其中,用户的潜在向量Ui表示矩阵U∈m×k中的第i行,地点的潜在向量Lj表示矩阵L∈n×k中的第j行;bi和bj分别是关于用户ui和地点lj的偏置项;μ表示全局偏置项.
将上述映射问题进行进一步扩展,得到如下最小化加权平方误差,如式(3)所示:
(3)
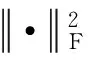
(4)
其中,λ1和λ2分别是用户和兴趣点的权重因子;U∈m×k和L∈n×k分别代表用户矩阵和地点矩阵.一般通过梯度下降的方法来求解U和L.
3GeoSoRev模型
本文在考虑用户历史签到数据的基础上,还考虑了用户对兴趣点评论的语义依据以及兴趣点相关的情景信息,提出一种新的兴趣点推荐模型GeoSoRev(geographical,social and review matrix factorization)模型.
3.1评论内容信息建模
评论经常用于解释用户评级的原因,从而有利于理解用户的评级行为,同时对评论的深入挖掘可以有效地缓解兴趣点冷启动问题.主题建模技术经常被用于挖掘在评论中隐藏的“主题”,最简单的主题模型是潜在狄利克雷分配模型(LDA)[17].基于矩阵分解的主题模型可以估计每个文档的隐含主题的独立概率分布[18],本文采用基于矩阵分解的主题模型来发现评论中的隐藏“主题”.
首先,将一个评论定义为一个文档di,j(即用户ui对兴趣点lj的评论),单词数目为N(n∈{1,2,…,N}),Bdi,j,n代表单词-评论矩阵的元素,Fi,j,n代表在评论文档di,j中单词n的频度矩阵的元素.那么基于式(1),频率(评分)矩阵采用2个实数矩阵Θ和Φ的内积近似表示,如式(5)所示:
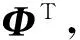
(5)
其中,Θ=(θdi,j),Φ=(φn,k),且φn,k,θdi,j>0,它们分别是单词和主题的独立概率分布.
将式(5)最小化后得到式(6):
(6)
将式(5)结合式(3),采用TopicMF模型[19]思想,得到融合了评论信息的兴趣点推荐模型,如式(7)所示:
(7)
上述目标函数将基于矩阵分解的评级预测模型与基于矩阵分解的发现潜在评论文本内容中的主题因素模型结合起来.因此,需要我们将主题因素和用户、地点相对应的潜在因素关联起来.为了体现这种关联关系,采用基于HFT模型思想中的转换函数[20]进行三者的融合.
(8)
其中,β是一个转换参数,上述函数体现用户、主题因素、地点三者之间的单调关系.上述函数基于这样的融合依据:用户对一个兴趣点给予很高的评级那么代表着他对这个兴趣点很强的偏好,同时获得高评级中某些特定单词的分布必然对应一些相关用户的评论话题中的主题,而这些主题必然被讨论得更多.
3.2地理信息建模
用户在兴趣点的签到记录包含着许多地理信息,因此,本文基于一个真实的数据集Foursquare[9]中的用户签到位置分布进行分析.如图3所示,通过对地理分布的估计来捕捉用户对特定地点的偏好.

Fig. 3 Physical distance influence probability distribution of users in Foursquare[9].图3 在Foursquare[9]中物理距离对用户签到情况的影响
如图3所示,可以发现:同一个用户签到的大部分兴趣点都处于一个相互地理距离很小的范围中,这一现象可以归因于地理区域的影响.在现实中,人们通常访问一个兴趣点(例如博物馆),然后前往其附近的兴趣点(例如餐馆和商店).毗邻的兴趣点比远距离的兴趣点具有更强的地理相关性.因此,用户的签到地点往往形成地理集群区域.由此根据用户签到数据的地理区域位置特征进行建模可以有效提高兴趣点推荐的效果.
本文不同于根据用户访问过的兴趣点和尚未访问的兴趣点之间的地理关联关系进行建模来预测用户偏好.本文对于用户ui对地点lj的偏好采用该用户对地点lj几个近邻地点的偏好表示,同时使用地理区域位置关系加权策略来弥补经典矩阵分解模型中对于地理位置的建模缺陷.因此,根据式(1)(2),基于地理区域特征[21]进行兴趣点推荐,最小化问题表示为如下公式:

(9)
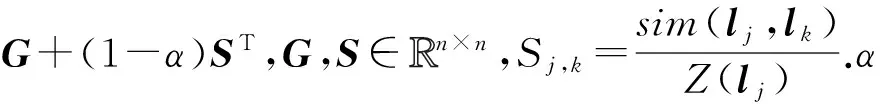
(10)
∀lk∈C(lj),
其中xj,xk分别表示地点lj,lk的地理坐标(经度和纬度),从地理区域的大小考虑,对于距离用户太远的地理区域中的兴趣点,用户签到的可能性很小.因此,本文提出一个地理区域大小距离变量D进行地理范围区别,而C(lj) 表示地点lj的邻近的地点,在实验中根据经验值设置D=10 000,如果待推荐的地点不在用户当前位置的C(lj)中则不考虑该地点.
3.3用户社交关系建模
在现实中,用户经常会去那些用户好友强烈推荐的餐馆或者地点.换句话说,基于社会关系的用户好友极大地影响了用户基于兴趣点的签到行为,可以利用访问用户的社会网络关系来提升兴趣点推荐算法的性能.
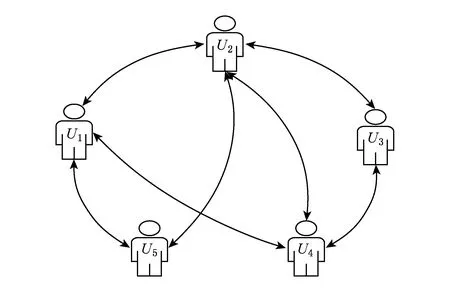
Fig. 4 Social network.图4 社交网络
如图4所示为现实世界中好友之间的社交网络,用户与用户之间的社交联系是相互的,本文引入相似度函数来体现好友之间的联系.因此,基于融合社交网络信息兴趣点推荐模型[22],目标函数最小化如式(11)所示:
(11)
其中,sim(i,f)为用户ui和好友uf之间的相似度.本文采用皮尔森相关系数来计算相似度,其计算公式如下:
sim(i,f)=
(12)

3.4GeoSoRev模型
在3.1~3.3节中本文基于矩阵分解模型将评级预测与评论内容信息、地理位置信息和用户社交关系分别整合建模,如式(7)(9)(11).通过合并潜在因素和主题,提出一个融合方案GeoSoRev模型来融合评论内容信息、地理信息和社会关系进行评级预测.最小化目标函数如下:

(13)

3.5GeoSoRev模型优化
本文采用梯度下降法[23]来求解目标公式的局部最优解.
(W⊙W⊙(UHLT))LHT+λ1ui+

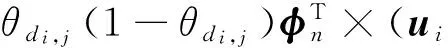
(14)
(WT⊙WT⊙(LHTUT))UH+λ2lj+
(15)
(16)
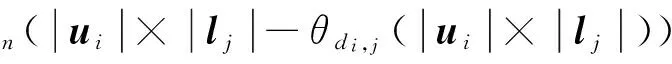
(17)
本文的目标是同时优化与评级相关的参数(U,L,H)和与之相关的主题参数矩阵θ,φ.其中U,L和H通过式(14)~(16)进行梯度下降优化,φ是通过式(6)的更新得到.因此,通过迭代以下2个步骤来实现:

(18)

(19)
对于式(15)的第1步,通过L-BFGS优化算法[24]予以更新;式(15)的第2步,对于φ更新采用投影梯度技术[25]来完成.2个步骤是反复迭代,直到最终达到局部最优.
4实验
4.1实验数据集
实验中采用了真实的数据集,即Foursquare数据集.Foursquare数据集[26]包含2个子数据集,一个数据集收集来自美国纽约(NYC)的数据,一个数据集收集来自美国洛杉矶(LA)的数据.2个数据集的统计如表2所示.由表2可观察到,2个数据集的用户-兴趣点的矩阵密度分别为5.68×10-5和4.04×10-5.由于数据集中用户-兴趣点矩阵密度非常低而造成了大多数主流的兴趣点推荐算法的精度普遍不高.例如,基于数据集的用户-兴趣点矩阵密度为2.72×10-4,得到的准确率最大只有0.06[27].所以,基于本文的数据集中比较低的用户-兴趣点矩阵密度,最终得到普遍偏低的预测准确率和召回率是合理的.同时LA数据集的矩阵密度略高于NYC数据集,因此,基于LA数据集得到的准确率和召回率大多略高于基于NYC数据集.
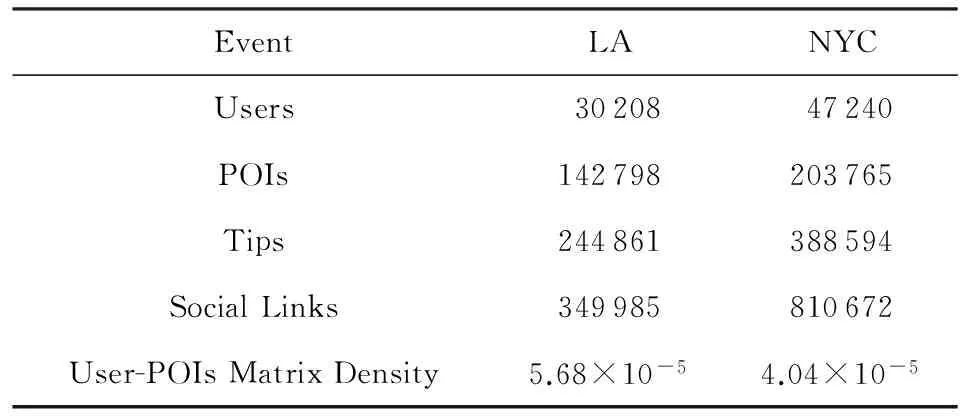
Table 2 Statistic on the Datasets
为了验证推荐算法的准确性,对2个数据集都进行预处理,仅保留每天至少访问5个位置的活跃用户.本文实验中按 8∶2的比例将数据随机地分为训练集和测试集,同时这个随机选择独立做5次.
4.2评价指标
关于推荐性能,本文采用2个广泛使用的指标来评估Topk兴趣点推荐性能,即准确率Precision@k和召回率Recall@k,简写为P@k和R@k.对一个目标用户ui,P@k表示前k个被推荐的兴趣点会包括多少比例的测试访问地点;R@k表示前k个被推荐兴趣点中有多少比例是这个用户访问过的.Q(ui)表示用户ui签到过的地点,E(ui)表示前k个被推荐的兴趣点.P@k和R@k定义为
(20)
(21)
其中,V表示测试数据中用户的数量.在实验中,选择P@1,P@5和P@10,R@1,R@5和R@10作为评价指标,结果统计如表3所示:

Table 3 LA Dataset
4.3推荐模型对比
本文选定了5种方法作为对比模型:
1) CoRe[28].提出了一种基于鲁棒性规则融合用户社会关系和地理影响的兴趣点推荐算法,其中对地理影响因素基于核密度估计进行建模.
2) USG[27].采用一种统一的线性模型融合用户偏好、社会关系和地理影响,从而进行兴趣点推荐建模.
3) UAI[29].基于情感分析技术对用户的评论进行建模,同时采用一种混合模型基于用户社会和地理相似性融合评论建模进行兴趣点的推荐.
4) DRW[30].基于动态随机游走模型融合用户社会关系、类别信息和流行度信息进行兴趣点推荐.
5) NCPD[31].基于NMF矩阵分解模型融合用户的地理信息和类别信息进行兴趣点推荐算法,其中采用基于用户地理邻居的影响对地理因素进行建模.
实验中,k的值分别设置为1,5,10.每改变一次k值,对每一个算法计算P@k和R@k.在实验中出于考虑实验的效果和有效性的目的,将隐式空间维数设置为200.λ1,λ2是控制用户和地点矩阵的权重参数,通过交叉验证设置λ1,λ2=0.05;λ3是控制社交关系的权重参数,设置λ3=0.01;λ4是控制评论信息的权重参数,设置λ4=0.1.设置式(9)中的地理位置权重α=0.4时,推荐效果最佳[21].
4.4实验结果分析
本节从3个角度来评估GeoSoRev模型:1)将GeoSoRev模型与5种现有的兴趣点推荐模型进行比较;2)基于提出的模型对比分析地理信息、用户社交关系和评论文本内容这3个要素对推荐系统评估指标的贡献;3)讨论相关参数影响.
4.4.1推荐模型的比较与分析
如表3和表4所示,由于基于NMF矩阵分解模型融合了社交关系影响、地理位置因素的影响以及评论信息,与其他5个对比推荐模型相比GeoSoRev模型在准确率和召回率上表现出最好的推荐质量.兴趣点个数k的增加,使得准确率不断下降和召回率不断上升.这是由于给用户推荐更多的兴趣点有助于用户发现更多的兴趣点,这样会促进用户更愿意进行兴趣点的签到.
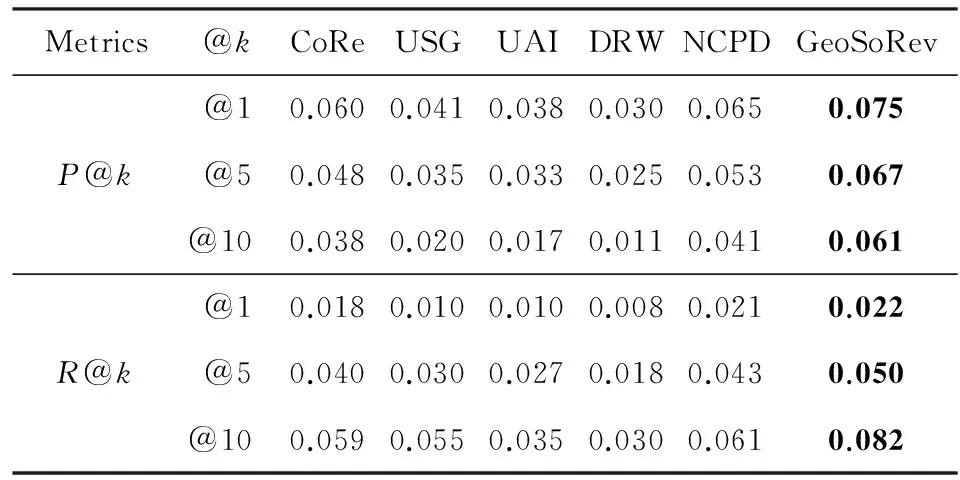
Table 4 NYC Dataset
1) USG.该模型整合用户社交关系和兴趣点地理影响,但没有考虑相关类别信息和评论信息.此外,把兴趣点地理影响以及用户社会关系影响进行简单的线性加权而没有考虑它们之间实际的联系,这与现实不符,因为有些用户可能更多地依靠朋友的推荐而有些用户更多地受限于地理因素的影响.因此,如表3和表4所示,USG最终体现出第4优秀的推荐精度.
2) CoRe.该模型和USG一样,同样缺乏对类型信息、评论信息的考虑.但是由于它采用了一个更具有鲁棒性的规则而不是简单的线性加权来对用户的社会关系和地理影响进行融合,同时对地理因素也进行基于核密度估计的建模.因此,如表3和表4所示,它最终体现出第3优秀的推荐精度.
3) UAI.基于情感分析技术对评论信息进行建模分析情感倾向,但是分析过程中该模型仅仅简单将表示评论中的情感属性相加而作为情感倾向的评价标准,这样的假设与实际情况有一定的差别.例如:“高质量”、“高价格”体现出了不同的情感倾向,不能因为都含有一个“高”而把它们作为相同的情感属性.此外,该模型采用了概率矩阵模型基于社交和地理相似性结合上述评论模型进行三者融合,从而进行兴趣点推荐.因此,如表3和表4所示,它最终体现出第5优秀的推荐精度.
4) DRW.基于动态的随机游走模型,融合了用户的社交关系、相关类别信息以及流行度信息,忽略了兴趣点推荐中最重要的地理因素的影响.因此,它最终体现出最差的推荐效果.
5) NCPD.基于NMF矩阵分解模型融合地理影响和流行度信息,同时从地理邻域特点基于矩阵分解模型对地理因素进行建模.但是,由于缺乏对用户社会关系的建模,因此相对于CoRe,最终推荐精度提高不大.如表3和表4所示,它最终体现出第2优秀的推荐精度.
6) GeoSoRev.基于2个数据集GeoSoRev模型在推荐质量上表现最好,相对于NCPD算法取得了较大的提高.原因如下:①GeoSoRev相对于USG,CoRe,NCPD,DRW来说,全面考虑用户基于兴趣点的评论内容息、用户社会关系以及基于地理邻域特点的地理因素的影响.②相比UAI而言,GeoSoRev中评论内容信息采用了基于主题矩阵分解模型来整合评论内容而没有采用基于情感分析技术来对评论内容进行建模,而且对地理因素建模采用了基于地理邻域特征而不是类似UAI中基于地理位置相似性建模.
4.4.2要素影响分析
本节对GeoSoRev模型中地理信息、用户社交关系和评论内容信息3个要素进行分析.这3个要素分别被命名为Geo,So和Rev,同时这3个要素分别对应式(6)(9)(11).图5(a)(b)分别是基于LA数据集在准确率和召回率2个评估指标上3个要素与GeoSoRev模型的对比结果.图6(a)(b)分别是基于NYC数据集在准确率和召回率2个评价指标上3个要素与GeoSoRev模型的对比结果.
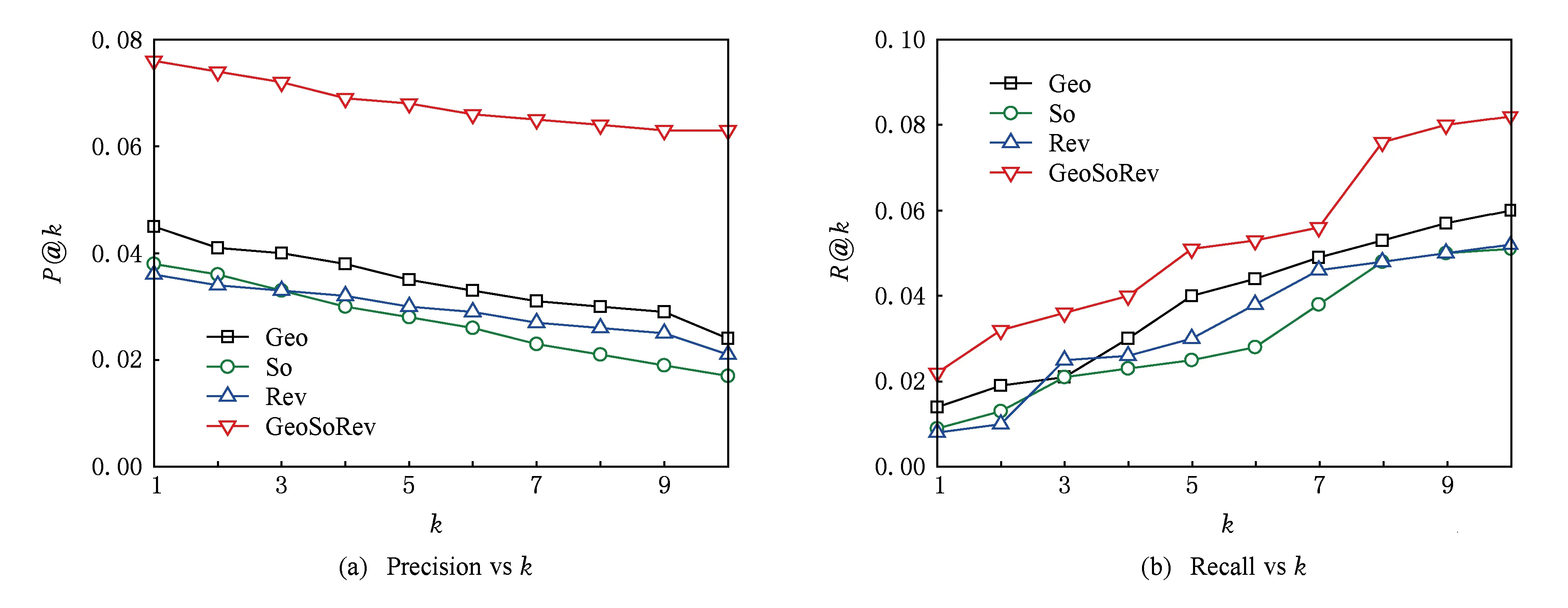
Fig. 5 Recommendation accuracy of GeoSoRev compared with its three components on LY datasets.图5 GeoSoRev模型基于LY数据集与其3个组成要素的推荐性能对比
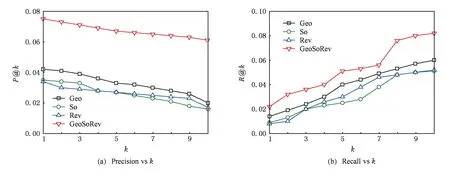
Fig. 6 Recommendation accuracy of GeoSoRev compared with its three components on NYC datasets.图6 GeoSoRev模型基于LY数据集与其3个组成要素的推荐性能对比
从图5、图6可以得到以下结论:1)3个要素对于兴趣点推荐都是至关重要的;2)三者的融合有助于提高推荐精度,这一点从GeoSoRev模型无论是在准确率还是召回率上都显著优于单独的3个要素可以看出.得出上述结论的原因在于:用户在实际生活中受到了多方面情景信息的影响,而不能片面地从某一个方面来对用户的偏好预测进行建模.因此兴趣点推荐应当充分利用各种兴趣点的情景信息,这也是解决兴趣点推荐中冷启动问题和数据稀疏问题的一个有效方法.
4.4.3参数分析
GeoSoRev模型有3个重要的参数:1)控制评论参数λ4;2)控制社交关系影响参数λ3;3)地理邻域关系加权参数α.研究分析这些参数时,通过改变其中一个参数的数值同时固定其他参数,来分析其对最终推荐结果的影响以及GeoSoRev模型对于参数的灵敏度问题.
1) 对邻域关系加权参数α进行分析,设置k=5,λ4=0.05,λ1=0.5,λ2=0.5,λ3=0.001.如图7(a)(b)显示了α基于2个数据集对于式(13)的影响.从图7(a)(b)可以看出:①α的取值范围在0.4~0.6之间时获得了比较好的效果,这说明α在衡量用户对于推荐的兴趣点的偏好和地理邻域特征方面的重要性;②α=0或者α=1都会导致推荐精度的下降.特别是α=0时,被认为不考虑地理邻域特征,由此造成了推荐精度的下降.
2) 当k=5,λ1=0.5,λ2=0.5,λ4=0.05时,社交信息参数λ3对整个模型的影响如图8(a)(b)所示.从图8(a)(b)得到如下结论:①当λ3=0.001时取得最好的推荐效果,但是当λ3=0时推荐精度会下降;②当λ3>1时,GeoSoRev模型表现稳定,没有因为λ3的变化而变得敏感;③当λ3在0~1之间时,性能的波动不是很明显.因此,GeoSoRev模型对于λ3不是非常敏感,选择λ3=0.001作为默认值是合理的.
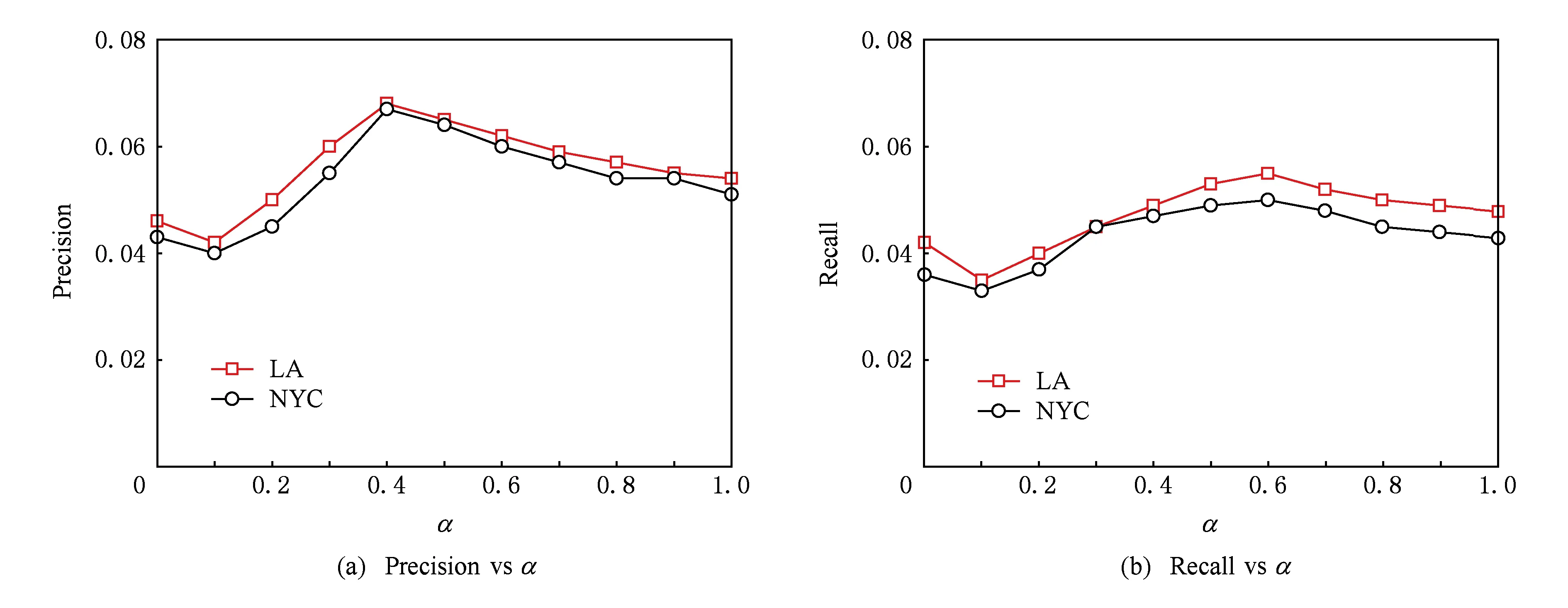
Fig. 7 Effect of parameter α on recommendation accuracy of GeoSoRev.图7 GeoSoRev模型对于参数α的分析
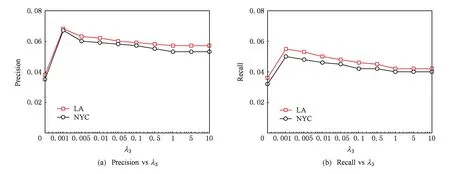
Fig. 8 Effect of sensitive parameter λ3 on recommendation accuracy of GeoSoRev.图8 GeoSoRev模型对于参数λ3的敏感度分析
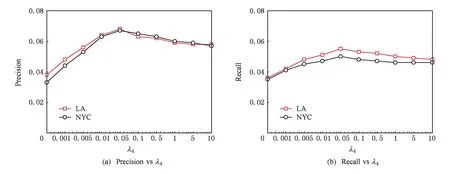
Fig. 9 Effect of sensitive parameter λ4 on recommendation accuracy of GeoSoRev.图9 GeoSoRev模型对于参数λ4的敏感度分析
3) 当k=5,λ1=0.5,λ2=0.5,λ3=0.001时,评论关系参数λ4对整个模型的影响如图9(a)(b)所示.如图9(a)(b)所示,当λ4=0.05时,GeoSoRev模型在准确率和召回率上取得比较好的效果;但是当λ4>1时,GeoSoRev模型表现相对比较稳定,没有因为λ4的变化而变得敏感;当λ4在0~1之间时性能波动不是很明显.因此,GeoSoRev模型对于λ4不是很敏感而是比较稳定的,而λ4=0.05作为默认值是合理的.这主要因为在一篇评论中用户可能只提到了部分潜在因素而不是所有的因素.
5结论与展望
如何将用户的多种情景信息和用户的评论信息等多种异构数据应用到兴趣点推荐问题中对于传统的推荐系统而言是一个挑战.本文提出一种新的推荐模型GeoSoRev,该模型将3种异构多源的信息进行融合并有效地进行推荐.GeoSoRev较好地解决了基于位置社交网络研究中利用情景信息和评论内容进行兴趣点推荐的问题.其最大的优势和创新点在于将用户签到信息、社会影响、地理影响、情感影响等多个方面的影响因素都融合到一个统一的模型中,这也是一个全新的工作.真实数据集的实验结果表明,GeoSoRev模型相对于其他的主流推荐模型在准确率和召回率2个评估指标上有着明显的提高.
近年来,深度神经网络(即深度学习)已经被用来学习各种情景信息和文本内容,从而被应用到推荐问题中.因此,未来将深度学习技术融入到GeoSoRev模型中是一个非常有价值的研究问题.
参考文献
[1]Wang Yuanzhuo, Jin Xiaolong, Chen Xueqi. Network big data: Present and future[J]. Chinese Journal of Computers, 2013, 36(6): 1125-1138 (in Chinese)(王元卓,靳小龙,程学旗,网络大数据: 现状与展望[J]. 计算机学报, 2013, 36(6): 1125-1138
[2]Ding Zhaoyun, Jia Yan, Zhou Bin. Survey of data mining for microblogs[J]. Journal of Computer Research and Development, 2014, 51(4): 691-706 (in Chinese)(丁兆云, 贾焰, 周斌. 微博数据挖掘研究综述[J]. 计算机研究与发展, 2014, 51(4): 691-706)
[3]Liu X, Liu Y, Aberer K, et al. Personalized point-of-interest recommendation by mining users’ preference transition[C] //Proc of the 22nd ACM Conf on Information and Konwledge Management (CIKM’13). New York: ACM, 2013: 733-738
[4]Wu L, Chen E H, Liu Q, et al. Leveraging tagging for neighborhood-aware probabilistic matrix factorization[C] //Proc of the 21st ACM Conf on Information and Knowledge Management (CIKM’12). New York: ACM, 2012: 1854-1858
[5]Li X T, Cong G. Rank-GeoFM: A ranking based geographical factorization method for point of interest recommendation[C] //Proc of the 38th Int ACM SIGIR Conf on Research on Development in Information Retrieval(SIGIR’15). New York: ACM, 2015: 433-442
[6]Yuan Q, Cong G, Ma Z, et al. Time-aware point-of-interest recommendation[C] //Proc of the 36th Int ACM SIGIR Conf on Research and Development in Information Retrieval(SIGIR’13). New York: ACM, 2013: 363-372
[7]Liu B, Xiong H. A general geographical probabilistic factor model for point of interest recommendation[J]. IEEE Trans on Knowledge and Data Engineering, 2015, 27(5): 1167-1179
[8]Jamali M, Ester M. A matrix factorization technique with trust propagation for recommendation in social networks[C] //Proc of the 4th ACM Conf on Recommender Systems(RecSys’10). New York: ACM, 2010: 135-142
[9]Gao H J, Tang J L, Hu X, et al. Content-aware point of interest recommendation on location-based social networks[C] //Proc of the 29th AAAI Conf on Artificial Intelligence(AAAI’15). Menlo Park, CA: AAAI, 2015: 336-350
[10]Ference G, Ye M. Location recommendation for out-of-town users in location-based social networks[C] //Proc of the 22nd ACM Conf on Information and Knowledge Management(CIKM’13). New York: ACM, 2013: 721-726
[11]Cheng C, Yang H Q, King I, et al. Fused matrix factorization with geographical and social influence in location-based social networks[C]//Proc of the 26th AAAI Conf on Artificial Intelligence(AAAI’12). Menlo Park, CA: AAAI, 2012: 211-276
[12]Lian D F, Zhao C, Xie X, et al. GeoMF: Joint geographical modeling and matrix factorization for point-of-interest recommendation[C] //Proc of the 20th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining (KDD’14). New York: ACM, 2014: 831-840
[13]Cheng Z Y, Caverlee J, Lee K, et al. Exploring millions of footprints in location sharing services[C] //Proc of the 5th Int Conf on Weblogs and Social Media(ICWSM’11). Menlo Park, CA: AAAI, 2011: 221-226
[14]Yin H Z, Cui B, Sun Y Z, et al. LCARS: A spatial item recommender system[J]. ACM Trans on Information Systems, 2014, 32(3): 111-1137
[15]Yin H Z, Sun Y Z, Cui B, et al. LCARS: A location-content-aware recommender system[C] //Proc of the 19th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining (KDD’13). New York: ACM, 2013: 221-229
[16]Koren Y, Bell R, Volinsky C. Matrix factorization techniques for recommender systems[J]. IEEE Computer Society, 2009, 42(8): 30-37
[17]Blei M D, Ng A Y, Jordan I M. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3(1): 993-1022
[18]Cai D, Mei Q, Han J W, et al. Modeling hidden topics on document manifold[C] //Proc of the 17th ACM Conf on Information and Knowledge Management(CIKM’08). New York: ACM, 2008: 911-920
[19]Bao Y, Fang H, Zhang J. TopicMF: Simultaneously exploiting ratings and reviews for recommendation[C] //Proc of the 28th AAAI Conf on Artificial Intelligence (AAAI’14). Menlo Park, CA: AAAI, 2014: 236-250
[20]McAuley J, Leskovec J. Hidden factors and hidden topics understanding rating dimensions with review text[C] //Proc of the 7th ACM Conf on Recommender Systems (RecSys’13). New York: ACM, 2013: 165-172
[21]Liu Y, Wei W, Sun A X, et al. Exploiting geographical neighborhood characteristics for location recommendation[C] //Proc of the 23rd ACM Conf on Information and Knowledge Management(CIKM’14). New York: ACM, 2014: 739-748
[22]Ma H, Zhou D Y. Recommender systems with social regularization[C] //Proc of the 4th Int ACM Conf on Web Search and Data Mining (WSDM’11). New York: ACM, 2011: 287-296
[23]Koren Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model[C] //Proc of the 14th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining (KDD’08). New York: ACM, 2008: 426-434
[24]Nocedal J. Updating quasi-newton matrixes with limited storage[J]. Mathematics of Computation, 1980, 35(151): 773-782
[25]Lin C J. Projected gradient methods for nonnegative matrix factorization[J]. Neural Computation, 2007, 19(10): 2756-2779
[26]Bao J, Zheng Y, Mokbel M F, et al. Location-based and preference-aware recommendation using sparse geo-social networking data[C] //Proc of the 20th Int ACM Conf on Advances in Geographic Information Systems (SIGSPATIAL’12). New York: ACM, 2012: 199-208
[27]Zhang J D, Chow C Y. CoRe: Exploiting the personalized influence of two-dimensional geographic coordinates for location recommendation[J]. Information Science, 2015, 29(1): 163-181
[28]Ye M, Yin P, Lee W C, et al. Exploiting geographical influence for collaborative point-of-interest recommendation[C] //Proc of the 34th Int ACM SIGIR Conf on Research and Development in Information Retrieval(SIGIR’11). New York: ACM, 2011: 325-334
[29]Yang D Q, Zhang D Q, Yu Z Y, et al. A sentiment-enhanced personalized location recommendation system[ C] //Proc of the 24th ACM Conf on Hypertext and Social Media (HT’13). New York: ACM, 2013: 119-128
[30]Ying J J C, Kuo W N, Tseng V S, et al. Mining user check-in behavior with a random walk for urban point-of-interest recommendations[J]. ACM Trans on Intelligent Systems and Technology, 2014, 5(3): 1-26
[31]Hu L K, Sun A X, Liu Y. Your neighbors affect your ratings: On geographical neighborhood influence to rating prediction[C] //Proc of the 37th Int ACM SIGIR Conf on Research and Development in Information Retrieval (SIGIR’14). New York: ACM, 2014: 345-354

Gao Rong, born in 1981. PhD candidate in Wuhan University. His main research interests include data mining and intelligent recommendation (gaorong198149@163.com).

Li Jing, born in 1967. Professor and PhD supervisor in Wuhan University. His current research interests include data mining and multimedia technology.

Du Bo, born in 1983. Associate professor and PhD supervisor in Wuhan University. His current research interests include data mining and pattern recognition(remoteking@whu.edu.cn).

Yu Yonghong, born in 1978. PhD and lecturer in Nanjing University. His current research interests include data mining and recommendation algorithm(yuyh@njupt.edu.cn).

Song Chengfang, born in 1978. PhD and lecturer in Wuhan University. His current research interests include visualization analysis and location service (songchf@whu.edu.cn).

Ding Yonggang, born in 1966. PhD and associate professor in Hubei University. Her current research interests include data mining and Web information retrieval (hddyg@hubu.edu.cn).
A Synthetic Recommendation Model for Point-of-Interest on Location-Based Social Networks: Exploiting Contextual Information and Review
Gao Rong1, Li Jing1, Du Bo1, Yu Yonghong2, Song Chengfang1, and Ding Yonggang1,3
1(ComputerSchool,WuhanUniversity,Wuhan430072)2(StateKeyLaboratoryforNovelSoftwareTechnology(NanjingUniversity),Nanjing210046)3(FacultyofEducation,HubeiUniversity,Wuhan430062)
AbstractWith the rapid growth of location-based social network (LBSN), point-of-interest (POI) recommendation has become an important mean to help people discover attractive locations. However, most of existing models of POI recommendation on LBSNs improve recommendation quality by exploiting the user check-in history behavior and contextual information(e.g., geographical information and social correlations), and they tend to ignore the review texts information accompanied with rating information for recommender models. While in reality, users only check in a few POIs in LBSN, which makes the user-POIs check-in history records and contextual information highly sparse, and causes a big challenge for POIs recommendations. To tackle this challenge, a novel POIs recommendation model called GeoSoRev is proposed in this paper, which combines users’ preference to a POI with geographical information, social correlations and reviews text on the basis of the classic recommendation model based on matrix factorization. Experimental results on two real-world datasets collected from Foursquare show that GeoSoRev achieves significantly superior precision and recalling rates compared with other state-of-the-art POIs recommendation models.
Key wordslocation recommendation; matrix factorization; social relationships; geographical information; review text
收稿日期:2015-12-01;修回日期:2016-02-03
基金项目:国家“九七三”重点基础研究发展计划基金项目(2012CB719905);国家自然科学基金青年项目(41201404);中央高校基本科研业务费专项资金(2042015gf0009)
通信作者:李晶(leejingcn@163.com)
中图法分类号TP311
DOI:计算机研究与发展10.7544issn1000-1239.2016.20151079 Journal of Computer Research and Development53(4): 764-775, 2016
This work was supported by the National Basic Research Program of China (973 Program) (2012CB719905), the National Natural Science Foundation (41201404), and the Fundamental Research Funds for the Central Universities (2042015gf0009).
