二次改进遗传算法与3DNoC低功耗映射
2016-06-30张大坤宋国治林华洲任淑霞
张大坤 宋国治 林华洲 任淑霞
(天津工业大学计算机科学与软件学院 天津 300387)(Zhandakun2013@163.com)
二次改进遗传算法与3DNoC低功耗映射
张大坤宋国治林华洲任淑霞
(天津工业大学计算机科学与软件学院天津300387)(Zhandakun2013@163.com)
摘要随着集成电路技术的迅速发展,芯片的集成度不断提高,片上众多处理单元间的高效互连成为关键问题,因而相继出现了片上系统(system-on-chip, SoC)和二维片上网络(two-dimensional network-on-chip, 2D NoC).当二维片上网络在多方面达到瓶颈时,三维片上网络(three-dimensional network-on-chip, 3D NoC)应运而生.三维片上网络已引起学术界和产业界的高度重视,三维片上网络低功耗映射是其中的1个关键问题.之前的研究曾提出过一种基于改进遗传算法的3D NoC低功耗映射算法,并收到了良好的仿真效果.但当问题规模变大时,计算量随之增大、运行效率明显降低.针对这一问题,对3D NoC中面向功耗优化的二次改进遗传算法任务映射机制进行研究,提出了一种新的3D NoC低功耗映射算法,并对该映射算法进行了仿真实验.实验结果表明,在种群规模较大的条件下,该算法不仅能够继续降低功耗,而且能够大幅度地减少映射算法的运行时间.
关键词三维片上网络;低功耗映射;改进遗传算法;二次改进遗传算法;贪心算法
1958年世界诞生了第1个集成电路,随着集成电路规模的不断增大,片上系统(system-on-chip,SoC)应运而生,而且SoC的处理单元(processingelements,PE)数不断增加,为高效地连接数量巨大的PE,产生了二维片上网络(two-dimensionalnetwork-on-chip, 2DNoC)这种主流的片上互连架构.而2DNoC在面积、功耗、布局布线以及封装密度等方面都已达到了瓶颈,三维片上网络(three-dimensionalnetwork-on-chip, 3DNoC)应运而生.自2005年第1篇以3DNoC为主题的学术论文发表以来[1],3DNoC以其更短的全局互连、更高的性能、更低的互连损耗、更高的封装密度以及更小的体积等诸多优势成为1个重要的研究方向[2-3].降低功耗是3DNoC所面临的1个关键问题,从多种途径降低3DNoC的功耗非常必要.映射决定知识产权(intellectualproperty,IP)核在3DNoC上的位置,通过改进映射算法能够有效地降低3DNoC的功耗.因此,3DNoC低功耗映射已逐渐成为3DNoC领域的研究热点.3DNoC映射问题和任务调度问题相似,都是NP难解问题[4].有许多研究者尝试应用各种算法解决3DNoC映射问题,其中,美国宾夕法尼亚州立大学Charles[5]采用遗传算法研究了考虑到热感知和通信感知的3DNoC映射问题;南京大学王佳文[6-8]、汤普森河大学的Elmiligi等人[9]、航空电子系统综合技术重点实验室Ge等人[10]均尝试过采用遗传算法解决3DNoC映射问题,并取得了相应的研究成果.本文将对3DNoC中面向功耗优化的二次改进遗传算法任务映射机制进行研究.
13DNoC低功耗映射问题
1.1基本概念
3DNoC低功耗映射就是在给定通信轨迹图和拓扑结构图的基础上,研究如何将IP核映射到3DNoC的资源节点上,使得整个3DNoC的通信量最小,达到降低通信功耗的目的.为了描述3DNoC映射问题,给出如下定义:
定义1. 通信轨迹图CTG(N,C).设CTG(N,C)为有向图,其中N为顶点集,节点ni∈N表示1个IP核;C为边集,有向边ci j∈C表示节点ci到节点cj的边,wi j表示边ci j的权重.
定义2. 拓扑结构图TAG(T,E).设TAG(T,E)为有向图,其中,T为PE集合,ti∈T表示1个PE;E为边集,有向边ei j表示节点ti到节点tj的边[11-12].
1.23DNoC映射算法评估标准
目前尚没有一致公认的面向3DNoC映射问题的评估标准.3DNoC作为解决片上系统通信问题的解决方案.其中,网络吞吐量与平均延迟都是重要的性能指标;3DNoC映射算法的设计也应当考虑功耗问题,过高的功耗可能会对网络产生致命的影响;3DNoC的三维立体结构,会引发网络内部发热不均的问题,发热过高可能会导致整个网络的瘫痪;对于实时性要求相对高的应用,最大网络延时也应作为网络性能的重要指标.文献[13-14]提出了评价映射算法优劣的4个重要性能指标:
1) 平均网络延迟.3DNoC的出现主要是为了解决SoC内资源节点之间的通信问题,因此,平均网络延迟是衡量3DNoC设计质量的重要指标,平均网络延迟间接地决定了3DNoC的吞吐率.
2) 最大网络延迟.目前大多数针对3DNoC的延时模型都是平均延时模型,然而在出现拥塞的状况下,决定整个网络通信效率的往往是最大延迟,当最大延迟超过了其容错上限,将导致整个网络无法正常工作.因此,最大延迟也是3DNoC评估的重要指标.
3) 平均功耗.3DNoC在传递消息的过程中会发生能量的消耗,平均功耗能够反映3DNoC在传送数据时功耗性能.
4) 发热与负载均衡.3DNoC由于其结构特性,内部节点容易出现发热过高的情况,过热点的产生将影响整个芯片的性能.过热点区域位于网络边缘容易散热,可以降低过热点区域对整个网络性能的影响.因此,在网络设计时尽可能地将过热点区域分散到网络边缘.
1.33DNoC功耗模型
1.3.13DNoC功耗计算公式
3DNoC中的功耗主要来自2方面:路由节点上的功耗和链路上的功耗.路由节点上的功耗主要是路由节点内部存储、交换、路由内部连线和路由选择所产生的能耗;链路上的功耗指的是路由数据经过路由节点之间链路时所产生的能耗.文献[11]给出了3DNoC的功耗模型,节点ti发送1个微片(flit)到节点tj消耗的能量表示为
(1)
其中,μ表示节点ti到节点tj经过的路由器个数,μH和μV分别是节点ti到节点tj经过的水平方向和垂直方向的边数(跳步),ERbit表示1个微片通过 1个路由器时所消耗的能量,ELHbit和ELVbit分别表示1个微片通过1条水平方向和垂直方向的线路时的耗能.文献[14]给出的ELHbit和ELVbit的计算公式为
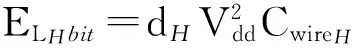
(2)

(3)
其中,dH和dV分别表示水平方向和垂直方向线路的长度,Vdd表示供电电压,CwireH和CwireV分别表示水平方向和垂直方向线路的电容.
1.3.2映射目标函数
3DNoC映射就是寻找IP核与PE的1个对应关系.在给定通信轨迹图CTG和拓扑结构图TAG的条件下寻找1个映射函数M(·):N→T,使得总功耗最低(用Emin表示),其目标函数如下:
(4)
且满足条件:

(5)
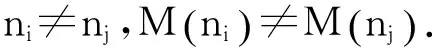
(6)
对于确定的拓扑结构,ERbit,ELHbit和ELVbit是确定的.由文献[11]可知,线路上的功耗与线路的长度成正比,所以,2个通信节点之间的线路长度是影响3DNoC功耗的关键要素.由于硅穿孔(throughsiliconvia,TSV)技术的出现,3DNoC在垂直方向的线路长度远远小于水平方向的长度,因此,传输同样的数据量,在垂直方向的功耗远远小于水平方向的功耗.
2基于改进遗传算法的3DNoC低功耗映射
本文作者曾对3DNoC映射问题进行了研究,提出一种基于改进遗传算法(improvedgeneticalgorithm,IGA)的3DNoC低功耗映射算法(简称IG映射算法)[15],现对其进行简单回顾.
2.1问题简介
如引言所述,用遗传算法解决3DNoC映射问题已取得一些研究成果[5-11],从映射出发降低3DNoC功耗是1个有效的途径.遗传算法根据问题的目标函数构造1个适应值函数,产生由多个解构成的初始种群,根据适应值的优劣选择种群中的个体进行遗传操作产生新的种群,当进化达到终止条件后,选择适应值好的个体作为问题的解.算法的实现主要分为如下5个步骤:
算法1. 遗传算法.
Step1. 遗传算法在运行之前要将解空间的数据表示成算法运行时可用的基因数据,由于每个IP核只能映射到1个PE上,因此,在映射问题中采用整数编码.
Step2. 随机产生1个初始种群,种群中每个个体都对应映射算法的1个解.
Step3. 根据问题的目标函数构造适应值函数,计算种群中每个个体的适应值.
Step4. 根据适应值的优劣不断地进行选择和繁殖操作,以得到下一代种群.
Step5. 达到终止条件后,选择适应值最好的个体作为算法的最终解.
基本遗传算法的初始种群是随机生成的,这使得初始种群存在个体分布不均匀、初始种群质量偏低的问题.作者提出的IG映射算法是将贪心算法与遗传算法相结合,用以解决3DNoC低功耗映射问题,相对于传统遗传算法具有更优的搜索能力.
2.2IG映射算法的核心思想
IG映射算法是贪心算法与遗传算法的组合,即采用贪心算法生成初始种群的遗传算法,贪心算法思想主要体现在生成初始种群个体上.用贪心算法生成初始种群个体主要分为3个步骤:
算法2. 贪心算法.
Step1. 随机地将任务图中的1个节点(即IP核)映射到3DNoC的第1个位置(把所有IP核从1到N进行编号,N为任务图上IP核的个数,n代表任意1个IP核;把所有PE从1到M进行编号,M为3DNoC上PE的个数,m代表任意1个PE).
Step2. 分别计算将所有IP核集合中可用数字放入所有PE集可用位置后的适应值,用n,m,fit表示未使用数字n放入3DNoC的第m个位置使得适应值fit最大,将n,m,fit放入集合F中,从F中选择fit最大的3组,随机地从这3组中选择一组n,m,fit,将n放到3DNoC的第m个位置,把n从可用的IP核集合中删除,把m从3DNoC的可用位置集合中删除.
Step3. 重复Step2,直到没有未使用的数字(IP核集合为空),即任务图中的所有节点都已映射到3DNoC上.
生成初始种群后,采用遗传算法进行遗传操作,得到最优个体,然后用最优个体生成仿真器能够识别的通信模式文件,仿真器读取通信模式文件进行仿真得到映射功耗.仿真结果表明,IG映射算法可以有效地降低功耗,从总体趋势上看,随着处理单元数目的增加,功耗降低的幅度逐渐增大,在种群规模为200、处理单元为120的情况下,总功耗可降低14.42%[15].
3二次改进遗传算法与3DNoC低功耗映射研究
3.1问题的提出与算法描述
3.1.1问题的提出
2.2节中的IG映射算法是采用贪心算法生成初始种群中的每个个体,使初始种群的质量整体得到了提升,有效地降低了功耗.但该算法在生成初始种群时,单个个体生成的计算量较大,在确定1个IP核映射到3DNoC上时,会计算所有未映射到3DNoC上的IP核放到3DNoC上所有可用位的适应值,而且生成每个个体都要进行同样的运算,所以该算法在生成初始种群时运行效率明显低于基本遗传算法.针对这一问题,对3DNoC中面向功耗优化的二次改进遗传算法任务映射机制进行研究,提出了一种基于改进贪心算法和遗传算法的3DNoC低功耗映射策略,并称其为基于二次改进遗传算法(doubleimprovedgeneticalgorithm,I2G)的3DNoC低功耗映射算法并称之为I2G映射算法.
3.1.2I2G映射算法的核心思想
IG映射算法是用一般的贪心算法生成初始种群,而I2G映射算法则采用改进贪心算法生成初始种群.I2G映射算法中采用的改进贪心算法与IG映射算法中采用的贪心算法的区别在于:
1) 2.2节中贪心算法在Step1,随机地将1个IP核(用n表示)映射到3DNoC的第1个位置(数字n可重复出现),而改进贪心算法中在第1个位置上放置的IP核(n)不可重复出现(n=1,2,…,N).
2) 2.2节中贪心算法在Step2,是从集合F中找出3组fit最大的n,m,fit,随机地从中选1组,而改进贪心算法只选取fit值最大的1组n,m,fit,将n放到3DNoC的第m个位置,把n从可用的IP核集合中删除,把m从3DNoC的可用位置集合中删除;重复2)直到IP核集合为空,即表示生成了1个个体.
3) 2.2节中贪心算法可以生成任意多个个体,而改进贪心算法只能生成N个个体(N为任务图规模).因此,改进贪心算法会对所有已生成的个体进行变异操作生成一定数量的邻居个体,最后从所有生成的个体中选取一定数量的个体作为初始种群.
I2G映射算法的具体实现详见3.2.3节.
3.2种群个体向量表示与初始种群生成
3.2.1种群个体向量表示
由于每个PE都可以向其他任意1个PE发送数据,CTG中的IP核可以映射到任意1个可用的PE上.因此,在3DNoC映射中种群个体采用整数编码,假设个体X=(x1,x2,…,xn),n为CTG的IP核个数,xi为IP核编号,个体X的编码为1到n的1种排列,通过对编码进行解码即可得到1种映射方案.1个简单的16节点视频对象平面解码器芯片(videoobjectplanedecoder,VOPD)的通信轨迹图如图1所示[16],以此图为例来说明种群个体的向量表示.图1中箭头附近的数字表示节点间的通讯量,单位是MBps.
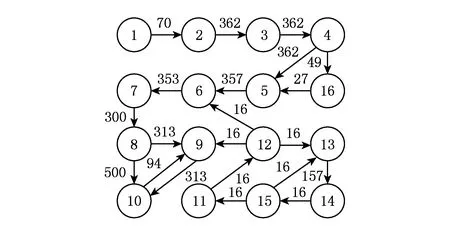
Fig. 1 VOPD communication trace diagram.图1 VOPD 通信轨迹图
VOPD中的IP核用数字1,2,…,16表示,将VOPD映射到2×3×3的3DNoC上,3DNoC上的每个PE用数字t1到t18表示,t1到t6表示第1层,t7到t12表示第2层,t13到t18表示第3层,如图2所示.个体X=(2,3,4,1,16,5,7,6,11,15,14,12,13,10,8,9),表示将IP核集(2,3,4,1,16,5,7,6,11,15,14,12,13,10,8,9)分别映射到处理单元t1到t16上,映射结果如图3所示.将所有IP核映射到3DNoC上之后,计算3DNoC上所有节点之间的通信总量,用遗传算法根据3DNoC上的通信总量计算其适应值,通信总量越大,适应值越小,用遗传算法根据适应值大小进行遗传操作.
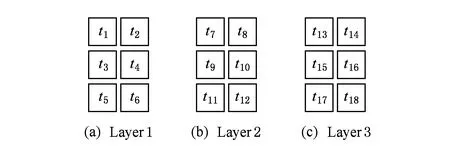
Fig. 2 3D NoC topological structure图2 3D NoC拓扑结构

Fig. 3 Mapping result图3 映射结果
3.2.2应用改进贪心算法生成初始种群
应用本文提出的改进贪心算法生成初始种群(Pop)的主要过程如下:
算法3. 改进贪心算法.
Step1. 将数字i放到个体X的第1个位置(i=1,2,…,N,当选取每个i后,重复Step2到Step5,每次循环都生成1个个体).
Step2. 初始化可用集合P={1,2,…,N},N为CTG的IP核个数,将i从可用集合P中删除.
Step3. 遍历可用集合P中的数字n,将n放入个体X的所有可用位置,计算放入这些位置后X的适应值,从这些适应值中找到最大的适应值fit,记下n放到使得X适应值最大的位置m,把n,m,fit存到集合F中.
Step4. 遍历集合F,找到fit值最大的1个元素n,m,fit,把n放到个体X的第m个位置,并把n从可用集合P中删除.
Step5. 重复Step3和Step4,直到可用集合P=∅,当P=∅时,表示产生了新个体X,把X加入临时种群tempPop中.
Step6. 重复上述Step5,生成N个个体.
Step7. 将个体X中的任意2个坐标数字交换(即变异操作),生成1个新个体Y,即X的邻居个体.用此方法生成20个X的邻居个体放入临时种群tempPop中.
Step8. 从临时种群tempPop中选取一定规模适应值最大的个体放入Pop中.
3.2.3I2G映射算法实现
1) 低功耗映射实现流程
算法4.I2G映射算法.
Step1. 采用改进贪心算法生成初始种群(详见3.2.2节).
Step2. 用遗传算法对初始种群进行进化操作,得到算法的最优解.
Step3. 根据最优解生成仿真平台能够识别的通信模式(trafficpattern)文件.
Step4. 仿真平台读取通信模式文件进行仿真,得到3DNoC低功耗映射仿真结果.
2) 通信模式文件的生成过程
算法5. 通信模式文件生成.
Step1. 将CTG(N,C)里的边集C,根据改进遗传算法得到最优个体X,转换成TAG的边集E.例如:最优个体X=(2,3,4,1,8,5,7,6),边c12,边c12的权重w12=100,映射到TAG上后得到边e41,边e41的权重w41=100.统计所有边的通信量之和wSum.
Step2. 生成随机数1≤r≤n,如果第r条边为e13,则在通信模式文件中写入1 3,如果通信量等于0,则循环查找下一条边,直到找到通信量大于0的边,在通信模式文件中写入该条边的信息,将该条边的通信量减1.
Step3. 重复Step2,直到所有边的通信量为0.
4仿真实验与结果分析
4.1仿真平台与参数设计
4.1.1仿真平台选择
仿真实验是在Ubuntu13操作系统下,采用C++语言编写算法的实现程序,在codeblocks12.11环境下,采用AccessNoxim0.2作为仿真软件进行映射算法的仿真(AccessNoxim0.2对主流的2DNoC仿真软件noxim进行了改进,改进后可以用于3DNoC的仿真实验).
4.1.2拓扑结构与路由选择
1) 拓扑结构的选择
3DMesh具有结构规则、布线简单、网络节点位置平等且在垂直方向互连采用TSV技术减小了总体布线长度等优点,实验中采用了3DMesh结构.
2) 路由选择
XYZ路由算法易于理解与实现,是主流的路由算法,实验中采用了该路由算法.
4.1.3参数设置
1) 算法的参数设置.种群规模为200,遗传迭代次数为100,交叉率为0.9,变异率为0.02.
2) 仿真软件的参数设置.数据包采用无记忆泊松分布(memorylessPoissondistribution)方式注入,数据包的注入率(packetinjectionrate)设为0.02;仿真软件统计循环5 000次的总功耗;数据包的大小介于2个微片到10个微片之间;路由器每个通道的缓存大小设为8个微片.
4.1.4硬件运行环境
整个仿真实验的硬件环境是:CPU为Intel®CoreTMi3-2120,主频为3.30GHz,内存为4GB的微型计算机.
4.2仿真实验结果分析
采用C++语言编写了基于IG映射算法[15]和基于I2G映射算法的3DNoC低功耗映射程序,在上述环境下进行了仿真实验.
4.2.1经典任务图的功耗对比
1) 针对VOPD的功耗对比
首先针对2个经典的通信轨迹图VOPD和DVOPD(doublevideoobjectplanedecoder)进行仿真实验.其中,VOPD中有16个节点,如图1所示,将VOPD映射到2×2×4的3DNoC上.仿真实验中,分别采用IG映射算法和I2G映射算法对该任务图进行映射操作,用得到的最优解生成通信模式文件,仿真器AccessNoxim通过读取通信模式文件进行映射仿真,得到映射功耗.用实验数据分别对2种映射算法得到的最小功耗、平均功耗和最大功耗进行了比较,如图4所示:
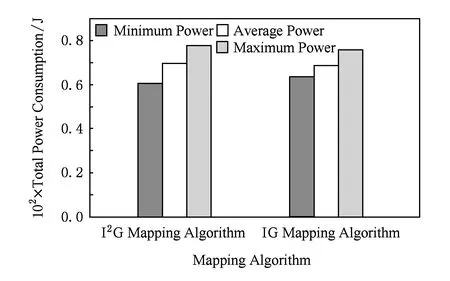
Fig. 4 Comparison of two mapping algorithms’ power consumption for VOPD.图4 针对VOPD的2种映射算法功耗对比
分析针对VOPD的2种映射算法仿真结果可见,在最低功耗方面I2G映射算法低于IG映射算法,即采用I2G映射算法的功耗更低,但是降低的幅度较小;而在平均功耗和最大功耗方面,I2G映射算法的功耗高于IG映射算法的功耗,I2G映射算法与IG映射算法的唯一区别就是生成初始种群时采用的贪心策略不同.对任务图分别进行实验,由实验结果可知:I2G映射算法与IG映射算法相比,最低功耗降低了2.02%、平均功耗增加了2.15%、最高功耗增加了1.54%.其中,I2G映射算法的功耗高于基于IG映射算法[16]的功耗,这是由于VOPD只有16个节点(节点过少),采用改进贪心策略得到的初始种群容易陷入局部最优.
2) 针对DVOPD的功耗对比
通信轨迹图DVOPD有32个节点,如图5所示[16],图5中箭头附近的数字表示节点间的通讯量,单位是MBps.实验中将DVOPD映射到2×2×4的3DNoC上,针对通信轨迹图DVOPD分别用2种映射算法进行了仿真实验.

Fig. 5 DVOPD task communication diagram.图5 DVOPD任务通信图
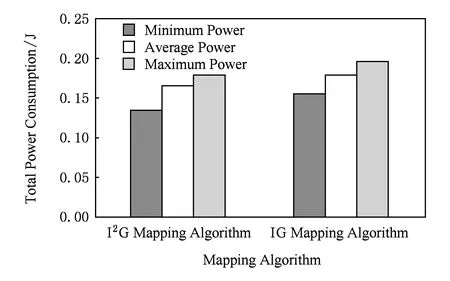
Fig. 6 Comparison of two mapping algorithms’ power consumption for DVOPD.图6 针对DVOPD的2种映射算法功耗对比
实验中对任务通信图DVOPD分别采用IG映射算法和I2G映射算法的仿真结果如图6所示.I2G映射算法得到的仿真结果明显优于IG映射算法的仿真结果:I2G映射算法与IG映射算法相比,最低功耗降低了13.37%、平均功耗降低了9.18%、最高功耗降低了7.48%.功耗降低显著,这是由于DVOPD有32个节点,任务规模较大,采用改进贪心策略得到的初始种群不容易陷入局部最优.由以上实验和分析可见,当任务图规模增大时,I2G映射算法的优势更为明显.
4.2.2经典任务图映射算法运行时间对比
IG映射算法和I2G映射算法的运行时间对比如图7所示.由图7可见,I2G映射算法的运行时间明显少于IG映射算法的运行时间.对于VOPD,由于任务图规模较小,生成每个个体所用的时间较短,因此I2G算法的运行时间减少幅度较小,比IG映射算法减少了19.11%(I2G映射算法的运行时间为3.619s、IG映射算法的运行时间为4.474s);而对于DVOPD,I2G映射算法的运行时间比IG映射算法的运行时间[15]减少幅度增大、减少了68.90%(I2G映射算法的运行时间为5.444s、IG映射算法的运行时间为17.503s).

Fig. 7 Comparison of two mapping algorithms’ running time.图7 2种映射算法运行时间对比
4.2.3200种群规模下随机任务图的功耗对比
1) 仿真实验数据
采用任务生成器TGFF[17]生成随机任务图,针对不同IP核数的CTG、种群规模为200时,分别采用IG映射算法和I2G映射算法求解10次,得到的功耗如表1和表2所示(对仿真实验数据从低到高进行了排序).

Table 1 Experimental Results of Ten Simulation for IG Mapping Algorithm
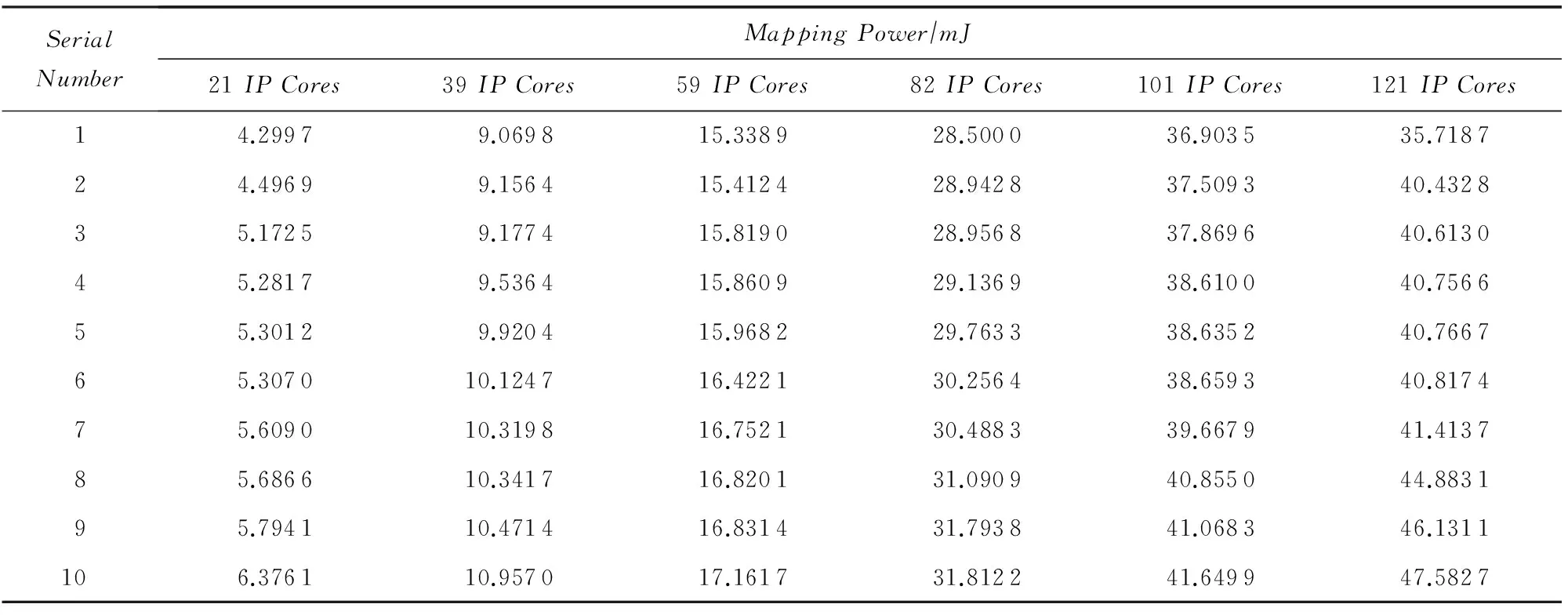
Table 2 Experimental Results of Ten Simulation for I2G Mapping Algorithm
2) 最低功耗比较
当IP核数较少时,I2G映射算法相对于IG映射算法的最低功耗降低幅度较小,在10%以内.其中,21个IP核时,I2G映射算法比IG映射算法的功耗低了17.46%,这是由于IP核数目较少,容易导致2种算法均陷入局部最优,因此出现了在21个IP核时I2G映射算法的功耗降低幅度较大.从整体趋势来看,随着IP核数的增加,功耗降低幅度增加,如图8所示.当IP核数为121时,I2G映射算法比IG映射算法功耗降低了22.64%.
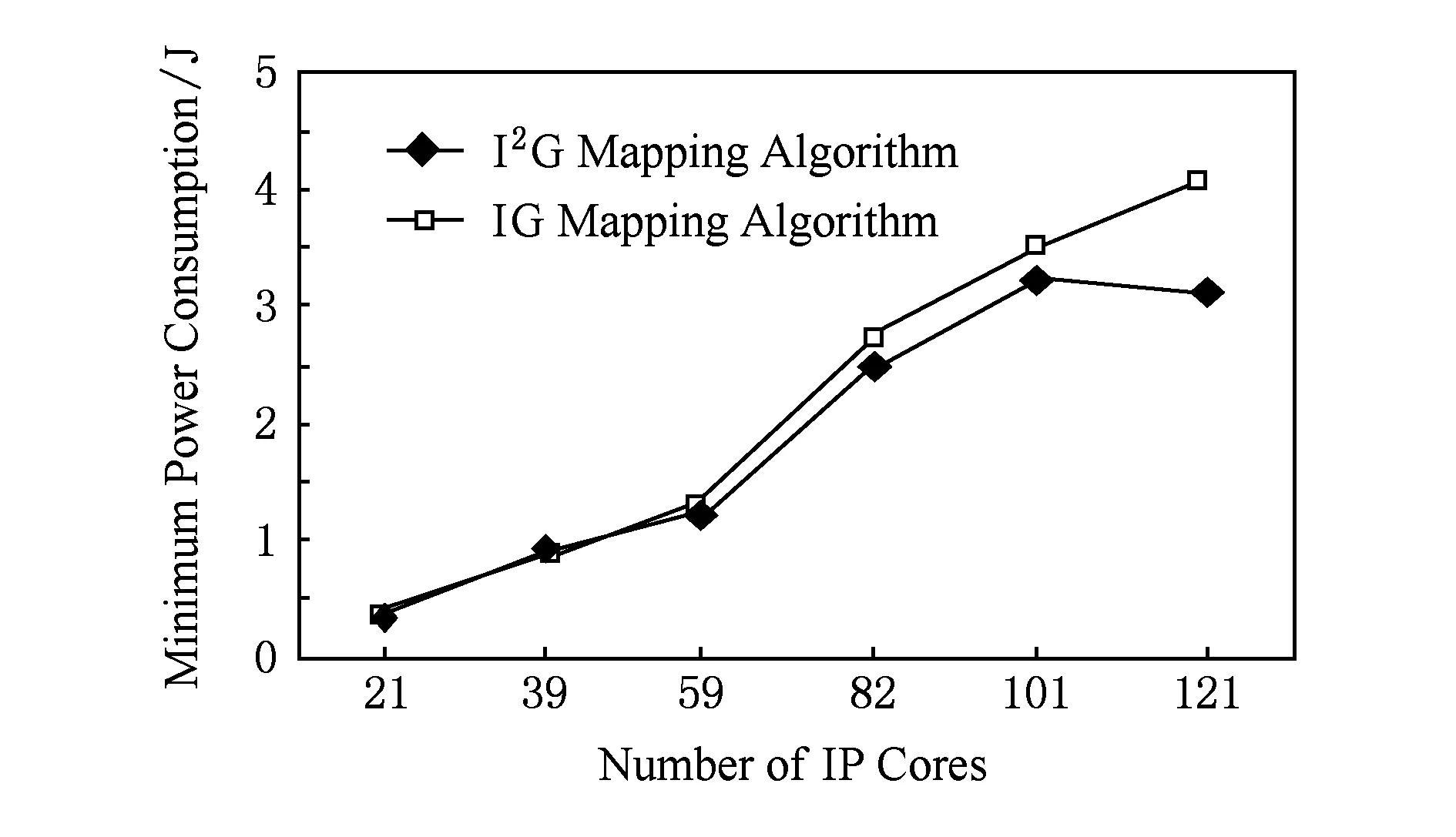
Fig. 8 Comparison of two mapping algorithms’ minimum power consumption.图8 2种映射算法最低功耗对比
3) 最高功耗对比
当IP核个数为21时,I2G映射算法相对于IG映射算法最高功耗降低了17.40%.当IP核个数为82时,I2G映射算法比IG映射算法的最高功耗降低了19.25%(为所做实验的最大降低幅度),如图9所示.当IP核数为121时,I2G映射算法相比IG映射算法最高功耗降低了13.95%.
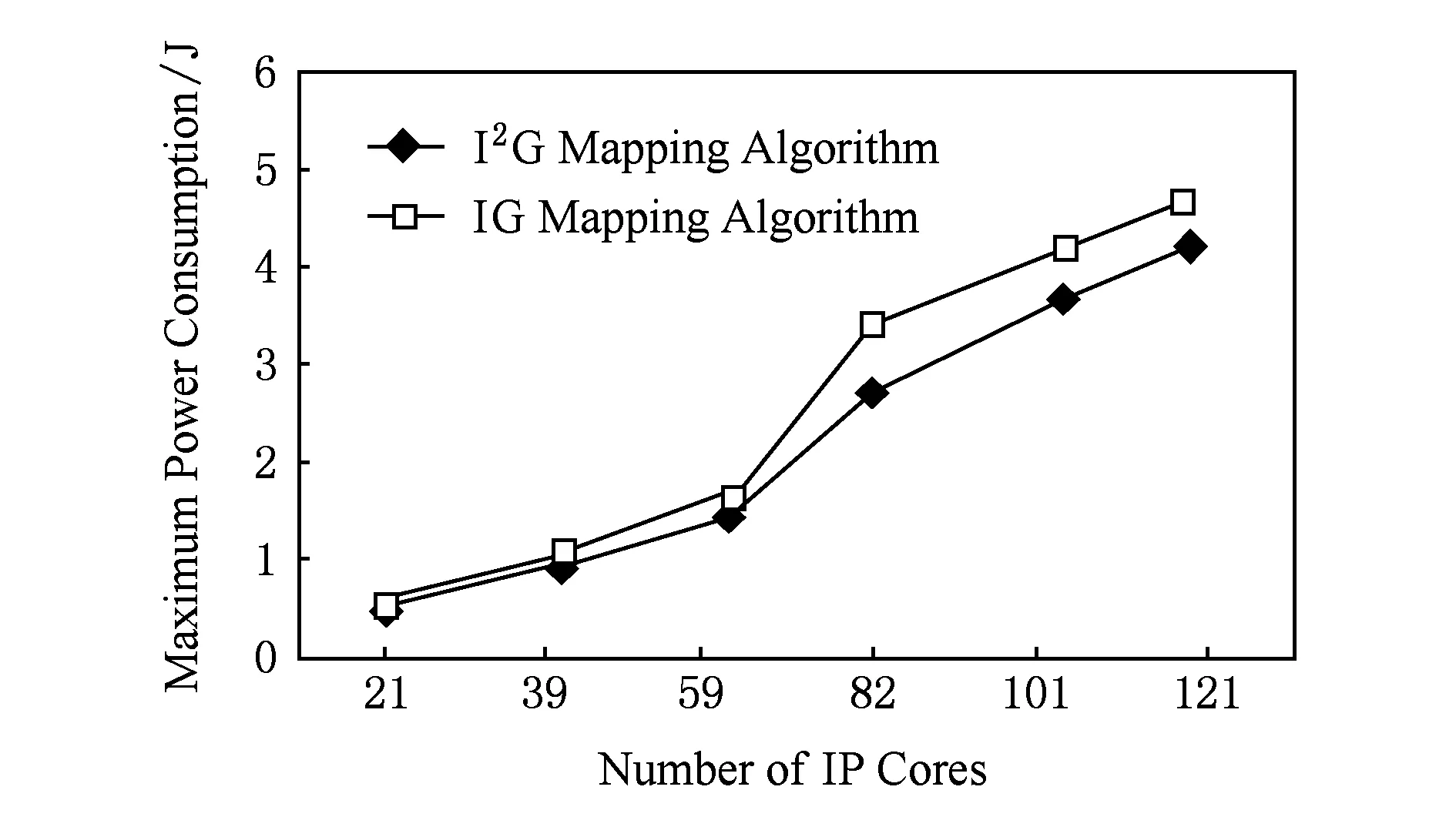
Fig. 9 Comparison of two mapping algorithms’ maximum power consumption.图9 2种映射算法最高功耗对比
4) 平均功耗对比
当IP核数为21时,I2G映射算法比IG映射算法平均功耗降低了14.85%;当IP核数为82时,I2G映射算法比IG映射算法平均功耗降低了13.61%;当IP核数为121时,I2G映射算法相比IG映射算法平均功耗降低了17.18%(为所做实验的最大值),如图10所示:
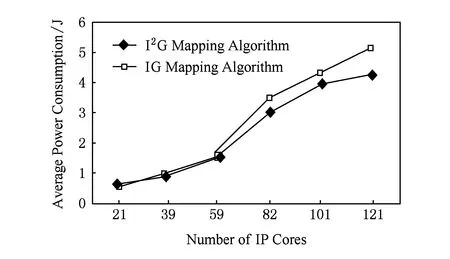
Fig. 10 Comparison of two mapping algorithms’ average power consumption.图10 2种映射算法平均功耗对比
4.2.4种群规模200随机任务图运行时间对比
种群规模为200时2种映射算法的运行时间对比如图11所示.由图11可见,I2G映射算法比IG映射算法的运行时间显著减少;当IP核数为59时,I2G映射算法比IG映射算法的运行时间减少了74.05%.
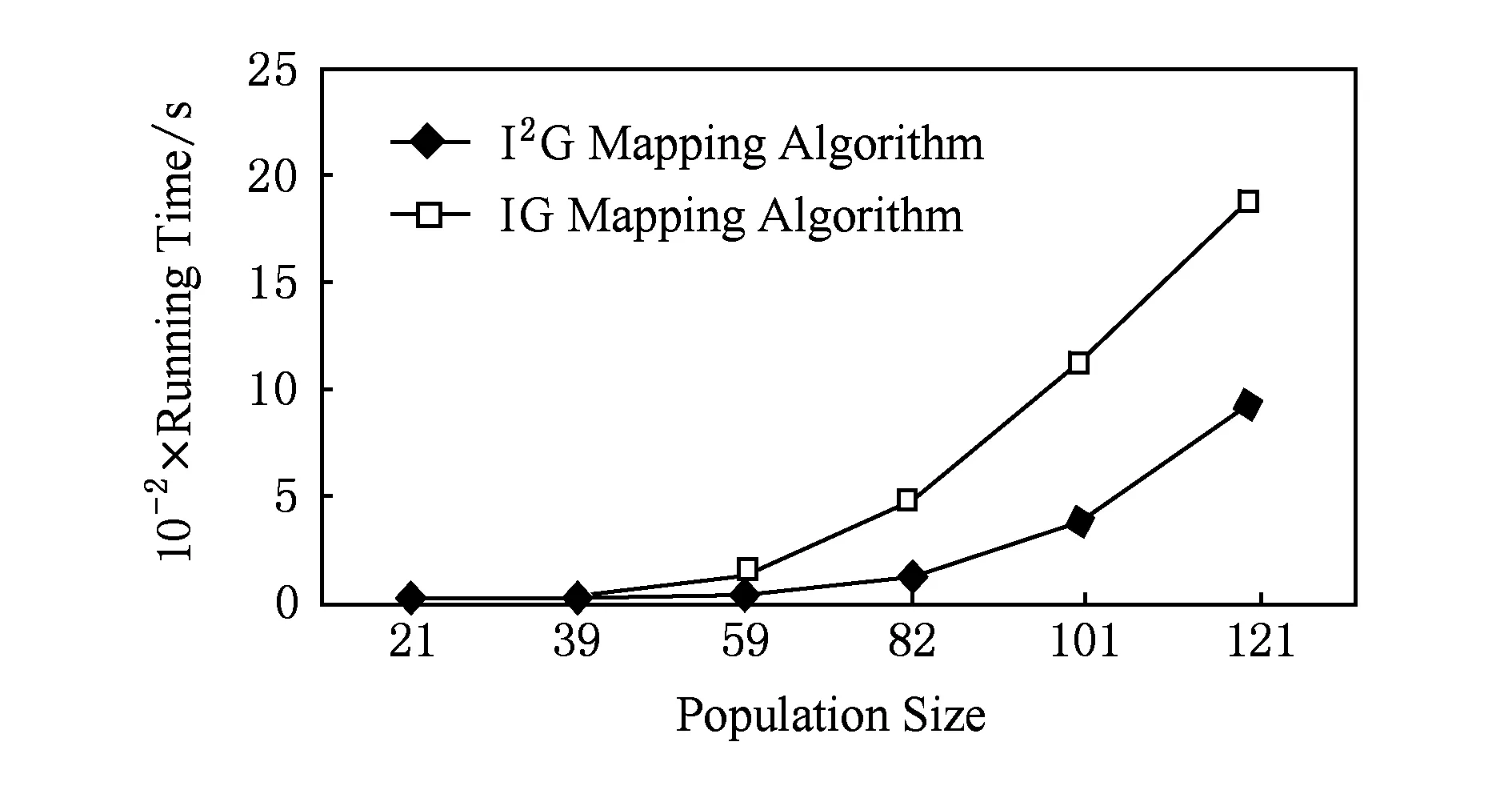
Fig. 11 Comparison of two mapping algorithms’ running time with a population size of 200.图11 种群规模为200的2种映射算法运行时间对比
4.2.5300种群规模随机任务图功耗与时间对比
1) 2种映射算法功耗对比
种群规模为300时,2种映射算法平均功耗的比较如图12所示.IP核数为121时,I2G映射算法比IG映射算法的功耗降低了13.48%.
2) 2种映射算法运行时间对比
种群规模为300时I2G映射算法与IG映射算法运行时间对比如图13所示.IP核数为121时,I2G映射算法比IG映射算法的运行时间减少了85.56%.
4.2.6随机任务图不同种群规模下运行时间对比
2种映射算法在IP核数为82时,种群规模不同时的运行时间对比如图14所示.当种群规模为600时,I2G映射算法比IG映射算法运行时间减少了89.98%(此时功耗降低16.36%).随着种群规模的增大,I2G映射算法的运行时间比IG映射算法的运行时间减少幅度逐渐增大;随着种群规模的增加,IG映射算法的运行时间大幅度增加,而I2G映射算法的运行时间变动幅度很小(这是由于I2G映射算法采用了改进贪心策略生成初始种群,因此,种群规模对映射算法的运行时间影响很小).

Fig. 12 Comparison of two mapping algorithms’ average power consumption with a population size of 300.图12 种群规模为300时2种映射算法平均功耗对比
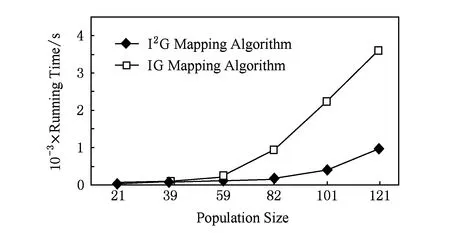
Fig. 13 Comparison of two mapping algorithms’ average power consumption with a population size of 300.图13 种群规模为300时2种映射算法平均功耗对比
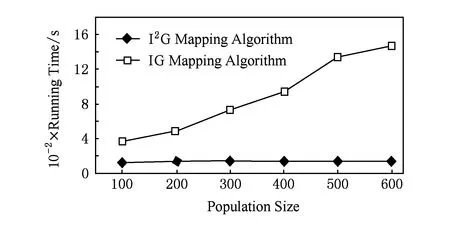
Fig. 14 Comparison of two mapping algorithms’s running time with different population sizes and 82 IP cores.图14 IP核数82时不同种群规模2种映射算法运行时间对比
4.2.7映射算法收敛速度对比
针对VOPD的收敛速度对比如图15所示,从迭代开始IG映射算法得到的适应值要远远大于基本遗传算法和I2G映射算法,而且在之后的进化过程中,IG映射算法得到的适应值变化很小,这说明在任务图规模较小时,IG映射算法容易陷入局部最优.

Fig. 15 Convergence speed for two VOPD mapping algorithms.图15 针对VOPD的2种映射算法的收敛速度对比
针对DVOPD在100次的迭代过程中收敛速度对比如图16所示,基本遗传算法的收敛速度比较慢,最终得到的适应值要小于另外2种映射算法;IG映射算法的收敛速度比基本遗传算法快,但是比I2G映射算法慢;I2G映射算法在算法运行初期得到的最大适应值要比IG映射算法小,而算法运行后期I2G映射算法收敛速度更快,而且得到的适应值更大.
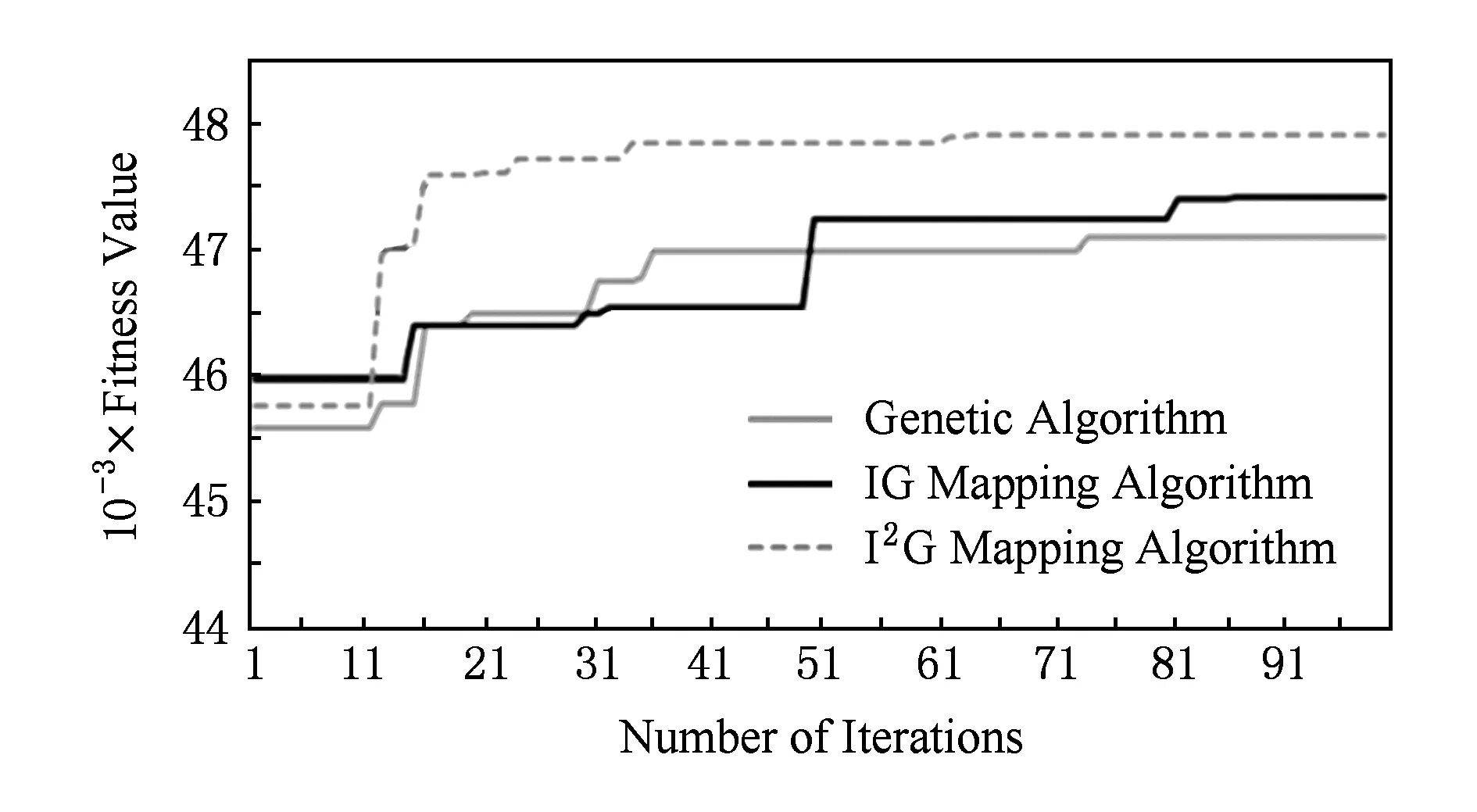
Fig. 16 Convergence speed for two DVOPD mapping algorithms.图16 针对DVOPD的2种映射算法的收敛速度对比
5结论与展望
5.1结论
针对IG映射算法运行时间较长的问题,本文提出了基于I2G算法的3DNoC低功耗映射算法(简称I2G映射算法).仿真结果表明,随着种群规模的增大,I2G映射算法在功耗继续保持降低的前提下,运行时间大幅度地减少.特别是,当IP核数为82、种群规模为600时,I2G映射算法与IG映射算法相比,平均功耗降低了16.36%,运行时间减少了89.98%.仿真实验表明,本文所提出的I2G映射算法效果显著.
5.2展望
1) 本文采用XYZ路由算法进行了I2G映射算法的仿真实验,在今后的研究中将对动态路由策略下的映射问题进行研究.
2) 发热是3DNoC设计中需要考虑的重要问题,随着研究的深入,我们将在映射算法研究中加入发热等方面因素的考虑.
3) 随着专用3DNoC需求的增多,出现了许多异构3DNoC架构,例如基于异构布局、位移交换和基于树图的3DNoC架构. 目前,针对异构3DNoC架构的映射算法的研究还处于起步阶段,还有很大的发展空间. 在未来的研究中,可以充分利用异构特征,针对不同类型的任务通信图采用不同的映射算法来提高3DNoC的映射效率并降低系统的功耗.
4) 目前有一种映射方法是将任务图映射到子网络上,并将子网络用定位的方式在片上网络中找到相应大小的区域,最后将任务图映射到该区域. 采用这样的映射方式,多个任务的映射可同时进行. 但由于任务通信图与子网络上处理单元大小存在不一致性,往往造成子网络上处理单元的浪费。减少处理单元的浪费将是一个值得研究的课题.
参考文献
[1]LeeK,LeeSJ,KimD,etal.Networks-on-chipandnetworks-in-packageforhigh-performanceSoCplatforms[C] //Procofthe2005ConfonAsianSolid-StateCircuits.NewYork:ACM, 2005: 485-488
[2]PavlidisVF,FriedmanEG. 3-Dtopologiesfornetworks-on-chip[J].IEEETransonVeryLargeScaleIntegrationSystems, 2007, 15(10): 1081-1090
[3]DavisWR,WilsonJ,MickS,etal.Demystifying3DICs:Theprosandconsofgoingvertical[J].IEEEDesign&TestofComputers, 2005, 22(6): 498-510
[4]JohnsonDS,GareyM.ComputersandIntractability:AGuidetotheTheoryofNP-Completeness[M].SanFrancisco,CA:Freeman&Co, 1979
[5]CharlesAQ.Thermal-awaremappingandplacementfor3-DNoCdesigns[C] //Procofthe2005IntConfonSOC.NewYork:ACM, 2005: 25-28
[6]WangJiawen. 3DNockeytechnologyresearch[D].Nanjing:NanjingUniversity, 2012 (inChinese)(王佳文. 3DNoC关键技术研究[D]. 南京: 南京大学, 2012)
[7]WangJiawen,LiLi,WangZhongfeng,etal.Energy-efficientmappingfor3DNoCusinglogisticfunctionbasedadaptivegeneticalgorithms[J].ChineseJournalofElectronics, 2014, 23(2): 254-262
[8]WangJiawen,LiLi,HongBingpan,etal.Latency-awaremappingfor3DNoCusingrank-basedmulti-objectivegeneticalgorithm[C] //Procofthe2011ConfonASIC.NewYork:ACM, 2011: 413-416
[9]ElmiligiH,GebaliF,El-Kharashi,etal.Power-awaremappingfor3DNoCdesignsusinggeneticalgorithms[J].ProcediaComputerScience, 2014, 34: 538-543
[10]GeFen,FengGui,YuShuang,etal.Power-andthermal-awaremappingfor3Dnetwork-on-chip[J].InformationTechnologyJournal, 2013, 12(23): 7297-7304
[11]WangXiaohang,LiuPeng,YangMei,etal.Energyefficientrun-timeincrementalmappingfor3Dnetworks-on-chip[J].JournalofComputerScienceandTechnology, 2013, 28(1): 54-71
[12]ZhangZhen.Researchofmappingmethodsfor3D-mesh-orientedCMPnetworksonchip[D].Guangzhou:GuangdongUniversityofTechnology, 2012 (inChinese)(张振. 基于3D-MESH的CMP片上网络映射方法研究[D]. 广州: 广东工业大学, 2012)
[13]QianYue,LuZhonghai,DouQiang,etal.CommunicationperformanceanalysisoftheNoCsin2Dand3Darchitectures[J].ComputerEngineering&Science, 2011, 33(3): 34-40 (inChinese)(钱悦, 鲁中海, 窦强, 等. 片上网络二维和三维结构的通信性能分析[J]. 计算机工程与科学, 2011, 33(3): 34-40)
[14]MatsutaniH,KoibuchiM,AmanoH.Tightly-coupledmulti-layertopologiesfor3-DNoCs[C] //Procofthe2007ConfonParallelProcessing.NewYork:ACM, 2007: 75-79
[15]LinHuaZhou,ZhangDaKun,HuangCui.Researchonlow-powermappingforthree-dimensionalnetwork-on-chipbasedonimprovedgeneticalgorithm[J].ComputerEngineering&Application, 2016, 52(1): 81-88 (inChinese)(林华洲, 张大坤, 黄翠. 基于改进遗传算法的3DNoC低功耗映射研究[J]. 计算机工程与应用, 2016, 52(1): 81-88)
[16]PradipKS,SantanuC.Asurveyonapplicationmappingstrategiesfornetwork-on-chipdesign[J].JournalofSystemsArchitecture, 2013, 59(1): 60-76
[17]DickRP,RhodesDL,WolfW.TGFF:Taskgraphsforfree[C] //Procofthe1998ConfonHardware/SoftwareCodesign.NewYork:ACM, 1998: 97-101

ZhangDakun,bornin1960.ReceivedherPhDdegreeincomputertechnologyfromNortheasternUniversity.ProfessoratTianjinPolytechnicUniversity.Hermainresearchinterestsinclude3Dnetworks-on-chip,bigdatavisualizationanalysis,andvirtualreality.

SongGuozhi,bornin1977.ReceivedhisPhDdegreefromQueenMary,UniversityofLondon,UK.AssociateprofessoratTianjinPolytechnicUniversity.Hismainresearchinterestsinclude3Dnetworks-on-chip,heterogeneouswirelessnetworkintegration,andqueueingtheory(guozhi.song@gmail.com).

LinHuazhou,bornin1990.MScandidate.Hisresearchinterestsinclude3Dnetworks-on-chip(linhuazhou90@126.com).

RenShuxia,bornin1973.ReceivedherPhDdegreefromTianjinUniversity.Associateprofessor.Herresearchinterestsinclude3Dnetworks-on-chip,datamining,andbigdataanalysis(t_rsx@126.com).

2014年《计算机研究与发展》高被引论文TOP10
数据来源:中国知网,CSCD;统计日期:2016-02-16
DoubleImprovedGeneticAlgorithmandLowPowerTaskMappingin3DNetworks-on-Chip
ZhangDakun,SongGuozhi,LinHuazhou,andRenShuxia
(School of Computer Science & Software Engineering, Tianjin Polytechnic University, Tianjin 300387)
AbstractWith the rapid development of integrated circuit technology, the number of integrated components on a chip continues to increase. Efficient interconnection between the processing units on chip becomes a key issue. Therefore firstly system-on-chip (SoC) and then two-dimensional networks-on-chip (2D NoC) have been proposed to cope with this problem. But now even the 2D NoC has reached a bottleneck in many aspects, so the design of Three-Dimensional networks-on-chip (3D NoC) is inevitable. 3D NoC has attracted the attention of the researchers from both Academia and industry. One of the key issues of 3D NoC is low-power mapping. We have previously proposed a 3D NoC low-power mapping algorithm based on improved genetic algorithm with good results. But when the scale of the problem gets larger, the amount of calculation increases gradually and operation efficiency is reduced significantly. To solve this problem, this paper proposes a new 3D NoC task mapping algorithm with power optimization based on a double improved genetic algorithm, and the simulation experiments are conducted to validate the algorithm. The results show that under the conditions of a large population size, the 3D NoC task mapping algorithm cannot only reduce the power, but also reduce the running time significantly.
Key words3D network-on-chip (3D NoC); low-power mapping; improved genetic algorithm; double improved genetic algorithm; Greedy algorithm
收稿日期:2015-07-23;修回日期:2016-01-22
基金项目:国家自然科学基金项目(61272006)
中图法分类号TP391
ThisworkwassupportedbytheNationalNaturalScienceFoundationofChina(61272006).
