多模态演讲语篇评价意义的构建
——以《穹顶之下》为例
2016-06-29贺娟
贺 娟
(集美大学外国语学院,福建厦门 361021)
多模态演讲语篇评价意义的构建
——以《穹顶之下》为例
贺娟
(集美大学外国语学院,福建厦门 361021)
摘要:在多模态语篇中,语言、面部表情、手势动作和图像等符号资源共同参与评价意义的构建。以评价系统和视觉语法为理论框架,从语言资源和非语言资源两个方面对多模态演讲语篇——柴静《穹顶之下》的演讲视频进行评价意义分析。研究表明,适量的态度意义语言资源有利于在情感上与观众产生共鸣,介入意义和级差意义语言资源又补充和调整了态度意义,增强了说服力。非语言资源方面,镜头中说话人与观众之间的公众距离、拍摄视角、目光接触和面部表情、手势动作等符号都各自实现了符合演讲语篇的互动关系、介入程度和态度意义。最后进一步探讨了语言资源和非语言资源的评价意义存在叠加或互补关系。
关键词:多模态演讲语篇; 评价意义; 视觉语法
2015年,前央视记者柴静题为《穹顶之下——中国雾霾调查报告》[1](以下简称《穹顶之下》)的演讲视频,截止到2015年3月1日零点在国内各大视频网站的总点击量突破了3100万次[2]。该多模态语篇拥有如此强大的传播力,一方面,传播主体的名人效应和以社会热点问题作为传播内容能够吸引人们的注意力,尤其是网络用户;另一方面,它结合了声音、文字和图像等多种符号资源的动态传播方式,以及其中传递的态度、情感和互动关系产生更完整评价意义[3]196,叠加的情感效果倍增,有利于引导观众的价值立场。
近年来,越来越多的语言学工作者将目光投向了多模态交际(multimodal communication)和动态语篇(dynamic discourse),并且对广告、电影等语篇进行理论研究,进而建立起有效的分析框架,如Kress和Leeuwen的《视觉语法》、O’Halloran的《多模态语篇分析》等。他们将系统功能语言学中的概念、人际、语篇三大元功能的理论框架[4]应用于多模态语篇的研究和拓展,但是很少有研究者关注多模态语篇中多种符号资源评价意义的构建。本文以系统功能语言学中的评价系统和社会符号学的视觉语法为理论基础,采用实证分析法,考察了柴静2015年的演讲视频——《穹顶之下》中多种符号资源如何构建评价意义,调动观众的情感并进行协调联合,从语篇语义学和社会符号学的角度探讨多模态演讲语篇如何成功吸引观众、建立关系。
一、理论框架
评价系统是位于语篇语义层的人际意义体系之一[5]33,关注的是人们如何运用资源构建评价意义——即告诉读者、听众或观众自己的态度和感觉,达到协商社会关系或结成联盟的目的。评价意义系统由三个相互联系的意义子系统构成:态度(attitude)、介入(engagement)和级差(graduation)。态度意义包括情感(affect,个人感情)、判定(judgment,行为评判)和鉴赏(appreciation,事物评价)。介入意义和级差意义关注的是如何形成一致的价值立场和与读者、听众或观众进行联盟。介入子系统分为单声(monoglossia)和多声(heteroglossia)两种方式。级差子系统根据情感的强度或数量分为语势(force)的强化弱化程度和聚焦(focus)的柔化锐化程度两个量值。评价系统综述如图1所示。

图1评价系统综述[5]38
由于Martin的评价系统是以语言资源为基础的意义构建理论框架,而演讲视频语篇具有多模态性。除了语言之外,还有人物面部表情、手势动作、身体移动和以现场屏幕为载体的图像、视频等非语言资源参与语篇的意义生成。Martin认为,就人际意义而言,语言与图像之间的关系与评价意义紧密相连[6]321。因此有必要在评价意义的理论框架中引入视觉语法中非语言符号的互动意义理论。在研究图像中再现参与者(represented participants)和互动参与者(interactive participants)之间的互动意义时,Kress和Van Leeuwen建立了三个意义生成子系统(图2):接触(contact)、社会距离(social distance)和态度(attitude)。接触分为索取(demand)和提供(offer)两种意义,以图像中再现参与者是否正视(gaze)互动参与者为判断依据。参与者之间社会距离的亲疏由图像拍摄镜头的远近来决定。态度涉及到图像参与者的参与程度(involvement),参与者之间的权势关系(power)等意义,主要由取景角度(angle)来决定,分为水平或垂直角度和高于、平视或低于水平视线角度。
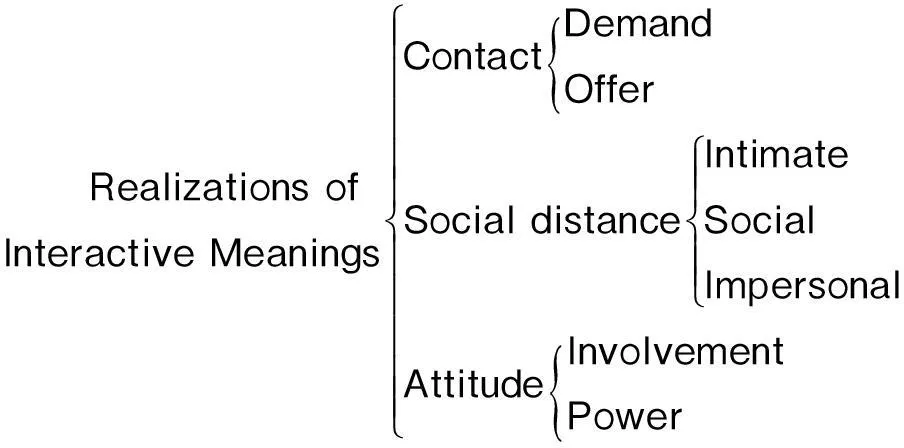
图2 视觉资源互动意义的实现[7]148
视觉语法中关于图像参与者之间互动意义的描写框架填补了评价系统中非语言符号意义生成的理论空白,对于多模态语篇中评价意义的互动关系和意义构建研究十分重要。近年来,Kress和Van Leeuwen也注意到电影、电视广告和新闻等语篇的动态性(dynamics)特点,并积极倡导视觉语法向多模态化语篇领域的拓展。在这方面,O’Halloran致力于以电影为主的多模态语篇的应用性研究[8],并结合社会符号学和认知心理学相关理论深入探讨电影是如何通过语言和非语言资源——如面部表情(facial expressions)、身体动向(body orientation)等——共同实现情感意义(emotive meaning)的构建[9-10]。
二、语篇分析
演讲视频语篇具有典型的多模态和动态特征。以《穹顶之下》为例,整个语篇长达104分钟,由演讲口头语言、说话人(柴静)的面部表情、手势动作、身体移动和以屏幕为载体的图片和视频等包含语言、声音和图像等多种模态资源构成。本文主要从语言资源和视觉资源两方面具体分析该语篇如何构建评价意义。
(一)语言资源的评价意义构建
1.态度意义
《穹顶之下》整个语篇从演讲结构上可以分为三个部分:第一部分(5分50秒之前)说话人用女儿患有肿瘤一事引出对其可能病因——雾霾产生调查念头;第二部分(从5分50秒到102分)是说话人对长达一年深入调查的记录和报告——雾霾是什么?它从哪里来?我们该怎么办?第三部分(最后两分钟)说话人以女儿康复为落脚点,讲述对洁净空气的期盼。从语言资源方面,从语篇中收集到的态度意义一共47个。其中情感类资源26个,判定类资源8个,鉴赏类资源13个。这些态度类的具体词汇见表1。

表1 多模态演讲语篇语言资源的态度意义分析
①其中“又凛冽又清新”统计为2个;“洁净美好的”统计为2个。
首先,从态度意义语言资源的数量来看,一共收集记录了48个。就一篇长达104分钟,平均语速约为300字/min左右的演讲语篇来说,态度意义的份量是微乎其微的。但是对于一个以调查报告为主要内容的演讲语篇来说,主观性的态度情感资源越少越好,这样才能体现出调查过程及其结论的客观性和可信度。
其次,从态度意义语言资源的种类来看,情感意义所占比例最大(55%)。情感是人们对某种行为、过程或现象在感情上作出的反应,有积极和消极之分。在这26个情感意义语言资源中,表达消极意义的有害怕、脆弱的、心酸、恐惧等,多出现在语篇的前半部分,描述的是说话人在得知女儿患病时的心理活动和采访时负面新闻带来的感受。表达积极意义的语言资源多出现在语篇的后半部分,如甜蜜、依恋、亲切、高兴等,描述的是说话人享受清新空气的心情和对洁净地球的美好憧憬。这种从消极意义逐渐向积极意义过渡的情感类语言资源在语篇中的布局,无形中让观众感受到说话人“立足现在,展望未来”的立场和愿望。
判定意义在态度意义语言资源中所占比例最小(17%)。判定是对人们行为的评估。语篇中的7个判定意义都是消极的,如蠢、狠、罪恶等,其中“严重的”出现了8次,“尴尬”出现了5次。这说明就中国雾霾现状和污染物排放行为语篇传递的态度是谴责的、批评的。说话人希望引起“同呼吸,共命运”观众的反应和共鸣。
鉴赏意义13个,占态度意义语言资源的28%。鉴赏是对过程、自然现象的评估。语篇中的鉴赏意义多是积极的,如清新、美妙、优雅等,流露着说话人对洁净空气和绿色地球的向往之情。而语篇中出现耸动的、可怕、严格等鉴赏意义又提醒着观众雾霾现状令人担忧。
2.介入意义
柴静的这个中国雾霾现状调查报告语篇,按她自己的话来说是一个“演讲”,而她本人是这个演讲的主讲人。因此从介入意义的方式来看,该语篇应该属于单声式介入,即说话人只提供一种价值立场,如“我眼睁睁的看着它成为现实。”根据统计,单声式介入占到整个语篇的40%左右,主要包括说话人自己的生活经历、采访经历和应对雾霾的过程和感受等。而多声式介入占到语篇的60%左右,主要有两种表现形式:一是通过说话人在现场的间接引语实现,如“世卫组织告诉我”、“清华的郝吉明博士告诉我说”等,所引用的内容一般是数据、结论等,一共66次。引用的信息源头多为NASA(美国航空航天局)、中科院、北京环保局、清华北大实验室和国家环保部等权威机构。
二是通过现场屏幕播放的采访视频和资料片等间接引用方式实现,只是说话人与所引用的内容之间没有通过传统的引用语形式出现。视频资源包括采访汽车企业负责人、群众4次,大气污染防治专家12次,医生2次,当地官员4次,环保部门26次;资料片7次,如伦敦治污、洛杉矶减排、中国大气污染现状等;还有两次采访音频和两个知识动画短片。向观众表明价值立场、争取联盟并建立一致关系是介入意义的根本所在。《穹顶之下》演讲语篇在形式上是以单声介入方式向观众汇报中国雾霾现状的调查报告,是“一场我与雾霾的私人恩怨”。实质上语篇中大量引用权威人士和机构的数据、结论的多声介入方式大大增强了说服力,多方采访和相关资料片的引用也确保了该调查报告语篇的客观性。
3.级差意义
级差意义是评价系统的中心[5]136。态度意义和介入意义在性质上都有等级之分。从《穹顶之下》语篇一共收集到二十余种级差意义的语言资源来看,其中大部分属于语势范畴的强化,如非常(幸运)、最(快)、一点儿、很(多)、越来越(大)等。这些级差意义对态度意义在程度上或数量上有增强效果,有利于说话人加强话语力度、强化评价功能,进而将观众拉入语篇的价值立场。而好像、不可能(很快)则属于聚焦范畴的柔化,这种安抚性的处理方式有利于拉拢潜在的持有不同立场的观众。具有级差意义的词汇见表2。

表2 多模态演讲语篇语言资源的级差意义分析
(二)视觉资源的评价意义构建
在《穹顶之下》中除了语言资源之外,还有两种非语言资源共同完成语篇评价意义的构建:镜头中的人物和以屏幕为载体的图表、数据、结论和音频视频资源。
1.镜头中的人物
在《穹顶之下》语篇中,出现在镜头里的人物有两种:讲台上站立的说话人柴静和坐在台下的百余名观众,分析以说话人为主。下面从接触意义(目光正视与否)、社会距离(镜头长短)和态度意义(表情手势、身体移动和拍摄角度)三方面分析评价意义如何通过人物镜头得以实现。
首先从接触意义来看,作为演讲人的柴静是语篇中的主要再现参与者。演讲的大多数时间她的目光投向台下的观众,即语篇中其他再现参与者。整个演讲过程她将目光正视镜头,即正面注视互动参与者——非现场观众的情况只有四次,且持续时间只有两三秒。说话人目光正视现场观众,是再现参与者之间的互动,表达的是索取意义,即说话人向现场观众寻求一种想象中的社会关系及回应,达到实现双方价值立场一致的目的。而说话人与非现场观众正视目光的缺失,表达的是提供意义,即说话人只负责信息传递,不从主观意愿上寻求共同价值立场,而是将非现场观众的注意力引向演讲呈现的具体内容。多模态演讲语篇的主要受众是非现场的众多网络用户,客观的传递知识和信息更加符合该语篇的主旨——一份对中国雾霾现状的调查报告。语篇中主观因素的尽可能减少和淡化实际上大大增强了内容的客观性和可信度。
其次从社会距离来看,社会关系决定交际中人们彼此间的距离[7]124。人与人之间保持的距离依赖于他们的社会关系。在《穹顶之下》语篇中,很多情况下人物是出现在长镜头(long shot)和中长镜头(medium long shot)中的,即说话人的全身或半身镜头占据着整个画面的二分之一或者更多空间。说话人的短镜头(close shot)即面部特写镜头相对较少,只有6次。这样的镜头处理方式使说话人与非现场观众之间形成了一种社会远距离(far social distance),是一种陌生的社会关系。即使讲台上的说话人与现场观众之间也保持着5米左右的公众距离(public distance)。远距离镜头中折射出的是再现参与者和互动参与者之间疏远的社会关系。
最后从态度意义来看,动态语篇中人物的面部表情、手势动作和身体移动直接表达了当时的情感和心理活动。微笑代表着说话人的泰然自若、坚定自信;开心的笑表达了对美好事物(如APEC蓝)的喜爱和憧憬;自嘲式的笑反映出对某些现象或事件(如某企业负责人为新闻报道而炸烟囱)的无奈与心酸。
演讲的同时,说话人大部分时间双手自然垂放于身体两侧或者平行叠放于身体前侧;身体时不时在讲台上向左右两侧移动。一旦有结论性的文字、数据或图表资源出现在她身后的大屏幕上,说话人的手会向外向上伸开,或者转向屏幕,有时候手也会指向屏幕上的内容,似乎在向观众发出邀请的信号,即参与这个雾霾的调查过程,成为共同的当事人和见证人。这些随着演讲内容变换的手势、动作可以看作是视觉资源的一种“语势”强化作用,有助于增强语言资源的强度和力度。
此外,说话人与观众之间视线角度的选择,也是一种“观点”,表达着主观的态度[7]129。面向观众时,说话人采取的是正面的(frontal)、自上而下的角度(top-down angle)或者水平视线的角度(eye-level angle),这是说话人最大限度参与语篇过程的体现。并且在参与者的权势关系中,说话人代表的是权势的一方。图3是视频中演讲画面的两幅截图。

图3 《穹顶之下》演讲语篇视频截图
2.以现场屏幕为载体的图表、数据、结论和音频视频资源
经统计,《穹顶之下》演讲语篇现场的屏幕一共播放图片118张,包括数据、文字性问题结论和相关知识等;照片72张,主要有调查采访时的记录照片和生活照片;曲线图、卫星地形分布图、表格和柱形图等共计图表35张。还有采访音频两个,采访和资料视频31个。技术基本上成为了符号学过程的一部分[7]217。这些在语篇过程中以现代技术为依托的非语言资源实际上以“间接引语”的介入方式参与了整个语篇评价意义的构建。多种符号资源的互动丰富了观众的听觉和视觉模态形式,使语篇的评价意义得以整合与扩展[11] 121-123。
三、结论
本文采用评价意义和视觉语法作为理论框架,以多模态演讲语篇《穹顶之下》为语料,从语言资源和非语言资源两个方面进行评价意义分析,得出以下结论:
a)语言资源方面,作为一篇调查报告性质的演讲,《穹顶之下》主讲人陈述了大量的数据、结论、事实、实验和采访等信息材料,为数不多的态度意义语言资源一方面直接表达了说话人对雾霾造成空气污染的消极情感、对排放大气污染物行为的批判谴责以及对洁净空气和美好地球的赞美期盼;另一方面适当的态度意义穿插于各种客观事实和信息之间,起到了穿针引线的作用,及时引导观众在接收信息的同时投入相应的态度和价值。演讲语篇的最终目的是说服和劝告[5]225。在提供客观信息的同时,一定的态度意义语言资源有利于在情感上引起观众的共鸣和回应。此外,表达介入意义和级差意义的语言资源能有效地增强说服力、争取和观众联盟以及强化评价意义。
b)视觉资源方面,说话人目光正视现场观众,表达了寻求回应和互动的索取意义;而正视镜头的目光缺失,则表达的是提供意义——众多非现场观众是负责信息接收的一方。镜头中说话人与现场观众保持的公众距离以及与非现场观众之间的社会远距离,是由双方的疏远社会关系决定的。说话人的面部表情、手势和身体移动直接反映喜怒哀乐的态度意义。面对观众或镜头,说话人多采用正面、自上而下的视角,这是最大限度的参入和介入语篇的体现,也表明说话人在与观众的互动关系中是权势的一方。此外,以屏幕为载体的图文视频资源是说话人间接通过权威性的信息源头表明自己的价值立场,可以看作是引用视觉资源的多声介入方式,有增强说服力的作用。
c)多种符号资源的评价意义整合方面,不同的符号模态——视觉的、语言的和手势的都有各自的潜能和局限性[7]29。因此,多模态动态语篇的最大优势就在于个模态符号资源的意义经过叠加、整合和互动会产生更完整的意义体。首先,现场观众的面部特写镜头在语篇中有110次,经观察分析后发现一般是在两种情况下出现:一是说话人在提出问题或陈述结论后;二是在屏幕上播放数据、图表或视频资源后。这时候出现的现场观众特写镜头是对寻求一致立场语言资源的最好视觉补充和配合,加强了再现参与者之间的互动关系。其次,除了语言资源多声介入意义的直接体现,以屏幕为载体的众多权威人士和机构提供的数据图表、结论和采访实录的间接引用,从视觉上丰富了多声介入意义,有利于多维度的统一双方价值立场。最后,镜头中人物的面部表情、手势和身体移动都是对语言资源评价意义的强化和形象化体现,共同实现说话人要表达的意义[12]343。多模态演讲语篇评价意义的构建如图4所示。
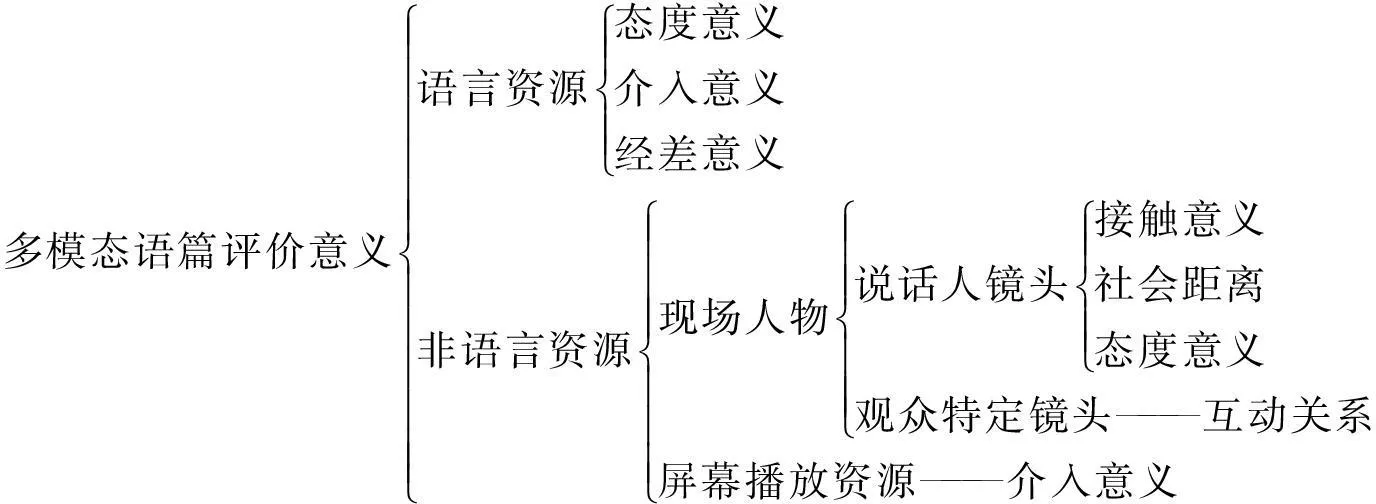
图4 多模态演讲语篇评价意义的构建
评价意义作为语篇语义学资源,其目的在于结成联盟、团结观众或读者[5]32。多模态语篇使得参与者互动关系呈现动态性、灵活性和多变性的特点[7]261。本文从语言资源和非语言符号资源两个方面考察分析了演讲视频语篇——《穹顶之下》的评价意义构建,并进一步探讨了各模态符号资源之间评价意义的互动和叠加,可以有效实现更完整的语篇意义体,多方位多角度促使观众产生情感上的共鸣和形成统一的价值立场。《穹顶之下》之所以传播力度大,一方面雾霾是当下中国老百姓关注的社会热点问题;另一方面,多符号权威信息源的介入、同为当事人立场的感同身受都起到了说服观众、引起共鸣的重要作用。从评价意义构建的角度看,这篇多模态演讲语篇在语言策略和人际关系上是成功的。
参考文献:
[1] 电影天堂.2015年柴静拍雾霾纪录片《穹顶之下》[EB/OL].[2015-03-02].http://www.dy2018.com/i/94646.html.
[2] 马荣.中关村在线.柴静《穹顶之下》点击量突破3000万[EB/OL].[2015-03-02].http://soft.zol.com.cn/509/5090185.html.
[3] 黄国文.功能语言学与语篇分析研究:第2辑[M].北京:高等教育出版社,2010.
[4] HALLIDAY M. An Introduction to Functional Grammar [M]. 2nd ed. London: Amold,1994.
[5] MARTIN J,WHITE P. The Language of Evaluation: Appraisal in English [M]. New York: Palgrave Macmillan,2005.
[6] MARTIN J. Fair trade: negotiating meaning in multimodal texts [C]// COPPOCK P. The Semiotics of Writing: Transdisciplinary Perspectives on the Technology of Writing. Bloomington: Indiana University Press,2001.
[7] KRESS G, LEEUWEN T. Reading Images: The Grammar of Visual Design [M]. London: Routledge,1996.
[8] O’HALLORAN K. Visual semiosis in film [M]// O’ HALLORAN K. Multimodal Discourse Analysis: Systematic Functional Perspectives.London:Continuum,2004.
[9] FENG D, O’ HALLORAN K. Representing emotion in visual images: A social semiotic approach [J]. Journal of Pragmatics,2012,44:2067-2084.
[10] FENG D, O’ HALLORAN K. The multimodal representation of emotion in film: Integrating cognitive and semiotic approaches [J]. Semiotica,2013,197:101-122.
[11] 朱永生,严世清.系统功能语言学再思考[M].上海:复旦大学出版社,2011.
[12] 张德禄.语篇分析理论的发展及应用[M].北京:外语教学与研究出版社,2012.
(责任编辑: 任中峰)
Construction of Multimodal Speech Discourse Appraisal Meanings:a Case ofUndertheDome
HEJuan
(School of Foreign Languages, Jimei University, Xiamen 361021, China)
Abstract:In multimodal discourses, language, facial expressions, gestures and images are all involved in constructing appraisal meanings. By adapting appraisal system and visual grammar as the theoretical framework, this paper analyzes appraisal meanings of Under the Dome-a multimodal speech discourse written by Chai Jing from the perspectives of verbal resources and nonverbal resources. The research findings indicate moderate verbal resources with attitude meanings help to establish emotional response with the audience. Engagement meanings and graduation resources contribute to the supplement and adjustment of evaluative meanings and persuasion. In terms of nonverbal resources, the public distance, the shooting angles and eye contact between the speaker and the audience as well as the speaker’s facial expressions, gestures and body movements construct respective interactions, involvement degree and attitude meanings in accordance with a speech discourse. The study ends up with overlapping and complementary relationships of verbal resources and nonverbal appraisal resources.
Key words:multimodal speech discourse; appraisal meanings; visual grammar
DOI:10.3969/j.issn.1673-3851.2016.06.009
收稿日期:2016-3-21
作者简介:贺娟(1979-),女,四川宜宾人,硕士,主要从事系统功能语言学和语篇分析方面的研究。
中图分类号:H030
文献标志码:A
文章编号:1673- 3851 (2016) 03- 0273- 06 引用页码: 060302
