基于关键词图的社交话题抽取及情感极性判别
2016-06-20尹兰,雷霈,周竞
尹 兰,雷 霈,周 竞
(1.贵州师范大学 大数据与计算科学学院,贵州 贵阳 550001;2.武汉大学 计算机科学学院, 湖北 武汉 430072)
基于关键词图的社交话题抽取及情感极性判别
尹兰1,2,雷霈1,2,周竞2
(1.贵州师范大学 大数据与计算科学学院,贵州 贵阳550001;2.武汉大学 计算机科学学院, 湖北 武汉430072)
摘要:研究结合社交媒体特点,充分考虑标签文本和内容文本信息,融合了传统的LDA话题模型对社交文本信息进行话题聚类,从而实现了对社交数据的话题发现,与此同时,文章提出了基于关键词图模型构建话题特征,并结合支持向量机模型进行文本情感极性判别。研究在开放微博数据集和COAE2014公开评测数据上进行了相关实验,实验证明了有效的关键词图模型能进一步克服中文语义的模糊性和歧义性。
关键词:LDA;社交话题;关键词图; SVM
0引言
社交媒体是人们数字化生活的虚拟场景和大数据载体,通过对社交数据分析进而实现对社交群体生活有效关注具有深刻的社会现实意义。但由于社交数据环境异构杂乱,数据具有时效性,突发性,加之中文语义固有的模糊性及语义单元存在的切分歧义等复杂性特点。社交话题的发现一直是一个热点和难点问题。文章在传统LDA(Latent Dirichlet Allocation)[1]模型进行主题发现的基础上,充分考虑社交文本的特点,有效利用自然标注的主题标签有效抽取相关话题。
围绕相关主题,能有效进行情感极性判断是文本情感分析的基本内容,由于中文情感分析复杂性加之社交短文本信息缺失,文章提出关键词图话题呈现模型,以便更准确的呈现上下文语义信息,从而提升情感极性甄别的精度,结合SVM[2]支持向量机模型我们构建了文本情感判别模型,实验证明了本文提出方法的有效性。
1社交文本话题发现及情感分析
话题模型是自然语言处理领域一个备受推广的应用模型,著名的模型有Stockholm于1999年提出的PLSA(Probabilistic Latent Semantic Analysis)[3, 4]和Blei等人[1]于2003年提出的著名的LDA(Latent Dirichlet Allocation)。PLSA基于多项式分布和条件分布混合建模词和文档的共现概率,其主要在传统的潜在语义分析基础上利用EM算法进行参数学习。LDA模型是一个概率生成的贝叶斯模型,其基本思想是假设一篇文档的具体内容信息能够由一些潜在话题的多项式分布来表征,而话题又能够由一系列词的多项式分布来表征,文档能够由一系列语义上相关的词语和在某些话题中出现的概率来表征。LDA模型因其在文本任务处理中的能力被不断推广,改进及并行化实现[5, 6,7]。PLSA和LDA都是建立在概率独立性假设的基础上,即植根于传统的词袋(Bag of Words)理论。但这两个模型都不可避免忽略了词汇之间复杂的相互关系。但LDA模型在各种文本任务中得到广泛的应用,因此,本文选取该模型作为话题抽取的基本模型。
传统的情感极性判别可看做1个离散数据的二分类问题,大量类似任务通过各种SVM模型工具包得到实现。本文把话题抽取和极性判别整体进行讨论,重点提出了上下文词网络的语义表征方法,具体任务实施如下:
1)利用爬取的开放微博数据作为文本数据,结合带”#”标签的话题词和基于LDA模型抽取的话题词构建文本话题;
2)将话题进行情感极性标注,将情感极性判定任务转化成一个分类任务,结合SVM模型进行情感分类。在情感分类中,充分考虑关键词连接图模型下情感极性的特征值。
研究在开放微博数据集和COAE2014公开评测数据上进行了相关实验,平均正确率可达到了86%。
2研究任务实施框架及模型方法
基于社交网络的话题抽取,本质是1个文本聚类问题,在实际社交网络环境往往需要繁琐的数据清洗,本文利用信息熵方法抽取相关标签话题词作为候选话题,采用LDA模型对内容文本进行话题发现,构建话题后选集。并在话题关键词图模型基础上采用SVM模型进行话题情感极性判别,利用改进的WG-SVM实现话题极性的判别,整体流程如图1所示。
最大熵原理由E.T.Jaynes 在1957 年提出,原理在于如果知道与未知分布相关的部分先验知识时,需要选取满足这些先验知识的同时满足熵值能取得最大的变量的概率分布。如公式(1)所示,笔者利用该模型对#标记的标签话题进行度量抽取,以便充分利用社交网络中自然标注的有效信息。
(1)
在熵计算中,通过选取特征函数把先验知识组织成特征向量,给定特征函数f1,f2,……,fk,把问题描述成满足约束条件的优化问题。为充分考虑微博信息的时效性,具体特征选取包括:评论时效特征,发送时效特征,转发的时效特征等进行度量。
研究利用ICTCLAS[8](InstituteofComputingTechnology,ChineseLexicalAnalysisSystem)进行中文分词,正确率可以达到97.58%。LDA模型是自然语言处理领域被广为推广的话题抽取应用模型,其通过概率推导获取文本的潜在主题结构。在LDA中,文本的词分布是可观测到的样本,而文本的主题属于隐含变量, 利用文本的相应规则和已知数据,LDA通过概率分布推导可以求得文本的主题结构
考虑各主题词之间关系对情感极性的影响,本文提出了基于关键词图的情感分类WG-SVM方法,该词图主要考虑了上下文共现关系及词性特征2个因素。
G=
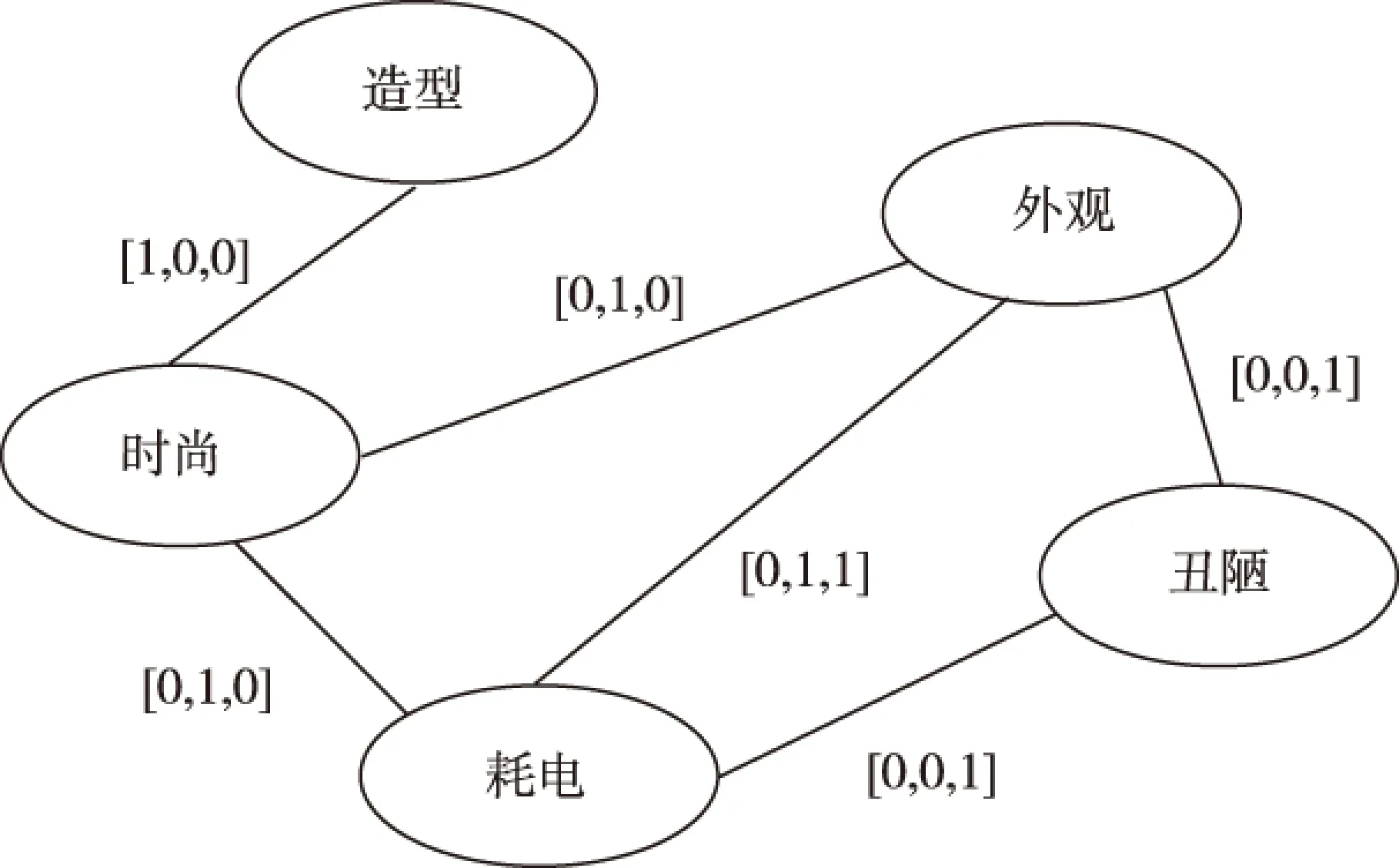
图2 关键词图Fig.2 Key words graph
语料经过预处理得到候选词集,词集作为网络节点词初始化构成关键词图,如图3所示:
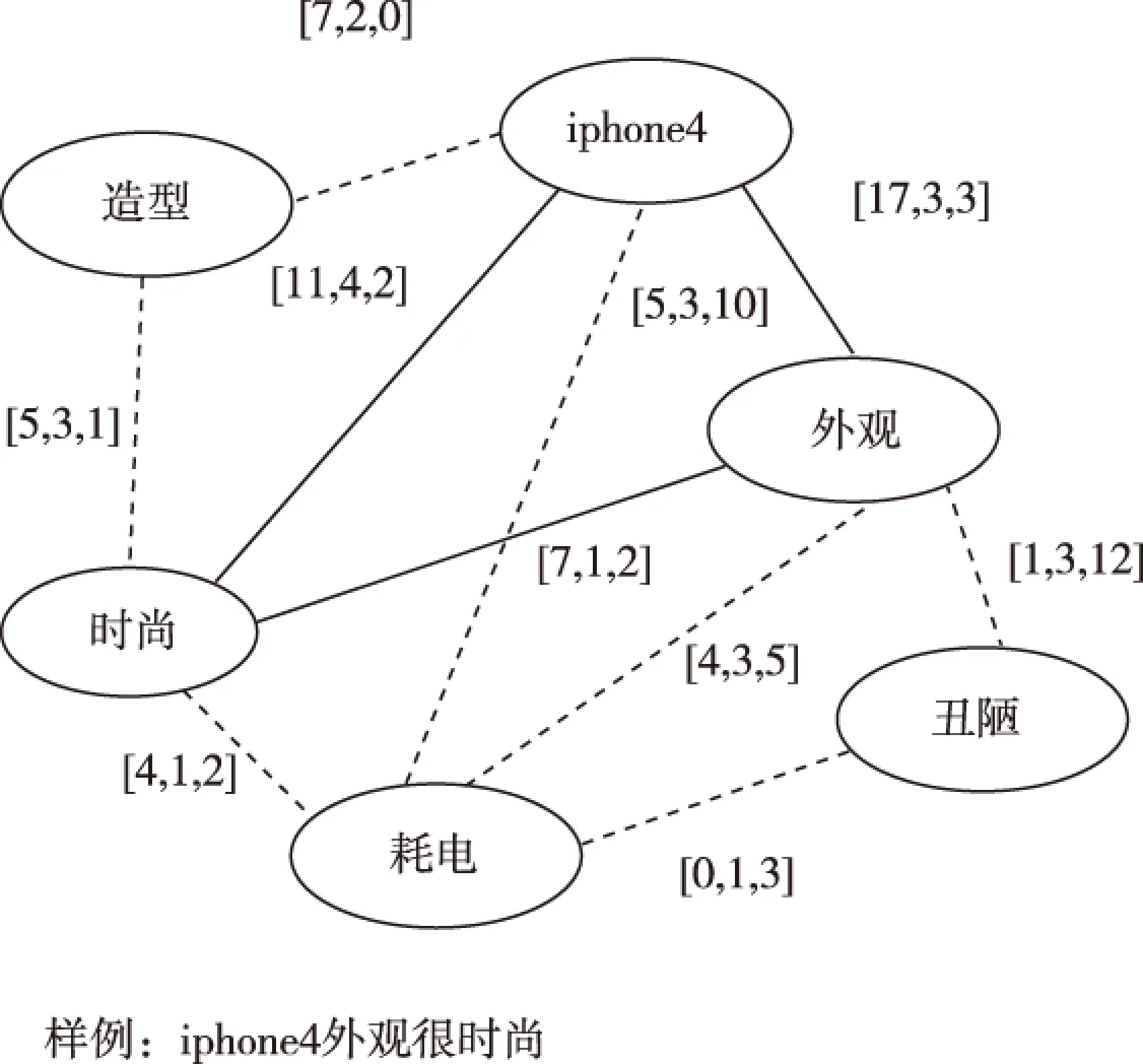
图3 关键词图连接样例Fig.3 A sample for linking words in our graph
考虑到不同词性(名词,动词,形容词,副词),分别对词图中各关键词进行正面/负面极性概率计算,计算公式如公式(2)和(3)所示,表示与端点连接的边,并且边所连接的词语在语料中同现:
(2)
(3)
每一个候选词通过结合词性及极性概率计算抽取特征值,如:Fn,pol,Fv,pol,Fadj,pol,Fadv,pol表示为名词,动词,形容词,副词的极性特征,并根据得到相关特征进行分类器训练。
3实验结果
实验数据选择了2015年3月部分开放微博数据及COAE2014公开评测数据进行实验。图3为本文采用的改进的主题模型在电影,体育及乳制品3个主题数据进行试验, 把改进的主题聚类同传统LSI及LDA话题聚类的F-Score值对比结果。
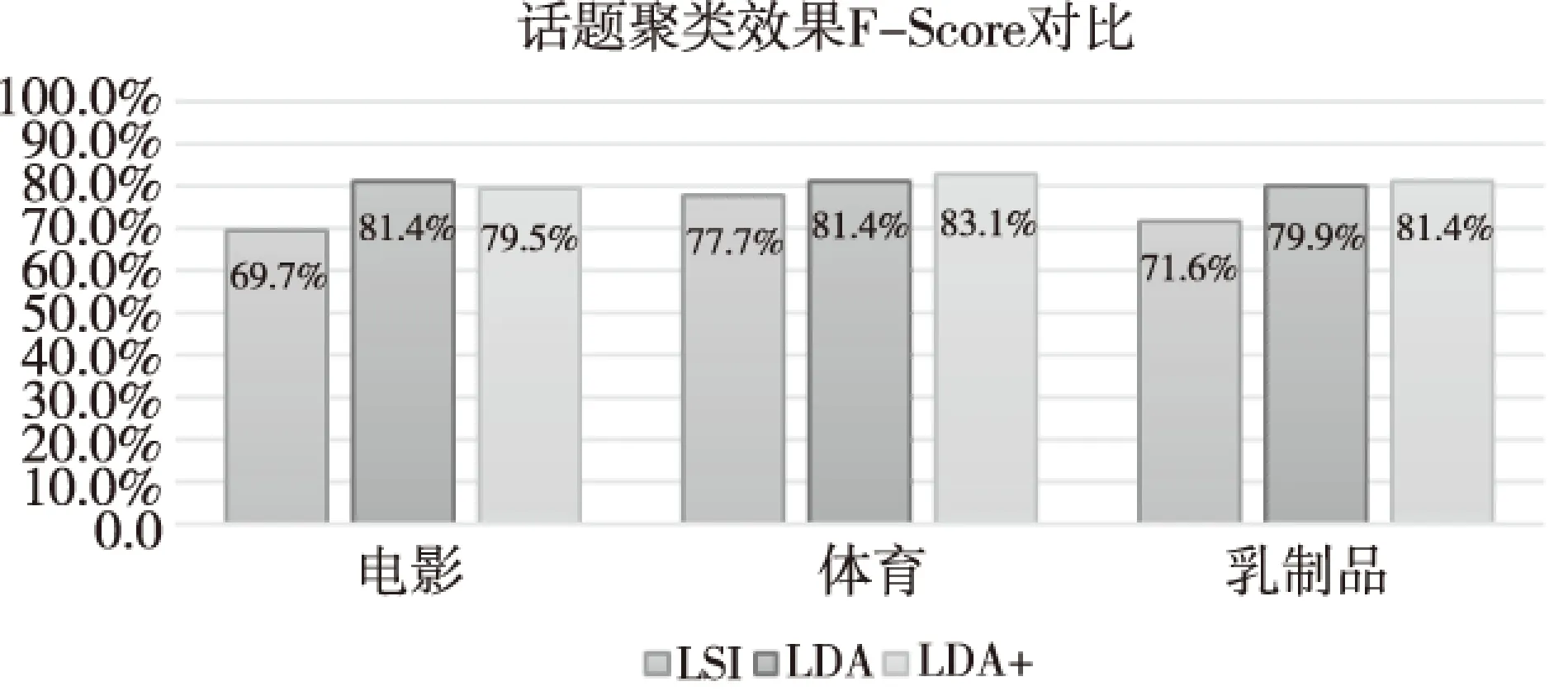
图4 话题聚类效果Fig.4 Topic clustering results
结合提出的关键词连接图表示方法基础上,在3个主题文本上进行了文本情感极性判定,并把方法同传统的SVM方法[2]和基于点互信息的SO-PMI[9]方法进行了比较,结果如图4所示。说明基于关键词的图模型能更好的表征词汇之间的语义关系。

图5 话题情感极性判别效果Fig.5 Sentiment polarity discrimination for topics
4结论
社交网络开放数据的复杂性应用场景导致了常规的话题模型存在一定的局限性,本文结合有效的预处理及话题标签信息改进话题聚类的精度,与此同时,提出了基于关键词图模型构建话题特征,并利用支持向量机进行文本情感极性分类。实验证明了有效的关键词图模型能进一步克服中文语义的模糊性和歧义性。但由于中文语义的复杂性,其语义理解及情感分析非常困难,特别是社交短文本信息更是极具挑战,因此,高质量的语料数据集和利用网络模型构建有效的上下文情景信息非常重要。
研究基于传统模型框架上进行了探索和实践,近年来,随着社交事件在网络的传播及影响,各类围绕社交文本的研究也方兴未艾,而其中围绕某一主题的语义情感分析仍需得到更进一步相关应用实践[10]。
参考文献:
[1] BLEI D M,Ng A Y,JORDAN M I.Latent dirichlet allocation[J].The Journal of machine Learning research,2003,3:993-1022.
[2] CORTES C,VAPNIK V.Support-vector networks[J].Machine learning,1995,20(3):273-297.
[3] HOFMANN T.Unsupervised Learning by Probabilistic Latent Semantic Analysis[J].Machine Learning,2001,42(1-2):177-196.
[4] HOFMANN T.Probabilistic latent smantic analysis[J].Uncertainty in Artificial Intelligence,1999,38(11):155-162.
[5] PEROTTE A,BARTLETT N,ELHADAD N,et al.Hierarchically Supervised Latent Dirichlet Allocation[J].Advances in Neural Information Processing Systems,2011,24:2609-2617.
[6] LIU Z,ZHANG Y,CHANG E Y,et al.Plda+: Parallel latent dirichlet allocation with data placement and pipeline processing [J].ACM Transactions on Intelligent Systems and Technology (TIST),2011,2(3):389-396.
[7] BLEI D M.Probabilistic Topic Models[EB/OL].(2012-01-01)[2014-10-28].http://www.cs.princeton.edu/~blei/topicmodeling.html.
[8] 张华平.汉语分词[EB/OL].(2012-01-01)[2014-3-25].http://ictclas.nlpir.org/.
[9] TURNEY P D.Thumbs up or thumbs down?:semantic orientation applied to unsupervised classification of reviews[C]//Proceedings of the 40th annual meeting on association for computational linguistics,July,2002,Association for Computational Linguistics(ACL),Philadelphia,USA:417-424.
[10]NGUYEN T H,SHIRAI K.Topic Modeling based Sentiment Analysis on Social Media for Stock Market Prediction[C]//The 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing (ACL-IJCNLP),July,26-31,2015, Association for Computational Linguistics(ACL),Beijing:1354-1364.
Topic extraction and graph based sentiment polarity discrimination
YIN Lan1,2,LEI Pei1,2,ZHOU Jing2
(1.Big Data and Computer Science School, Guizhou Normal University, Guiyang, Guizhou 550001,China;2.Computer School of Wuhan University, Wuhan, Hubei 430072,China)
Abstract:Social media is the platform for our daily digital life, social topic detection is a hot but difficult issue for data in social media is with the complexity in heterogeneity, timing and linguistic ambiguity. In this paper, we apply Maximum Entropy on tag texts and LDA model on social contents for social topic detection, meanwhile, a key word graph based method is proposed for text sentiment analysis with SVM. Experiments on open Weibo data and COAE2014 data show the effectiveness of our proposed strategy for Chinese semantic analysis.
Key words:LDA; social topic; key word graph; SVM
文章编号:1004—5570(2016)02-0076-04
收稿日期:2016-03-18
基金项目:贵州省科技厅联合基金(黔科合J字LKS[2012]33号, LKS[2012]37号)
作者简介:尹兰(1979-),女,副教授,研究方向:自然语言处理,知识表示,复杂网络,E-mail:yl@gznu.edu.cn.
中图分类号:TP391
文献标识码:A
