基于决策表的数据挖掘建模方法研究
2016-06-13杜松江张继成
杜松江,张继成
(长江大学工程技术学院,湖北荆州434023)
基于决策表的数据挖掘建模方法研究
杜松江,张继成
(长江大学工程技术学院,湖北荆州434023)
摘要:挖掘模型的建立与评价是数据挖掘的核心部分。介绍了数据挖掘中的决策表算法,再以某商业银行CRM系统为例,选取银行营销活动历史数据为对象,并详述了通过Clementine数据挖掘软件建立银行客户响应预测模型的方法。
关键词:决策列表;Clementine;预测模型;响应率
在Clementine数据挖掘系统中,节点和数据流的理解非常重要。节点代表了系统即将对数据进行的操作。通过很多的节点来执行数据的整个过程称为一个数据流,数据流的方向通过节点之间的联系得到。数据流的过程是挖掘过程中需要重点关注的问题。
以某商业银行为例,该银行举办一系列金融产品的促销活动,不同客户对此类活动的响应可能不同,比如性别、年龄、家庭和收入等因素会对此类产品的购买力产生不同程度的影响[1]。通常,可以选择神经网络、决策表和决策树C5.0等算法建立预测模型来预测各因素对此类促销活动的响应程度。
本文阐述了如何在Clementine数据挖掘软件中使用决策列表建立客户响应预测模型。
1决策表
决策表(decision table)又称判断表,经常用于描述有多种决策方案、处理判断条件很多、条件彼此结合的情况。在一些数据处理问题当中,针对不同逻辑条件的组合值,分别执行不同的操作,决策表非常适合于处理这类问题。
决策表由四部分组成:①“基本条件”列出所有可能的变量、关系或预测。②“候选条件”就是各种条件组合可能取得的值。③“动作”指要执行的所有可能的操作。④“动作入口”指根据对应的条件组合,所选择的对应操作。类似C语言中的语句结构if-else和switch-case,每个条件和满足该条件的执行语句相对应。但是,两者又有不同,决策表能非常清楚地表现多个条件和多个动作间直接的单独联系,而传统的程序语句只能描述简单的控制结构。构造决策表分为5个步骤:①确定规则的个数;②列出所有的基本条件和动作;③确定条件项;④确定动作项,得到初始决策表;⑤简化决策表,合并相似规则。
决策列表算法可生成表示给定结果的可能性上限和下限规则。决策列表模型在CRM中得到了广泛的推广应用,如市场营销和呼叫中心。
2建立模型
在分析当前客户关系管理中数据挖掘的应用基础上,以某商业银行的CRM系统开发为背景,利用决策列表建立客户响应预测模型,生成商业银行的客户响应具体模型。
使用决策列表模型,根据以前的促销活动,识别积极响应当前活动的客户特征。该商业银行客户响应预测模型的数据流如图1所示。
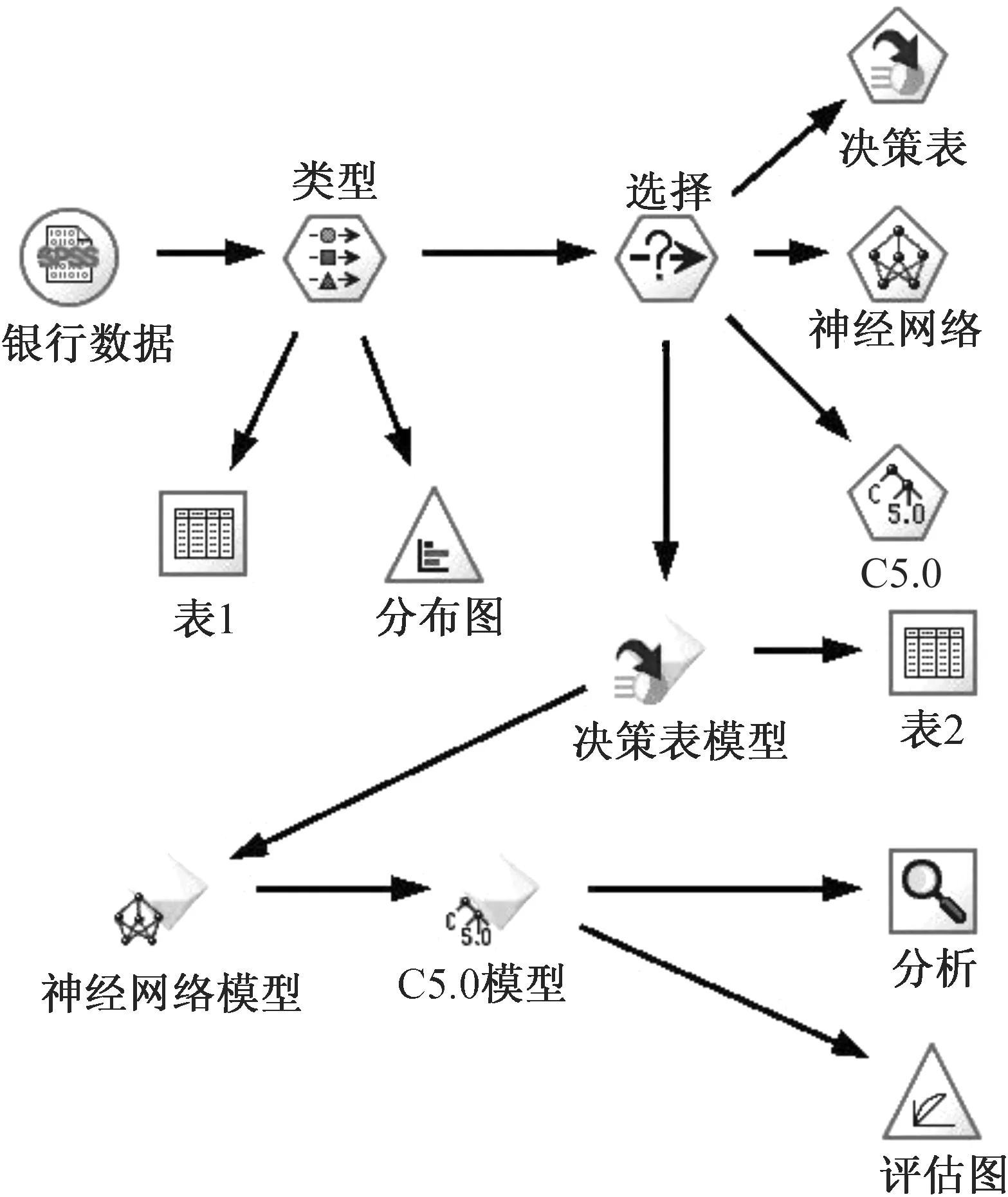
图1 客户响应预测模型的数据流
银行数据文件(即数据流的数据源节点)的历史数据可跟踪过去的营销活动中为特定客户提供的报价,由campaign字段的值表示。Premium account活动中的记录数最大,campaign字段的值在数据中实际编码为整数,并带有类型节点中定义的标签,可以使用工具栏切换表中值标签的显示。该文件还包括若干包含每位客户的相关人口统计和金融信息的字段,这些字段可用于构建或“训练”依据特定特征而针对不同组预测响应率的模型[2]。
添加类型节点,然后选择响应作为目标字段(“方向”为输出)。将此字段的“类型”设置为标志。对于下列字段,应将“方向”属性设置为无:campaign、customer_id、purchase、response_date、product_id、purchase_date、X_random和Rowid[3]。这些字段在数据中均有用途,但不会在实际模型的构建中使用。单击类型节点的“读取值”按钮以确保值获得实例化。
数据中虽然包含4种不同活动的信息,但是每次分析应该集中关注其中的1项。由于Premium conditions活动(在数据中编码为campaign=2)中的记录数最大,因此可以使用选择节点实现仅在数据流中包含这些记录[4]。
在数据流中添加决策列表节点。在“模型”选项卡中,目标值应默认设为 1 ,以表示要搜索的结果。在这种情况下,正在搜索对以前的报价发出响应的客户。为简化本例中的模型,将最大段数设为 3,将新预测的置信区间更改为85%,选择启动交互会话,并执行节点以显示决策列表查看器。
由于尚未定义任何段,因此所有记录都位于其余段中。在示例的13 504个记录中,有1 952个记录响应,总匹配率为14.45%。可通过识别更多可能(或较少可能)做出积极响应的客户段来提高此匹配率。
在交互列表查看器的菜单中选择“工具-开始默认挖掘任务”选项,此操作将根据在决策列表节点中指定的设置运行默认的挖掘任务。任务完成后将获得3个替代模型,这3个模型列在右侧的“会话结果”选项卡上。从列表中选择第1个替代模型,然后单击右下角的预览按钮,预览结果如图2所示。
使用“预览”面板,可以在不更改工作模型的情况下快速浏览任意数量的替代模型,从而简化尝试不同方法的过程。
为了更好地观察模型,可能需要在窗口中将“预览”面板最大化。为此,可以单击箭头图标或拖动“预览”面板边框。使用基于预测变量(如收入、每月事务数和 RFM 得分)的规则,模型可确定响应率明显高于总体样本响应率的段。组合段后,该模型会提示可以将匹配率大幅提高至92.21%。但该模型只占总体样本的小部分,还有将近12 000 条记录(其中有 1 313 条匹配记录)位于其余段中。笔者希望模型在仍排除低响应率段的情况下捕获更多的匹配记录。

图2 预览结果
要尝试使用不同建模方法,可从菜单中选择“工具-组织挖掘任务”选项,单击“创建挖掘任务”按钮再次添加1个任务,并指定向下搜索作为任务名。将任务搜索方向改为向下,此操作将使算法搜索具有最低响应率的段,将最小段增至1 000。
在“组织挖掘任务”对话框中,确保已选择向下搜索任务,然后单击执行。此任务返回1组新的替代模型,可以将其添加到“会话结果”选项卡,并采用与以前结果相同的方式进行浏览。
这次,每个模型都可识别具有低响应率而不是高响应率的段。浏览第1个替代模型,只需排除这些低响应率段就可以将其余段中的匹配率提高到39.81%。此值低于前面浏览的模型的值,但其覆盖率更高(总匹配率更高),如图3所示。

图3 向下搜索任务
将这2种方法组合使用(使用向下搜索剔除不需要的记录,然后使用向上搜索)可改进此结果。单击“预览”面板中的改善工作模型使此模型(第2个向下搜索替代模型)成为工作模型。分别右键单击前2个段,然后选择排除段。这些段共同捕获近8 000条记录,但之间匹配率为0,因此可将其从未来的报价中排除(排除段的得分将为空,并以此来表示这些段)。右键单击第3个段并选择删除段,此段匹配率16.19%与基准匹配率14.45%的差别不是很大,因此不足以证明应将其保留。另外,删除段与排除段是2种不同的操作。排除段只是更改其得分方式,而删除段则将段完全从模型中删除(见图4)。
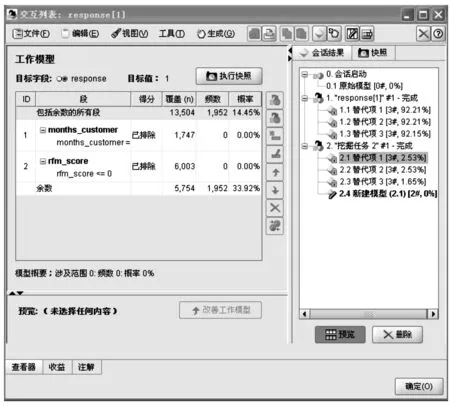
图4 改善工作模型
排除最低响应率段后,便可在剩余段中搜索高响应率段。单击表中的其余行将其选中,使下一项挖掘任务仅应用于该行。在选中其余段的情况下,重新打开“组织挖掘任务”对话框。编辑默认挖掘任务,将段数增至5、最小段增至500,然后执行任务。此操作将返回另一替代模型。通过将1项挖掘任务的结果反馈给另一挖掘任务,这些最新模型将同时包含高响应率段和低响应率段。具有低响应率的段将被排除,这意味着其得分为Null,而未排除的段得分为1。总体统计量反映了上述排除结果,其中第1个替代模型具有 45.63% 的匹配率,覆盖率(3 456条记录中有1 577条匹配记录)高于以前任何一个模型,如图5所示。
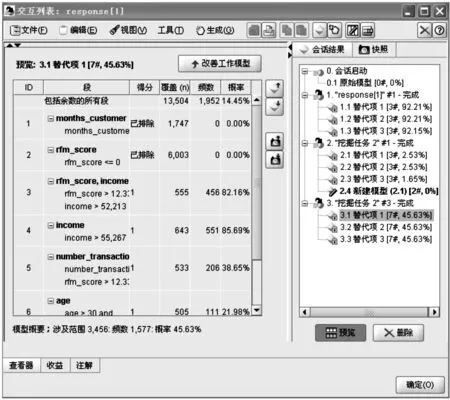
图5 包含高响应率段和低响应率段的模型
3模型评估
在实际数据建模过程中,往往需要参考模型评价标准来使用多种不同的数据挖掘算法。选取合适的数据集为对象,建立预测模型进行挖掘,可以通过分析报告和评估图来对比分析结果,比较各种算法预测的准确率。
[参考文献]
[1]赵伦,侯波,颜昌沁.利用Clementine C5.0模型预测CDMA客户流失[J].电脑知识与技术,2011(20):5031-5032.
[2]李学明,杨阳,秦东霞,等.基于频繁闭项集的新关联分类算法ACCF[J].电子科技大学学报,2012,41(1):104-109.[3]刘志鹏.数据挖掘产品IBM SPSS Modeler新手使用入门[EB/OL].(2011-03-24)[2015-12-02].http://www.ibm.com/developerworks/cn/data/library/techarticle/dm-1103liuzp/.
[4]薛薇,陈欢歌.基于Clementine的数据挖掘[M].北京:中国人民大学出版社,2012.
责任编辑:陈亮
Research on Modeling Method of Data Mining Based on Clementine
DU Songjiang,ZHANG Jicheng
(College of Engineering Technology,Yangtze University,Jingzhou 434023)
Abstract:The establishment and evaluation of mining model is the core of data mining.This paper first introduces the decision table algorithm in data mining,selects the historical data of bank marketing activities as the object by taking a commercial bank CRM system as an example,and describes in detail the method of establishing a bank customer response prediction model by using Clementine data mining software.
Key words:decision list;Clementine;prediction model;response rate
doi:10.3969/j.issn.1671- 0436.2016.02.012
收稿日期:2016- 02-23
作者简介:杜松江(1981—),男,硕士,讲师。
中图分类号:TP311.13
文献标志码:A
文章编号:1671- 0436(2016)02- 0051- 04
