分时段下高炉铁水含硅量的时间序列建模与预测
2016-06-13柳传武李新光吴彩林张庆丰
柳传武,李新光,吴彩林,张庆丰
(1.马鞍山职业技术学院,安徽马鞍山243031;2.安徽工业大学电气与信息工程学院,安徽马鞍山243002)
分时段下高炉铁水含硅量的时间序列建模与预测
柳传武1,李新光2,吴彩林1,张庆丰1
(1.马鞍山职业技术学院,安徽马鞍山243031;2.安徽工业大学电气与信息工程学院,安徽马鞍山243002)
摘要:高炉炉内物理化学反应复杂,而保证高炉正常工作的关键就是温度。高炉温度与铁水硅含量成正比,选用传递函数模型来预测硅含量,便可获得高炉温度信息。选取喷煤量、鼓风量和冷却水流量为输入变量,提出了输入分时段传递函数的硅含量预测模型并对原始数据采取对数预处理,以降低预测方差。该模型能准确地预测硅含量,预测准确率都在93%以上。
关键词:高炉铁水;硅含量;时间序列法;传递函数模型
高炉的生产过程非常复杂,它是一个具有较大滞后性、时变性、非线性、强耦合等特性的系统,一般无法通过直接测量得到高炉的炉温。截至目前,国内外高炉研究者经过多年实践和研究,提出了许多温度控制与预测模型,如基于控制算法的“炉温预报和控制模型”、基于高炉生产的“机理或半机理模型”、基于高炉生产数据统计所建立的模型和基于专家知识库的“专家系统模型”,这些模型在实际生产实践中都存在一些问题,难以推广应用[1-4]。
近年来,国内外专家根据高炉温度与铁水硅含量成正比的规律,通过测量铁水硅含量就可以推测出高炉温度。在实际的生产过程中,利用铁水的含硅量来表示高炉炉温,高炉铁水的含硅量就成为了一个非常重要的指标,反映高炉的热平衡状态情况、生铁质量情况以及高炉炉体内的物化反应情况。若高炉生产条件发生变化,如风温、喷煤流量、鼓风量、冷却水量、配料焦炭及炉渣碱度等变化,则高炉铁水硅含量也会随之改变,影响它的因素有很多[5-7]。
利用时间序列法来预测铁水的硅含量,不仅能反映出高炉炉温变化的连续性,而且这种方法需要的历史数据比较少,计算速度也很快。因此,在高炉温度预测上,这种方法也得到了广泛的应用[8-9]。
1建立分时段下时间序列的传递函数模型
高炉的生产工艺流程如图1所示。从高炉的生产实际出发,假设系统是一个非平稳的时间序列随机过程,选取鼓风量、喷煤量、冷却水流量这3个主要影响因素为输入变量,考虑到时间的变化和硅含量变化的连续性[10-12],同时考虑模型预测误差对硅含量预测结果的影响,建立分时段下时间序列的传递函数模型。
本文借鉴文献[13]所建立的时间序列的传递函数模型,即
yt=(H(B)/G(B))Xt+Nt
(1)
式中:yt代表温度序列;Xt代表3行1列的输入矩阵,分别代表喷煤量、鼓风量以及冷却水量;G(B)=1+a1B+a2B2+…+anBn;H(B)=1+b1B+b2B2+…+bmBm;B为系数矩阵;Nt代表噪声序列,可用ARMA模型描述为
(2)
式中:C(B)和D(B)代表B的多项式,亦代表白噪声序列;et代表预测误差。

图1 高炉生产工艺流程
在传统的传递函数模型中,基本假设是温度、输入序列都是在平稳的时间序列状态下的,但实际上它们却都是非平稳的时间序列,故所提出的传递函数模型如下说明:①采用ARIMA模型来达到消除温度和输入序列的非平稳性的目的[14-16];②此模型加入了误差分析部分,考虑了预测误差对于预测结果所带来的影响;③考虑了温度分布影响因素(时段因素)。
比起顺序温度序列,分时段温度序列的特征使它的分布更集中、变化更单一。采用分时段来建模,有利于提高预测的精度,减小预测的误差[17]。
下面建立传递函数的预测模型,其模型表达式为
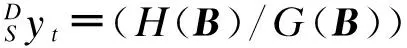
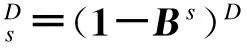
已知滑动平均模型,数学表达式为
yt=et-θ1et-1-…-θqet-q
(4)
式中:θ1,θ2…,θq代表模型参数;et,et-1…,et-q代表随机干扰的白噪声序列;q代表模型的阶次,它主要是取决于同yt所相关的残差数据。将其代入各多项式,再将式(4)展开,得到下列展开表达式
yt+a1yt-1+a2yt-2+…+anyt-n=
b1Xt+…+bmXt-m+1+et+c1et-1+…+cqet-q
(5)
式中Xt代表3行1列的输入矩阵,分别代表喷煤量、鼓风量以及冷却水。
(6)
θT(t)=(a1,…,an,b1,…,bm,…,c1,…,cq)
(7)

由式(5)~(7)可以写出如下表达式
yt=φT(t)θ(t)+et
(8)

(9)
2工程实际应用
2.1建模与模型误差分析
以某钢厂1#高炉为例,每天能够出18次钢水,通过对每炉检测能够形成了18个温度序列。对这18个温度序列来逐一进行建模的基础上,为保证所训练数据的实时性,不断滚动更新模型训练时间点的所有数据,来提高温度预测的准确度。硅含量的时段分布具有非常明显的特点(白天温度普遍很高,而在午夜和凌晨温度比较低),故要考虑时段因素对于硅含量的变化影响。选取鼓风量、喷煤量、冷却水流量这3个主要影响因素为输入变量,铁水温度为输出量,表1列出了在每个时段下的传递函数模型,并对温度进行了对数处理,影响因子同样进行了对数处理。

表1 分时段传递函数模型
模型误差所采用的评价标准为平均绝对百分比误差MAPE,表达式为
(10)

2种模型预测误差见表2。
国内市场:据协会监测的24个省份数据显示,中国磷酸二铵批发价格周环比总体稳定,局部价格上涨为主。其中,河北、山西、安徽、山东、湖北、广东、陕西、新疆8省份价格上涨4.5-100元/吨,安徽省涨幅最大;黑龙江省价格下跌66.7元/吨,其余省份价格持稳。中国磷酸二铵零售价格周环比持稳,局部价格涨跌互现。其中,河北、广东、陕西、新疆4省份价格上涨4.2-82.5元/吨,陕西省涨幅最大;山西、黑龙江、湖北、四川4省份价格下跌2.5-100元/吨,黑龙江省跌幅最大,其余省份价格保持稳定。
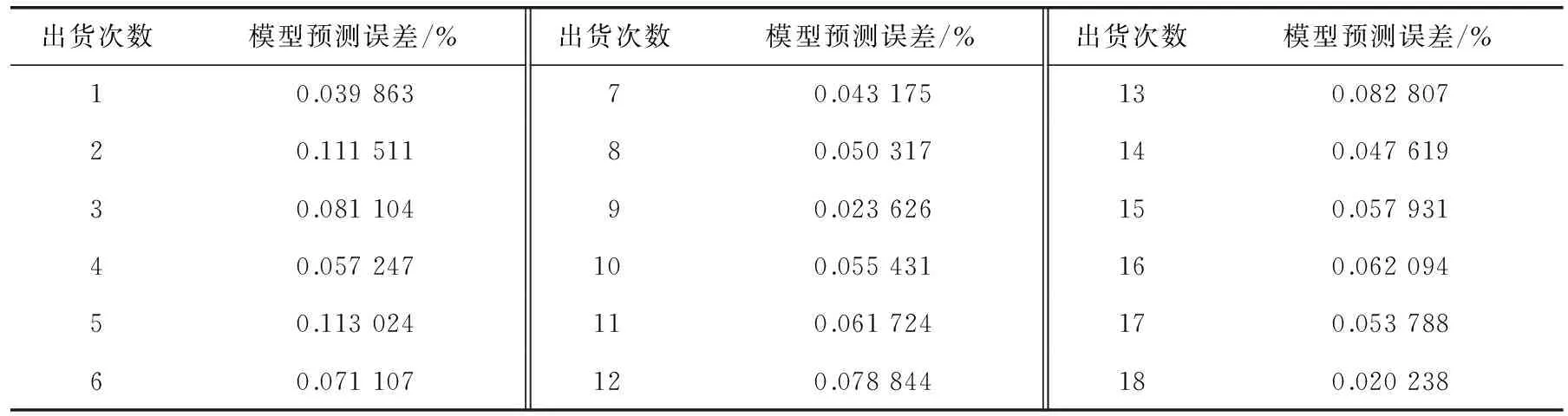
表2 传递函数模型与改进模型预测误差表
由表2可以得出,所预测的18个出货点的平均绝对误差,各时段的MAPE差异较大。出货点误差较大的主要分布在第2天到第8天所在的出货时间点,这个时间点硅含量变化大,造成误差也大。按时间来分布,主要是集中分布在凌晨以及上午这2个时间段。主要原因如下:夜班时期内各项的影响因素变化大,受到其他不确定性因素的影响也大,就给预测增加了难度,此时,炉温就会非常不稳定,最大的误差已达到0.138%。在其他出货时间点的MAPE大多约为0.1%,换算预测精度在±0.03,预测精度较高。此外,一些出货时间点即使是在硅含量变化较大时,误差也是全部能够控制在一个比较合理的范围内。许多文献中所提到的硅含量变化较大的时间点则预测误差就比较大,文中所研究的分时段建模则有效地避免了这种现象。
使用该预测方法,也会存在较大和较小误差出现的时候,针对波动较大的时段,则预测的难度就比较高。这表明,高炉炉温是多种影响因素的一个集中反映。
2.2实际应用与误差分析
以某钢厂为例,图2~5介绍了连续8d硅含量以及相应喷煤量、鼓风量、冷却水流量的变化。
表3给出了对数传递函数模型预测的日平均误差,最大误差为0.107 289%,最小误差为0.032 897%,说明了模型预测效果较好。
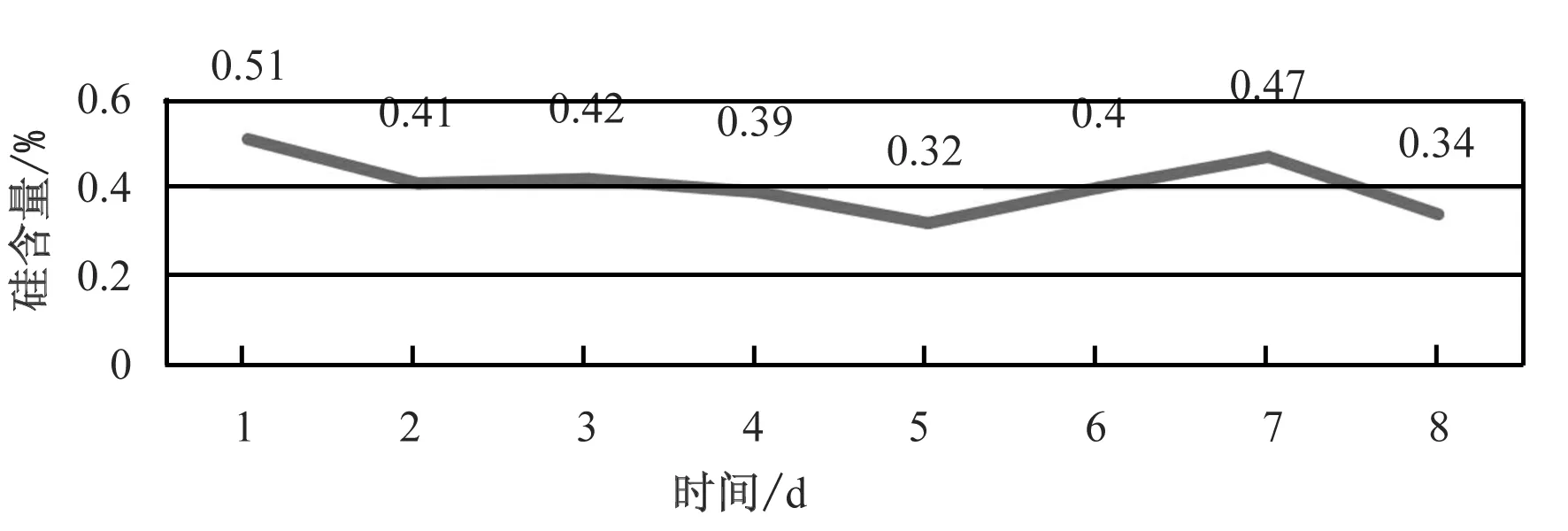
图2 某钢厂高炉连续8 d硅含量的曲线
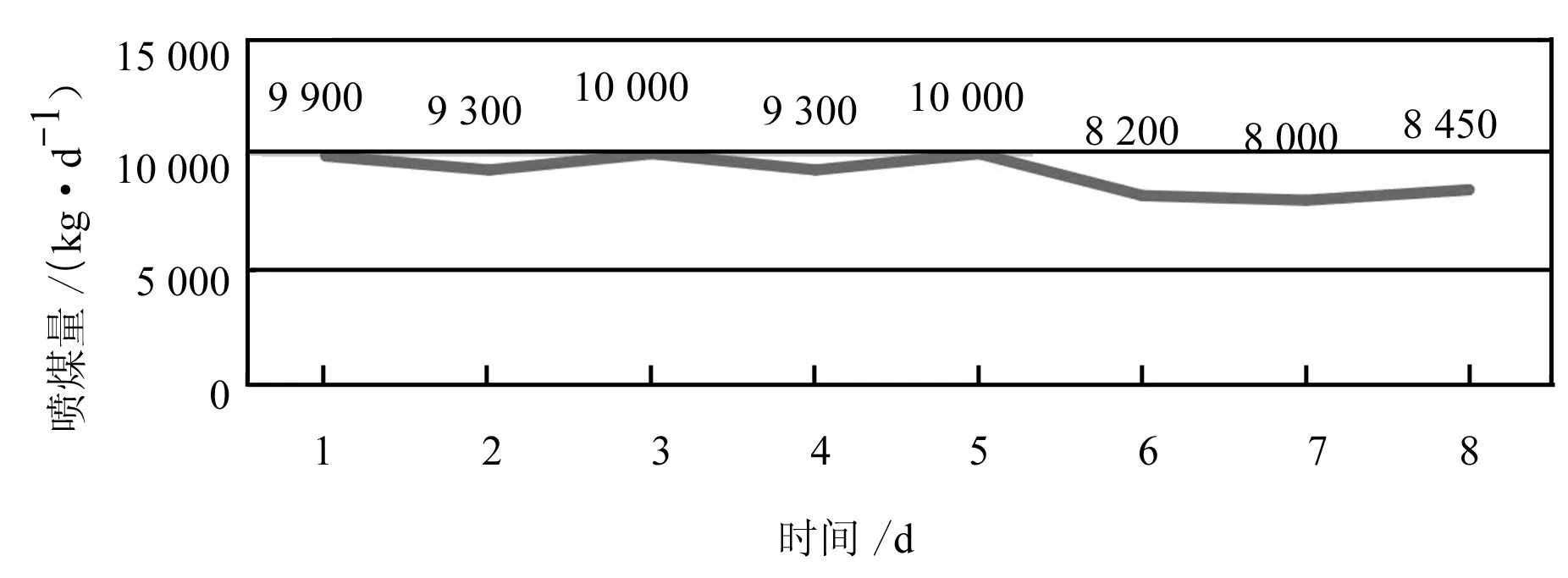
图3 某钢厂高炉连续8 d喷煤量的曲线
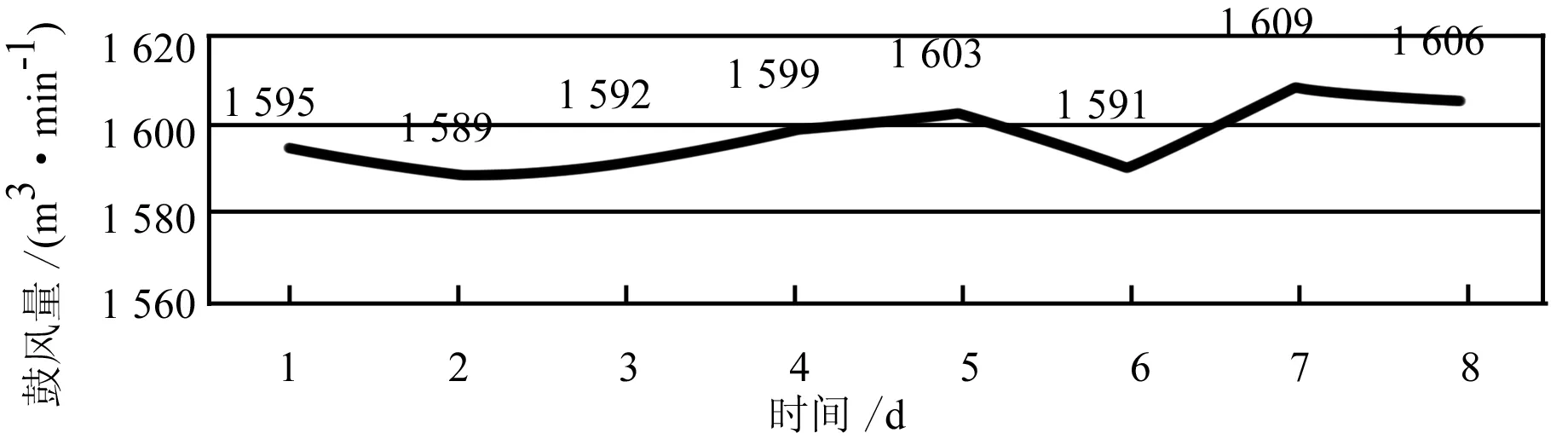
图4 某钢厂高炉连续8 d鼓风量的曲线

图5 某钢厂高炉连续8 d冷却水流量的曲线

时间对数传递函数模型预测误差/%时间对数传递函数模型预测误差/%第1天0.057451第5天0.064508第2天0.072164第6天0.049976第3天0.047945第7天0.107289第4天0.032897第8天0.053267
图6为对数传递函数模型预测值与实际值之间的对比曲线。观察图6可得出对数传递函数模型所预测出来的曲线可以与实际曲线较好地吻合。实际应用表明,预测初期效果并不是很好,但随着时间的推移,所预测的结果逐渐变好,主要原因是对历史数据的采取了预处理,通过合理地选择预处理的数据可以很显著地提高预测准确度。
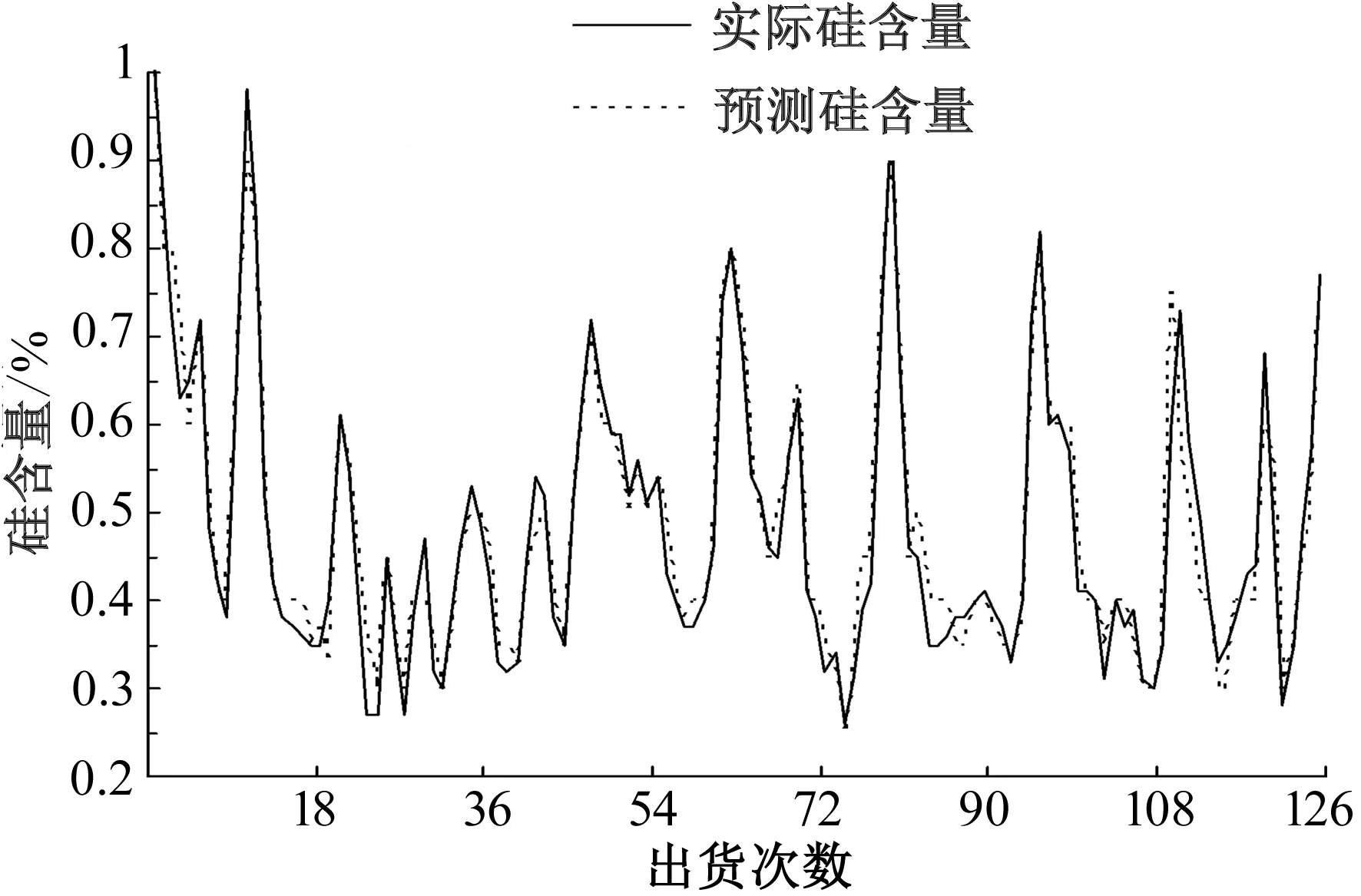
图6 对数传递函数模型预测值与实际值对比图
3结论
本文提出的一种用于某钢厂高炉硅含量预测的传递函数模型,采用分时段下的时间序列函数模型,利用ARIMA模型对原始数据的不平稳性来进行处理,并计入了三大主要影响因素(鼓风量、喷煤量、冷却水)以及误差对温度所带来的影响。算例表明,分时段建立模型能有效提高预测的精度。炉温是多项指标中的一个集中反映,影响高炉炉温的因素还有很多,本文仅仅考虑了其中的部分因素,如能合理地考虑更多的影响因素,对于预测高炉炉温来说可能会取得更好的效果。
[参考文献]
[1]尹菊萍,蒋朝辉.基于数据的高炉铁水硅含量预测[J].有色冶金设计与研究,2015,36(3):36-41.
[2]刘祥官,刘芳.高炉炼铁过程优化与智能控制系统[M].北京:冶金工业出版社,2003:1-21.
[3]袁冬芳,赵丽.高炉铁水硅含量序列的支持向量机预测模型[J].太原理工大学学报,2014,45(5):684-688.
[4]孙克勤.高炉铁水含硅量预报自适应数学模型的研究与实验[J].钢铁,1989,24(6):4-8.
[5]郜传厚,渐令,陈积明.复杂高炉炼铁过程的数据驱动建模及预测算法[J].自动化学报,2009,35(6):725-730.
[6]崔桂梅,蒋召国,詹万鹏,等.基于时间序列的神经网络高炉炉温预测[J].冶金自动化,2015,39(5):15-21.
[7]SAXEN H,GAO C H,GAO Z W.Data-driven time discrete models for dynamic prediction of the hot metal silicon content
in the blast furnace:A review[J].IEEE Transactions on Industrial Informatics,2013,9(4):2213-2225.
[8]唐贤伦,庄陵,胡向东.铁铁水硅含量的混沌粒子群支持向量机预报方法[J].控制理论与应用,2009,26(8):838-842.
[11]刘祥官,王文慧.应用小波分析方法改进铁水硅含量预测[J].钢铁,2005,40(8):15-17.
[12]高小强,王逸名.高炉铁水硅含量预测评价与模型选择[J].钢铁研究学报,2007,19(5):5-9.
[13]贺诗波.高炉硅含量预测控制的时间序列混合建模[J].浙江大学学报(工学版),2007,41(10):1739-1742.
[14]谢灵杰.高炉铁水硅含量预测中的直接经验和间接经验[D].重庆:重庆大学,2003:1-28.
[15]孙桂利.时间序列方法在临钢六号高炉铁水含硅量预测中的应用[D].西安:西安建筑科技大学,2001:1-16.
[16]李爱莲,赵永明.基于灰色关联分析的ELM高炉温度预测模型[J].钢铁研究学报,2015,27(11):33-37.
[17]何勇,鲍一丹,吴江明.随机型时间序列预测方法的研究[J].系统工程理论与实践,1997(1):22-27.
责任编辑:陈亮
A Time Series Prediction Model for Hot Metal Silicon Content in Blast Furnace at Different Times
LIU Chuanwu1,LI Xinguang2,WU Cailin1,ZHANG Qingfeng1
(1.Maanshan Technical College,Maanshan 243031;2.School of Electrical and Information Engineering,Anhui University of Technology,Maanshan 243002)
Abstract:With complicated physical and chemical reactions taking place in the blast furnace,temperature is the key to ensure the smooth operation of the blast furnace.The temperature of the blast furnace is proportional to the silicon content of molten iron.Transfer function model is used to predict the Si content,and temperature information of the blast furnace can thus be obtained.Pulverized coal injection rate,blast volume and flow rate of cooling water are chosen to be input variables,the model for predicting Si content at different times is built through using transfer function model.Logarithmic pretreatment of the original data is proposed to reduce the prediction variance.It is found that the model can predict Si content accurately,and the prediction accuracy is above 93%.
Key words:blast furnace hot metal;Si content;time series method;transfer function model
doi:10.3969/j.issn.1671- 0436.2016.02.005
收稿日期:2016- 03- 03
基金项目:安徽省教育厅高校自然科学研究重点项目(KJ2016A697;KJ2016A698)
作者简介:柳传武(1974—),男,硕士,讲师。
中图分类号:TF543;TP391
文献标志码:A
文章编号:1671- 0436(2016)02- 0020- 05
