语言学的交叉学科研究:语言普遍性、人类认知、大数据
2016-06-06梁君英刘海涛
梁君英 刘海涛
(浙江大学 外国语言文化与国际交流学院,浙江 杭州 310058)
主题栏目:语言与认知研究(学术访谈)
语言学的交叉学科研究:语言普遍性、人类认知、大数据
梁君英 刘海涛
(浙江大学 外国语言文化与国际交流学院,浙江 杭州 310058)
麻省理工学院学者近期发表在国际顶尖期刊《美国科学院院报》上的一项语言学交叉研究利用已经公开发布的依存树库,对37种语言进行了统计分析,指出人类语言存在依存距离最小化这一倾向。此研究被媒体热议,但却存在一些缺陷。依存距离是两个句法相关词之间的线性距离,受工作记忆机制的约束,与句法处理的复杂度密切相关。因此,人类语言具有依存距离最小化的倾向。基于句法标注语料库的依存距离最小化研究表明,大数据研究方法在语言认知研究中具有重要作用。现代语言学具有鲜明的交叉学科色彩,语言研究中不同学科的相互借鉴与融合有助于深入揭示语言系统的运作规律以及语言与认知之间的关系。
依存距离最小化;语言普遍性;认知科学;大数据
访谈时间:2015年9月22日 访谈地点:浙江大学紫金港校区青荷悦空间
访谈主持人:梁君英教授(以下简称为梁) 访谈嘉宾:刘海涛教授(以下简称为刘)
梁:今天我们在这里举行一个有关国家社科基金重大课题“现代汉语的计量语言学研究”的访谈,我想先从一个目前非常热门的话题开始。最近我们听说麻省理工学院(MIT)的大脑与认知科学系有一个重大成果:他们发现人类语言中可能存在依存长度最小化(Dependency Length Minimization,DLM)这样一个普遍规律。这项研究发表在PNAS也就是《美国科学院院报》上[1],八月初刚刚在线优先发表(early edition)就在学界引起广泛关注,随后美国的许多媒体都对此进行了长篇报道,我想问一下刘老师,您对这个问题是怎么看的?
刘:语言研究很少能够引起主流媒体的关注。MIT的这项研究在美国《科学》杂志、MIT新闻网站以及许多其他媒体的主要位置进行了报道,这种情况是不多见的。我们知道,尽管语言学家一再强调他们的研究很重要,认为语言学是一门领先科学(pilot science),但在科学家面前说语言学是领先科学是比较尴尬的一件事。但这次MIT的研究确实得到了大家的广泛关注,这是因为他们的研究迎合了我们当今时代一些主要的热点:第一,语言研究之所以重要,是因为通过语言研究我们可以了解人的认知。研究认知的方法多种多样,但从人的外在特性来看,人与其他动物的区别在于人有一个比较复杂的语言系统。与其他研究路径相比,语言是人每天都用得到的,研究材料极易获得,因此,通过研究语言来研究人的认知是认知科学里较为热点的内容。MIT这次研究的主题恰好可以把语言和人的认知联系在一起。第二,这几年有个热词叫“大数据”,在这项研究里也使用了来自多种语言的大量数据。第三,MIT认为这项研究发现了人类语言的一个普遍特征。这三点加起来刚好符合这个时代科学研究的特征,所以引起关注也并不是特别奇怪的事情。
梁:刘老师提到了我们今天访谈的三个关键词:语言、人类认知、大数据。我也听说在心理学科里有一个共识,认为语言是人类的平均认知规律,现在MIT实验室采取了大数据的手段对此进行了研究。刘老师可不可以先为我们介绍下这篇文章的主要内容?
刘:这篇文章的标题是《用37种语言来验证依存长度最小化》。首先,在一项研究中出现37种语言不是一件容易的事情,这里关键还有一个依存长度最小化,这是这篇文章的一个核心概念。依存长度是什么呢?我们平时说的句子是一个线性的词串,句子里的每个词之间是有联系的。如果对这个线性词串进行句法分析,把句中有句法关系的词连起来,就能形成一个句子的结构树或结构图。这是人类理解语言的第一步。那么问题就来了,如果句法分析是要把线性的词串变成结构树或图的话,两个相联系的词之间就存在线性的距离。比如图1为“我吃一个大苹果”的依存分析,“我”和“吃”之间有联系,“吃”和“苹果”之间有联系,“大”和“苹果”之间有联系,“个”和“苹果”之间有联系,“一”和“个”之间有联系,这样每个词在句中都被两两的词间关系联系起来。“我”和“吃”是挨着的。但“吃”和“苹果”之间有三个词,分别是“一”、“个”、“大”。
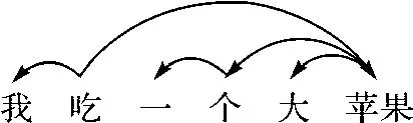
图1 “我吃一个大苹果”的依存分析
也就是说,形成依存句法关系的词与词之间的距离有远有近,这篇文章称这个距离为长度,长度是美国的叫法。在依存句法的发源地欧洲,一般称之为距离。依存距离或者依存长度是依存语法框架下的一个概念,因为依存句法分析方法关注词与词之间的关系。但在生成句法框架里,词与词之间的关系并不重要,更关注部分与整体的关系。
依存距离我们理解了,那最小化是什么呢?大概早在20世纪初的时候,人们就注意到自然语句中,有依存关系的词在一个句子中靠得比较近[2]。说得理论点,就是一个句子中词的顺序一般倾向于使这个句子的依存距离尽可能小。但过去人们没有计算机,单纯靠手数,数了十几个、几百个句子就觉得有这样一种倾向,但都没能取得突破性的进展。随着计算机以及语料库的普及,特别是在1990年左右有句法标注的语料库(树库)的出现,为我们真正地采用大规模真实语料研究依存距离最小化提供了可能。2004年,西班牙学者Ramon Ferrer-i-Cancho在《物理评论E》上发表了一篇文章,题为《存在句法联系的词之间的欧几里得距离研究》[3],实际就是依存距离研究。他考察了一个罗马尼亚语的树库,发现在大规模的真实语料中,依存距离趋向于一个比较小的值。这两年,捷克布拉格大学等机构推出了一些树库项目,加起来涵盖了三四十种语言。这次MIT的研究就是利用这些已经公开发布的依存树库,对37种语言进行了统计分析,发现人类语言确实存在依存距离最小化的倾向。他们在文章中也承认这个想法早就有了,但强调指出过去的研究总共只做过7种语言的依存距离最小化研究,因此,他们的研究是世界上第一个用大规模、跨语言的语料验证依存距离最小化的。这是他们的一个主要观点。有关新闻报道也都强调MIT是第一个用多种语言来进行依存距离最小化研究的,我认为这也是这篇文章能够被PNAS录用并发表的主要原因。语料是别人的,计算依存距离最小化的方法是别人的,这个想法也是别人的。MIT只是说,过去只有7种语言,但现在他们的研究用了37种,当然7和37还是很不一样的。他们的研究大概就是这样一个情况。
梁:现在国内语言学在宣传报道方面跟进得非常快。前段时间,国内语言学界的各种网络媒体与微信平台都推送了这一研究,并宣称这是对乔姆斯基研究的进一步推进。刘老师,您刚才提到的这些,是不是说MIT的研究跟乔姆斯基尤其是他的普遍语法(UG)之间并没有太大关系呢?
刘:将两者联系起来的实际上是国外的一个新闻报道[4]。乔姆斯基说人类语言有一个普遍语法,这种普遍语法隐含于语言表面的多样性。有人便将乔姆斯基与此项研究联系起来。但实际上两者之间可能没什么关系。乔姆斯基认为人的大脑里有一个专门主管语言的东西,是天生的,具有普遍性[5]。至于它到底是什么,目前人们还确定不了。但Gibson实验室的这项研究似乎为乔姆斯基的普遍语法带来了新的曙光。实际上两者关系可能并不大,依存距离最小化与人的工作记忆有关。依存语法中,依存关系存在于从属词和支配词之间。一个词只有找到它的支配词或者从属词,才能形成一个更复杂或者更明晰的概念。在“我吃一个大苹果”这个句子中,我们听到“吃”的时候,由于不知道后面跟的是什么,就要把这个词记住,同样,我们要把后面出现的“一”、“个”、“大”等都记住,这样,在听到“苹果”的时候,我们才能把这些词语从记忆中移开。具有依存关系的两个词之间的词越多,短时间内我们需要记住的内容也就越多。因此,依存距离最小化实际上是认知特别是工作记忆容量对语言结构的一种约束。工作记忆并非仅仅用于语言处理,而是人的普遍认知机制的一部分。也就是说,依存距离最小化是人类普遍认知机制对语言线性排列约束的结果。换句话说,依存距离最小化实际上和乔姆斯基所说的普遍语法(或者说大脑中专门的语言模块)没有什么直接联系。
梁:我记得不久前看您的微信,您转发了“语言学午餐”微信平台推送的这个报道后,同时贴上了你们团队大约在七八年前就发表的一个类似的研究。如果我的理解是正确的,其实你们的研究远远地走在MIT之前,您能不能分享一下你们团队研究的主要内容,或者说你们的研究跟他们的有什么区别呢?
刘:我们团队研究依存语法大概开始于1987年前后,那是很久之前的事了。我们当时对依存语法进行研究的一个主要原因就是如果要研究语言,首先要寻找一种普适的语言分析方法,先不管后面的机制是什么,至少这种方法应该能够分析尽可能多的语言。像短语结构语法,分析英语这样语序相对固定的语言还比较容易对付;但如果分析像斯拉夫语族的语言,比如捷克语和俄语,就会遇到很大的困难。这时我们发现,还有一种来自欧洲的语法体系叫依存语法(Dependency Grammar)[67],我们就开始对它进行系统的了解。从1987年到现在,我们对依存语法的研究持续了很长时间。在这个延续的研究中,我们自然而然地遇到了这个依存距离的问题。大约在1995年前后,英国Hudson教授写过一篇文章,第一次在现代依存句法框架下提出了依存距离的计算方法[8]。当时Hudson和他的几个博士研究生对英语、德语和日语的依存距离进行了分析。因为条件限制,他们在20世纪90年代的研究中基本没有使用语料库。到了2003年、2004年前后,我们采用依存语法试着建立了一个汉语的树库,即采用依存句法标注的语料库,我们发现汉语的依存距离要比英语大很多[9]。这一结果非常有意思,因为Hudson和他的学生发现日语、英语、德语的依存距离都差不多。Hudson认为我们这个发现非常重要[10],因为依存距离和人类认知密切相关,而一般认为,无论说哪一种语言,人的工作记忆容量是相似的,但我们的结果显示中文的依存距离显著地大于其他语言。在语言与认知领域有一个著名的假说,叫萨丕尔-沃尔夫假说[11]。这个假说认为语言会影响思维模式等与认知密切相关的东西,但一直没有找到直接的例证来说明。而汉语的依存距离大也许从另一个角度为这个假说提供了一个佐证。
我们也觉得搞清楚这个问题是非常有趣的,我就让我的几个硕士和博士生来专门研究这个问题。也就是说,实际上我们对依存距离的研究始于12年以前,是自然地通过研究依存语法发现的。既然已经发现汉语的依存距离比其他几种语言要大,我们当然就会想到扩大样本库。在2004年左右,我们就开始在世界各地寻找依存树库。大概到了2005年底、2006年初的时候,我们大约收集到了20种语言的样本,包括我们自己标注的样本。我们发现在这20种语言里,汉语的依存距离仍然是最大的。此外也发现其中大概有十四五种语言基本上是一样的,表明大部分语言的依存距离都是差不多的,符合依存距离与人类工作记忆密切相关的想法。此外,我们也生成了两种随机语言,与这20种真实自然语言的依存距离进行比较。所谓随机,就是说这不是人类真正的语言,是不符合语法的。所以不管你采用怎样的随机策略,都只是计算效率的问题,没有语言学意义,因为已经不符合语法了。我们就做了两种随机语言,一是完全随机,只要符合依存句法的普遍规律,不控制句法树的交叉结构;第二就是保证不交叉。这样就得到了两种随机语言。计算它们的依存距离并与上述20种语言的依存距离相比较,我们发现真实语言的依存距离更小。这实际上是在人类历史上第一次用大量真实语料揭示自然语言中的依存距离最小化倾向。在十年前,这是很新的东西,很多人不太理解。这些研究成果写成文章后,几经周折,于2008年发表在国际认知科学协会的会刊《认知科学学报》上[12]。这篇文章提出了明确的假设:人类语言的句法分析器偏好于依存距离最小化的句子,实际上就是说距离最小化是人类语言普遍的特征,这一点我们在该文的摘要里也明确提到了。此外,和MIT的研究相比,我们做得更加全面:我们关注的点比他们多,我们和认知的联系也更紧密一些,我们和依存句法的联系是水到渠成的。但后来我们没有过多地宣传这个。因为计算依存距离用的是文本,其结果可能受诸多因素影响,比如,不同语言的影响,文本大小的影响,文本主题的影响,同样,标注方式也会影响这个结果。在没有弄清这些可能的变量之前,不能简单地得出结论,因为对科学家而言这是不够严谨的。所以2008年以后,我们还在不断地完善对依存距离最小化的理解,继续研究有哪些因素在影响依存距离最小化。
梁:这显然是很长的一段历史了。从1987年开始,刘老师团队就已经关注欧洲的依存语法体系;在过去的28年里,这个团队一直做着孜孜不倦的努力。比较有代表性的成果之一就是刚才提到的2008年的那篇文章。通过对20种语言进行的大规模跨语言比较研究,并得到一个结论:依存距离最小化倾向可能是人类语言的一个普遍规律。这对之后的研究起到了重要的推动作用。听到这里大家可能会跟我一样感到惊讶,因为刚刚说到MIT的这个研究出来之后,许多媒体都不断地推送,有一句话特别引人注目:“这是人类历史上第一次大规模的跨语言的研究发现的普遍规律”,而且还特别强调说前期研究加起来都不超过7种语言,很明显这里存在一个错误。我很想知道,刘老师您这个团队针对这个问题有没有做出什么回应?
刘:首先还是要说技术上的一些细节。因为依存距离的算法有两类,第一类是 Hudson提出的,从欧洲的依存句法发展来的算法,其语言学的实用意义和价值较大[8]。依存距离可以判别一个句子的理解难度。就是说一个句子的依存距离越大,理解难度越大,这样就会存在不同句子长度之间的比较。比如,有5个词的句子,6个词的句子,还有的句子是13个词的。有时13个词的句子并不一定比5个词的难。你要计算依存距离的指标,不同句子之间的难度应该是可以比较的。如果需要进行比较,你就要把句子长度的因素去掉。否则只是简单地把句子里面的依存距离相加,长的句子永远是难的,但实际上它并不一定难。而采用平均值就可以消除句子长度带来的影响,也就是说,依存距离加起来再除以句长。句子中的根词是没有词支配它的,要把这个词减掉。这样一来,不同长度的句子的难度就可以进行比较了,这是欧洲学者和我们采用的算法。第二类是两位美国学者在2007年左右提出的一套算法[13-14],MIT的研究用的就是这一套算法。他们只是把句子中的依存长度加起来。就刚才说的那个句子“我吃一个大苹果”,按照我们的算法这个句子的平均依存距离是9÷5=1.8,而MIT得到的该句的依存距离为9。显然,他们这种计算会导致不同长度的句子之间很难比较。在我们2008年的文章里,不同语言可以比较平均依存距离[12]。而MIT的研究没有办法做这样的比较,于是就把37种语言中的每种语言都画了图表[1]。也就是说,它的最小化实际上只是一个图示化的说明。
MIT的这篇文章说“这是人类历史上第一次大规模的跨语言的研究发现的普遍规律”,强调先前研究所涵盖的语言不超过7种[1]。正如你所说,这些表述不太准确。我们在七八年前就做过了针对20种语言的依存距离最小化研究,取得了类似的研究成果[12]。因此,MIT文章说他们是第一次大规模的跨语言研究,这是有失偏颇的。此外,依存距离可能受到很多因素的影响,这些因素在该文中都没有提到过,这也是一个问题。另一个问题是,他们在做随机语言时考虑了太多语言学的因素,没有做到完全的随机,这也削弱了该研究的说服力。还有一点,他们说支配词在后面的语言和支配词在前面的语言与依存距离是有相关性的,这个说法也是比较随意的。前人的很多研究表明,说这两者之间有相关性还为时尚早。
针对MIT文章中的上述问题,我们写了一篇文章进行了质疑,并把这篇文章放在了arXiv预印网站上[15]。麻省理工学院的三位作者看到后,对我们这篇文章做了回应[16]。在他们看来,我们的质疑是有道理的,并分别对这些质疑进行了解释与说明。特别是对文章中“以往的研究没有超过7种语言”等表述问题向我们致歉,承认忽视了我们之前的工作是一个错误,并表示将在PNAS上对这一点进行说明与更正。在PNAS随后刊登的更正中,MIT论文的作者认为我们2008年的研究是一项从更普遍的角度验证依存距离最小化的研究,而他们自己则更关注语序变化对依存距离最小化的影响。MIT的作者认为他们的工作是对我们2008年的文章等前人研究的一个补充与精细化,并强烈建议阅读他们文章的研究者同时也应该了解我们2008年的研究。
梁:这样说来,刘老师您的团队和MIT实验室的交锋是卓有成效的。一方面,充分说明了我们浙江大学计量语言学的研究团队已经真正走到了世界前列;另一方面,也许我们的研究团队与MIT团队会有很大的合作空间,当然如果您愿意的话。
刘:你用“交锋”这个词,显得火药味太浓了。应该说,这是一个比较正常的学术讨论。我们也不能通过这一个事情就说我们已经在世界前列了,即使我们在采用依存句法树库的语言研究方面确实比国外的学者早了几年,但仍然需要进一步努力。一时走在前面不难,难的是一直走在前面。MIT的Gibson团队在语言认知方面的研究目前处于世界前列,而我们在采用标注语料库以及语言复杂网络方面的研究要更胜一筹,如果我们两家可以合作的话,相信会取得一些有意义的研究成果。MIT这三位作者在他们的邮件和书面回应中,也表达了想与我们合作的愿望。
梁:回顾过去,我们可以发现从1987年开始,刘老师已经付出二十多年孜孜不倦的努力,成果颇丰,有一系列专著和论文。您可以向大家分享一下过去二十年内您对依存距离研究做出的贡献吗?
刘:至今为止,依存距离这个领域可供参考的资料都非常少,也很难找得到。为了满足大家的需求,我们从1987年开始收集资料,于2009年在科学出版社出版了《依存语法的理论与实践》一书[17]。这本书包含了该领域涉及的主要问题,对参考文献和前人所做的研究都有详尽的介绍,覆盖范围很广。2007年,我们在Glottometrics上发表了一篇《依存距离的分布》的文章[18]。这篇文章的一个主要发现是,一个句子偏好依存距离最小的排序,主要是因为依存距离的分布是有规律的。MIT的这几位作者在他们去年的一个poster论文里也引用了这篇文章。有趣的是,我们在2007年的这篇文章里也研究了依存距离最小化。当时,我们发现真实语言文本的依存距离基本成一条直线,而且明显小于几种随机语言。这明确表示自然语言中存在依存距离最小化的倾向。
2007年,我们还利用依存树库研究依存距离和依存关系,在MTT(意义文本理论)的国际会议上发表过一篇文章,提出了依存距离最小化以及不同类型的依存关系优选的依存方向也不同[19]。2009年发表在《语料库和语言学理论》杂志的文章中,我们不但提出了依存距离(MDD)的计算公式,也明确指出汉语的依存距离是最大的[9]。2009年我们还利用多个树库研究了语言的依存距离相关计量特征,结果发现语料的规模、语体、标注方式、句长等因素都可能对依存距离及依存方向产生影响[20]。2010年,我们用依存方向作为指标,从类型学角度研究了语言分类。该成果发表在Lingua上,这是第一个大规模真实语言数据支持的依存方向或语言类型研究[21]。2012年,我们发表了一篇关于罗曼语族语言特征的文章,主要解决两个问题:第一,从共时的角度,是否可以找到区分罗曼语言和其他语言的客观指标?第二,从历时的角度看,如果存在罗曼语族,那个指标是否可以区分现代罗曼语和拉丁语呢[22]?我们用了15种语言的依存树库,包括古希腊语、拉丁语以及现代罗曼语族等六种主要语言。这个研究明确显示依存方向(支配词置后或置前)和依存距离关系不大,这可以从一个侧面说明MIT文章的最后一个观点有问题。2013年,我们对语码转换句子中的依存距离进行了研究,成果发表在Lingua上[23]。2015年年初,我们采用双语平行依存树库对句子长度与依存距离及方向的关系以及相邻依存关系数量等进行了研究,成果发表在Language Sciences上[24]。在罗曼语言的研究中我们还发现:现代语言依存距离较短,因为现代语言考虑到人们当面交流的需要;而以书面语为主的古典文本,比如拉丁语及古希腊语,依存距离偏大[22]。我们后来从世界语的文本中也发现这样的特点[25]。这是我们在依存距离方面做的一些主要研究,还有一些其他的相关成果,这里就不一一介绍了。
梁:从刘老师的介绍中我们不难发现三个贯穿始终的关键词:语言的普遍性、人类认知规律和大数据。在这样一个研究背景下,您是如何把这三个热点融合在一起,构建出非常系统的研究框架的?
刘:这可能因为我初涉语言学领域的经历和别人不同。我最早是学自动化的工科生,对系统的概念理解比较深刻。不过之前研究的是工业控制系统的运行规律,现在研究的是语言系统的运作规律。语言的规律蕴藏在每天的听说读写中,我们的研究就是从实际发生的自然文本中找规律。为了发掘具有普遍性的语言规律,需要收集大量的语言数据。相比传统的语言学研究方法,这就算是大数据或数据密集型语言研究了,这是我们从十几年前就开始使用的方法。我们大部分人都将语言的普遍性理解成多种语言的普遍规律,所以我们需要用大量的数据来挖掘多种语言存在的规律。语言研究的价值和意义就是发现人类认知机制、社会及文化对语言系统的形成与运作的影响。语言作为由人驱动的符号系统,受到大脑的约束和限制,所以语言学家希望通过自然语言挖掘到认知规律,通过认知规律来解释语言规律。就一个很长的词而言,如果其使用频率突然增加,这个词就会变得很短。这就是语言受认知约束的一个明显例子。如果我们从这个角度来理解语言的话,就不难意识到语言研究的框架中包括了语言的普遍性、人类认知规律以及大数据等内容。
梁:谢谢刘老师。刚才刘老师通过交叉学科的视角分析了语言作为一个系统的概念。英国的《自然》杂志最近一期的封面有一句话很醒目:Why scientists have to work together to save the world,指出了交叉学科的重要性。请问您对语言学的交叉学科发展有什么建议呢?
刘:学科的划分本身就是人类因为能力所限而做出的一种不合理的做法。人类对人本身、人所处的社会以及大自然的运行规律感兴趣,却又受能力所限,且每人特长不同,所以才将学科区分开来,如同盲人摸象的过程。随着科学的发展和技术的进步,人类通过辅助工具扩大自己能力的可能性大大提高,原来只有精力与能力研究大象腿为什么动的人现在也可以联系其他部位来做出解释。但从研究本身而言,不存在交叉的问题,因为本身就是一个系统。既然语言研究也是研究系统的规律,为何我们不与时俱进,借鉴进步迅速、成果丰硕的研究系统的其他方法和工具促进语言学的学科发展呢?
梁:最近五年,刘老师的团队在学科交叉上做出了显著成绩,为浙江大学的语言学学科发展做出了重要贡献。2011年,该团队获得了国家社科基金首批跨学科重大课题,这是浙江大学第一个交叉学科的重大课题。2014年,刘老师团队的论文发表在Physics of Life Reviews[26],一个影响因子高达9.478的高端学术期刊。在浙江大学积极推进世界一流大学和一流学科建设的大环境下,浙江大学外语学院也在制定一流基础骨干学科的建设方案。那么,我很想知道,您对人文学科发展有什么期待和建议呢?
刘:前几天教育部公示的第七届社科奖,我们发表在《科学通报》的采用平行语言网络进行语言分类研究的文章在交叉学科类获得三等奖[27]。从第四届到第七届教育部社科奖的 12年内,这可能是第一个获得交叉学科奖的语言学文章。我们也有另外两项语言学的交叉学科研究双双获得了2015年浙江省第十八届哲学社会科学优秀成果二等奖[23,28]。2015年初,我们有两篇文章入选ESI的全球百分之一的高被引文章,一个是刚才提到的发表在Physics of Life Reviews的文章[26],另外一个关于语言层级网络的文章,发表在Journal of Chinese Linguistics上[28]。这意味着我们学院或者浙大人文学科有两门学科(社会科学类、生物学与生物化学类)进入ESI。能做出这样的成绩,是因为我们借鉴了其他学科较为成熟的方法来研究人类语言的问题,也就是大家说的交叉学科或跨学科。过去我们常认为,人文学科主要靠人类自己的聪明才智思考人类的过去与未来。而在这个到处都是数据的信息时代,可能应该借鉴一些其他学科的方法与范式来研究人文。我认识的一位荷兰人Rens Bod写过一本书叫《人文新史》,他综述了世界几大文明传统人文领域的发展。这本书的副标题是《从古到今对原则与模式的探索》[29],这意味着人文本身也是探索人类模式和规律的。所以语言学可能应该借鉴探索模式和规律的研究方法。如果你使用古人不曾有的工具和方法,你对人本身的认识、对社会的认识、对自然的认识可能就会更深入一些。
梁:在访谈结束之前,刘老师可不可以分享一下在学术研究过程中有什么样的愿景或信念?
刘:我理解的语言学是探索语言结构和演化规律的科学。在我来浙江大学的五年里,着重在两个方向进行了努力:一是中国语言学的国际化,二是语言学研究的科学化。我希望在退休之前还能为这“两化”做一点力所能及的事情。
梁:我非常期待在场的各位老师和同学们牢记我们的理念,为实现语言学研究的“国际化与科学化”做出坚持不懈的努力。感谢刘老师的分享!感谢各位老师和同学们的参与!
(感谢徐春山博士参与访谈题目的讨论、访谈内容的确定、访谈文本的后期整理工作;感谢敬应奇、方圆圆、牛若晨等研究生为本文所做的文字转写工作!)
[1]R.Futrell,K.Mahowald&E.Gibson,″Large-scale Evidence of Dependency Length Minimization in 37 Languages,″Proceedings of the National Academy of Sciences,Vol.112,No.33(2015),pp.10336-10341.
[2]O.Bhhaghel,″BeziehungenZwischenUmfangundReihenfolgevonSatzgliedern,″ Indogermanische Forschungen,Vol.25(1909),pp.110-142.[O.Behaghel,″Relations between the Scope and Order of Sentence Elements,″Indo-European Research,Vol.25(1909),pp.110-142.]
[3]F.I.C.Ramon,″Euclidean Distance between Syntactically Linked Words,″Physical Review E,Vol.70,No.5 (2004),pp.148-168.
[4]C.O’Grady,″MIT Claims to Have Found a′Language Universa′lThat Ties All Languages Together:A Language Universal Would Bring Evidence to Chomsky’s Controversial Theories,″2015-08-06,http://arstechnica.co.uk/ science/2015/08/mit-claims-to-have-found-a-language-universa-ltha-tties-al-llanguages-together/,2015-08-16.
[5]N.Chomsky,Language and Thought,Wakefield:Moyer Bell,1983.
[6]L.Tesn iè re,E lé ments de La Syntaxe Structural,Paris:Klincksieck,1959.[L.Tesn iè re,Elements of Structural Syntax,Paris:Klincksieck,1959.]
[7]R.Hudson,An Introduction to Word Grammar,Cambridge:Cambridge University Press,2010.
[8]R.Hudson,″Measuring Syntactic Difficulty,″http://www.phon.ucl.ac.uk/home/dick/dif culty.htm,2008-07-06.
[9]H.T.Liu,R.Hudson&Z.W.Feng,″Using a Chinese Treebank to Measure Dependency Distance,″Corpus Linguistics and Linguistic Theory,Vol.5,No.2(2009),pp.161-174.
[10]R.Hudson,″Foreword,″in H.T.Liu(ed.),Dependency Grammar:From Theory to Practice,Beijing: Science Press,2009,pp.52-59.
[11]J.B.Carroll(ed.),Language,Thought and Reality,Cambridge:MIT Press,1956.
[12]H.T.Liu,″Dependency Distance as a Metric of Language Comprehension Difficulty,″Journal of Cognitive Science,Vol.9,No.2(2008),pp.159-191.
[13]D.Temperley,″Minimization of Dependency Length in Written English,″Cognition,Vol.105,No.2(2007), pp.300-333.
[14]D.Gildea&D.Temperley,″Do Grammars Minimize Dependency Length?″Cognitive Sciences,Vol.34,No.2 (2010),pp.286-310.
[15]H.T.Liu,C.S.Xu&J.Y.Liang,″Dependency Length Minimization:Puzzles and Promises,″2015-09-15, http://arxiv.org/abs/1509.04393,2015-09-16.
[16]R.Futrell,K.Mahowald&E.Gibson,″Response to Liu,Xu,and Liang(2015)and Ferrer--iCancho and G ó mez-Rod rí guez(2015)on Dependency Length Minimization,″2015-10-01,http://arxiv.org/abs/ 1510.00436,2015-10-03.
[17]刘海涛:《依存语法的理论与实践》,北京:科学出版社,2009年。[Liu Haitao,Dependency Grammar: Theory and Practice,Beijing:Science Press,2009.]
[18]H.T.Liu,″Probability Distribution of Dependency Distance,″Glottometrics,Vol.15(2007),pp.1-12.
[19]H.T.Liu,″Dependency Relations and Dependency Distance:A Statistical View Based on Treebank,″in K. Gerdes,T.Reuther&L.Wanner(eds.),Meaning-Text Theory2007:Proceedings of the3rd International Conference on Meaning-Text Theory,Klagenfurt,May20-24,2007,M ü nchen:Verlag Otto Sagner, 2007,pp.269-278.
[20]H.T.Liu,Y.Y.Zhao&W.W.Li,″Chinese Syntactic and Typological Properties Based on Dependency Syntactic Treebanks,″PoznańStudies in Contemporary Linguistics,Vol.45,No.4(2009),pp.509-523.
[21]H.T.Liu,″Dependency Direction as a Means of Word-order Typology:A Method Based on Dependency Treebanks,″Lingua,Vol.120,No.6(2010),pp.1567-1578.
[22]H.T.Liu&C.S.Xu,″Quantitative Typological Analysis of Romance Languages,″Poznań Studies in Contemporary Linguistics,Vol.48,No.4(2012),pp.597-625.
[23]L.Wang&H.T.Liu,″Syntactic Variation in Chinese-English Code-switching,″Lingua,No.1(2013), pp.58-73.
[24]J.Y.Jiang&H.T.Liu,″The Effects of Sentence Length on Dependency Distance,Dependency Direction and the Implications:Based on a Parallel English-Chinese Dependency Treebank,″Language Sciences,Vol.50 (2015),pp.93-104.
[25]H.T.Liu,″Quantitative Analysis of Zamenhof’s Esenco Kaj Estonteco,″Language Problems&Language Planning,Vol.35,No.1(2011),pp.57-81.
[26]J.Cong&H.T.Liu,″Approaching Human Language with Complex Networks,″Physics of Life Reviews, Vol.4(2014),pp.598-618.
[27]H.T.Liu&J.Cong,″Language Clustering with Word Co-occurrence Networks Based on Parallel Texts,″Chinese Science Bulletin,No.10(2013),pp.1139-1144.
[28]H.T.Liu&J.Cong,″Empirical Characterization of Modern Chinese as a Mult-ilevel System from the Complex Network Approach,″Journal of Chinese Linguistics,No.1(2014), pp.1-38.
[29]R.Bod,A New History of the Humanities:The Search for Principles and Patterns from Antiquity to the Present,Oxford:Oxford University Press,2013.
Interdisciplinary Studies of Linguistics:Language Universals,Human Cognition and Big-data Analysis
Liang Junying Liu Haitao
(School of International Studies,Zhejiang University,Hangzhou310058)
This interview examines a recent study on Dependency Distance(length)Minimization, introduces earlier works on and the significance of this topic.
Dependency distance,or,dependency length,is taken as an insightful metric of syntactic complexity in the framework of dependency grammar(DG).According to dependency grammar, the syntactic structure of a sentence consists of nothing but dependencies between individual words— an assumption that is widely accepted not only in computational linguistics but also in theoretical linguistics.A dependency relation has the following core properties:it is a binary relation between two linguistic units;it is usually asymmetrical,with one of the two units actingas the governor and the other as dependent;it is classified in terms of a range of general grammatical relations,as shown conventionally by a label on top of the arc linking the two units.
Sentences are linearly unfolded,and as a result,the governor and the dependent may or may not be adjacent.That is,there may be different linear distances between governors and dependents.This linear distance is termed as dependency distance(length),usually measured by the number of the intervening words between them,which is believed to have much to do with parsing(processing)difficulty.
In terms of dependency grammar(DG),the syntactic parsing of a sentence is based on successive input of individual words,committed to establishing,at each parsing state,syntactic relation between the presently processed word and a previous one.As a cognitive activity, syntactic parsing is complemented via working memory,on which different burdens may be imposed by different dependency distances:the intervening words may either strain the capacity the WM or result in,owing to time-decay of memory,difficult retrieval of a previous word. Hence,longer dependency distance,or more intervening words,probably means more syntactic complexity and higher cognitive cost in processing.
Given the cognitive possibility that dependency distance positively correlates with syntactic complexity and processing difficulty,it may be assumed that human languages,which are definitely constrained by general cognitive mechanisms,should prefer structures with short dependency distances for the sake of less demand on working memory resources.This tendency is termed as Dependency Distance Minimization(DDM):in natural languages,a sentence should be structured in such a way so as to minimize its overall dependency distance syntactically related words in this sentence.The DDM hypothesis is presumed as one possible linguistic universal motivated by general human cognition.
Obviously,the hypothesis of DDM is deduced from the cognitive assumption that working memory is limited in capacity and subject to time-invoked forgetting.Thus the validity of this hypothesis should be empirically tested.Evidences in support of the preference for short dependency distance were first found in comprehension experiments on different types of relative clauses(RC).However,due to the high cost and laboriously careful design,the experiments are usually conducted upon a small number of subjects and a limited range of artificially composed linguistic material.Therefore,when it comes to language universals like DDM,large corpusbased quantitative study may serve as a significant supplement to psychological experiments, especially in this big data era.Verbal communication is by nature a type of human behavior which is regulated,to a considerable degree,by human cognition.That is,there might well be some cognition-shaped patterns or universals in language.With the development of computer science, big-data-based statistical analysis has become one important means to detect patterns in various human behaviors.In this sense,large-scale corpus,which gives researchers easy access to big data of verbal behaviors,may contribute much to scientific linguistic researches that aim to detect linguistic patterns and to trace their cognitive motivations.In other words,if DDM is a general cognition-shaped tendency in language,corpus-based big-data analysis should be able to detect this tendency.What is noticeable is that investigation into DDM demands a dependency treebank, that is,corpus annotated with syntactic relations between words,because DD is concerned withthe linear length of the syntactic relations between words.
This interview briefly reviews the cognitive DDM researches based on corpus-data and comments on some existent problems and future directions in this field.In the past,linguistic universals were rarely considered in terms of cognitive constraints and seldom pursued through corpus-based big-data analysis.However,as expounded in this interview,researches into DDM in human languages reveal that it is valuable to cognitively investigate linguistic universals through statistical analysis of big-language-data,which strongly suggests that,to obtain truly scientific discoveries,it may well be essential for linguistic studies to integrate efforts from multiple disciplines— cognitive science,mathematics,physics and biology,to name just a few.
Dependency Distance Minimization;language universals;cognitive science;big-data
2015-10-23[本刊网址·在线杂志]http://www.journals.zju.edu.cn/soc
[在线优先出版日期]2016-01-06[网络连续型出版物号]CN33-6000/C
国家社会科学基金重大项目(11&ZD188)
1.梁君英(http://orcid.org/0000-0002-3603-294X),女,浙江大学外国语言文化与国际交流学院教授,博士生导师,心理学博士,主要从事心理语言学、构式语法与依存语法、双语加工等方面的研究;2.刘海涛(http://orcid.org/0000-0003-1724-4418),男,浙江大学外国语言文化与国际交流学院求是特聘教授,博士生导师,文学博士,主要从事计量语言学、语言复杂网络、配价理论与依存语法等方面的研究。
10.3785/j.issn.1008-942X.CN33-6000/C.2015.10.231
