国家教育考试网上有害信息自动监测模型研究
2016-06-05杨跃东鲁欣正
杨跃东 鲁欣正
国家教育考试网上有害信息自动监测模型研究
杨跃东 鲁欣正
随着信息技术的飞速发展,互联网已成为国家教育考试有害信息传播的主要途径。为净化涉考网络环境,保障教育考试的公平和安全,在国家教育考试期间,各级考试机构安排专人利用百度、搜狗等搜索引擎,人工搜索有害信息,并上报有关部门进行处置。然而该方式存在工作效率低、搜索范围小、信息分析程度低等问题。针对这些问题,本文利用主题搜索、文本处理等信息技术手段,提出了以领域知识库为核心的有害信息自动监测模型,自动对互联网信息进行采集、去重、分类等处理,实时提供分类统计、热点分析、来源分析等基础数据。最后给出该模型与现有人工监测的协作方式,两者之间相互补充,从而形成覆盖面大、实时性强、精确度高的有害信息监控体系。
教育考试;有害信息;信息采集;信息处理;领域知识库
1 引言
随着互联网的快速发展,网络已经逐渐成为主要的信息传播途径,人们每时每刻产生的信息都能够通过互联网迅速传播。2015年7月23日,中国互联网络信息中心(CNNIC)在京发布第36次《中国互联网络发展状况统计报告》,该报告显示,截至2015年6月,我国网民规模达6.68亿,互联网普及率为48.8%。[1]全球数据信息量也呈指数式爆炸增长之势,根据国际数据公司IDC研究报告,从2010年到2020年,全球数据量会有50倍的增长,将达到40ZB(约40万亿GB)。
在互联网普及、网民数量庞大、信息爆炸增长的环境下,网络已发展成为人们日常交流、表达思想和宣泄情绪的重要平台,成为反映社会舆情的“第四媒体”。在国家教育考试领域,围绕教育考试相关的有害信息通过互联网快速、广泛传播,严重影响教育考试公平和公正性。国家教育考试的组织和管理遇到了前所未有的压力和挑战,考试组织管理不仅要打好传统考试安全战,还要打好信息战、新闻战。目前,在高考、研考、成考、自考等国家教育考试中,有害信息监测的工作方式为:各省级考试机构指派专人,利用百度、搜狗等搜索引擎进行人工搜索,将搜索结果报送教育部考试中心,经过统一汇总后报公安等有关部门。这种方式有如下几点不足:一是工作效率较低,网上有害信息监测人员需花费大量的时间在网络上通过关键词搜索有害信息,随意性较强,各省之间搜索手段趋同,工作效率较低。二是覆盖范围较小,利用百度等传统互联网搜索引擎,搜索结果数量依赖于给定关键词的多少,在有限的时间内,人工往往无法枚举所有的关键词组合,因此,信息检索的范围较小。三是缺乏有效分析,由于主要精力用于搜索和汇总,导致缺乏对有害信息的分析判断,例如类型分析、热点分析等。
针对上述问题,为了更加快速、科学、全面地监测和掌握互联网有害信息动态,本文结合国家教育考试的实际业务,充分利用主题搜索、文本处理等信息化技术手段,提出了国家教育考试网上有害信息自动监测模型,结合人工搜索,形成覆盖面大、实时性强、精确度高的有害信息监控体系,为教育考试的安全、公平和公正保驾护航。
2 网上有害信息概念界定
在学术界,网上有害信息没有形成统一的定义。目前使用最多的称呼是有害信息或不良信息。对其分类而言,不同的角度给出的分类界定也有所不同。从法律层面来看,根据《计算机信息网络国际联网安全保护管理办法》和《互联网安全保护技术措施规定》等国家法律法规,网上有害信息(互联网有害信息)包括:煽动抗拒、破坏宪法和法律、行政法规实施的;煽动颠覆国家政权,推翻社会主义制度的;煽动分裂国家、破坏国家统一的;煸动民族仇恨、民族歧视,破坏民族团结的;捏造或者歪曲事实,散布谣言,扰乱社会秩序的;宣扬封建迷信、淫秽、色情、赌博、暴力、凶杀、恐怖,教唆犯罪的;公然侮辱他人或者捏造事实诽谤他人的;损害国家机关信誉的;其他违反宪法和法律、行政法规的。[2]从信息性质来分,有些学者认为不良信息大致可以分为“违反法律”、“违反道德”和“破坏信息安全”三大类别。从信息所属领域来划分,网络有害信息可以分为“政治领域的有害信息”、“经济领域的有害信息”、“文化领域的有害信息”和“社会领域的有害信息”等多类。[3]
本文采用领域分类法,所研究的网上有害信息界定为“教育考试领域的有害信息”,即影响考试安全、公平、公正的互联网信息,具体包括:买卖答案、作弊器材、代考替考、考试作弊、漏题泄题等内容。考前重点关注买卖答案、作弊器材、代考替考等;考中重点关注考试作弊、漏题泄题等;考后重点关注考场情况、大规模舞弊等。
3 网上有害信息自动监测模型
教育考试领域的有害信息自动监测模型主要由领域知识库、信息采集、分析处理、服务应用四个部分组成,构成了以领域知识库为核心的有害信息自动监测体系。结构如图1所示。
3.1 领域知识库
领域知识库是整个模型的核心,是驱动模型自动和正常运转的基础,是区别传统搜索引擎(百度、Google、搜狗等)的关键,其选择的优劣将决定监测模型查全率和查准率。结合实际业务,本文提出了基于多维关键词的领域知识库构建方法:
(1)罗列关键词
一方面可根据业务经验人工设定关键词,另一方面可以从历年有害信息监测结果中分析和提取相关关键词。例如,根据2014年1月研究生考试2 000多条有害信息中,可抽取2014、研考、研究生考试、保过、QQ、Q、扣扣、出售、提供、发现、题目、作文题、试卷、答案等关键词。
(2)关键词分类
将上述的关键词进行细粒度拆分,并按照其属性归类,分为时间、考试类型、行为、对象、途径等类,例如“2014”、“14”、“二零一四”等属于时间类别,“发现”、“我有”等属于行为类别,“QQ”、“Q”、“扣扣”等属于途径类别。以2014年研究生考试为例,各类别样例如下:
1)时间类别={今年,2014,14,二零一四};
2)考试类型类别={研究生考试,研考,考研,硕士生,统考,研究生};

图1 国家教育考试网上有害信息自动监测模型结构
3)行为类别={购买,出售,叫卖,卖,买,提供,发现,我有,泄题,漏题,提前发现,…};
4)对象类别={答案,真题,试题,卷子,试卷,原题,题目,作文,设备,耳机,器材,针孔,接收设备,…};
5)途径类别={Q,QQ,扣扣,扣,…}。
每个有害信息主题词都是由这些类别中的关键词组合而成的,例如(今年,购买,答案)、(2014,出售,答案)为两个有害信息主题词。
根据以上分析,不同的类别可构建有害信息多维离散空间(A-时间,B-考试类型,C-行为,D-对象,E-途径,…),每条有害信息主题词X∈(A,B,C,D,E,…)。该离散空间也可通俗称为领域知识库。该领域知识库可根据监测结果进行持续的扩充、优化和调整。随着知识库的完善,本文监测模型的效果将越好,有害信息的查准率将越高。
(3)查询表达式构造及应用
领域知识库建立完毕后,可构建不同维度的查询表达式,以用于采集、处理和分析等阶段。例如,在采集阶段,为保证互联网信息的抓取效率,可采用二维组合(时间,考试类型),也即采用((今年| 2014|14|二零一四)&(研究生考试|研考|考研|硕士生|统考|研究生|硕士生))这个查询表达式采集互联网的数据。在处理和分析阶段,可采用(行为,对象)、(行为,途径)、(对象,途径)、(行为,对象,途径)等多种组合方式进行再次检索,例如:
①买卖答案类查询表达式:(购买|出售|叫卖|卖|买|提供|发现|我有)&(答案|真题|试题|卷子|试卷|原题|题目|作文)
②泄题漏题类查询表达式:(泄题|漏题|提前发现|泄露)&(答案|真题|试题|卷子|试卷|原题|题目|作文)
③通过QQ进行代考替考的查询表达式:(Q|QQ|扣扣|扣)&(代考|替考|助考|枪手|助攷|包过|保过)
将多维查询表达式笛卡尔展开后,将对应若干组有害信息主题词,例如二维查询表达式“(购买|出售)&(答案|真题)”展开后,对应(购买,答案)、(购买,真题)、(出售,答案)、(出售,真题)四个有害信息主题词。
3.2 信息采集
有害信息在互联网上存在较为分散,并且形式多样,有独立网站、新闻、论坛、贴吧、博客、微博等各种形式。信息采集的主要任务是从这些形式多样、海量的信息载体中有选择地挖掘可能含有有害信息的页面文档。根据信息采集技术和原理的不同,可分为网页信息采集模型、微博信息采集模型、元搜索采集模型三类。
(1)网页信息采集模型
该模型主要针对于独立网站、新闻、论坛、贴吧、博客等信息源,利用面向主题的网络爬虫技术[4,5],按照设定的网页搜索策略(广度优先、深度优先等),从初始化URL列表中下载网页,并根据有害信息领域知识库中的主题词进行相关性判断,舍弃没有价值URL地址,提取符合要求的URL地址,经过去重和筛选后,加入到待搜索的URL列表中继续进行下载。相关性判断公式为:

其中主题词X∈(时间,考试类型)。
(2)微博信息采集模型
微博作为言论非常活跃的阵地,信息量及其庞大(例如新浪微博网站每天产生上亿条微博),而且消息的传播速度惊人。很多有害信息都在微博中引爆,并在几分钟或几十分钟之内大面积扩散,因此需要对其进行重点监测。微博采集内容主要包括信息正文、URL、发布时间、微博客名称、微博客网站名称、转发次数、评论数量、评论人、发布人粉丝数等内容。在微博的分析上,我们可以对微博热点话题、消息评论数等重要指标进行评价。
在采集技术手段上,可采用新浪等微博平台提供的API接口进行采集,例如通过statuses/mentions获取当前用户的若干条最新微博。该方式将受到API授权及每天调用次数的限制,数据采集量无法满足应用需求。还可以采用模拟登录的微博数据采集方式,通过程序模拟用户登录微博服务器后进行数据自动采集。[6]
(3)元搜索采集模型
在实际应用中,由于互联网信息源极其庞大,仅仅依靠网页信息采集和微博信息采集无法对全网进行覆盖,容易忽略某些重要的信息。因此,为提高有害信息监测的覆盖面,需要借助元搜索的方式进行补充,以达到全网监测的目的。元搜索是一种基于搜索引擎的搜索方法,汇聚百度、谷歌、搜狗等常见搜索引擎的搜索功能和博客、微博网站自身信息检索功能,对所有搜索结果进行整合、去重,加入有害信息原始库中。[7,8]
在技术实现上,首先根据有害信息知识库,构造符合搜索引擎要求的查询命令。以百度搜索为例,经过URL编码转换和条件组合后,查询表达式“(2014|14|今年)&(研究生|研考)&(泄题)”将转换为“2014%7C14%7C今年%20研究生%7C研考%20泄题”,再将搜索引擎的链接、编码、时间限制等信息合并得到完整的查询命令。例如“http://www.bai⁃du.com/s?wd=2014%7C14%7C今年%20研究生%7C研考%20泄题&ie=utf-8&lm=7”表示用百度搜索引擎查询一周内,有关2014年研究生考试泄题的信息。此外,可采用多线程技术同时构造多组关键词,向多个搜索引擎发送查询请求,从而有效提高检索速度。
3.3 分析处理
信息分析处理环节是整个模型的核心部分,按照关键词对有害信息原始库的数据进行进一步精加工,并进行分类,为后续应用提供有效的数据支撑。整个处理过程包括两个主要步骤:
(1)预处理
经过信息采集得到的有害信息页面文档一般采用HTML格式进行存储,正文内容和格式标签混在一起,干扰后续的处理和分析,因此,预处理的主要目的是将有害信息原始库中数据进行去重、内容提取、分词表示等,将HTML有害信息转换为可量化的表达。
①页面文档去重。不同的信息采集模型可能采集到相同的页面文档,因此,首先可以根据URL进行去重处理,将重复采集的页面剔除。
[9]
③中文分词。将有效的文本信息进行中文分词,将其切成一个个词语,并去除停用词和噪音词,后续的分类处理将基于这些词语进行。例如“提供2013年各省高考考试真题原卷答案/需要的加Q”分词后形成(“提供”、“2013”、“各省”、“高考”、“考试”、“真题”、“原卷”、“答案”、“需要”、“Q”)。目前中文分词算法很多,大致可归纳为:词典分词方法、理解分词方法、统计分词法等。[10]国内外也有很多开源的分词系统或项目,例如庖丁解牛分词包、LingPipe、IKAnalyzer和ICTCLA等。
(2)热度及相关性计算
热度及相关性计算的目的是统计页面重复出现的次数(次数越多,热度越高),以及与输入查询表达式的相关程度(也即相似度),最终形成如表1所示的数据,这些数据将为后续热点分析、主题分类等提供支撑。
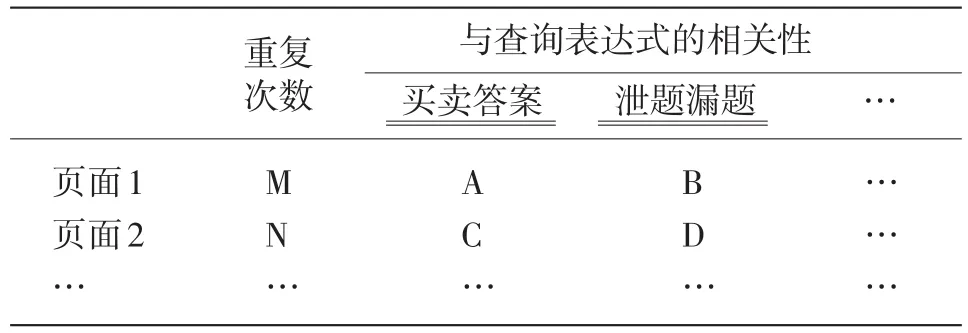
表1 热度及相关性计算后生成的内容
①页面文档表示。为进行页面文档之间、页面文档与查询表达式之间的相关性计算,需要对页面文档进行量化表示,转为计算机可识别的符号。可采用布尔模型、向量空间模型、概率模型等进行表示,其中向量空间模型(VSM)是目前最常用的一种表示方法。[11,12]每个页面文档d可表示为一组特征向量:V(d)=(t1:w1(d),t2:w2(d),…,tn:wn(d))简化表达为:V(d)=(w1(d),w2(d),…,wn(d))其中t为关键词,wi(d)为关键词ti在文档d中出现的次数。例如在某一页面文档中,关键词“2014”出现1次,关键词“高考”出现4次,关键词“答案”出现6次,则该文档的向量表示为(2014:1,高考:4,答案:6),简化表示为(1,4,6)。
②页面文档热度计算。对教育考试有害信息监测工作而言,如果某一条有害信息被多次转载,或者出现在多个不同的网站中,则该信息为热点信息,需要重点关注。因此,页面文档热度计算的核心是识别页面内容是否重复,如果重复则热度加一。判断页面文档重复可采用基于聚类的方法、基于签名的方法、基于特征码的方法等。[13]本模型采用K-Means等聚类算法进行重复次数计算,算法的核心是页面文档的相似度。文档中文分词后仅保留动词和名词,将页面文档向量按照wi(d)的大小值排序,取前10个关键词,并进行对齐处理,使两个文档关键词个数和顺序完全一致。两个特征向量表示的文档d1和d2之间的相似度可用余弦距离来刻画,将两个向量放到坐标系原点,以两个向量的夹角θ的余弦值来表示文档的相似程度,夹角越大相似度越小,夹角越小相似度越大,其相似度定义为:

当两个文档之间的相似度高于设定的阈值时,则认为这两个文档属于同一类,重复次数增加1次。
③与查询表达式之间的相关性计算。根据教育考试网上有害信息监测需要,基于领域知识库构造任意多组查询表达式,例如买卖答案类、泄题漏题类等,计算与每个聚类类别(用该类中的任意一个页面文档来表示该类别)的相似程度,相似度越大,则表示该文档越符合查询表达式的要求。给定文档向量V(d)=(t1:w1(d),t2:w2(d),…,tn:wn(d))和有害信息主题词X=(x1,x2,…,xm),从文档向量V(d)中提取仅仅包括关键词xi的子向量M(d)=(x1:w1(d),x2:w2(d),…,xm:wm(d)),则文档d与主题词X之间的相似度定义为:

给定页面d和查询表达式S,令S笛卡尔展开后分解为(X1,X2,…,Xl),也即S可分解为l组有害信息主题词,则文档d与查询表达式S之间的相似度定义为:

通过该方法可以计算所有页面文档与查询表达式之间的相似度。
3.4 服务应用
根据数据分析处理产生的结果,可以围绕教育考试有害信息监测的需要,进行进一步的分类统计、热点分析、来源分析、趋势分析等,以方便管理和决策。
(1)分类统计
根据给定的查询表达式,可对买卖答案类、作弊设备类、助考代考类、泄题漏题类进行分类监测,并按照有害信息发布时间和相关程度排序列出。还可分析各类有害信息所占的比重,从而在业务上指导监控的重点,例如考前绝大部分有害信息为买卖答案类。此外,在实际业务应用中,还可以构造任意专题的查询表达式,并不单单限定于有害信息。
(2)热点分析
基于页面文档重复次数,可以统计某段时间内,有害信息出现的次数,并进行排序。对于微博来说,还可以按照转发量和评论量进行统计排序。通过该功能,可掌握有害信息的扩散情况,对次数最多的信息进行重点关注和处理,可在上报公安部门的时候,进行强调说明。
(3)来源分析
通过来源站点排名分析可清楚掌握有害信息主要在哪些媒体出现,从而进行专题分析和重点监测。例如,2014年研究生考试中,对1000多个论坛监测过程中,大家论坛、返利网论坛、百度贴吧、天涯社区、e度教育网、腾讯论坛都是有害信息出现次数比较多的论坛。
(4)趋势分析
通过对不同考试项目有害信息长期持续的跟踪,分析其随时间变化有害信息出现的条数以及类别分布情况,可以总结经验,为第二年有害信息监控工作的开展提供依据。
4 监测模型与现有业务模式的结合
有害信息自动监测模型在提高工作效率、增加有害信息监测的覆盖面,以及增强对信息的分析和利用程度等方面具有较为显著的优势。然而,如何将自动监测模型与现有业务模式有机结合,充分整合和利用全战线人员的力量,这是发挥该模型作用的重要因素。本文认为,有害信息自动监测模型可以为业务提供技术手段,然而人工监测仍然是不可或缺的方面。具体作用体现在如下两个方面:
(1)信息甑别。引入自动监测模型,将极大提高有害信息的数量。根据目前业务模式,需要定期将有害信息反馈给公安部门,由公安部门进行后续处理。然而如此庞大的数据量全部反馈给公安部门,势必加大其工作量。为此,可以集中全战线工作人员在模型监测结果的基础上,分任务进行有害信息过滤和甑别(而不是重复搜索),例如人工判断有害信息的重要性和危害程度,结合模型提供的热点信息,选择性地上报公安部门,一方面可减轻公安部门的工作量,另一方面可提高有害信息打击的精度。
(2)微博信息的监测。由于微博信息更新较快,而且影响面较大,可以安排人工对新浪、腾讯等几个重点微博进行跟踪和监控,与自动监测模型相互配合、相互补充,监测效果会更好。
参考文献
[1]中国互联网络信息中心.第36次中国互联网络发展状况统计报告 [EB/OL]. http://www.cnnic.cn/gywm/xwzx/rdxw/2015/201507/ t20150723_52626.htm,2015-7-23.
[2]左坚卫.互联网有害信息的界定和相关行为的处理刍议[J].信息网络安全,2005(6):35-36.
[3]王勇.媒介融合环境下网络有害信息传播与治理研究述评[J].昆明理工大学学报(社会科学版),2013(1):79-85.
[4]孙骏雄.基于网络爬虫的网站信息采集技术研究[D].大连:大连海事大学,2014.
[5]陈立为.面向主题信息采集系统现状分析[J].湖南有色金属,2014(2):77-80.
[6]孙青云,王俊峰,赵宗渠,高梦超.一种基于模拟登录的微博数据采集方案[J].计算机技术与发展,2014(3):6-10.
[7]杨更.基于元搜索的信息采集平台设计与实现[J].计算机应用与软件,2012(7):175-177,259.
[8]吴小兰,汪琪.元搜索引擎研究综述[J].图书情报工作,2009(9):46-49.
[9]高天宏.互联网舆情分析中信息采集技术的研究与设计[D].北京:北京邮电大学,2015.
[10]奉国和,郑伟.国内中文自动分词技术研究综述[J].图书情报工作,2011(2):41-45.
[11]宋辰.科技情报采集系统的设计及其快速文本聚类方法研究[D].北京工业大学,2014.
[12]贾自艳.Web信息智能获取若干关键问题研究[D].北京:中国科学院研究生院(计算技术研究所),2004.
[13]刘书一.基于文本相似度的网页消重策略[J].计算机应用与软件,2011(11):228-229,278.
Research on the Model of Internet Harmful Information Auto-detection about National Education Examinations
YANG Yuedong&LU Xinzheng
With the rapid development of information technology,the Internet has become the main way of the harmful information on National Education Examinations.In order to ensure fair and safe examination,the examination staff search harmful information using search engines,such as Baidu and Sogou.The search results will be submitted to the relevant departments for disposal.However,this method has some problems,such as low efficiency,small searching scope and low information analysis.In order to solve these problems,this paper presents an Internet harmful information auto-detecting model based on domain knowledge.The model can automatically collect information of the Internet,de-duplicate,classify,and provide the basis data for classification,hot spot analysis and source analysis.Finally,this paper presents the model of cooperation with the existing manual monitoring to form a harmful information monitoring system with large coverage,real-time performance and high accuracy.
NationalEducation Examinations;HarmfulInformation;Information Collection;Information Processing;Domain Knowledge
G405
A
1005-8427(2016)03-0008-7
杨跃东,男,教育部考试中心,工程师,博士(北京 100084)
鲁欣正,男,教育部考试中心,处长(北京 100084)
