电网企业大数据在财务决策中的应用研究
2016-06-02杨进
杨 进
(国家电网公司冀北电力有限公司 财务资产部,北京 100053)
电网企业大数据在财务决策中的应用研究
杨进
(国家电网公司冀北电力有限公司 财务资产部,北京 100053)
摘要:大数据是一个世界范围内、各行各业都日益重视的话题,然而,大数据代表什么、电力企业如何应用大数据,这些问题的理解者或许并没有那么多,本文的目的有两个:一是通过阅读本文,读者能够对大数据有个全面的正确的认识和理解;二是以某电网企业为例,运用各种数据分析工具(包括时间序列分析、回归分析、聚类分析),将大数据理念与实际的电网企业财务决策挂钩,通过分析两个财务决策情景来展示大数据的财务应用,让对大数据仍有模糊认识的读者更加清晰、形象地看到大数据是如何应用的,以此来加快我国大数据的应用发展。通过案例应用可以看到大数据的确可以为电网企业发挥重要作用。
关键词:大数据;智能电网;财务;时间序列分析;聚类分析
近年来,随着全球能源问题日益严峻,世界各国都开展了智能电网的研究工作,2011年麦肯锡研究报告《大数据:创新、竞争和生产力的下一个前沿领域》 使得大数据在企业界迅速火热。大数据被视为下一个创新和生产力提升的前沿,2009年,谷歌公司通过大数据业务对美国经济的贡献就为540 亿USD,而这只是大数据所蕴含的巨大经济效益的冰山一角,随着大数据研究的地位以及将会给社会带来的价值,大数据已成为学术界和产业界共同关注的研究主题。
在智能电网系统中,大数据产生于整个系统的各个环节。随着大量智能电表及智能终端的安装部署,电力企业可以每隔一段时间获取用户的用电信息,从而收集了比以往粒度更细的海量电力消费数据,构成智能电网中用户侧大数据。
为了响应财务大数据的号召,电网企业财务部推行全面预算管理,全面预算管理是让企业大数据、海量数据“活起来”的最好方式,通过对数据进行分析可以更合理地设计电力需求响应系统和短期负荷预测系统、更好的理解电力客户的用电行为等。但是,由于云计算平台的广泛应用,积累了海量、多源异构数据,这急需人们研究这种大数据的分析技术和理论。
一、大数据与电力系统的内涵
(一)大数据内涵
2010年Apache Hadoop 组织给出的大数据定义为,“普通的计算机软件无法在可接受的时间范围内捕捉、管理、处理的规模庞大的数据集”。定义中提到了三个关键词:数据量、处理时间和处理工具。说明,在对大数据的理解方面,巨大的数据量、尽快的处理时间和多样化的处理工具是必不可少的部分,然而巨大的数据量和实时的处理时间却又是矛盾的,因此对处理工具的多样性和实用性提出很高的要求。学界普遍认同的三个大数据特性是体量大(Volume)、类型多(Variety)和速度快(Velocity)。除此之外,IBM 公司认为大数据还应具有可信性和可用性(Veracity),而国际数据公司(IDC)则认为数据应当具有价值性(Value)。
(二)电力企业如何理解大数据
可以说智能电网就是“大数据”在电力行业中的一种应用,电力大数据的特征可以概括为5“V”3“E”。除了以上介绍的5V以外,3“E”特征是电力大数据所独有的,包括能量(Energy)、交互(Exchange)、共情(Empathy)。能量可以理解为数据的价值。数据交互性特指在智能电网中,用户与供电公司在电流、信息流方面的交互。共情为用户与供电公司、国家、社会达成统一目标,协调多方面利益,最终实现经济转型和可持续发展。
二、电网数据类型
(一)按业务分类
电网中的数据大致可以分为4 类:财务数据,即有关于各种资产成本、运维成本、投资决策、用电收入等的数据;生产数据,即电网运行状态及相关监测信息,如网络运行拓扑、设备状态信息;运营数据,即影响分布式电源出力的配电网相关区域天气信息,如光照、气温、风速等信息;企业管理数据,即网内用户的状态及营销信息,如用户的用电量信息等,美国太平洋天然气电力公司每个月从900 万个智能电表中收集超过3 TB 的数据[5]。最后,新业务数据主要包括分布式电源、电动汽车等数据。
(二)按数据结构分类
依照数据结构的划分形式,这些数据可以分为结构化数据和非结构化数据,结构化数据存储在数据库里,可以用二维表结构来逻辑表达实现的数据。相对于结构化数据,无法用二维逻辑表表达的数据即称为非结构化数据。非结构化数据主要包括线路、监测图片和视频、设备检修管理等的日志信息等,这部分数据增长非常迅速,互联网数据中心(Internet data center,IDC)的一项调查报告指出:企业中80%的数据都是非结构化数据,这些数据每年都按指数增长60%。
(三)按数据实时性分类
从数据实时性上来分,主动配电网中的数据又可以分为准实时数据、非实时数据、实时数据。设备运行日志、监测视频、用户营销信息等信息因其应用实时性要求低,列为非实时数据;以保证配电网的正常运行,设备的状态监测信息、气象信息等并非实时调用的信息目的是供后期对设备状态分析及预测使用,归为准实时信息;配电网调度、控制、保护等需要的数据一般时效性很高,为真实完整记录生产运行的每个细节,完整反映生产运行过程,要求达到“实时变化采样”,因此大部分为实时数据。这些数据中蕴藏着丰富的信息,对于分析生产运行状态、提供控制和优化策略、故障诊断以及知识发现和数据挖掘具有重要意义。
三、电力行业财务部门如何应用大数据
(一)大数据的内部应用
1.提高财务管控能力,帮助企业战略落地
相比较企业内外部的其他类型的数据,财务数据更复杂、更庞大,因此包含着更多的宝贵信息。例如,可以建立数据分析模型,对会计数据进行分析和信息挖掘,也可以对成本、费用、收入、利润等进行行业比较分析、区域市场分析、增长情况分析等,从而发现经济的近期和远期规律,从而在挖掘市场潜力的同时,更好的控制行业风险、提升行业竞争力。在进行模型预测的基础上,利用全面预算管理解决方案,得到不同时期、不同产品类别的明细数据情况,便于企业的实际和预算数据进行比较,分析差距,找到解决问题的方法。通过与网络报销、费用控制等分析工具的配合,可以大大提高财务管控能力,帮助企业实现战略落地。
2.通过成本效益分析,支持基建决策
发电企业通过大数据提供的有效数据预先进行成本效益预测,进而更科学的做出发电站的选址、输电线路的设计的决策。另外,如果条件允许的话,还可以根据卫星系统数据将月相与潮汐数据进行综合,更好的服务与电网公司基建建设。不确定的宏观环境对电网企业投资决策科学化提出更高的要求,因此,电网公司需要充分利用大数据的分析优势,借此提高财务的决策支撑、资源配置、风险防范作用,进而提高电网公司的盈利能力、投资能力。
3.升级客户分析,提高财务收益
电网公司的财务管理倡导投资管理精益化,以此来提高投资效率,在具体的数据分析方面,应该以分析型数据为基础,科学配置各种服务资源,构建营销数据分析模型。另外,为了对各级数据需求者提供多为、直观的分析展示,应建立各种针对营销的系统性算法模型库,并且注重开发多样性的数据可视化工具,进而主动把握市场动态,为企业获得更好的效益、为顾客提供更好的基础做好铺垫。
4.提高财务管控能力,加强财务同其他部门的协同管理
电网各信息系统大多是基于本业务或本部门的需求,存在不同的平台、应用系统和数据格式,导致信息与资源分散,异构性严重,横向不能共享,上下级间纵向贯通困难。通过实施大数据管理,可以整合电力行业生产、运营、销售、管理的数据,设计各部门全环节数据共享平台,将优化内部信息沟通,使财务、人事等工作的开展更顺畅,进而提高财务部门的管控水平。
(二)大数据的外部应用
利用电力行业数据可给用户提供更加丰富的增值服务内容。通过与用户进行互动式对话,可以发掘更多节能降耗的关键点,比如,随着电动汽车的发展,用户可以在用电低谷给电动汽车充电,然后在用电高峰期将存储的电贡献出来,电网公司可以提供其相当于高峰电价的补助,这样既缓解了电网公司的波动性,又给用户带来了部分收入。
除了与用户进行数据互换外,还可以与外界进行数据的交换,例如挖掘用户用电与天气、交通等因素所隐藏的关联关系,完善用户用电需求预测模型,进而为各级决策者提供多维、直观、全面、深入的预测数据,主动把握市场动态。
作为重要经济先行数据,用电数据和会计数据同样重要。如果说用电数据是一个地区经济运行的“风向标”,那么会计数据是准确反映一个国家经济运行情况的“晴雨表”,可作为投资决策者的参考依据。
四、大数据应用案例——电网企业大数据分析支持财务管理决策
(一)变电站运检成本变动规律分析
一个资产从投入到运维、检修最后到资产退役,整个过程中成本的发生不是固定的,刚投入的设备运行状态良好,需要检修、运维的成本花费较低,随着后期使用年限的增加,各种问题随之出现:零件坏损、外壳腐蚀、地标更换、事故及异常事件发生频率增加等等,最后的结果是检修消缺工作越来越繁重,危险点分析越发复杂,运维压力逐渐增大,因此,全面透彻的对一个变电站在投运后不同阶段发生的成本进行分析,有利于及时的核算所需资源、人力,使得财务工作的实施更具准确性、可操作性、可预见性,提高整个财务工作在变电运维方面的管控能力。
变电站的选择:变电站根据电压等级可分为:500KV、220KV、110KV、35KV、10KV,不同的等级的变电站运维检修成本必然不同,因此首要工作就是选择一个适当的电压等级的变电站作为分析目标。本文选取变电站电压等级有两个原则,一:该等级变电站数量较多,保证多个变电站的平均数据具有客观性;二:该等级变电站数据可得、且操作上可行。因为电网公司500KV变电站数量一般较少,约3个左右,因此不适合第一条原则。而110KV以下的变电站数量又太多,数据搜集及处理比较繁琐,因此根据数量和数据可得性、可处理性选择220KV变电站。
数据单位的选择:即便都是220KV变电站,各自的容量也是不同的,为了更具科学性,本文选取的成本单位为元/MVA。
最后需说明的一点是:本文的重点是提供一个运用大数据提高财务分析、预测能力的使用方案,对于数据的准确性是其次,出于保密考虑该数据有所偏颇,但依旧可以从该分析方法上窥探大数据对电网公司的巨大作用。
以220KV变电站为例,根据各220KV变电站多年运维数据累计,得出一个标准的220KV变电站自投入运行后每年的成本,该成本由三部分组成:变电检修成本、变电站通信设备检修成本、变电运行成本。假设自2000年投运,一个标准220KV变电站自投运后每年成本如下:

20009453720011053852002113464200312865920042038712005224585200624309620073205072008346736200936453920104253922011474396
图1220KV变电站每年成本(元/MVA)
运用EVIEWS软件画出这12年数据的时序图如下:

图2 220KV变电站成本时序图
从上图可以看出该序列具有两个特点:1.明显的上升趋势,因此并非平稳序列;2.有较明显的周期波动性,第一次波动时隔4年,后两次均为3年。
因此可以选择以下模型进行该序列的分析:
costt=Tt+St+It
其中,Tt代表长期趋势,即图中的增长趋势;St代表周期波动;It代表随机波动
长期趋势拟合:
分别用线性拟合和曲线拟合进行尝试
线性拟合:选用costt=a+bt+It;E(It)=0,Var(It)=σ2进行拟合
拟合结果如下:

VariableCoefficientStd.Errort-StatisticProb.C20244.8013894.301.4570580.1758T35926.021887.86319.029990.0000
由拟合结果可知,T的系数显著非零,且判决系数为97%,说明拟合结果良好且时间因素能解释大部分数据变动,唯一不足之处是常数的系数不显著。
通过长期趋势拟合,可以得到趋势拟合图,下面对比原序列与拟合序列的图谱之间的吻合度,见图3。
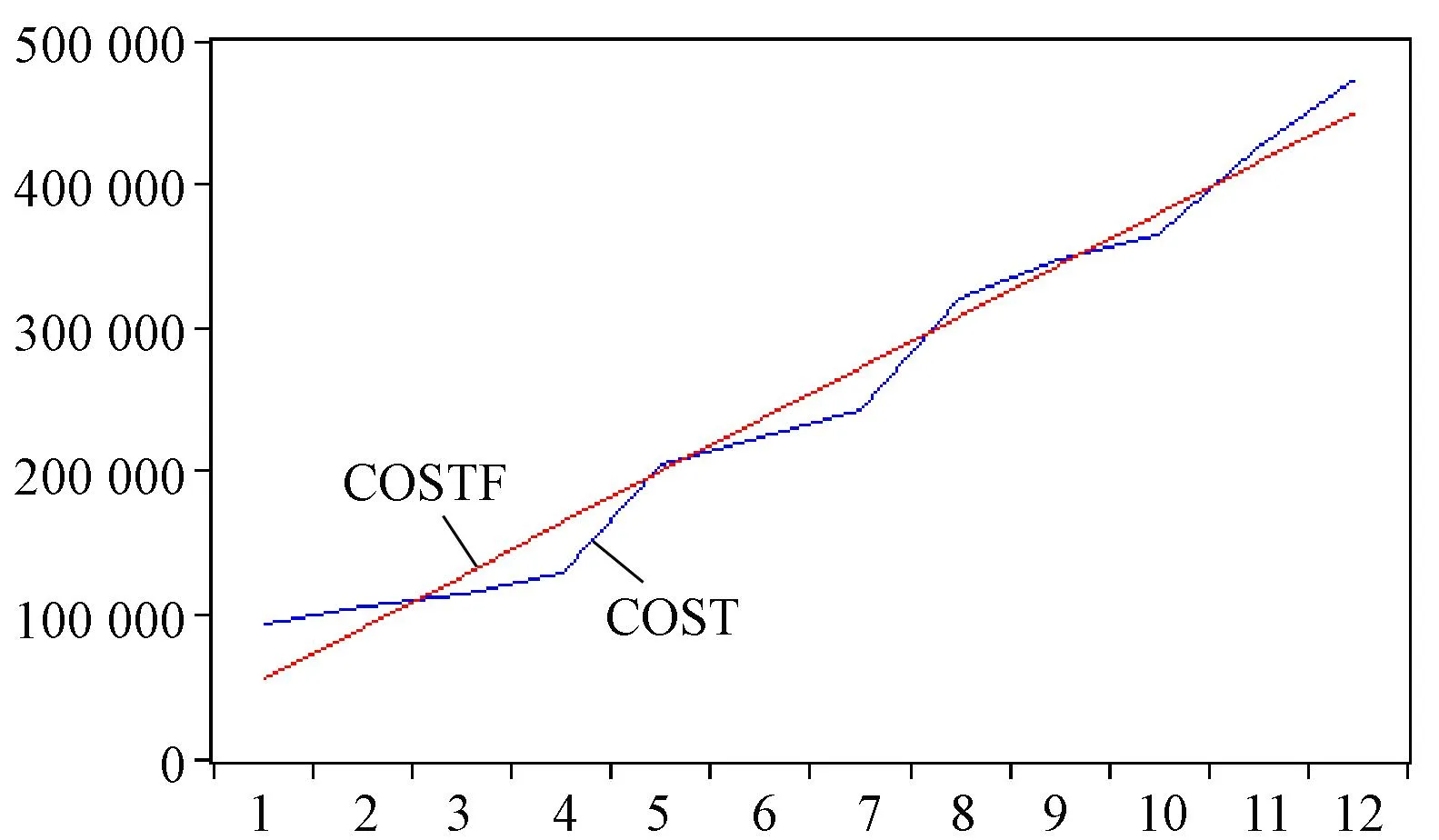
图3 趋势拟合效果图
从图3可以看出,线性拟合虽然拟合出了大部分效果,可是仍然存在一些波动情况,拟合效果仍有可提升的空间。

图3 东、中、西部全社会用电量及增速
下面尝试曲线拟合,拟合模型如下:
costt=a+b*t+c*t2
拟合结果如下表:

VariableCoefficientStd.Errort-StatisticProb.C61011.7017854.223.4172150.0077T18454.496314.6342.9224950.0170T*T1343.964472.85932.8422080.0193
可以看出,无论从各系数显著性和判决系数来看,曲线拟合都比线性拟合要效果优良很多,下面通过拟合效果图来直观的查看拟合效果。

图4 趋势拟合效果图
上图可以看出趋势效果已经基本拟合完成,只剩下部分的周期波动效果有待提升,因此在趋势拟合方面最终采用曲线拟合,拟合方程为:
costt=61011+18454*t+1344*t2
从拟合方程可以看出一下几点:
1.随着时间T的增加,变电站维护成本呈递增趋势。
2.成本增加不是线性的,增长幅度随T的增加而增大,为18454+144T。由此可见,随着投运时间的增加,检修运维各项成本的增加并不是线性的,而是以越来越快的速度增加。
周期波动因素分析:
除了趋势效果外,还可能存在周期波动,又称为季节波动,季节波动最好理解的就是气温、商品零售额、某景点旅游人数等现象,这些现象都会呈现明显的季节变动规律。相应的,由变电站成本序列图可以看出,该序列也存在季节效应,即每隔一段时间,成本会大幅上升一次,下面进行季节效应分析。
下图为各年的季节因子数及因子图

图5 各年的季节因子数及因子图
由上图可以看出以下几点:
1.波动因子以1为分界线,等于1的年份为该年成本与长期趋势一致,大于1的年份为成本除了长期趋势外还有向上波动的趋势,小于1的年份为该年除了长期趋势外,有向下波动的趋势。由此可以看出第8年以后,每年的成本除了长期趋势的增加外,还有季节性向上波动的趋势,总体来说成本会涨的更快;而第2-4,6-7年均有向下的波动,总体来说成本涨的会比长期趋势慢一些。
2.自投运后的第5年、第9年、第11年均为成本波动剧增期,在这些运营期到来之前,应提高自己的财务管控能力,扩大资金来源,节约成本,搞好资本运作,为财务工作提供坚实的基础。
3.在第4、8、10年为花费波动较小的年份,在这些期间最重要的是节约成本,提高运维效率,为波动最剧烈时期的到来做好准备。
以上现象从常理来推断亦可理解,因为在前期投入运营后,设备新、状态好,因此运维检修成本波动不大,而运维一段时间后,由于部分设备出现故障,因此需要一定的大修甚至技改,因此运维检修成本会有一个突然增加的年份,技改大修过后,设备状态又焕然一新,运维检修成本又恢复平稳,以此类推,每隔几年便会有突然增加的年份,通过大数据,可以预测出这些成本突增的年份是在投运后的第几年,由此提前做好人员上的安排以及资金上的供给,防止计划提前造成捉襟见肘,可大大提高财务计划的前瞻性、可预测性和科学性,为增强财务管控能力提供坚实的分析基础。

图6 最终拟合效果图
经过上述的趋势拟合及季节因子分析,可以得出全新的拟合效果图,通过该图可以发现不仅长期的曲线增长趋势被拟合了,同时每年不同的波动情况也拟合的良好,说明用该方法与大数据理念来分析变电站运维检修成本科学且有效。
(二)变电站运维成本预测
在上述分析的基础上,我们可以大致预测出一个变电站每年的运维检修成本变化趋势,如果一个变电站的年限为20年,那么可以把之前相似变电站的成本进行拟合,再考虑货币时间价值因素,完全的拟合出一个该种变电站的运维成本图,以此作为新建变电站的成本参考,提前预测到该站全生命周期内成本的总和及分布。然而,上述方式还存在不足之处,因为考虑到技术的进步速度、国家政策的变更、环境压力的增加、用电人口的增多等等因素,新建的变电站可能在技术、容量、运维方式等方面发生巨大的变化,因而之前老旧变电站的成本参考性大大降低,这时再用之前老站的成本来对新站进行估计的话,无疑会错误的诱导财务计划编制人员,影响其对资金需求的判断,从而导致财务甚至整个企业资金链断裂,其重大影响促使我们考虑其他更科学的预测方法。
下面的这种预测方法原理与之前有很大不同,该方法不是单纯的通过众多相似变电站来寻找运维年份与成本之间的关系,而是根据同一变电站的历史年份的成本发生额来预测未来几年的成本发生,简单来说,上面的方法是横向分析多个变电站从大数据中取得关系,而该方法是纵向分析单个变电站,用该站历史数据预测未来。
条件假定:假设新型变电站已经运维12年,且其运维成本与上述数据一致,下面进行未来年份数据的预测。
由上述分析可知,此阶段曲线拟合效果最好,因此首先进行数列的2阶差分,差分后自相关、偏自相关图如下:

通过白噪声检验发现仍存在部分相关性,经过试验发现AR(3)模型能很好的拟合,拟合后参数如图:

VariableCoefficientStd.Errort-StatisticProb.C-22831.0049899.87-0.4575360.6665AR(3)0.7626170.2398373.1797360.0245
因此拟合模型为:
因此最终展开后的拟合模型为:
costt=2*costt-1+costt-2+0.76costt-3-1.52costt-5+0.76costt-6
从第7期开始预测,预测值及效果如下
可见预测效果很好,现拟合未来两年的成本,拟合图如下:

图7 预测效果图

图8 拟合效果图
由此,对待没有运维经验的新站,可以用此方法,根据某站前几年的运行数据来预测未来几年的成本情况,这样无疑更提高了财务预测与编制的准确性、科学性。
(三)对需求侧进行分析
用电用户按用途可以分为四类:大工业用电、一般商业用电、居民用电、农业用电,不同类型的用户用电需求不同、电价不同,因而针对各类用户,可以采用不同的电能管理政策。例如,大工业和一般商业用电一般需求难以调节,相对的居民用电和农业用电可调节性高,通过电价制定,可以促使其在用电高峰与低谷之间进行合理转移,由此提高用电的灵活性和平稳性。本文要做的就是将某电网供电的几个地区按某些指标进行分类,分类后每个类别内的地区在总用电量、用电构成上具有相似性,进而在用电收入核算和电价制定上具有可效仿性。另外,如果该电网扩大供电区域,也可以将新区域纳入分类系统,预测新区域的收入与政策效果。
影响电量收入的因素有很多,综合考虑影响总用电量和四种用电比例的影响因子,最终选定居民GDP、第一产业产值、第二产业产值、人口数4个指标。选取城市数值如下:
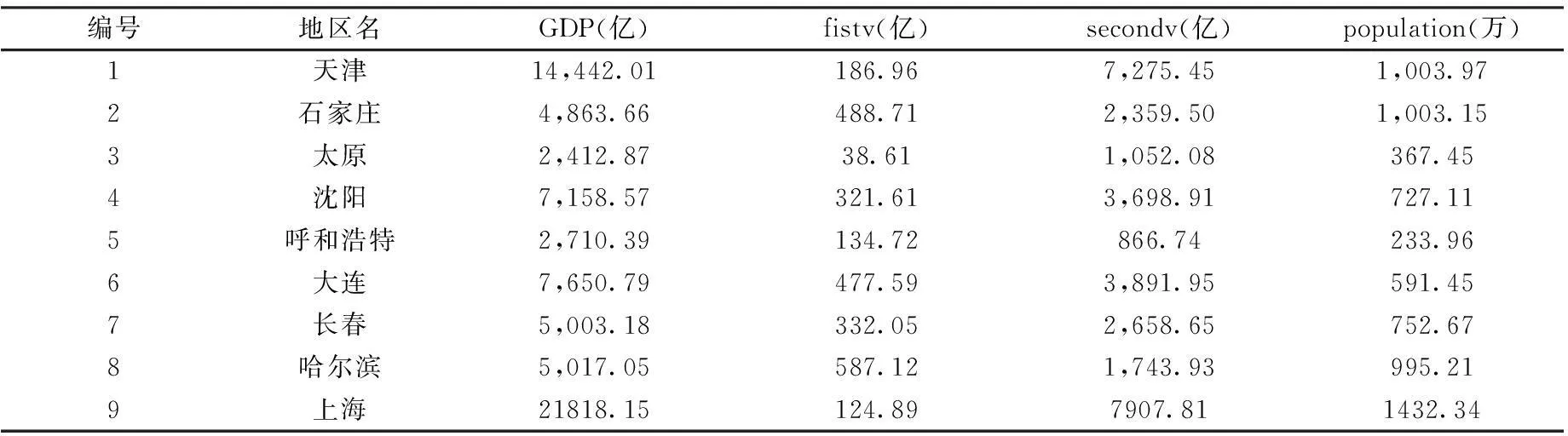
编号地区名GDP(亿)fistv(亿)secondv(亿)population(万)1天津14,442.01186.967,275.451,003.972石家庄4,863.66488.712,359.501,003.153太原2,412.8738.611,052.08367.454沈阳7,158.57321.613,698.91727.115呼和浩特2,710.39134.72866.74233.966大连7,650.79477.593,891.95591.457长春5,003.18332.052,658.65752.678哈尔滨5,017.05587.121,743.93995.219上海21818.15124.897907.811432.34
选用SPSS进行聚类分析,分析过程中的数据处理为:1.原始变量标准化;2.聚类方法为组内联结法,计算距离选择平方欧式距离;最后输出树状聚类图如图9。

图9 树状聚类图
在图9中,纵坐标代表各个地区,横坐标代表距离数,以不同的距离数为界,可以有不同精细程度的分类。如果以5为界可以得到4组分类:第一组(1,4,7,6)、第二组(2,3)、第三组(9)、第四组(5,8)图中的1-9分别代表从上至下9个地区,因此最后的聚类结果是,天津、沈阳、长春、大连为一类;石家庄、太原为一类,上海单独一类,呼和浩特和哈尔滨勉强为一类。如果以距离10为界,可以得到三组分类,以此类推。通过上述分类,与现实对照可以发现,以上分类基本是合理和科学的,而且很方便,因此可以应用到实际电网公司供电区域的聚类上,聚类完成后,可以分别考虑各自组别的用电量、电价等用电策略,以此提高财务的管理能力和收益能力。
五、总结
本文通过各种统计方法,将大数据理念与财务数据结合,展示了财务部门如何应用大数据来提高财务决策工作,希望有一个抛砖引玉的作用,促使各位学者积极投身于大数据的具体应用中去,提高我国企业在财务决策中利用大数据的实际应用能力。另外,面对海量的智能电网数据,如何在有限的屏幕空间下,以一种直观、容易理解的方式展现给用户,是一项非常有挑战性的工作,也是未来要探索的方向。
参考文献:
[1]Divyakant Agrawal,Philip Bernstein,Elisa Bertino,et al.Challengesand opportunities with big data[J].Proceedings of the VLDB Endowment,2012(12).
[2]周晖,钮文洁,王毅.从缴费行为分析电力客户的信用度[J].电力需求侧管理,2006(6).
[3]Conejo A J,Morales J M,Baringo L.Real-time demand responsemodel[J].IEEE Transactions on Smart Grid,2010(3).
[4]牛东晓,谷志红,邢棉,等.基于数据挖掘的SVM 短期负荷预测方法研究[J].中国电机工程学报,2006(18).
[5]谢华成,陈向东.面向云存储的非结构化数据存取[J].计算机应用,2012(7).
[6]江苏瑞中数据股份有限公司.海迅实时数据库助力智能电网建设[EB/OL].http://wenku.baidu.com/view/f3ee4ed 1614e852458fb5744.html.
[7]Wong P C,Shen H W,Chen C,et al.Top ten interaction challenges in extreme-scale visual analytics[J].Computer Graphics and Applications,2012(4).
(责任编辑:王荻)
Research on Application of Big Data on Financial Decision-making of Power Grid Enterprises
YANG Jin
(Financial Assets Pivision,State Grid North Hebei Electric Power Co.,Ltd.,Beijing 100053,China)
Abstract:Big data is an increasingly important topic in the world,however,what big data meaning and how to apply is still unclear.There are two aims in this article :firstly,it give the readers a comprehensive understanding about big data; secondly,takes one grid enterprise for example to show how to use big data through all kinds of analytic tools (including time series analysis、cluster analysis、regression analysis),two scenarios about financial decision-making are demonstrated in order to display the application of big data.The results show that big data will and can make a difference in grid enterprise.
Key words:big data; smart power grids; finance; time series analysis; cluster analysis
收稿日期:2015-12-23
作者简介:杨进,男,国家电网公司冀北电力有限公司财务资产部稽核处处长,高级经济师。
中图分类号:F407.61
文献标识码:A
文章编号:1008-2603(2016)02-0033-07
