一种改进的基于梯度提升回归算法的O2O电子商务推荐模型
2016-05-30孙克雷邓仙荣安徽理工大学计算机科学与工程学院安徽淮南232001
孙克雷, 邓仙荣(安徽理工大学 计算机科学与工程学院, 安徽淮南 232001)
一种改进的基于梯度提升回归算法的O2O电子商务推荐模型
孙克雷, 邓仙荣
(安徽理工大学 计算机科学与工程学院, 安徽淮南 232001)
摘要:位置属性对于线下消费的用户具有重要影响。为了有效提高个性化推荐精度,在对O2O电子商务特点进行用户特征分析的基础上,在推荐算法中引入当前时间参数和位置参数,提出了一种改进的基于梯度提升回归算法的O2O电子商务推荐模型。实验结果表明,改进的基于梯度提升回归算法的O2O电子商务推荐模型在实时性和准确性方面明显优于传统的推荐算法。
关键词:梯度提升回归树,位置服务,个性化推荐,行为日志分析
0 引 言
互联网的快速发展将人类带进了信息化时代,从根本上改变了个人生活和企业发展。对于个人而言,足不出户就可以买到所需要的商品或服务,让消费者享受到电子商务模式的便利;对于企业而言,互联网在企业和消费者之间建立了直接联系,为企业带来更大的商机。贝恩公司与阿里巴巴研究院联合开展的2015年度中国电商报告显示,2014年中国线上销售额已经达到2.9万亿,其中一线城市人均支出超过10万元,由此可见,O2O电子商务改变了消费者的消费模式。推荐系统是利用数据挖掘等技术,分析消费者在电子商务网站的访问行为,产生消费者感兴趣产品信息的推荐结果。
1 相关研究
O2O电子商务是基于大数据平台架构下的典型案例,关键问题是依据海量的商品数据和用户数据建立一个有效的推荐模型,目前流行的推荐模型主要有以下三种:
1)基于协同过滤的推荐:分为基于物品的协同过滤和基于用户的协同过滤[1,2]。协同过滤通过对用户偏好信息进行分析,根据偏好数据计算相似用户和相似物品,然后基于相似物品或相似用户进行推荐[3]。协同过滤的主要优点是集合了他人的经验,有利于推荐新信息,实现个性化推荐;缺点主要是稀疏性问题和冷启动问题。
2)基于关联规则的推荐:关联规则挖掘已经是数据挖掘中的一个经典的问题,主要是挖掘不同商品在销售过程中的相关性,由此预判消费者在购买了一些商品后的下一次购物行为,当关联规则得到验证后,就可以建立基于关联规则的推荐模型,Agrawal等在1993年最早提出了Aprior的关联规则推荐算法[4]。
3)基于模型的推荐:本质上是应用机器学习方法解决推荐问题,将已有用户行为数据和商品属性数据进行预处理后,分析特征向量,获取训练样本[5],再找到一个可行的训练算法验证预测结果。其关键在于如何分析和约简特征向量,将用户实时偏好信息反馈给已建立模型,从而提高推荐准确率。
本文采用基于模型的推荐,通过深入挖掘移动O2O电子商务中的用户行为日志,抽取出能辨别用户对商品服务购买行为的基本特征,然后将其融入梯度提升回归算法,建立用户兴趣偏好模型来预测用户的购物行为。梯度提升回归算法(Gradient Boost Decision Tree)是一种组合决策树机器学习算法[6],通过组合多个弱决策树形成一个强决策树预测模型。梯度提升回归算法具有评价特征重要性的能力,和SVM一起被认为是泛化能力较强的算法。
2 移动用户基于位置的偏好特征分析
O2O是典型的基于位置服务的一种电子商务模式,提供的商品以本地服务类为主,如饮食,住宿,娱乐等,要求用户线下实地体验,其主要特点是位置信息对于用户行为特征有重大影响[7]。上述位置信息是个广义概念,同时包含了时间和地理位置两个维度的数据。
1)在时间维度上,如果用户刚刚消费一个项目,那短期内再次消费的可能性很低,例如理发服务。设用户消费某一商品或服务项目的平均周期为T,消费时间周期T对用户的相关性函数定义为:
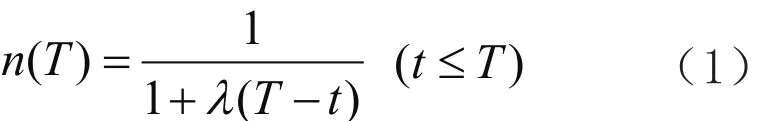
其中,λ是时间衰减参数。显然,当t=T时,n(T)取得最大值。
2)在地理位置维度上,移动位置不同对用户消费需求也有重大影响。在热门消费场景区域比如商场街区等,用户会有一定的随众倾向,在一些偏远、冷门的场景,用户平均消费倾向又所降低。根据长尾理论,虽然场景活跃度高的地方集中了大多数的用户需求,但是冷门的地方往往代表了用户个性化需求[8]。因此,需综合考虑场景活跃度和用户活跃度以计算位置信息影响因子[9,10]。假定场景活跃度是N(s),用户活跃度是N(u),假定位置信息影响因子定义W为:

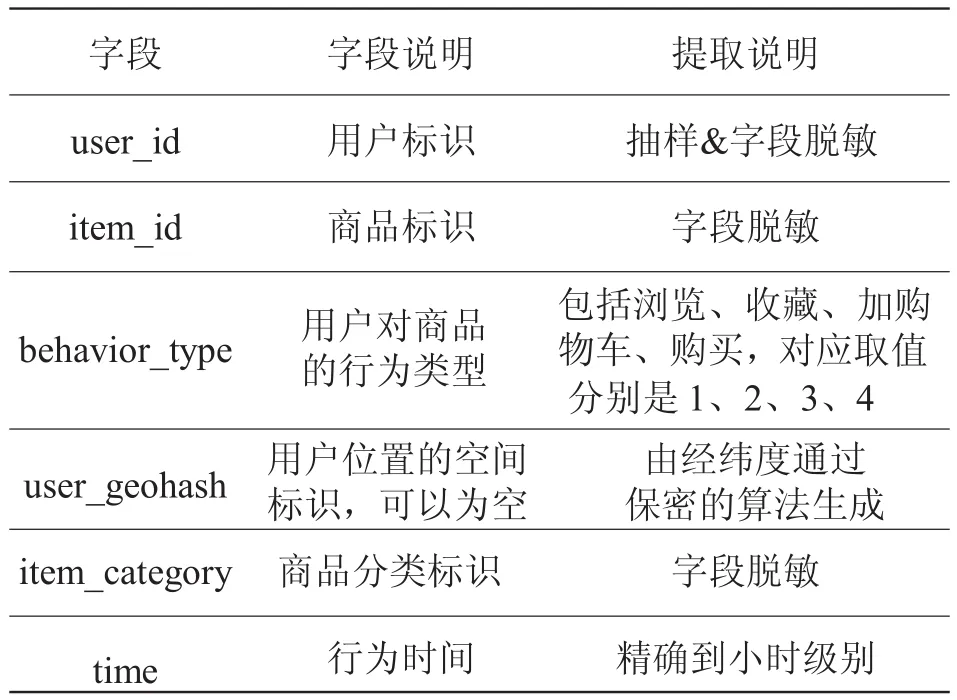
实验时,N(s)以场景所在地的品牌转化率表示,N(u)以用户在此场景所在地的品牌转化率表示,其中0 3.1原理及方法 Gradient Boost Decision Tree(GBDT)是Fridedman在1999年提出的一种组合模型,它的基本思想是通过构建M个弱分类器,经过多次迭代最终组合而成一个强分类器。每一次迭代是为了改进上一次结果,减少上一次模型的残差。并且在残差减少的梯度方向上建立新的组合模型[11]。为了描述模型的精确程度,引入损失函数。假定为训练样本,代表参数集合,β是每个分类器的权值,α是分类器内的参数,则以P为参数的x函数: 将式(2)写成梯度下降的形式为式(3),表示Fm(x)是之前所得模型Fm-1(x)的损失函数下降最快的方向: 对每个候选都计算偏导数gm(xi): 最终得到一个N维梯度下降方向向量: 使用最小二乘法得αm: 进而得到βm: 如此迭代M次最终得到参数集合P。 3.2改进梯度提升回归算法AGBDT: 梯度提升回归算法是一种组合决策树,通过对一系列的弱分类器累加,同时迭代逼近找出各分类器最佳权值,即损失函数在梯度下降方向时的参数,得出预测结果。原则上,各个分类器的初始权值一般设置相等,但本文研究O2O实际场景中,当前位置和时间对位置特征分类器有明显影响。通过多次实验将初始权值优化设置如下: 最终改进公式为: 其中,W是位置信息影响因子,n(T)是用户商品服务消费时间周期相关性函数。 4.1实验数据 实验数据为阿里巴巴公司在真实O2O电子商务业务场景下,一个月的移动端行为数据和下一天用于准确度计算的移动端行为数据。数据项包含了脱敏处理的用户ID、用户行为、行为触发时间、用户位置信息数据和商品ID、商品类别、商品位置信息。在真实的业务场景下,需要对所有商品的一个子集构建个性化推荐模型。在完成任务的过程中,不仅需要利用用户在这个商品子集上的行为数据,还需要利用更丰富的用户行为数据。定义符号如下:U——用户集合;I——商品全集;P——商品子集,P∩_I;D——用户对商品全集的行为数据集合。本文目标是利用D来构造U中用户对P中商品的推荐模型。 1)数据说明: 数据包含两个部分,如表1、2所示。第一部分是用户在商品全集上的移动端行为数据(D): 表1 用户行为日志字段说明 表2 商品数据字段说明 训练数据包含了抽样出来的一定量用户在一个月时间(11.18~12.18)内的移动端行为数据(D),测试数据是这些用户此后一天(12.19)对商品子集(P)的购买数据。实验将使用训练数据建立推荐模型,并输出用户在此后一天对商品子集购买行为的预测结果。 2)评估指标: 采用经典的精确度(precision)、召回率(recall)和F1值作为评估指标[8]。计算公式如下: 其中PredictionSet为算法预测的购买数据集合,ReferenceSet为真实的答案购买数据集合。我们以F1值作为最终的唯一评测标准。 4.2实验设计 4.2.1特征提取 原始数据包含字段:用户ID、商品ID、商品类别ID、时间(精确到小时)、地理位置、用户行为。首先划分特征类别,比如分为用户—商品类特征,用户—商品类别类特征,商品—商品类别特征,商品类特征,用户类特征,商品类别类特征,交叉特征等几个方面。划分粒度分为月,周,天,小时,初步数据统计之后会发现购买时间热段和冷段,来适当调整时间片长度。主要特征有:直接特征,按时间维度划分点击次数,购买次数,收藏次数,加入购物车次数;位置特征,划分基于位置信息的各种用户行为;转化率特征,品牌被点击,收藏,加入购物车到成功购买的转化率;时间特征:最后一次购买,点击,收藏,加入购物车的时间差,同类商品平均购买时间间隔,历史至今点击,购买的天数。为了获取基于位置信息的用户活跃度N(u)和场景活跃度N(s),需要提取用户-位置-转化率三维特征,位置-转化率二维特征。 4.2.2实验结果与分析 本文在构建完成的训练集中,正负样本的比例采取大约为1:300,首先为了评估特征个数对实验结果的影响,固定迭代次数k=300,得到图1特征个数m与F1之间的曲线关系。由图1可知,当m在[10, 20]上升趋势明显,m>30,F1分数平缓增长,m=80时,取得最大值。m>80后,曲线有下降趋势。综合考虑F1分数和算法复杂度,m=80效果最好。 图1 特征个数与F1分数相关曲线 在取特征个数m=80,评估在算法GBDT和改进算法AGBDT下,迭代次数和F1分数的关系,训练结果如图2所示,迭代次数相同的情况下,改进算法AGBDT取得更高F1分数,说明合理预判决策树权值有助于降低迭代次数。迭代次数k在[50, 100]时,两种算法的F1值趋势明显上升,k>100,增速放缓,k>400有明显下降趋势。综合考虑,迭代次数选择k=350。 图2 迭代次数和F1分数相关曲线 最终,在正负样本比例取1:300,特征个数m=80,迭代次数k=350,取得实验结果如表3: 表3 实验最终结果 综上所述,GBDT算法由多个弱分类器组成的强分类器具有较强的泛化能力,可以综合考虑多个特征组合的不同情形,在本文中,为了在推荐模型中考虑当前位置信息对用户购物行为的影响,在相对应的特征分类器上添加了相关位置信息相关因子,和时间消费周期函数。实验结果表明,改进算法取得了良好的准确率和召回率。 本文在应用GBDT算法实现基于用户购物行为历史数据预测下一步购物行为的基础上,进行了随着位置改变引起的推荐内容变化的算法改进。不过由于条件限制,并未做线上实时推荐测试,因此关于算法推荐模型的实际运行情况将成为下一个研究重点。 参考文献 [1]许海玲,吴潇,李晓东,等.互联网推荐系统比较研究[J]. 软件学报,2009,20(2):350-262. [2]Leungcw, Chansc, Chungf, et al. An empirical study of a cross-level association rule mining approach to cold-start recommendations[J]. Knowledge-Based Systems, 2008, 21(7): 515-529. [3]马宏伟,张光卫,李鹏.协同过滤推荐算法综述[J].小型微型计算机系统,2009,30(7):1282-1288. [4]Agrawal R, Imuekubsju R, Swami A. Mining association rules between sets of items in large databases[C].//.Proc. of ACM SIGMOD International Conference on Management of Data. New York: ACM Press,1993;207-216. [5]闫友彪,陈元琰.机器学习的主要策略综述[J]. 计算机应用研究,2004,(7):4-11. [6]Friedman JH. Greedy function approximation:a gardient boosting machine[J]. Annal of Statistics, 2000, 29(5): 1189-1232. [7]孟祥武,胡勋,王立才,等. 移动推荐系统及其应用[J]. 软件学报,2013,24(1):91-108. [8]项亮.推荐系统实践[M].北京:人民邮电出版社,2012. [9]张新猛,蒋盛益,张倩生,等.基于用户偏好加权的混合网络推荐算法[J].山东大学学报(理学版),2015(50):30-34. [10]王兴茂,张兴明.基于贡献因子的协同过滤推荐算法[J].计算机应用研究,2015, 32(12): 3351- 3354. [11]Friedman JH. Stochastic gradient boosting[J]. Computatianal Statistics & Data Analysis, 2002,38(4): 367-378 基金支持:安徽省自然科学基金(1408085QE94) A Recommendation Model for O2O E-commercebased on Improved Gradient Boosting Regression Trees SUN Kelei,DENG Xianrong Abstract:Location attribute exerts important infuences on offine consuers. In order to improve the accuracy of personalized recommendation, basing on the analysis of the O2O e-commerce with user characteristics, this paper introduces the current time and location parameters to the basis of the recommendation algorithm, and it proposes O2O e-commerce recommendation model on improved gradient boosting regression tree The results show this model is apparently superior to the traditional recommendation algorithm both in real-time and accuracy. Keywords:GBDT, LBS, Personalized recommendations, behavior log analysis 作者简介:孙克雷(1980-),男,博士,副教授,主要研究方向为信息融合。 收稿日期:2015-12-08 DOI:10.11921/j.issn.2095-8382.20160217 中图分类号:TP391 文献标识码:A 文章编号:2095-8382(2016)02-087-053 梯度提升回归算法(Gradient Boost Decision Tree)
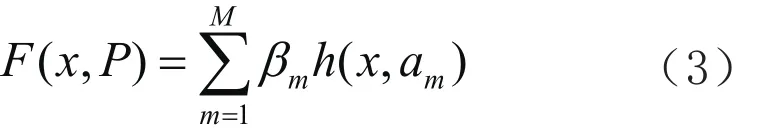

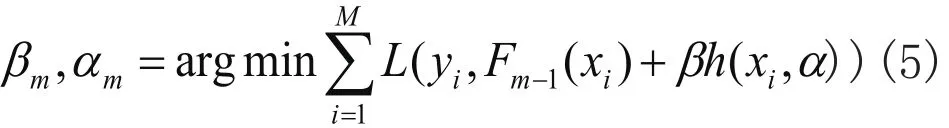

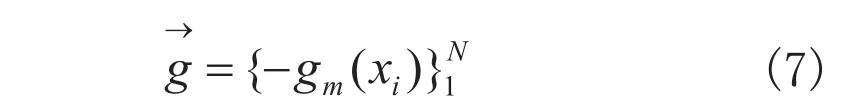




4 实验结果与分析





5 总结与展望
(School of Computer Science and Engineering, Anhui University of Science and Technology, Huainan 232001, China)
